(一)珍惜自己的时间和精力
当年在国外留学,有一次挂着QQ开始自习,突然QQ发出提示,结果定睛一看,是一位长久不联系的同学发来了消息。于是开始一阵寒暄之后,同学就开始问“你什么时候回国啊?帮我带一个iPhone好不好?听说国外比较便宜”之类的话。对于这种场景,想必各位留学生都不陌生。由于汇率差等一些因素,香港和新加坡的电子产品一般来说比国内会便宜一些,总会有国内各种各样的同学联系国外的同学,求帮忙带各种各样的物品。小到 iPod,大到 Mac Pro,甚至会有衣服和化妆品。
能够提出这种要求的人认为留学生在国外学习生活,平时闲着无事可做,顺便去商场买一个 iPhone 或者化妆品轻而易举。再说,反正这个留学生会回国,回国的时候顺便塞在箱子里面就可以带回来了,也不用国际邮递的费用,举手之劳而已。这种时候,不同的留学生就会有不同的处理方案,有一种是有求必应,导致自己回国的箱子塞满了其他人的行李。另外一种是置之不理,只带着自己应该携带的行李。
第一种人呢,就是传统意义上的老好人。这种人对其他人的要求都是有求必应,别人随便说的一句话,顺口提的一个要求都会极大可能地去满足对方,哪怕自己亏本。其实,对于一个留学生而言,时间就是金钱,无论是去商场买东西还是在网上下单购物都会耗费大量的时间。曾经见过一位留学生花了很多时间去商场帮忙代购奢侈品,回国的时候却因为颜色略有不同,对方拒不买单的情况。导致这些结果,都是因为一些留学生在无形之中当了一次老好人,认为别人只是提了一个要求,自己应该完成。不过请别忘记,求别人帮忙是需要人情的,国内的朋友求留学生带iPhone,就已经欠了留学生一个人情。而且在这个过程中,留学生的时间成本被无限度的降低,代购在对方的眼里就只是一个不需要成本的事情。而真正的朋友,会尊重对方的付出,会时刻维持着这一份友谊。
(二)不要有求必应
博士生一般都会承担每周6小时甚至更多的助教任务,在这几个小时内,需要给本科生开设课程,讲解习题,有的时候还需要给本科生批改作业。在考试前夕,就有学生有问题需要来咨询博士生。本来,博士生作为助教,是有义务给本科生讲解习题的。但是,总有一些本科生,会在考试前提出各种各样无理的要求,比如“再把这门课从头到尾给我讲解一遍,把这套试卷给我讲解一下”之类的。在我眼里,能提出这种要求的学生,基本上考试也就这样了,讲不讲已经基本上不重要了。作为一个大学生,自己需要为自己的选择买单,平时不花时间学习,一天晚上就想搞定高分几乎是一件不可能的事情。对于这些学生,自己的选择一般都是提出建议:“你可以去数学系五楼的答疑教室,那里会有助教给你详细地讲解问题”。
但是,也有一些助教,不会拒绝学生,为了满足学生的这些需求,在考试前不吃饭不睡觉,时刻保持email在线,随时准备回答学生提出的各种各样的问题。对于学生提出了需要当面答疑的要求也从不拒绝,从早上9点一直干到晚上11点,每两个小时就安排一批学生答疑。当然这种对工作负责任的精神值得大家学习,不过这种方式实在是不可取。作为一个PHD,首要任务就是科研,教学只是不那么重要的一件事情,只要不出教学事故,不收到学生投诉即可。就目前的就业情况来看,科研论文才是王道,为了学生付出太多实在是舍本逐末。退一万步讲,能够提出让助教花费整个晚上为他答疑这种要求的本科生,只是把助教当成了一个可以有求必应的人,只是把这个职业当成了服务性的职业,认为交了学费就应该享受到这些服务。对于这些学生,实在是不值得花费博士生过多的精力。数学系本来就给本科生开设了 Consultation Room,在非助教工作时间完全可以把答疑的工作推给这些地方,因为只有这些地方才是专门为了学生答疑而设置的机构,而不是私底下给学生们答疑。学会对一些不合理的要求说“不”是一个非常重要的能力。
(三)不要成为别人情绪的垃圾桶
想必大家都在玩腾讯的两大产品,微信和QQ。在微信或者QQ上面,总会有人时刻传递着各种负能量,随便抓住一个朋友就开始抱怨自己的生活多么不如意,自己的人生有多么的艰难。偶尔一两次当然无所谓,就当是开导朋友,帮朋友一把也是一种义务。但是,如果天天抱怨这些事情而没有任何正能量,就会让人产生一种厌恶。使用微信或者QQ是为了达成一种信息的交换,如果一方一直产生负能量,就会在无形之中把这种负能量传递给其他人,从而影响到其他人的生活。
在读本科的时候,大家或许还会互相关心一下对方在做什么。到了工作岗位之后,其他人做什么样的事情其实已经和自己没有太大关系了,尤其是不在同一个公司,同一个城市,甚至同一个行业的人。一些整天抱怨行业或者运气不好的人,何必不鼓起勇气跳出圈子,去寻找想要的东西。在微信或者QQ上抱怨并不能够解决任何问题,能够摆脱这种现状只有靠自己的努力,而不是当一个键盘侠。对于一些整天传播负能量的人,最好的办法就是屏蔽他们,避免他们的情绪影响到自己的生活。
每个人都在一天天地成长,在帮助别人的同时也在接受着其他人的帮助。对于别人小小的帮助,要学会感恩。在帮助他人的时候,也要学会明辨是非,拒绝成为一个老好人。
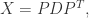
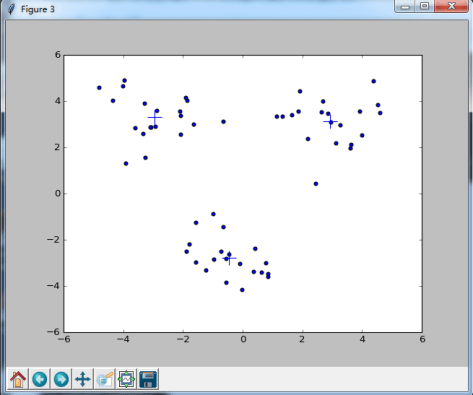
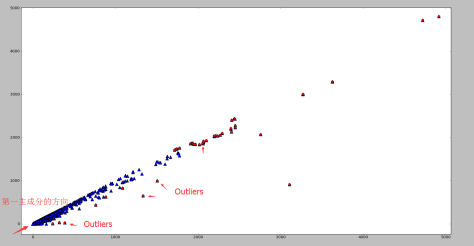
 。从图像上看,一个特征向量可以看成 2 维平面上面的一条线,或者高维空间里面的一个超平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,可以把对角矩阵 D 中的特征值进行从大到小的排序,矩阵 P 的每一列也进行相应的调整,保证 P 的第 i 列对应的是 D 的第 i 个对角值。
。从图像上看,一个特征向量可以看成 2 维平面上面的一条线,或者高维空间里面的一个超平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,可以把对角矩阵 D 中的特征值进行从大到小的排序,矩阵 P 的每一列也进行相应的调整,保证 P 的第 i 列对应的是 D 的第 i 个对角值。

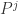 是矩阵 P 的前 j 列,也就是说
是矩阵 P 的前 j 列,也就是说 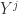 是一个 (N,j) 维的矩阵。如果考虑拉回映射的话(也就是从主成分空间映射到原始空间),重构之后的数据集合是
是一个 (N,j) 维的矩阵。如果考虑拉回映射的话(也就是从主成分空间映射到原始空间),重构之后的数据集合是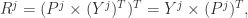
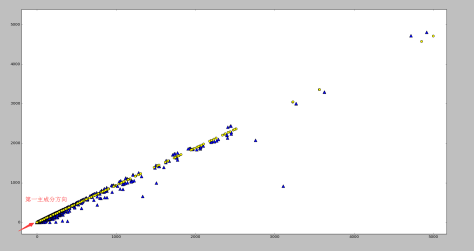
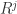 是使用 top-j 的主成分进行重构之后形成的数据集,是一个 (N,p) 维的矩阵。
是使用 top-j 的主成分进行重构之后形成的数据集,是一个 (N,p) 维的矩阵。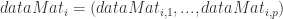 的异常值分数(outlier score)如下:
的异常值分数(outlier score)如下: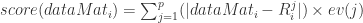
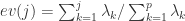
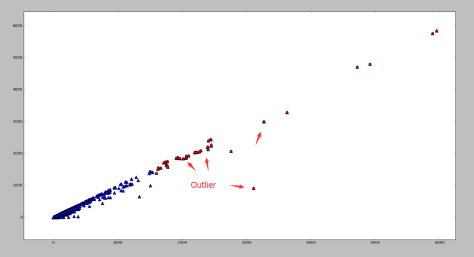
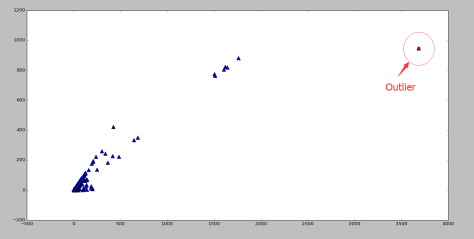
 指的是 Euclidean 范数, ev(j) 表示的是 top-j 的主成分在所有主成分中所占的比例,并且特征值是按照从大到小的顺序排列的。因此,ev(j) 是递增的序列,这就表示 j 越高,越多的方差就会被考虑在 ev(j) 中,因为是从 1 到 j 的求和。在这个定义下,偏差最大的第一个主成分获得最小的权重,偏差最小的最后一个主成分获得了最大的权重 1。根据 PCA 的性质,异常点在最后一个主成分上有着较大的偏差,因此可以获得更高的分数。
指的是 Euclidean 范数, ev(j) 表示的是 top-j 的主成分在所有主成分中所占的比例,并且特征值是按照从大到小的顺序排列的。因此,ev(j) 是递增的序列,这就表示 j 越高,越多的方差就会被考虑在 ev(j) 中,因为是从 1 到 j 的求和。在这个定义下,偏差最大的第一个主成分获得最小的权重,偏差最小的最后一个主成分获得了最大的权重 1。根据 PCA 的性质,异常点在最后一个主成分上有着较大的偏差,因此可以获得更高的分数。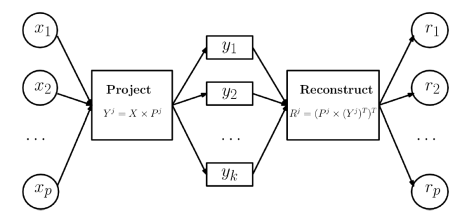
 ,那么可以计算出这 n 个点的均值
,那么可以计算出这 n 个点的均值 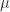 和方差
和方差 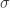 。均值和方差分别被定义为:
。均值和方差分别被定义为: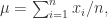

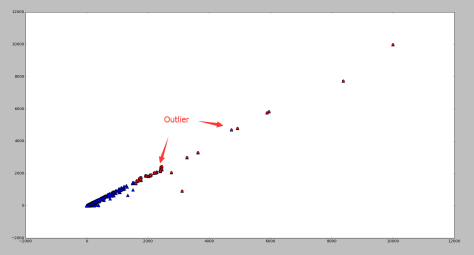
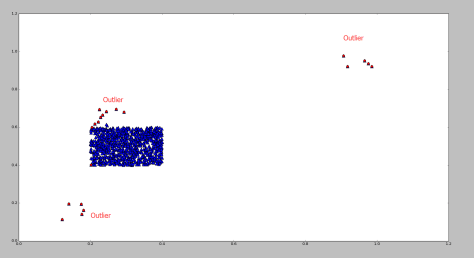
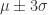 包含了99.7% 的数据,如果某个值距离分布的均值
包含了99.7% 的数据,如果某个值距离分布的均值  ,那么这个值就可以被简单的标记为一个异常点(outlier)。
,那么这个值就可以被简单的标记为一个异常点(outlier)。 ,那么可以计算每个维度的均值和方差
,那么可以计算每个维度的均值和方差  具体来说,对于
具体来说,对于  ,可以计算
,可以计算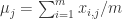
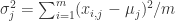
 ,可以计算概率
,可以计算概率 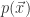 如下:
如下:
 ,可以计算 n 维的均值向量
,可以计算 n 维的均值向量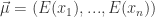
 的协方差矩阵:
的协方差矩阵:![\Sigma=[Cov(x_{i},x_{j})], i,j \in \{1,...,n\}](https://s0.wp.com/latex.php?latex=%5CSigma%3D%5BCov%28x_%7Bi%7D%2Cx_%7Bj%7D%29%5D%2C+i%2Cj+%5Cin+%5C%7B1%2C...%2Cn%5C%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

 是均值向量,那么对于数据集 D 中的其他对象
是均值向量,那么对于数据集 D 中的其他对象  ,从
,从 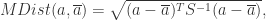
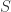 是协方差矩阵。
是协方差矩阵。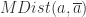 是数值,可以对这个数值进行排序,如果数值过大,那么就可以认为点
是数值,可以对这个数值进行排序,如果数值过大,那么就可以认为点  进行离群点检测,如果
进行离群点检测,如果 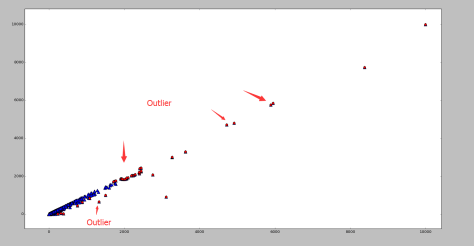
 统计量检测多元离群点
统计量检测多元离群点 ,
,
 是
是  是所有对象在第 i 维的均值,n 是维度。如果对象
是所有对象在第 i 维的均值,n 是维度。如果对象 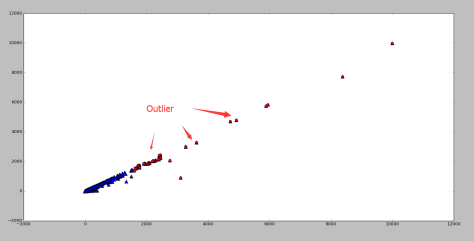
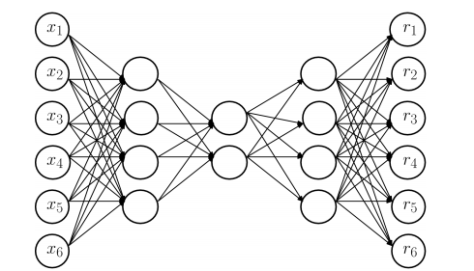

 ,其中
,其中 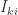 表示第 k 层中第 i 个神经元的输入,
表示第 k 层中第 i 个神经元的输入, 表示第 k 层使用的激活函数。那么
表示第 k 层使用的激活函数。那么
 是第 k 层中第 j 个神经元的输出,
是第 k 层中第 j 个神经元的输出, 是第 k 层神经元的个数。对于第二层和第四层而言 (k=2,4),激活函数选择为
是第 k 层神经元的个数。对于第二层和第四层而言 (k=2,4),激活函数选择为
 是一个参数,通常假设为1。对于中间层 (k=3) 而言,激活函数是一个类阶梯 (step-like) 函数。有两个参数 N 和
是一个参数,通常假设为1。对于中间层 (k=3) 而言,激活函数是一个类阶梯 (step-like) 函数。有两个参数 N 和  ,N 表示阶梯的个数,
,N 表示阶梯的个数,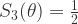 +
+ .
. ,
, . 那么
. 那么  就如下图所示。
就如下图所示。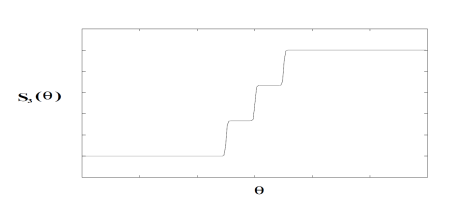
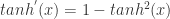 和
和  。因此有学者指出 [1],使用三个隐藏层是没有必要的,使用1个或者2个隐藏层的神经网络也能够得到类似的结果;同样,没有必要使用
。因此有学者指出 [1],使用三个隐藏层是没有必要的,使用1个或者2个隐藏层的神经网络也能够得到类似的结果;同样,没有必要使用 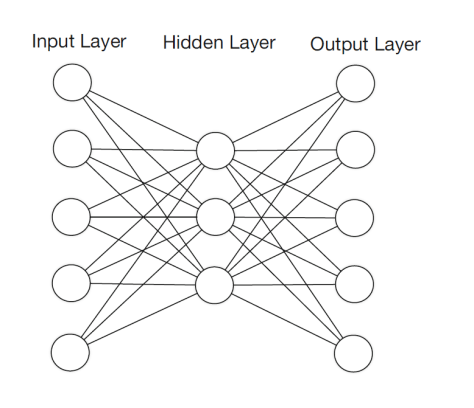
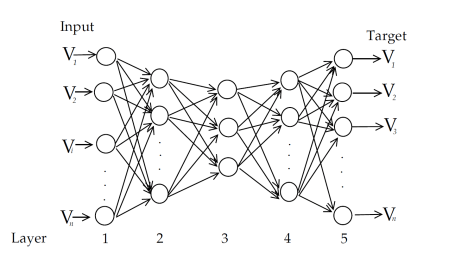
 ,其中有 m 个样本,并且输入和输出是一样的值。换句话说,也就是 n 维向量
,其中有 m 个样本,并且输入和输出是一样的值。换句话说,也就是 n 维向量 .
.![q=[(n+1)/2]](https://s0.wp.com/latex.php?latex=q%3D%5B%28n%2B1%29%2F2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,这里的 [] 表示 Gauss 取整函数。输出层第 j 个神经元的阈值使用
,这里的 [] 表示 Gauss 取整函数。输出层第 j 个神经元的阈值使用  表示,隐藏层第 h 个神经元的阈值使用
表示,隐藏层第 h 个神经元的阈值使用 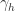 表示。输入层第 i 个神经元与隐藏层第 h 个神经元之间的连接权重是
表示。输入层第 i 个神经元与隐藏层第 h 个神经元之间的连接权重是  , 隐藏层第 h 个神经元与输出层第 j 个神经元之间的连接权重是
, 隐藏层第 h 个神经元与输出层第 j 个神经元之间的连接权重是  其中
其中 



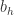 是隐藏层第 h 个神经元的输出,
是隐藏层第 h 个神经元的输出,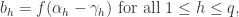
 是激活函数。写成矩阵形式就是:
是激活函数。写成矩阵形式就是: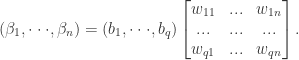
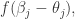 其中
其中 
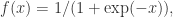 那么直接通过导数计算可以得到
那么直接通过导数计算可以得到 
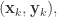 通过神经网络得到的输出是
通过神经网络得到的输出是  并且
并且  对于
对于 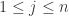 都成立。那么神经网络在训练集
都成立。那么神经网络在训练集  的均方误差是
的均方误差是
 整体的误差是
整体的误差是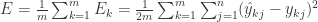
 +
+
 来获得更新规则,下面来推导每一个参数的更新规则。对于
来获得更新规则,下面来推导每一个参数的更新规则。对于  计算梯度
计算梯度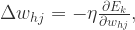
 先影响到第 j 个输出层神经元的输入值
先影响到第 j 个输出层神经元的输入值  再影响到第 j 个输出层神经元的输出值
再影响到第 j 个输出层神经元的输出值  ,最后影响到
,最后影响到 
 可以得到
可以得到  对于
对于  可以得到
可以得到 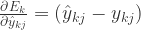 .
. 和
和  可以得到
可以得到 

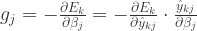

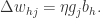
 .
.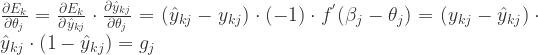




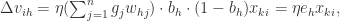 其中
其中 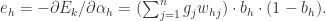

 +
+ 并且更新的规则如下:
并且更新的规则如下:



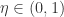 控制着算法每一轮迭代中的更新步长,若步长太大则容易振荡,太小则收敛速度过慢,需要人工调整学习率。 对每个训练样例,BP 算法执行下面的步骤:先把输入样例提供给输入层神经元,然后逐层将信号往前传,直到计算出输出层的结果;然后根据输出层的误差,再将误差逆向传播至隐藏层的神经元,根据隐藏层的神经元误差来对连接权和阈值进行迭代(梯度下降法)。该迭代过程循环进行,直到达到某个停止条件为止。
控制着算法每一轮迭代中的更新步长,若步长太大则容易振荡,太小则收敛速度过慢,需要人工调整学习率。 对每个训练样例,BP 算法执行下面的步骤:先把输入样例提供给输入层神经元,然后逐层将信号往前传,直到计算出输出层的结果;然后根据输出层的误差,再将误差逆向传播至隐藏层的神经元,根据隐藏层的神经元误差来对连接权和阈值进行迭代(梯度下降法)。该迭代过程循环进行,直到达到某个停止条件为止。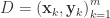 和学习率
和学习率 

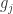
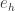
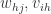 与阈值
与阈值 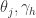
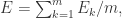 其中 m 是训练集合中样本的个数。不过,标准的 BP 算法每次仅针对一个训练样例更新连接权重和阈值,也就是说,标准 BP 算法的更新规则是基于单个的
其中 m 是训练集合中样本的个数。不过,标准的 BP 算法每次仅针对一个训练样例更新连接权重和阈值,也就是说,标准 BP 算法的更新规则是基于单个的 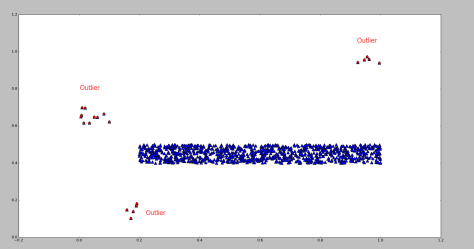
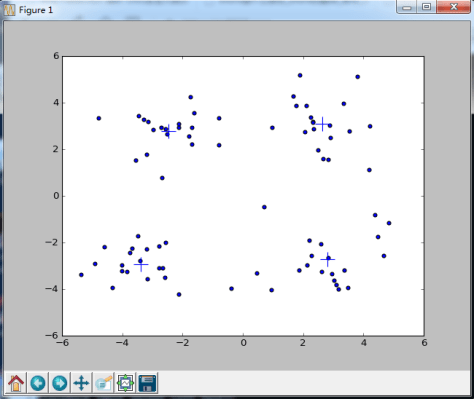
![E=\sum_{i=1}^{K}\sum_{p \in C[i]} dist(p, c[i])^{2}](https://s0.wp.com/latex.php?latex=E%3D%5Csum_%7Bi%3D1%7D%5E%7BK%7D%5Csum_%7Bp+%5Cin+C%5Bi%5D%7D+dist%28p%2C+c%5Bi%5D%29%5E%7B2%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)