
随着深度学习的发展,word2vec 等技术的兴起,无论是 NLP 中的词语,句子还是段落,都有着各种各样的嵌入形式,也就是把词语,句子,段落等内容转换成一个欧氏空间中的向量。然后使用机器学习的方法来进行文本的聚类和相似度的提取,甚至进行情感分类等操作。那么在表示学习(Representation Learning)方向上,除了刚刚提到的自然语言之外,语音,图像,甚至图论中的Graph都可以进行嵌入的操作,于是就有了各种各样的表示算法。既然提到了表示学习,或者特征提取的方法,而且在标注较少的情况下,各种无监督的特征提取算法就有着自己的用武之地。除了 NLP 中的 word2vec 之外,自编码器(Auto Encoder)也是一种无监督的数据压缩算法,或者说特征提取算法。本文将会从自编码器的基础内容出发,在时间序列的业务场景下,逐步展开基于自编码器的时间序列表示方法,并且最终如何应用与时间序列异常检测上。
自编码器
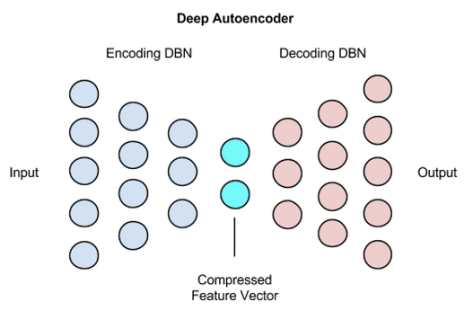
提到自编码器(Auto Encoder),其实它就是一种数据压缩算法或者特征提取算法。自编码器包含两个部分,分别是编码层(encoder)和解码层(decoder),分别可以使用 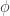
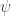

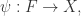

其目标函数就是为了拟合一个恒等函数。对于最简单的情况,可以令 



损失函数就是 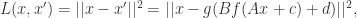
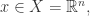





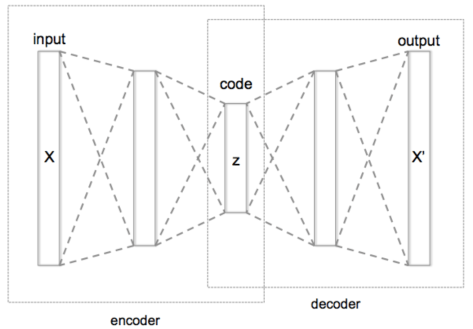
对于自编码器而言,它的输入层的维度等于输出层的维度,隐藏层的维度是需要小于输入层的维度的。只有这样,自编码器才可以学习到数据分布的最显著特征。如果隐藏层的维度大于或者等于输入层的维度,其实是没有任何意义的,具体的解释可以参考下面这个Claim。
Claim. 对于自编码器而言,其中隐藏层的维度 

Proof. 如果 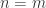




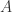

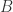



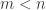
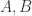
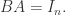
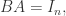

这就导致了矛盾。因此,只有在
对于自编码器而言,其本质上也是一个神经网络,那么它的激活函数其实不仅可以选择 sigmoid, 还可以使用 tanh,ReLU,LeakyReLU 等其余激活函数,其本质上都是为了拟合一个恒等变换,中间层则作为一个特征提取的工具。在训练的时候,同样是使用反向传播算法,可以使用不同的优化函数,例如 SGD,Momentum,AdaGrad,RMSProp,Adam 等。
在图像领域,有学者尝试使用自编码器来进行图像的重构工作,图像的特征提取等内容,整体来看也能达到不错的效果,请看下图:

从上图来看,基于均方误差的自编码器是无法重构出乒乓球的。由于该自编码器的容量有限,目标函数是均方误差,因此自编码器并没有意识到乒乓球是图片中的一个重要物品。
时间序列异常检测:
时间序列异常检测一直是学术界和工业界都关注的问题,无论使用传统的 Holt-Winters,ARIMA,还是有监督算法进行异常检测,都是统计学和传统机器学习的范畴。那么随着深度学习的兴起,是否存在某种深度学习算法来进行异常检测呢?其实是存在的。请看上图,左边一幅图有一个白色的小乒乓球,但是随着自编码器进行重构了之后,白色的小乒乓球已经在重构的图像中消失了。那么根据异常检测的观点来看,小乒乓球其实就可以作为图片中的异常点。只要在图片的局部,重构出来的图片和之前的图片存在着巨大的误差,那么原始图片上的点就有理由认为是异常点。
在这个思想下,针对时间序列异常检测而言,异常对于正常来说其实是少数。如果我们使用自编码器重构出来的时间序列跟之前有所差异的话,其实我们就有理由认为当前的时间序列存在了异常。其实,简单来看,基于自编码器的时间序列异常检测算法就是这样的:
原始时间序列
-> Auto Encoder(Encoder 和 Decoder)
-> 重构后的时间序列
-> 通过重构后的时间序列与原始时间序列的整体误差和局部误差来判断异常点
简单来说,只要输出的时间序列在局部的信息跟原始的时间序列不太一致,就有理由认为原始的时间序列存在着异常。
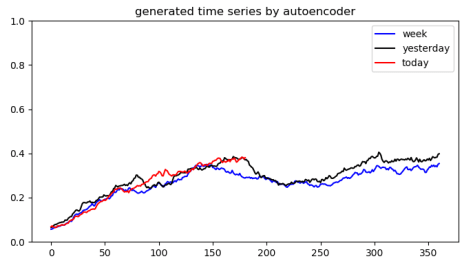
那么,首先我们需要提取时间序列中的一些子序列,例如我们可以提取今天(today),昨天(yesterday),一周前(week)的数据,基于同样的时间戳把它们重叠在一起,也就是下图这个形式。其中,蓝线表示一周前的数据,黑线表示昨天的数据,红色表示今天的数据。
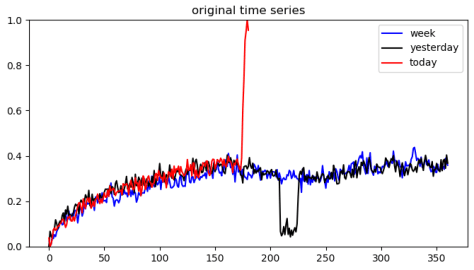
基于一条很长的时间序列,我们可以提取它的很多子序列,从而构造出很多的片段序列。这些片段序列就可以形成自编码器的输入数据,而自编码器是模拟一个恒等变换,因此它会把有异常的点尽量磨平,而正常的点则保持原样。所以,通过大量子片段来进行训练数据的输入,自编码器就能够得到一个较为合理的权重。得到了一个训练好的自编码器之后,对于任何一个子片段,都可以重构出一个新的片段。例如上面的子片段就可以重构成下图:对于今天的数据(today),那个凸起被直接抹平;对于昨天的数据(yesterday)而言,那个凹下去的部分也被磨平。基于时间序列重构前和重构后的数据差异,可以获得时间序列的异常点。
除此之外,还有很多时间序列的异常点可以被自编码器(AutoEncoder)发现,例如下面四幅图,无论是上涨,还是下跌,其实都可以被自编码器(AutoEncoder)发现异常。








总结
通常来说,在时间序列异常检测场景中,异常的比例相对于正常的比例而言都是非常稀少的。因此,除了有监督算法(分类,回归)之外,基于无监督算法的异常检测算法也是必不可少的。除了 HoltWinters,ARIMA 等算法之外,本文尝试了一种新的异常检测算法,基于深度学习模型,利用自编码器的重构误差和局部误差,针对时间序列的异常检测的场景,初步达到了一个还不错的效果。这种方法可以用来提供部分异常样本,加大异常检测召回率的作用。但是这种方法也有一定的弊端:
- 从理论上说,它只能对一个时间序列单独训练一个模型,不同类型的时间序列需要使用不同的模型。这样的话,其实维护模型的成本比较高,不太适用于大规模的时间序列异常检测场景;
- 对周期型的曲线效果比较好,如果是毛刺型的数据,有可能就不太适用;因为长期的毛刺型数据就可以看成正常的数据了。
- 每次调参需要人为设置一定的阈值,不同的时间序列所需要的阈值是不一样的。
参考文献
- Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications, Haowen XU, etc., 2018
- Deep Learning, Ian Goodfellow, etc., 2016
- https://zr9558.com/2016/06/12/replicator-neural-networks/

这个实现中每层的维度是怎么确定的,例如求P(Z|X)均值、方差这层的输出维度应该如何确定,假设原始输入数据集是MNIST,这种二值的
LikeLike