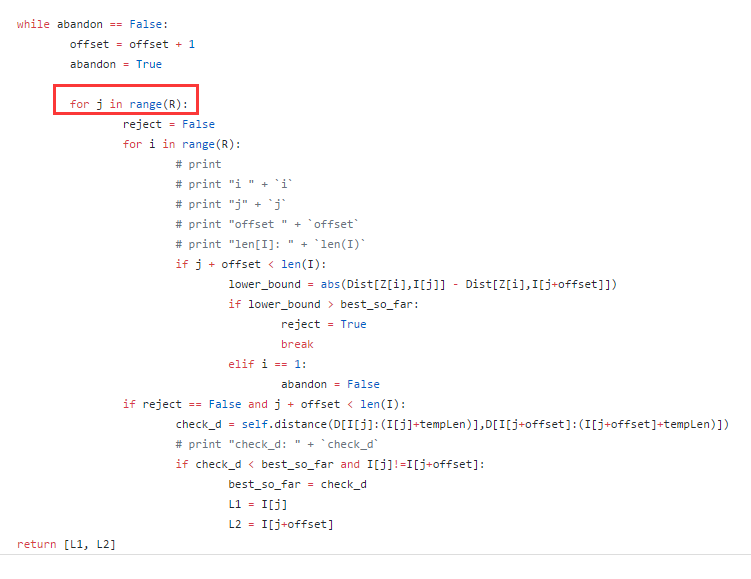
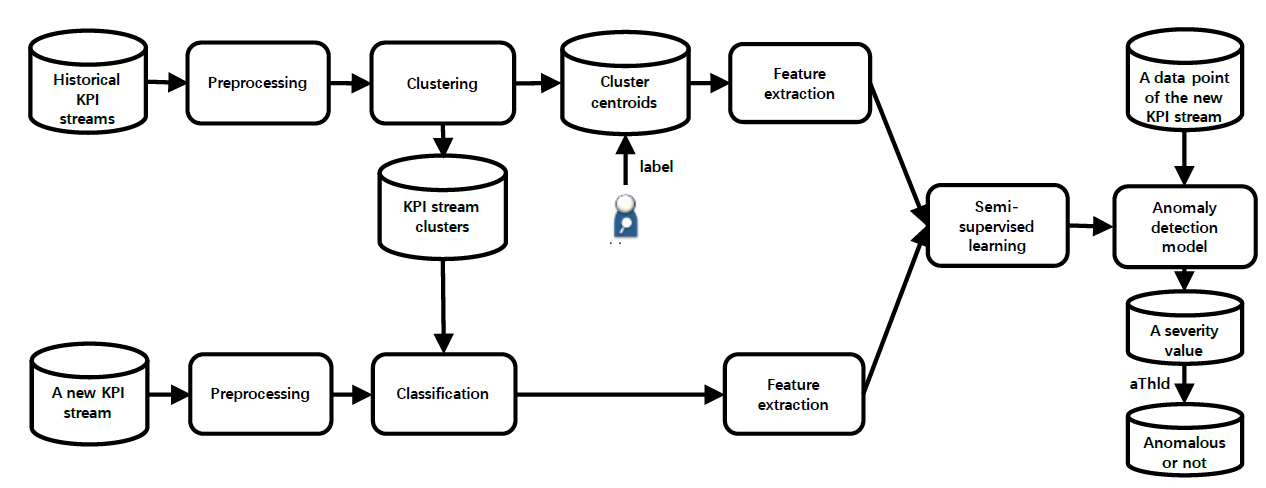
1. ChatTS概述
ChatTS: Aligning Time Series with LLMs via Synthetic Data for Enhanced Understanding and Reasoning 这篇文章是清华大学、字节跳动与必示科技三方共同创作而成。

在实际的工作中,时间序列在运维领域中占据着非常重要的地位,尤其是近些年大语言模型(LLM)的发展,极大地推动了时间序列这一领域的发展。这篇论文介绍了一个叫做ChatTS的模型,它是专为时间序列分析设计的新型多模态大语言模型(MLLMs)。为缓解训练数据稀缺问题,作者们提出基于属性的合成时间序列生成方法,可自动生成具有详细属性描述的时序数据。同时,作者们创新性地提出时间序列演化式指令生成方法(Time Series Evol-Instruct),通过生成多样化时序问答对来增强模型的推理能力。ChatTS是首个以多元时间序列作为输入,并进行理解和推理的时间序列多模态大语言模型,且完全基于合成的数据集微调。作者们在包含真实数据的基准数据集上开展评估,涵盖6项对齐任务和4项推理任务。
实验结果表明,ChatTS在对齐任务中提升46.0%,在推理任务中提升25.8%,其代码的官方链接是: https://github.com/NetManAIOps/ChatTS,HuggingFace的官方链接是:https://huggingface.co/bytedance-research/ChatTS-14B/tree/main ,模型的权重都可以在HuggingFace上面直接下载并使用。
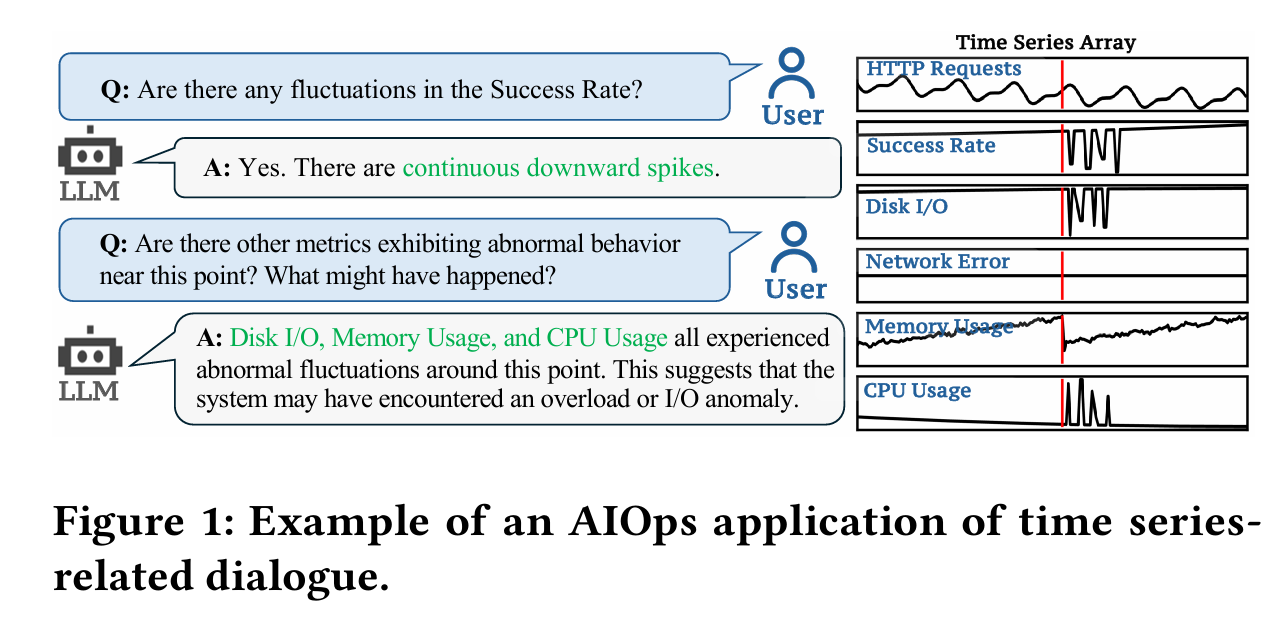
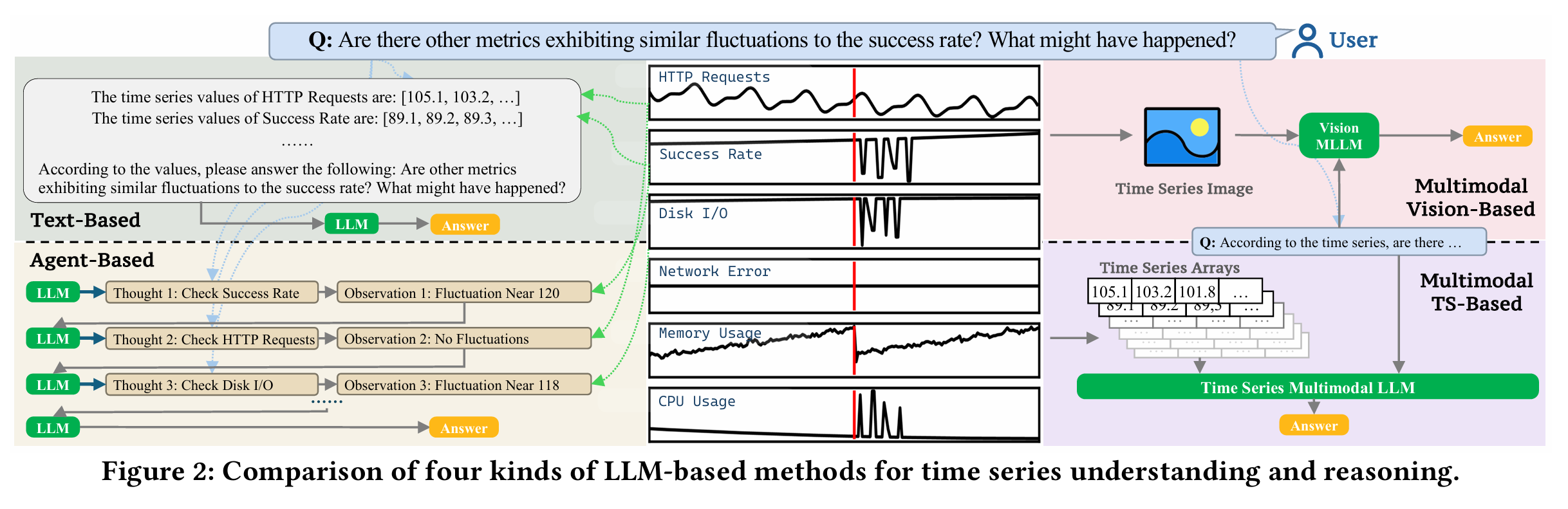
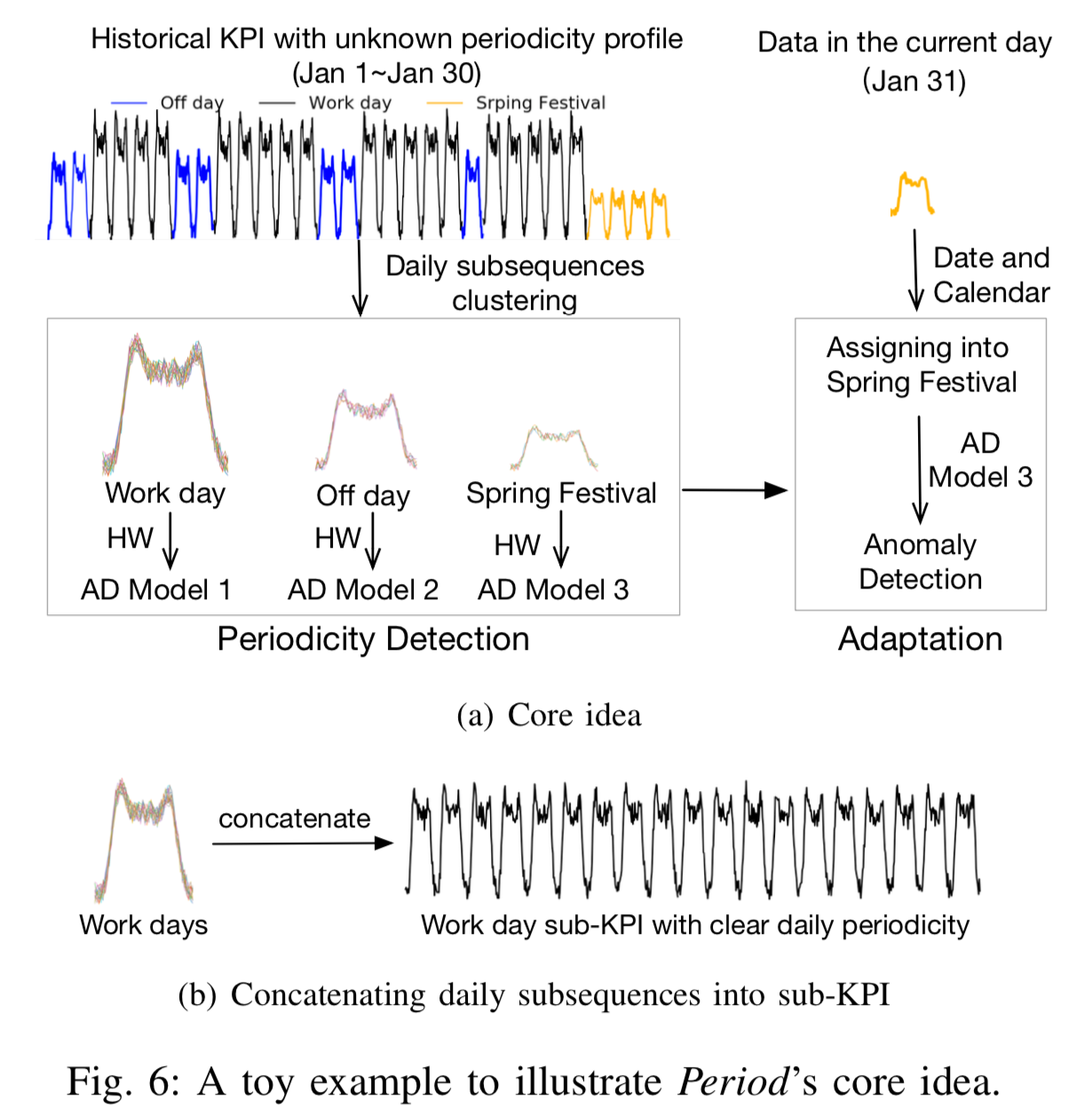
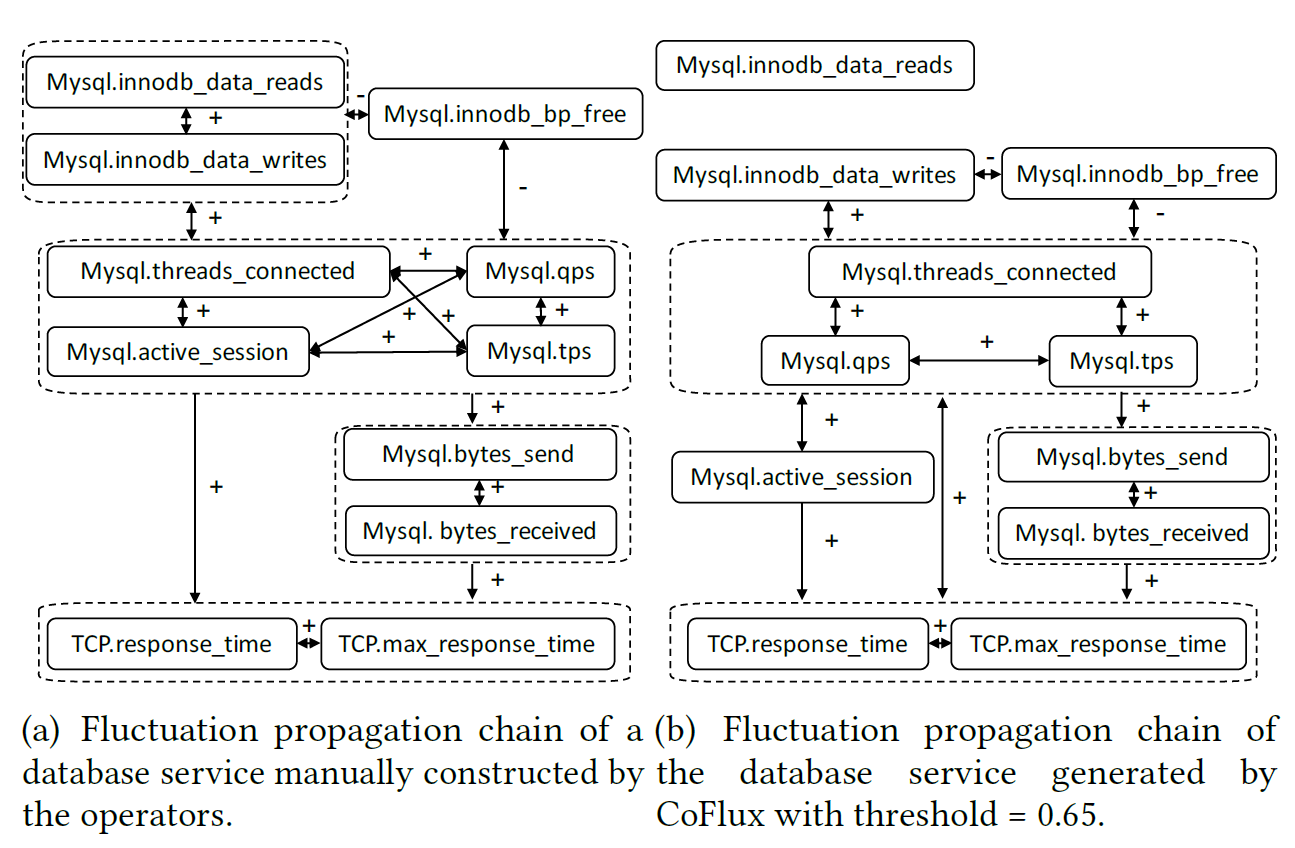
用一个实际的例子来说明这个情况,那就是用户可以针对某个KPI曲线进行提问,并咨询是否有其他曲线存在了波动,然后并提问根因,大语言模型(LLM)进行了回答。
从图2的描述来看,如果要将多条时间序列进行输入,其实可以至少有四种方法可以执行:
- Text-Based:将多条时间序列整理成具体的数值,然后一次性输入给大模型进行分析和输出;
- Agent-Based:不同的时间序列输入给不同的大模型,然后一次性汇总之后进行汇总大模型LLM的处理和输出;
- Multimodal Vision-Based:将时间序列处理成图片信息,然后通过多模态大模型进行处理和分析,然后输出结果;
- Multimodal TS-Based:将多条时间序列的数值直接输入大模型,开发一个Time Series Multimodal LLM并做输出。
ChatTS的亮点是将多维时间序列直接作为输入,然后进行推理和分析。目前是一个14B的模型,它是在QWen2.5-14B-Instruct的基础上进行微调的,其开源代码使用也很简单,可以参考下面的代码:
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoProcessor
import torch
import numpy as np
# Load the model, tokenizer and processor
model = AutoModelForCausalLM.from_pretrained("./ckpt", trust_remote_code=True, device_map=0, torch_dtype='float16')
tokenizer = AutoTokenizer.from_pretrained("./ckpt", trust_remote_code=True)
processor = AutoProcessor.from_pretrained("./ckpt", trust_remote_code=True, tokenizer=tokenizer)
# Create time series and prompts
timeseries = np.sin(np.arange(256) / 10) * 5.0
# 构造异常的时间序列取值
timeseries[100:] -= 10.0
prompt = f"I have a time series length of 256: <ts><ts/>. Please analyze the local changes in this time series."
# Apply Chat Template
prompt = f"<|im_start|>system\nYou are a helpful assistant.<|im_end|><|im_start|>user\n{prompt}<|im_end|><|im_start|>assistant\n"
# Convert to tensor
inputs = processor(text=[prompt], timeseries=[timeseries], padding=True, return_tensors="pt")
# Move to GPU
inputs = {k: v.to(0) for k, v in inputs.items()}
# Model Generate
outputs = model.generate(**inputs, max_new_tokens=300)
print(tokenizer.decode(outputs[0][len(inputs['input_ids'][0]):], skip_special_tokens=True))
如果是使用vLLM推理的话,可以参考这份代码:
import chatts.vllm.chatts_vllm
from vllm import LLM, SamplingParams
# Load the model
language_model = LLM(model="./ckpt", trust_remote_code=True, max_model_len=ctx_length, tensor_parallel_size=1, gpu_memory_utilization=0.95, limit_mm_per_prompt={"timeseries": 50})
# Create time series (np.ndarray) and prompts (chat_templated applied)
ts1, ts2 = ...
prompt = ...
# Model Inference
outputs = language_model.generate([{
"prompt": prompt,
"multi_modal_data": {"timeseries": [ts1, ts2]}
}], sampling_params=SamplingParams(max_tokens=300))
2 ChatTS方法论
2.1 模块划分
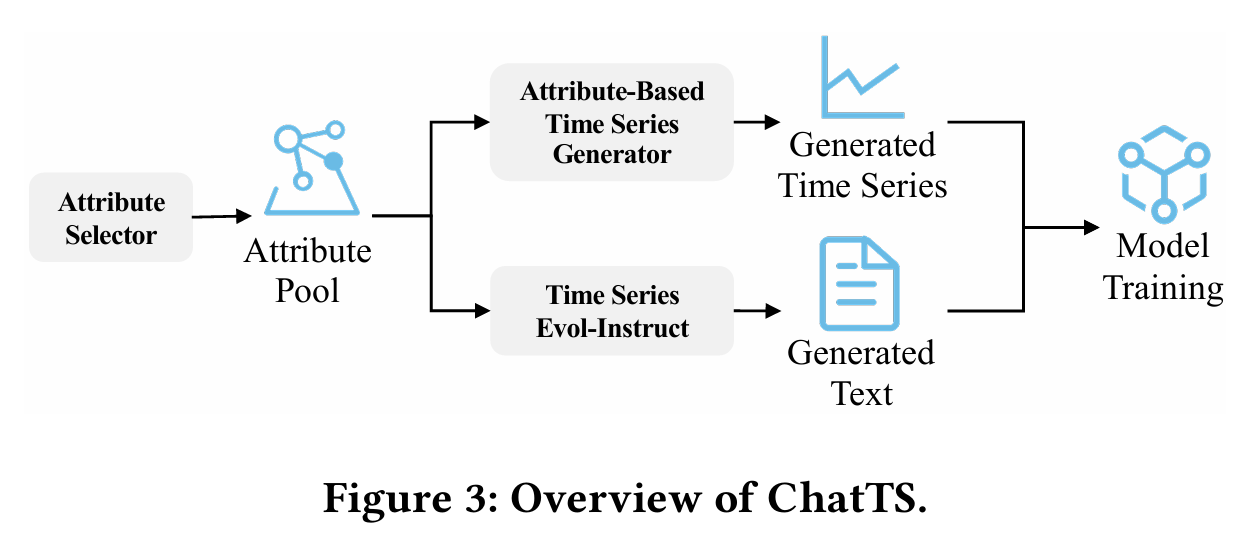
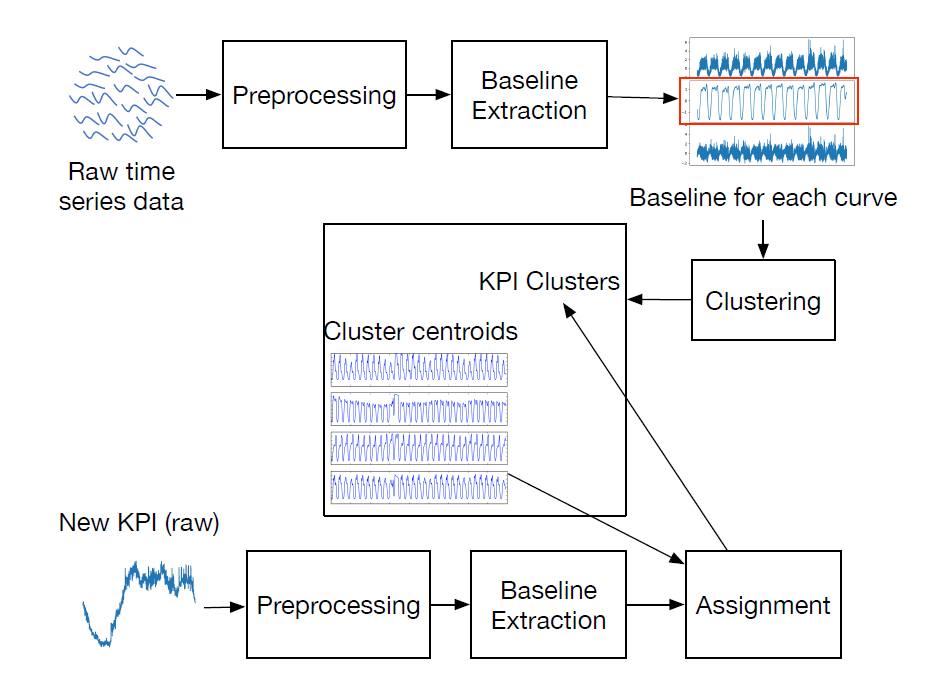
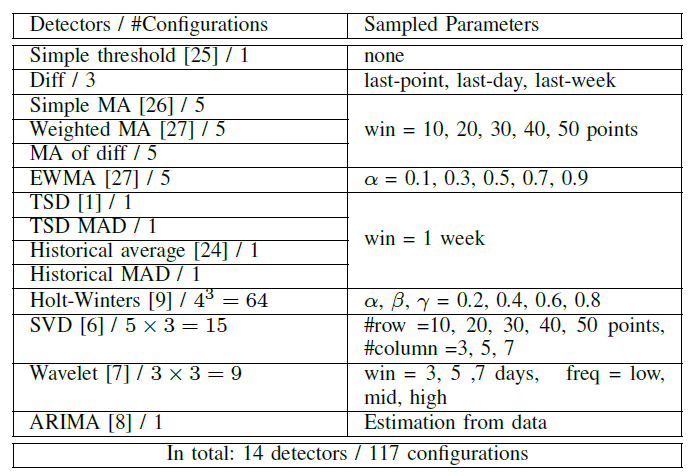
从论文的介绍来看,ChatTS的数据模块大概可以分成以下几个情况:
- Attribute Selector:属性选择器,主要用于精准的属性选择,方便生成满足这些属性的时间序列;属性包括趋势类(稳定趋势、上升趋势、下降趋势等),周期类(三角函数、正方形、无周期等),局部波动类,是否存在噪声等类别。
- Attribute-Based Time Series Generator:基于属性的时间序列生成器,可以使用规则的方法进行生成;
- Time Series Evol-Instruct:时间序列演化式指令,用于生成大量的、多样的、精准的时间序列,并且有相应的文本回答,属于一个(time series,text question-answer)的信息;
- 模型设计(model design):使用了多维时间序列作为数据的输入;
- 模型训练(model training):使用了监督微调(SFT,Supervised Fine-Tuning)的方法,在已有模型的基础上进行了微调;
整体的流程可以参考下图的方法:通过选择不同的属性,生成不同的样本数据,以及相应的问题和答案。
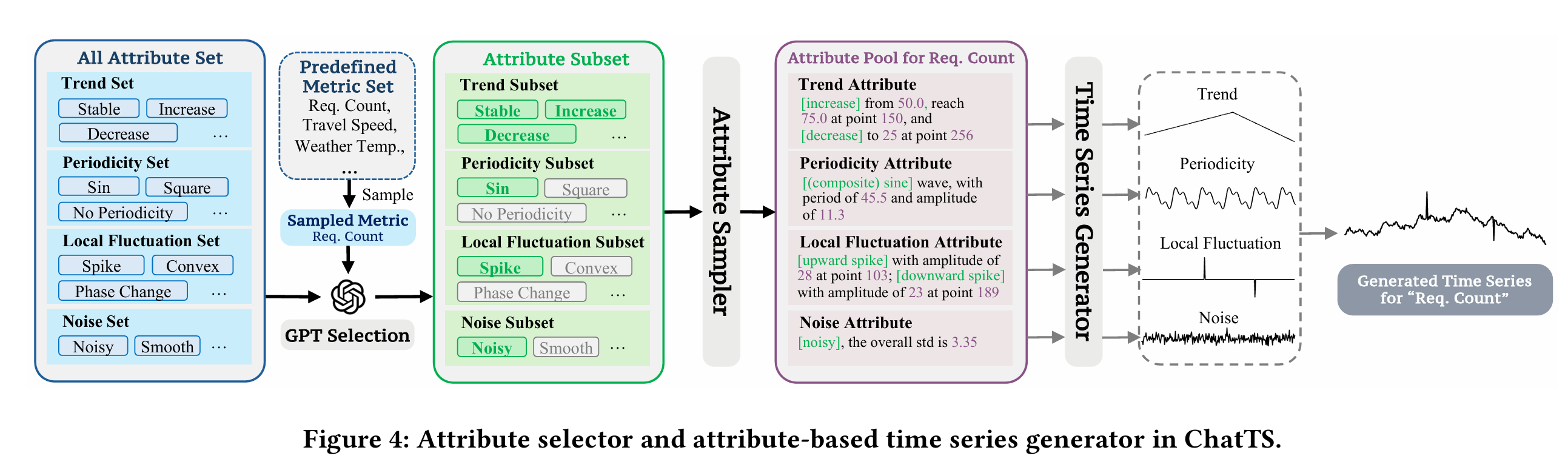
同样的,时间序列的相应指令可以参考下图:
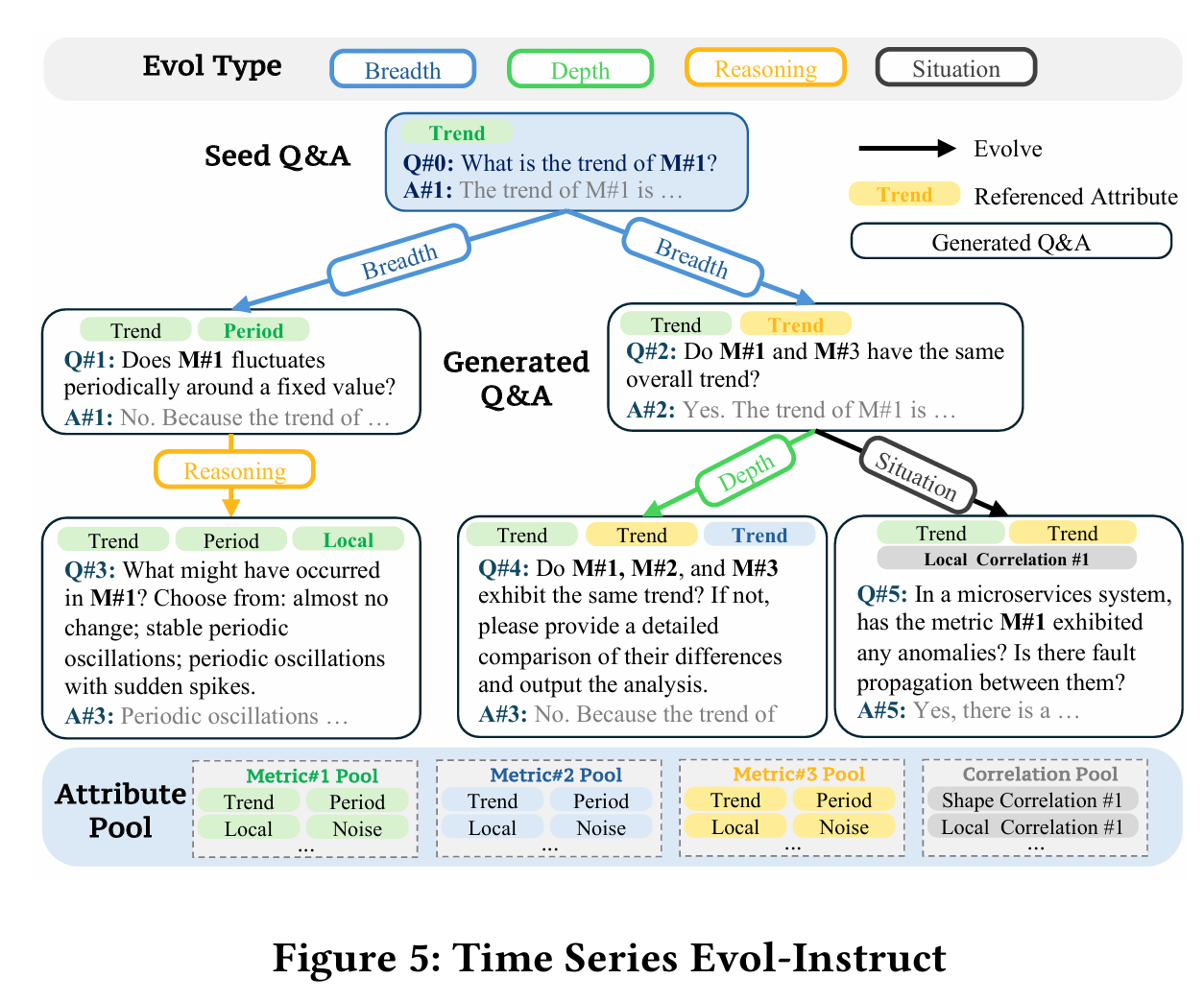
2.2 模型微调
而在模型微调的时候,需要将时间序列和文本进行分别输入,按照一定的格式进行编码,其中包括对时间序列的解释,以及相应的问题和答案。
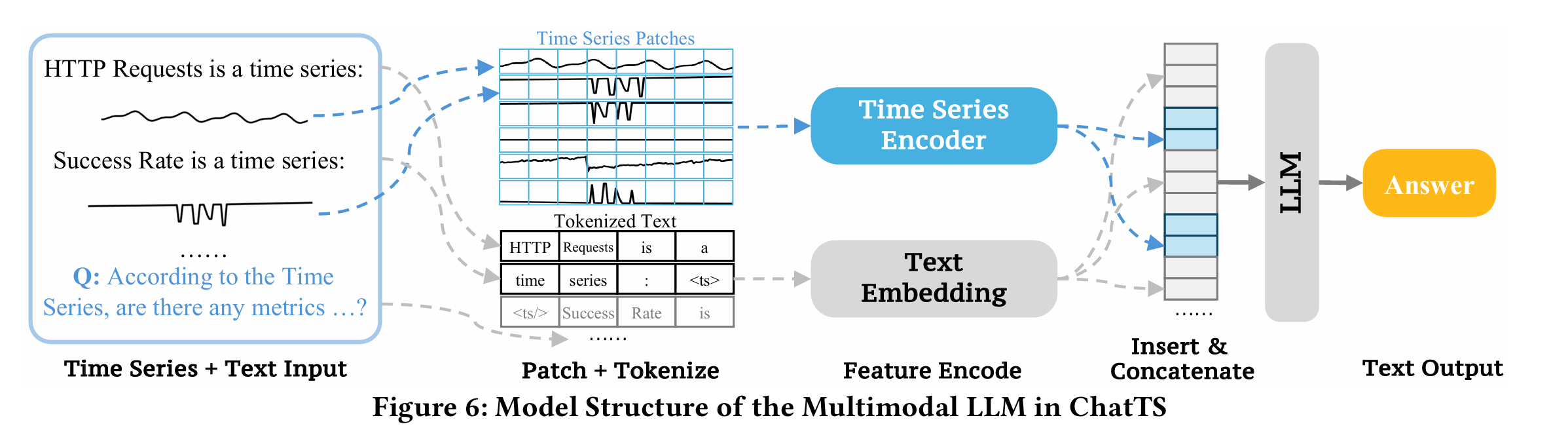
而ChatTS的样本训练大约是万这个量级,在现有模型的基础上即可微调出不错的结果。
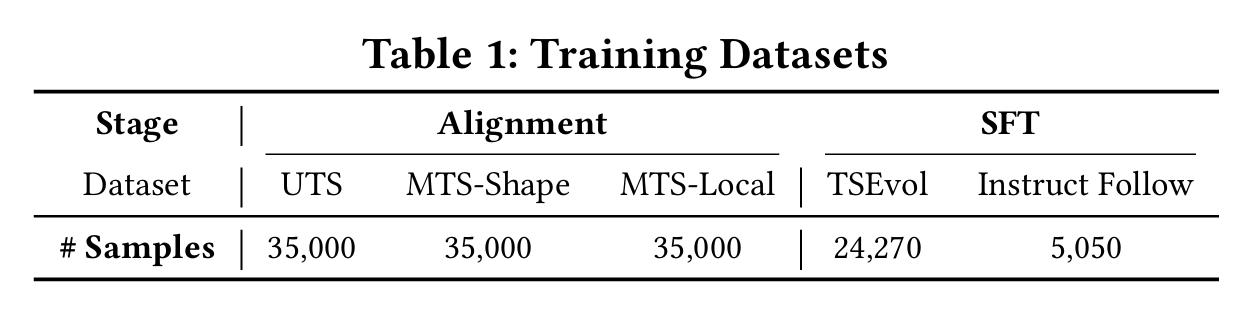
ChatTS的训练可以在QWen2.5-14B-Instruct的基础上进行两阶段的微调,包括大尺度的微调训练(large-scale alignment training)和监督微调(SFT)。具体的问答案例可以参考图8的内容。

模态对齐训练阶段
在第一阶段,我们使用基于属性的合成时间序列数据进行大规模对齐训练,以建立大语言模型中文本与时序模态的初步对齐。此阶段使ChatTS能够有效实现文本描述与时序属性的语义映射。在模态对齐阶段,通过手工设计模板和LLM精炼构建了三个训练数据集:
- UTS(单变量时间序列)数据集 :包含单变量时序基础属性描述任务(涵盖全局与局部属性分析);
- MTS-Shape(多元形态)数据集 :由具有全局趋势相关性的多元数据构成,旨在增强模型分析多元相关性的能力;
- MTS-Local(多元局部)数据集 :包含局部波动相关的多元数据,重点提升模型对多元时序局部特征的分析能力;
鉴于多元时序(MTS)具有更复杂的特征组合,我们将MTS与UTS的训练数据规模设定为约2:1的比例(具体训练数据规模对模型性能的影响详见第4.5节的数据集扩展研究)。
监督微调阶段
在第二阶段,通过监督微调(SFT)开发模型执行复杂问答与推理任务的能力。该阶段主要使用两类训练数据:
- TSEvol生成数据集 :通过时间序列演化式指令生成方法(Time Series Evol-Instruct)构建,用于增强模型对时序问题的问答推理能力;
- 指令遵循(IF)数据集 :基于预定义模板构建,专门训练模型遵循特定响应格式;
对于TSEvol方法,我们使用对齐训练阶段的数据集配合LLM生成的问答对作为种子数据。通过联合训练,使多模态大语言模型能够精准响应时序领域查询,并强化其处理上下文驱动的复杂推理任务的能力。在模态对齐和监督微调阶段,我们通过系列数值任务系统提升ChatTS的数值分析能力,包括:极值识别、分段均值计算、局部特征提取(如尖峰位置/幅度)、季节性与趋势振幅分析、以及单点原始数值解析。实验结果中的数值评估指标验证了ChatTS在时序数值分析方面的卓越性能。
训练配置
- 数据格式:两阶段均采用问答对格式。在模态对齐阶段混入少量IF数据以缓解指令遵循能力退化;
- 防止过拟合策略:SFT阶段混30%对齐训练数据集;
- 时序长度覆盖:训练数据包含64-1024长度的时序序列,确保模型处理变长时序的能力;
- 训练框架:基于DeepSpeed和LLaMA-Factory [65]进行全参数监督微调,基础模型选用Qwen2.5-14B-Instruct;
- 推理环境:Qwen与ChatTS均采用DeepSpeed框架部署。

3 ChatTS评估方法
3.1 数据的评估
本节通过回答以下研究问题(research questions)全面评估ChatTS的性能:
- RQ1:ChatTS与时序数据的对齐效果如何?
- RQ2:ChatTS在时序推理任务中的表现如何?
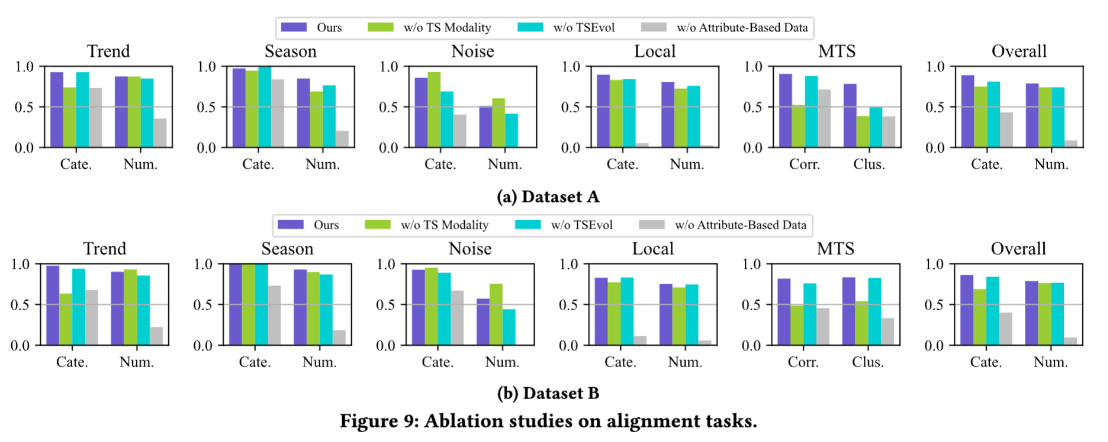
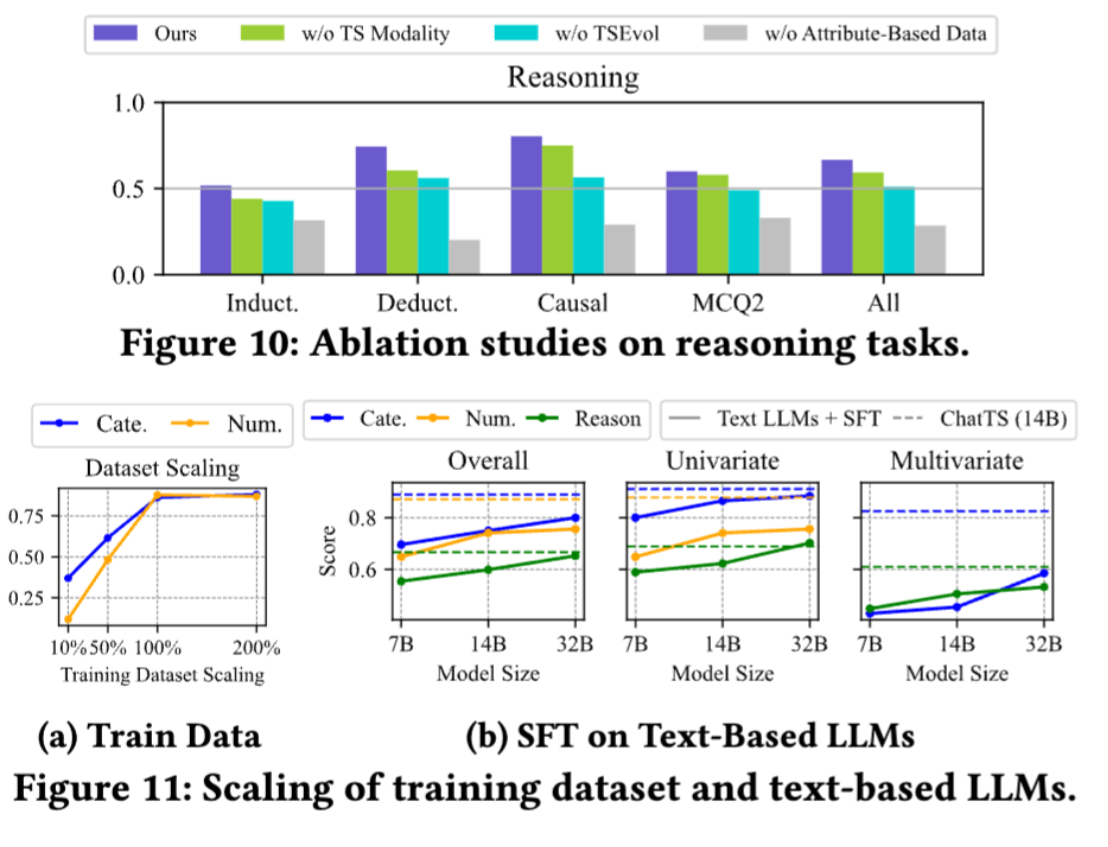
- RQ3:基于属性的合成数据与TSEvol方法是否有效?
- RQ4:训练集规模如何影响模型性能?
- RQ5:ChatTS的时序模态设计是否真正发挥作用?
- RQ6:ChatTS的原生时序多模态能力是否优于代理型方法?
参照多模态大语言模型通用评估范式,我们将评估任务分为两类:
- 对齐任务(验证文本-时序语义映射):(1)单变量任务:趋势识别、季节性检测、噪声分析、局部波动分析(含分类与数值子任务)(2)多元任务:相关性分析、聚类分析(均为分类任务)
- 推理任务(验证时序逻辑推演能力) (1)归纳推理:问答任务,对单/多元时序物理意义进行归纳总结(2)演绎推理:判断题(T/F),基于预设条件与单变量时序进行逻辑推演(3)因果推理:选择题,根据单变量时序选择最可能诱因(4)比较推理(MCQ2):选择题,对比两组时序选择正确答案
评估指标可以使用相对准确率:
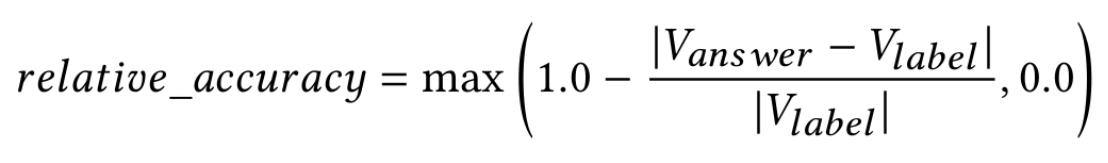
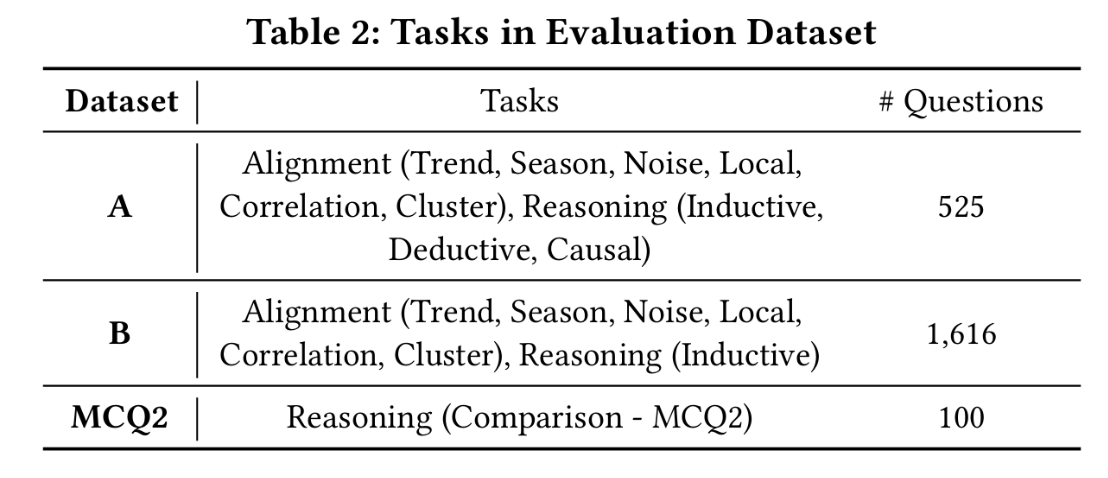
验证数据集采用以下数据:
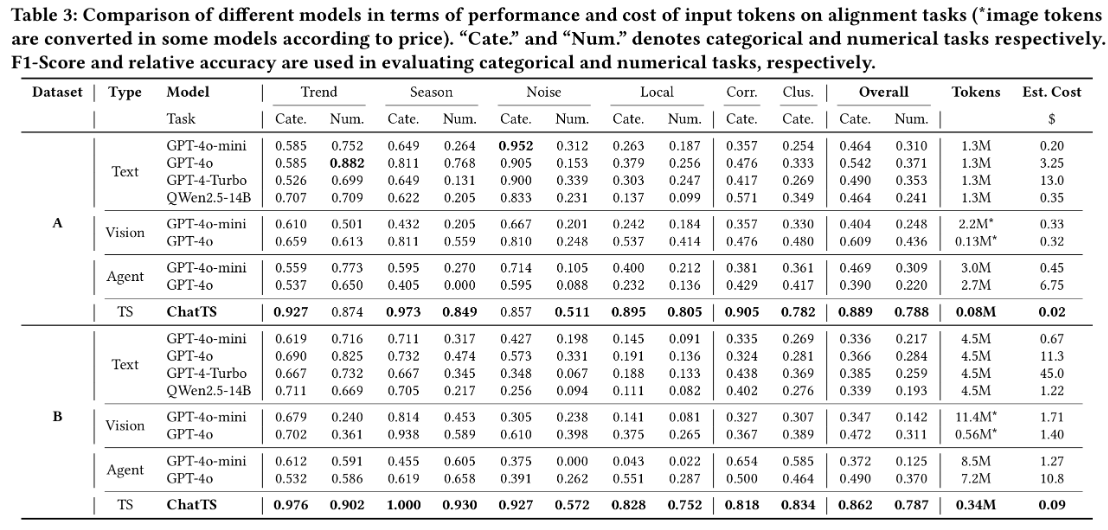
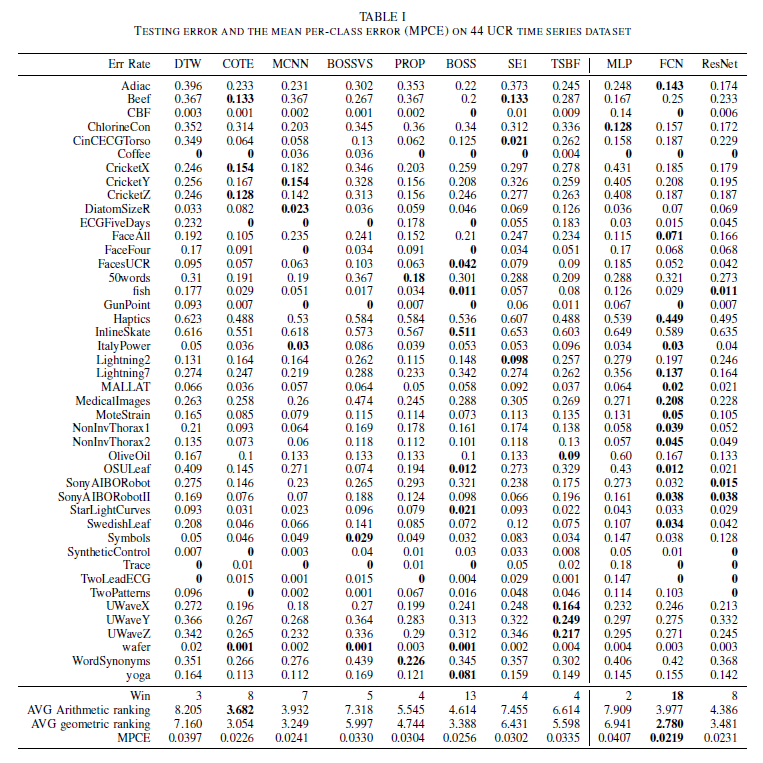
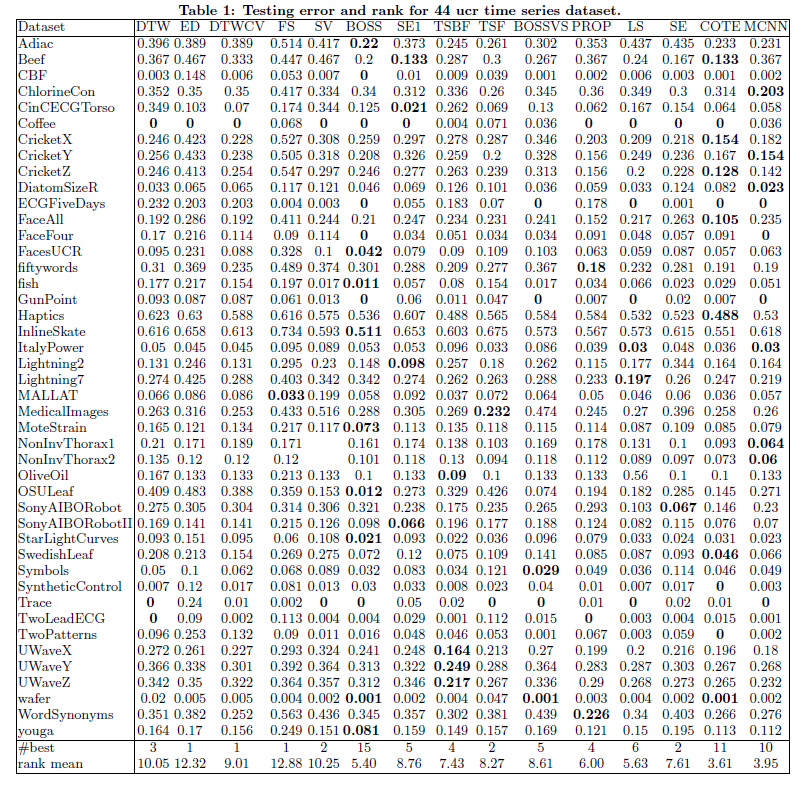
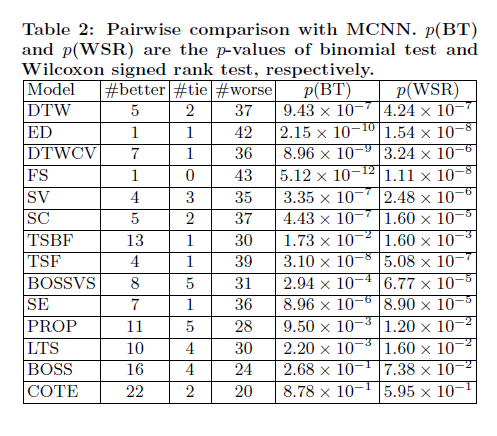
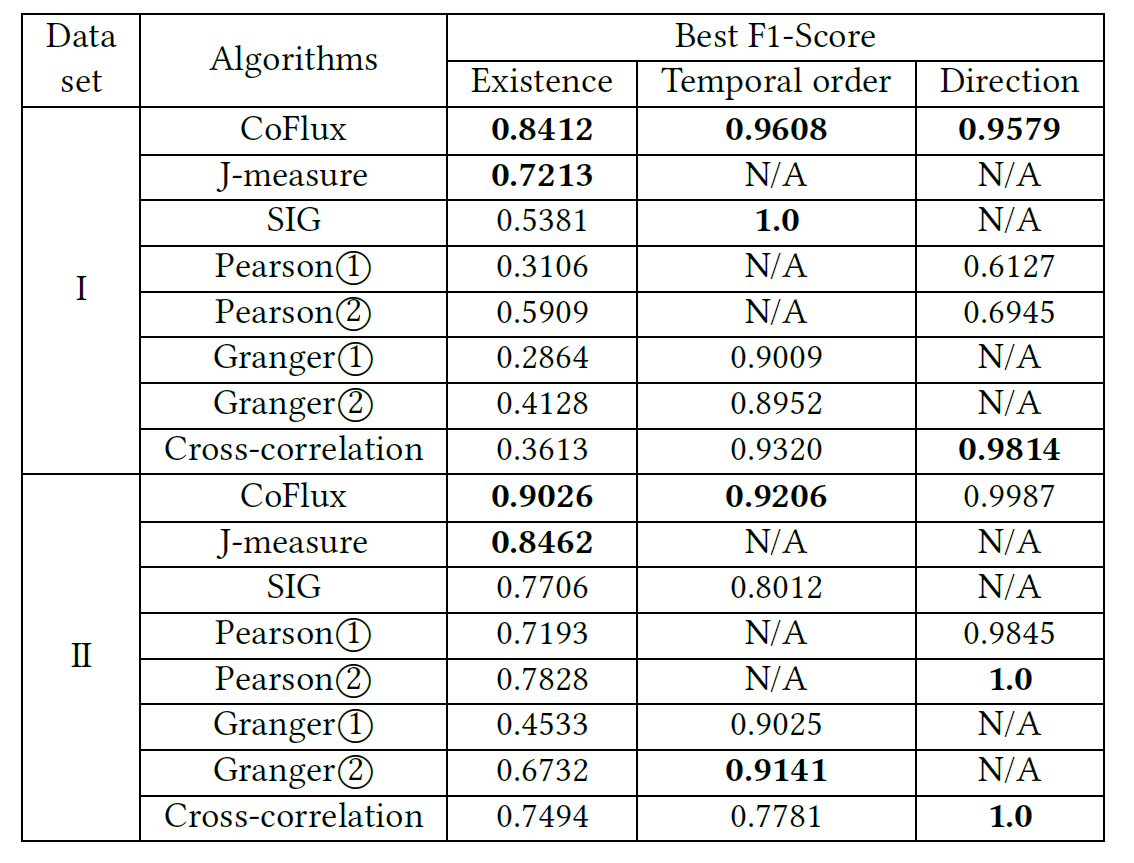
从模型的数据效果来看,相对其他开源模型和API的使用结果来看,ChatTS都获得了不错的数据表现:
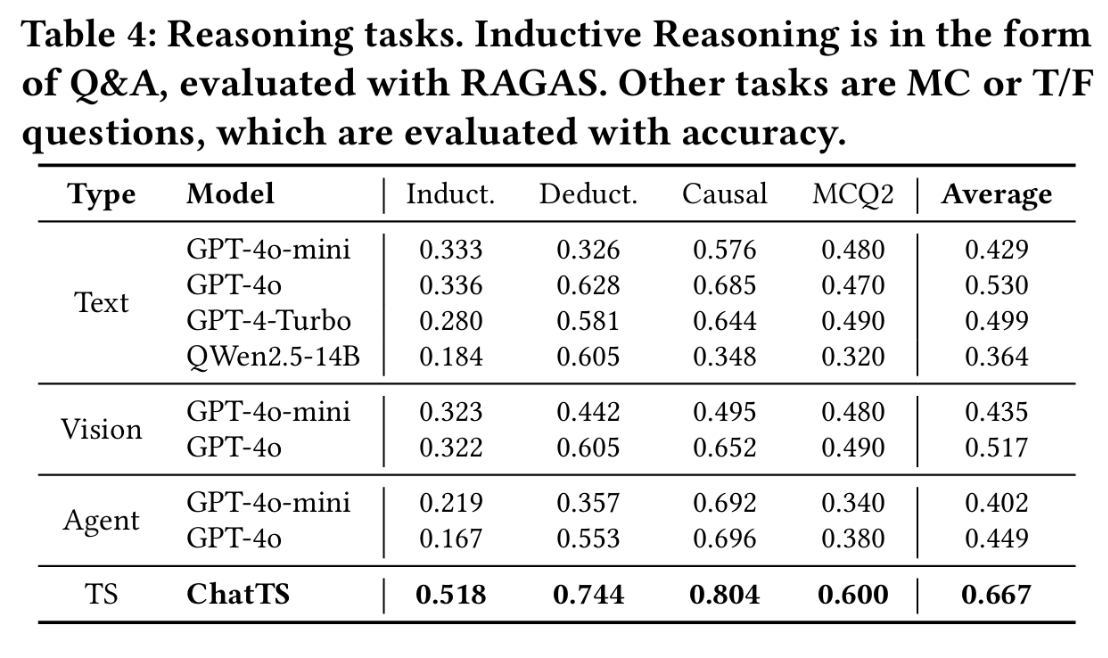
3.2 实战的评估
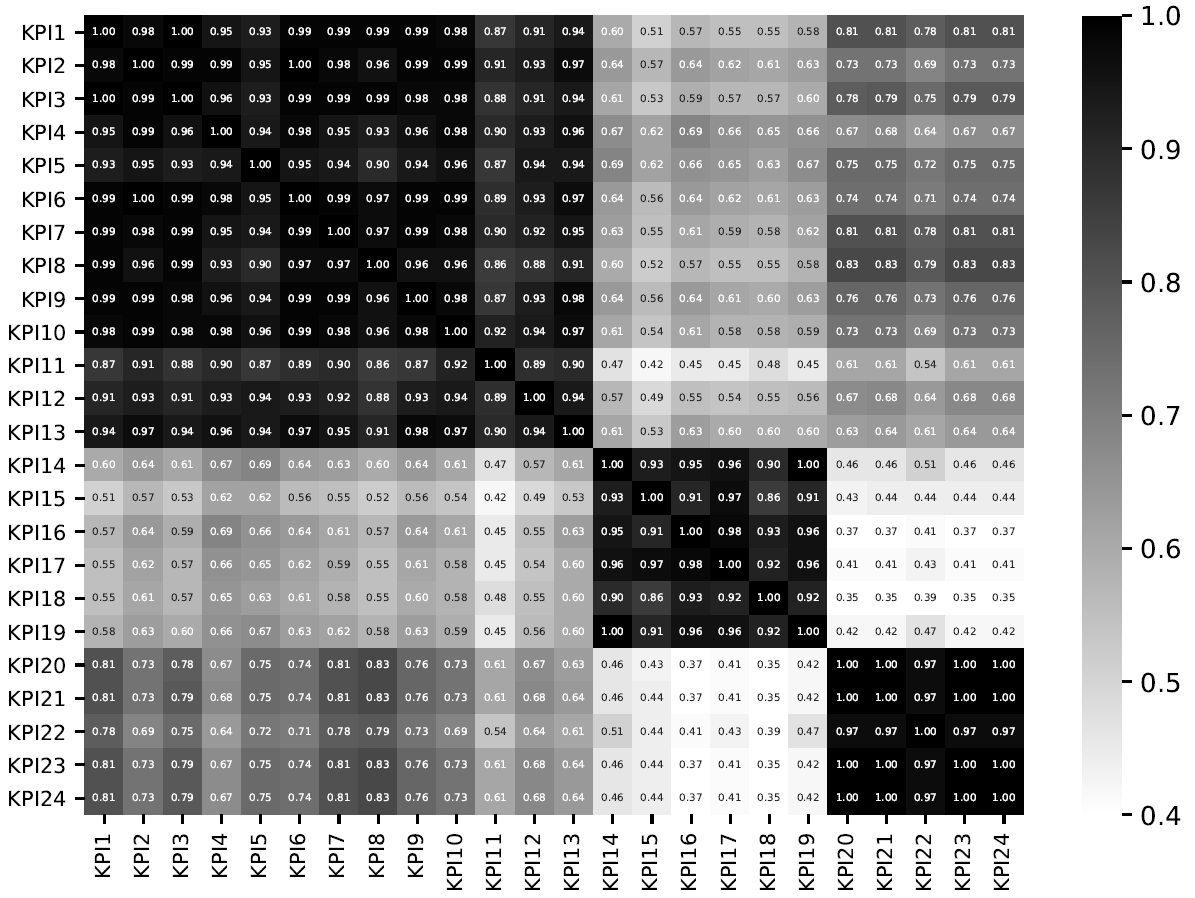
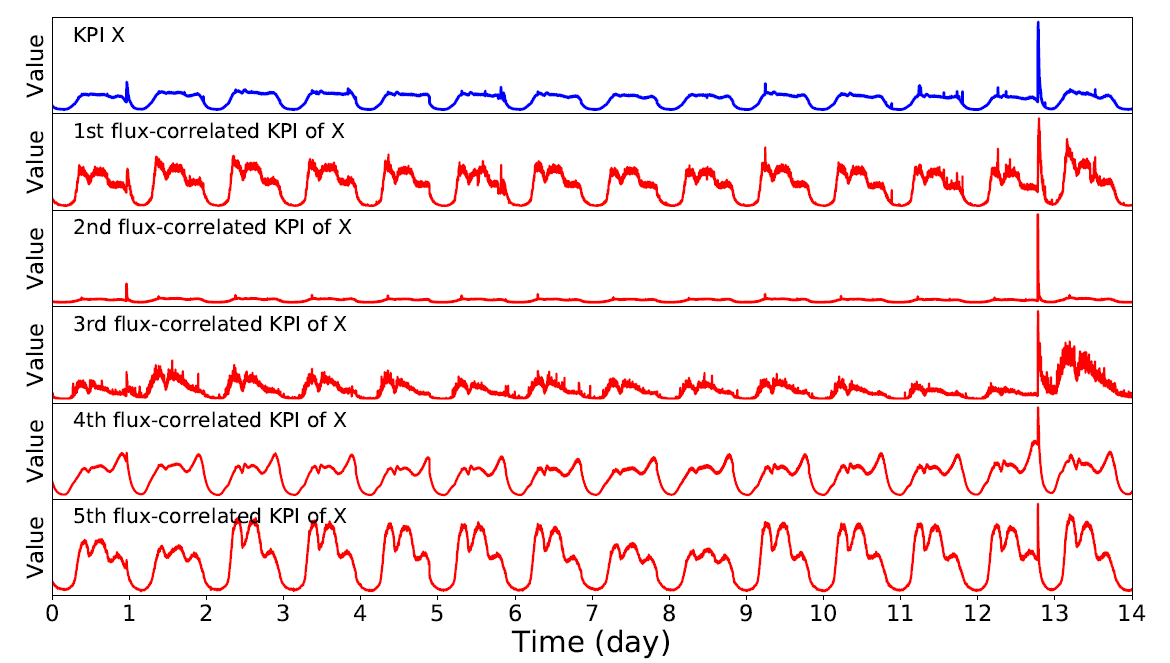
除了理论上的应用之外,ChatTS还可以用于各种实际的场景,例如形状与统计值分析:
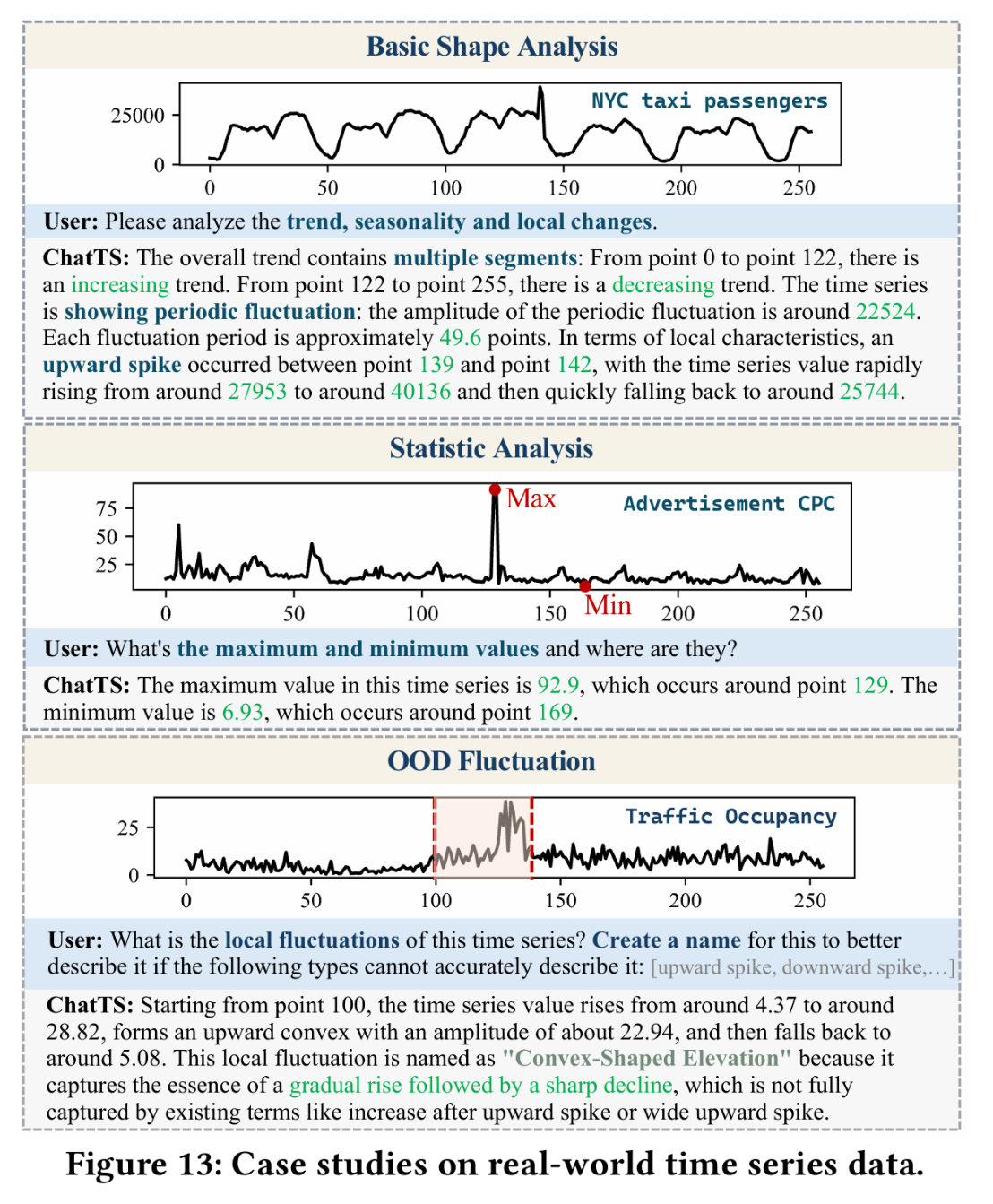
可以进行数据库的失效分析:

还支持时间序列数据的细节分析:

4 ChatTS论文总结
针对时间序列理解与推理领域长期存在的跨模态数据稀缺难题,本文提出首个支持多元时序输入的多模态大语言模型ChatTS,开辟了基于合成数据的时序语义对齐新模式,核心贡献体现在三个维度:
- 首创属性驱动的时序合成引擎,通过参数化建模生成兼具多样性和精确标注的时序-文本对,突破真实数据标注成本限制;
- 开发时序演化式指令生成框架(TSEvol),融合属性组合推理与Evol-Instruct机制,构建出覆盖复杂推理场景的20.8万高质量QA对;
- 建立多维度评估体系,在包含真实场景的跨领域数据集上验证模型性能,在时序对齐任务(F1=0.823)和因果推理任务(Acc=78.4%)上分别实现46.0%和25.8%的绝对性能提升,显著超越GPT-4o等基线模型。本研究不仅证实了合成数据在跨模态学习中的可行性,更为时序分析范式从传统特征工程向语义理解跃迁提供了技术基础设施,相关代码、模型及数据集已在GitHub开源。
这些成果验证了该方法在弥合时间序列数据与自然语言理解鸿沟方面的有效性。作者们已开源源代码、训练模型权重及评估数据集以供复现和后续研究:https://github.com/NetManAIOps/ChatTS。


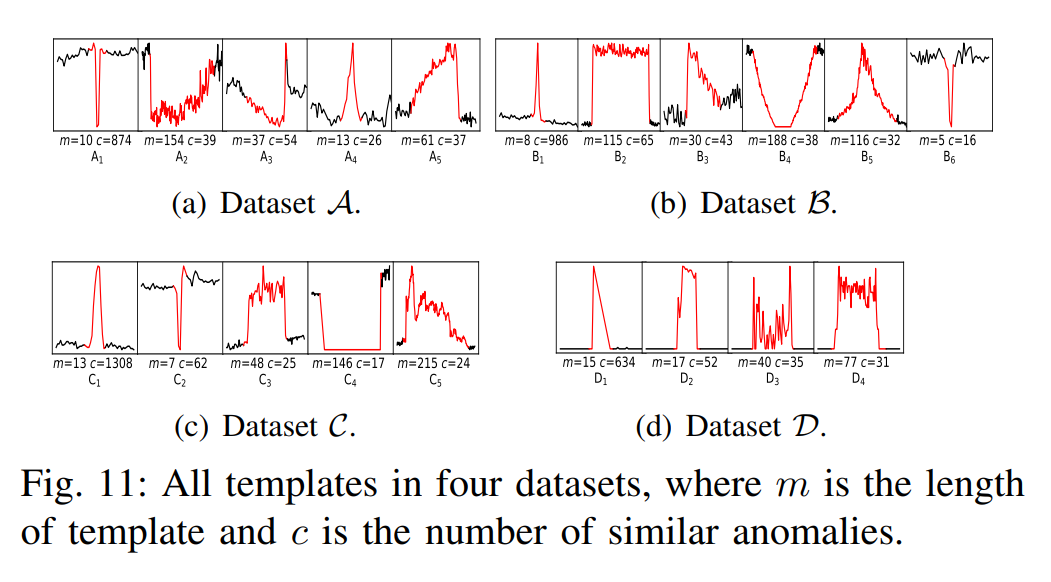
![£¨Í¼±í£©[Éç»á]2020Äê½Ú¼ÙÈշżٰ²ÅŹ«²¼](https://zr9558.com/wp-content/uploads/2020/05/2020e5b9b4e4b8ade59bbde88a82e58187e697a5e5ae89e68e92.jpg)
 和
和  ,提出了相似性的计算方法。
,提出了相似性的计算方法。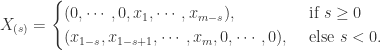
 的个数都是
的个数都是 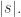 进一步可以定义,当
进一步可以定义,当 ![s\in[-w,w]\cap\mathbb{Z}](https://s0.wp.com/latex.php?latex=s%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 时,
时,
 归一化之后的最大值作为
归一化之后的最大值作为 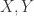 的相似度,i.e.
的相似度,i.e.![NCC(X,Y)=\max_{s\in[-w,w]\cap\mathbb{Z}}\frac{CC_{s}(X,Y)}{\|x\|_{2}\cdot\|y\|}.](https://s0.wp.com/latex.php?latex=NCC%28X%2CY%29%3D%5Cmax_%7Bs%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D%7D%5Cfrac%7BCC_%7Bs%7D%28X%2CY%29%7D%7B%5C%7Cx%5C%7C_%7B2%7D%5Ccdot%5C%7Cy%5C%7C%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

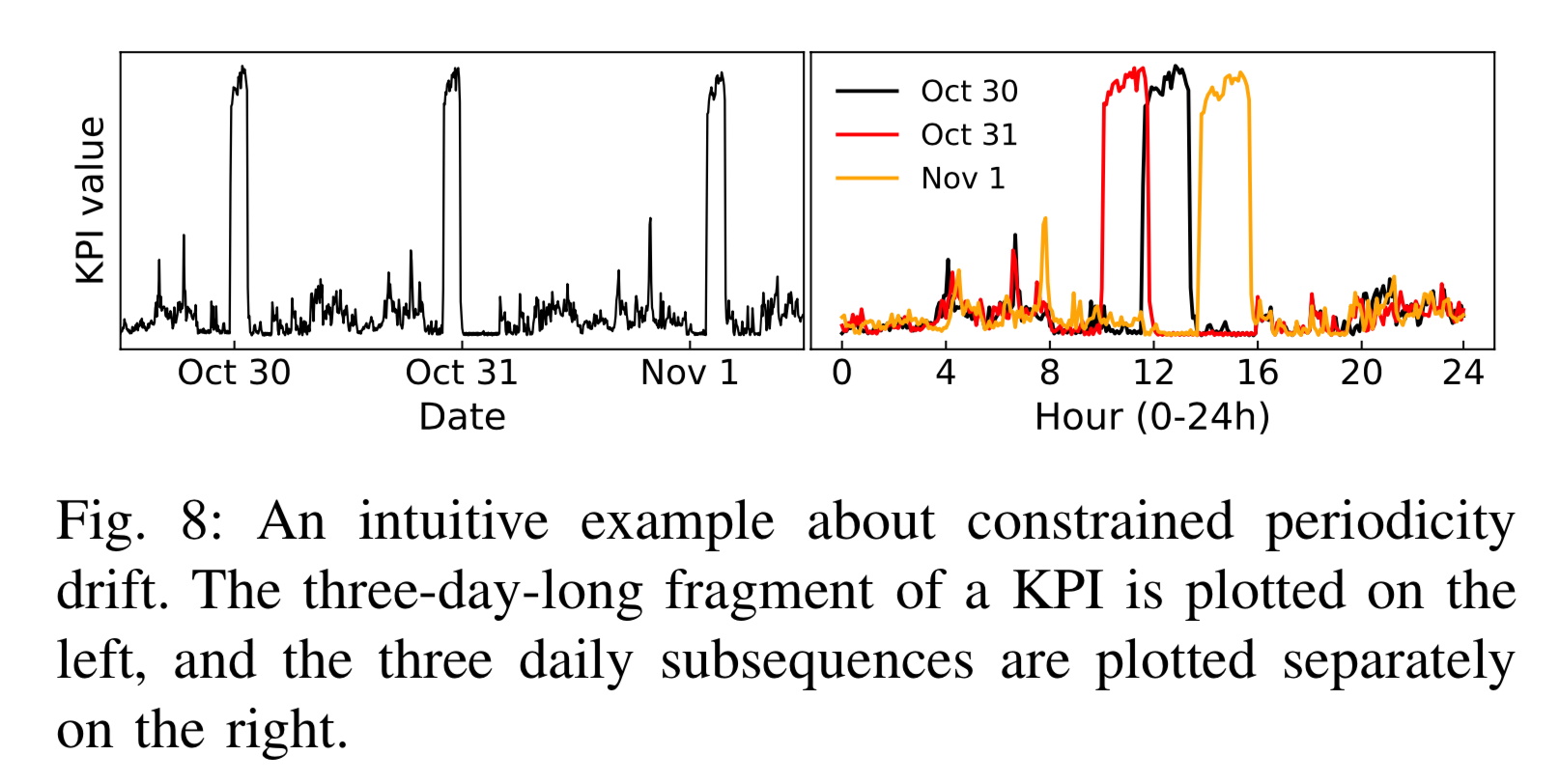
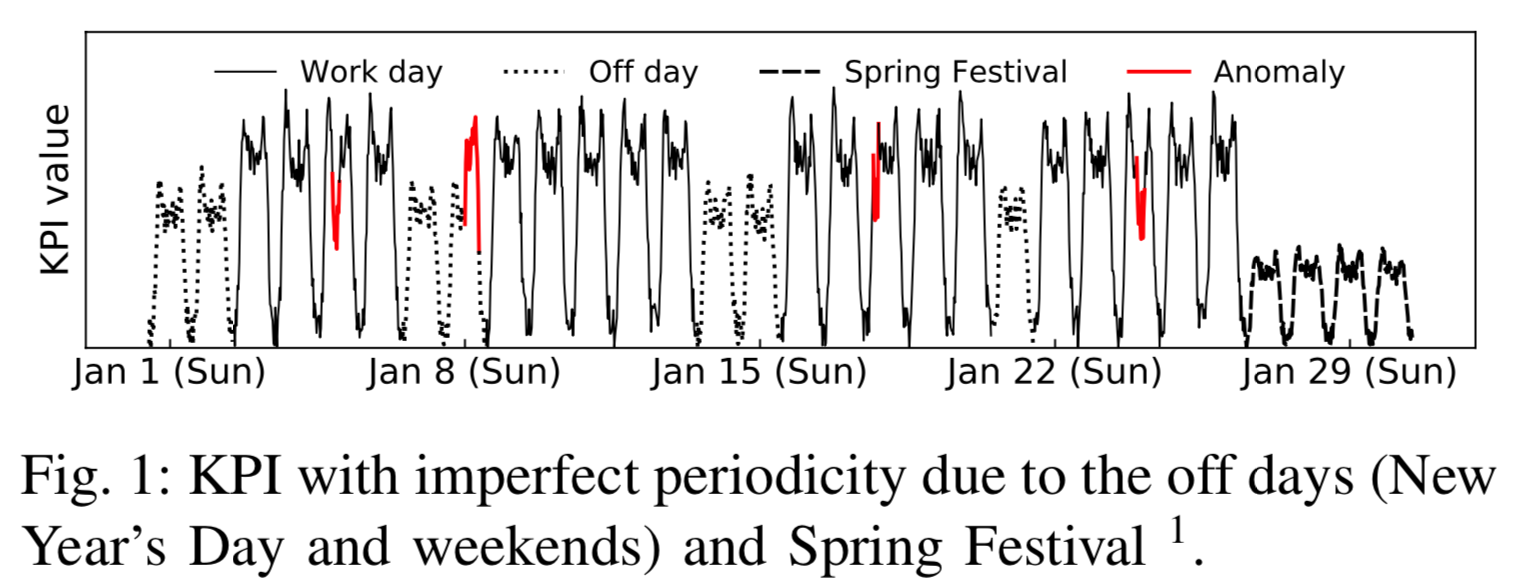
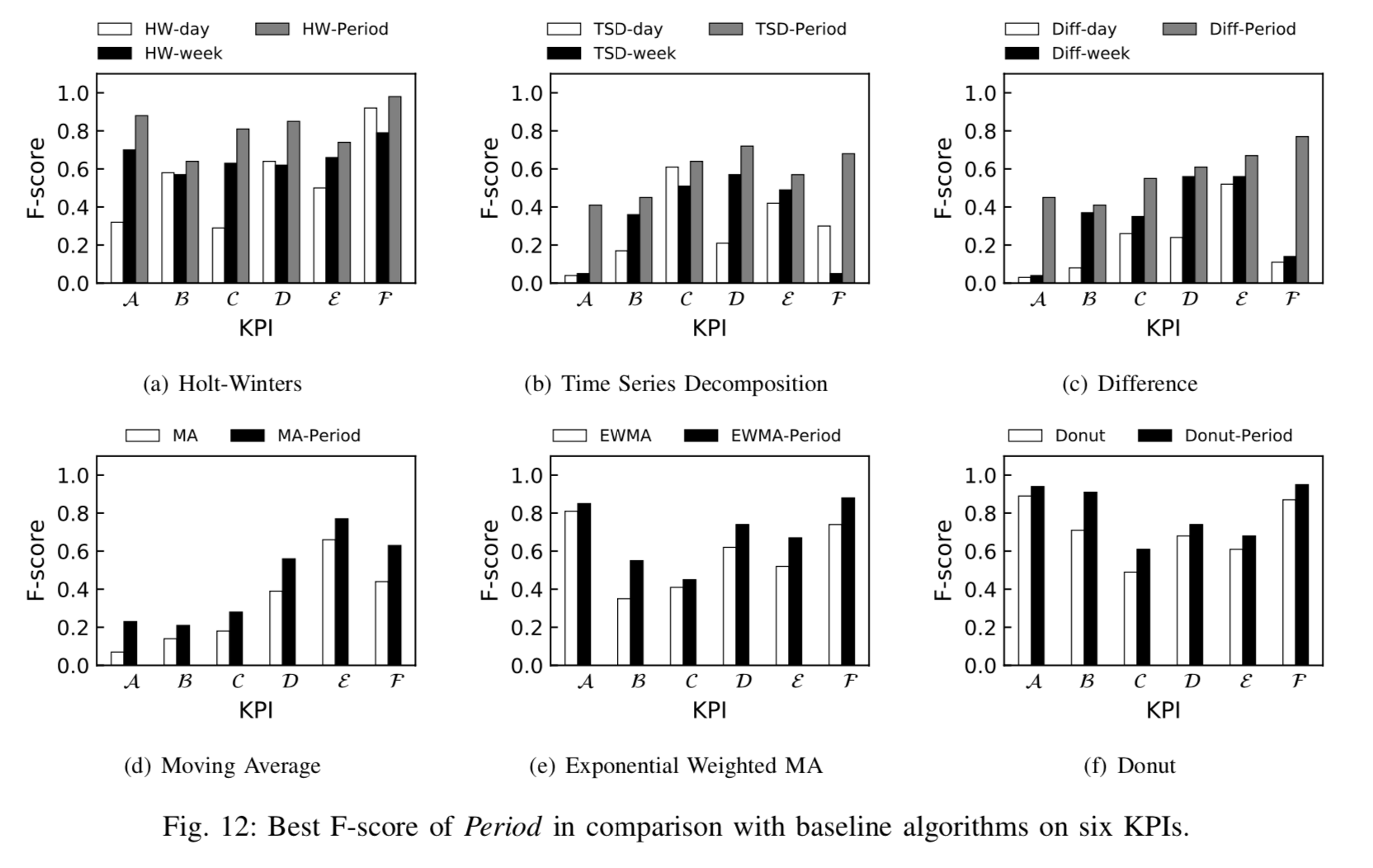
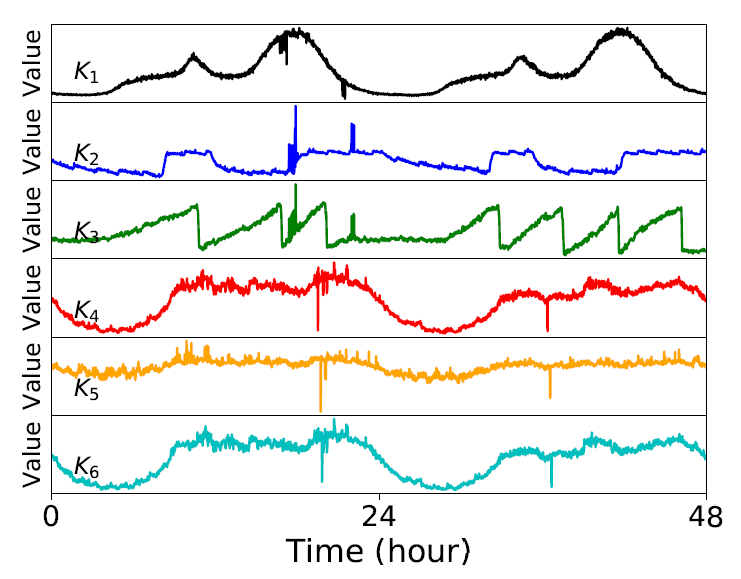
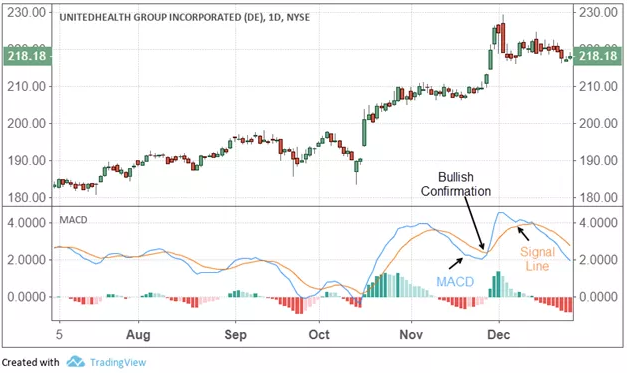
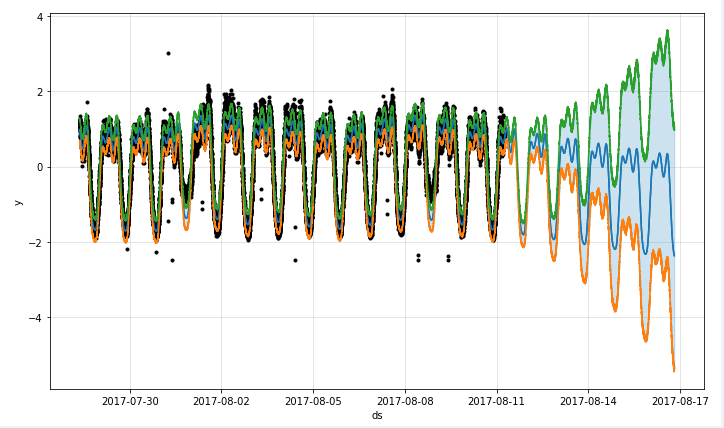
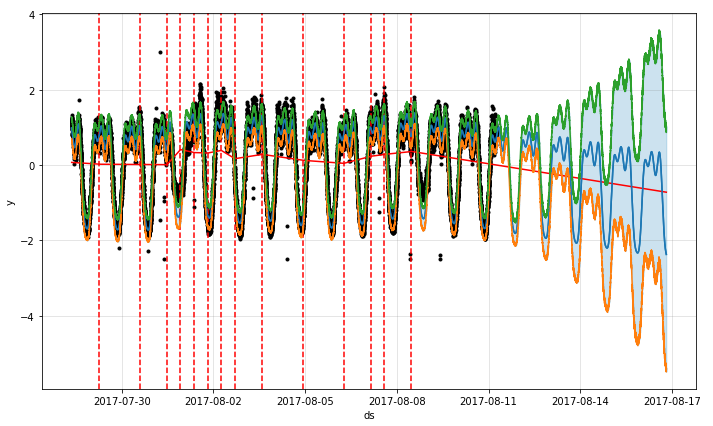
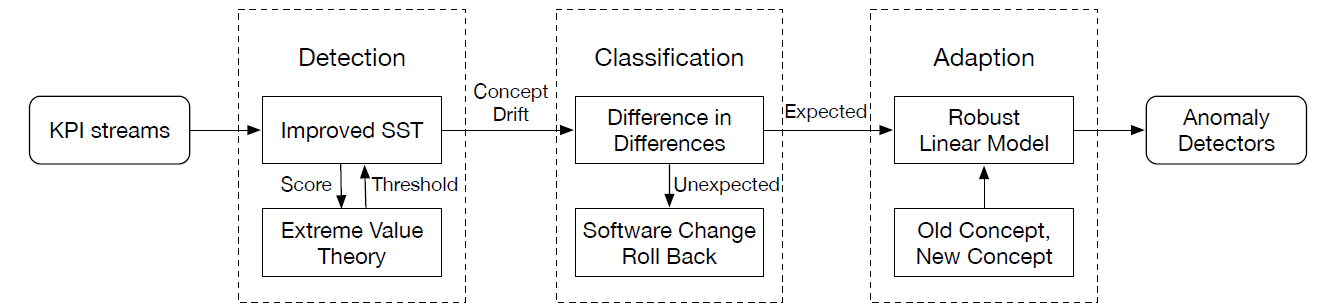
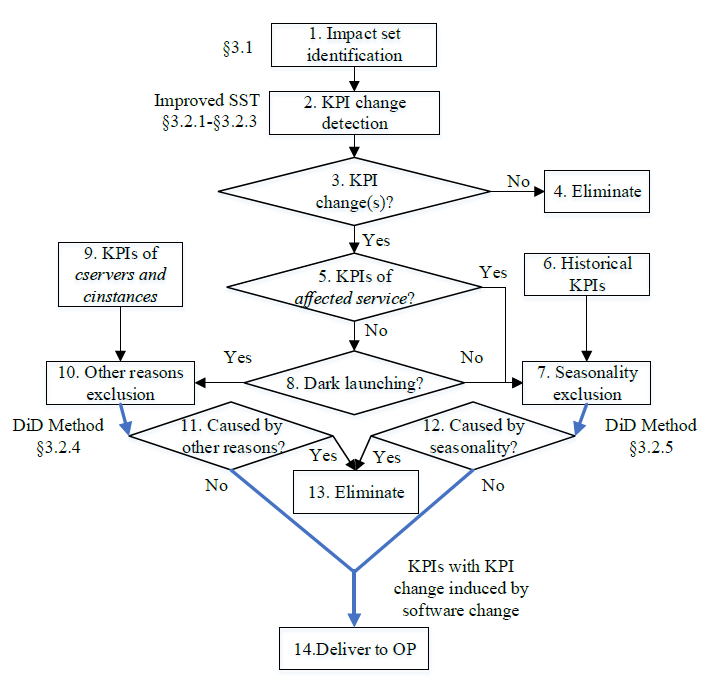
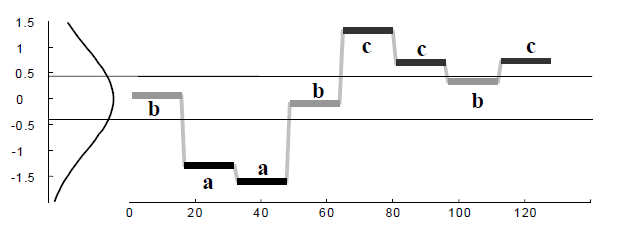
 呢,因为在一些实际的情况下,时间序列是会存在漂移的,例如上图所示。该时间序列在 10 月 30 日,31 日,11 月 1 日 都出现了一个凸起,但是如果考虑它的同比图,其实是可以清楚地看出该时间序列就存在了漂移,也就是说并不是在一个固定的时间戳就会出现同样的凸起,而是间隔了一段时间。这就是为什么需要考虑
呢,因为在一些实际的情况下,时间序列是会存在漂移的,例如上图所示。该时间序列在 10 月 30 日,31 日,11 月 1 日 都出现了一个凸起,但是如果考虑它的同比图,其实是可以清楚地看出该时间序列就存在了漂移,也就是说并不是在一个固定的时间戳就会出现同样的凸起,而是间隔了一段时间。这就是为什么需要考虑 
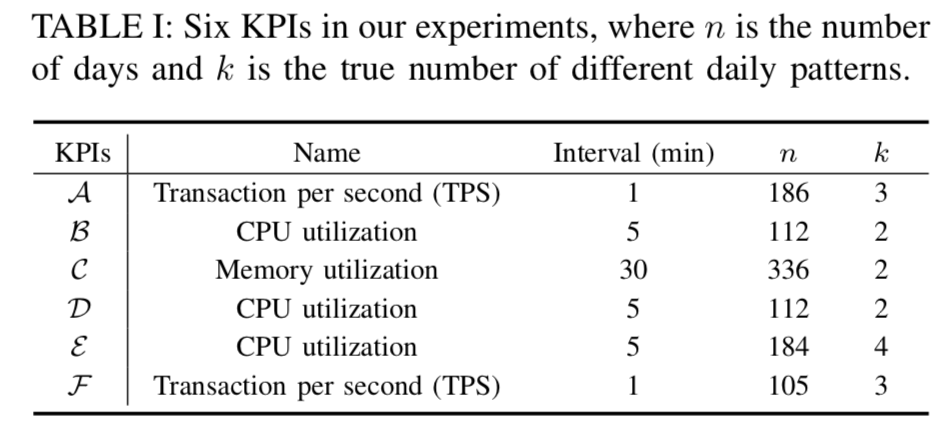
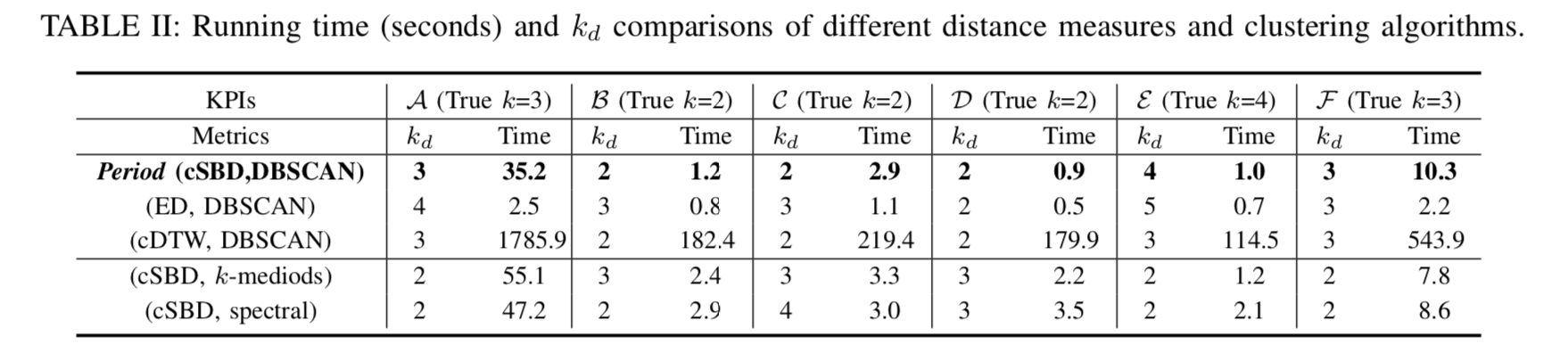
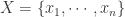
 的时间序列,高维时间序列
的时间序列,高维时间序列
 个不同的单维时间序列而组成的,对于每一个
个不同的单维时间序列而组成的,对于每一个  而言,时间序列
而言,时间序列  的长度都是
的长度都是 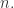 而时间序列的分类数据通常来说都是这种格式:数据集
而时间序列的分类数据通常来说都是这种格式:数据集
 是 one hot 编码,长度为
是 one hot 编码,长度为 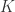 (表示有
(表示有 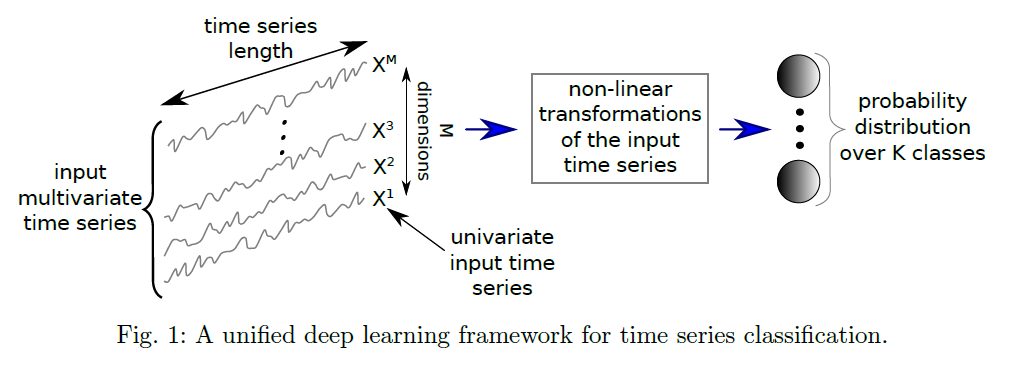
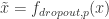 ,
, ,
, .
. ,
, ,
, ,
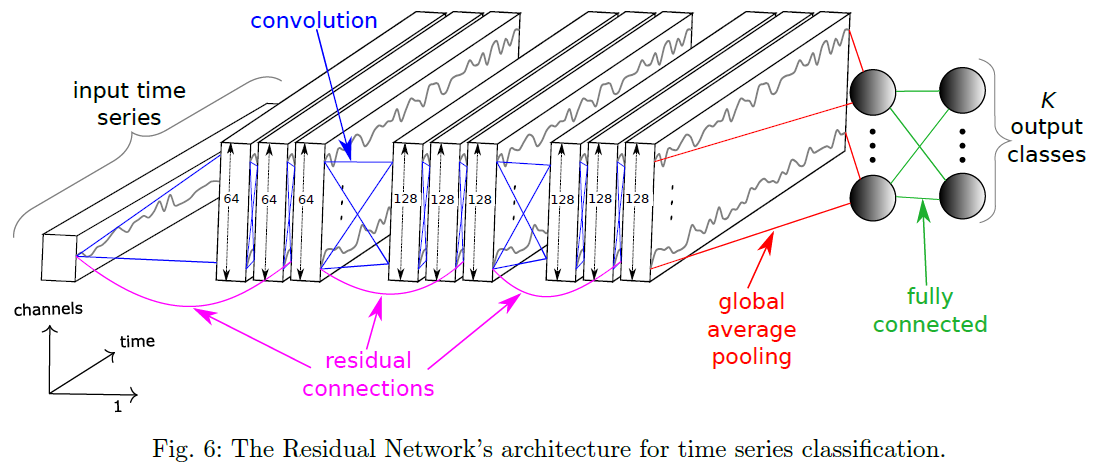
, 指的是卷积算子,BN 指的是 Batch Normalization,ReLU 则是激活函数。
指的是卷积算子,BN 指的是 Batch Normalization,ReLU 则是激活函数。 来表示第
来表示第  个卷积块,而 Residual 块就定义为:
个卷积块,而 Residual 块就定义为: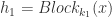 ,
,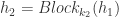 ,
, ,
,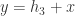 ,
, .
.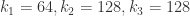 。
。
 是由
是由  ,通过模型其实可以计算出模型对每一个类的错误率
,通过模型其实可以计算出模型对每一个类的错误率 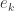 ,那么模型的 MPCE 就是:
,那么模型的 MPCE 就是: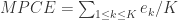 .
.
 ,其中
,其中  表示在时间戳
表示在时间戳  下的取值,并且时间序列
下的取值,并且时间序列  的长度是
的长度是  。其中
。其中 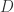 集合里面包含
集合里面包含 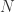 条时间序列,每条时间序列
条时间序列,每条时间序列 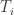 对应着一个标签
对应着一个标签 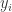 。
。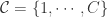 中的元素,
中的元素, 。
。
 ,
, 表示窗口长度。对于不同的窗口长度
表示窗口长度。对于不同的窗口长度 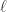 ,我们可以的到不同的时间序列平滑序列,但是它们的长度都是一样的,都是原始的时间序列长度
,我们可以的到不同的时间序列平滑序列,但是它们的长度都是一样的,都是原始的时间序列长度 ![T^{k} = \{t_{1+k\cdot i}\}, 0\leq i \leq [(n-1)/k]](https://s0.wp.com/latex.php?latex=T%5E%7Bk%7D+%3D+%5C%7Bt_%7B1%2Bk%5Ccdot+i%7D%5C%7D%2C+0%5Cleq+i+%5Cleq+%5B%28n-1%29%2Fk%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) .
.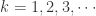 来进行下采样的时间序列提取。在进行了恒等变换,平滑变换,下采样之后,时间序列就可以变成多种形式,作为神经网络的输入。
来进行下采样的时间序列提取。在进行了恒等变换,平滑变换,下采样之后,时间序列就可以变成多种形式,作为神经网络的输入。 ,
, ,可以生成
,可以生成  个子序列如下所示:
个子序列如下所示: ,
,
 ,长度是
,长度是 ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 或者
或者 ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) :
: ,
, ,
,![\tilde{x}_{0}^{i}\in[0,1], \forall 1\leq i\leq n](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7B0%7D%5E%7Bi%7D%5Cin%5B0%2C1%5D%2C+%5Cforall+1%5Cleq+i%5Cleq+n&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,![\tilde{x}_{-1}^{i} \in [-1,1],\forall 1\leq i\leq n](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7B-1%7D%5E%7Bi%7D+%5Cin+%5B-1%2C1%5D%2C%5Cforall+1%5Cleq+i%5Cleq+n&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。于是可以使用三角函数来代替归一化之后的值。下面通用
。于是可以使用三角函数来代替归一化之后的值。下面通用  来表示归一化之后的时间序列,令
来表示归一化之后的时间序列,令 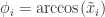 ,
,![\tilde{x}_{i} \in [-1,1]](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7Bi%7D+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,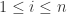 。因此,
。因此,![\phi_{i}\in[0,\pi]](https://s0.wp.com/latex.php?latex=%5Cphi_%7Bi%7D%5Cin%5B0%2C%5Cpi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,于是,
,于是,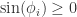 。
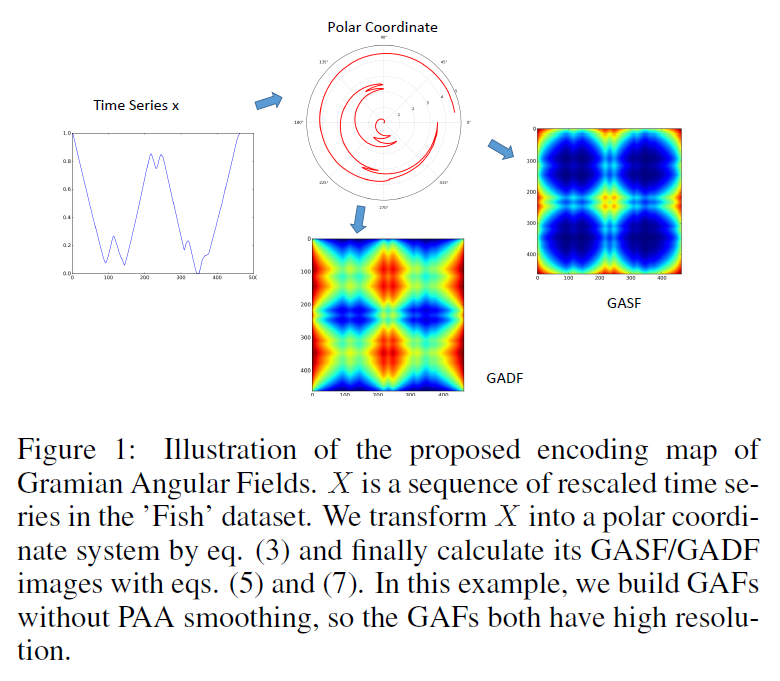
。![GASF = [\cos(\phi_{i}+\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=GASF+%3D+%5B%5Ccos%28%5Cphi_%7Bi%7D%2B%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![GASF = [\cos(\phi_{i})\cdot \cos(\phi_{j}) - \sin(\phi_{i})\cdot \sin(\phi_{j})]_{n\times n}](https://s0.wp.com/latex.php?latex=GASF+%3D+%5B%5Ccos%28%5Cphi_%7Bi%7D%29%5Ccdot+%5Ccos%28%5Cphi_%7Bj%7D%29+-+%5Csin%28%5Cphi_%7Bi%7D%29%5Ccdot+%5Csin%28%5Cphi_%7Bj%7D%29%5D_%7Bn%5Ctimes+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 ,可以得到
,可以得到
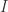 表示单位矩阵。它的对角矩阵是
表示单位矩阵。它的对角矩阵是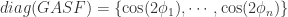

 ,可以得到
,可以得到  。
。![GADF = [\sin(\phi_{i}-\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=GADF+%3D+%5B%5Csin%28%5Cphi_%7Bi%7D-%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![= [\sin(\phi_{i})\cdot cos(\phi_{j}) - \cos(\phi_{i})\cdot\sin(\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=%3D+%5B%5Csin%28%5Cphi_%7Bi%7D%29%5Ccdot+cos%28%5Cphi_%7Bj%7D%29+-+%5Ccos%28%5Cphi_%7Bi%7D%29%5Ccdot%5Csin%28%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
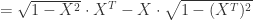 .
.
 ,我们把它们的值域分成
,我们把它们的值域分成 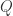 个桶,那么每一个
个桶,那么每一个  都可以被映射到一个相应的
都可以被映射到一个相应的  上。于是我们可以建立一个
上。于是我们可以建立一个  的矩阵
的矩阵  ,
, 表示在桶
表示在桶 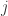 中的元素被在桶
中的元素被在桶  ,同时,它也满足
,同时,它也满足  。于是,得到矩阵
。于是,得到矩阵  。
。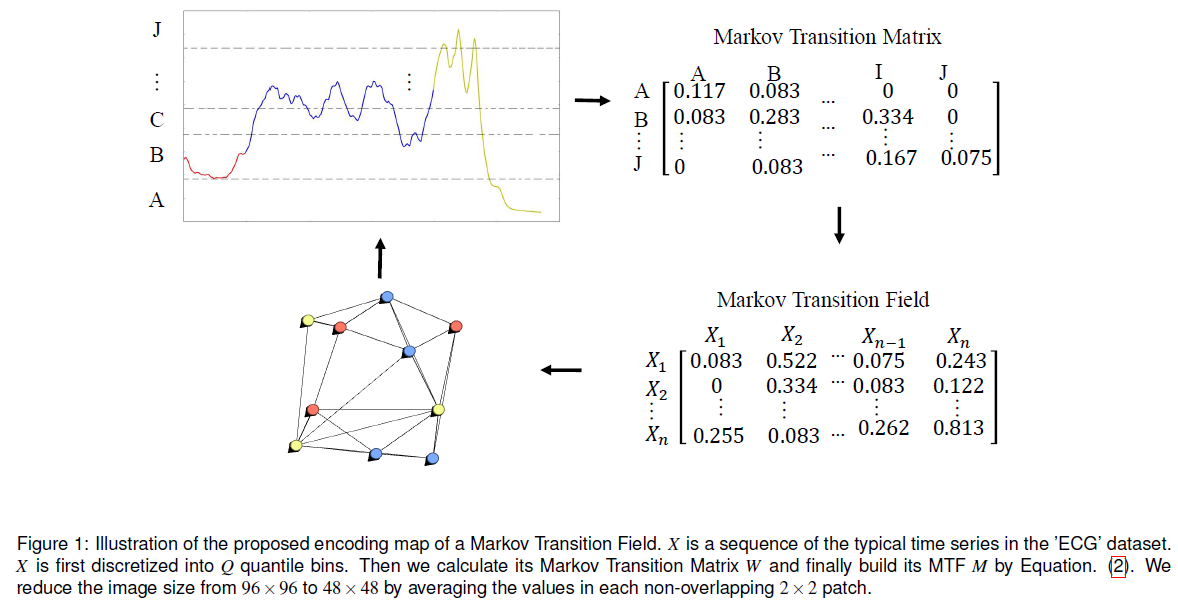
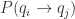 ,同样有
,同样有  。因此,我们同样可以构造出一个
。因此,我们同样可以构造出一个 

 就作为数据点
就作为数据点 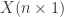 就可以变成特征矩阵
就可以变成特征矩阵  。对于特征矩阵
。对于特征矩阵 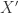 可以使用 isolation forest 来做无监督的异常检测并且做阈值的设定;如下图所示:
可以使用 isolation forest 来做无监督的异常检测并且做阈值的设定;如下图所示: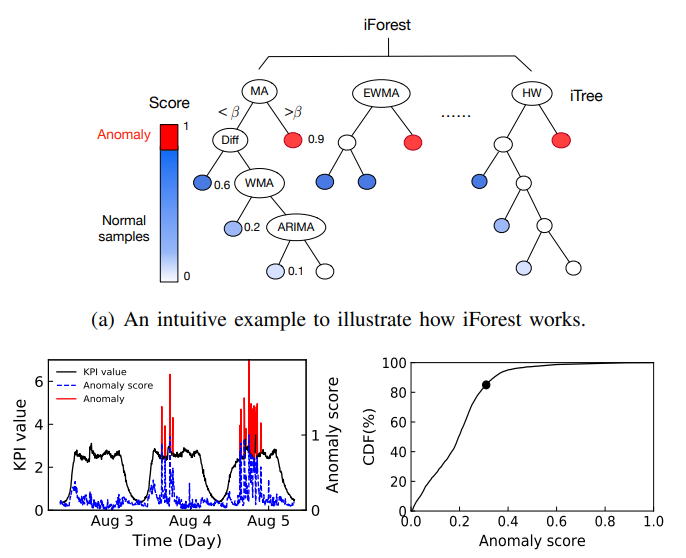
 和
和  ,因此在搜索的时候需要必要的加速工作。在这种地方,作者们使用了 LB-Kim,LB-Keogh,LB-Keogh-Reverse 算法来做搜索的加速工作。而这些的时间复杂度是
,因此在搜索的时候需要必要的加速工作。在这种地方,作者们使用了 LB-Kim,LB-Keogh,LB-Keogh-Reverse 算法来做搜索的加速工作。而这些的时间复杂度是  。整体的思路是,如果两条时间序列
。整体的思路是,如果两条时间序列 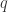 和
和  的 LB-Kim,LB-Keogh,LB-Keogh-Reverse 的下界大于某个阈值,则不计算它们之间的 DTW 距离。否则就开始计算 DTW。并且在计算 DTW 的时候,如果大于下界,则会提前终止(early stopping),不会继续计算下去。如果都没有大于阈值,则把这个候选曲线和 dist 距离放入列表,最后根据列表中的 dist 来做距离的逆序排列。
的 LB-Kim,LB-Keogh,LB-Keogh-Reverse 的下界大于某个阈值,则不计算它们之间的 DTW 距离。否则就开始计算 DTW。并且在计算 DTW 的时候,如果大于下界,则会提前终止(early stopping),不会继续计算下去。如果都没有大于阈值,则把这个候选曲线和 dist 距离放入列表,最后根据列表中的 dist 来做距离的逆序排列。
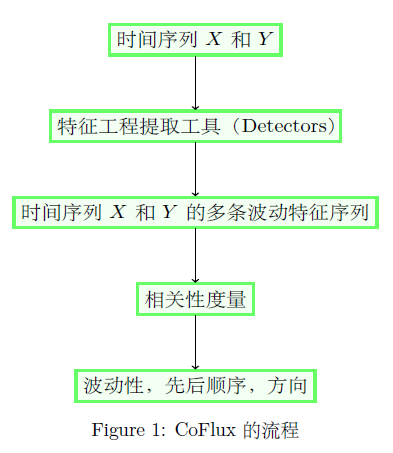
 和
和  存在波动相关性,则需要输出这两条时间序列的波动先后顺序和是否同向波动。如果两条时间序列
存在波动相关性,则需要输出这两条时间序列的波动先后顺序和是否同向波动。如果两条时间序列 
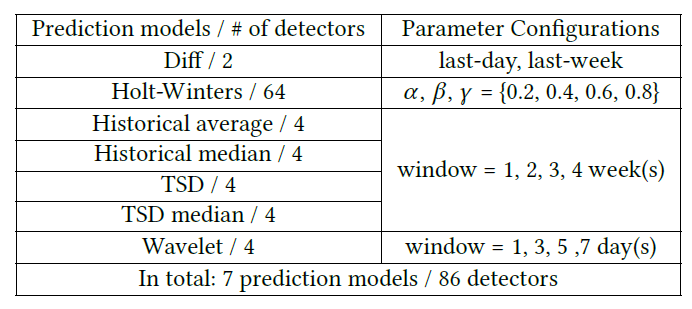
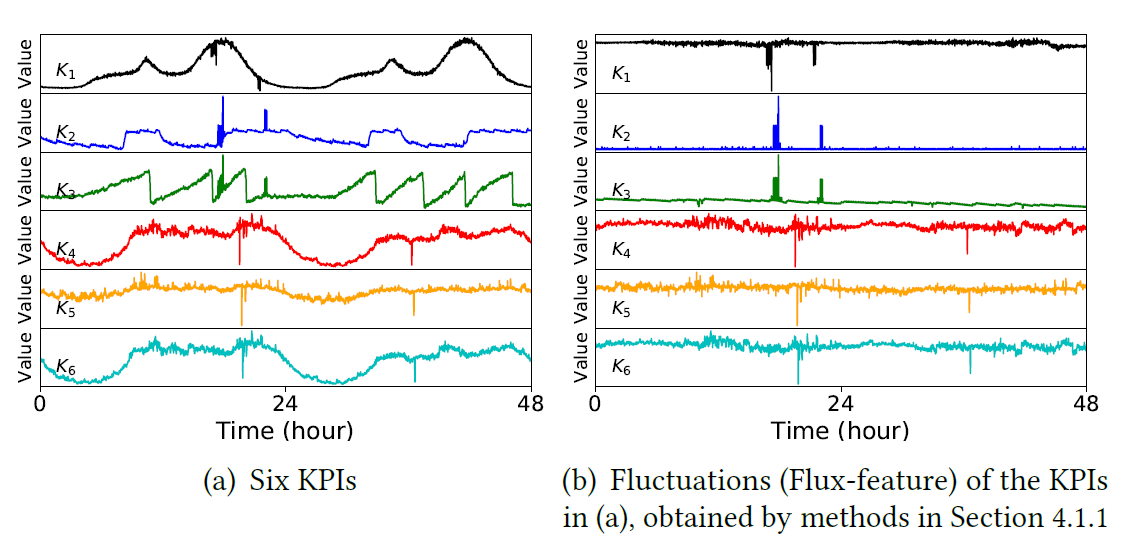
 ,对于任意一个 detector,可以得到一条关于
,对于任意一个 detector,可以得到一条关于 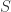 的预测值曲线
的预测值曲线  。于是针对某个 detector 可以得到一个波动特征序列
。于是针对某个 detector 可以得到一个波动特征序列 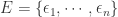 ,其中
,其中  ,
, ;
;


 如下:
如下: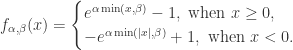

 和
和  ,可以计算它们之间的相关性,先后顺序,是否同向。
,可以计算它们之间的相关性,先后顺序,是否同向。
 个。其中,
个。其中,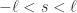 。特别地,当
。特别地,当 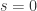 时,
时, ,那么我们可以定义
,那么我们可以定义  与
与 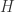 的内积是:
的内积是: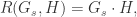
 指的是向量之间的内积(inner product)。同时可以定义相关性(Cross Correlation)为:
指的是向量之间的内积(inner product)。同时可以定义相关性(Cross Correlation)为: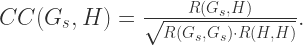



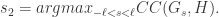

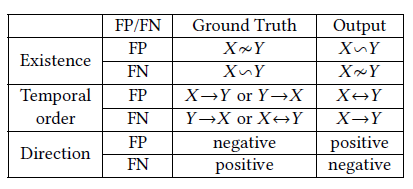
 是一个元组,里面蕴含着三个信息,分别是相关性,波动方向,前后顺序。
是一个元组,里面蕴含着三个信息,分别是相关性,波动方向,前后顺序。![FCC(G,H) \in [-1,1]](https://s0.wp.com/latex.php?latex=FCC%28G%2CH%29+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,越接近 1 或者 -1 就表示放大之后的波动特征曲线
,越接近 1 或者 -1 就表示放大之后的波动特征曲线  和
和 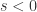 或者
或者  的分析就可以判断先后顺序。因此,CoFlux 方法的是通过对
的分析就可以判断先后顺序。因此,CoFlux 方法的是通过对 
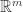 中的
中的 
 ,事先设定的类别个数是
,事先设定的类别个数是  是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合
是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合 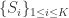 使得
使得  达到最小,其中
达到最小,其中  表示集合
表示集合  中的所有点的均值。
中的所有点的均值。 表示欧式空间的欧几里得距离,在这种情况下,除了使用
表示欧式空间的欧几里得距离,在这种情况下,除了使用 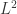 范数之外,还可以使用
范数之外,还可以使用  范数和其余的
范数和其余的 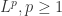 范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。
范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。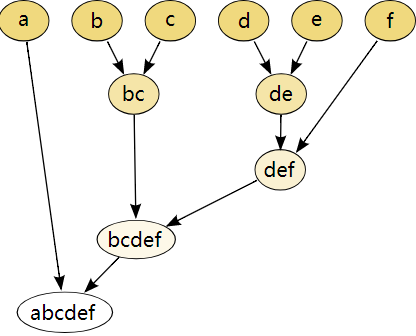
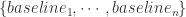 和
和  。i.e.
。i.e.  。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章:
。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章: 距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把
距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把  和
和  进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是
进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是  量级的,其中
量级的,其中 
 还是
还是 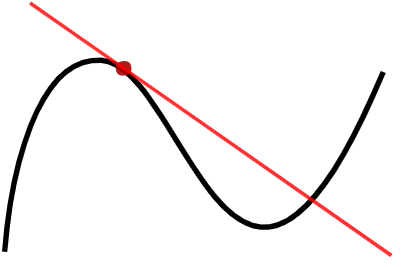
 是定义域
是定义域  上的可导函数,那么某个点
上的可导函数,那么某个点  的导数则定义为:
的导数则定义为:
 。如果
。如果  ,那么在
,那么在  的附近,
的附近, ,那么在
,那么在  ,则基于这个事实无法轻易的判断
,则基于这个事实无法轻易的判断  ,
,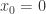 ;(2)
;(2)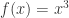 ,
,
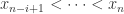 时,表示时间序列在
时,表示时间序列在 ![[n-i+1,n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2Cn%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调递增的;当
这个区间内是严格单调递增的;当  时,表示时间序列在
时,表示时间序列在 ![[n-i+1, n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2C+n%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。
这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。![X_{N} = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的一个子序列
的一个子序列 ![[x_{i},x_{i+1},\cdots,x_{j}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%2C%5Ccdots%2Cx_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,其中
,其中  。如果存在某个
。如果存在某个 ![k\in (i,j]](https://s0.wp.com/latex.php?latex=k%5Cin+%28i%2Cj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和一组非负实数
和一组非负实数 ![[w_{i}, w_{i+1},\cdots,w_{j}]](https://s0.wp.com/latex.php?latex=%5Bw_%7Bi%7D%2C+w_%7Bi%2B1%7D%2C%5Ccdots%2Cw_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 使得
使得 其中
其中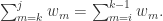
 其中
其中 ![X = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,可以考虑第
,可以考虑第  时,
时,

 ,当第一个公式大于零时,表示
,当第一个公式大于零时,表示 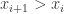 ,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示
,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示 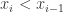 ,i.e. 处于单调下降的趋势中。
,i.e. 处于单调下降的趋势中。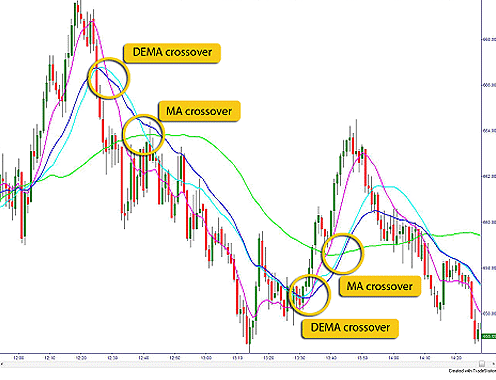
![X=[x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,如果考虑时间戳
,如果考虑时间戳 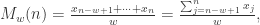
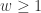 指的就是窗口的大小。
指的就是窗口的大小。 ,
,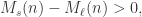 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。 。假设
。假设  ,那么通过数学推导可以得到:
,那么通过数学推导可以得到:

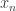 历史上的
历史上的 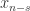 历史上的
历史上的  个点的平均值,该序列有上涨的趋势。反之,如果
个点的平均值,该序列有上涨的趋势。反之,如果  ,那么该序列有下跌的趋势。
,那么该序列有下跌的趋势。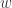 ,对于简单移动平均算法,那么
,对于简单移动平均算法,那么  每个元素的权重都是
每个元素的权重都是  ,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
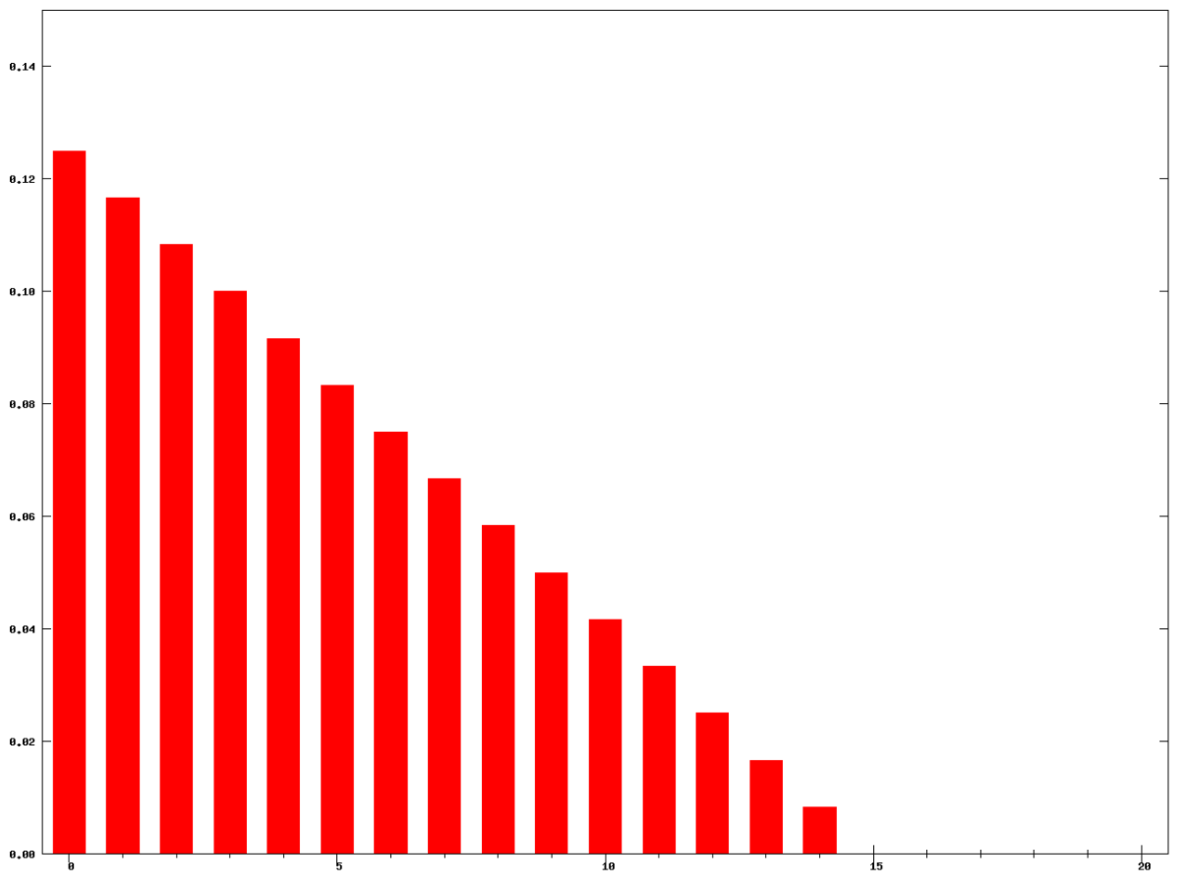
 ,那么
,那么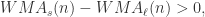 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。 。假设
。假设  ,那么
,那么




![j_{0}=[s\cdot(s+1)/(\ell + s-1)]](https://s0.wp.com/latex.php?latex=j_%7B0%7D%3D%5Bs%5Ccdot%28s%2B1%29%2F%28%5Cell+%2B+s-1%29%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,这里的
,这里的 ![[\cdot]](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示 Gauss 取整函数。因为
表示 Gauss 取整函数。因为
 ,于是距离当前点
,于是距离当前点 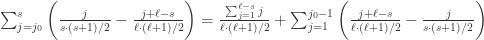

 时,表示时间序列有上涨的趋势;当
时,表示时间序列有上涨的趋势;当  时,表示时间序列有下跌的趋势。
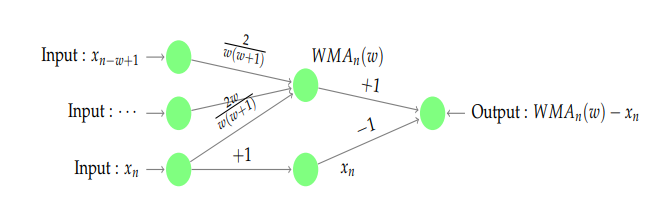
时,表示时间序列有下跌的趋势。 ,那么它的指数移动平均算法就是:
,那么它的指数移动平均算法就是: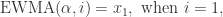

 。
。

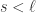 ,那么短线和长线则分别是:
,那么短线和长线则分别是:
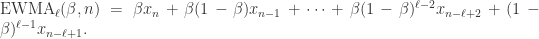
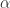 是与
是与 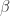 是与
是与  时,
时,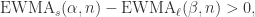 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。注:当
表示短线下穿长线,曲线有下跌的趋势。注:当  时,
时,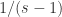 可以看做
可以看做  .
. 。那么
。那么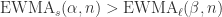


 时,表示时间序列有下跌的趋势。
时,表示时间序列有下跌的趋势。 时,根据假设有
时,根据假设有  ,并且
,并且


 ,通过计算可以得到
,通过计算可以得到  ,也就是说
,也就是说  在
在 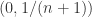 上是递增函数,在
上是递增函数,在  是递减函数。于是当
是递减函数。于是当 


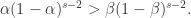
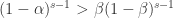 ,那么
,那么  可以写成
可以写成

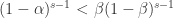 ,那么
,那么 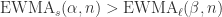 可以写成
可以写成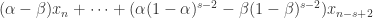

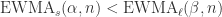 时,也可以使用同样的方法证明时间序列有下跌的趋势。
时,也可以使用同样的方法证明时间序列有下跌的趋势。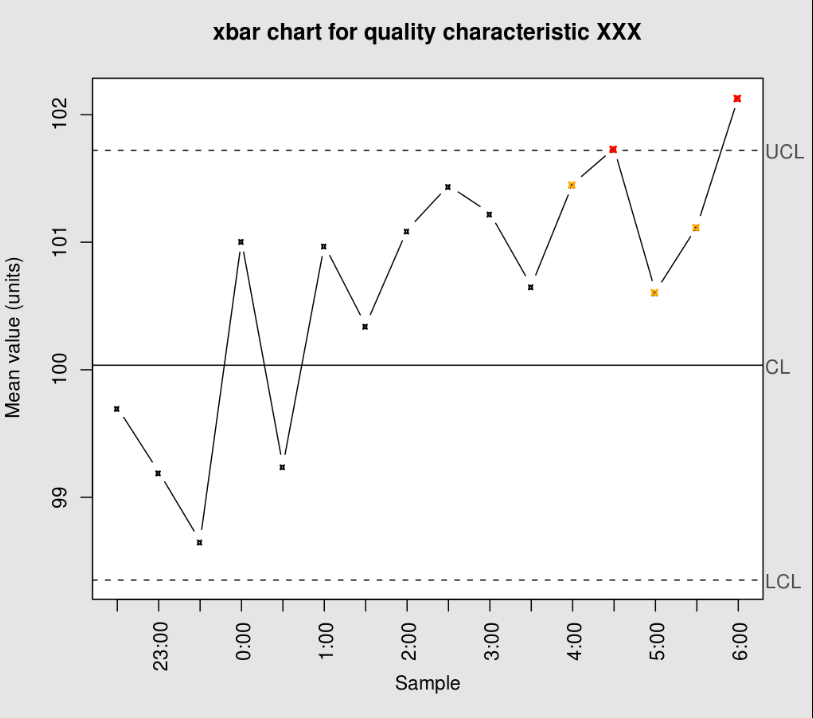
 控制图
控制图![X_{N} = [x_{1},\cdots, x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,为了计算某个时间戳
,为了计算某个时间戳 ![[x_{1},x_{2},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 中的所有点,可以计算出均值和方差如下:
中的所有点,可以计算出均值和方差如下:

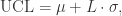


 表示系数,通常选择
表示系数,通常选择  。
。 ,那么说明
,那么说明 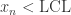 时,那么说明
时,那么说明 
 的方差是
的方差是
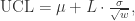

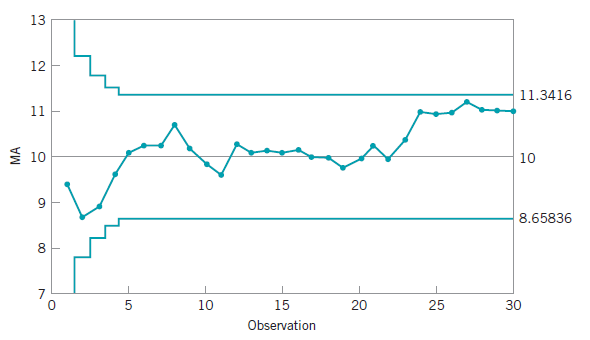

 的方差是:
的方差是:


 。
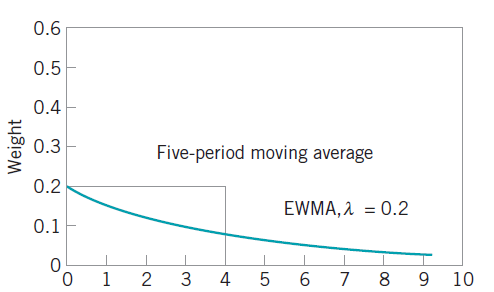
。
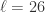 ,
, 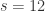 ,
,  ,基于时间序列
,基于时间序列  ,有
,有


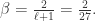

 ,计算 DEA 如下:
,计算 DEA 如下:
 ,
,




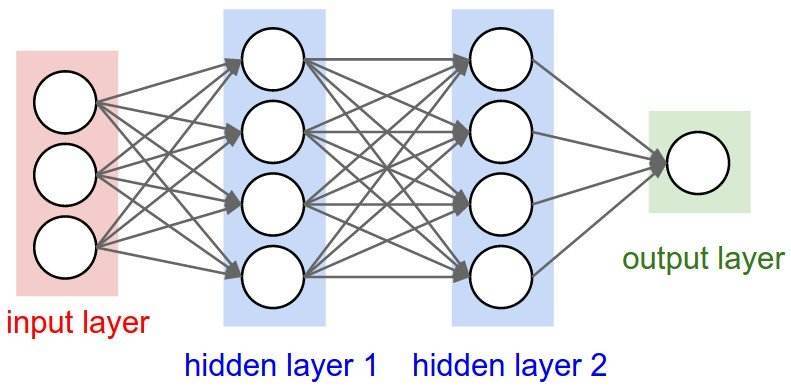
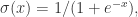
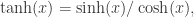
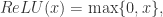




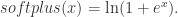
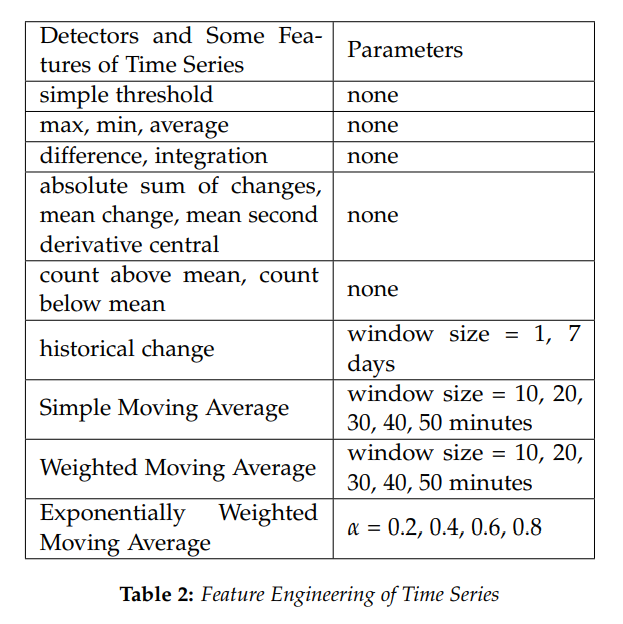
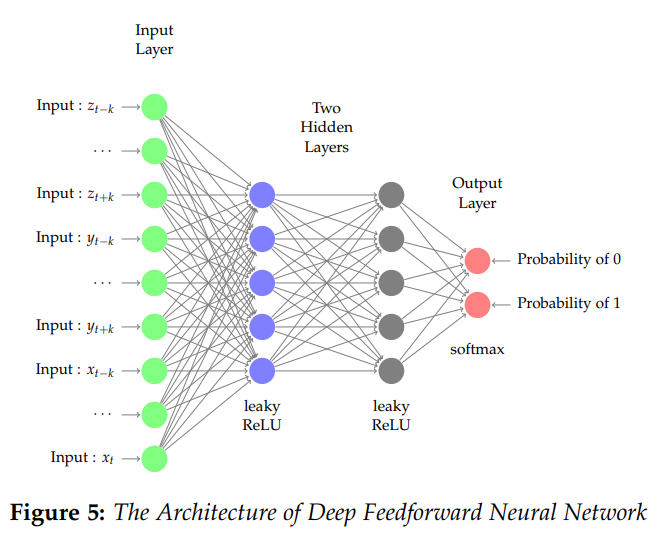
 ,存在一个前馈神经网络
,存在一个前馈神经网络 ![\boldsymbol{X}_{n}=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7BX%7D_%7Bn%7D%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,该神经网络的输入和输出分别是
,该神经网络的输入和输出分别是  和表格 2 中
和表格 2 中 ![X_{n} = [x_{1},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的以上统计特征之前,我们可以先使用神经网络构造出这几种运算方法。
的以上统计特征之前,我们可以先使用神经网络构造出这几种运算方法。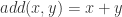 与减法
与减法 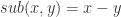 的构造十分简单,如下图构造即可:
的构造十分简单,如下图构造即可:

 通过计算可以得到
通过计算可以得到  所以,可以构造如下的神经网络来表示绝对值函数:
所以,可以构造如下的神经网络来表示绝对值函数: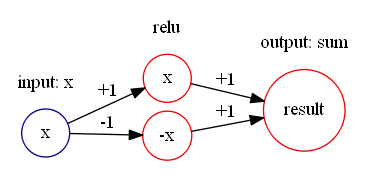
 通过计算可以得到
通过计算可以得到
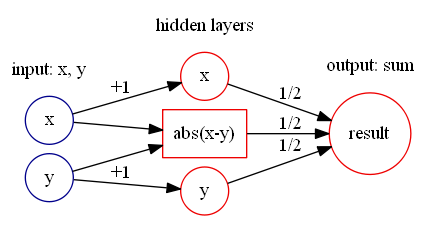
 通过计算可以得到
通过计算可以得到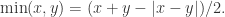


 指的是
指的是 
 这个函数可以使用 Softplus 激活函数来表达。令 Softplus 为
这个函数可以使用 Softplus 激活函数来表达。令 Softplus 为



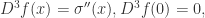



 就可以用神经网络来近似表示:
就可以用神经网络来近似表示:
 这个函数可以使用 Sigmoid 激活函数来表达。因为 Sigmoid 函数的 Taylor Series 是
这个函数可以使用 Sigmoid 激活函数来表达。因为 Sigmoid 函数的 Taylor Series 是

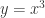 就可以用神经网络来近似表示:
就可以用神经网络来近似表示:
![X_{n} =[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的最大值,最小值等各种各样的统计指标。如果按照上文所描述的,以下特征都可以用神经网络轻松构造出来:
的最大值,最小值等各种各样的统计指标。如果按照上文所描述的,以下特征都可以用神经网络轻松构造出来:



![\sum_{i=1}^{n}[(x_{i}-\mu)/\sigma]^{3},](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%28x_%7Bi%7D-%5Cmu%29%2F%5Csigma%5D%5E%7B3%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![\sum_{i=1}^{n}[(x_{i}-\mu)/\sigma]^{4},](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%28x_%7Bi%7D-%5Cmu%29%2F%5Csigma%5D%5E%7B4%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


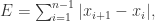


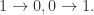
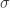 函数的图像,当
函数的图像,当  的时候,
的时候,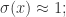 当
当  的时候,
的时候, 因此,可以使用函数
因此,可以使用函数  来估计 NOT 逻辑门。
来估计 NOT 逻辑门。 时,
时,
 时,
时,
 是否大于常数
是否大于常数 
 可以得到
可以得到 时,
时,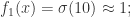
 时,
时,
 近似于判断待测试值
近似于判断待测试值 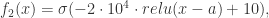 可以得到
可以得到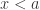 时,
时,
 时,
时,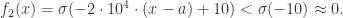
 近似于判断待测试值
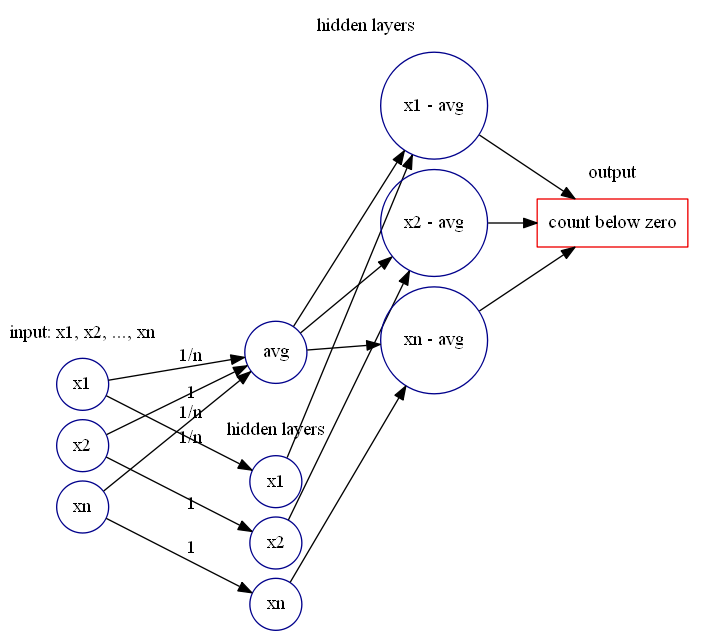
近似于判断待测试值 ![X_{n}=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 每个点与均值的差值,然后使用前面的神经网络模块计算出大于零的差值个数与小于零的差值个数即可。
每个点与均值的差值,然后使用前面的神经网络模块计算出大于零的差值个数与小于零的差值个数即可。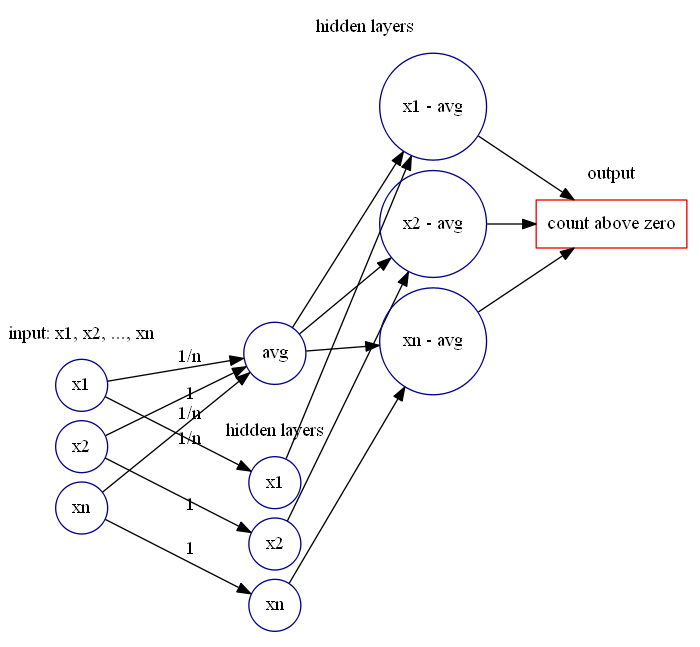
![X_{n} = [x_{1},\cdots,x_{n}],](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 我们可以使用一个窗口值
我们可以使用一个窗口值 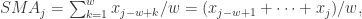
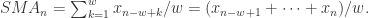
 就可以作为一个特征。然后根据不同的窗口长度
就可以作为一个特征。然后根据不同的窗口长度 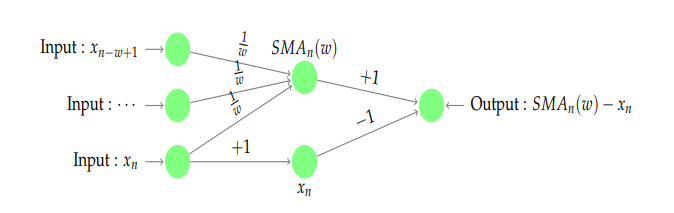
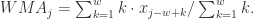




![= \alpha[x_{n-1}+(1-\alpha)x_{n-2}+\cdots+(1-\alpha)^{k}x_{n-(k+1)}] + (1-\alpha)^{k+1}EWMA_{n-(k+1)}](https://s0.wp.com/latex.php?latex=%3D+%5Calpha%5Bx_%7Bn-1%7D%2B%281-%5Calpha%29x_%7Bn-2%7D%2B%5Ccdots%2B%281-%5Calpha%29%5E%7Bk%7Dx_%7Bn-%28k%2B1%29%7D%5D+%2B+%281-%5Calpha%29%5E%7Bk%2B1%7DEWMA_%7Bn-%28k%2B1%29%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![\approx \alpha[x_{n-1}+(1-\alpha)x_{n-2}+\cdots+(1-\alpha)^{k}x_{n-(k+1)}]](https://s0.wp.com/latex.php?latex=%5Capprox%C2%A0%5Calpha%5Bx_%7Bn-1%7D%2B%281-%5Calpha%29x_%7Bn-2%7D%2B%5Ccdots%2B%281-%5Calpha%29%5E%7Bk%7Dx_%7Bn-%28k%2B1%29%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 的取值就可以得到特征。所以,神经网络可以构建为如下形式:
的取值就可以得到特征。所以,神经网络可以构建为如下形式:
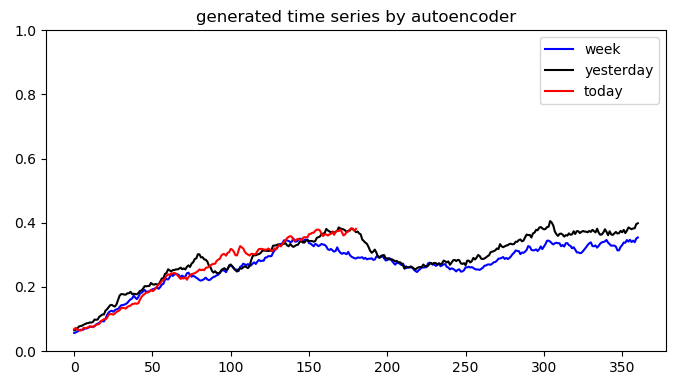
![X_{n} = [x_{week}, x_{yesterday}, x_{today}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7Bweek%7D%2C+x_%7Byesterday%7D%2C+x_%7Btoday%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 可以拆分成三个部分
可以拆分成三个部分 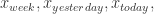 分别是一周前的数据,昨天的数据,今天的数据,假设它们的长度都是 [n/3],最后一点都表示不同天但是同一个时刻的取值。所以,同环比特征
分别是一周前的数据,昨天的数据,今天的数据,假设它们的长度都是 [n/3],最后一点都表示不同天但是同一个时刻的取值。所以,同环比特征![x_{today}[-1] - x_{yesterday}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D+-+x_%7Byesterday%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 与
与 ![x_{today}[-1] - x_{week}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D+-+x_%7Bweek%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 都是可以通过神经网络构造出来。
都是可以通过神经网络构造出来。 与
与 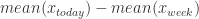 这一类特征也可以构造出来。
这一类特征也可以构造出来。 等函数,再计算两者的差值即可。例如,我们可以构造一个特征用于计算当前值是否高过昨天的峰值,以及超出的幅度是多少。用公式来表示那就是:
等函数,再计算两者的差值即可。例如,我们可以构造一个特征用于计算当前值是否高过昨天的峰值,以及超出的幅度是多少。用公式来表示那就是:![\max\{x_{today}[-1]-\max\{x_{yesterday}\}, 0\},](https://s0.wp.com/latex.php?latex=%5Cmax%5C%7Bx_%7Btoday%7D%5B-1%5D-%5Cmax%5C%7Bx_%7Byesterday%7D%5C%7D%2C+0%5C%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![x_{today}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 大于昨天的最大值,就返回它高出的幅度;否则就返回0。
大于昨天的最大值,就返回它高出的幅度;否则就返回0。![\min\{x_{today}[-1]-\min\{x_{week}\},0\},](https://s0.wp.com/latex.php?latex=%5Cmin%5C%7Bx_%7Btoday%7D%5B-1%5D-%5Cmin%5C%7Bx_%7Bweek%7D%5C%7D%2C0%5C%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 激活函数使用
激活函数使用  即可。
即可。![X_{n} = [x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的取值在
的取值在 ![[0,0.1), [0.1,0.2),\cdots,[0.9,1]](https://s0.wp.com/latex.php?latex=%5B0%2C0.1%29%2C+%5B0.1%2C0.2%29%2C%5Ccdots%2C%5B0.9%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这十个桶的个数,进一步得到它们落入这十个桶的概率是多少。这一类特征可以通过之前所构造的 count 函数来生成。因此,分类特征也是可以通过构造神经网络来形成的。
这十个桶的个数,进一步得到它们落入这十个桶的概率是多少。这一类特征可以通过之前所构造的 count 函数来生成。因此,分类特征也是可以通过构造神经网络来形成的。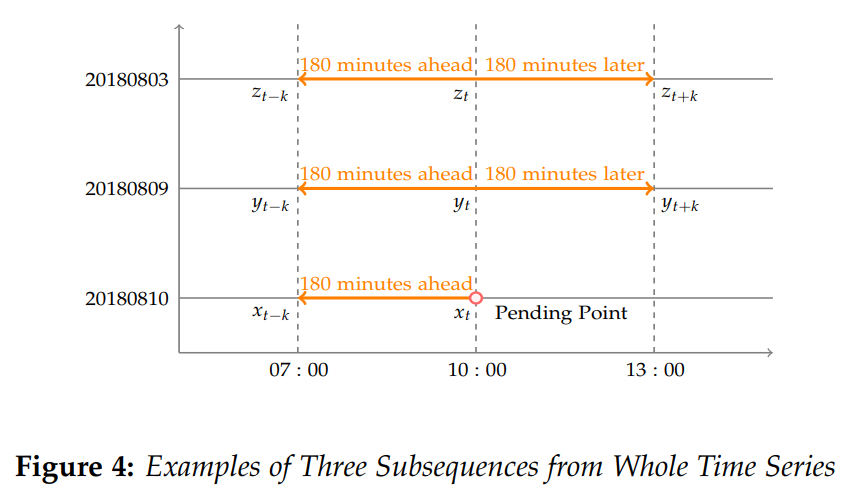
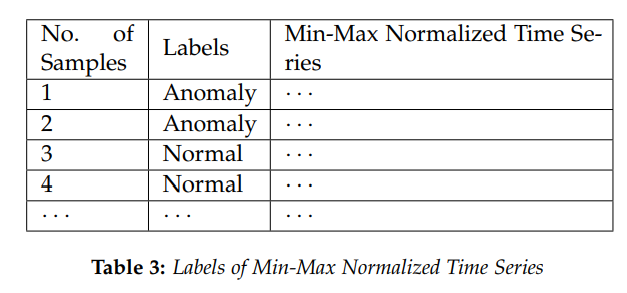
 分成几个部分,分别是季节项
分成几个部分,分别是季节项 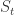 ,趋势项
,趋势项  ,剩余项
,剩余项  。也就是说对所有的
。也就是说对所有的  ,都有
,都有

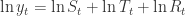 。所以,有的时候在预测模型的时候,会先取对数,然后再进行时间序列的分解,就能得到乘法的形式。在 fbprophet 算法中,作者们基于这种方法进行了必要的改进和优化。
。所以,有的时候在预测模型的时候,会先取对数,然后再进行时间序列的分解,就能得到乘法的形式。在 fbprophet 算法中,作者们基于这种方法进行了必要的改进和优化。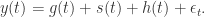
 表示趋势项,它表示时间序列在非周期上面的变化趋势;
表示趋势项,它表示时间序列在非周期上面的变化趋势;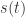 表示周期项,或者称为季节项,一般来说是以周或者年为单位;
表示周期项,或者称为季节项,一般来说是以周或者年为单位; 表示节假日项,表示在当天是否存在节假日;
表示节假日项,表示在当天是否存在节假日; 表示误差项或者称为剩余项。Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
表示误差项或者称为剩余项。Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。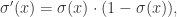 并且
并且 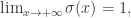
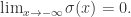 如果增加一些参数的话,那么逻辑回归就可以改写成:
如果增加一些参数的话,那么逻辑回归就可以改写成:
 称为曲线的最大渐近值,
称为曲线的最大渐近值, 时,恰好就是大家常见的 sigmoid 函数的形式。从 sigmoid 的函数表达式来看,它满足以下的微分方程:
时,恰好就是大家常见的 sigmoid 函数的形式。从 sigmoid 的函数表达式来看,它满足以下的微分方程: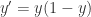 。
。 .
. 的三个参数
的三个参数 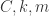 不可能都是常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,作者考虑把这三个参数全部换成了随着时间而变化的函数,也就是
不可能都是常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,作者考虑把这三个参数全部换成了随着时间而变化的函数,也就是  。
。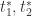 就是时间序列的两个变点。
就是时间序列的两个变点。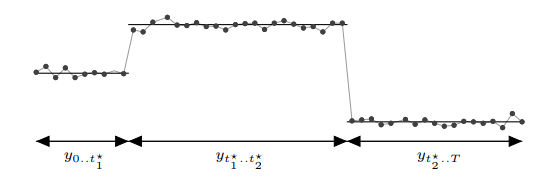
 上,那么在这些时间戳上,我们就需要给出增长率的变化,也就是在时间戳
上,那么在这些时间戳上,我们就需要给出增长率的变化,也就是在时间戳  上发生的 change in rate。可以假设有这样一个向量:
上发生的 change in rate。可以假设有这样一个向量: 其中
其中  表示在时间戳
表示在时间戳  上的增长率就是
上的增长率就是  ,通过一个指示函数
,通过一个指示函数  就是
就是
 一旦变化量
一旦变化量 
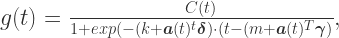
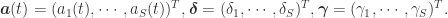
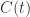 ,在使用 Prophet 的 growth = ‘logistic’ 的时候,需要提前设置好
,在使用 Prophet 的 growth = ‘logistic’ 的时候,需要提前设置好  而分段线性函数指的是在每一个子区间上,函数都是线性函数,但是在整段区间上,函数并不完全是线性的。正如下图所示,分段线性函数就是一个折线的形状。
而分段线性函数指的是在每一个子区间上,函数都是线性函数,但是在整段区间上,函数并不完全是线性的。正如下图所示,分段线性函数就是一个折线的形状。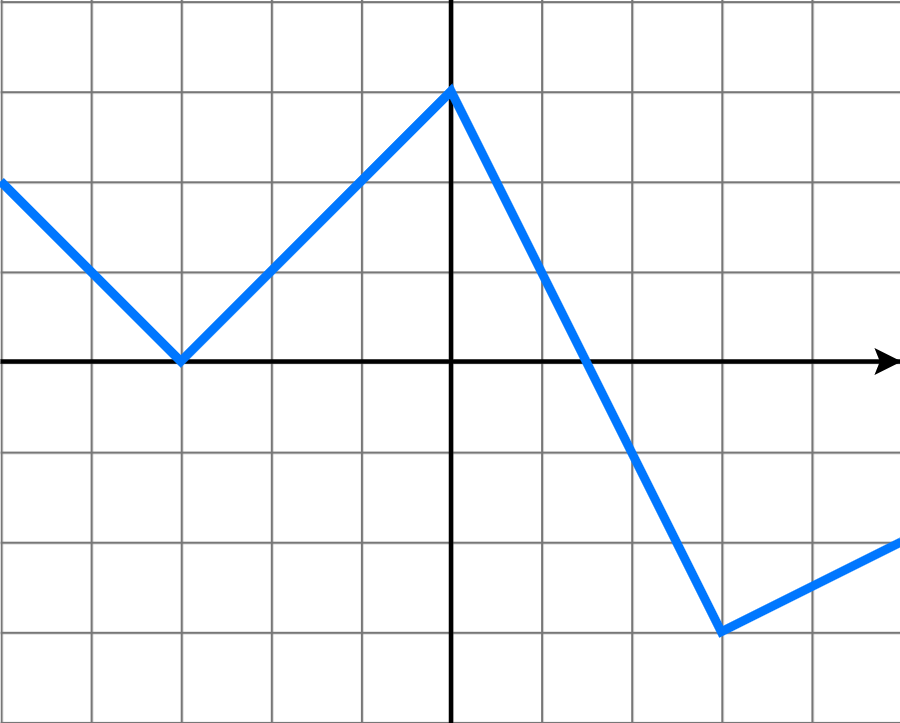

 表示增长率的变化量,
表示增长率的变化量, 的设置不一样,在分段线性函数中,
的设置不一样,在分段线性函数中,
 注意:这与之前逻辑回归函数中的设置是不一样的。
注意:这与之前逻辑回归函数中的设置是不一样的。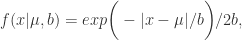
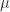 表示位置参数,
表示位置参数, 表示尺度参数。Laplace 分布与正态分布有一定的差异。
表示尺度参数。Laplace 分布与正态分布有一定的差异。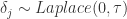 ,这里的
,这里的  就是 change_point_scale。
就是 change_point_scale。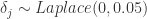 的。因此,当
的。因此,当  的数据中,我们可以选择出
的数据中,我们可以选择出 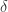 的情况。这里令
的情况。这里令  ,于是新的增长率的变化量就是按照下面的规则来选择的:当
,于是新的增长率的变化量就是按照下面的规则来选择的:当  时,
时,
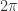 为周期的函数,那么它的傅立叶级数就是
为周期的函数,那么它的傅立叶级数就是 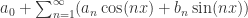 。
。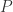 表示时间序列的周期,
表示时间序列的周期, 表示以年为周期,
表示以年为周期, 表示以周为周期。它的傅立叶级数的形式都是:
表示以周为周期。它的傅立叶级数的形式都是: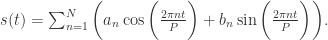
 ;对于以周为周期的序列(
;对于以周为周期的序列( 。这里的参数可以形成列向量:
。这里的参数可以形成列向量: 。
。![X(t) = \bigg[\cos(\frac{2\pi(1)t}{365.25}),\cdots,\sin(\frac{2\pi(10)t}{365.25})\bigg]](https://s0.wp.com/latex.php?latex=X%28t%29+%3D+%5Cbigg%5B%5Ccos%28%5Cfrac%7B2%5Cpi%281%29t%7D%7B365.25%7D%29%2C%5Ccdots%2C%5Csin%28%5Cfrac%7B2%5Cpi%2810%29t%7D%7B365.25%7D%29%5Cbigg%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![X(t) = \bigg[\cos(\frac{2\pi(1)t}{7}),\cdots,\sin(\frac{2\pi(3)t}{7})\bigg]](https://s0.wp.com/latex.php?latex=X%28t%29+%3D+%5Cbigg%5B%5Ccos%28%5Cfrac%7B2%5Cpi%281%29t%7D%7B7%7D%29%2C%5Ccdots%2C%5Csin%28%5Cfrac%7B2%5Cpi%283%29t%7D%7B7%7D%29%5Cbigg%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 而
而  的初始化是
的初始化是  。这里的
。这里的  seasonality_prior_scale。这个值越大,表示季节的效应越明显;这个值越小,表示季节的效应越不明显。同时,在代码里面,seasonality_mode 也对应着两种模式,分别是加法和乘法,默认是加法的形式。在开源代码中,
seasonality_prior_scale。这个值越大,表示季节的效应越明显;这个值越小,表示季节的效应越不明显。同时,在代码里面,seasonality_mode 也对应着两种模式,分别是加法和乘法,默认是加法的形式。在开源代码中, 函数是通过 fourier_series 来构建的。
函数是通过 fourier_series 来构建的。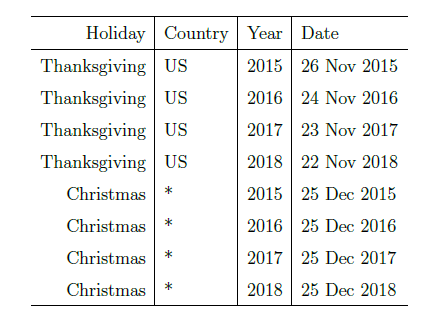
 表示该节假日的前后一段时间。为了表示节假日效应,我们需要一个相应的指示函数(indicator function),同时需要一个参数
表示该节假日的前后一段时间。为了表示节假日效应,我们需要一个相应的指示函数(indicator function),同时需要一个参数  来表示节假日的影响范围。假设我们有
来表示节假日的影响范围。假设我们有 
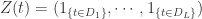 和
和 
 并且该正态分布是受到
并且该正态分布是受到  holidays_prior_scale 这个指标影响的。默认值是 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。用户可以根据自己的情况自行调整。
holidays_prior_scale 这个指标影响的。默认值是 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。用户可以根据自己的情况自行调整。
 changepoint_prior_scale 可以用来控制趋势的灵活度,
changepoint_prior_scale 可以用来控制趋势的灵活度, holidays prior scale 用来控制节假日的灵活度。
holidays prior scale 用来控制节假日的灵活度。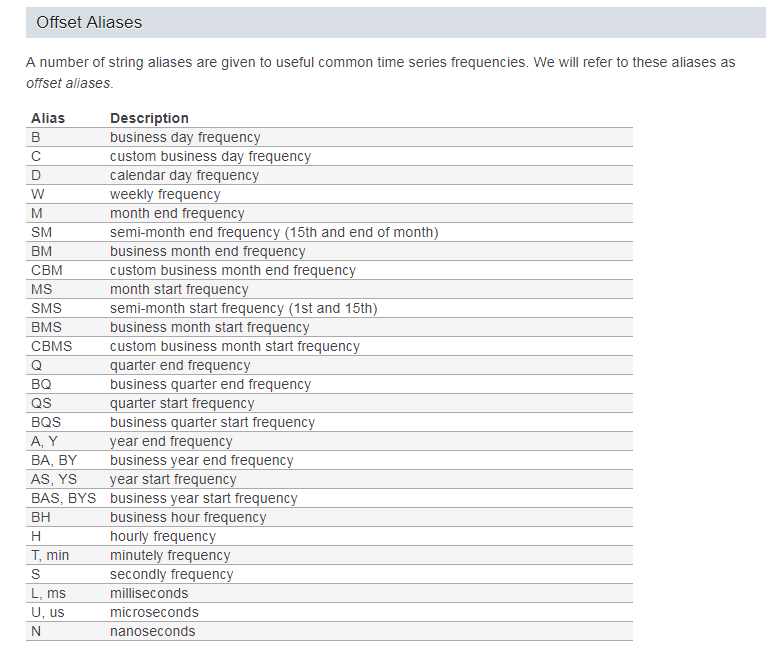


![[x_{1},x_{2}, \cdots, x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2Cx_%7B2%7D%2C+%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示原始的时间序列的话,标准化指的是
表示原始的时间序列的话,标准化指的是 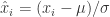 ,其中
,其中 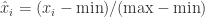 ,其中
,其中 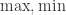 分别表示这段时间内的最大值与最小值。
分别表示这段时间内的最大值与最小值。![[x_{1},x_{2},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,基线提取就是:
,基线提取就是: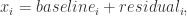
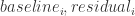 分别指的是
分别指的是 ![[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,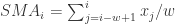 ,
, 。也就是说
。也就是说  。
。![X = [x_{1},\cdots,x_{m}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bm%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和
和 ![Y = [y_{1},\cdots,y_{m}]](https://s0.wp.com/latex.php?latex=Y+%3D+%5By_%7B1%7D%2C%5Ccdots%2Cy_%7Bm%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 而言,为了解决左右平移的问题,需要考虑一个偏移量
而言,为了解决左右平移的问题,需要考虑一个偏移量 


![NCC \in [-1,1]](https://s0.wp.com/latex.php?latex=NCC+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 指的是 Normalized version of Cross-Correlation,
指的是 Normalized version of Cross-Correlation,![SBD \in [0,2]](https://s0.wp.com/latex.php?latex=SBD+%5Cin+%5B0%2C2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 指的是 Shape-based distance。
指的是 Shape-based distance。
![X=[x_{1},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和
和 ![Y = [y_{1},\cdots, y_{n}]](https://s0.wp.com/latex.php?latex=Y+%3D+%5By_%7B1%7D%2C%5Ccdots%2C+y_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,那么以下陈述是等价的。
,那么以下陈述是等价的。 使得二维点集
使得二维点集  能够被很好的拟合好,也就是说此刻的方差较小。
能够被很好的拟合好,也就是说此刻的方差较小。![[y_{1},\cdots,y_{n}]](https://s0.wp.com/latex.php?latex=%5By_%7B1%7D%2C%5Ccdots%2Cy_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的 Pearson 系数很高;
的 Pearson 系数很高; 使得
使得 ![[x_{1}/\mu_{1},\cdots,x_{n}/\mu_{1}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2F%5Cmu_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%2F%5Cmu_%7B1%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 与
与 ![[y_{1}/\mu_{2},\cdots,y_{n}/\mu_{2}]](https://s0.wp.com/latex.php?latex=%5By_%7B1%7D%2F%5Cmu_%7B2%7D%2C%5Ccdots%2Cy_%7Bn%7D%2F%5Cmu_%7B2%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 几乎一致。
几乎一致。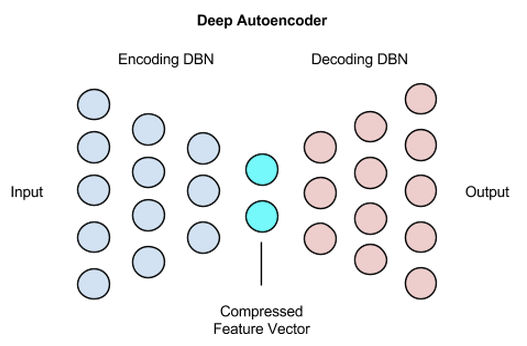
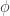 和
和 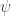 来表示,也就是说:
来表示,也就是说:
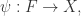


 ,并且编码器和解码器都是前馈神经网络,也就是说:
,并且编码器和解码器都是前馈神经网络,也就是说:

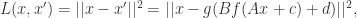 其中
其中 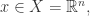

 和
和 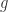 分别是编码层和解码层的激活函数,
分别是编码层和解码层的激活函数, 和
和  分别是编码层和解码层的矩阵和相应的向量。具体来说它们的矩阵大小分别是
分别是编码层和解码层的矩阵和相应的向量。具体来说它们的矩阵大小分别是 
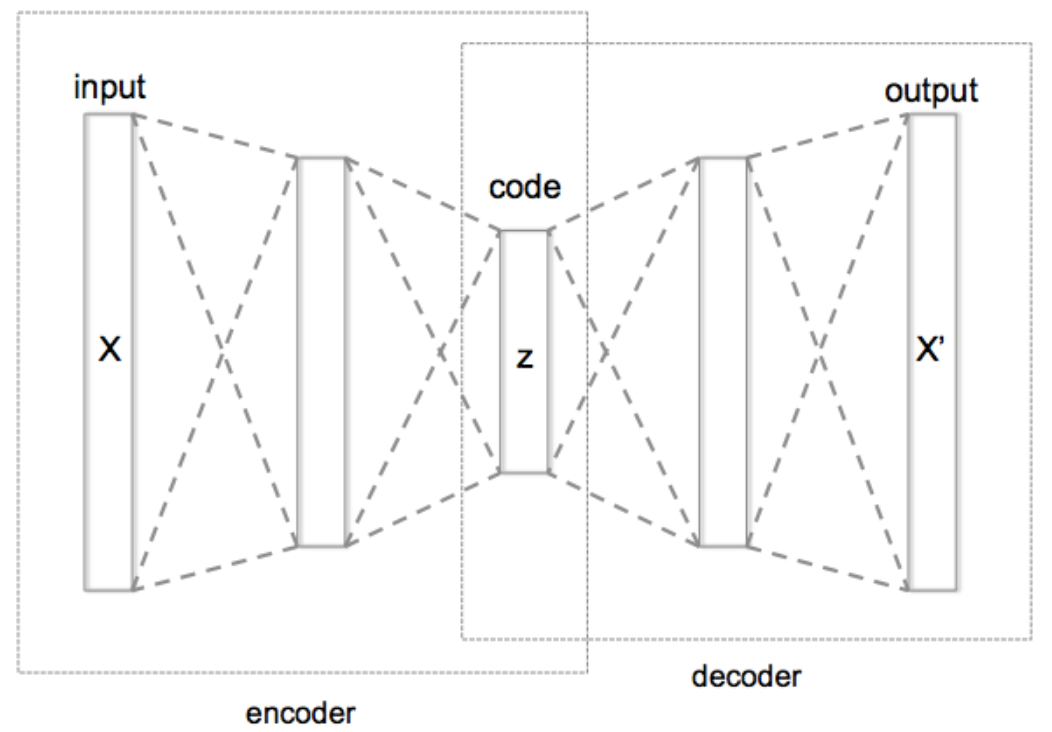
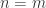 ,那么令
,那么令 

 就可以得到一个自编码器,而这个自编码器对于提取特征没有任何的意义。同理,当
就可以得到一个自编码器,而这个自编码器对于提取特征没有任何的意义。同理,当  时,
时,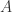 是一个
是一个  矩阵,
矩阵,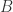 是一个
是一个  矩阵。从线性代数的角度来看,有无数个矩阵
矩阵。从线性代数的角度来看,有无数个矩阵  满足
满足  。这种情况下对于提取特征也是没有意义的。而当
。这种情况下对于提取特征也是没有意义的。而当 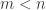 时,其实无法找到矩阵
时,其实无法找到矩阵 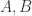 使得
使得  如果存在
如果存在  那么
那么









 ,
,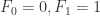 。按照其递归公式来计算,我们可以详细写出前面的几项,那就是:
。按照其递归公式来计算,我们可以详细写出前面的几项,那就是:
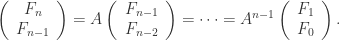
 的矩阵 A 能够对角化,那就是存在可逆矩阵 P 使得
的矩阵 A 能够对角化,那就是存在可逆矩阵 P 使得
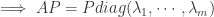

 表示一个
表示一个  。如果把矩阵 P 写成列向量的形式,i.e.
。如果把矩阵 P 写成列向量的形式,i.e.  ,那么以上的矩阵方程就可以转换为
,那么以上的矩阵方程就可以转换为 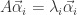 ,
, 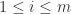 。进一步来说,如果要计算矩阵 A 的幂,就可以得到:
。进一步来说,如果要计算矩阵 A 的幂,就可以得到:
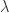 的多项式的解,
的多项式的解,
 ,
, 和
和  ,它们所对应的特征向量分别是:
,它们所对应的特征向量分别是: .
. .
. 具有弱平稳性(Weak Stationary)指的是:
具有弱平稳性(Weak Stationary)指的是: 对于所有的
对于所有的 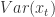 对于所有的
对于所有的  与
与  的协方差对于所有的
的协方差对于所有的  ,可以定义 ACF 为
,可以定义 ACF 为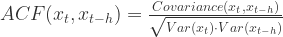 .
. .
.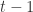 时刻的取值
时刻的取值  相关,其公式就是:
相关,其公式就是: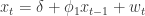 ,
,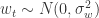 ,并且
,并且 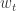 满足 iid 条件。其中
满足 iid 条件。其中  表示 Gauss 正态分布,它的均值是0,方差是
表示 Gauss 正态分布,它的均值是0,方差是  。
。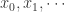 是弱平稳的,i.e. 必须满足
是弱平稳的,i.e. 必须满足 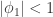 。
。 ,则可以得到一些 AR(1) 模型的例子如下图所示:
,则可以得到一些 AR(1) 模型的例子如下图所示: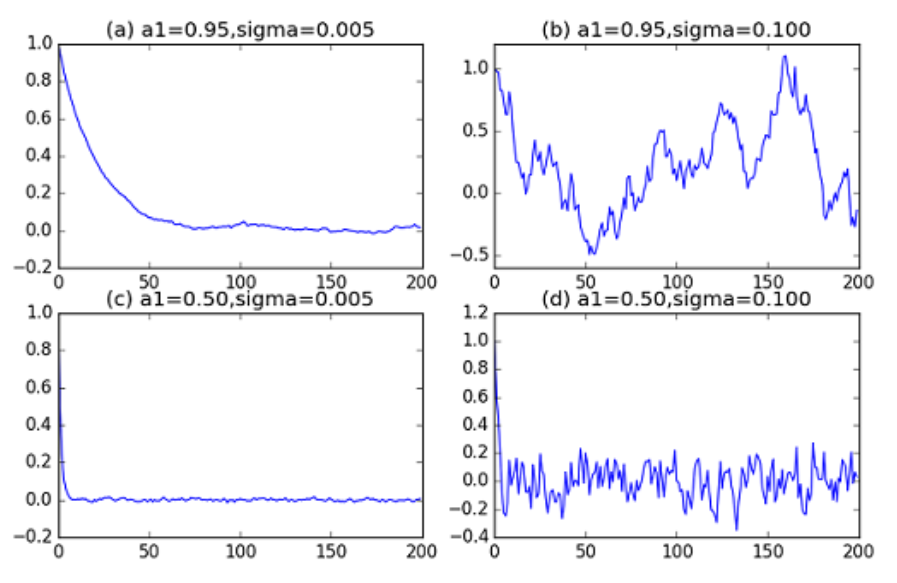
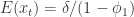 .
. .
. .
. ,
,
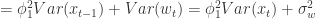 ,
,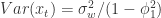 .
.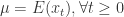 . 从
. 从 
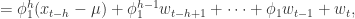
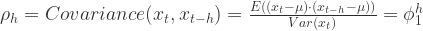 .
.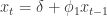 对于所有的
对于所有的  都成立。也就是可以写成一个一维函数的迭代公式:
都成立。也就是可以写成一个一维函数的迭代公式:
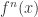 的收敛性,这里的
的收敛性,这里的  表示函数
表示函数 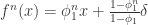 ,
,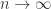 ,可以得到
,可以得到  。这与
。这与  ,可以从公式上得到
,可以从公式上得到  当
当 

 .
. ,我们可以得到
,我们可以得到 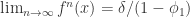 . i.e.
. i.e.  .
.
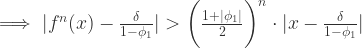 .
. as
as 


 并且忽略误差项,因此可以得到简化版的模型形如:
并且忽略误差项,因此可以得到简化版的模型形如: .
.
 ,求解可以得到
,求解可以得到  ,i.e.
,i.e. 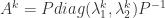 。当
。当  都在单位圆内部的时候,也就是该模型
都在单位圆内部的时候,也就是该模型 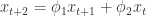 满足稳定性的条件。
满足稳定性的条件。


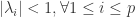 ,该 p 阶差分方程
,该 p 阶差分方程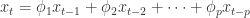
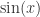 和余弦函数
和余弦函数 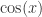 ,只是平移了
,只是平移了 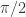 个长度而已。本文将会介绍一些基于形状的时间序列的距离算法,并且介绍如何在给定时间序列的情况下,在时间序列数据库中寻找相似的时间序列。
个长度而已。本文将会介绍一些基于形状的时间序列的距离算法,并且介绍如何在给定时间序列的情况下,在时间序列数据库中寻找相似的时间序列。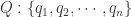 和
和  。首先我们可以建立一个
。首先我们可以建立一个  的矩阵,
的矩阵, 位置的元素是
位置的元素是  ,这里的 dist 可以使用
,这里的 dist 可以使用  范数。其次,我们想找到一条路径,使得这个矩阵的累积距离最小,而这条路则是两条时间序列之间的最佳匹配。在这里,我们可以假设这条路径是
范数。其次,我们想找到一条路径,使得这个矩阵的累积距离最小,而这条路则是两条时间序列之间的最佳匹配。在这里,我们可以假设这条路径是  ,其中
,其中  。
。
 .
. ,有
,有

 最终的取值
最终的取值  就是我们需要的解,也就是两条时间序列的 DTW 距离。按照上面的算法,DTW 算法的时间复杂度是
就是我们需要的解,也就是两条时间序列的 DTW 距离。按照上面的算法,DTW 算法的时间复杂度是  时,则
时,则  表示最后的距离;
表示最后的距离; 时,则
时,则  时,则
时,则  表示最后的距离。
表示最后的距离。 ,则
,则
![q[i]](https://s0.wp.com/latex.php?latex=q%5Bi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 与
与 ![c[j]](https://s0.wp.com/latex.php?latex=c%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的话,i 与 j 需要满足
的话,i 与 j 需要满足  ,这里的 w 表示窗口长度。因此算法的描述如下:
,这里的 w 表示窗口长度。因此算法的描述如下:
 。
。 。通过某种相似度或者距离计算方法,计算出给定的时间序列
。通过某种相似度或者距离计算方法,计算出给定的时间序列 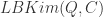

 .
. ,给定一个窗口的取值 r,得到
,给定一个窗口的取值 r,得到  ,
,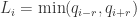 。
。

 ,有不等式
,有不等式  成立。
成立。 .
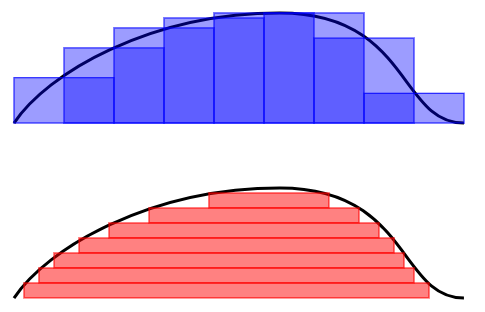
. 在 [0,1] 区间上与 X 坐标轴所夹的图形面积,就使用了 Riemann 积分的思想。 他把 [0,1] 区间等长地切割成 n 段,每一段使用一个长方形去逼近
在 [0,1] 区间上与 X 坐标轴所夹的图形面积,就使用了 Riemann 积分的思想。 他把 [0,1] 区间等长地切割成 n 段,每一段使用一个长方形去逼近 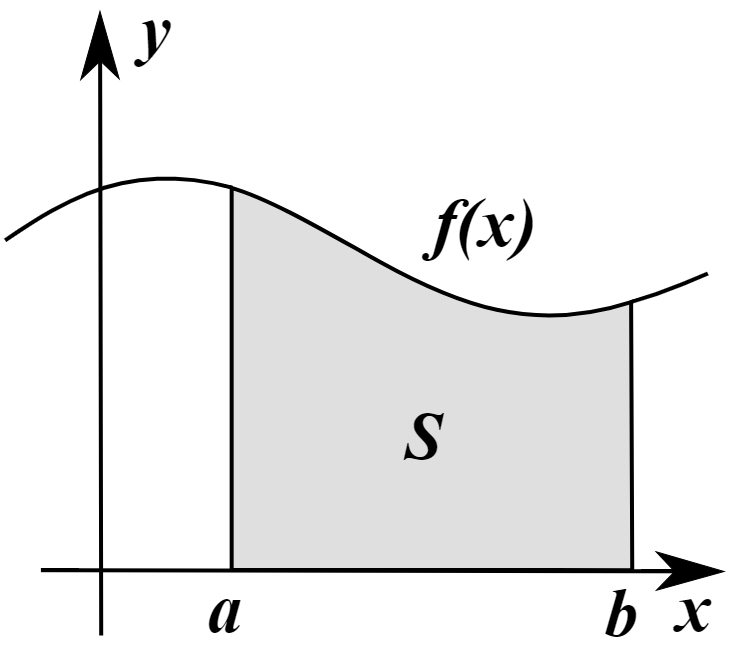
 ,
,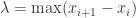 表示这些区间长度的最大值,在这里
表示这些区间长度的最大值,在这里  。在每一个子区间上
。在每一个子区间上![[x_{i},x_{i+1}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上取出一个点
上取出一个点 ![t_{i}\in[x_{i},x_{i+1}]](https://s0.wp.com/latex.php?latex=t_%7Bi%7D%5Cin%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。而函数
。而函数 
![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上的取值是
上的取值是  ,存在
,存在  使得对于任意取样分割,当
使得对于任意取样分割,当 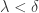 时,就有
时,就有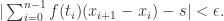
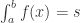 .
.


 ,这里的
,这里的  是系数,
是系数, 是可测集合,
是可测集合,
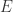 上的 Lebesgue 积分是:
上的 Lebesgue 积分是: ,
, 表示零函数,这里的大小关系表示对定义域内的每个点都要成立。
表示零函数,这里的大小关系表示对定义域内的每个点都要成立。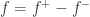 ,而这里的
,而这里的  和
和 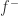 都是非负可测函数。所以可以定义任意可测函数的 Lebesgue 积分如下:
都是非负可测函数。所以可以定义任意可测函数的 Lebesgue 积分如下: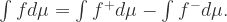 .
.![(R)\int_{a}^{b}f(x)dx = (L)\int_{[a,b]}f(x)dx](https://s0.wp.com/latex.php?latex=%28R%29%5Cint_%7Ba%7D%5E%7Bb%7Df%28x%29dx+%3D+%28L%29%5Cint_%7B%5Ba%2Cb%5D%7Df%28x%29dx&bg=ffffff&fg=2b2b2b&s=1&c=20201002) .
. ;
;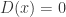 .
.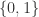 ,无法画出函数图像,它不是 Riemann 可积的,但是它 Lebesgue 可积。
,无法画出函数图像,它不是 Riemann 可积的,但是它 Lebesgue 可积。 这样的定义域而已。所以,之前所讨论的很多连续函数的想法都可以应用在时间序列上。
这样的定义域而已。所以,之前所讨论的很多连续函数的想法都可以应用在时间序列上。 用
用 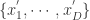 来表示,其中
来表示,其中 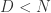 。那么后者就是原始序列的一种表示(representation)。
。那么后者就是原始序列的一种表示(representation)。 ,定义 PAA 的序列是:
,定义 PAA 的序列是: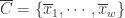 ,
, .
. 。用图像来表示那就是:
。用图像来表示那就是: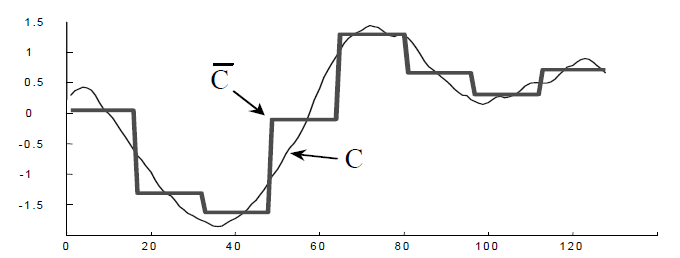
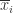 的定义上稍作修改即可。
的定义上稍作修改即可。 ,用
,用 来表示 Gauss 曲线下方的一些点,而这些点把 Gauss 曲线下方的面积等分成了
来表示 Gauss 曲线下方的一些点,而这些点把 Gauss 曲线下方的面积等分成了  表示
表示  。
。 ,那么
,那么  ;如果
;如果  ,那么
,那么  ,在这里
,在这里 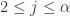 ;如果
;如果 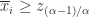 ,那么
,那么 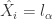 。
。
 .
.
 表示时间序列 X 的取值落在第 k 个桶的比例(概率),maxbin 表示桶的个数,len(X) 表示时间序列 X 的长度。
表示时间序列 X 的取值落在第 k 个桶的比例(概率),maxbin 表示桶的个数,len(X) 表示时间序列 X 的长度。 ,其中
,其中  表示实数集合,并且函数
表示实数集合,并且函数  满足以下几个条件:
满足以下几个条件: ,并且
,并且  当且仅当
当且仅当 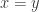 ;
; ,也就是满足对称性;
,也就是满足对称性;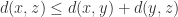 ,也就是三角不等式。
,也就是三角不等式。 (其中
(其中  或者
或者 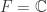 )上的向量空间
)上的向量空间 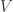 与一个内积(映射)所构成,
与一个内积(映射)所构成,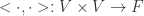 ,它满足以下设定:
,它满足以下设定: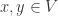 ,有
,有 

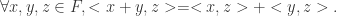
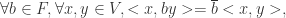

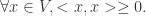
 的映射:
的映射: 是同构映射。
是同构映射。 和
和 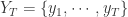 ,于是可以使用欧几里德空间里面的
,于是可以使用欧几里德空间里面的 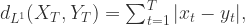


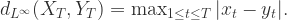
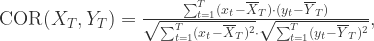
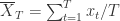 ,
, 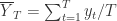 。
。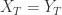 ,则
,则 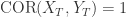 表是它们是完全一致的,如果两条时间序列
表是它们是完全一致的,如果两条时间序列  ,则
,则 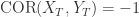 表示它们之间是负相关的。
表示它们之间是负相关的。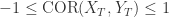 .
.

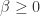 .
.
 的性质:
的性质: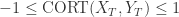
 表示两条时间序列持有类似的趋势, 它们会同时上涨或者下跌,并且涨幅或者跌幅也是类似的。
表示两条时间序列持有类似的趋势, 它们会同时上涨或者下跌,并且涨幅或者跌幅也是类似的。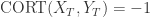 表示两条时间序列的上涨和下跌趋势恰好相反。
表示两条时间序列的上涨和下跌趋势恰好相反。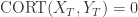 表示两条时间序列在单调性方面没有相关性。
表示两条时间序列在单调性方面没有相关性。![d_{CORT}(X_{T},Y_{T}) = \phi_{k}[CORT(X_{T},Y_{T})]\cdot d(X_{T},Y_{T}),](https://s0.wp.com/latex.php?latex=d_%7BCORT%7D%28X_%7BT%7D%2CY_%7BT%7D%29+%3D+%5Cphi_%7Bk%7D%5BCORT%28X_%7BT%7D%2CY_%7BT%7D%29%5D%5Ccdot+d%28X_%7BT%7D%2CY_%7BT%7D%29%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
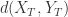 可以用
可以用 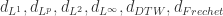 来计算,而
来计算,而
 ,可以定义自相关系数为:
,可以定义自相关系数为: ,
, 分别表示该时间序列的均值和方差。该公式相当于是比较整个时间序列
分别表示该时间序列的均值和方差。该公式相当于是比较整个时间序列 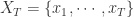 的两个子序列的相似度(Pearson 系数),这两个子序列分别是
的两个子序列的相似度(Pearson 系数),这两个子序列分别是  和
和  。
。 ,可以对每一个时间序列得到一组自相关系数的向量,用公式描述如下:
,可以对每一个时间序列得到一组自相关系数的向量,用公式描述如下:

 的情况,可以假定
的情况,可以假定  和
和  。于是,可以定义时间序列之间的距离如下:
。于是,可以定义时间序列之间的距离如下: .
. 表示一个
表示一个  的矩阵。它有着很多种选择,例如:
的矩阵。它有着很多种选择,例如: 表示单位矩阵。用公式表示就是
表示单位矩阵。用公式表示就是 .
. 表示一个
表示一个  。此时相当于一个带权重的求和公式。
。此时相当于一个带权重的求和公式。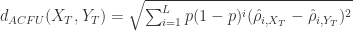 .
.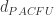 和
和  两个距离公式。
两个距离公式。 ,
, .
.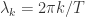 ,
, ,
,![n=[(T-1)/2]](https://s0.wp.com/latex.php?latex=n%3D%5B%28T-1%29%2F2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。这里的
。这里的 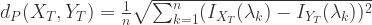 .
.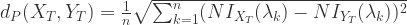 ,
, ,
, ,
, 和
和 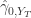 表示
表示  的标准差(sample variance)。
的标准差(sample variance)。 .
.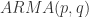 模型有自己的 AR 表示,因此可以得到相应的一组参数
模型有自己的 AR 表示,因此可以得到相应的一组参数  ,所以,对于每一条时间序列,都可以用一组最优的参数去逼近。如果
,所以,对于每一条时间序列,都可以用一组最优的参数去逼近。如果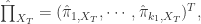

 和
和 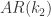 对于时间序列
对于时间序列 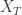 和
和  的参数估计,则 Piccolo 距离如下:
的参数估计,则 Piccolo 距离如下: ,
, ,
,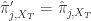 当
当  ,并且
,并且 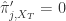 当
当 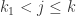 。
。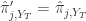 当
当  ,并且
,并且  当
当 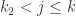 。
。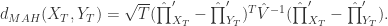
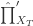 和
和 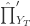 表示
表示 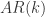 模型对于
模型对于 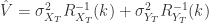 ,
,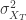 和
和 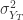 表示时间序列的方差,
表示时间序列的方差, 和
和 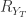 表示时间序列的 sample covariance 矩阵。
表示时间序列的 sample covariance 矩阵。 的结构,i.e.
的结构,i.e. 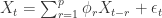 ,这里的
,这里的 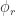 表示 AR 模型的参数,
表示 AR 模型的参数,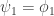 ,
, 当
当  ,
, 当
当  。
。 .
.

![\text{skewness}(X) = E[(\frac{X-\mu}{\sigma})^{3}]=\frac{1}{T}\sum_{i=1}^{T}\frac{(x_{i}-\mu)^{3}}{\sigma^{3}},](https://s0.wp.com/latex.php?latex=%5Ctext%7Bskewness%7D%28X%29+%3D+E%5B%28%5Cfrac%7BX-%5Cmu%7D%7B%5Csigma%7D%29%5E%7B3%7D%5D%3D%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bi%3D1%7D%5E%7BT%7D%5Cfrac%7B%28x_%7Bi%7D-%5Cmu%29%5E%7B3%7D%7D%7B%5Csigma%5E%7B3%7D%7D%2C&bg=ffffff&fg=2b2b2b&s=1&c=20201002)
![\text{kurtosis}(X) = E[(\frac{X-\mu}{\sigma})^{4}]=\frac{1}{T}\sum_{i=1}^{T}\frac{(x_{i}-\mu)^{4}}{\sigma^{4}} .](https://s0.wp.com/latex.php?latex=%5Ctext%7Bkurtosis%7D%28X%29+%3D+E%5B%28%5Cfrac%7BX-%5Cmu%7D%7B%5Csigma%7D%29%5E%7B4%7D%5D%3D%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bi%3D1%7D%5E%7BT%7D%5Cfrac%7B%28x_%7Bi%7D-%5Cmu%29%5E%7B4%7D%7D%7B%5Csigma%5E%7B4%7D%7D+.&bg=ffffff&fg=2b2b2b&s=1&c=20201002)

![[\min(X_{T}), \max(X_{T})]](https://s0.wp.com/latex.php?latex=%5B%5Cmin%28X_%7BT%7D%29%2C+%5Cmax%28X_%7BT%7D%29%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间等分为十个小区间,那么时间序列的取值就会分散在这十个桶中。根据这个等距分桶的情况,就可以计算出这个概率分布的熵(entropy)。i.e. Binned Entropy 就可以定义为:
这个区间等分为十个小区间,那么时间序列的取值就会分散在这十个桶中。根据这个等距分桶的情况,就可以计算出这个概率分布的熵(entropy)。i.e. Binned Entropy 就可以定义为: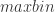 表示桶的个数,
表示桶的个数, 表示时间序列
表示时间序列 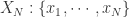 的长度是
的长度是  ,下面来详细介绍 Approximate Entropy 的算法细节。
,下面来详细介绍 Approximate Entropy 的算法细节。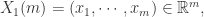
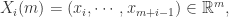

 ,可以计算出哪些向量与
,可以计算出哪些向量与  较为相似。i.e.
较为相似。i.e.
 范数。
范数。

 会基于具体的时间序列具体调整;
会基于具体的时间序列具体调整;
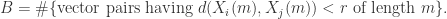
 表示集合的元素个数。根据度量
表示集合的元素个数。根据度量  )的定义可以知道
)的定义可以知道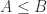 ,因此 Sample Entropy 总是非负数,i.e.
,因此 Sample Entropy 总是非负数,i.e.
 .
.
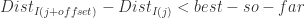 ,而不是
,而不是 ,因为
,因为  是递增排列的,并且 best-so-far > 0.
是递增排列的,并且 best-so-far > 0.