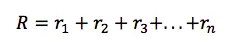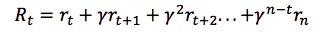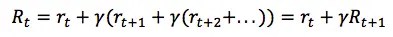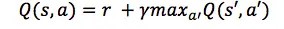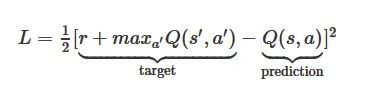文/Not_GOD(简书作者)
原文链接:http://www.jianshu.com/p/d347bb2ca53c
著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”。
Two years ago, a small company in London called DeepMind uploaded their pioneering paper “Playing Atari with Deep Reinforcement Learning” to Arxiv. In this paper they demonstrated how a computer learned to play Atari 2600 video games by observing just the screen pixels and receiving a reward when the game score increased. The result was remarkable, because the games and the goals in every game were very different and designed to be challenging for humans. The same model architecture, without any change, was used to learn seven different games, and in three of them the algorithm performed even better than a human!
It has been hailed since then as the first step towards general artificial intelligence – an AI that can survive in a variety of environments, instead of being confined to strict realms such as playing chess. No wonder DeepMind was immediately bought by Google and has been on the forefront of deep learning research ever since. In February 2015 their paper “Human-level control through deep reinforcement learning” was featured on the cover of Nature, one of the most prestigious journals in science. In this paper they applied the same model to 49 different games and achieved superhuman performance in half of them.
Still, while deep models for supervised and unsupervised learning have seen widespread adoption in the community, deep reinforcement learning has remained a bit of a mystery. In this blog post I will be trying to demystify this technique and understand the rationale behind it. The intended audience is someone who already has background in machine learning and possibly in neural networks, but hasn’t had time to delve into reinforcement learning yet.
我们按照下面的几个问题来看看到底深度强化学习技术长成什么样?
- 什么是强化学习的主要挑战?针对这个问题,我们会讨论 credit assignment 问题和 exploration-exploitation 困境。
- 如何使用数学来形式化强化学习?我们会定义 Markov Decision Process 并用它来对强化学习进行分析推理。
- 我们如何指定长期的策略?这里,定义了 discounted future reward,这也给出了在下面部分的算法的基础。
- 如何估计或者近似未来收益?给出了简单的基于表的 Q-learning 算法的定义和分析。
- 如果状态空间非常巨大该怎么办?这里的 Q-table 就可以使用(深度)神经网络来替代。
- 怎么样将这个模型真正可行?采用 Experience replay 技术来稳定神经网络的学习。
- 这已经足够了么?最后会研究一些对 exploration-exploitation 问题的简单解决方案。
强化学习
Consider the game Breakout. In this game you control a paddle at the bottom of the screen and have to bounce the ball back to clear all the bricks in the upper half of the screen. Each time you hit a brick, it disappears and your score increases – you get a reward.

图 1:Atari Breakout 游戏:来自 DeepMind
Suppose you want to teach a neural network to play this game. Input to your network would be screen images, and output would be three actions: left, right or fire (to launch the ball). It would make sense to treat it as a classification problem – for each game screen you have to decide, whether you should move left, right or press fire. Sounds straightforward? Sure, but then you need training examples, and a lots of them. Of course you could go and record game sessions using expert players, but that’s not really how we learn. We don’t need somebody to tell us a million times which move to choose at each screen. We just need occasional feedback that we did the right thing and can then figure out everything else ourselves.
This is the task reinforcement learning tries to solve. Reinforcement learning lies somewhere in between supervised and unsupervised learning. Whereas in supervised learning one has a target label for each training example and in unsupervised learning one has no labels at all, in reinforcement learning one has sparse and time-delayed labels – the rewards. 基于这些收益,agent 必须学会在环境中如何行动。
尽管这个想法非常符合直觉,但是实际操作时却困难重重。例如,当你击中一个砖块,并得到收益时,这常常和最近做出的行动(paddle 的移动)没有关系。在你将 paddle 移动到了正确的位置时就可以将球弹回,其实所有的困难的工作已经完成。这个问题被称作是 credit assignment 问题——先前的行动会影响到当前的收益的获得与否及收益的总量。
一旦你想出来一个策略来收集一定数量的收益,你是要固定在当前的策略上还是尝试其他的策略来得到可能更好的策略呢?在上面的 Breakout 游戏中,简单的策略就是移动到最左边的等在那里。发出球球时,球更可能是向左飞去,这样你能够轻易地在死前获得 10 分。但是,你真的满足于做到这个程度么? 这就是 exploration-exploit 困境 ——你应当利用已有的策略还是去探索其他的可能更好的策略。
强化学习是关于人类(或者更一般的动物)学习的重要模型。我们受到来自父母、分数、薪水的奖赏都是收益的各类例子。credit assignment 问题 和 exploration-exploitation 困境 在商业和人际关系中常常出现。这也是研究强化学习及那些提供尝试新的观点的沙盒的博弈游戏的重要原因。
Markov Decision Process
现在的问题就是,如何来形式化这个强化学习问题使得我们可以对其进行分析推理。目前最常见的就是将其表示成一个 Markov decision process。
假设你是一个 agent,在一个环境中(比如说 Breakout 游戏)。环境会处在某个状态下(比如说,paddle 的位置、球的位置和方向、每个砖块是否存在等等)。agent 可以在环境中执行某种行动(比如说,将 paddle 向左或者向右移动)。这些行动有时候会带来收益(比如说分数的增加)。行动会改变环境并使其新的状态,然后 agent 又可以这行另外的行动,如此进行下去。如何选择这些行动的规则称为策略。一般来说环境是随机的,这意味着下一个状态的出现在某种程度上是随机的(例如,你输了一个球的时候,重新启动新球,这个时候的射出方向是随机选定的)。
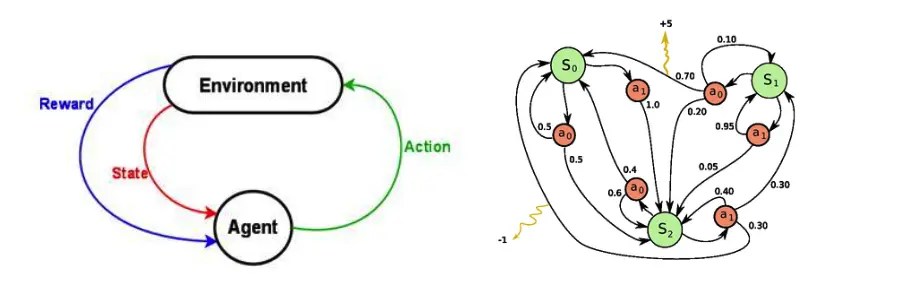
图 2:左:强化学习问题。右:Markov decision process
状态和行动的集合,以及从一个状态跳转到另一个状态的规则,共同真诚了 Markov decision process。这个过程(比方说一次游戏过程)的一个 episode 形成了一个有限的状态、行动和收益的序列:
这里的 s_i 表示状态,a_i 表示行动,而 r_{i+1} 是在执行行动的汇报。episode 以 terminal 状态 s_n 结尾(可能就是“游戏结束”画面)。MDP 依赖于 Markov 假设——下一个状态 s_{i+1} 的概率仅仅依赖于当前的状态 s_i 和行动 a_i,但不依赖此前的状态和行动。
Discounted Future Reward
To perform well in the long-term, we need to take into account not only the immediate rewards, but also the future rewards we are going to get. How should we go about that?
Given one run of the Markov decision process, we can easily calculate the total reward for one episode:
Given that, the total future reward from time point t onward can be expressed as:
But because our environment is stochastic, we can never be sure, if we will get the same rewards the next time we perform the same actions. The more into the future we go, the more it may diverge. For that reason it is common to use discounted future reward instead:
Here γ is the discount factor between 0 and 1 – the more into the future the reward is, the less we take it into consideration. It is easy to see, that discounted future reward at time step t can be expressed in terms of the same thing at time step t+1:
If we set the discount factor γ=0, then our strategy will be short-sighted and we rely only on the immediate rewards. If we want to balance between immediate and future rewards, we should set discount factor to something like γ=0.9. If our environment is deterministic and the same actions always result in same rewards, then we can set discount factor γ=1.
A good strategy for an agent would be to always choose an action that maximizes the (discounted) future reward.
Q-learning
In Q-learning we define a function Q(s, a) representing the maximum discounted future reward when we perform action a in state s, and continue optimally from that point on.
**
**The way to think about Q(s, a) is that it is “the best possible score at the end of the game after performing action a in state s“. It is called Q-function, because it represents the “quality” of a certain action in a given state.
This may sound like quite a puzzling definition. How can we estimate the score at the end of game, if we know just the current state and action, and not the actions and rewards coming after that? We really can’t. But as a theoretical construct we can assume existence of such a function. Just close your eyes and repeat to yourself five times: “Q(s, a) exists, Q(s, a) exists, …”. Feel it?
If you’re still not convinced, then consider what the implications of having such a function would be. Suppose you are in state and pondering whether you should take action a or b. You want to select the action that results in the highest score at the end of game. Once you have the magical Q-function, the answer becomes really simple – pick the action with the highest Q-value!
Here π represents the policy, the rule how we choose an action in each state.
OK, how do we get that Q-function then? Let’s focus on just one transition <s, a, r, s’>. Just like with discounted future rewards in the previous section, we can express the Q-value of state s and action a in terms of the Q-value of the next state s’.
This is called the Bellman equation. If you think about it, it is quite logical – maximum future reward for this state and action is the immediate reward plus maximum future reward for the next state.
The main idea in Q-learning is that we can iteratively approximate the Q-function using the Bellman equation. In the simplest case the Q-function is implemented as a table, with states as rows and actions as columns. The gist of the Q-learning algorithm is as simple as the following[1]:
α in the algorithm is a learning rate that controls how much of the difference between previous Q-value and newly proposed Q-value is taken into account. In particular, when α=1, then two Q[s,a] cancel and the update is exactly the same as the Bellman equation.
The maxa’ Q[s’,a’] that we use to update Q[s,a] is only an approximation and in early stages of learning it may be completely wrong. However the approximation get more and more accurate with every iteration and it has been shown, that if we perform this update enough times, then the Q-function will converge and represent the true Q-value.
Deep Q Network
环境的状态可以用 paddle 的位置,球的位置和方向以及每个砖块是否消除来确定。不过这个直觉上的表示与游戏相关。我们能不能获得某种更加通用适合所有游戏的表示呢?最明显的选择就是屏幕像素——他们隐式地包含所有关于除了球的速度和方向外的游戏情形的相关信息。不过两个时间上相邻接的屏幕可以包含这两个丢失的信息。
如果我们像 DeepMind 的论文中那样处理游戏屏幕的话——获取四幅最后的屏幕画面,将他们重新规整为 84 X 84 的大小,转换为 256 灰度层级——我们会得到一个 256^{84X84X4} 大小的可能游戏状态。这意味着我们的 Q-table 中需要有 10^67970 行——这比已知的宇宙空间中的原子的数量还要大得多!可能有人会说,很多像素的组合(也就是状态)不会出现——这样其实可以使用一个稀疏的 table 来包含那些被访问到的状态。即使这样,很多的状态仍然是很少被访问到的,也许需要宇宙的生命这么长的时间让 Q-table 收敛。我们希望理想化的情形是有一个对那些还未遇见的状态的 Q-value 的猜测。
这里就是深度学习发挥作用的地方。神经网络其实对从高度结构化的数据中获取特征非常在行。我们可以用神经网络表示 Q-function,以状态(四幅屏幕画面)和行动作为输入,以对应的 Q-value 作为输出。另外,我们可以仅仅用游戏画面作为输入对每个可能的行动输出一个 Q-value。后面这个观点对于我们想要进行 Q-value 的更新或者选择最优的 Q-value 对应操作来说要更方便一些,这样我们仅仅需要进行一遍网络的前向传播就可立即得到所有行动的 Q-value。

图 3:左:DQN 的初级形式;右:DQN 的优化形式,用在 DeepMind 的论文中的版本
DeepMind 使用的深度神经网络架构如下:
这实际上是一个经典的卷积神经网络,包含 3 个卷积层加上 2 个全连接层。对图像识别的人们应该会注意到这里没有包含 pooling 层。但如果你好好想想这里的情况,你会明白,pooling 层会带来变换不变性 —— 网络会对图像中的对象的位置没有很强的感知。这个特性在诸如 ImageNet 这样的分类问题中会有用,但是在这里游戏的球的位置其实是潜在能够决定收益的关键因素,我们自然不希望失去这样的信息了!
网络的输入是 4 幅 84X84 的灰度屏幕画面。网络的输出是对每个可能的行动(在 Atari 中是 18 个)。Q-value 可能是任何实数,其实这是一个回归任务,我们可以通过简单的平方误差来进行优化。
给定转移 <s, a, r, s’>,Q-table 更新规则变动如下:
- 对当前的状态 s 执行前向传播,获得对所有行动的预测 Q-value
- 对下一状态 s’ 执行前向传播,计算网络输出最大操作:max_{a’} Q(s’, a’)
- 设置行动的 Q-value 目标值为 r + γ max_{a’} Q(s’, a’)。使用第二步的 max 值。对所有其他的行动,设置为和第一步返回结果相同的 Q-value 目标值,让这些输出的误差设置为 0
- 使用反向传播算法更新权重
Experience Replay
到现在,我们有了使用 Q-learning 如何估计未来回报和用卷积神经网络近似 Q-function 的方法。但是有个问题是,使用非线性函数来近似 Q-value 其实是非常不稳定的。对这个问题其实也有一堆技巧来让其收敛。不过这样也会花点时间,在单个 GPU 上估计要一个礼拜。
其中最为重要的技巧是 experience replay。在游戏过程中,所有的经验 <s, a, r’, s’> 都存放在一个 replay memory 中。训练网络时,replay memory 中随机的 minibatch 会取代最近的状态转移。这会将连续的训练样本之间的相似性打破,否则容易将网络导向一个局部最优点。同样 experience replay 让训练任务与通常的监督学习更加相似,这样也简化了程序的 debug 和算法的测试。当然我们实际上也是可以收集人类玩家的 experience 并用这些数据进行训练。
Exploration-Exploitation
Q-learning 试着解决 credit assignment 问题——将受益按时间传播,直到导致获得受益的实际的关键决策点为止。但是我们并没有解决 exploration-exploitation 困境……
首先我们注意到,当 Q-table 或者 Q-network 随机初始化时,其预测结果也是随机的。如果我们选择一个拥有最高的 Q-value 的行动,这个行动是随机的,这样 agent 会进行任性的“exploration”。当 Q-function 收敛时,它会返回一个更加一致的 Q-value 此时 exploration 的次数就下降了。所以我们可以说,Q-learning 将 exploration 引入了算法的一部分。但是这样的 exploration 是贪心的,它会采用找到的最有效的策略。
对上面问题的一个简单却有效的解决方案是 ε-greedy exploration——以概率ε选择一个随机行动,否则按照最高的 Q-value 进行贪心行动。在 DeepMind 的系统中,对ε本身根据时间进行的从 1 到 0.1 的下降,也就是说开始时系统完全进行随机的行动来最大化地 explore 状态空间,然后逐渐下降到一个固定的 exploration 的比例。
Deep Q-learning 算法
现在我们得到加入 experience replay的最终版本:
DeepMind 其实还使用了很多的技巧来让系统工作得更好——如 target network、error clipping、reward clipping 等等,这里我们不做介绍。
该算法最为有趣的一点就是它可以学习任何东西。你仔细想想——由于我们的 Q-function 是随机初始化的,刚开始给出的结果就完全是垃圾。然后我们就用这样的垃圾(下个状态的最高 Q-value)作为网络的目标,仅仅会偶然地引入微小的收益。这听起来非常疯狂,为什么它能够学习任何有意义的东西呢?然而,它确实如此神奇。
Final notes
Many improvements to deep Q-learning have been proposed since its first introduction – Double Q-learning, Prioritized Experience Replay, Dueling Network Architecture and extension to continuous action space to name a few. For latest advancements check out the NIPS 2015 deep reinforcement learning workshop and ICLR 2016 (search for “reinforcement” in title). But beware, that deep Q-learning has been patented by Google.
It is often said, that artificial intelligence is something we haven’t figured out yet. Once we know how it works, it doesn’t seem intelligent any more. But deep Q-networks still continue to amaze me. Watching them figure out a new game is like observing an animal in the wild – a rewarding experience by itself.
Credits
Thanks to Ardi Tampuu, Tanel Pärnamaa, Jaan Aru, Ilya Kuzovkin, Arjun Bansal and Urs Köster for comments and suggestions on the drafts of this post.
Links
David Silver’s lecture about deep reinforcement learning
Slightly awkward but accessible illustration of Q-learning
UC Berkley’s course on deep reinforcement learning
David Silver’s reinforcement learning course
Nando de Freitas’ course on machine learning (two lectures about reinforcement learning in the end)
Andrej Karpathy’s course on convolutional neural networks
[1] Algorithm adapted from http://artint.info/html/ArtInt_265.html
文/Not_GOD(简书作者)
原文链接:http://www.jianshu.com/p/d347bb2ca53c
著作权归作者所有,转载请联系作者获得授权,并标注“简书作者”。



")


")
")
")




")


 > 0")