
在之前的时间序列相似度算法中,时间戳都是一一对应的,但是在实际的场景中,时间戳有可能出现一定的偏移,但是两条时间序列却又是十分相似的。例如正弦函数 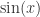
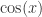
基于动态规划的相似度计算方法
DTW 的经典算法
基于动态规划的相似度计算的典型代表就是 DTW(Dynamical Time Warping )和 Frechet 距离。在这里将会主要介绍 DTW 算法。详细来说,DTW 算法是为了计算语音信号处理中,由于两个人说话的时长不一样,但是却是类似的一段话,欧几里德算法不完全能够解决这类问题。在这种情况下,DTW 算法就被发展出来。DTW 算法是为了计算两条时间序列的最佳匹配点,假设我们有两条时间序列 Q 和 C,长度都是 n,并且 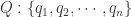








现在我们需要找到一条路径使得

这条路径就是动态规划的解,它满足一个动态规划方程:对于 


其初始状态是 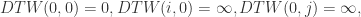



- 如果
时,则
表示最后的距离;
- 如果
时,则
- 如果
时,则
表示最后的距离。
Remark.
DTW 算法不满足三角不等式。例如:

DTW 的加速算法
某些时候,我们可以添加一个窗口长度的限制,换言之,如果要比较 ![q[i]](https://s0.wp.com/latex.php?latex=q%5Bi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![c[j]](https://s0.wp.com/latex.php?latex=c%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

初始条件和之前一样。

这里的 

相似时间序列的搜索
相似的时间序列的搜索问题一般是这样的:
Question 1. 给定一条时间序列 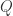
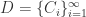
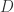
Question 2. 给定一条时间序列 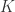
DTW 算法的下界 LB_Kim
对于两条时间序列 Q 和 C 而言,可以分别提取它们的四个特征,那就是最大值,最小值,第一个元素的值,最后一个元素的值。这样可以计算出 LB_Kim
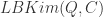

可以证明 
DTW 算法的下界 LB_Yi
有学者在 LB_Kim 的基础上提出了一种下界的计算方法,那就是 LB_Yi,有兴趣的读者可以参见:efficient retrieval of similar time sequences under time warping, 1998.
DTW 算法的下界 LB_Keogh
但是,如果是基于 DTW 的距离计算方法,每次都要计算两条时间序列的 DTW 距离,时间复杂度是
(1)首先定义时间序列 Q 的上下界。i.e. 

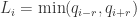
(2)定义公式:


其中,LBKeogh 满足性质:
对于任意两条长度为 n 的时间序列 Q 和 C,对于任意的窗口 

所以,可以把搜索的算法进行加速:
Lower Bounding Sequential Scan(Q)
best_so_far = infinity
for all sequences in database
LB_dist = lower_bound_distance(C_{i},Q)
if LB_dist < best_so_far
true_dist = DTW(C_{i},Q)
if true_dist < best_so_far
best_so_far = true_dist
index_of_best_match = i
endif
endif
endfor
在论文 Exact Indexing of Dynamic Time Warping 里面,作者还尝试将 Piecewise Constant Approximation 与 LB_Keogh 结合起来,提出了 LB_PAA 的下界。它满足条件 
总结
本文初步介绍了 DTW 算法以及它的下界算法,包括 LB_Kim, LB_Keogh 等,以及时间序列数据库的搜索算法。
