
提到时间序列,大家能够想到的就是一串按时间排序的数据,但是在这串数字背后有着它特殊的含义,那么如何进行时间序列的表示(Representation),如何进行时间序列的信息提取(Information Extraction)就成为了时间序列研究的关键问题。
就笔者的个人经验而言,其实时间序列的一些想法和文本挖掘是非常类似的。通常来说句子都是由各种各样的词语组成的,并且一般情况下都是“主谓宾”的句子结构。于是就有人希望把词语用一个数学上的向量描述出来,那么最经典的做法就是使用 one – hot 的编码格式。i.e. 也就是对字典里面的每一个词语进行编码,一个词语对应着一个唯一的数字,例如 0,1,2 这种形式。one hot 的编码格式是这行向量的长度是词典中词语的个数,只有一个值是1,其余的取值是0,也就是 (0,…,0,1,0,…,0) 这种样子。但是在一般情况下,词语的个数都是非常多的,如何使用一个维度较小的向量来表示一个词语就成为了一个关键的问题。几年前,GOOGLE 公司开源了 Word2vec 开源框架,把每一个词语用一串向量来进行描述,向量的长度可以自行调整,大约是100~1000 不等,就把原始的 one-hot 编码转换为了一个低维空间的向量。在这种情况下,机器学习的很多经典算法,包括分类,回归,聚类等都可以在文本上得到巨大的使用。Word2vec 是采用神经网络的思想来提取每个词语与周边词语的关系,从而把每个词语用一个低维向量来表示。在这里,时间序列的特征提取方法与 word2vec 略有不同,后面会一一展示这些技巧。
时间序列的统计特征
提到时间序列的统计特征,一般都能够想到最大值(max),最小值(min),均值(mean),中位数(median),方差(variance),标准差(standard variance)等指标,不过一般的统计书上还会介绍两个指标,那就是偏度(skewness)和峰度(kuriosis)。如果使用时间序列 



![\text{skewness}(X) = E[(\frac{X-\mu}{\sigma})^{3}]=\frac{1}{T}\sum_{i=1}^{T}\frac{(x_{i}-\mu)^{3}}{\sigma^{3}},](https://s0.wp.com/latex.php?latex=%5Ctext%7Bskewness%7D%28X%29+%3D+E%5B%28%5Cfrac%7BX-%5Cmu%7D%7B%5Csigma%7D%29%5E%7B3%7D%5D%3D%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bi%3D1%7D%5E%7BT%7D%5Cfrac%7B%28x_%7Bi%7D-%5Cmu%29%5E%7B3%7D%7D%7B%5Csigma%5E%7B3%7D%7D%2C&bg=ffffff&fg=2b2b2b&s=1&c=20201002)
![\text{kurtosis}(X) = E[(\frac{X-\mu}{\sigma})^{4}]=\frac{1}{T}\sum_{i=1}^{T}\frac{(x_{i}-\mu)^{4}}{\sigma^{4}} .](https://s0.wp.com/latex.php?latex=%5Ctext%7Bkurtosis%7D%28X%29+%3D+E%5B%28%5Cfrac%7BX-%5Cmu%7D%7B%5Csigma%7D%29%5E%7B4%7D%5D%3D%5Cfrac%7B1%7D%7BT%7D%5Csum_%7Bi%3D1%7D%5E%7BT%7D%5Cfrac%7B%28x_%7Bi%7D-%5Cmu%29%5E%7B4%7D%7D%7B%5Csigma%5E%7B4%7D%7D+.&bg=ffffff&fg=2b2b2b&s=1&c=20201002)
其中 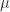
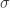
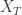
时间序列的熵特征
为什么要研究时间序列的熵呢?请看下面两个时间序列:
时间序列(1):(1,2,1,2,1,2,1,2,1,2,…)
时间序列(2):(1,1,2,1,2,2,2,2,1,1,…)
在时间序列(1)中,1 和 2 是交替出现的,而在时间序列(2)中,1 和 2 是随机出现的。在这种情况下,时间序列(1)则更加确定,时间序列(2)则更加随机。并且在这种情况下,两个时间序列的统计特征,例如均值,方差,中位数等等则是几乎一致的,说明用之前的统计特征并不足以精准的区分这两种时间序列。
通常来说,要想描述一种确定性与不确定性,熵(entropy)是一种不错的指标。对于离散空间而言,一个系统的熵(entropy)可以这样来表示:

如果一个系统的熵(entropy)越大,说明这个系统就越混乱;如果一个系统的熵越小,那么说明这个系统就更加确定。
提到时间序列的熵特征,一般来说有几个经典的例子,那就是 binned entropy,approximate entropy,sample entropy。下面来一一介绍时间序列中这几个经典的熵。
Binned Entropy
从熵的定义出发,可以考虑把时间序列 ![[\min(X_{T}), \max(X_{T})]](https://s0.wp.com/latex.php?latex=%5B%5Cmin%28X_%7BT%7D%29%2C+%5Cmax%28X_%7BT%7D%29%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

其中 

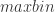

如果一个时间序列的 Binned Entropy 较大,说明这一段时间序列的取值是较为均匀的分布在
Approximate Entropy
回到本节的问题,如何判断一个时间序列是否具备某种趋势还是随机出现呢?这就需要介绍 Approximate Entropy 的概念了,Approximate Entropy 的思想就是把一维空间的时间序列提升到高维空间中,通过高维空间的向量之间的距离或者相似度的判断,来推导出一维空间的时间序列是否存在某种趋势或者确定性。那么,我们现在可以假设时间序列 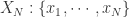
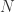


Step 1. 固定两个参数,正整数
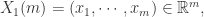
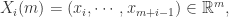

Step 2. 通过新的向量 


在这里,距离 


Step 3. 考虑函数

Step 4. Approximate Entropy 可以定义为:

Remark.
- 正整数
会基于具体的时间序列具体调整;
- 如果某条时间序列具有很多重复的片段(repetitive pattern)或者自相似性(self-similarity pattern),那么它的 Approximate Entropy 就会相对小;反之,如果某条时间序列几乎是随机出现的,那么它的 Approximate Entropy 就会相对较大。
Sample Entropy
除了 Approximate Entropy,还有另外一个熵的指标可以衡量时间序列,那就是 Sample Entropy,通过自然对数的计算来表示时间序列是否具备某种自相似性。
按照以上 Approximate Entropy 的定义,可以基于 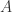
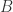

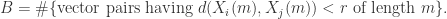
其中,

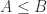

Remark.
- Sample Entropy 总是非负数;
- Sample Entropy 越小表示该时间序列具有越强的自相似性(self similarity)。
- 通常来说,在 Sample Entropy 的参数选择中,可以选择
.
时间序列的分段特征
即使时间序列有一定的自相似性(self-similarity),能否说明这两条时间序列就完全相似呢?其实答案是否定的,例如:两个长度都是 1000 的时间序列,
时间序列(1): [1,2] * 500
时间序列(2): [1,2,3,4,5,6,7,8,9,10] * 100
其中,时间序列(1)是 1 和 2 循环的,时间序列(2)是 1~10 这样循环的,它们从图像上看完全是不一样的曲线,并且它们的 Approximate Entropy 和 Sample Entropy 都是非常小的。那么问题来了,有没有办法提炼出信息,从而表示它们的不同点呢?答案是肯定的。
首先,我们可以回顾一下 Riemann 积分和 Lebesgue 积分的定义和不同之处。按照下面两幅图所示,Riemann 积分是为了算曲线下面所围成的面积,因此把横轴划分成一个又一个的小区间,按照长方形累加的算法来计算面积。而 Lebesgue 积分的算法恰好相反,它是把纵轴切分成一个又一个的小区间,然后也是按照长方形累加的算法来计算面积。
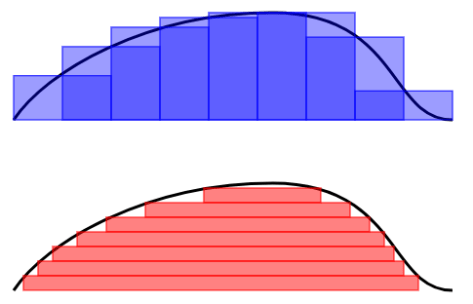
之前的 Binned Entropy 方案是根据值域来进行切分的,好比 Lebesgue 积分的计算方法。现在我们可以按照 Riemann 积分的计算方法来表示一个时间序列的特征,于是就有学者把时间序列按照横轴切分成很多段,每一段使用某个简单函数(线性函数等)来表示,于是就有了以下的方法:
- 分段线性逼近(Piecewise Linear Approximation)
- 分段聚合逼近(Piecewise Aggregate Approximation)
- 分段常数逼近(Piecewise Constant Approximation)
说到这几种算法,其实最本质的思想就是进行数据降维的工作,用少数的数据来进行原始时间序列的表示(Representation)。用数学化的语言来描述时间序列的数据降维(Data Reduction)就是:把原始的时间序列 
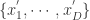
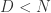
分段聚合逼近(Piecewise Aggregate Approximation)— 类似 Riemann 积分
在这种算法中,分段聚合逼近(Piecewise Aggregate Approximation)是一种非常经典的算法。假设原始的时间序列是 
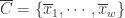
其中

在这里 
至于分段线性逼近(Piecewise Linear Approximation)和分段常数逼近(Piecewise Constant Approximation),只需要在 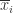
符号逼近(Symbolic Approximation)— 类似 Riemann 积分
在推荐系统的特征工程里面,特征通常来说可以做归一化,二值化,离散化等操作。例如,用户的年龄特征,一般不会直接使用具体的年月日,而是划分为某个区间段,例如 0~6(婴幼儿时期),7~12(小学),13~17(中学),18~22(大学)等阶段。
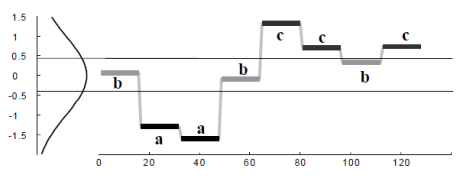
其实在得到分段特征之后,分段特征在某种程度上来说依旧是某些连续值,能否把连续值划分为一些离散的值呢?于是就有学者使用一些符号来表示时间序列的关键特征,也就是所谓的符号表示法(Symbolic Representation)。下面来介绍经典的 SAX Representation。
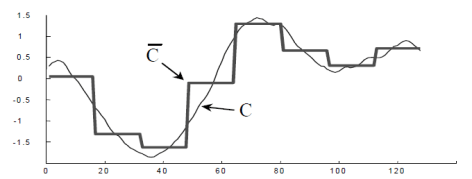
如果我们希望使用 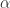



SAX 方法的流程如下:
Step 1. 正规化(normalization):也就是该时间序列被映射到均值为零,方差为一的区间内。
Step 2. 分段表示(PAA):
Step 3. 符号表示(SAX):如果 



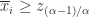
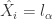
于是,我们就可以用
 、
、
总结
在本篇文章中,我们介绍了时间序列的一些表示方法(Representation),其中包括时间序列统计特征,时间序列的熵特征,时间序列的分段特征。在下一篇文章中,我们将会介绍时间序列的相似度计算方法。

very impressive!
LikeLike