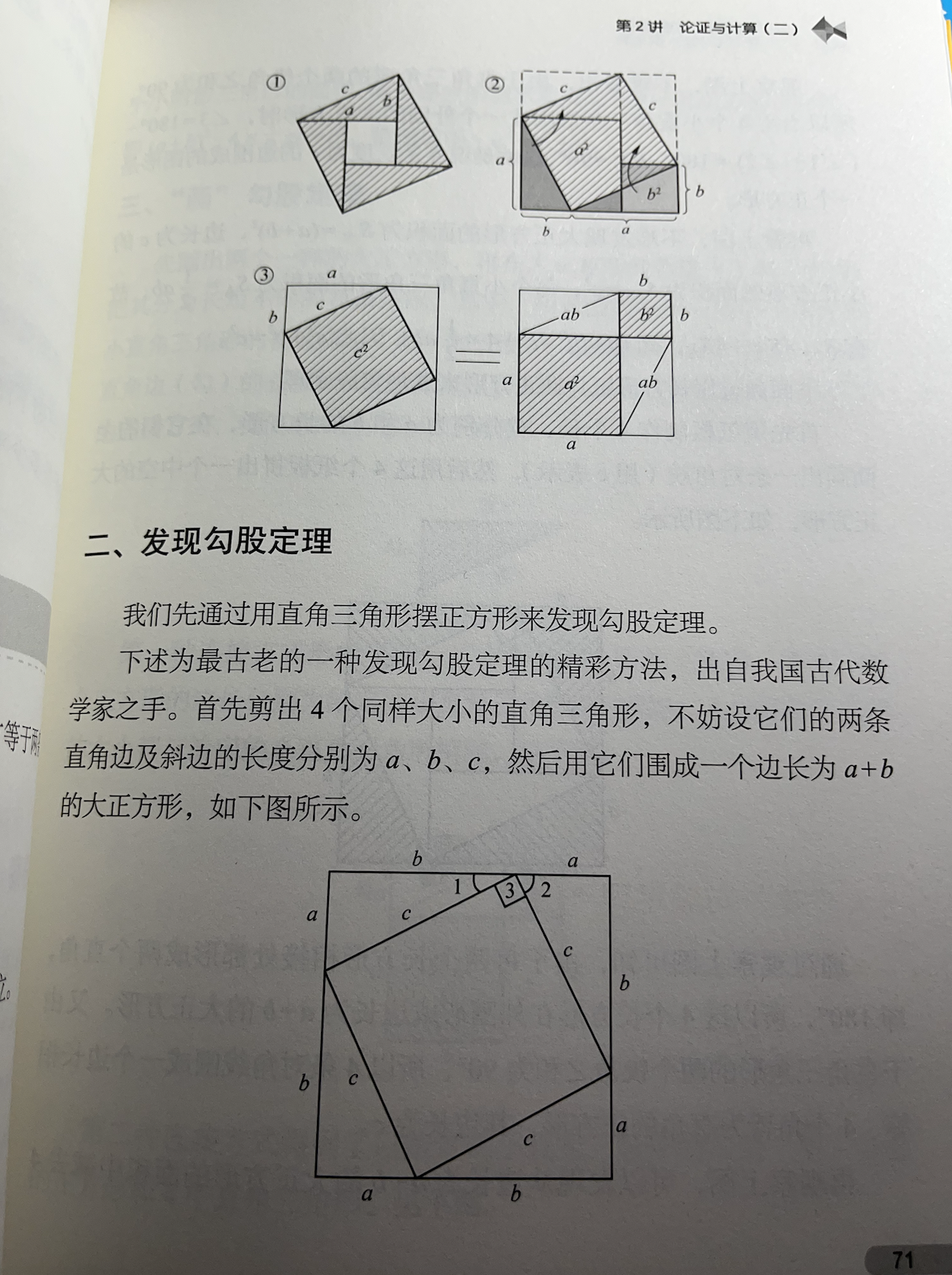
William Thurston(昵称 Bill)是 1982 年数学界最高奖菲尔兹奖得主,2012 年去世。他的数学研究就像进行魔术表演,总是突然就从帽子里抽出绝妙的创意,无数次让世界范围内的数学家们惊叹不已。1970-1980年间,Thurston 的研究工作在拓扑学领域引起了一场翻天覆地的革命,对数学界的影响一直持续到现在。
Dennis Sullivan 是 2010 年数学界另一个大奖沃尔夫奖得主,在代数拓扑和复动力系统两个领域为数学界作出深刻的贡献。Thurston 和 Sullivan 的研究有着很大的交集。当 Sullivan 得知 Thurston 去世的消息后,他迅速写下了这十个记录他们之间来往的故事。
撰文|Dennis Sullivan
翻译|杜晓明
故事一
1971 年 12 月,在伯克利召开的一个动力系统研讨班结束的时候,貌似解决了一个能很好地应用于动力系统的平面上的棘手问题。解决方案宣称:能把 N 个两两位置不同的点逐步移动到另外的 N 个点,使得在移动过程中不发生自交,并且每一步都整体只移动非常小的距离。坐在前排的资深动力系统专家们都乐观地相信这个结果,因为根据之前的经验,在三维以及更高维数的动力系统的应用中,由于这些点能摆成一般位置,这个结论显然是对的,如今该定理在二维的情形也应该成立。
一个坐在教室最后排的长头发、大胡子的研究生站了起来,说证明中的算法是不成立的。他就是 Bill Thurston。他怯怯地走到黑板前面,画了两幅图,每幅图都有 7 个点。然后开始按照刚才的算法来操作。一开始出现的连线尽管很短很少,但毕竟挡住了另外一部分线的延伸方向。想把另外一部分线继续延长又同时避免出现交叉的话,必须从别的地方绕回来,于是各条线开始变得越来越长。在这个复杂的图示例子里,刚才的算法无效!我从未见过其他人有如此强的理解力,也从来没见过有人能如此之快就创造性地构造出反例。这让我从此对几何上可能出现的复杂性产生敬畏。
各个时期(上世纪70 年代、80 年代、90 年代)的 Thurston。
故事二
几天之后,伯克利的研究生们邀请我(那时我也同样是大胡子、长头发)在分隔办公区与电梯区的走廊墙壁上画一些与数学有关的壁画。就在准备画的时候,故事一里面提到的那位研究生跑来问我:“你觉得画这个东西有意思吗?”他给我看的是平面上围着三个点绕来绕去的一些复杂的一维对象。我问:“这是什么?”他的答案让我很惊讶:“它是一条简单闭曲线。”我说:“这一定很有趣!”
于是我们就开始花几个小时一起在墙上画这条曲线。这真是一次非常棒的学习如何粘贴的体验。为了让这条曲线看起来较美观,首先得画一些较短的、彼此平行的、有些弯曲的短线(正如叶状结构局部方形邻域内的图案一样),然后再把它们光滑地接起来。我问他是如何想到这样的曲线的,他说:“从一条给定的简单闭曲线出发,不停地沿着中间的相交曲线作成对的 Dehn twist。”
这幅 2 米高、4 米宽、画着曲线的壁画(见2003年《美国数学会通讯》第50卷第3期的封面)署有作者和日期:“DPS and BT, December, 1971”,它在伯克利的墙上保留了40多年,直到几年前才被擦去。
过去在伯克利 Evans Hall 里由 Thurston 和 Sullivan 一起画的壁画。这个围着三个点绕来绕去的复杂图像实际上是一条简单闭曲线。| 摄影:Ken Ribet
故事三
上面两个故事在伯克利发生的那个星期,其实我只是从麻省理工学院访问伯克利,讲一系列关于微分形式和流形同伦论的课。那时候叶状结构与微分形式到处出现,并且成为研究的热潮,我想利用在我的研究中出现的1-形式来描述基本群的中心下降序列,进而构造叶状结构。这些叶状结构的叶子覆盖了从流形到它的幂零流形的映射图像。幂零流形就是从基本群的高阶幂零子群出发构造的流形。这其实是把利用同调来构造的到高维环面的 Abel 映射推广成幂零的情形。由于缺少 Lie 群的知识,我曾向麻省理工学院和哈佛大学的微分几何学家们请教这个推广的可能性,但我自己还是没弄明白。这些都太模糊、太代数化了。
来到伯克利之后,我在第一次课上就提出这方面的问题,并私下里与 Bill 进行讨论。开始我并没有抱什么希望,因为这是奇怪的代数与几何的混合体。然而第二天,Bill 就想到了彻底的解决方法,并且给出了完整的解释。对于他来说,这些只是很初等的东西,涉及的几何知识也不多,仅仅是 Elie Cartan 的 dd=0 的对偶形式中的 Jacobi 关系。
就在以上两个故事发生期间,我向我的老朋友 Moe Hirsch 提起了 Bill Thurston。Thurston 是 Moe 的博士生,那时候正处于博士阶段的第五年。我记得是 Moe 还是谁说过,Bill 开始念博士时进展很缓慢,甚至在口试时出了点小问题。当时 Bill 被要求举一个万有覆盖的例子,他选择了画亏格为2 的曲面的万有覆盖,在黑板上画出一些笨拙的八边形,八个八边形共用一个顶点。
亏格 2 曲面的万有覆盖。
这种论证很快就在黑板上越来越呈现为没有说服力的混乱。我想 Bill 是第一个在考场上想出如此非平凡的万有覆盖的人。Moe 说,不久之后,Bill 便开始以每个月一个的速度解决博士论文级别的大问题。许多年之后,我听说就在那段时间里, Bill 刚好有了他的第一个孩子 Nathaniel。孩子在晚上不睡觉,所以 Bill 也没法睡觉。在念研究生的时候,有一整年的时间,他晚上都只能与 Nathaniel 在地板上来回地走。
在伯克利度过的那一周改变了我的人生。我很感激命运让我有幸欣赏到所谓的“莫扎特现象”,并且认识了一位新的朋友。我刚从伯克利回到麻省理工学院,就马上把这一切告诉我在麻省的同事们。但我想我的热情过于强烈了,以致没法让别人全部理解:“我遇到了自己所见过的、甚至从没期望会遇到的最好的一位研究生。”
我安排 Bill 先去普林斯顿高等研究院(IAS),然后来麻省理工学院做一场报告,并计划把他招到麻省理工学院。但最后的结果是,Bill 在 1973-1974 年来麻省理工学院访问了一年,但那一年我正好去访问法国高等科学研究院(IHES),并且在法国一待就是 20 年。而 Bill 则被邀请回到普林斯顿大学任职。
故事四
普林斯顿高等研究院,1972-1973
在 1972-1973 这段时间,我从麻省理工学院访问普林斯顿,于是与 Bill 接触的机会更多了。一天,我们从普林斯顿高等研究院出来准备去吃午饭。我问 Bill,什么是极限圆(horocycle)。他说:“你们待在这儿别动。”然后他开始向学院的草地走去。走了一段距离,他停住并转过身来,说:“你们在以我为圆心的圆周上。”然后他转身走得更远,再次转过身来说了一些东西。由于距离远,他说什么我已经听不清楚了。他每走到一个新的地方就再喊一次,我们终于知道他说的是同样的意思:“你们在以我为圆心的圆周上。”接下来他走得更远了。由于距离太远,他喊什么我都听不见了。等他转过身来使劲喊大概同样意思的时候,我忽然知道了什么是极限圆。
极限圆
Atiyah 问我们其中某些拓扑学家:平坦向量丛是否存在分类空间?他曾对这样的丛构造出一些新的示性类。由 Brown 定理,我们知道这东西存在,但是还不知道如何具体地构造出来。第二天,Atiyah 说,当他问 Thurston 这个问题的时候,Thurston 给出了一个神奇的构造:把作为向量丛结构群的李群看成一个抽象群,赋予离散拓扑,然后就给出分类空间。
后来,我听说 Thurston 通过画图证明给 Jack Milnor 看:任意单峰映射的动力系统模式都会出现在取适当值c时对应的二次函数 x → x2+c 的迭代中。我因为正在学习动力系统,所以就计划花一个学期的时间在普林斯顿,向 Bill 学习这篇从刚才提到的画图而发展出来的关于 Milnor-Thurston 万有性的著名论文。
故事五
普林斯顿大学,1976 年秋
1976 年 9 月,我准备去普林斯顿大学学习一维动力系统,而 Thurston 则已经发展出曲面映射的新理论。我刚到的时候,他在高等研究院做了三个小时精彩的即兴演讲来解释这个理论。我非常幸运:因为有之前在伯克利的墙上画那条曲线的艰苦劳动,由此启发,Thurston 关于叶状结构的极限的主要定理直观上对我来说非常清晰。在我待的那个学期即将结束的时候,Thurston 告诉我,他相信这些东西对应的映射环面具有双曲度量。我问他为什么,他说不知道如何向我解释,因为我没有充分理解微分几何。
在我离开普林斯顿之后的几个星期里,Bill 没有我的干扰,有更多时间从事研究。对于特定的 Haken 流形,他完成了双曲度量存在性的证明。而对于映射环面的情形,他后来又花了两年多的时间。其中的细节本文后面会说。
在 Bill 讲授的一门一学期课程里,研究生和我都学到了很多关键的思想:
- “双曲几何在无穷远处变成共形几何”的类比。让人印象深刻的是,Bill 处理的方式是在双曲空间内部而不是在无穷远边界处,他关注的是一个特殊的模型。这给我带来完全不同的心理体验。
- 我们学会极限点凸包的边界曲面的内蕴几何。一天,Bill 来上课,他在讲台上转动一个他自己做的精巧的纸制装置,不停地旋转,而他却不说任何话,直到我们领悟出平坦性为止。
- 我们还学到了双曲曲面的厚薄分解。我记得 Bill 在普通房间的黑板上画出有 50 米长不停环绕的曲面薄块。忽然一切明朗起来,包括如何解释在几何上收敛到 Riemann 曲面组成的模空间上著名的 Deligne-Mumford 紧化上的点。
后来 Sullivan 在课上讲解带很“薄”的部分的双曲曲面。
1976 秋,我在普林斯顿整整待了一个学期。Bill 和我讨论如何理解 Poincare 猜想,希望证明一个对所有三维闭流形都成立的更一般性的猜想。我们的想法是建立在三维是相对较低的维数这个基础之上。我们在一篇小文中论述,只要能证明三维闭流形都有共形平坦坐标,就可以证明整个 Poincare 猜想。我们决定在这个问题上共同花上一年。然而,当时在那儿学习的一位名叫 Bill Goldman 的本科生在几年之后证明了这个前提是不正确的。(如果上数学家家谱网站查师承关系,可以查到 Thurston 与 Goldman 都是Hirsch 直接指导的博士。Thurston 为 Hirsch 带来的学术后裔有 200 多个,而 Goldman 则带来 30 多个。除了他们俩之外,Hirsch 的其他博士带来的学术后裔加起来没几个。)
接下来,Bill 在普林斯顿发展了 quasi-Fuchsian 型 Klein 群的极限的理论,来寻找映射环面上的双曲结构。与此同时,我在巴黎努力想解决 Ahlfors 的极限集零测度猜想。一年之后,他的研究取得了关键进展(把尖点封闭上了),而我的研究则在否定的方向上取得了极大进展(证明所有与已知 Klein 群信息有关的遍历论方法都是不够的,有太多深层次的非线性障碍)。在一次瑞士阿尔卑斯山上召开的会议上,我们对比了各自的笔记。他的整个映射环面证明计划虽然完成了,但是证明过程非常复杂。而我否定方向的信息则能把 Mostow 刚性定理推广成一般性的结论,这能在相当大的程度上简化 Bill 在纤维化情形下的证明(参见次年Bourbaki讨论班关于 Thurston 工作的报告)。
Thurston 证明映射环面上存在双曲结构的论文首页。该项工作把三维流形的双曲结构、Riemann 曲面、分形、填充二维区域的连续曲线等众多领域联系了起来。
故事六
石溪会议,1978 年夏
在石溪举行了一次关于Klein 群的盛大会议。Bill 出席了会议,但没有发言。Gromov 和我邀请他即兴做一个计划之外的长时间的报告。这是一场通向双曲三维流形无穷远端、凸包、皱褶曲面、ending lamination 等等的美妙旅程。在报告的过程中,Gromov 凑过来跟我说,Bill 这次报告使他感觉这个方面的研究还没真正开始。
凸包与皱褶曲面。双曲球体表面有一条分形曲线,粉红色与浅绿色的两个皱褶曲面围住的部分是该分形曲线在双曲球体内部的凸包,作为凸包边界的皱褶曲面在除了一个零测集之外都是测地曲面。| 图片来源:http://vivaldi.ics.nara-wu.ac.jp/~yamasita/
故事七
科罗拉多,1980 年 6 月至 1981 年 8 月
Bill 和我一起在 Boulder 大学做 Ulam 访问教授,在那里举办两个讨论班:一个较大的讨论班是把整个双曲性定理的全部证明细节过一遍,另一个较小的讨论班是关于Klein 群的动力系统以及一般性的动力系统。参加第一个讨论班的许多研究生们共同检查了双曲性定理的全部证明细节。
有一天,在动力系统的讨论班上,Thurston 迟到了。Dan Rudolph 正在精力充沛地对一个以往证明过程极度复杂的定理作简化证明。这个简化的证明在一小时之内就能讲完。在两个遍历的保测度变换的轨道相差不太远的前提下,该定理能把轨道等价类加强成共轭类。旧的证明 Katznelson、Ornstein 和 Weiss 用了一门短课才能解释清楚,而新证明的引人注目之处在于仅仅用一小时就能完成。Thurston 终于来了,问我前面讲了什么,让我帮他跟上进度。我都照办了。
在讲座即将结束的时候,Thurston 大声向我耳语:证明的难点究竟在哪里?我向他发出“嘘”声让他安静,提醒他应该尊重课堂环境。最后,Bill 说,只要想象一下:在一根线上布满了珠子;珠子往线的两端无穷地延伸,中间只有有限的间隙;然后让它们都滑向左边(同时他张开出双臂给我作形象的说明)。只要把这个想法翻译成标准的文字,就马上能给出一个新的证明。那天晚些时候,Dan Rudolph 充满敬畏地跟我说,他之前没有想象到 Bill Thurston 会聪明到这个程度。
故事八
美国加州 La Jolla 与巴黎,1981 年夏末
在科罗拉多的经历很愉快。Thurston 的几何讨论班在完全放松的氛围中度过。某一天我们构想出了 8 种几何模型,另一天我们为某个对象究竟应该命名为“manifold”还是“orbifold”而投票。我也正在写几篇我自己的关于 Hausdorff 维数、动力系统、极限集的测度的论文。接下来的夏天末尾,Thurston 回到普林斯顿。我则从巴黎飞到 La Jolla,给美国数学学会做一系列关于动力系统最新进展的特邀报告。为了达到更好的演讲效果,我决定改变报告的主题,换成首次向数学界公开展示整个双曲性定理!并且我也希望以此作为 Boulder 讨论班结束后我给自己安排的一次期末考试。
在去往美国的飞机上,我只准备了一页纸的概括性讲稿。但将要讲的报告却一共安排了四到五天,每天两场!第一天估计能勉强应付过去。我想:先讲点综述,剩下的再即兴发挥一下吧。但是想把这么重要的一系列报告做好,我需要极好的运气。历史性的时刻到了!
从巴黎到加州有 9 个小时的时差。刚到达的那天深夜我睡不着,到安排给我的办公室里准备报告的内容。很快我却发现,关于双曲性的论证过程,我碰到很多问题都没法自行解答。这时我发现办公室桌上的电话居然还可以打长途。此刻加州的时间是凌晨 4 点,普林斯顿的时间是早上 7 点。我打电话到 Thurston 的家,他接了。我向他陈述了我的问题,他先给出部分简短的回答。我赶快用笔记下来。他说等送完小孩到学校再赶回办公室之后给我回电话。当他在两个半小时之后打电话给我时,我对他刚才的答案提出更多否定意见,而他又作出更加细致的答复。我们终于把所有可能产生问题的地方都处理完毕。
加州时间 8 点整,我准备好了两场演讲的材料。第一天顺利度过:第一场报告,午餐,去沙滩,游泳,第二场报告,晚餐,告别同事,回住处睡觉。重新看报告的录像时我才发现,听众的阵容强大得可怕:Ahlfors,Bott,陈省身,Kirby,Siebenmann,Edwards,Rosenberg,Freedman,丘成桐,Maskit,Kra,Keen,Dodziuk……
来听这次报告的人。作开场介绍的是德高望重的 Ahlfors。听众里包含了当时几何与拓扑领域几乎所有的顶尖数学家。
Bill 和我每天重复这样的事情,配合得很完美。每天加州时间早上 8 点的时候,我准备好我的两场报告内容,做好一切提问的应对。当陈述 Bill 那些绝妙地控制住测地线长度的技术时,演讲推向高潮!这些测地线是分支皱褶曲面在分支处的曲线。要估计它们的长度,利用的却是内蕴曲面上测地流产生的动力系统的熵。这个熵又与分支曲面万有覆盖的面积增长率有关。但在负曲率的空间中,这个面积的增长速度却又被双曲球体的体积增长率所控制。证毕!不但如此,Thurston 还构造出一个漂亮的例子,表明估计的界是精确的。对于听众之一的 Harold Rosenberg(他是来自巴黎的精明的朋友)来说,这次报告的水平是超乎想象的。报告结束之后,他沮丧地问我:“Dennis,你是不是一直把 Thurston 锁在你办公室的楼上呀?”
Sullivan 阐述控制测地线长度绝妙证明的时刻。
我之前一直对这些报告背后的故事三缄吾口,直到现在才说出来。这一系列报告都被 Micheal Freedman 用录像机记录了。如今这些 Thurston-Sullivan 讲座的视频都能在互联网上找到。
故事九
巴黎,1981 年秋
我在美国数学学会的演讲大获成功之后,Bill 来巴黎访问我。我在私人办公室买了个舒适的沙发床,以便于他休息。他很有礼貌地问了我以下两个问题:一、如果之前在美国数学学会的演讲上没有把报告的主题换成他的双曲性定理的话,我原定计划讲的是什么内容;二、在科罗拉多,除了双曲性定理的讨论班之外,我似乎还在一直忙着别的东西,具体是在研究什么。
关于这些,我总共有 6 篇计划中论文的内容要告诉他。其中包括一个我从他那里学到的最吸引人的想法:对于无穷远球面上一个适当的集合来说,从双曲球体内部一点看过去时,在视觉上的 Hausdorff 测度,能定义出一个双曲三维空间中 Laplace 算子对应于本征值 f(2-f) 的大于零的本征函数。我向他陈述并解释这些想法。每当我陈述完一个想法,他就马上给出一个证明,或者我给出我证明的主要思路。这六篇论文里的定理都被我们一一证明,有的是他证,有的是我证。我们差点漏掉一种情形:如果最后一个本征函数 f>1 的话,规范化之后新的本征函数的平方积分范数将可以通过凸核的体积来估计。Bill 躺回沙发床中,闭上双眼想了没多久,就很快把差点漏掉的这种情形证明了出来。他估计的方法是让测地线无限延长,然后在横截的方向求平均值。
随后我们外出散步,从 Orleans 港穿过巴黎市区走到 Clignancourt 港。我们边走边沉浸在数学讨论之中,以致于忘了自己身处何地。一直等到我们经过塞纳河,圣母院和古监狱同时映入眼帘时,才想起来自己置身于美丽的巴黎。
故事十
从普林斯顿到曼哈顿,1982-1983
由于开始了长达 13 年的纽约市立大学 Einstein 研讨班的主持职务,我不得不把时间分配开,一直在法国高等科学研究院和纽约市立大学研究生中心之间来回奔波。Einstein 研讨班的主题一开始是动力系统与拟共形同胚,后来慢慢转变成拓扑中的量子对象。Bill 则继续发掘和训练有天赋的学生,传播双曲空间那些漂亮的理论,培养出大批新一代年轻的几何学家。Bill 推迟写他那关于双曲性定理论文的终稿。取而代之的,是让他不断培养起来的越来越多的新一代几何学家们把整套理论发展到更加广阔的天地中去。他在 20 世纪 70 年代初关于叶状结构的论文震撼了该领域,但同时也终结了该领域的研究。他不想看到在双曲几何领域发生同样的事情。
有一次,我们准备在曼哈顿聚一下,讨论在单变量复动力系统、双曲几何,以及我之前研究的 Klein 群的各种类比。在公寓里我们很随意地讨论,讨论话题也开始拓展延伸。最后我们在 Bill 乘火车回普林斯顿之前 30 分钟制定好了研究计划。我概括了一般性的类比:庞加莱极限集、不连续域、复结构的形变、刚性定理、分类空间、Ahlfors 有限性定理、Ahlfors 与 Bers 的工作……与以下概念相比较:Julia 集、Fatou 集、非游荡域定理、Hubbard 与 Douady 的工作……他快速完整地吸收了这些想法,然后离开去坐火车。
两周之后,我们听说他用 Teichmüller 空间上不动点的观点改写了整个复动力系统的理论,其中的部分手法与他的双曲性定理异曲同工。若干年后许多新的结果相继涌现,比如 McMullen 的工作。自此,复动力系统的研究提升到了一个更高的水平。
后 记
在 2011 年 Banff 举行的 Jack Milnor 的 80 岁寿宴上,我和 Bill 再次相遇。在 30 年之后,我们从之前研究中断的地方重新开始。(当我第二次见到他的绿色格子衬衫时,我称赞这件衣服,第二天他就把衣服送给了我。)我们还约定一起去攻克 Klein 群和复动力系统框架里遗留下来的一个大问题:不变线场猜想。这是一个好主意,不幸的是,它永远都不可能实现了。
Thurston 在 Banff 的会议上讲解多项式迭代与熵之间的联系。
在那次会议上,当 Jeremy Kahn 报告他和 Markovic 合作的对长达数十年之久的子曲面猜想作出的证明的时候,Bill 小声对我说:“我忘了取偏移这一步了。”在 Kahn-Markovic 的证明中,需要把所有可能的理想三角形粘起来,构造出浸入的曲面,然后把遍历理论应用到在这个空间的作用上。当两个理想三角形沿着一条边粘合时,各自的中心在粘合的边上的垂足也许并不吻合,而是可以差了一个偏移量。这一步偏移保证了取极限时不遗漏任何东西,这也正是 Bill 之前的证明里漏掉的。我带着极为愉快的心情看到 Kahn 和 Markovic 完成了证明。证明的每一步都让我回忆起 30 多年前 Bill 发明的类似关键思想与技术。这些思想与技术都传递到他在普林斯顿的门徒们那儿了。
同一次会议上 Kahn 讲解他与合作者的技术。
本文英文原文出自Notices of the A.M.S.,2015 年 11 期。中文翻译曾发表于杜晓明科学网博客,此文为最新修订版,原文题目为“沃尔夫奖得主Sullivan:菲尔茨奖得主Thurston的十个故事”,现标题为编者所加。原文链接:https://www.ams.org/journals/notice
























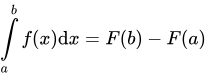





















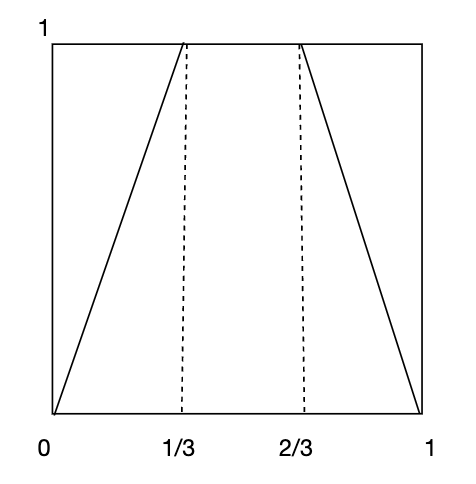
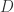 (例如单位正方形
(例如单位正方形 ![[0,1] \times [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) )。马蹄映射
)。马蹄映射  的作用是将这个矩形进行非线性拉伸和折叠,使其在水平方向上拉长,在垂直方向上压缩,并弯曲成“马蹄”形状。
的作用是将这个矩形进行非线性拉伸和折叠,使其在水平方向上拉长,在垂直方向上压缩,并弯曲成“马蹄”形状。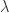 倍,
倍, )。
)。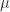 倍,
倍, )。
)。 则相当于反向操作,即垂直拉伸、水平压缩,并反向折叠。
则相当于反向操作,即垂直拉伸、水平压缩,并反向折叠。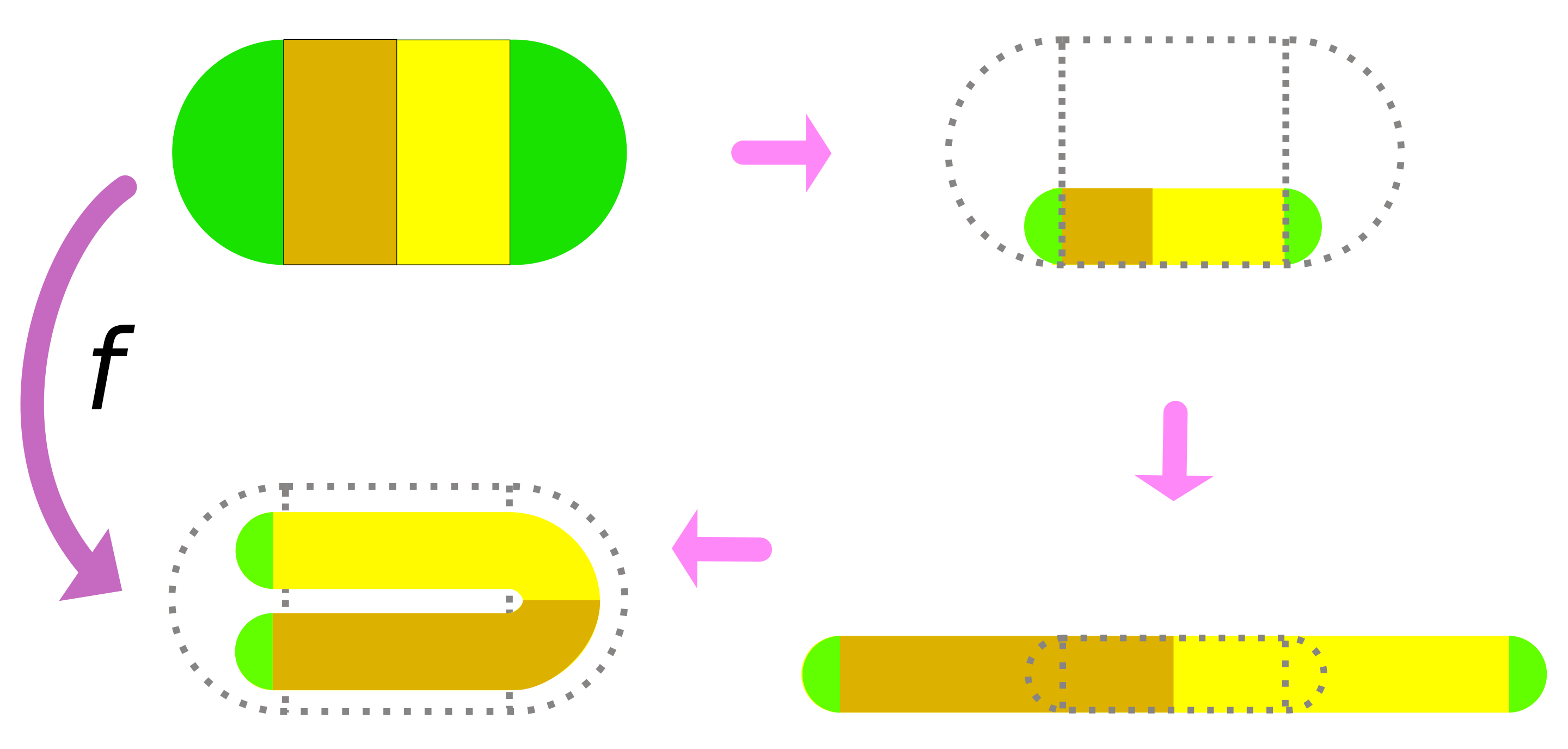
 。
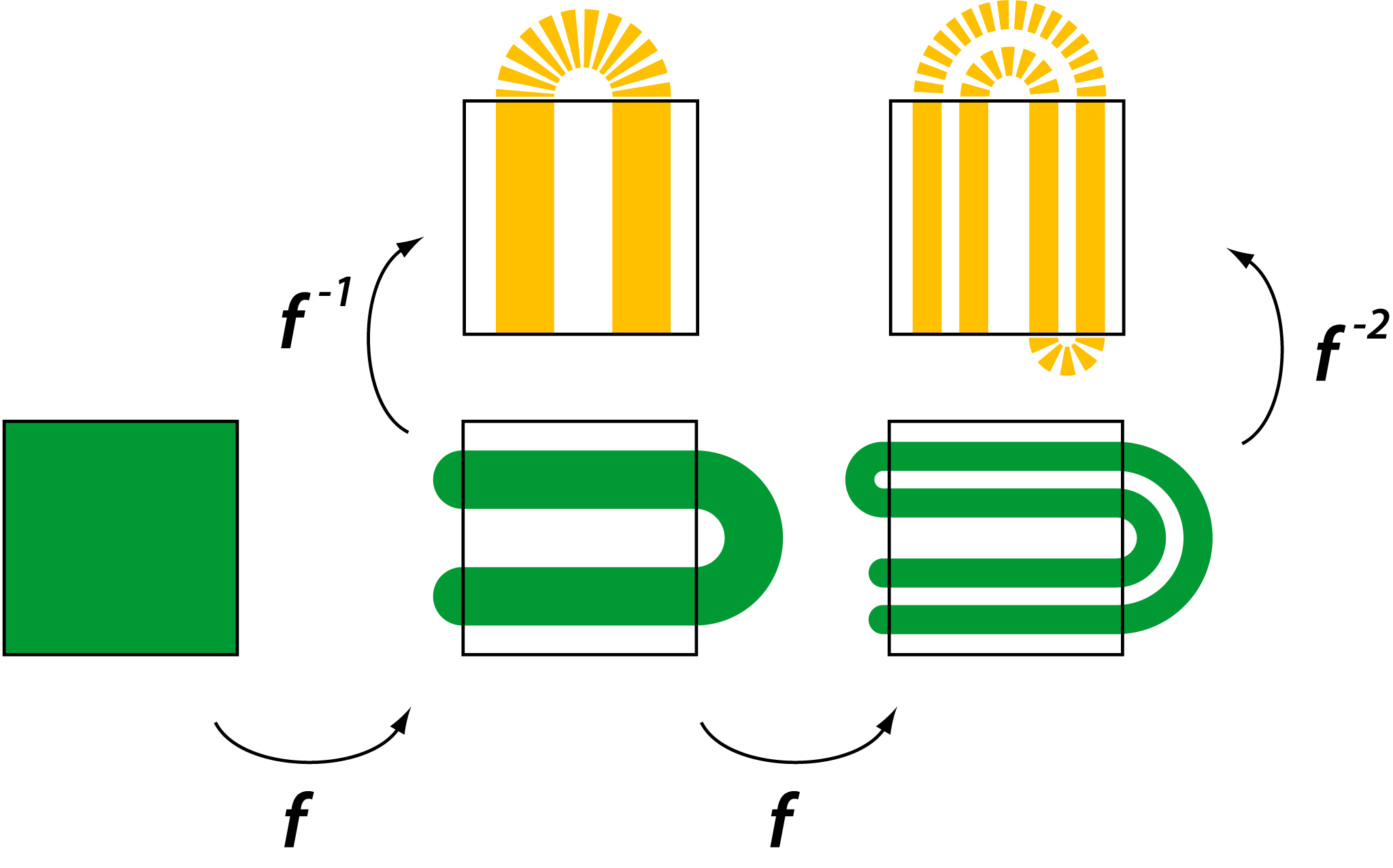
。 )表示,其中“0”和“1”分别代表点在每次迭代中落在左侧或右侧条带。这种对应关系表明,马蹄映射的动力学行为等价于伯努利移位(Bernoulli Shift),即一个无限符号序列的混沌系统。
)表示,其中“0”和“1”分别代表点在每次迭代中落在左侧或右侧条带。这种对应关系表明,马蹄映射的动力学行为等价于伯努利移位(Bernoulli Shift),即一个无限符号序列的混沌系统。




































 使得
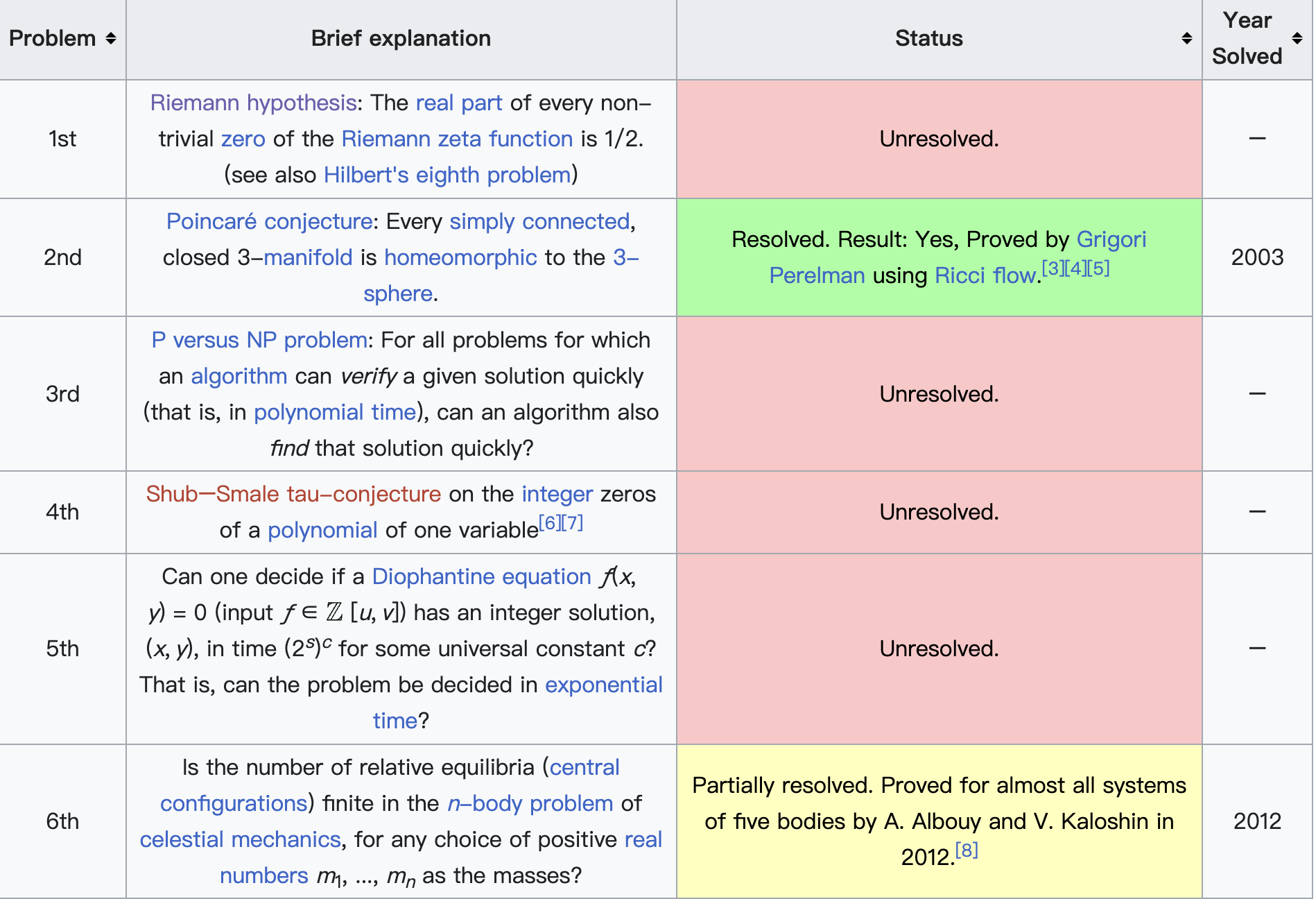
使得  这个区域内没有黎曼函数的零点,都是巨大的突破。
这个区域内没有黎曼函数的零点,都是巨大的突破。 ,于是提出猜想:
,于是提出猜想: (对数积分)。数学家勒让德(Adrien-Marie Legendre,1798)在《数论随笔》中提出经验公式:
(对数积分)。数学家勒让德(Adrien-Marie Legendre,1798)在《数论随笔》中提出经验公式: ,首次尝试用解析方法逼近素数分布。
,首次尝试用解析方法逼近素数分布。 使得:
使得:  具体值:
具体值: ,
, 。他使用的关键工具是切比雪夫函数
。他使用的关键工具是切比雪夫函数  ,并且证明
,并且证明  当且仅当
当且仅当  。
。 函数,并发表论文《论小于给定数值的素数个数》,定义:
函数,并发表论文《论小于给定数值的素数个数》,定义:  。解析延拓至复平面(除
。解析延拓至复平面(除  外全纯)。显式公式给出
外全纯)。显式公式给出  的精确表达式(含黎曼函数的零点):
的精确表达式(含黎曼函数的零点):  。
。 ,则素数定理误差最优。
,则素数定理误差最优。 (对
(对  ),并推出:
),并推出:  。具体的方法:
。具体的方法: 的欧拉乘积和非零性,证明
的欧拉乘积和非零性,证明  在
在  解析。
解析。
 。
。 。
。 模式。
模式。 推出 PNT。
推出 PNT。 无零点,而黎曼猜想要求
无零点,而黎曼猜想要求  。
。 上无零点的结论,直接等价于数论中的核心定理——素数定理(Prime Number Theorem)。根据刚刚的陈述,素数定理描述素数分布渐近行为:
上无零点的结论,直接等价于数论中的核心定理——素数定理(Prime Number Theorem)。根据刚刚的陈述,素数定理描述素数分布渐近行为:  或等价形式
或等价形式 其中:
其中: 的素数个数,
的素数个数, 对所有实数
对所有实数  在
在  表示为复积分:
表示为复积分: 

 )弱得多,但已足以推出素数分布的主项。
)弱得多,但已足以推出素数分布的主项。 ,但无零点条件仅给出
,但无零点条件仅给出  。
。 )中零点分布,有以下结论:
)中零点分布,有以下结论: )处有零点,这些零点称为平凡零点。
)处有零点,这些零点称为平凡零点。 ),且是
),且是  )内。
)内。 上。
上。 (
( 为正整数):除负偶数(平凡零点)外,
为正整数):除负偶数(平凡零点)外, 表明,若
表明,若  是零点,则
是零点,则  也是零点,但平凡零点仅在负偶数处。
也是零点,但平凡零点仅在负偶数处。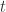 成立,这是素数定理证明的关键步骤。
成立,这是素数定理证明的关键步骤。 ,其中
,其中  是常数。
是常数。 :无零点(欧拉乘积收敛且非零)。
:无零点(欧拉乘积收敛且非零)。 ),但黎曼假设认为它们实际全部位于
),但黎曼假设认为它们实际全部位于  使得
使得 



 。
。 。
。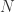 不被任何
不被任何  整除(因
整除(因  )。
)。

 时,有:
时,有:  表示渐近等价,即:
表示渐近等价,即:  。通过数值的计算,我们可以直接得到下面的计算结果。
。通过数值的计算,我们可以直接得到下面的计算结果。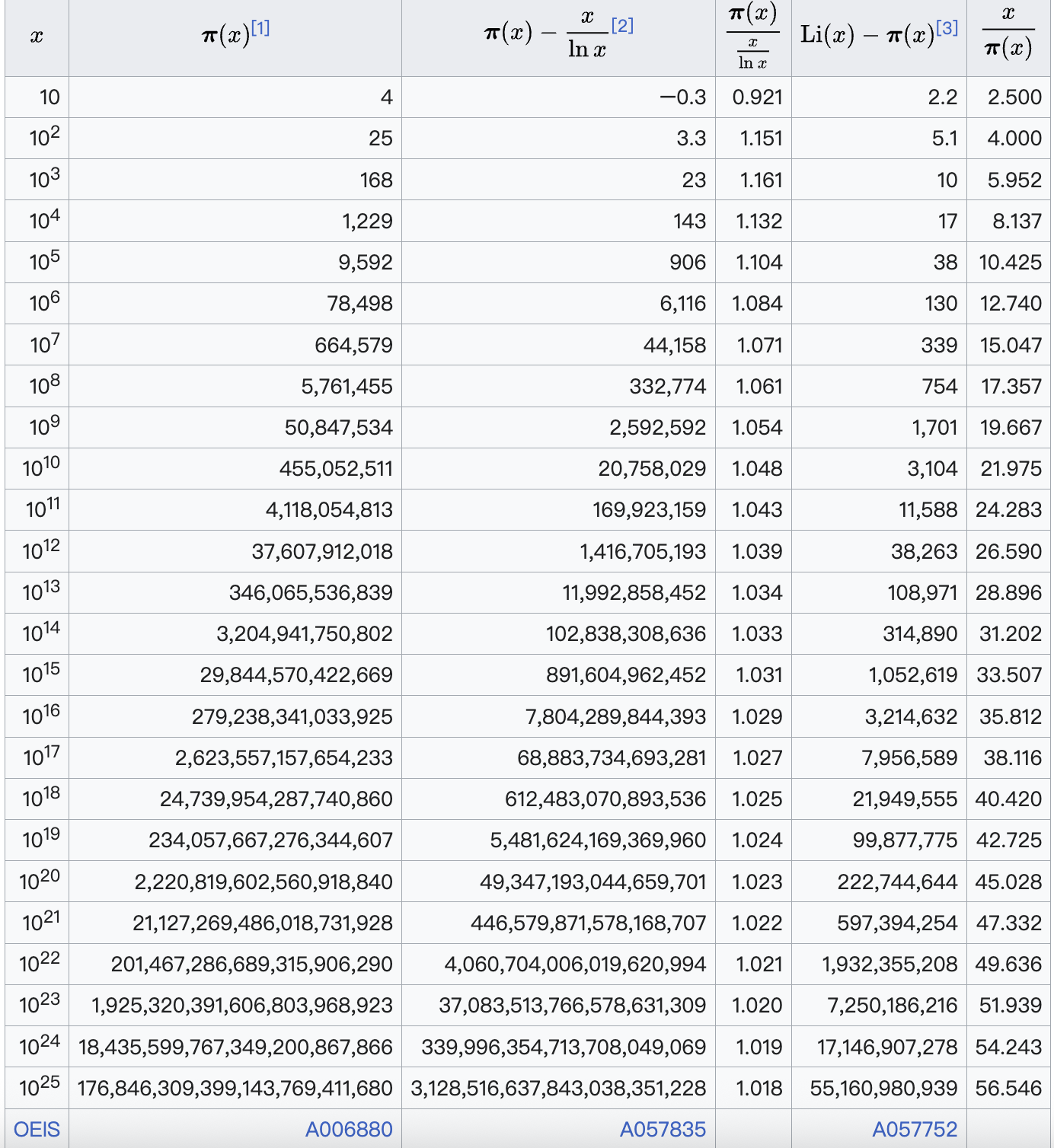
 ,其中
,其中  是对数积分函数,满足
是对数积分函数,满足  。
。 (对所有素数
(对所有素数  的
的  求和),则:
求和),则:  。定义
。定义  (其中
(其中  是冯·曼戈尔特函数,当
是冯·曼戈尔特函数,当  时
时  ,否则为 0),则:
,否则为 0),则: 
 时,
时, ,而
,而  ,比值约
,比值约  。
。 时,
时, ,
, ,比值约
,比值约  ,更接近 $ latex 1$。
,更接近 $ latex 1$。 的极限若存在必为
的极限若存在必为 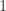 ,并给出上下界
,并给出上下界  。
。 。狄利克雷定理(算术级数中的素数分布)是素数定理在模
。狄利克雷定理(算术级数中的素数分布)是素数定理在模 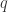 余
余  (
( )素数集上的推广。
)素数集上的推广。
 表示第 n 个素数,那么相邻素数的间距就是
表示第 n 个素数,那么相邻素数的间距就是  。当
。当  是正整数的时候,定义
是正整数的时候,定义  ,那么
,那么  就是孪生素数猜想。
就是孪生素数猜想。 ,存在无穷多对相邻素数,其差恰好为
,存在无穷多对相邻素数,其差恰好为  为所有孪生素数对
为所有孪生素数对  的集合,则其倒数和收敛:
的集合,则其倒数和收敛:  该级数的极限值称为 布鲁恩常数(Brun’s constant),记为
该级数的极限值称为 布鲁恩常数(Brun’s constant),记为  :
:  。
。 ),而孪生素数的倒数和收敛。这表明孪生素数比全体素数稀疏得多,即使孪生素数有无穷多对(孪生素数猜想尚未证明),其分布密度也足够低以保证倒数和有限。收敛性说明孪生素数的分布满足:
),而孪生素数的倒数和收敛。这表明孪生素数比全体素数稀疏得多,即使孪生素数有无穷多对(孪生素数猜想尚未证明),其分布密度也足够低以保证倒数和有限。收敛性说明孪生素数的分布满足:  , 即孪生素数的数量增长慢于
, 即孪生素数的数量增长慢于  (对比素数定理
(对比素数定理  的素数 p,p 既不整除 n,也不整除 n+2。则
的素数 p,p 既不整除 n,也不整除 n+2。则  。
。 ,其中 C为常数,具体推导利用容斥原理和不等式放缩(如切比雪夫边界)。
,其中 C为常数,具体推导利用容斥原理和不等式放缩(如切比雪夫边界)。 可得:
可得: 
 例如:当
例如:当 时,
时, ;当
;当 时,
时, 。针对收敛速度这个问题,因
。针对收敛速度这个问题,因  (
( 为孪生素数常数),级数收敛极慢,需极大
为孪生素数常数),级数收敛极慢,需极大 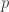 和
和  ,其差为2(即“k+1”)。在1966年,E. Bombieri与H. Davenport证明孪生素数密度上界:
,其差为2(即“k+1”)。在1966年,E. Bombieri与H. Davenport证明孪生素数密度上界: ,表明孪生素数分布稀疏,后人称之为Bombieri-Davenport上界。在1978年,中国数学家陈景润证明:存在无穷多对素数
,表明孪生素数分布稀疏,后人称之为Bombieri-Davenport上界。在1978年,中国数学家陈景润证明:存在无穷多对素数  ,其差不超过7000万(即
,其差不超过7000万(即  )。这一成果解决了弱哥德巴赫猜想的关键部分。
)。这一成果解决了弱哥德巴赫猜想的关键部分。 ,存在常数
,存在常数  ,使得无穷多对素数差不超过
,使得无穷多对素数差不超过  ,并探索广义孪生素数分布。
,并探索广义孪生素数分布。 )仍未完全证明,但246已是迄今最佳上界。
)仍未完全证明,但246已是迄今最佳上界。 ,即:
,即: 。
。 。
。 。
。 )。其结果长期未被超越,成为经典基准。
)。其结果长期未被超越,成为经典基准。 。
。 ,突破Rankin框架。
,突破Rankin框架。 (对应素数
(对应素数  )。上述渐进结果保证了间隔的无限增长,但具体数值依赖计算验证。素数大间距的发展历程体现了从初等证明到调和分析、组合数学的深度融合,尤其是2014年工作融合了多重数学工具,重塑了素数间隔的理论框架。
)。上述渐进结果保证了间隔的无限增长,但具体数值依赖计算验证。素数大间距的发展历程体现了从初等证明到调和分析、组合数学的深度融合,尤其是2014年工作融合了多重数学工具,重塑了素数间隔的理论框架。