
文章是:”Correlating Events with Time Series for Incident Diagnosis” 是微软在2014年的工作,并且发表在KDD上。
本文提出了一种无监督和统计判别的算法,可以检测出事件(E)与时间序列(S)的关联关系,并且可以检测出时间序列(S)的单调性(上升或者下降)。在这篇文章中,选择的事件有CPU(Memory, Disk)Intensive Program,Query Alert;选择的时间序列有 CPU(Memory)Usage,Disk Transfer Rate。时间序列的特点是它们的值域范围都是[0,1]。

案例是:时间序列是CPU的Usage,事件是Disk Intensive task和CPU intensive task。

关联关系的挖掘分成三个部分:
(1)是否存在关联性(Existence of Dependency):在事件(E)与时间序列(S)之间是否存在关联关系。
(2)关联关系的因果关系(Temporal Order of Dependency):是事件(E)导致了时间序列(S)的变化还是时间序列(S)导致了事件(E)的发生。
(3)关联关系的单调性影响(Monotonic Effect of Dependency):用于判断时间序列(S)是发生了突增或者是突降。
基本概念:
给定一个事件序列(E),事件发生的时间戳是
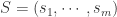



用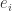


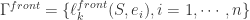
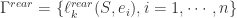
定义一:如果事件序列E和时间序列S是相关的,并且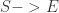
定义二:如果事件序列E和时间序列S是相关的,并且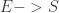
定义三:如果事件序列E和时间序列S是相关的,那么
定义四:如果



方法论:
第一步:最邻近算法(类似kNN)(Nearest Neighbor Method)
在计算时间序列之间距离的时候,使用DTW算法或者DTW-D算法会优于L1或者L2算法。
用
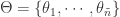

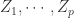



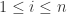



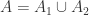


对于集合 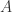





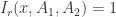


该方程
定义

在这里

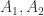
根据文献里面的观点,当p足够大的时候,
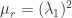
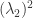



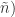
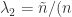
根据传统的Gauss分布Test方法,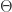
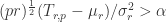




如果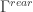
第二步:关联顺序的挖掘(Mining Existence and Temporal Order)
如果前面的子序列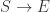
如果后面的子序列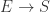
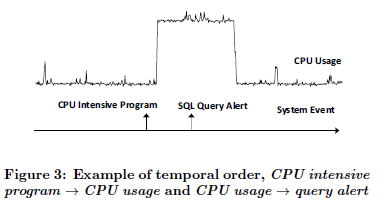
在Figure 3中,CPU Intensive Program 导致了 CPU Usage,并且 CPU Usage 导致了 SQL Query Alert。
第三步:单调性的影响类型(Mining Effect Type)
现在需要判断时间序列是突增还是突降了,需要引入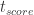
对于

那么,如果
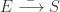

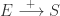
其中参数可以设置为:
算法综述:

其中,5,6行是为了计算相关性,

7-13行是
14-20行是
参数:
时间序列的长度 
最邻近的元素个数 
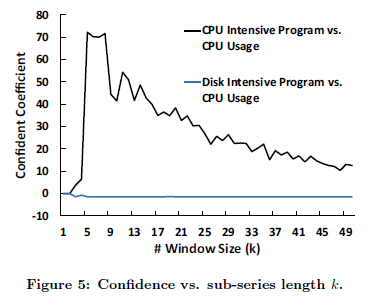

其他算法:
(1)Pearson Correlation
(2)J-Measure Correlation
