
在信息论和概率论里面,Kullback-Leibler 散度(简称KL散度,KL divergence)是两个概率分布 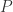
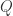

KL 散度的数学定义:
对于离散空间的两个概率分布

换句话说,它是两个概率分布 

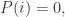
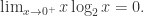
对于连续空间 

这里的 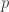
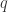
KL 散度的基本性质:
(1)KL 散度总是非负的,并且只有 
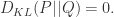
证明:利用Jensen’s Inequality。
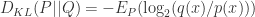
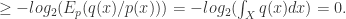
(2)如果 
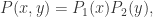


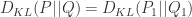

(3)如果定义分布
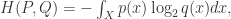
分布

那么
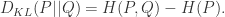
(4)KL 散度是两个概率分布
(5)从KL散度的定义可以得出

所以 KL 散度不满足距离的对称性。当然,如果需要把它弄成对称的,可以定义


简单例子:
比如有四个类别,一个方法 P 得到四个类别的概率分别是0.1,0.2,0.3,0.4。另一种方法 Q(或者说是事实情况)是得到四个类别的概率分别是0.4,0.3,0.2,0.1,那么这两个分布的 KL 散度就是
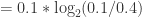

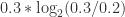

案例分析:
在实际的工作中,我们通常会有某个网页或者app被用户点击或者播放的数据,同时,我们会拥有用户画像(personas),此刻我们关心的问题就是如何计算网页里面的某个新闻或者app里面的某个专辑受到不同维度的用户画像的喜好程度。比如,如何判断该新闻是受到各个年龄层的用户的喜爱还是只是受到某个年龄层的用户的喜爱?如何判断某个电台节目是受到大众的喜爱还是更加受到男性或者女性的喜爱?此时,怎么计算物品被用户的喜欢程度就成为了一个重要的关键。
通常的方案就是,比方说:某个电台专辑被66.7%的男性用户播放过,被33.3%的女性用户播放过,那么该物品是不是真的就是更加受到男性用户的青睐呢?答案是否定的。如果使用这款app的用户的男女比例恰好是1:1,那么根据以上数据,该电台专辑显然更加受到男性用户的喜爱。但是,实际的情况,使用这款app的用户的男女比例不完全是1:1。如果男性用户:女性用户=2:1的话,如果某个电台专辑被66.7%的男性用户播放过,被33.3%的女性用户播放过,那么说明该专辑深受男女喜欢,两者对该专辑的喜好程度是一样的。因为基础的男女比例是2:1,该专辑被男女播放的比例是2:1,所以,该专辑对男女的喜爱程度恰好是1:1。
那么如何计算该专辑的喜好程度呢?首先我们会使用KL散度来描述这件事情。
 函数的输入是一组实数,那么对该函数进行近似的时候,最简单的方案就是
函数的输入是一组实数,那么对该函数进行近似的时候,最简单的方案就是 。在这里,
。在这里,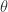 是这个函数的斜率,也就是这个函数
是这个函数的斜率,也就是这个函数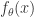 的参数。机器学习就是通过对这个参数的学习,完成函数的近似计算。这个模型对于
的参数。机器学习就是通过对这个参数的学习,完成函数的近似计算。这个模型对于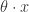 扩展成如下形式:
扩展成如下形式: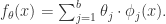
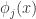 是基函数向量
是基函数向量 的第
的第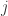 个分量,
个分量, 是
是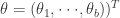 的第
的第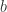

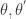 和
和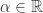 ,满足
,满足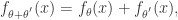


![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上的连续函数,对于任意的
上的连续函数,对于任意的 ,则存在多项式
,则存在多项式 使得对于所有的
使得对于所有的![x\in [a,b]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,有
,有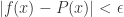
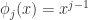
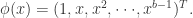
 的非线性函数,而且
的非线性函数,而且 可以逼近关于
可以逼近关于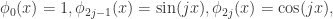 其中
其中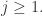
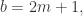
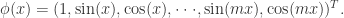
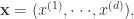 函数依旧可以扩展成如下模式:
函数依旧可以扩展成如下模式: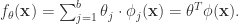
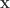
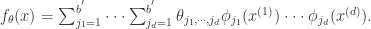
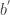 是各个维数的参数个数。对于这个模型而言,它的表现力十分丰富,但是不足之处在于所有的参数个数是
是各个维数的参数个数。对于这个模型而言,它的表现力十分丰富,但是不足之处在于所有的参数个数是 是一个非常巨大的数字,导致的维数灾难,所以在实际运用中,不主张用这个模型。
是一个非常巨大的数字,导致的维数灾难,所以在实际运用中,不主张用这个模型。
 它是一个关于维数
它是一个关于维数
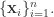
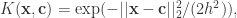
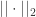
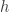


 有
有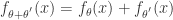 和
和  对于核函数来说,无论输入的是一维变量还是高维变量,核函数都可以容易的进行扩展。
对于核函数来说,无论输入的是一维变量还是高维变量,核函数都可以容易的进行扩展。
 是关于参数向量
是关于参数向量 的基函数,层级模型是基于参数向量
的基函数,层级模型是基于参数向量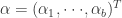 的线性形式。同时也包含参数向量
的线性形式。同时也包含参数向量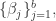 所以层级模型是基于参数向量
所以层级模型是基于参数向量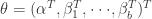 的非线性形式。
的非线性形式。 其中
其中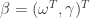
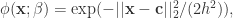 其中
其中
