
在机器学习领域,聚类问题一直是一个非常常见的问题。无论是在传统的机器学习(Machine Learning)领域,还是自然语言处理(Natural Language Processing)领域,都可以用聚类算法做很多的事情。例如在数据分析领域,我们可以把某个物品用特征来描述出来,例如该房子的面积,价格,朝向等内容,然后使用聚类算法来把相似的房子聚集到一起;在自然语言处理领域,通常都会寻找一些相似的新闻或者把相似的文本信息聚集到一起,在这种情况下,可以用 Word2Vec 把自然语言处理成向量特征,然后使用 KMeans 等机器学习算法来作聚类。除此之外,另外一种做法是使用 Jaccard 相似度来计算两个文本内容之间的相似性,然后使用层次聚类(Hierarchical Clustering)的方法来作聚类。
本文将会从常见的聚类算法出发,然后介绍时间序列聚类的常见算法。
机器学习的聚类算法
KMeans — 基于距离的机器学习聚类算法
KMeans 算法的目的是把欧氏空间 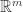

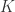
从数学语言上来说,假设已知的欧式空间点集为 

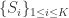



上面的 
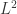

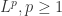
层次聚类 — 基于相似性的机器学习聚类算法
层次聚类通常来说有两种方法,一种是凝聚,另外一种是分裂。
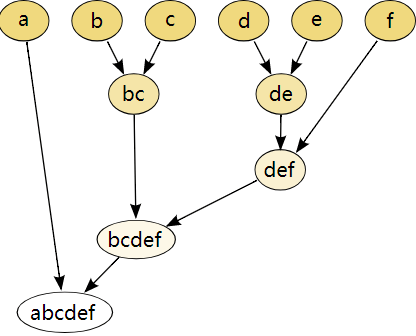
所谓凝聚,其大体思想就是在一开始的时候,把点集集合中的每个元素都当做一类,然后计算每两个类之前的相似度,也就是元素与元素之间的距离;然后计算集合与集合之前的距离,把相似的集合放在一起,不相似的集合就不需要合并;不停地重复以上操作,直到达到某个限制条件或者不能够继续合并集合为止。
所谓分裂,正好与聚合方法相反。其大体思想就是在刚开始的时候把所有元素都放在一类里面,然后计算两个元素之间的相似性,把不相似元素或者集合进行划分,直到达到某个限制条件或者不能够继续分裂集合为止。
在层次聚类里面,相似度的计算函数就是关键所在。在这种情况下,可以设置两个元素之间的距离公式,例如欧氏空间中两个点的欧式距离。在这种情况下,距离越小表示两者之间越相似,距离越大则表示两者之间越不相似。除此之外,还可以设置两个元素之间的相似度。例如两个集合中的公共元素的个数就可以作为这两个集合之间的相似性。在文本里面,通常可以计算句子和句子的相似度,简单来看就是计算两个句子之间的公共词语的个数。
时间序列的聚类算法
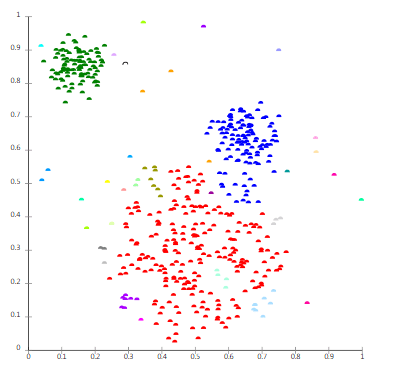
通过以上的描述,如果要做时间序列的聚类,通常来说也有多种方法来做,可以使用基于距离的聚类算法 KMeans,也可以使用基于相似度计算的层次聚类算法。
时间序列的特征提取
之前写过很多时间序列特征提取的方法,无论是常见的时间序列特征,例如最大值,最小值,均值,中位数,方差,值域等内容之外。还可以计算时间序列的熵以及分桶的情况,其分桶的熵指的是把时间序列的值域进行切分,就像 Lebesgue 积分一样,查看落入那些等分桶的时间序列的概率分布情况,就可以进行时间序列的分类。除了 Binned Entropy 之外,还有 Sample Entropy 等各种各样的特征。除了时域特征之外,也可以对时间序列的频域做特征,例如小波分析,傅里叶分析等等。因此,在这种情况下,其实只要做好了时间序列的特征,使用 KMeans 算法就可以得到时间序列的聚类效果,也就是把相似的曲线放在一起。参考文章:时间序列的表示与信息提取。
在提取时间序列的特征之前,通常可以对时间序列进行基线的提取,把时间序列分成基线和误差项。而基线提取的最简单方法就是进行移动平均算法的拟合过程,在这种情况下,可以把原始的时间序列 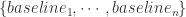


时间序列的相似度计算
如果要计算时间序列的相似度,通常来说除了欧几里得距离等 



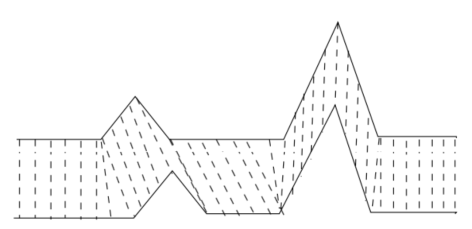
如果不考虑时间序列的“扭曲”的话,也可以直接使用欧氏距离,无论是 
除此之外,我们也可以用 Auto Encoder 等自编码器技术对时间序列进行特征的编码,也就是说该自编码器的输入层和输出层是恒等的,中间层的神经元个数少于输入层和输出层。在这种情况下,是可以做到对时间序列进行特征的压缩和构造的。除了 Auto Encoder 等无监督方法之外,如果使用其他有监督的神经网络结构的话,例如前馈神经网络,循环神经网络,卷积神经网络等网络结构,可以把归一化之后的时间序列当做输入层,输出层就是时间序列的各种标签,无论是该时间序列的形状种类还是时间序列的异常/正常标签。当该神经网络训练好了之后,中间层的输出都可以作为 Time Series To Vector 的一种模式。i.e. 也就是把时间序列压缩成一个更短一点的向量,然后基于 COSINE 相似度等方法来计算原始时间序列的相似度。参考文章:基于自编码器的时间序列异常检测算法,基于前馈神经网络的时间序列异常检测算法。
总结
如果想对时间序列进行聚类,其方法是非常多的。无论是时间序列的特征构造,还是时间序列的相似度方法,都是需要基于一些人工经验来做的。如果使用深度学习的方法的话,要么就提供大量的标签数据;要么就只能够使用一些无监督的编码器的方法了。本文目前初步介绍了一些时间序列的聚类算法,后续将会基于笔者的学习情况来做进一步的撰写工作。
参考文献
- 聚类分析:https://en.wikipedia.org/wiki/Cluster_analysis
- Dynamic Time Warping:https://en.wikipedia.org/wiki/Dynamic_time_warping
- Pearson Coefficient:https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
- Auto Encoder:https://en.wikipedia.org/wiki/Autoencoder
- Word2Vec:https://en.wikipedia.org/wiki/Word2vec,https://samyzaf.com/ML/nlp/nlp.html
