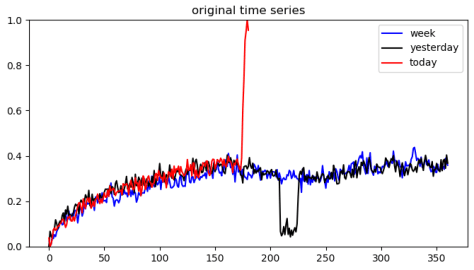
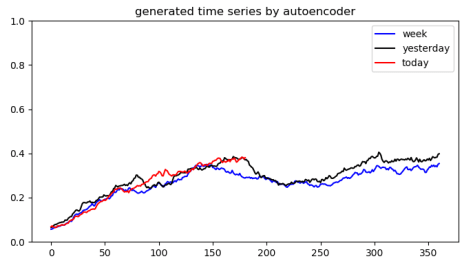
当年,曹操与刘备在汉中决战,两军久久僵持不下。曹操见久攻不下,心中烦闷,此时士兵来询问夜间的口令,曹操顺口说一句:“鸡肋。”而主簿杨修听到这句话,便开始收拾行装,并告诉周边的人一起收拾行装。众人不解,反问之,杨修解释道:“鸡肋鸡肋,食之无肉,弃之有味,今丞相进不能胜,恐人耻笑,明日必令退兵。”而杨修因为这句话而引来了杀身之祸。
熟读三国演义的人都知道,曹操杀了杨修之后,便令众军前进。其实到了最后,曹操也未能战胜刘备,获得汉中攻略战的胜利,只能退回许昌。虽然现在我们很难猜测曹操当时的想法是什么,不过“夫鸡肋,弃之如可惜,食之无所得”这句话却由于这个故事而流传下来。无论是当年的曹孟德,还是现在的很多平凡的普通人,身边总有一些事物与鸡肋一样,食之无味而弃之可惜。
在经济学中可以用沉没成本来描述鸡肋这个概念。沉没成本指的是已经付出了,但是不能收回的成本。例如,有一家电影院不允许顾客退票,有位顾客买了一张电影票,但是他看了半小时的电影之后觉得电影十分难看,这种时候他就有两种选择:
1. 继续看下去;
2. 中途离场,去做自己想做的事情。
其实绝大多数的人都会忍着看完这部难看的电影。而从经济学上的观点来看,如果人是足够理性的,当这个人在做决策的时候,是应该把沉没成本放在一边而不去考虑的,因为沉没成本是无法被改变的。按照上面的例子,无论他选择是否继续看下去,这个电影票的钱都已经无法退回,而此时需要做决定的事情是是否继续看完电影。通常这种情况下,按照经济学的理论来说,经济学家会建议这个人选择中途离场,去做任何自己想做的事情。因为这样的话他只是浪费了一张电影票的钱,但是省下来的时间却可以做其他更有趣的事情。

虽然这只是书本上的一个简单例子,但是这样的例子在生活中比比皆是。无论是对学生还是职场人士,无论是对普通人还是位高权重的决策者,都面临着沉没成本是否放弃的难题。对于学生而言,最常见的情况就是这个学生在大学期间学了四年根本不感兴趣的专业,但是在面临存在转专业的机会时,是否要放弃原有的技能而重新学习一个新的专业便成为了一个难题。对于在职人士而言,在面临一个有挑战但是并不熟悉的行业或者领域的时候,是否愿意放弃原有的一些经验,是否存在勇气进入一个新的领域也是一个难以抉择的问题。
沉没成本其实很影响一个人的决策。对于学生而言,如果在某个方向上花费了巨大的精力和时间,是很难下定决心转一个全新的方向的;对于工作后的人士而言,主动放弃已经拥有的一些经验,放弃已经掌握的一些人脉和资源,也是十分困难的。但是,在人生的十字路口,其实又必须要下定决心做一些事情。众所周知,学校里面的不少专业其实就是“鸡肋”,完全符合“食之无味,弃之可惜”的条件,无论是学生的就业率和成材率都处于所有专业的底部。如果这些专业的学生不放弃自己的专业,将会在这些专业里面越陷越深,最终无法自拔。其实,这些专业的学生继续从事该专业的学习都不能称之为“坚持”,而是在“死扛”,用自己的大好前途来耗费在一些没有任何用处的专业技能上。有的技能虽然看上去比较高大上,但实在是“屠龙之技”,离开了已有的圈子,学校之后就再无任何用武之地。这些专业还能继续招生的原因大概就是学校招聘了不少这些专业的教师。因此,对于这些专业的学生而言,不破不立,只有勇敢地走出自己所在的圈子,才能够体会到其他专业的精妙之处。

而对于职场人士而言,基本上都会想靠一些好项目来升职加薪,但是在整个社会的大环境下,有的方向确实是在走下坡路,行业越来越饱和,竞争越来越激烈,所做的技术难度越来越低。随着技术的发展,原有的一些技术和框架都会逐渐被淘汰,掌握的技能价值也会越来越低,甚至可能出现找一些应届生培训几个月之后就能够达到老员工的水平。在这种情况下,随着行业的整体下滑,如果还抱着原有的技术栈不松手,那只能变得越来越没有竞争力。在这种情况下,就要主动寻求突破,寻找自己所拥有的技能和其他专业的共同点,将自己的技能主动地迁移到更有潜力的方向上。在职场上,一定不要死抱着一个东西不放手,一定不要抱着我就是来做这个方向的想法,而其他的方向都不去了解和尝试。在工作中,应该审时度势,创造或者寻找优质的项目和资源,因为一个有潜力的项目和优质的资源所能够带来的好处有的时候会远远大于自己当年所做的方向,那个自己当年不舍得放弃的方向。

整体来说,在一个人面临着决策的时候,沉没成本最会影响一个人的决策。无论是从经济学的原理上来说,还是从日常经验上来讲,其实都应该放下包袱,轻装上阵,寻找一个更有前景和前途的方向去发挥自己的特长。







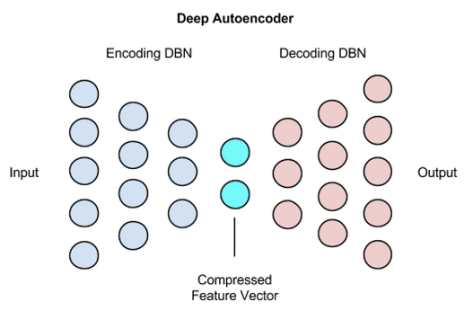
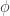 和
和 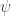 来表示,也就是说:
来表示,也就是说:
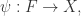


 ,并且编码器和解码器都是前馈神经网络,也就是说:
,并且编码器和解码器都是前馈神经网络,也就是说:

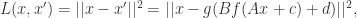 其中
其中 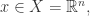

 和
和 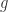 分别是编码层和解码层的激活函数,
分别是编码层和解码层的激活函数, 和
和  分别是编码层和解码层的矩阵和相应的向量。具体来说它们的矩阵大小分别是
分别是编码层和解码层的矩阵和相应的向量。具体来说它们的矩阵大小分别是 
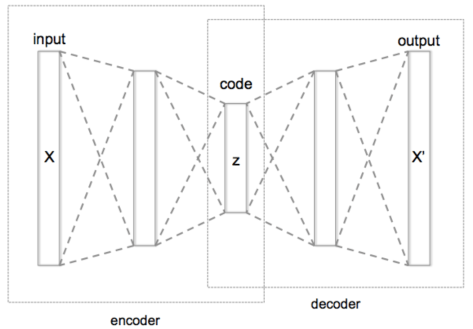
 一定是要小于输入层的维度
一定是要小于输入层的维度  的。
的。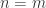 ,那么令
,那么令 

 就可以得到一个自编码器,而这个自编码器对于提取特征没有任何的意义。同理,当
就可以得到一个自编码器,而这个自编码器对于提取特征没有任何的意义。同理,当  时,
时,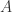 是一个
是一个  矩阵,
矩阵,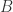 是一个
是一个  矩阵。从线性代数的角度来看,有无数个矩阵
矩阵。从线性代数的角度来看,有无数个矩阵  满足
满足  。这种情况下对于提取特征也是没有意义的。而当
。这种情况下对于提取特征也是没有意义的。而当 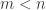 时,其实无法找到矩阵
时,其实无法找到矩阵 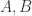 使得
使得 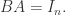 如果存在
如果存在 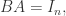 那么
那么