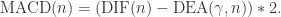引言
在机器翻译(Machine Translation)或者自然语言处理(Natural Language Processing)领域,以前都是使用数理统计的方法来进行分析和处理。近些年来,随着 AlphaGo 的兴起,除了在游戏AI领域,深度学习在计算机视觉领域,机器翻译和自然语言处理领域也有着巨大的用武之地。在 2016 年,随着深度学习的进一步发展,seq2seq 的训练模式和翻译模式已经开始进入人们的视野。除此之外,在端到端的训练方法中,除了需要海量的业务数据之外,在网络结构中加入一些重要的模块也是非常必要的。在此情形下,基于循环神经网咯(Recurrent Neural Network)的注意力机制(Attention Mechanism)进入了人们的视野。除了之前提到的机器翻译和自然语言处理领域之外,计算机视觉中的注意力机制也是十分有趣的,本文将会简要介绍一下计算机视觉领域中的注意力方法。在此事先声明一下,笔者并不是从事这几个领域的,可能在撰写文章的过程中会有些理解不到位的地方,请各位读者指出其中的不足。
注意力机制
顾名思义,注意力机制是本质上是为了模仿人类观察物品的方式。通常来说,人们在看一张图片的时候,除了从整体把握一幅图片之外,也会更加关注图片的某个局部信息,例如局部桌子的位置,商品的种类等等。在翻译领域,每次人们翻译一段话的时候,通常都是从句子入手,但是在阅读整个句子的时候,肯定就需要关注词语本身的信息,以及词语前后关系的信息和上下文的信息。在自然语言处理方向,如果要进行情感分类的话,在某个句子里面,肯定会涉及到表达情感的词语,包括但不限于“高兴”,“沮丧”,“开心”等关键词。而这些句子里面的其他词语,则是上下文的关系,并不是它们没有用,而是它们所起的作用没有那些表达情感的关键词大。
在以上描述下,注意力机制其实包含两个部分:
- 注意力机制需要决定整段输入的哪个部分需要更加关注;
- 从关键的部分进行特征提取,得到重要的信息。
通常来说,在机器翻译或者自然语言处理领域,人们阅读和理解一句话或者一段话其实是有着一定的先后顺序的,并且按照语言学的语法规则来进行阅读理解。在图片分类领域,人们看一幅图也是按照先整体再局部,或者先局部再整体来看的。再看局部的时候,尤其是手写的手机号,门牌号等信息,都是有先后顺序的。为了模拟人脑的思维方式和理解模式,循环神经网络(RNN)在处理这种具有明显先后顺序的问题上有着独特的优势,因此,Attention 机制通常都会应用在循环神经网络上面。
虽然,按照上面的描述,机器翻译,自然语言处理,计算机视觉领域的注意力机制差不多,但是其实仔细推敲起来,这三者的注意力机制是有明显区别的。
- 在机器翻译领域,翻译人员需要把已有的一句话翻译成另外一种语言的一句话。例如把一句话从英文翻译到中文,把中文翻译到法语。在这种情况下,输入语言和输出语言的词语之间的先后顺序其实是相对固定的,是具有一定的语法规则的;
- 在视频分类或者情感识别领域,视频的先后顺序是由时间戳和相应的片段组成的,输入的就是一段视频里面的关键片段,也就是一系列具有先后顺序的图片的组合。NLP 中的情感识别问题也是一样的,语言本身就具有先后顺序的特点;
- 图像识别,物体检测领域与前面两个有本质的不同。因为物体检测其实是在一幅图里面挖掘出必要的物体结构或者位置信息,在这种情况下,它的输入就是一幅图片,并没有非常明显的先后顺序,而且从人脑的角度来看,由于个体的差异性,很难找到一个通用的观察图片的方法。由于每个人都有着自己观察的先后顺序,因此很难统一成一个整体。
在这种情况下,机器翻译和自然语言处理领域使用基于 RNN 的 Attention 机制就变得相对自然,而计算机视觉领域领域则需要必要的改造才能够使用 Attention 机制。
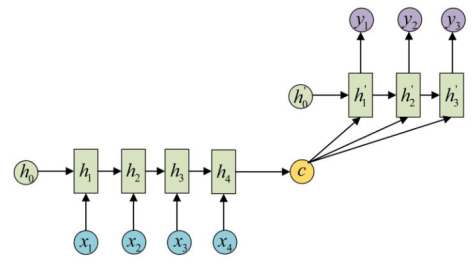
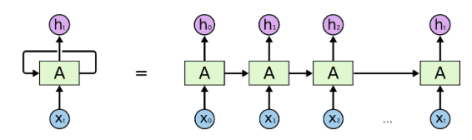
基于 RNN 的注意力机制
通常来说,RNN 等深度神经网络可以进行端到端的训练和预测,在机器翻译领域和或者文本识别领域有着独特的优势。对于端到端的 RNN 来说,有一个更简洁的名字叫做 sequence to sequence,简写就是 seq2seq。顾名思义,输入层是一句话,输出层是另外一句话,中间层包括编码和解码两个步骤。
而基于 RNN 的注意力机制指的是,对于 seq2seq 的诸多问题,在输入层和输出层之间,也就是词语(Items)与词语之间,存在着某种隐含的联系。例如:“中国” -> “China”,“Excellent” -> “优秀的”。在这种情况下,每次进行机器翻译的时候,模型需要了解当前更加关注某个词语或者某几个词语,只有这样才能够在整句话中进行必要的提炼。在这些初步的思考下,基于 RNN 的 Attention 机制就是:
- 建立一个编码(Encoder)和解码(Decoder)的非线性模型,神经网络的参数足够多,能够存储足够的信息;
- 除了关注句子的整体信息之外,每次翻译下一个词语的时候,需要对不同的词语赋予不同的权重,在这种情况下,再解码的时候,就可以同时考虑到整体的信息和局部的信息。
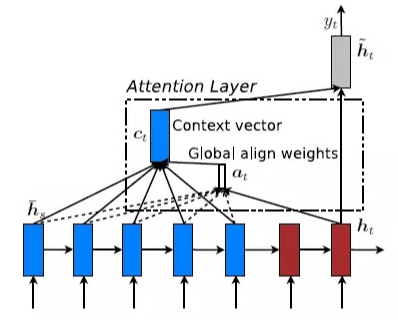
注意力机制的种类
从初步的调研情况来看,注意力机制有两种方法,一种是基于强化学习(Reinforcement Learning)来做的,另外一种是基于梯度下降(Gradient Decent)来做的。强化学习的机制是通过收益函数(Reward)来激励,让模型更加关注到某个局部的细节。梯度下降法是通过目标函数以及相应的优化函数来做的。无论是 NLP 还是 CV 领域,都可以考虑这些方法来添加注意力机制。
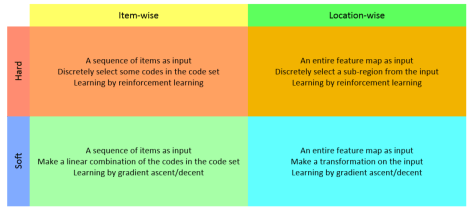
计算机视觉领域的 Attention 部分论文整理
下面将会简单的介绍几篇近期阅读的计算机视觉领域的关于注意力机制的文章。
Look Closer to See Better:Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition
在图像识别领域,通常都会遇到给图片中的鸟类进行分类,包括种类的识别,属性的识别等内容。为了区分不同的鸟,除了从整体来对图片把握之外,更加关注的是一个局部的信息,也就是鸟的样子,包括头部,身体,脚,颜色等内容。至于周边信息,例如花花草草之类的,则显得没有那么重要,它们只能作为一些参照物。因为不同的鸟类会停留在树木上,草地上,关注树木和草地的信息对鸟类的识别并不能够起到至关重要的作用。所以,在图像识别领域引入注意力机制就是一个非常关键的技术,让深度学习模型更加关注某个局部的信息。
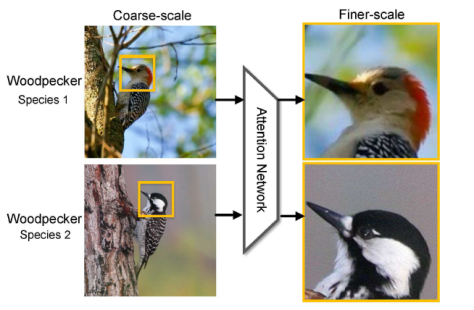
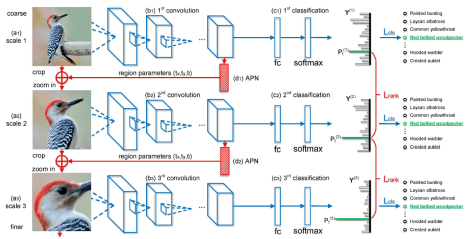
在这篇文章里面,作者们提出了一个基于 CNN 的注意力机制,叫做 recurrent attention convolutional neural network(RA-CNN),该模型递归地分析局部信息,从局部的信息中提取必要的特征。同时,在 RA-CNN 中的子网络(sub-network)中存在分类结构,也就是说从不同区域的图片里面,都能够得到一个对鸟类种类划分的概率。除此之外,还引入了 attention 机制,让整个网络结构不仅关注整体信息,还关注局部信息,也就是所谓的 Attention Proposal Sub-Network(APN)。这个 APN 结构是从整个图片(full-image)出发,迭代式地生成子区域,并且对这些子区域进行必要的预测,并将子区域所得到的预测结果进行必要的整合,从而得到整张图片的分类预测概率。
RA-CNN 的特点是进行一个端到端的优化,并不需要提前标注 box,区域等信息就能够进行鸟类的识别和图像种类的划分。在数据集上面,该论文不仅在鸟类数据集(CUB Birds)上面进行了实验,也在狗类识别(Stanford Dogs)和车辆识别(Stanford Cars)上进行了实验,并且都取得了不错的效果。

从深度学习的网络结构来看,RA-CNN 的输入时是整幅图片(Full Image),输出的时候就是分类的概率。而提取图片特征的方法通常来说都是使用卷积神经网络(CNN)的结构,然后把 Attention 机制加入到整个网络结构中。从下图来看,一开始,整幅图片从上方输入,然后判断出一个分类概率;然后中间层输出一个坐标值和尺寸大小,其中坐标值表示的是子图的中心点,尺寸大小表示子图的尺寸。在这种基础上,下一幅子图就是从坐标值和尺寸大小得到的图片,第二个网络就是在这种基础上构建的;再迭代持续放大图片,从而不停地聚焦在图片中的某些关键位置。不同尺寸的图片都能够输出不同的分类概率,再将其分类概率进行必要的融合,最终的到对整幅图片的鸟类识别概率。
因此,在整篇论文中,有几个关键点需要注意:
- 分类概率的计算,也就是最终的 loss 函数的设计;
- 从上一幅图片到下一幅图片的坐标值和尺寸大小。
只要获得了这些指标,就可以把整个 RA-CNN 网络搭建起来。
大体来说,第一步就是给定了一幅输入图片 
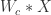



第二步就是计算下一个 box 的坐标 

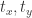

![[t_{x}, t_{y}, t_{\ell}] = g(W_{c}*X)](https://s0.wp.com/latex.php?latex=%5Bt_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%5D+%3D+g%28W_%7Bc%7D%2AX%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


局部注意力和放大策略(Attention Localization and Amplification)指的是:从上面的方法中拿到坐标值和尺寸,然后把图像进行必要的放大。为了提炼局部的信息,其实就需要在整张图片
在激活函数里面,逻辑回归函数(Logistic Regression)是很常见的。其实通过逻辑回归函数,我们可以构造出近似的阶梯函数或者面具函数。
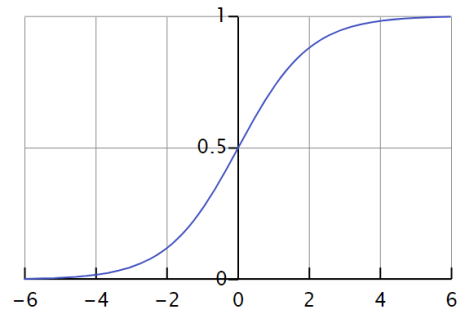
对于逻辑回归函数 

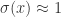
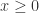

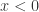

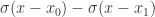




因此,基于以上的分析和假设,我们可以构造如下的函数: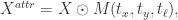


![M(t_{x}, t_{y}, t_{\ell}) = [\sigma(x-t_{x(t\ell)}) - \sigma(x-t_{x(br)})]\cdot[\sigma(y-t_{y(t\ell)}) - \sigma(y-t_{y(br)})],](https://s0.wp.com/latex.php?latex=M%28t_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%29+%3D+%5B%5Csigma%28x-t_%7Bx%28t%5Cell%29%7D%29+-+%5Csigma%28x-t_%7Bx%28br%29%7D%29%5D%5Ccdot%5B%5Csigma%28y-t_%7By%28t%5Cell%29%7D%29+-+%5Csigma%28y-t_%7By%28br%29%7D%29%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
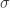
当然,从一张完整的图片到小图片,在实际操作的时候,需要把小图片继续放大,在放大的过程中,可以考虑使用双线性插值算法来扩大。也就是说:

其中 ![m = [i/\lambda] + \alpha, n = [j/\lambda] + \beta](https://s0.wp.com/latex.php?latex=m+%3D+%5Bi%2F%5Clambda%5D+%2B+%5Calpha%2C+n+%3D+%5Bj%2F%5Clambda%5D+%2B+%5Cbeta&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
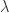
![[\cdot], \{\cdot\}](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D%2C+%5C%7B%5Ccdot%5C%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
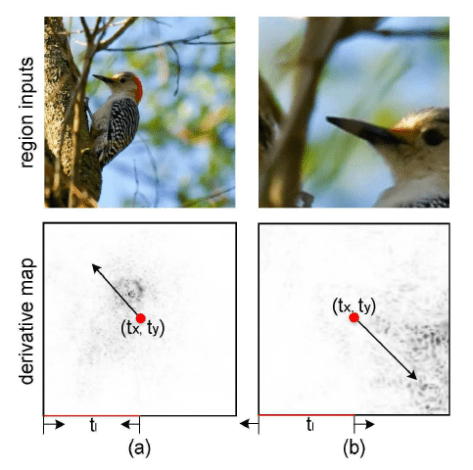
在分类(Classification)和排序(Ranking)部分,RA-CNN 也有着自己的方法论。在损失函数(Loss Function)里面有两个重要的部分,第一个部分就是三幅图片的 LOSS 函数相加,也就是所谓的 classification loss,
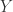



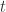

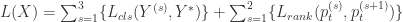
在这种 Attention 机制下,可以使用训练好的 conv5_4 或者 VGG-19 来进行特征的提取。在图像领域,location 的位置是需要通过训练而得到的,因为每张图片的鸟的位置都有所不同。进一步通过数学计算可以得到,
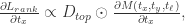
这里的 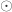
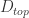
当 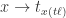

当 
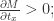
其余情况,

当 

当 
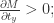
其余情况,
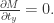
当 
其余情况,

因此,
RA-CNN 的实验效果如下:
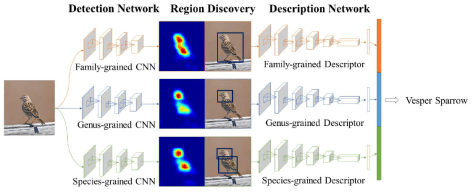
Multiple Granularity Descriptors for Fine-grained Categorization
这篇文中同样做了鸟类的分类工作,与 RA-CNN 不同之处在于它使用了层次的结构,因为鸟类的区分是按照一定的层次关系来进行的,粗糙来看,有科 -> 属 -> 种三个层次结构。
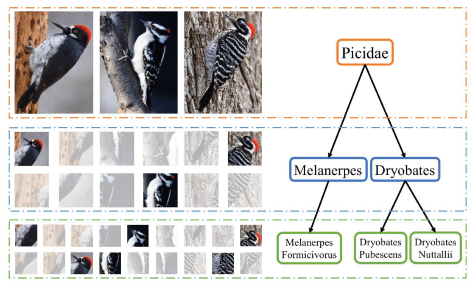
因此,在设计网络结构的过程中,需要有并行的网络结构,分别对应科,属,种三个层次。从前往后的顺序是检测网络(Detection Network),区域发现(Region Discovery),描述网络(Description Network)。并行的结构是 Family-grained CNN + Family-grained Descriptor,Genus-grained CNN + Genus-grained Descriptor,Species-grained CNN + Species-grained Descriptor。而在区域发现的地方,作者使用了 energy 的思想,让神经网络分别聚焦在图片中的不同部分,最终的到鸟类的预测结果。

Recurrent Models of Visual Attention
在计算机视觉中引入注意力机制,DeepMind 的这篇文章 recurrent models of visual attention 发表于 2014 年。在这篇文章中,作者使用了基于强化学习方法的注意力机制,并且使用收益函数来进行模型的训练。从网络结构来看,不仅从整体来观察图片,也从局部来提取必要的信息。
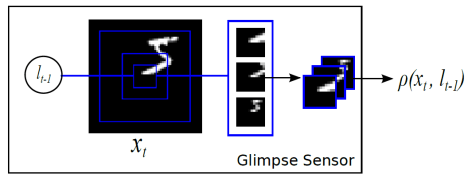
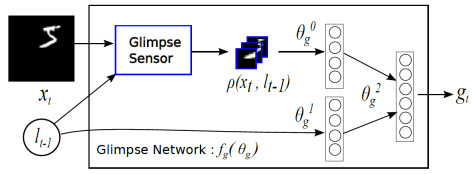
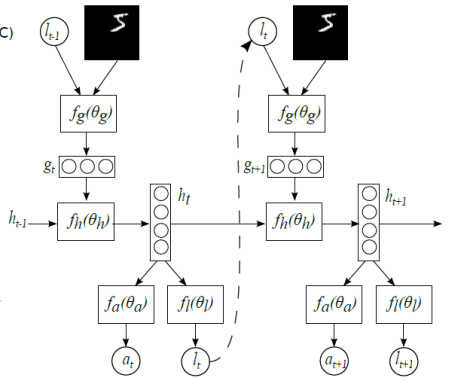
整体来看,其网络结构是 RNN,上一个阶段得到的信息和坐标会被传递到下一个阶段。这个网络只在最后一步进行分类的概率判断,这是与 RA-CNN 不同之处。这是为了模拟人类看物品的方式,人类并非会一直把注意力放在整张图片上,而是按照某种潜在的顺序对图像进行扫描。Recurrent Models of Visual Attention 本质上是把图片按照某种时间序列的形式进行输入,一次处理原始图片的一部分信息,并且在处理信息的过程中,需要根据过去的信息和任务选择下一个合适的位置进行处理。这样就可以不需要进行事先的位置标记和物品定位了。
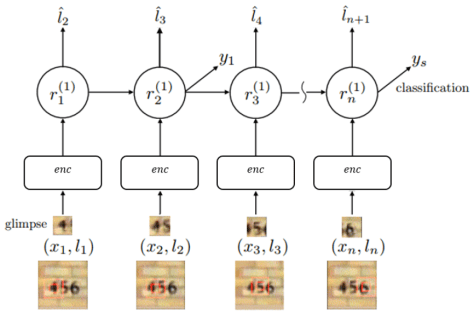
正如上图所示,enc 指的是对图片进行编码,


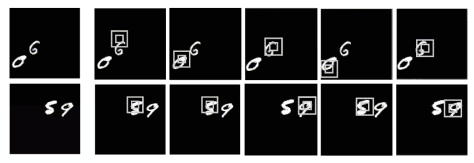
Multiple Object Recognition with Visual Attention
这篇文章同样是 DeepMind 的论文,与 Recurrent Models of Visual Attention 不同之处在于,它是一个两层的 RNN 结构,并且在最上层把原始图片进行输入。其中 enc 是编码网络,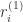
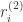
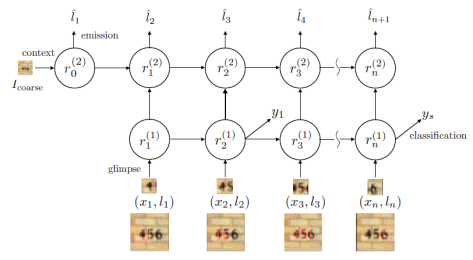
在门牌识别里面,该网络是按照从左到右的顺序来进行图片扫描的,这与人类识别物品的方式极其相似。除了门牌识别之外,该论文也对手写字体进行了识别,同样取得了不错的效果。

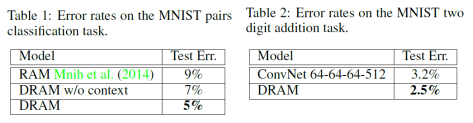
实验效果如下:
总结
本篇 Blog 初步介绍了计算机视觉中的 Attention 机制,除了这些方法之外,应该还有一些更巧妙的方法,希望各位读者多多指教。
参考文献
- Look Closer to See Better:Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition,CVPR,2017.
- Recurrent Models of Visual Attention,NIPS,2014
- GitHub 代码:Recurrent-Attention-CNN,https://github.com/Jianlong-Fu/Recurrent-Attention-CNN
- Multiple Granularity Descriptors for Fine-grained Categorization,ICCV,2015
- Multiple Object Recognition with Visual Attention,ICRL,2015
- Understanding LSTM Networks,Colah’s Blog,2015,http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- Survey on the attention based RNN model and its applications in computer vision,2016
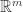 中的
中的  个节点,基于它们之间的距离公式,把它们划分成
个节点,基于它们之间的距离公式,把它们划分成  个类别,其中类别
个类别,其中类别 
 ,事先设定的类别个数是
,事先设定的类别个数是  是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合
是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合 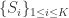 使得
使得  达到最小,其中
达到最小,其中  表示集合
表示集合  中的所有点的均值。
中的所有点的均值。 表示欧式空间的欧几里得距离,在这种情况下,除了使用
表示欧式空间的欧几里得距离,在这种情况下,除了使用 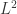 范数之外,还可以使用
范数之外,还可以使用  范数和其余的
范数和其余的 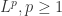 范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。
范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。
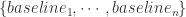 和
和  。i.e.
。i.e.  。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章:
。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章: 距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把
距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把  和
和  进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是
进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是  量级的,其中
量级的,其中 
 还是
还是 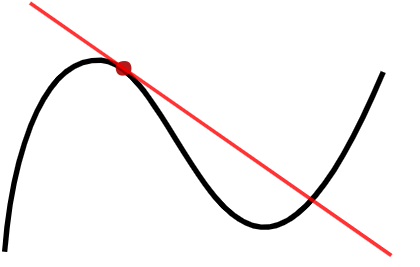
 是定义域
是定义域  上的可导函数,那么某个点
上的可导函数,那么某个点  的导数则定义为:
的导数则定义为:
 。如果
。如果  ,那么在
,那么在  的附近,
的附近, ,那么在
,那么在  ,则基于这个事实无法轻易的判断
,则基于这个事实无法轻易的判断  ,
,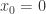 ;(2)
;(2)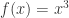 ,
,
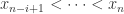 时,表示时间序列在
时,表示时间序列在 ![[n-i+1,n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2Cn%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调递增的;当
这个区间内是严格单调递增的;当  时,表示时间序列在
时,表示时间序列在 ![[n-i+1, n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2C+n%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。
这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。![X_{N} = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的一个子序列
的一个子序列 ![[x_{i},x_{i+1},\cdots,x_{j}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%2C%5Ccdots%2Cx_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,其中
,其中  。如果存在某个
。如果存在某个 ![k\in (i,j]](https://s0.wp.com/latex.php?latex=k%5Cin+%28i%2Cj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和一组非负实数
和一组非负实数 ![[w_{i}, w_{i+1},\cdots,w_{j}]](https://s0.wp.com/latex.php?latex=%5Bw_%7Bi%7D%2C+w_%7Bi%2B1%7D%2C%5Ccdots%2Cw_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 使得
使得 其中
其中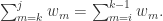
 其中
其中 ![X = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,可以考虑第
,可以考虑第  个点
个点  时,
时,

 ,当第一个公式大于零时,表示
,当第一个公式大于零时,表示 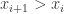 ,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示
,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示  ,i.e. 处于单调下降的趋势中。
,i.e. 处于单调下降的趋势中。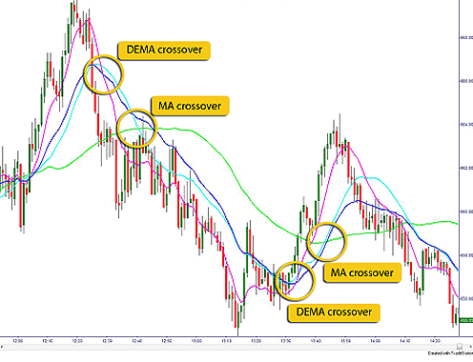
![X=[x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,如果考虑时间戳
,如果考虑时间戳 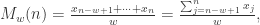
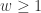 指的就是窗口的大小。
指的就是窗口的大小。 ,
,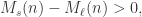 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。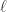 所对应的移动平均线。
所对应的移动平均线。 。假设
。假设  ,那么通过数学推导可以得到:
,那么通过数学推导可以得到:

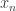 历史上的
历史上的 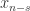 历史上的
历史上的  个点的平均值,该序列有上涨的趋势。反之,如果
个点的平均值,该序列有上涨的趋势。反之,如果  ,那么该序列有下跌的趋势。
,那么该序列有下跌的趋势。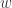 ,对于简单移动平均算法,那么
,对于简单移动平均算法,那么  每个元素的权重都是
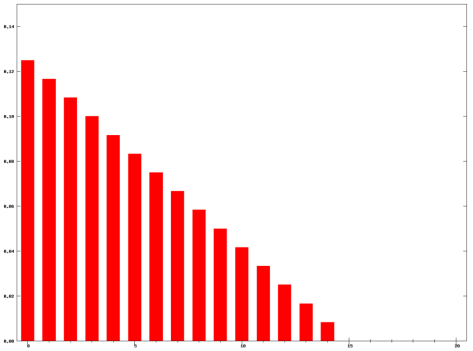
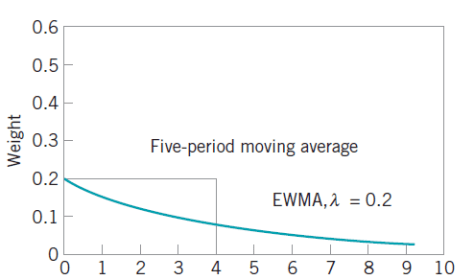
每个元素的权重都是  ,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
 ,那么
,那么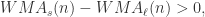 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。 。假设
。假设  ,那么
,那么




![j_{0}=[s\cdot(s+1)/(\ell + s-1)]](https://s0.wp.com/latex.php?latex=j_%7B0%7D%3D%5Bs%5Ccdot%28s%2B1%29%2F%28%5Cell+%2B+s-1%29%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,这里的
,这里的 ![[\cdot]](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示 Gauss 取整函数。因为
表示 Gauss 取整函数。因为
 ,于是距离当前点
,于是距离当前点 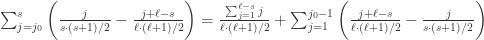

 时,表示时间序列有上涨的趋势;当
时,表示时间序列有上涨的趋势;当  时,表示时间序列有下跌的趋势。
时,表示时间序列有下跌的趋势。 ,那么它的指数移动平均算法就是:
,那么它的指数移动平均算法就是: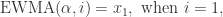

 。
。

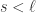 ,那么短线和长线则分别是:
,那么短线和长线则分别是:
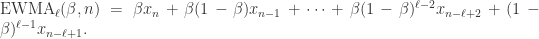
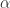 是与
是与 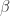 是与
是与  时,
时,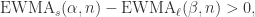 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。注:当
表示短线下穿长线,曲线有下跌的趋势。注:当  时,
时,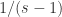 可以看做
可以看做  .
. 。那么
。那么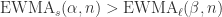


 时,表示时间序列有下跌的趋势。
时,表示时间序列有下跌的趋势。 时,根据假设有
时,根据假设有  ,并且
,并且


 ,通过计算可以得到
,通过计算可以得到  ,也就是说
,也就是说  在
在 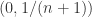 上是递增函数,在
上是递增函数,在  是递减函数。于是当
是递减函数。于是当 


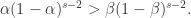
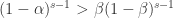 ,那么
,那么  可以写成
可以写成

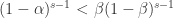 ,那么
,那么 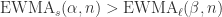 可以写成
可以写成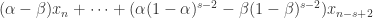

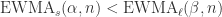 时,也可以使用同样的方法证明时间序列有下跌的趋势。
时,也可以使用同样的方法证明时间序列有下跌的趋势。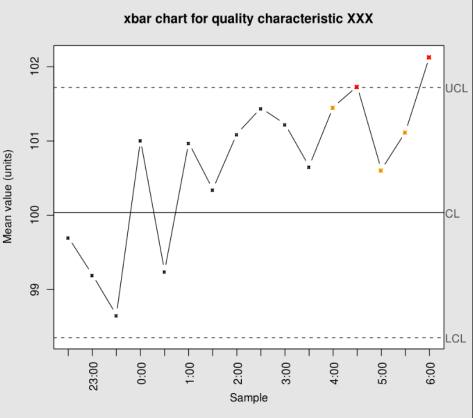
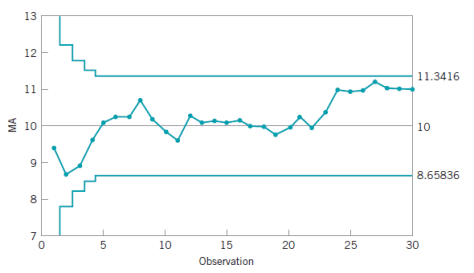
 控制图
控制图![X_{N} = [x_{1},\cdots, x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,为了计算某个时间戳
,为了计算某个时间戳 ![[x_{1},x_{2},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 中的所有点,可以计算出均值和方差如下:
中的所有点,可以计算出均值和方差如下:

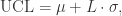


 表示系数,通常选择
表示系数,通常选择  。
。 ,那么说明
,那么说明 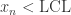 时,那么说明
时,那么说明 
 的方差是
的方差是
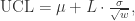

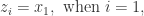

 的方差是:
的方差是:

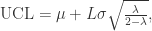

 。
。
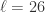 ,
, 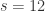 ,
,  ,基于时间序列
,基于时间序列  ,有
,有


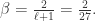

 ,计算 DEA 如下:
,计算 DEA 如下:
 ,
,