
这次整理的就是清华大学裴丹教授所著的两篇与时间序列相关的论文。一篇是关于时间序列聚类的,《Robust and Rapid Clustering of KPIs for Large-Scale Anomaly Detection》;另外一篇文章是关于时间序列异常检测的,重点检测时间序列上下平移的,《Robust and Rapid Adaption for Concept Drift in Software System Anomaly Detection》。本文将会整理一下这两篇文章的关键技术点。
Robust and Rapid Clustering of KPIs for Large-Scale Anomaly Detection
在互联网公司中,通常会拥有海量的的时间序列,而海量的时间序列就有着各种各样的形状和走势。因此,就有学者提出可以先对时间序列进行分类,然后根据不同的类使用不同的检测模型来进行异常检测。如果要做时间序列的分类,就先需要做聚类的操作,无论从 KMeans,DBSCAN,还是层次聚类来说,都会消耗一定的运算时间。所以,如何在较短的时间内进行聚类或者分类的操作则是这个系统的关键之处。于是,这篇文章提出了一个将时间序列快速聚类的方法。
时间序列 -> 时间序列分类
-> 根据每一类时间序列使用不同的异常检测模型
而在做时间序列聚类的时候,也有着不少的挑战。通常挑战来自于以下几点:
- 形状:通常来说,时间序列随着业务的变化,节假日效应,变更的发布,将会随着时间的迁移而造成形状的变化。
- 噪声:无论是从数据采集的角度,还是系统处理的角度,甚至服务器的角度,都有可能给时间序列带来一定的噪声数据,而噪声是需要处理掉的。
- 平移:在定时任务中,有可能由于系统或者人为的原因,时间序列的走势可能会出现一定程度的左右偏移,有可能每天 5:00 起的定时任务由于前序任务的原因而推迟了。
- 振幅:通常时间序列都存在一条基线,而不同的时间序列有着不同的振幅,振幅决定了这条时间序列的振荡程度,而振幅或者基线其实也是会随着时间的迁移而变化的。
从整篇论文来看,ROCKA 系统是为了做实时的时间序列分类判断的。要想做成实时的分类判断,就需要有离线和在线两个模块。其中离线是为了做模型训练或者聚类的,在线是为了使用离线处理好的模块来做曲线分类的。
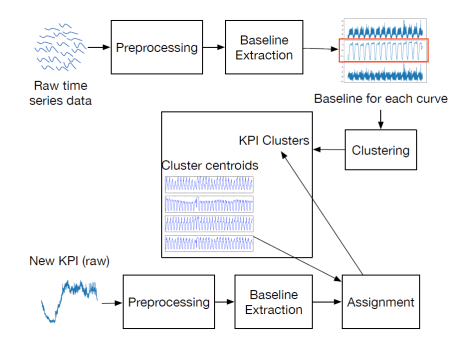
从整个系统来看,离线模块需要做以下几件事情:首先需要收集一批时间序列数据,也就是所谓的 Raw Time Series Data(Raw),通过预处理模块,实施基线提取,再进行聚类的操作,获得相应的聚类结果和质心。在线模块同样也要做类似的事情:首先对于每一条新来的时间序列数据,也就是所谓的 New Time Series Data(Raw),通过预处理模块,实施基线提取,然后使用已经聚类好的离线模块来进行实时的分类。
下面,我们来逐一分析每个模块的作用。
预处理模块(Preprocessing)
通常预处理模块包含几个关键点:
- 缺失值:缺失值指的是在该上报数据的时间戳上并没有相应的数据上报,数据处于缺失的状态。通常的办法就是把数据补齐,而数据补齐的方法有很多种,最简单的就是使用线性插值(Linear Interpolation)的方式来补齐。
- 标准化:对于一个时间序列而言,有可能它的均值是10万,有可能只有10,但是它们的走势有可能都是一样的。所以在这个时候需要进行归一化的操作。最常见的有两种归一化方法:一种是标准化,另外一种是最大最小值归一化。如果
表示原始的时间序列的话,标准化指的是
,其中
和
分别表示均值和标准差。最大最小值归一化指的是
,其中
分别表示这段时间内的最大值与最小值。
基线提取模块(Baseline Extraction)
基线提取指的是把时间序列分成基线和剩余项两个部分,假设时间序列是 ![[x_{1},x_{2},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
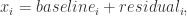
其中 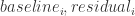

在处理基线的时候,有几件事情需要注意:
- 异常值的处理:通常需要移除一些明显异常的值,然后使用线性插值等方法来把这些移除的值补上。
- 使用简单的移动平均算法加上一个窗口值
来提取基线。假设时间序列是
,
,
。也就是说
。
- 提取基线的方式其实还有很多,使用带权重的移动平均算法(Weighted Moving Average),指数移动平均算法(Exponentially Weighted Moving Average)都可以提取基线,甚至使用深度学习中的 Autoencoder 或者 VAE 算法都能够提取基线。
基于密度的聚类算法(Clustering)
使用预处理和基线提取技术之后,可以得到原始时间序列的基线值,然后根据这些基线值来进行时间序列的聚类操作。一般来说,时间序列的聚类有两种方法:
- 通过特征工程的方法,从时间序列中提取出必要的时间序列特征,然后使用 KMeans 等算法来进行聚类。
- 通过相似度计算工具,对比两条时间序列之间的相似度,相似的聚成一类,不相似的就分成两类。
对于第一种方法而言,最重要的就是特征工程;对于第二种方法而言,最重要的是相似度函数的选择。在这篇文章中,作者选择了第二种方法来进行时间序列的聚类。对于两条时间序列 ![X = [x_{1},\cdots,x_{m}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bm%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![Y = [y_{1},\cdots,y_{m}]](https://s0.wp.com/latex.php?latex=Y+%3D+%5By_%7B1%7D%2C%5Ccdots%2Cy_%7Bm%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


通过这个偏移量


其中 ![NCC \in [-1,1]](https://s0.wp.com/latex.php?latex=NCC+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![SBD \in [0,2]](https://s0.wp.com/latex.php?latex=SBD+%5Cin+%5B0%2C2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
而聚类的另一个重要指标就是质心的选择,在这里,每个类的质心可以设置为:

实时分类(Assignment)
对于一条新的时间序列(Raw Data),同样需要经过预处理,基线提取等步骤,然后计算它与之前每一个质心的距离。然后进行距离的从小到大排序,最小的那一类可能就是所需要的。当然,当最小距离大于某个 threshold ,就说明这条新的时间序列曲线很可能不属于之前的任何一类。通过人工查看之后,可以考虑新增一类,并且更新之前所做的聚类模型。
聚类与时间序列异常检测
如果要做海量的时间序列异常检测的话,通常有以下两种做法。
- 先对时间序列进行聚类或者分类,针对不同的时间序列类型来使用不同的模型;
- 在时间序列异常检测中加入分类特征。
对于第一种方法而言,需要针对不同形状的时间序列维护不同的模型,而且如果第一层的聚类/分类错误了,那么使用的模型也会出现错误。对于第二种方法而言,关键在于样本的积累和分类特征的构建。
Robust and Rapid Adaption for Concept Drift in Software System Anomaly Detection
这篇文章是关于时间序列异常检测的,而清华大学的 Netman 实验室做时间序列异常检测的相关工作比较多。从 2015 年开始的 Opperentice(Random Forest 模型),Funnel(SST 模型,变更相关),到后来的 Donut(VAE 模型),都是时间序列异常检测的相关文章。而这篇问题提到的 StepWise 系统针对的场景是关于指标的迁移的,所谓概念漂移(Concept Drift)指的就是时间序列会随着变更,发布,调度或者其他事件的发生而导致上下漂移或者左右漂移。一个比较典型的例子就是关于网络流量的漂移,通常来说在某个特点的时间点,时间序列会出现猛跌或者猛涨的情况,但是下跌或者上涨之后的走势和历史数据是及其相似的,只是绝对值上有所变化。
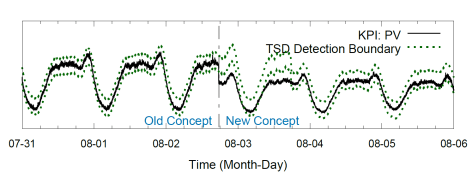
正如上图所示,在时间戳 08-02 附近,时间序列出现了一个下跌的情况。但是根据历史数据所计算出来的上界(Upper Bound)和下界(Lower Bound)却会把未来一段时间的序列都判断为异常。但是前后的曲线走势却是一样的,其实只有下跌的那一小段时间应该被判断为异常,其他时间都是正常的。基于以上的业务场景,这篇文章的作者就提出了概念漂移(Concept Drift)的一些方法。
在整个 StepWise 系统背后,有两个比较关键的地方。其中第一个关键之处就是如何判断异常点。在这个业务场景下,需要检测的是上图发生暴跌的点。而暴跌或者暴涨只是业务运维用来描述时间序列的一个词语。在统计学领域,这种点通常称为变点(Change Point)。所以概念漂移的检测可以转化为一个变点检测的问题,正是论文里面写的。
Insight 1:Concept drift detection can be converted into a spike detection problem in the change score stream.
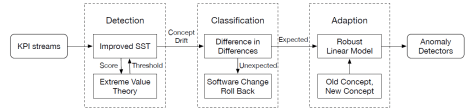
如果是进行变点检测的话,其实可以参考 2016 年的论文 Funnel:Assessing Software Changes in Web-based Services。里面使用了 Singular Spectrum Transform 来进行检测,并且使用 Difference in Difference 来判断时间序列是否真正出现了异常。关于 SST(Singular Spectrum Transform)的具体细节可以参考 Yasser Mohammad, Toyoaki Nishida 所撰写的 Robust Singular Spectrum Transform。SST 算法是基于 SVD 算法的,有一定的时间复杂度。而基于 SST 又有学者提出了 Robust SST,具体可以详见论文。而 StepWise 的其中两步就是 Detection 和 Classification,其中的 Detection 使用了 Improved SST,Classification 使用了Difference in Difference。而 Funnel 系统的其中两步也是 Improved SST 和 Difference in Difference,这与 Funnel 有异曲同工之妙,Funnel 系统详情请见下图。
而突变前后的时间序列可以分别叫做 Old Concept 和 New Concept,由于前后的走势几乎一致,所以本文的第二个关键点就是相似度的判断。
Insight 2:The relationship between new concept and old concept can be almost perfectly fitted by linear regression.
从数学的角度来讲,Insight 2 的陈述是想判断两条时间序列是否相似。假设 ![X=[x_{1},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![Y = [y_{1},\cdots, y_{n}]](https://s0.wp.com/latex.php?latex=Y+%3D+%5By_%7B1%7D%2C%5Ccdots%2C+y_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
- 存在一个线性关系
使得二维点集
能够被很好的拟合好,也就是说此刻的方差较小。
的 Pearson 系数很高;
- 分别存在两个值
使得
与
几乎一致。
所以,在 StepWise 中,作者通过线性回归的算法来判断 old concept 与 new concept 是否存在线性关系,也就是说这两者是否只是平移的关系。其实也可以尝试上面所说的其余方法。
整体来看,StepWise 大致分成两个关键步骤。首先使用类似 Funnel 系统的思想,先进行异常检测(SST),再使用判断一下是不是因为软件的变更引起的(DID),最后使用一层过滤逻辑(线性拟合)来判断是否出现了概念漂移的情况。在实际使用过程中,无论是异常检测还是过滤逻辑,都需要根据具体的业务来做,很难找到一个固定的模型来解决所有的难题。

ROCKA 论文里算密度半径得到的是个列表,选用哪个作为dbscan的密度半径,这个按照什么原则处理合适呢?
LikeLike