
GOOD
Together with Joseph Modayil, this year I am teaching the part on reinforcement learning of the Advanced Topics in Machine Learning course at UCL.
Lectures
Note that there will be two lectures about AlphaGo on March 24. We will talk about AlphaGo in the context of the whole course at the normal place and time (9:15am in Roberts 412), and in addition David Silver will give a seminar that afternoon. Neither of these will be required for the exam.
- Introduction to reinforcement learning updated January 14 (Lecture: January 14)
- Exploration and Exploitation updated January 21 (Lecture: January 21)
- Markov decision processes updated January 27 (Lecture: January 28)
- Dynamic programming updated February 3 (Lecture: February 4)
- Learning to predict updated February 10 (Lecture: February 11)
- Learning to control updated March 16 (Lecture: February 25)
- Value function approximation updated March 2 (Lecture: March 3)
- Policy-gradient algorithms updated March 9 (Lecture:…
View original post 51 more words


 ,动作是
,动作是  。该 agent 的策略定义为在状态
。该 agent 的策略定义为在状态 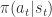 。如果折扣因子是
。如果折扣因子是  ,那么基于策略
,那么基于策略 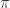 的动作值函数就定义为:
的动作值函数就定义为:![Q^{\pi}(s,a)=E[\sum_{i=0}^{\infty}\gamma^{i}r_{t+i}|s_{t}=s, a_{t}=a]](https://s0.wp.com/latex.php?latex=Q%5E%7B%5Cpi%7D%28s%2Ca%29%3DE%5B%5Csum_%7Bi%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5E%7Bi%7Dr_%7Bt%2Bi%7D%7Cs_%7Bt%7D%3Ds%2C+a_%7Bt%7D%3Da%5D&bg=ffffff&fg=2b2b2b&s=1&c=20201002) .
.
 是在状态
是在状态 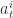 是
是  是某个常数。
是某个常数。
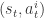 ,使用相应的神经网络同时把
,使用相应的神经网络同时把  和
和 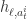 ,然后计算这两个向量的内积
,然后计算这两个向量的内积  ,最后选择
,最后选择 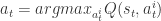 作为当前状态的动作。其中,
作为当前状态的动作。其中, 分别指的是状态网络和动作网络的第
分别指的是状态网络和动作网络的第 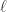 个隐藏层神经网络的输出。
个隐藏层神经网络的输出。 ,
,  和
和  ,
, 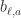 是在第
是在第  层和第
层和第 

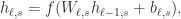

 。Q 值函数定义为
。Q 值函数定义为  ,其中 g 可以定义为两个向量的内积。
,其中 g 可以定义为两个向量的内积。
