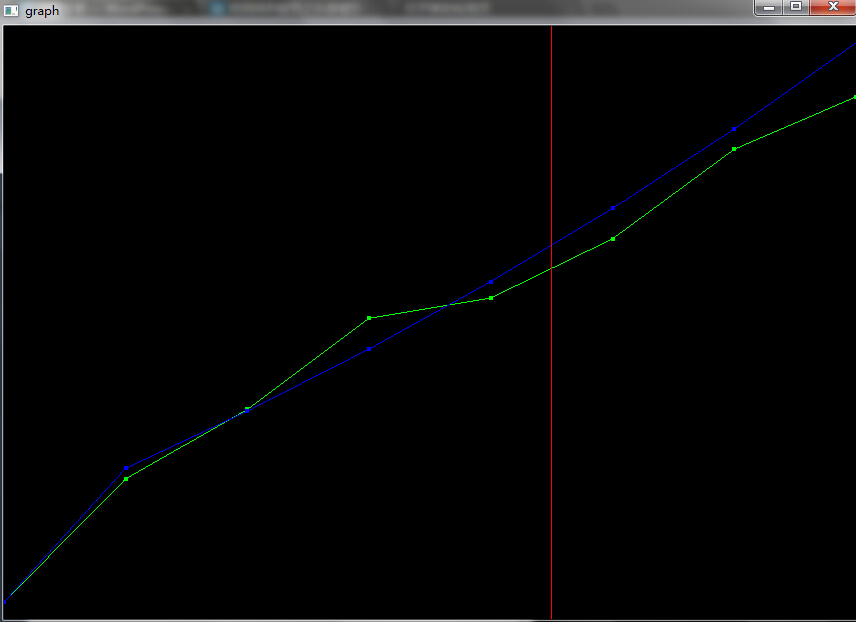
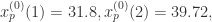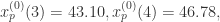引言
在推荐系统中,常常用二部图来表示用户和物品的关系:把用户(Users)看成一类点,把物品(Objects)看成另一类点。如果用户购买了某种物品,那么用户和物品之间就存在一条连线,也就是一条边。如果用户没有购买某种物品,那么用户和物品之间就没有连线。但是用户和用户之间,物品和物品之间是不存在连线的。换句话说就是同一类点之间是不存在连线的。这样的图结构就叫做二部图。电子商务中间的物品推荐,可以看成是二部图的边的挖掘问题。扩散过程可以用来寻找二部图中两个节点的关联强度。经典的扩散过程分成两类:一种叫做物质扩散(Probabilistic Spreading),它满足能量守恒定律;另一种叫做热传导(Heat Spreading),一般由一个或多个热源(物品)驱动,不一定满足能量守恒定律。
物质扩散(Probabilistic Spreading)算法流程
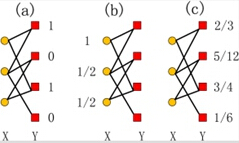
如图所示,用黄色的点来表示用户,用红色的点表示物品。用户有三位,物品有四个。第一个用户和第一个物品有连线表示第一个用户购买了第一个物品,而与第二个物品没有连线表示第一个用户没有购买第二个物品。根据图像(a)所示,第一个物品和第三个物品有能量1,第二个物品和第四个物品有能量0.对于物质扩散过程,第一个物品需要把自己的能量1平均分配给购买过它的用户一和用户二。第三个物品也需要把自己的能量1平均分配给购买过它的用户一和用户三。用户的能量就是所有用物品得到的能量的总和。正如图像(b)所示,第一个用户此时具有能量1,第二个和第三个用户都具有能量1/2.接下来,每个用户再把自身的能量平均分配给所有购买过的物品,物品的能量则是从所有用户得到的能量的总和。所以第一个物品的能量就是第一个用户的能量乘以0.5加上第二个用户的能量乘以1/3,所得的能量则是2/3.其他物品的能量用类似的方法计算。
物质扩散(Probabilistic Spreading)数学模型
假设有m个用户(Users)和n个物品(Objects),可以构造矩阵




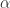



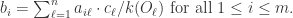
后面需要通过用户的能量来更新物品的能量,假设物品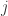


把

在这里对于
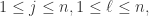

假设




性质1. 矩阵每列的和都是1,i.e.
对于所有的
都成立。
证明.
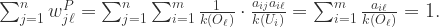
性质2.对于所有的
都成立。换言之,矩阵
证明. 根据
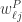
性质3. 矩阵对于所有的
证明. 根据矩阵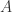
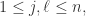

性质4. 能量守恒定律:

证明. 根据前面的性质,已经知道
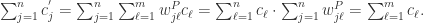
性质5. 如果物品的用户都是物品
的用户,换句话说,如果
则有
那么
对于所有的
那么物品
证明. 根据


根据条件,如果
根据上面性质,可以定义变量

其中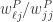



性质6.对于所有的
都是成立的。
证明. 根据以上性质可以得到
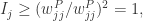
基于物质扩散算法的用户相似度
回顾一下基于用户的协同过滤算法:用户
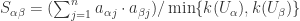
或者使用余弦表达式
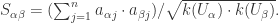
如果用户
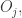

这里的求和指的把除了用户
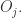


下面来介绍基于物质扩散方法的算法。与上面的方法类似,第一步就是定义用户相似度

上面定义表示物品



对于物质扩散的算法,可以用以下简单方法进行推广。增加参数



当


 那么吸引子的结构特性就包含在这个时间序列之中。为了从时间序列中提取出更多有用的信息,1980年Packard等人提出了时间序列重构相空间的两种方法:导数重构法和坐标延迟重构法。而后者的本质则是通过一维的时间序列
那么吸引子的结构特性就包含在这个时间序列之中。为了从时间序列中提取出更多有用的信息,1980年Packard等人提出了时间序列重构相空间的两种方法:导数重构法和坐标延迟重构法。而后者的本质则是通过一维的时间序列 的不同延迟时间
的不同延迟时间 来构建
来构建 维的相空间矢量
维的相空间矢量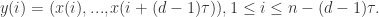
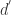 维混沌吸引子的一维标量时间序列
维混沌吸引子的一维标量时间序列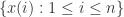 都可以在拓扑不变的意义下找到一个
都可以在拓扑不变的意义下找到一个 根据Takens嵌入定理,我们可以从一维混沌时间序列中重构一个与原动力系统在拓扑意义下一样的相空间,混沌时间序列的判定,分析和预测都是在这个重构的相空间中进行的,因此相空间的重构就是混沌时间序列研究的关键。
根据Takens嵌入定理,我们可以从一维混沌时间序列中重构一个与原动力系统在拓扑意义下一样的相空间,混沌时间序列的判定,分析和预测都是在这个重构的相空间中进行的,因此相空间的重构就是混沌时间序列研究的关键。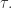 在Takens嵌入定理中,嵌入维数和延迟时间都只是理论上证明了其存在性,并没有给出具体的表达式,而且实际应用中时间序列都是有噪声的有限序列,嵌入维数和时间延迟必须要根据实际的情况来选取合适的值。
在Takens嵌入定理中,嵌入维数和延迟时间都只是理论上证明了其存在性,并没有给出具体的表达式,而且实际应用中时间序列都是有噪声的有限序列,嵌入维数和时间延迟必须要根据实际的情况来选取合适的值。
 与
与 在数值上非常接近,以至于无法相互区分,从而无法提供两个独立的坐标分量;但是如果延迟时间
在数值上非常接近,以至于无法相互区分,从而无法提供两个独立的坐标分量;但是如果延迟时间 从而在独立和相关两者之间达到一种平衡。
从而在独立和相关两者之间达到一种平衡。 可以写出其自相关函数如下:
可以写出其自相关函数如下:
 来做出自相关函数
来做出自相关函数 随着延迟时间
随着延迟时间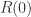 的
的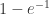 时,i.e.
时,i.e.  所得到的时间
所得到的时间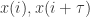 以及
以及 之间不相关,但是
之间不相关,但是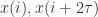 之间的相关性可能会很强。这一点意味着这种方法并不能够有效的推广到高维的研究。而且选择下降系数
之间的相关性可能会很强。这一点意味着这种方法并不能够有效的推广到高维的研究。而且选择下降系数 所构成的系统
所构成的系统 和
和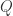 。通过信息论和遍历论的知识,从两个系统中获得的信息熵分别是:
。通过信息论和遍历论的知识,从两个系统中获得的信息熵分别是:
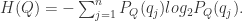
 分别是
分别是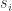 和
和 的概率。交互信息的计算公式是:
的概率。交互信息的计算公式是: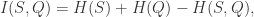

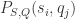 称为事件
称为事件 的联合分布概率。交互信息标准化就是
的联合分布概率。交互信息标准化就是
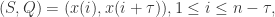 也就是
也就是
 那么
那么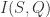 则是关于延迟时间
则是关于延迟时间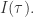
 的大小表示在已知系统
的大小表示在已知系统 的情况下,系统
的情况下,系统 的确定性的大小。
的确定性的大小。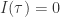 表示
表示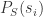 和
和 这里采取的方法是等间距格子法,其方法简要概述如下。
这里采取的方法是等间距格子法,其方法简要概述如下。 在
在 平面用一个矩形包含上面所有的点。将矩形
平面用一个矩形包含上面所有的点。将矩形 份,
份, 份(注:
份(注: 取值100~200之间即可)。那么在
取值100~200之间即可)。那么在
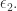 假设
假设 是
是 那么
那么 在第
在第![Row[i]](https://s0.wp.com/latex.php?latex=Row%5Bi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 做一次记录;
做一次记录;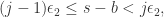 那么
那么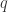 在第
在第![Col[j]](https://s0.wp.com/latex.php?latex=Col%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 做一次记录。
做一次记录。 那么
那么![P_{S}(i)=Row[i]/(n-\tau), 1\leq i\leq M_{1},](https://s0.wp.com/latex.php?latex=P_%7BS%7D%28i%29%3DRow%5Bi%5D%2F%28n-%5Ctau%29%2C+1%5Cleq+i%5Cleq+M_%7B1%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![P_{Q}(j)=Col[j]/(n-\tau), 1\leq j\leq M_{2}.](https://s0.wp.com/latex.php?latex=P_%7BQ%7D%28j%29%3DCol%5Bj%5D%2F%28n-%5Ctau%29%2C+1%5Cleq+j%5Cleq+M_%7B2%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 且
且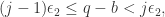 则
则 在标号为
在标号为 的格子中,对
的格子中,对![Together[i][j]](https://s0.wp.com/latex.php?latex=Together%5Bi%5D%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 做一次记录。那么
做一次记录。那么![P_{S,Q}(i,j)=Together[i][j]/(n-\tau)^{2}, 1\leq i\leq M_{1}, 1\leq j\leq M_{2}.](https://s0.wp.com/latex.php?latex=P_%7BS%2CQ%7D%28i%2Cj%29%3DTogether%5Bi%5D%5Bj%5D%2F%28n-%5Ctau%29%5E%7B2%7D%2C+1%5Cleq+i%5Cleq+M_%7B1%7D%2C+1%5Cleq+j%5Cleq+M_%7B2%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
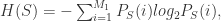


 第一次下降到极小值所对应的延迟时间
第一次下降到极小值所对应的延迟时间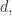 实际应用中通常的方法是计算吸引子的某些几何不变量(如关联维数,Lyapunov指数等)。选择好延迟时间
实际应用中通常的方法是计算吸引子的某些几何不变量(如关联维数,Lyapunov指数等)。选择好延迟时间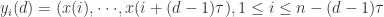
 其距离是
其距离是
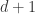 时,这两个点的距离就会发生变化,新的距离是
时,这两个点的距离就会发生变化,新的距离是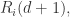 并且
并且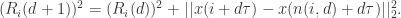
 比
比 大很多,那么就可以认为这是由于高维混沌吸引子中两个不相邻得点投影到低维坐标上变成相邻的两点造成的,这样的临近点是虚假的,令
大很多,那么就可以认为这是由于高维混沌吸引子中两个不相邻得点投影到低维坐标上变成相邻的两点造成的,这样的临近点是虚假的,令
![a_{1}(i,d)>R_{\tau} \in [10,50],](https://s0.wp.com/latex.php?latex=a_%7B1%7D%28i%2Cd%29%3ER_%7B%5Ctau%7D+%5Cin+%5B10%2C50%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 那么
那么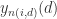 就是
就是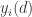 的虚假最临近点。这里的
的虚假最临近点。这里的 是阀值。
是阀值。 具有很强的主观性。此时Cao Liangyue教授提出了改进的FNN方法,此方法计算时只需要延迟时间
具有很强的主观性。此时Cao Liangyue教授提出了改进的FNN方法,此方法计算时只需要延迟时间
 那么基于延迟时间
那么基于延迟时间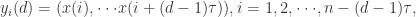 这里的
这里的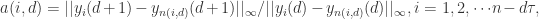
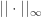 是最大模范数。其中
是最大模范数。其中 是第
是第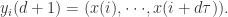
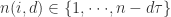 是使得
是使得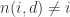 ,显然
,显然 由
由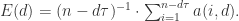
 与延迟时间
与延迟时间 当
当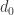 时,
时, 不再变化,那么
不再变化,那么 则是我们所寻找的最小嵌入维数。除了
则是我们所寻找的最小嵌入维数。除了 还可以定义一个变量
还可以定义一个变量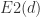 如下。令
如下。令
 定义
定义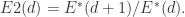 对于随机序列,数据之间没有相关性,
对于随机序列,数据之间没有相关性, 对于确定性的序列,数据点之间的关系依赖于嵌入维数
对于确定性的序列,数据点之间的关系依赖于嵌入维数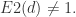
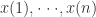 可以确定其延迟时间
可以确定其延迟时间 个
个

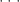


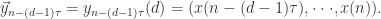
 建立一个动力系统的模型如下:
建立一个动力系统的模型如下: 其中
其中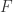 是一个连续函数。
是一个连续函数。 根据连续函数的性质可以知道:如果
根据连续函数的性质可以知道:如果 与
与 非常接近,那么
非常接近,那么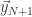 与
与 也是非常接近的,可以用
也是非常接近的,可以用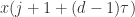 作为
作为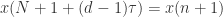 的近似值。
的近似值。 个最临近向量
个最临近向量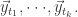 i.e. 也就是从其他的
i.e. 也就是从其他的 个向量中选取前
个向量中选取前 或者最大模范数
或者最大模范数 根据局部预测法的观点,可以得到
根据局部预测法的观点,可以得到 的近似值:
的近似值: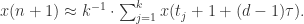

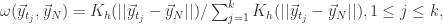


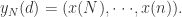

 是待定系数。假设向量
是待定系数。假设向量 此处可以用欧几里德范数
此处可以用欧几里德范数 使得
使得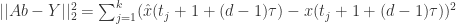
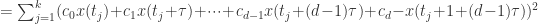

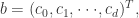 矩阵
矩阵 根据最小二乘法可以得到待定系数向量
根据最小二乘法可以得到待定系数向量 是最小二乘解。
是最小二乘解。


 是系统的三个坐标,
是系统的三个坐标,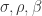 是三个系数。在这里,我们取
是三个系数。在这里,我们取 在解这个常微分方程的时候,使用了经典的Runge-Kutta数值方法。
在解这个常微分方程的时候,使用了经典的Runge-Kutta数值方法。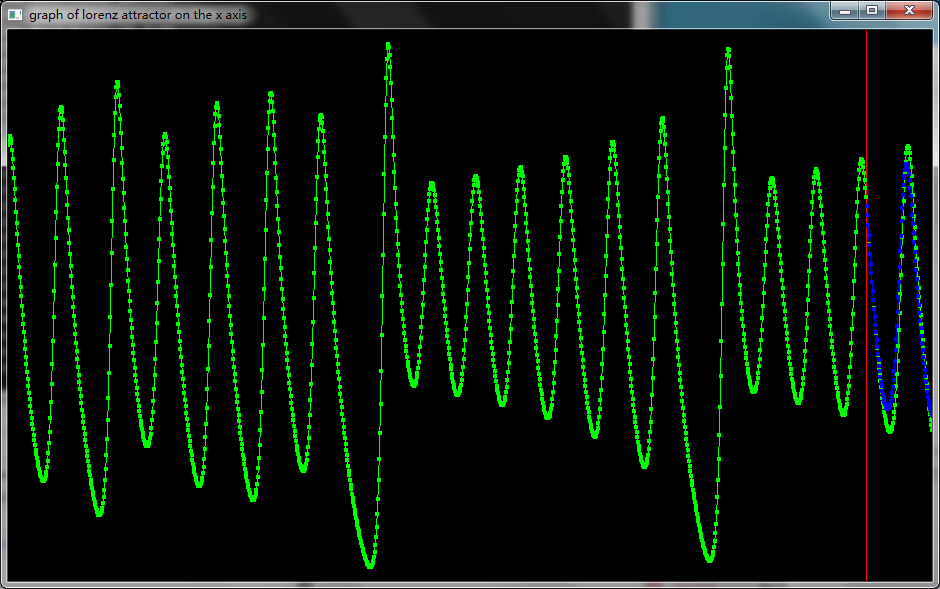
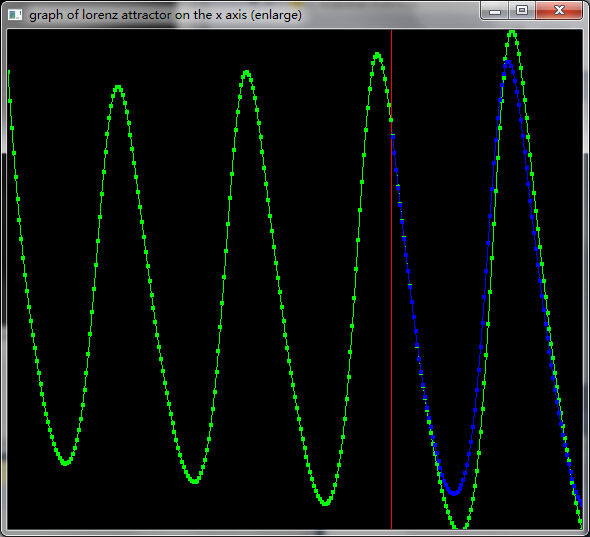

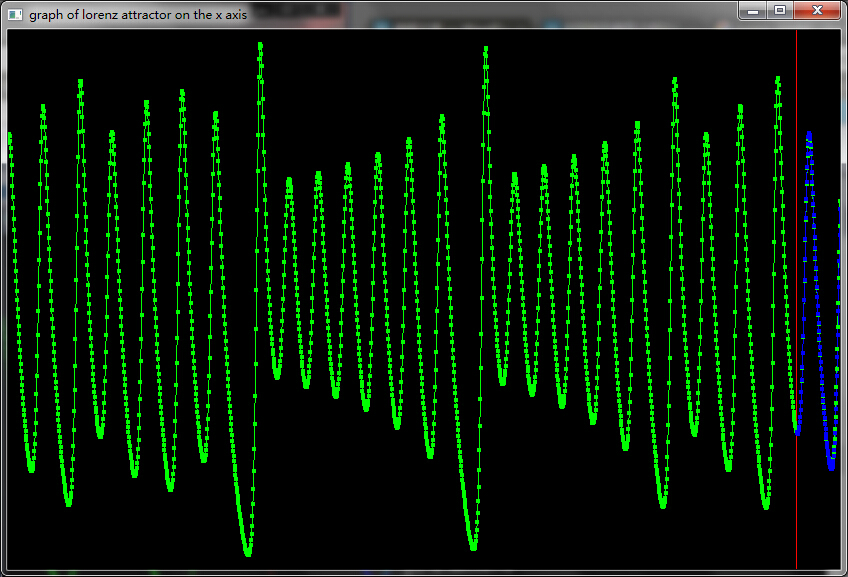

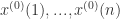 ,其中n是数组的长度。通过分析这组序列的内在结构,从而建立相应的微分方程模型,达到预测未来序列
,其中n是数组的长度。通过分析这组序列的内在结构,从而建立相应的微分方程模型,达到预测未来序列 的目的。
的目的。 ,其中
,其中
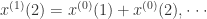


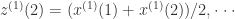
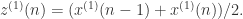
 , 它的离散方程是
, 它的离散方程是 这里
这里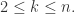 其中a成为发展系数,b称为控制系数。通过最小二乘法的推导,可以得到
其中a成为发展系数,b称为控制系数。通过最小二乘法的推导,可以得到 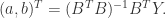 其中B和Y都是矩阵,定义如下:
其中B和Y都是矩阵,定义如下: ,
,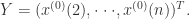

 从而得到序列的预测值:
从而得到序列的预测值:

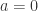
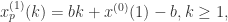 从而得到的序列的预测值:
从而得到的序列的预测值:
 离散方程则是
离散方程则是 通过最小二乘法的推导,可以得到
通过最小二乘法的推导,可以得到  ,
, 从而可以得到预测的序列
从而可以得到预测的序列

 , 那么
, 那么
 通过最小二乘法的推导,可以得到
通过最小二乘法的推导,可以得到  ,
,
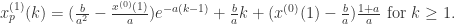

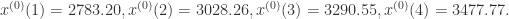 通过计算累积生成序列,可以进一步求的系数a和b的值,从而根据上面的模型进行模拟。通过模型可以算出
通过计算累积生成序列,可以进一步求的系数a和b的值,从而根据上面的模型进行模拟。通过模型可以算出


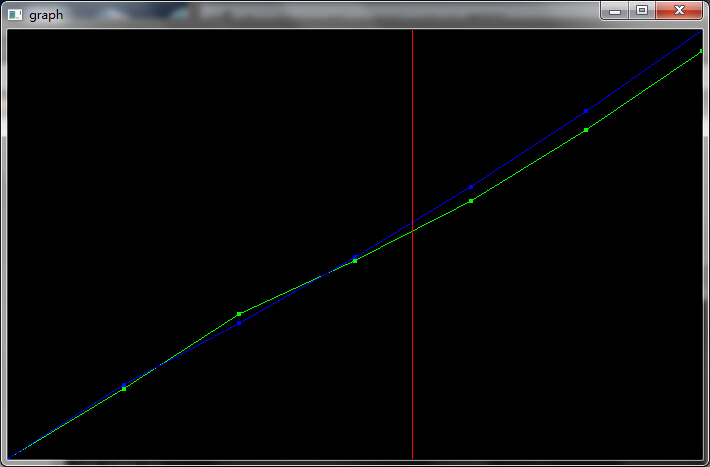
 通过计算累积生成序列,可以进一步求的系数a和b的值,从而根据上面的模型进行模拟。通过模型可以算出
通过计算累积生成序列,可以进一步求的系数a和b的值,从而根据上面的模型进行模拟。通过模型可以算出