现在做在线学习和 CTR 常常会用到逻辑回归( Logistic Regression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据流,美国的 Google 公司先后三年时间(2010年-2013年)从理论研究到实际工程化实现的 FTRL(Follow-the-regularized-Leader)算法,在处理诸如逻辑回归之类的带非光滑正则化项(例如 L1 范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色。
通常,优化算法中的 gradient descent 等解法,是对一批样本进行一次求解,得到一个全局最优解。但是,实际的互联网广告应用需要的是快速地进行模型的更新。为了保证快速的更新,训练样本是一条一条地过来的,每来一个样本,模型的参数对这个样本进行一次迭代,从而保证了模型的及时更新,这种方法叫做在线梯度下降法(Online gradient descent)。
在应用的时候,线上来的每一个广告请求,都提取出相应的特征,再根据模型的参数,计算一个点击某广告的概率。在线学习的任务就是学习模型的参数。所谓的模型的参数,其实可以认为是一个目标函数的解。跟之前说的根据批量的样本计算一个全局最优解的方法的不同是,解这个问题只能扫描一次样本,而且样本是一条一条地过来的。
当然这会有误差,所以为了避免这种误差,又为了增加稀疏性,有人又想到了多个版本的算法,Google 公司有人总结了其中几种比较优秀的,例如 FOBOS,AOGD 和微软的 RDA,同时提出了Google自己的算法 FTRL-Proximal。其中,FTRL-Proximal 在稀疏性和精确度等方面表现都比较好。
问题描述(最小化目标函数)
等价条件:
(1)约束优化(convex constraint formulation):
 subject to
subject to 
(2)无约束优化描述(soft regularization formulation):

注:当选择合适的常数 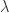 时,这两种描述是等价的。
时,这两种描述是等价的。
损失函数:
Linear Regression:

Logistic Regression:

传统算法(Gradient Descent)
Batch Gradient Descent: Repeat Until Convergence
{  }
}
这里的 Gradient Descent 是一种批量处理的方式(Batch),每次更新 W 的时候都需要扫描所有样本来计算一个全局梯度 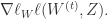
传统算法(Stochastic Gradient Descent)
Stochastic Gradient Descent 是另外一种权重更新方法:
Loop{
for j=1 to M { 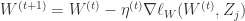 }
}
}
这里每次迭代仅仅根据单个样本更新权重 W,这种算法称为随机梯度下降法(Stochastic Gradient Descent)。
Truncated Gradient 算法简介
为了得到稀疏的特征权重 W,最简单粗暴的方式就是设定一个阈值,当 W 的某维度上系数小于这个阈值时将其设置为 0(称作简单截断)。这种方法实现起来很简单,也容易理解。但实际中(尤其在OGD里面)W 的某个系数比较小可能是因为该维度训练不足引起的,简单进行截断会造成这部分特征的丢失。
截断梯度法(TG, Truncated Gradient)是由John Langford,Lihong Li 和 Tong Zhang 在2009年提出,实际上是对简单截断的一种改进。下面首先描述一下 L1 正则化和简单截断的方法,然后我们再来看TG对简单截断的改进以及这三种方法在特定条件下的转化。
(1)L1 正则化法
由于 L1 正则项在 0 处不可导,往往会造成平滑的凸优化问题变成非平滑凸优化问题,因此在每次迭代中采用次梯度计算 L1 正则项的梯度。权重更新方式为:

注意,这里  是一个标量,且
是一个标量,且  ,为 L1 正则化参数。
,为 L1 正则化参数。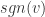 是符号函数,如果
是符号函数,如果  是一个向量,那么
是一个向量,那么  。
。 是学习率,通常假设为
是学习率,通常假设为  的函数。
的函数。 代表了第 t 次迭代中损失函数的梯度,由于 OGD 每次仅根据观测到的一个样本进行权重更新,因此也不再使用区分样本的下标 j。
代表了第 t 次迭代中损失函数的梯度,由于 OGD 每次仅根据观测到的一个样本进行权重更新,因此也不再使用区分样本的下标 j。
(2)简单截断法
以 k 为窗口,当 t/k 不为整数时采用标准的SGD进行迭代,当 t/k 为整数时,采用如下权重更新方式:这里的  是分段函数,
是分段函数,



这里  并且
并且  。如果 是一个向量,那么
。如果 是一个向量,那么  。
。
(3)截断梯度法(Truncated Gradient)
上面的简单截断法看上去十分 aggressive,因此截断梯度法在此基础上进行了改进工作。

这里的方程 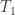 定义为:
定义为:
![T_{1}(v_{i},\alpha,\theta)=\max(0,v_{i}-\alpha) \text{ if } v_{i}\in [0,\theta]](https://s0.wp.com/latex.php?latex=T_%7B1%7D%28v_%7Bi%7D%2C%5Calpha%2C%5Ctheta%29%3D%5Cmax%280%2Cv_%7Bi%7D-%5Calpha%29+%5Ctext%7B+if+%7D+v_%7Bi%7D%5Cin+%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


其中  ,并且
,并且 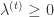 。Truncated Gradient 方法同样是以 k 作为窗口,每进行 k 步就进行一次截断操作。当 t/k 不是整数时,
。Truncated Gradient 方法同样是以 k 作为窗口,每进行 k 步就进行一次截断操作。当 t/k 不是整数时, ,当 t/k 是整数时,
,当 t/k 是整数时, 。从上面的公式可以看出,
。从上面的公式可以看出,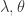 决定了 W 的稀疏程度,如果 和
决定了 W 的稀疏程度,如果 和 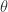 都很大,那么稀疏性就会越强。特别的,当
都很大,那么稀疏性就会越强。特别的,当  时,此时只需要控制一个参数就可以控制稀疏性。
时,此时只需要控制一个参数就可以控制稀疏性。
Truncated Gradient 的算法:
输入 ,初始化  for t = 1,2,3,... 计算
for t = 1,2,3,... 计算  按照下面规则更新 W,
(i)当 t/k 不是整数时,采用标准的 SGD (Stochastic Gradient Descent) 进行迭代。,并且
按照下面规则更新 W,
(i)当 t/k 不是整数时,采用标准的 SGD (Stochastic Gradient Descent) 进行迭代。,并且  for all
for all 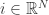 .
(ii)当 t/k 是整数时,采取截断技术。
.
(ii)当 t/k 是整数时,采取截断技术。
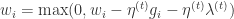 , if
, if ![(w_{i}-\eta^{(t)}g_{i})\in[0,\theta]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
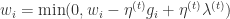 , else if
, else if ![(w_{i}-\eta^{(t)}g_{i})\in[-\theta,0]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B-%5Ctheta%2C0%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 , otherwise
return W.
, otherwise
return W.
(4)Truncated Gradient,简单截断法,L1 正则化之间的关系。
简单截断法和截断梯度法的区别在于选择了不同的截断公式  和 。如下图所示:
和 。如下图所示:
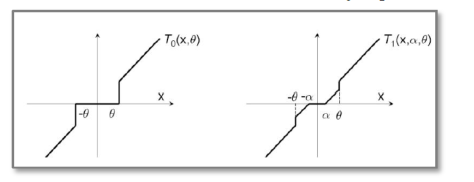
Truncated Gradient -> 简单截断法
从上图可以直接看出:选择  ,截断梯度法就可以变成简单截断法。从公式上也可以通过计算直接得出。
,截断梯度法就可以变成简单截断法。从公式上也可以通过计算直接得出。
Truncated Gradient -> L1 正则化
貌似有一点问题,需要重新推导。

 ,这里
,这里 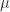 是这个特征的均值,
是这个特征的均值,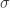 是这个特征的方差。这里的归一化的关键之处在于数据的变化(Data Transforming)。对于处理一些大尺度数据(比方说某个视频被所有用户观看的次数之类的),一般会使用对数来处理数据,或者双曲线函数。例如:
是这个特征的方差。这里的归一化的关键之处在于数据的变化(Data Transforming)。对于处理一些大尺度数据(比方说某个视频被所有用户观看的次数之类的),一般会使用对数来处理数据,或者双曲线函数。例如:

![\rho_{XY}=cov(X,Y)/(\sigma_{X}\sigma_{Y})\in [-1,1]](https://s0.wp.com/latex.php?latex=%5Crho_%7BXY%7D%3Dcov%28X%2CY%29%2F%28%5Csigma_%7BX%7D%5Csigma_%7BY%7D%29%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 ,那么说明两个变量是线性反相关的;如果
,那么说明两个变量是线性反相关的;如果  ,那么说明两个变量是线性相关的。不过需要主要的是,即使
,那么说明两个变量是线性相关的。不过需要主要的是,即使  ,也只是说明两个变量是线性无关的,并不能推出它们之间是独立的。此时知道的就是一个线性分类器并不能把这个特征的正负样本分开,需要把该特征和其他特征交叉或者做其余的特征运算,形成一个或者多个新的特征,让这些新的特征发挥新的价值,做好进一步的分类工作。
,也只是说明两个变量是线性无关的,并不能推出它们之间是独立的。此时知道的就是一个线性分类器并不能把这个特征的正负样本分开,需要把该特征和其他特征交叉或者做其余的特征运算,形成一个或者多个新的特征,让这些新的特征发挥新的价值,做好进一步的分类工作。



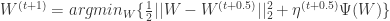

 ,如果
,如果  存在一个最优解,那么可以推断 0 向量一定属于
存在一个最优解,那么可以推断 0 向量一定属于  的次梯度集合:
的次梯度集合: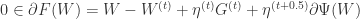 .
.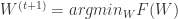 , 那么可以得到权重更新的另外一种形式:
, 那么可以得到权重更新的另外一种形式: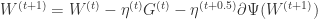
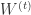 有关,还和自己
有关,还和自己 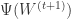 有关。这也许就是”前向后向切分”这个名称的由来。
有关。这也许就是”前向后向切分”这个名称的由来。 是 L1 范数,中间向量是
是 L1 范数,中间向量是  , 并且参数
, 并且参数 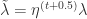 ,那么公式就可以展开得到
,那么公式就可以展开得到
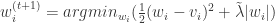 for all $latex 1\leq i \leq N$.
for all $latex 1\leq i \leq N$. 是
是  的最优解,那么
的最优解,那么  .
. ,那么
,那么  , 这与条件矛盾。
, 这与条件矛盾。
 for all
for all 
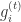 是梯度
是梯度 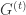 在第 i 个维度的分量。
在第 i 个维度的分量。 , 则有
, 则有  意思就是如果这次训练产生梯度的变化不足以令权重值发生足够大的变化时,就认为在这次训练中该维度不够重要,应该强制其权重是0.
意思就是如果这次训练产生梯度的变化不足以令权重值发生足够大的变化时,就认为在这次训练中该维度不够重要,应该强制其权重是0. ,那么则有
,那么则有
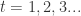 , 计算
, 计算  ,
, for all
for all  (3)Return W
(3)Return W ,可以得到 L1-FOBOS 与 Truncated Gradient 完全一致,换句话说 L1-FOBOS 是 Truncated Gradient 在一些特定条件下的形式。
,可以得到 L1-FOBOS 与 Truncated Gradient 完全一致,换句话说 L1-FOBOS 是 Truncated Gradient 在一些特定条件下的形式。
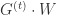 指的是向量
指的是向量  是一个严格凸函数,
是一个严格凸函数, 是一个非负递增序列。
是一个非负递增序列。 包括了之前所有梯度的平均值。
包括了之前所有梯度的平均值。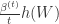 。
。 ;
; ,i.e.
,i.e.  是一个非负递增序列。那么 RDA 算法就可以写成:
是一个非负递增序列。那么 RDA 算法就可以写成:



 if
if 
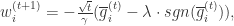 otherwise
otherwise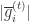 小于
小于  ,初始化
,初始化  (2)for
(2)for  更新
更新 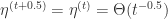 ,可以得到:
,可以得到: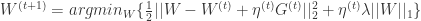

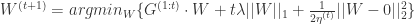
 。如果令
。如果令 

 上面的公式可以写成:
上面的公式可以写成:

