
近期阅读了一篇论文《Rapid Deployment of Anomaly Detection Models for Large Number of Emerging KPI Streams》,这篇文章基于之前的 ROCKA 系统做了一些额外的工作。ROCKA 系统是用来做时间序列的实时聚类的,而这篇文章是在 ROCKA 系统的基础上增加了时间序列异常检测的功能。通常来说,时间序列异常检测可以使用有监督的方法来解决,参考 Opperentice 系统。而本篇文章使用了半监督学习的思路来解决异常检测的问题,下面来详细分析一下这篇文章的细节,本文的作者把这个系统称为 ADS(Anomaly Detection through Self-training)。
数据集的情况
在论文中,作者使用了两份数据集,分别是已经历史上的 70 条时间序列,另外还有新来的 81 条时间序列。在 ADS 系统中,历史上的 70 条时间序列被划分成 5 类,并且已经可以找出每个类的质心位置,并且每条历史上的时间序列通常来说会大于三个星期(3 weeks)。本篇论文的评价指标是 F-Score,也属于机器学习领域里面比较常用的衡量模型效果的指标。整体来看,这篇文章的数据集大约是 200 条时间序列,时间序列的时间间隔通常来说是五分钟(不过其余的运维场景会有一分钟的数据采集粒度),而一般来说都拥有大半年甚至一年的时间跨度。那么时间点的个数预估是 200 * (1440 / 5) * 365。假设异常的数据:正常的数据 = 1:10000(也就是说平均每条时间序列每周至少发生一次异常),于是这批时间序列数据的异常数据量大约是 200 * (1440 / 5) * 365 / 10000 = 2102,也就是说异常的样本大约是 2102 个左右,剩下的都是正常的样本。PS:当然如果异常的数据:正常的数据的比例大于 1:10000 的话,异常的样本还会更多一些。整体来看,时间序列异常检测是一个样本极其不均衡的场景。
ADS 的系统架构
按照作者之前论文的经验,时间序列异常检测通常都是先做聚类,然后再根据每一个类的特点来做一个异常检测模型,之前的技术架构就是 ROCKA + Opperentice。因为 ROCKA 可以根据时间序列的走势和趋势来进行时间序列的实时分类/聚类,然后 Opperentice 就是做时间序列异常检测的模型。在本文的场景下,作者把 70 条时间序列分成了5 类,因此只需要维护 5 个时间序列的异常检测模型就可以了。当然把时间序列切分成更多的类也是可以的,只是需要维护的时间序列异常检测就变多了,人工成本会加大。
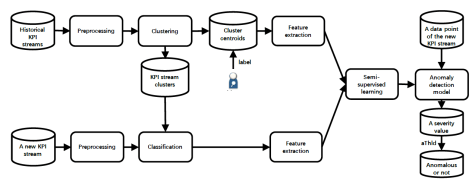
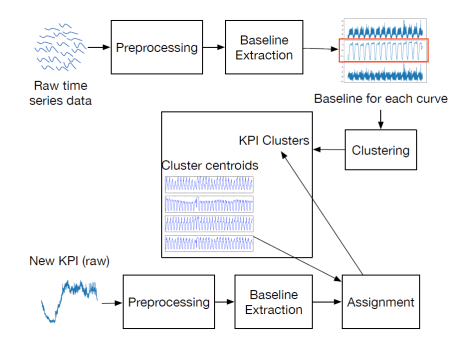
如果看到上面两幅图,有心的读者一定会发现其实 ADS 就是基于 ROCKA 所做的工作。ADS 先对时间序列进行了分类,然后进行了特征提取的工作,再通过半监督学习模型,最后进行异常检测。也就是说,ADS 会走下面四个步骤:
- ADS 先把历史上的时间序列进行聚类;
- 通过算法获得每一个类的质心,并且标记出质心曲线的异常点和正常点;
- 对新来的时间序列进行实时聚类,划分到合适的类别;
- 基于新来的时间序列(没有标记)和历史上的时间序列(有标记)使用无监督算法来重新训练一个新的模型,进行该类别的时间序列异常检测。
ADS 的细节
对于时间序列的聚类框架 ROCKA,之前的一篇 BLOG 里面已经详细介绍过,这里将不会再赘述。而 ADS 的另一个模块就是半监督学习算法 Contrastive Pessimistic Likelihood Estimation(CPLE),详细的论文细节可以参考论文《Contrastive Pessimistic Likelihood Estimation for Semi-Supervised Classification》。CPLE 有几个好处:
- CPLE 是半监督学习算法中比较健壮的,因为它并没有过多的假设条件,并且也符合这篇文章的业务场景,同时拥有质心曲线(有标记)和新来的曲线(无标记),使用半监督学习也是符合常理的。除了 CPLE,其实在实战过程中也可以多尝试其他的半监督模型,具体可以参考周志华的《机器学习》。
- CPLE 的复杂度比较低,计算快。
- CPLE 支持增量学习,因此,当越来越多新的时间序列进入 ADS,这个模型也会随之而调整并提高准确率。
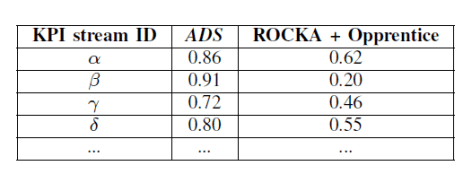
整体来看,ADS = ROCKA + CPLE,而在论文中,它的对比模型就是 ROCKA + Opperentice。而且在 CPLE 中,也使用了与 Opperentice 系统类似的特征,如下图所示。
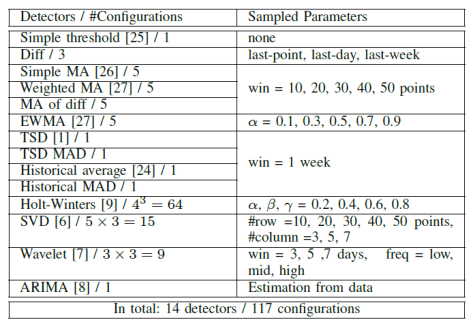
其实,从本质上来看,就是半监督学习与有监督学习在这份数据集合上面的比较。从这篇论文里面所展示的数据来看,CPLE 有一定的优势。
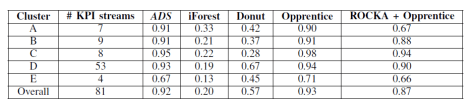
整体来看,本篇文章介绍了时间序列异常检测的一种方案,也就是把时间序列先进行聚类的操作,然后根据不同的类来进行异常检测。在异常检测的方法中,不仅可以使用 Random Forest,GBDT,XGBoost 等有监督学习方法,也可以使用 CPLE 等半监督算法。具体在业务中如何使用,其实只能够根据具体的数据来进行合理地选择了。

少有的深入研究 Time Series based ML 博客,非常不错。
LikeLike
哈哈,谢谢关注~~~
LikeLike