
黑盒函数的定义
在工程上和实际场景中,黑盒函数(black box function)指的是只知道输入和输出对应关系,而不知道它的内部结构,同时也不能写出具体表达式的一类函数。正如下图所示,每次给定一组输入,通过黑盒函数的计算,都能够得到一组输出的值,但是却无法写出 Black box 函数的精确表达式。

与之相反的是函数或者系统称之为白盒函数(open system),它不仅能够根据具体的输入获得相应的输出,还能够知道该函数的具体表达式和细节描述。例如 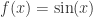

黑盒函数的研究对象
无论是白盒函数还是黑盒函数,都有很多的学术界人士和工业界人士去研究。通常来说,对于一个函数 
- 最大值与最小值,i.e.
和
- 根,i.e.
- 函数的单调性与凹凸性等。


对于具有明显表达式的函数,例如
黑盒函数的根
对于多项式 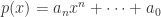
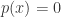

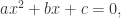

对于一般函数 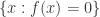
二分法
在数学分析中,介值定理(Intermediate value theorem)描述了连续函数在两点之间的连续性,具体描述是:
[介值定理] 如果连续函数 ![[a,b],](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


从介值定理可以得到,如果我们知道 

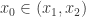

如果要计算 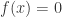
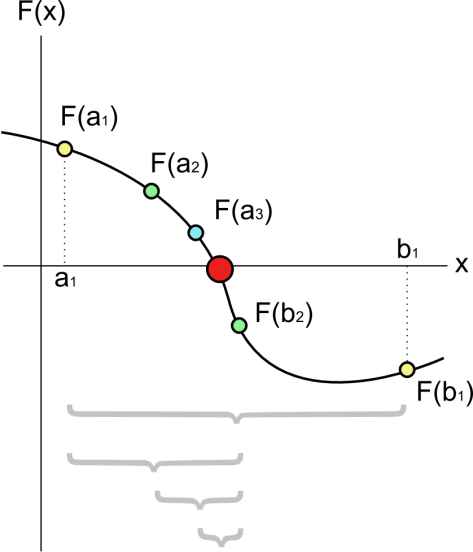
- 先找到一个区间
- 求这个区间的中点
并求出
的取值;
- 如果
那么
就是函数的根;如果
就选择
为新的区间,否则选择
为新的区间;
- 重复第 2 步和第 3 步直到达到最大迭代次数或者最理想的精度为止。

牛顿法(Newton’s Method)
牛顿法的大致思想是:选择一个接近 
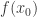
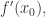
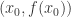
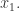

我们可以不停地重复以上过程,就得到一个递推公式:

在一定的条件下,牛顿法必定收敛。也就是说 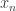


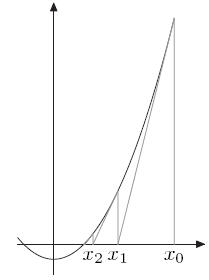
割线法
根据导数的定义:
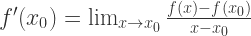
可以得到,当 
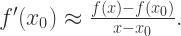
当我们不能够计算
于是,割线法与牛顿法的迭代公式非常相似,写出来就是:

在这里,割线法需要两个初始值 
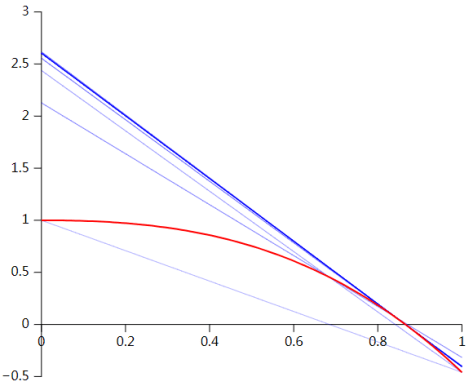
备注
对于黑盒函数而言,我们是不知道它们的表达式的,因此以上的方法和技巧在黑盒函数的使用上就有限制。例如牛顿法是需要计算函数的导数值的,因此不适用在这个场景下。但是对于二分法与割线法,只需要计算函数在某个点的取值即可,因此可以用来寻找黑盒函数的根。
黑盒函数的最大值与最小值
对于能够写出表达式的函数而言,如果要寻找 
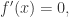
Weierstrass 逼近定理
对于黑盒函数而言,通常来说我们只知道一组输入和相应的输出值。如果只考虑一维的情况而言,那就是 

- 闭区间上的连续函数可以用多项式级数一致逼近;
- 闭区间上的周期为
的连续函数可以用三角函数级数一致逼近。
用数学符号来描述就是:
[Weierstrass 逼近定理] 假设 
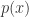
![x\in[a,b],](https://s0.wp.com/latex.php?latex=x%5Cin%5Ba%2Cb%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

因此,如果要计算黑盒函数的最大值和最小值,可以使用一个多项式去拟合这
Lagrange 插值公式
按照之前的符号,如果我们拥有 



于是,要计算黑盒函数的最大值与最小值,就可以转化成计算
除了数学方法之外,机器学习中有一种算法叫做启发式优化算法,也是用来计算黑盒函数的最大值和最小值的,例如粒子群算法与模拟退火算法等。
粒子群算法(Particle Swarm Optimization)


PSO 最初是为了模拟鸟群等动物的群体运动而形成的一种优化算法。PSO 算法是假设有一个粒子群,根据群体粒子和单个粒子的最优效果,来调整每一个粒子的下一步行动方向。假设粒子的个数是 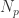

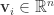

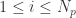
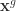
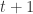
![\bold{v}_{i}(t+1) = \bold{v}_{i}(t) + c r_{1}[\bold{x}_{i}^{*}(t) - \bold{x}_{i}(t)] + c r_{2}[\bold{x}^{g}(t) - \bold{x}_{i}(t)],](https://s0.wp.com/latex.php?latex=%5Cbold%7Bv%7D_%7Bi%7D%28t%2B1%29+%3D+%5Cbold%7Bv%7D_%7Bi%7D%28t%29+%2B+c+r_%7B1%7D%5B%5Cbold%7Bx%7D_%7Bi%7D%5E%7B%2A%7D%28t%29+-+%5Cbold%7Bx%7D_%7Bi%7D%28t%29%5D+%2B+c+r_%7B2%7D%5B%5Cbold%7Bx%7D%5E%7Bg%7D%28t%29+-+%5Cbold%7Bx%7D_%7Bi%7D%28t%29%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
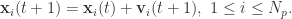
在这里,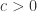

![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
模拟退火(Simulated Annealing)
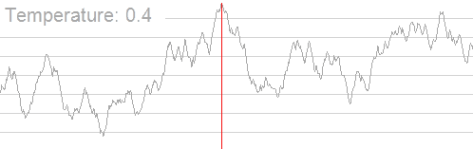
模拟退火算法是为了模拟金属退火现象。其核心思想是构造了温度 
模拟退火的大体思路是这样的:先设置一个较大的温度值 


Repeat:
a. Repeat:
i. 进行一个随机扰动 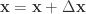
ii. 计算 
如果 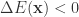


否则,按照 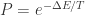

b. 令 
直到
总结
本文从数学和机器学习的角度,简要介绍了部分计算黑盒函数的最大值,最小值和根的方法,后续将会介绍更多的类似方法。
