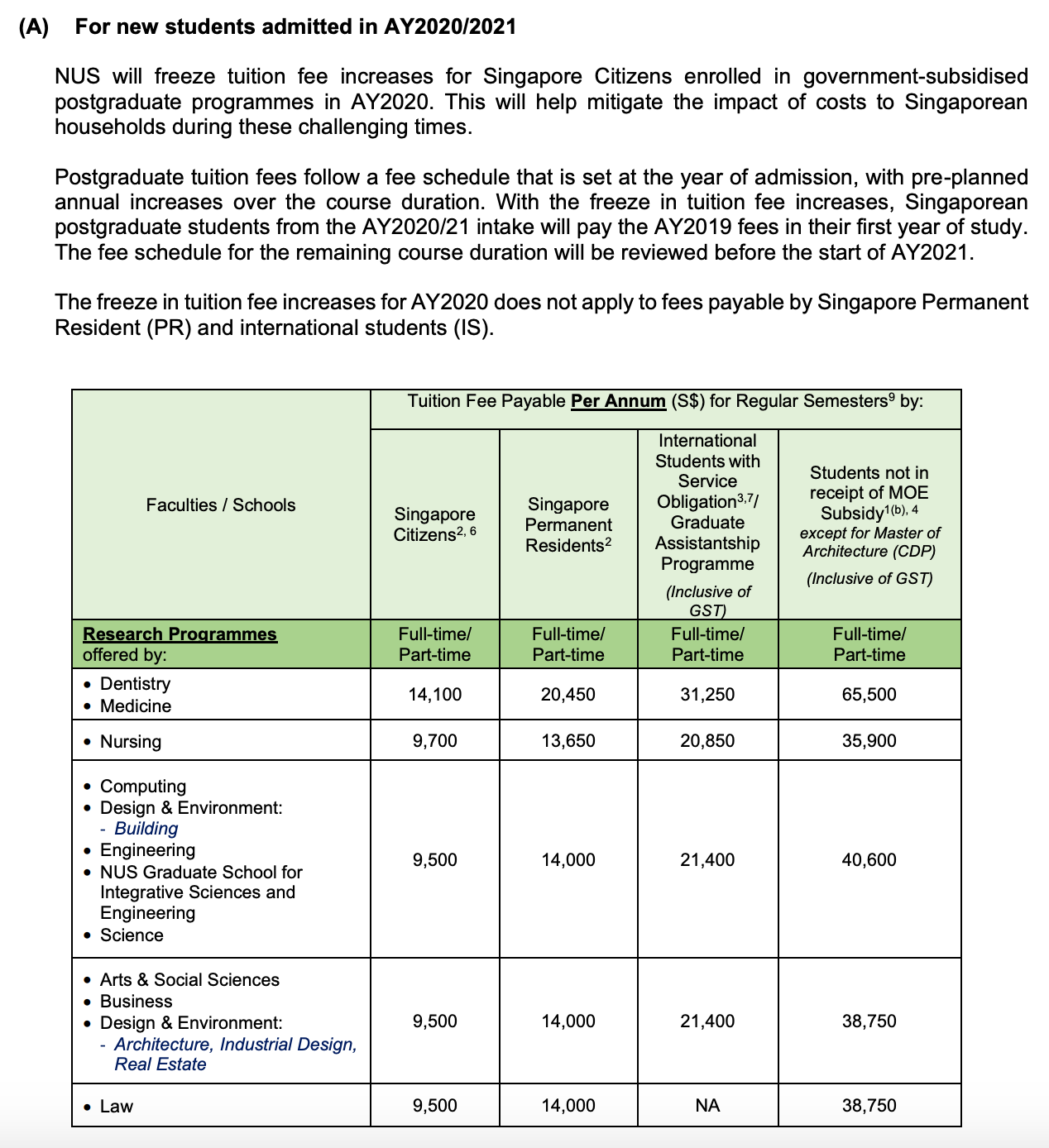
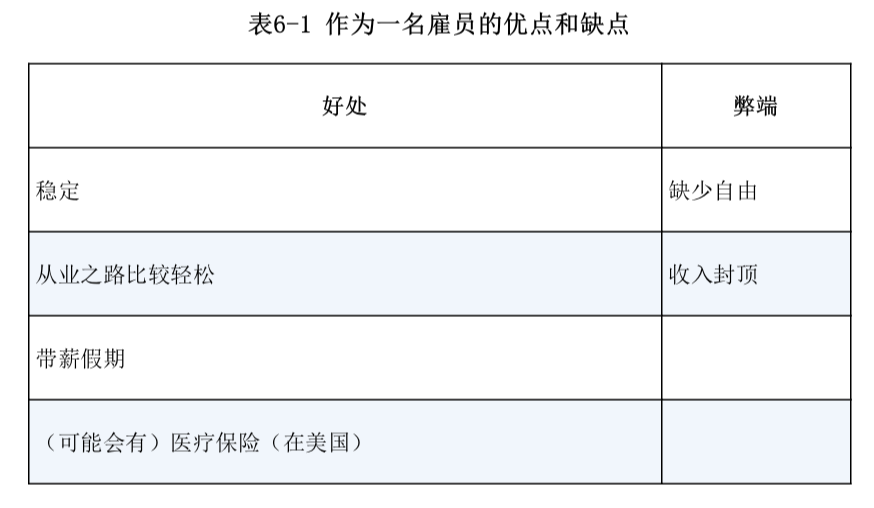
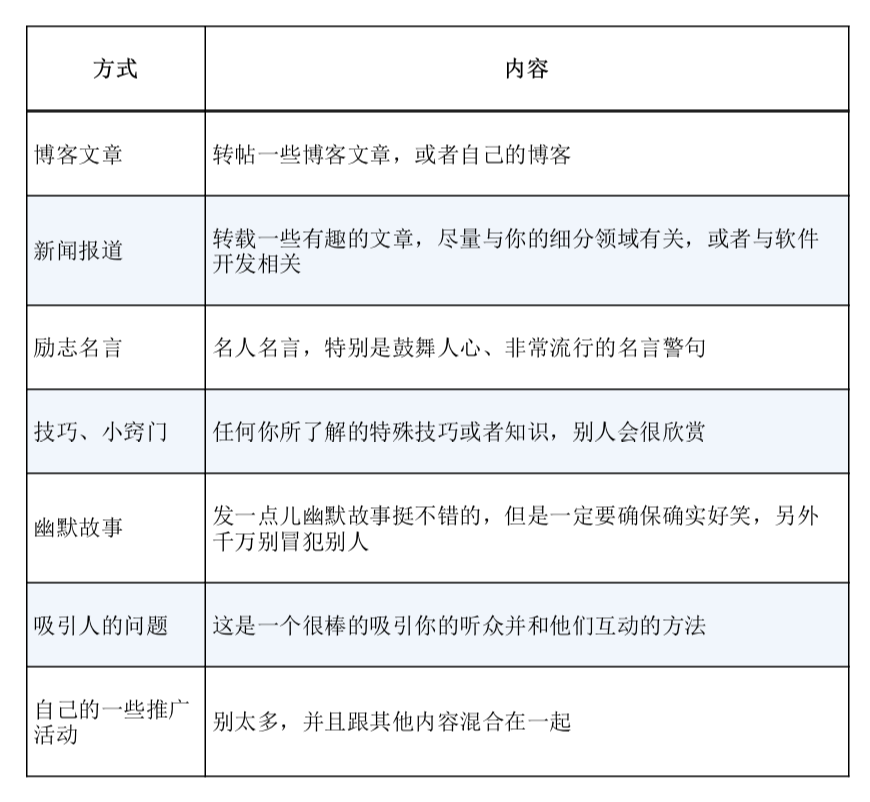
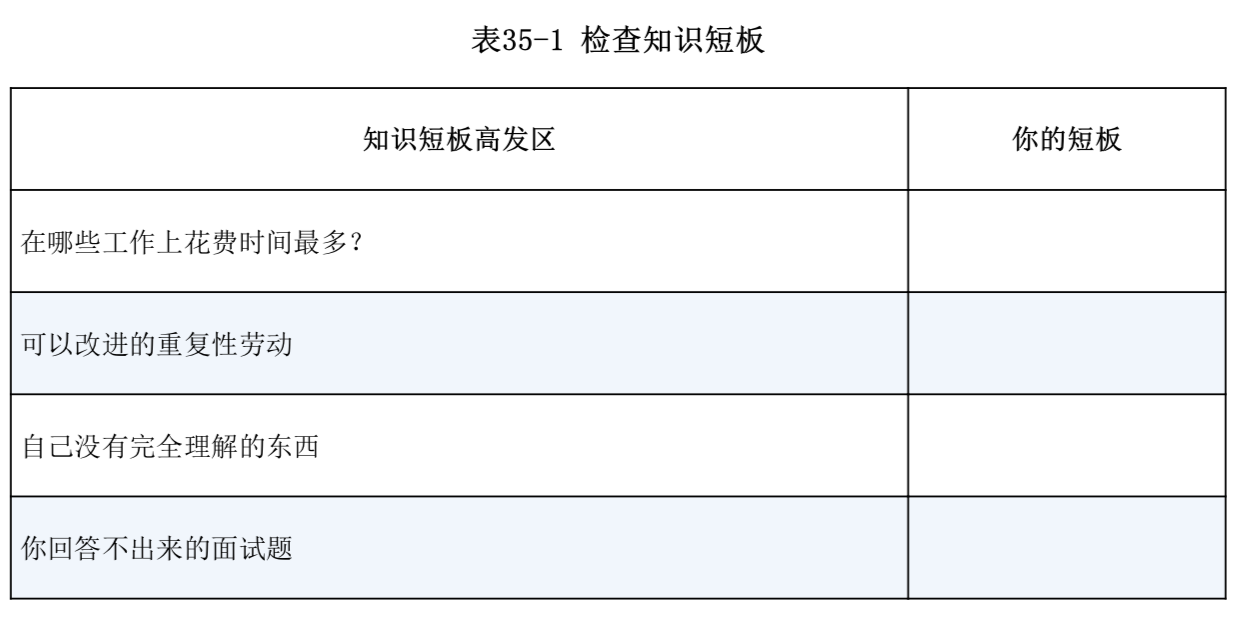
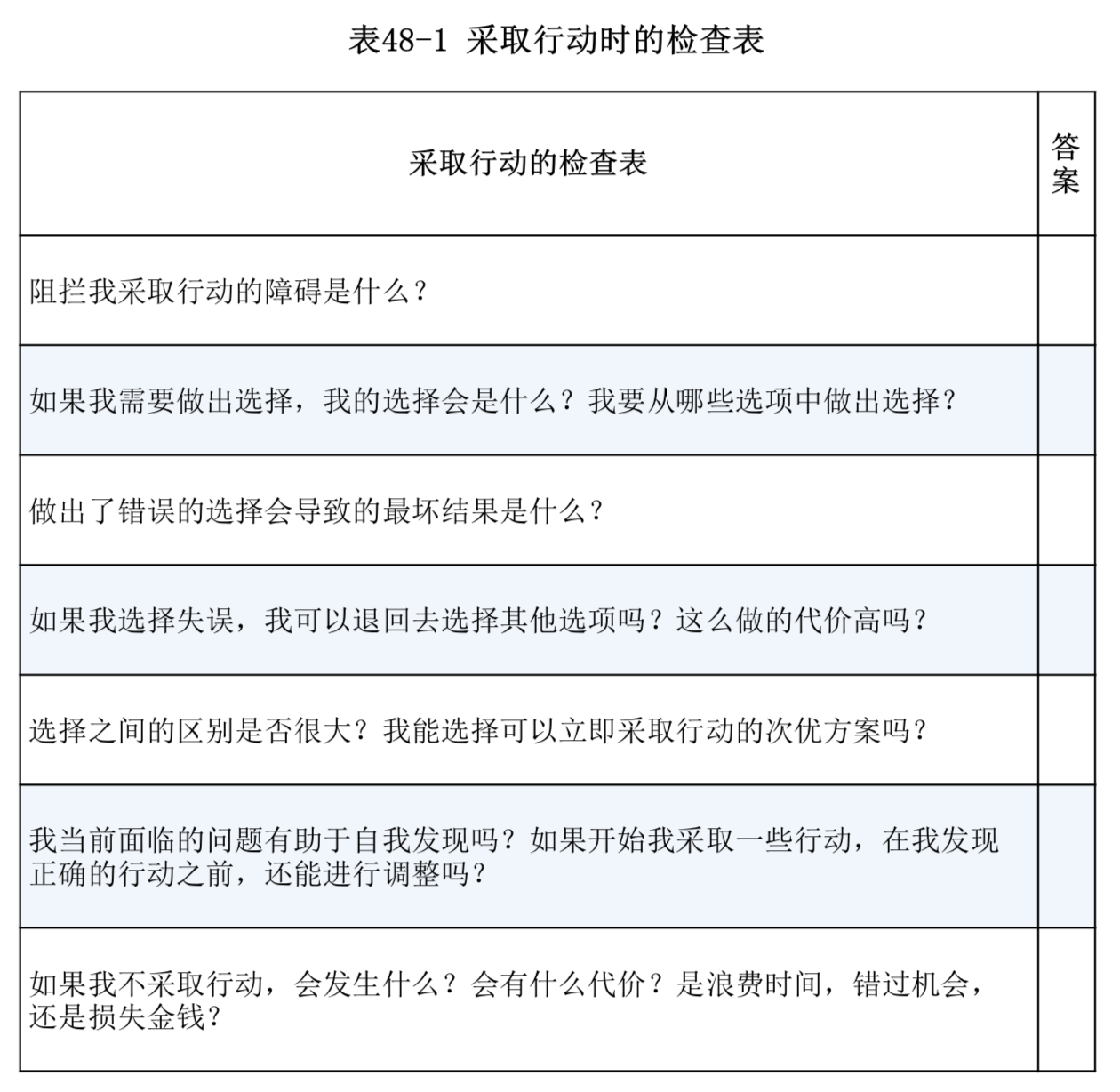
这个问题的应用场景十分广泛。例如:对于 Google 主页面而言,同一个账户可能会访问 Google 主页面多次。于是,在诸多的访问流水中,如何计算出 Google 主页面每天被多少个不同的账户访问过就是一个重要的问题。那么对于 Google 这种访问量巨大的网页而言,其实统计出有十亿 的访问量或者十亿零十万的访问量其实是没有太多的区别的,因此,在这种业务场景下,为了节省成本,其实可以只计算出一个大概的值,而没有必要计算出精准的值。
Count-distinct Problem 的维基百科:https://en.wikipedia.org/wiki/Count-distinct_problem
Heule, Stefan, Marc Nunkesser, and Alexander Hall. “HyperLogLog in practice: algorithmic engineering of a state of the art cardinality estimation algorithm.” Proceedings of the 16th International Conference on Extending Database Technology. 2013.
Flajolet, Philippe, et al. “Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm.” 2007.
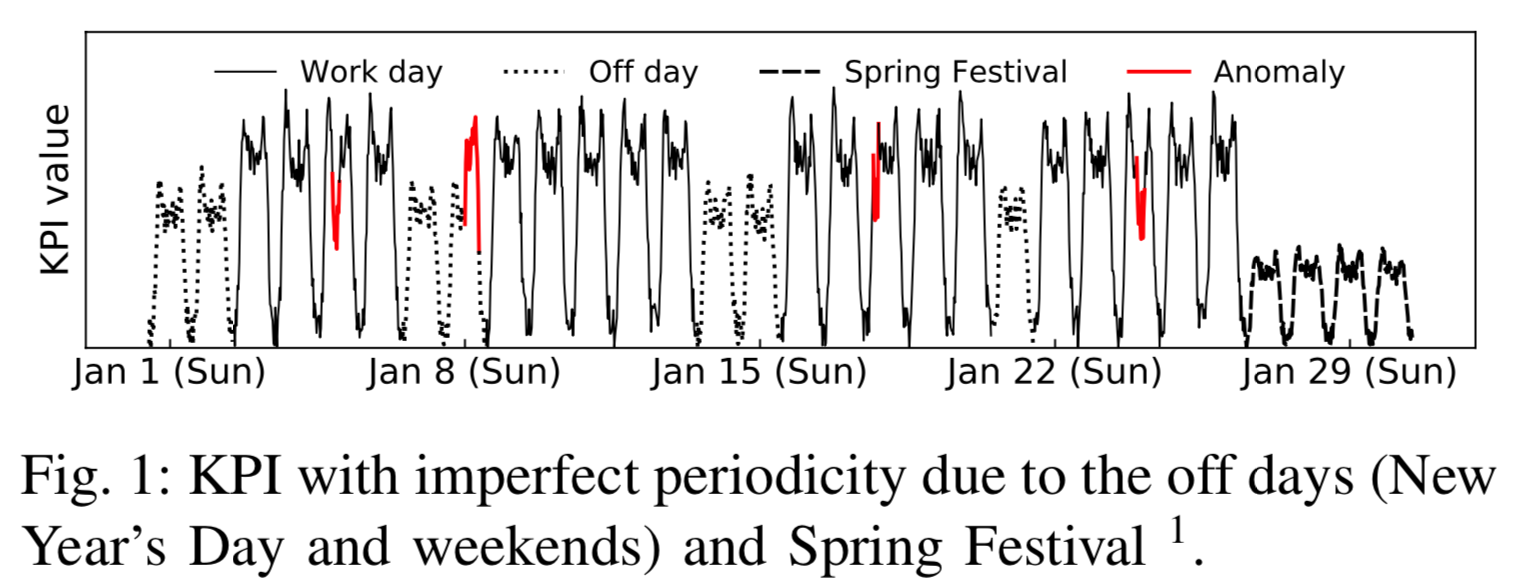
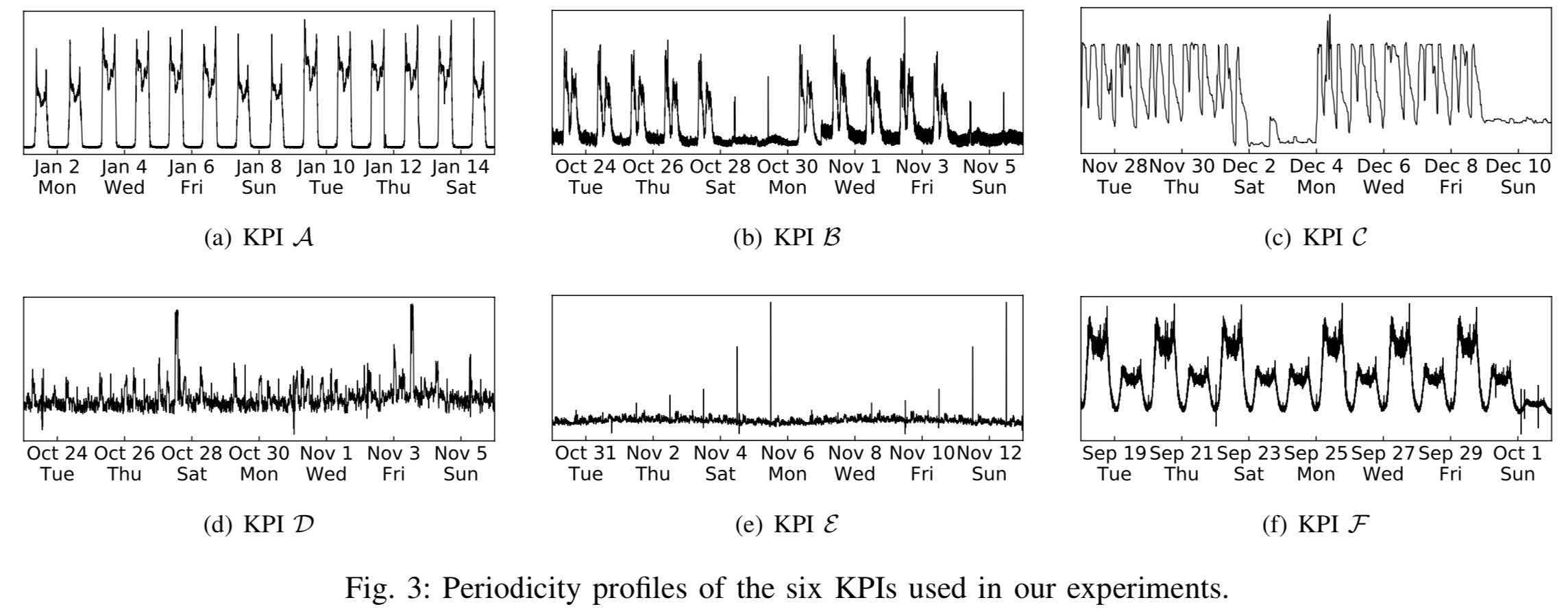
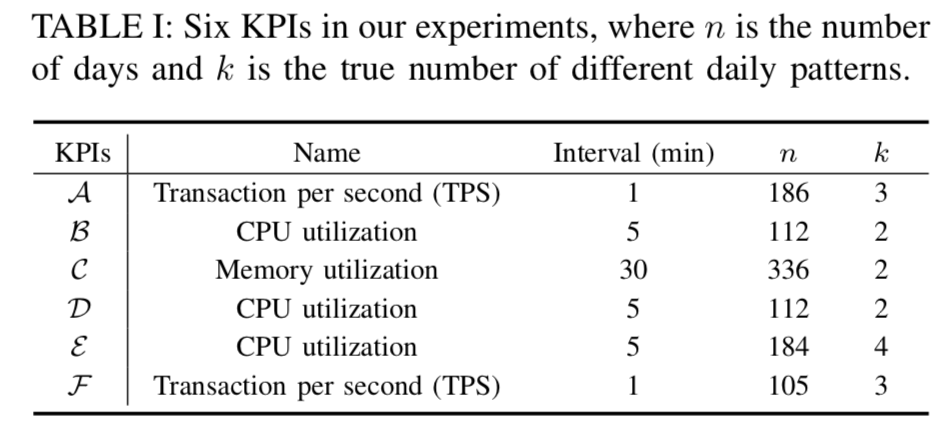
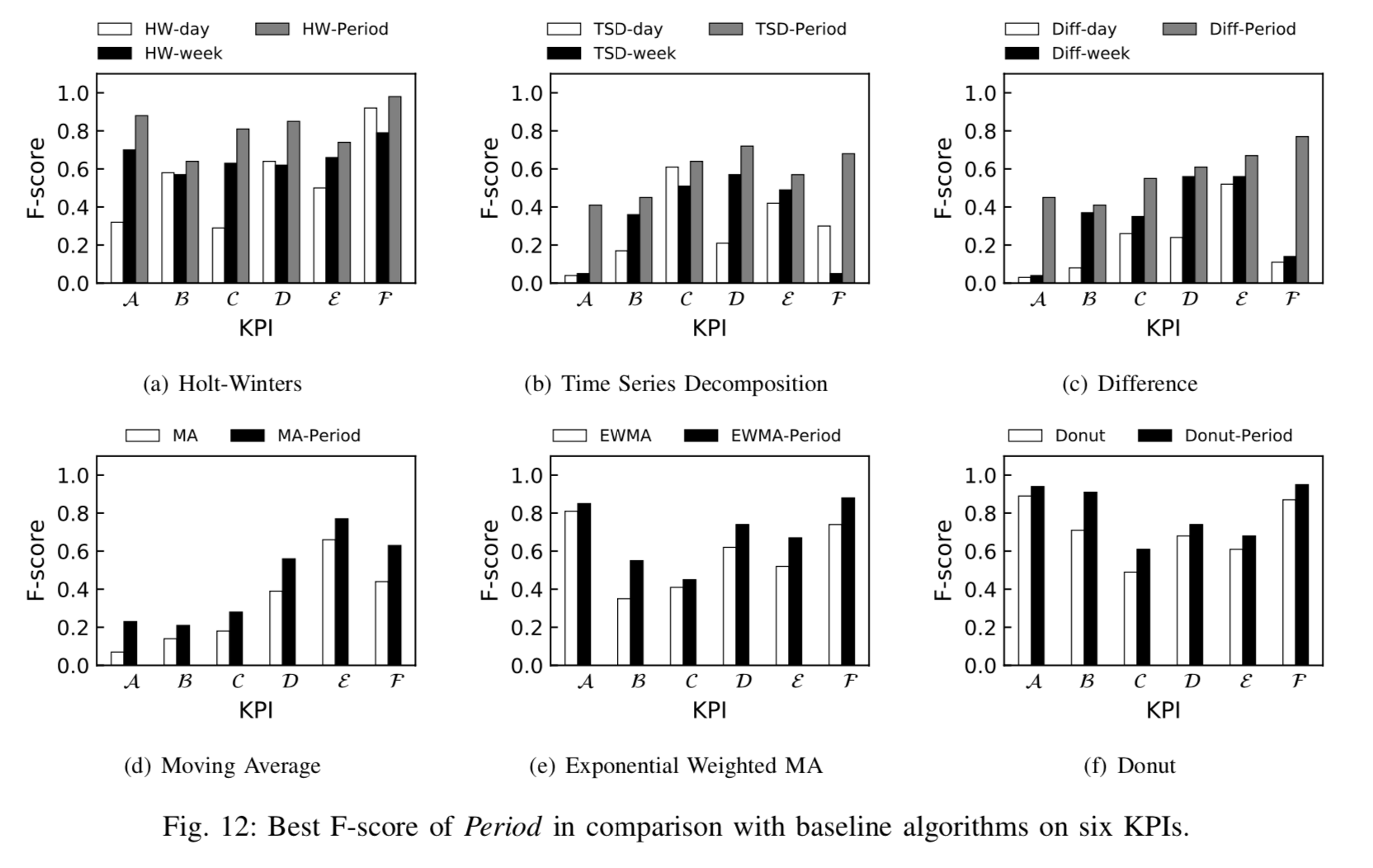
在上图中,我们可以看到论文中使用的数据都具有某种周期性(Periodicity)。KPI A,B,C 都是具有明显具有工作日和周末特点的,在工作日和周末分别有着不同的形状;KPI D 则是关于网上应用商店周五促销的,因此在周五周六的时候,其实时间序列会出现一个尖峰(peak);KPI E 的话则是每隔 7 天,会有两个尖刺,然后并且迅速恢复;KPI F 的话则是可以看出时间序列在十一的走势跟其余的时间点明显有区别。除此之外,对于一些做旅游,电商等行业的公司,其节假日效应会更加突出一点,而且不同的业务在节假日的表现其实也是不一样的。有的时间序列在节假日当天可能会上涨(电商销售额),有的时间序列在节假日当天反而会下降(订车票,飞机票的订单量)。因此,在对这些时间序列做异常检测的同时,如何避免其节假日效应就是一个关键的问题了。
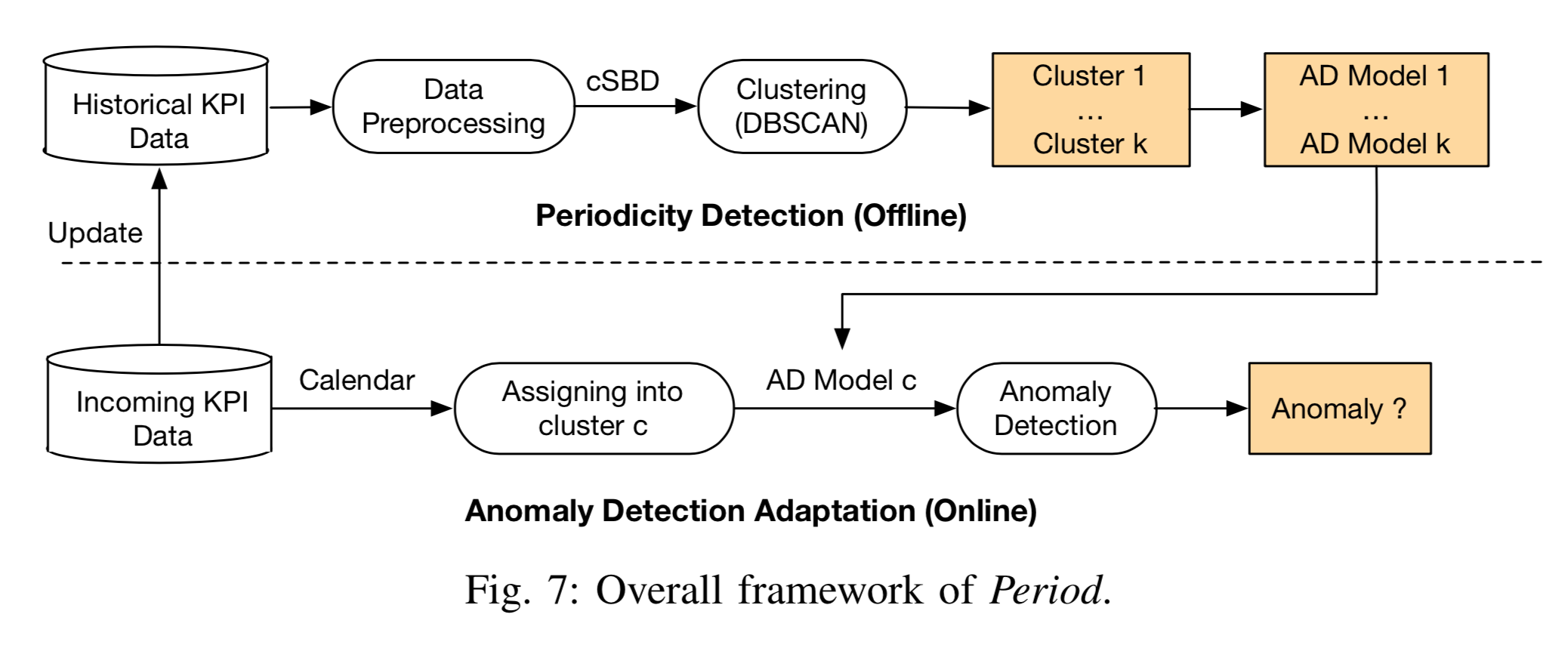
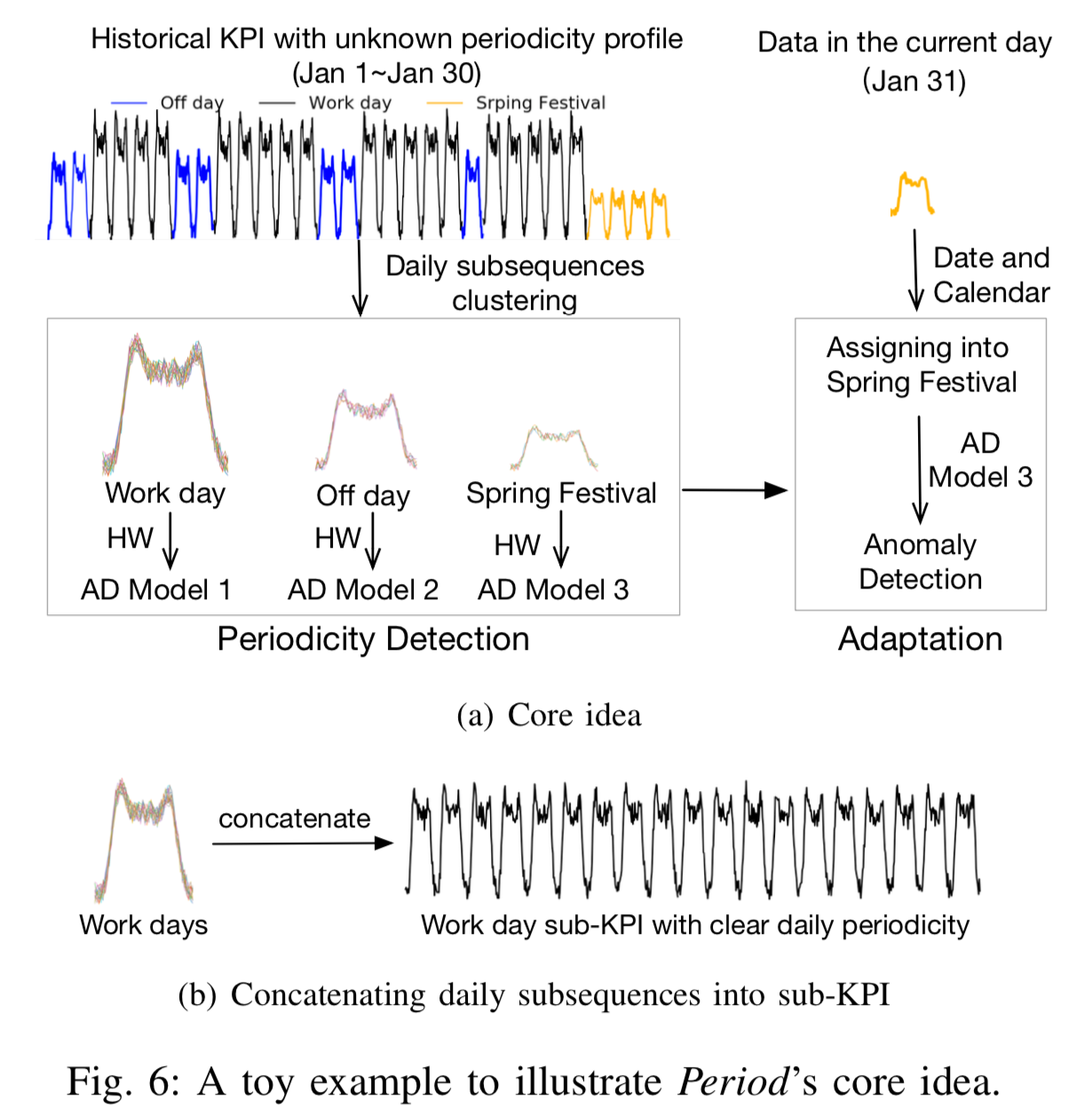
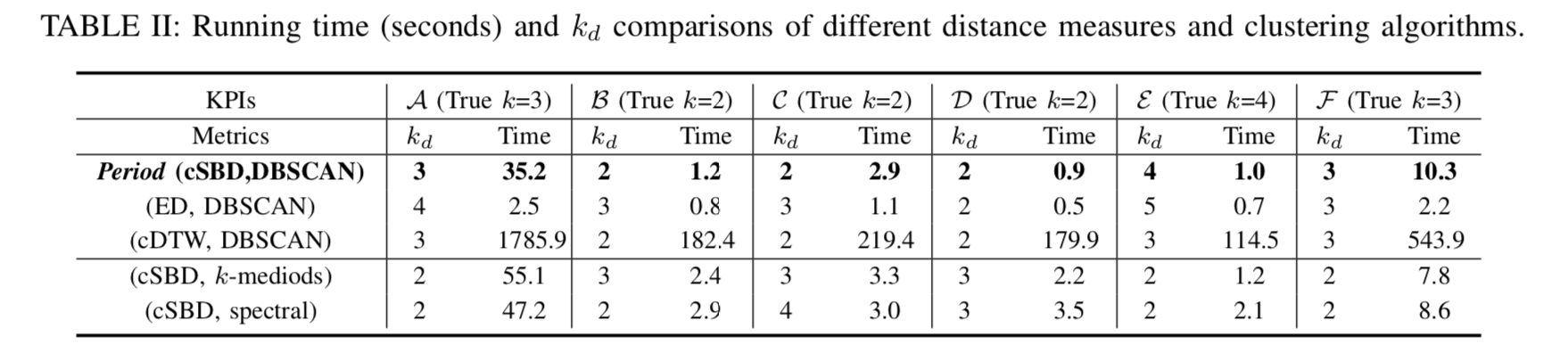
从上图可以看到 Period 的核心思路(core idea)。在本文使用的数据中,时间序列的长度较长,一般来说都是好几个月到半年不等,甚至更长的时间。对于一条时间序列(a given KPI),可以将它的历史数据(historical data)进行按天切分,获得多个子序列(sub KPIs)。对于这多个子序列,需要进行聚类以得到不同类别。或者按照日历直接把时间序列的工作日(work day),休息日(off day),春节(spring festival)序列进行切分,将工作日放在一起,休息日放在一起,春节放在一起。把这些子序列进行拼接就可以得到三条时间序列数据,分别是原时间序列的工作日序列(work day subsequence),休息日序列(off day subsequence),春节序列(spring festival subsequence)。然后分别对着三条时间序列训练一个异常检测的模型(例如 Holt-Winters 算法,简写为 HW)。对于新来的时间序列,可以根据当日具体的日期(工作日,休息日或者春节)放入相应的模型进行异常检测,从而进一步地得到最终的结果。
到了第三年才开始逐渐分流,学习不同的课程。如果是在数学与应用数学专业,就是学习实变函数,泛函分析,拓扑学,微分几何等课程。如果是在信息与计算科学,则是学习实变函数,泛函分析,偏微分方程数值解,运筹学,计算机图形学,信号处理等课程。在不同的专业上面,所学习到的课程内容则是完全不一样的。而该专业的编程工具主要还是使用 Matlab,毕竟用 C++ 这种编程语言写矩阵运算一类的确实不太合适。

 而言,它可能存在重复的元素,用
而言,它可能存在重复的元素,用  来表示这个数据流的不同元素的个数,i.e.
来表示这个数据流的不同元素的个数,i.e. 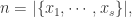 并且这个集合可以表示为
并且这个集合可以表示为  目标是:使用
目标是:使用  这个量级的存储单位,可以得到
这个量级的存储单位,可以得到 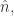 其中
其中  并且估计值
并且估计值 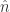 和实际值
和实际值 
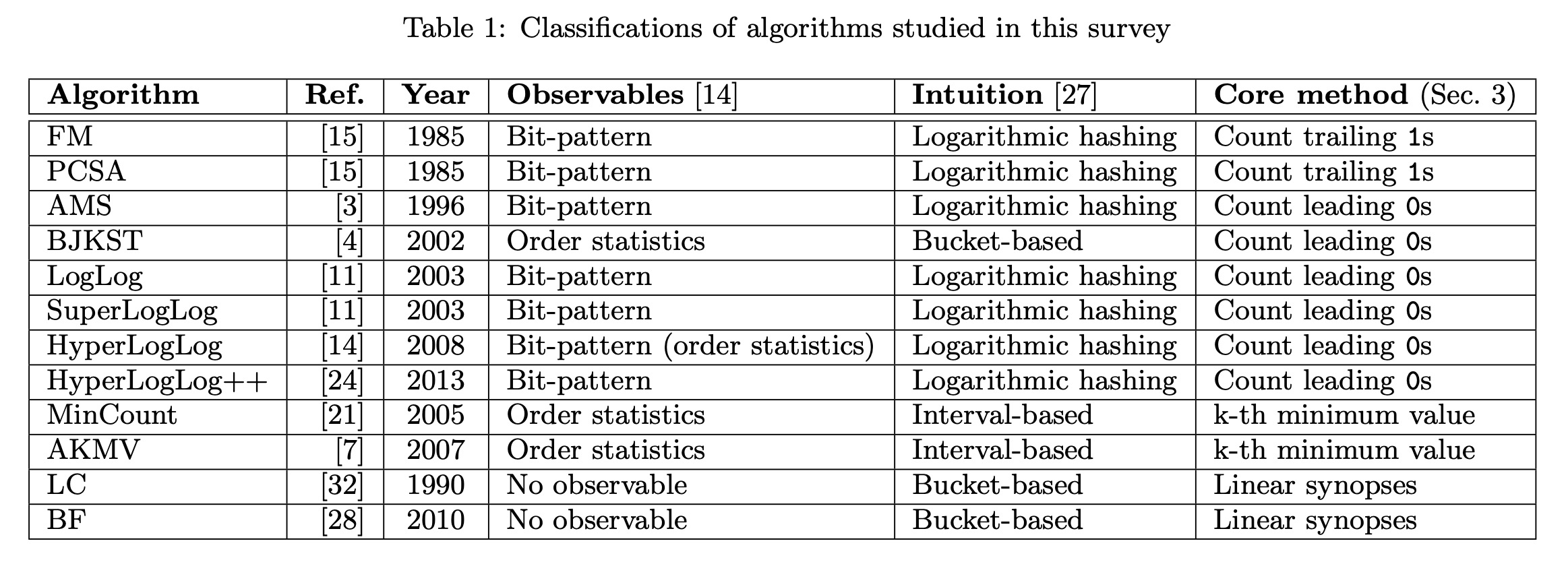

 映射到
映射到  也就是说用二进制来表示数据流中的元素。每一个数据流中的元素
也就是说用二进制来表示数据流中的元素。每一个数据流中的元素  都对应着一个
都对应着一个  序列。
序列。 硬币的反面对应着
硬币的反面对应着  依次扔出
依次扔出 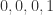 的概率是多少?通过概率计算可以得到是这个概率是
的概率是多少?通过概率计算可以得到是这个概率是  那么相当于平均需要扔
那么相当于平均需要扔 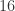 次,才会获得
次,才会获得  这个序列。反之,如果出现了
这个序列。反之,如果出现了 
 令
令  表示第一个
表示第一个 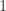 出现的位置。也就是说
出现的位置。也就是说  那么在扔硬币的场景下,出现这样的序列平均至少需要扔
那么在扔硬币的场景下,出现这样的序列平均至少需要扔  次。对于一批大量的随机的
次。对于一批大量的随机的  意味着不重复的元素估计有
意味着不重复的元素估计有 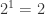 个;
个; 意味着不重复的元素估计有
意味着不重复的元素估计有  个;
个; 意味着不重复的元素估计有
意味着不重复的元素估计有  个;
个;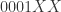 意味着不重复的元素估计有
意味着不重复的元素估计有  个。
个。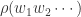 来表示
来表示 

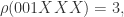

 的最大值,就可以预估出整体的数量。i.e.
的最大值,就可以预估出整体的数量。i.e.  整体的数量预估是
整体的数量预估是 

 值。总共操作
值。总共操作 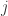 次操作得到的值记为
次操作得到的值记为 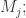 于是就可以对
于是就可以对  进行均值处理,可以使用以下方法:
进行均值处理,可以使用以下方法: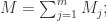
![M=\sqrt[m]{M_{1}\cdots M_{m}};](https://s0.wp.com/latex.php?latex=M%3D%5Csqrt%5Bm%5D%7BM_%7B1%7D%5Ccdots+M_%7Bm%7D%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

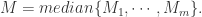
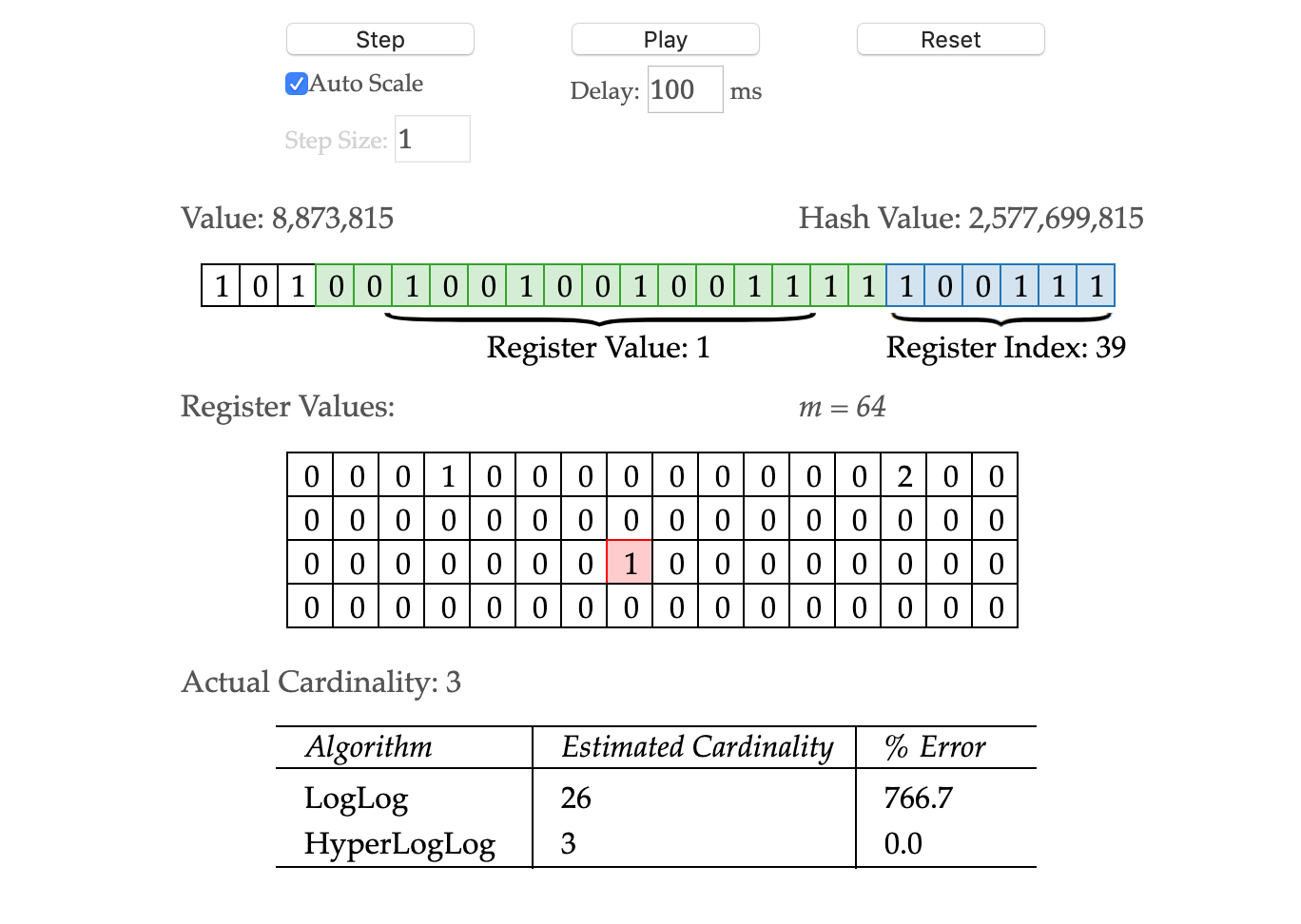
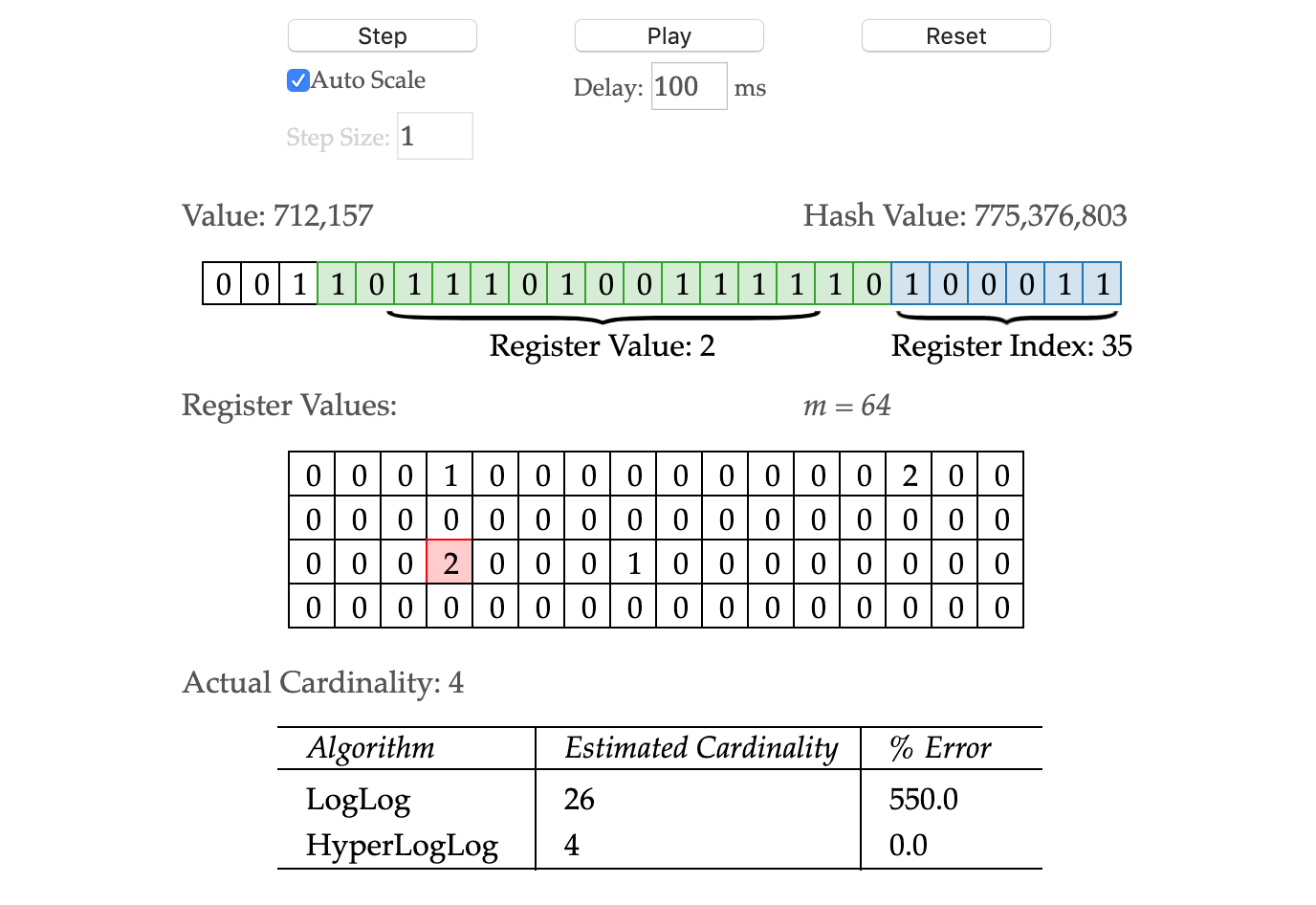
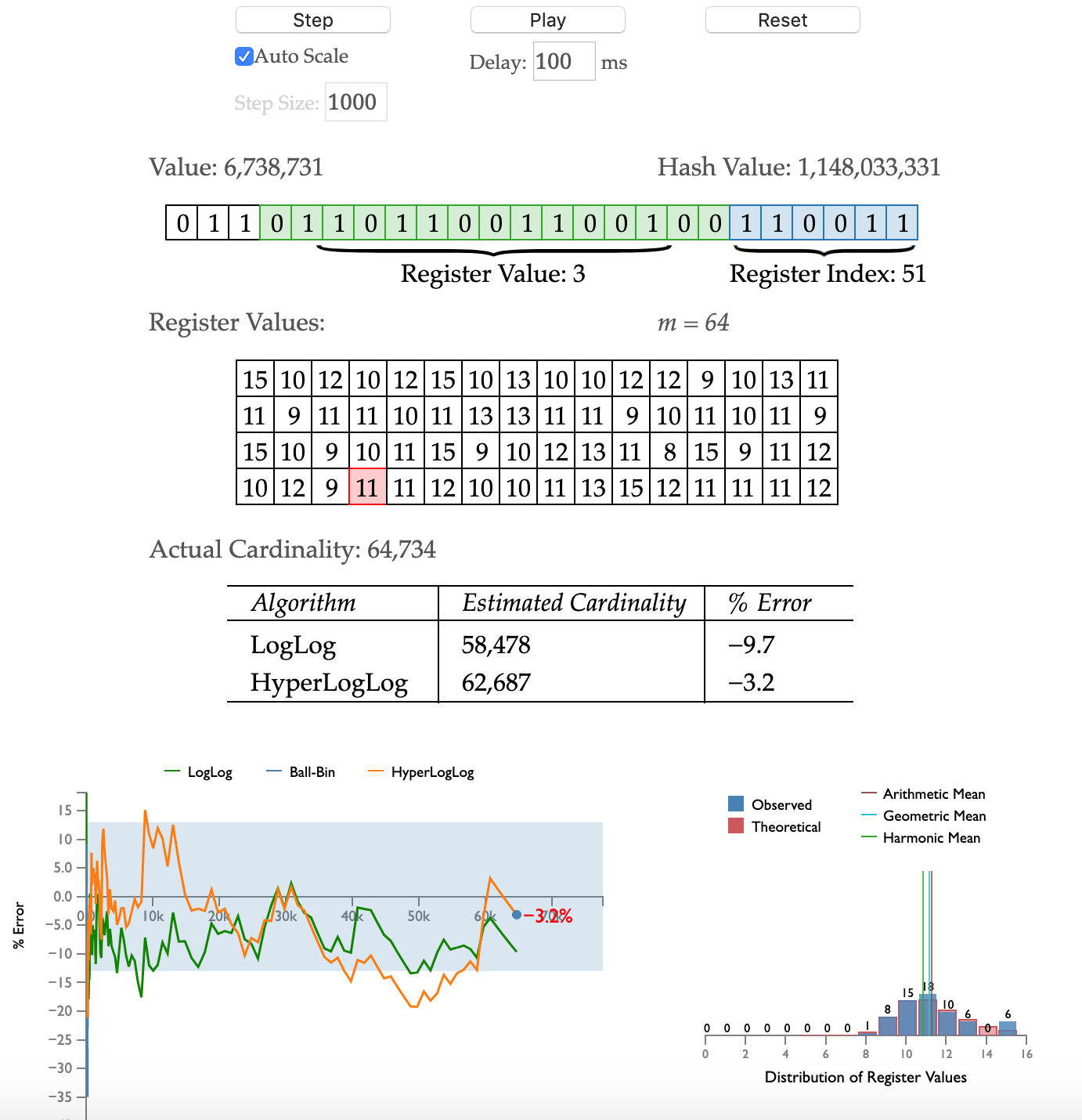
 HyperLogLog 从某个位置
HyperLogLog 从某个位置 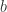 开始,低位
开始,低位  用于决定桶的序号,也就是第几个桶。桶的个数就是
用于决定桶的序号,也就是第几个桶。桶的个数就是  高位
高位  用于估算放在桶里面的元素个数。
用于估算放在桶里面的元素个数。 预估元素个数
预估元素个数 
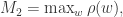 预估元素个数
预估元素个数 
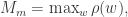 预估元素个数
预估元素个数 
 来估算桶里面的元素个数,那么在有
来估算桶里面的元素个数,那么在有 

 当
当  的时候,
的时候, 是发散的;当
是发散的;当 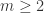 的时候,
的时候, 是收敛的。因此,在使用这个算法的时候最好放入
是收敛的。因此,在使用这个算法的时候最好放入  中的每一个元素
中的每一个元素  可以通过 hash 函数转换成一个
可以通过 hash 函数转换成一个 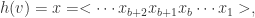 其中
其中  表示二进制中的最低位,
表示二进制中的最低位,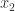 表示次低位。
表示次低位。 来计算放在第
来计算放在第 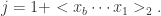 同时将
同时将  计算这批序列的
计算这批序列的  函数的最大值,然后记为
函数的最大值,然后记为 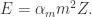
 这个量级的,其中
这个量级的,其中 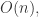 只需要遍历一遍所有元素即可得到最终结果。
只需要遍历一遍所有元素即可得到最终结果。 二进制就是
二进制就是 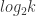 个 bit 就能够存储;
个 bit 就能够存储;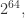 二进制就是
二进制就是  位,
位,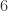 个 bit 就可以存储。
个 bit 就可以存储。

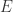 值来进行调整。将
值来进行调整。将 
 此时的基数相对于桶的数量而言不算太多,因此可能存在多个空桶,需要进行调整。
此时的基数相对于桶的数量而言不算太多,因此可能存在多个空桶,需要进行调整。 是
是 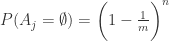 表示桶
表示桶  空的概率;
空的概率; 表示桶
表示桶 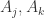 同时为空的概率(
同时为空的概率( );
); 当
当  充分大的时候,约为
充分大的时候,约为  个。
个。 那么可以更新为
那么可以更新为  事实上,可以通过
事实上,可以通过  解出
解出 
 那么更新为
那么更新为  其中
其中 
 的误差大约在
的误差大约在 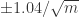 左右。
左右。 其实也可以用近似值来代替,毕竟如下公式的计算是有一定的成本的。
其实也可以用近似值来代替,毕竟如下公式的计算是有一定的成本的。
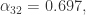
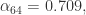
 当
当 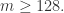

![\alpha_{m}\cdot m^{2}\cdot\bigg(\sum_{j=1}^{m}2^{-M[j]}\bigg)^{-1};](https://s0.wp.com/latex.php?latex=%5Calpha_%7Bm%7D%5Ccdot+m%5E%7B2%7D%5Ccdot%5Cbigg%28%5Csum_%7Bj%3D1%7D%5E%7Bm%7D2%5E%7B-M%5Bj%5D%7D%5Cbigg%29%5E%7B-1%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)











![£¨Í¼±í£©[Éç»á]2020Äê½Ú¼ÙÈշżٰ²ÅŹ«²¼](https://zr9558.com/wp-content/uploads/2020/05/2020e5b9b4e4b8ade59bbde88a82e58187e697a5e5ae89e68e92.jpg)
 和
和  ,提出了相似性的计算方法。
,提出了相似性的计算方法。
 的个数都是
的个数都是 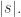 进一步可以定义,当
进一步可以定义,当 ![s\in[-w,w]\cap\mathbb{Z}](https://s0.wp.com/latex.php?latex=s%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 时,
时,
 归一化之后的最大值作为
归一化之后的最大值作为  的相似度,i.e.
的相似度,i.e.![NCC(X,Y)=\max_{s\in[-w,w]\cap\mathbb{Z}}\frac{CC_{s}(X,Y)}{\|x\|_{2}\cdot\|y\|}.](https://s0.wp.com/latex.php?latex=NCC%28X%2CY%29%3D%5Cmax_%7Bs%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D%7D%5Cfrac%7BCC_%7Bs%7D%28X%2CY%29%7D%7B%5C%7Cx%5C%7C_%7B2%7D%5Ccdot%5C%7Cy%5C%7C%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

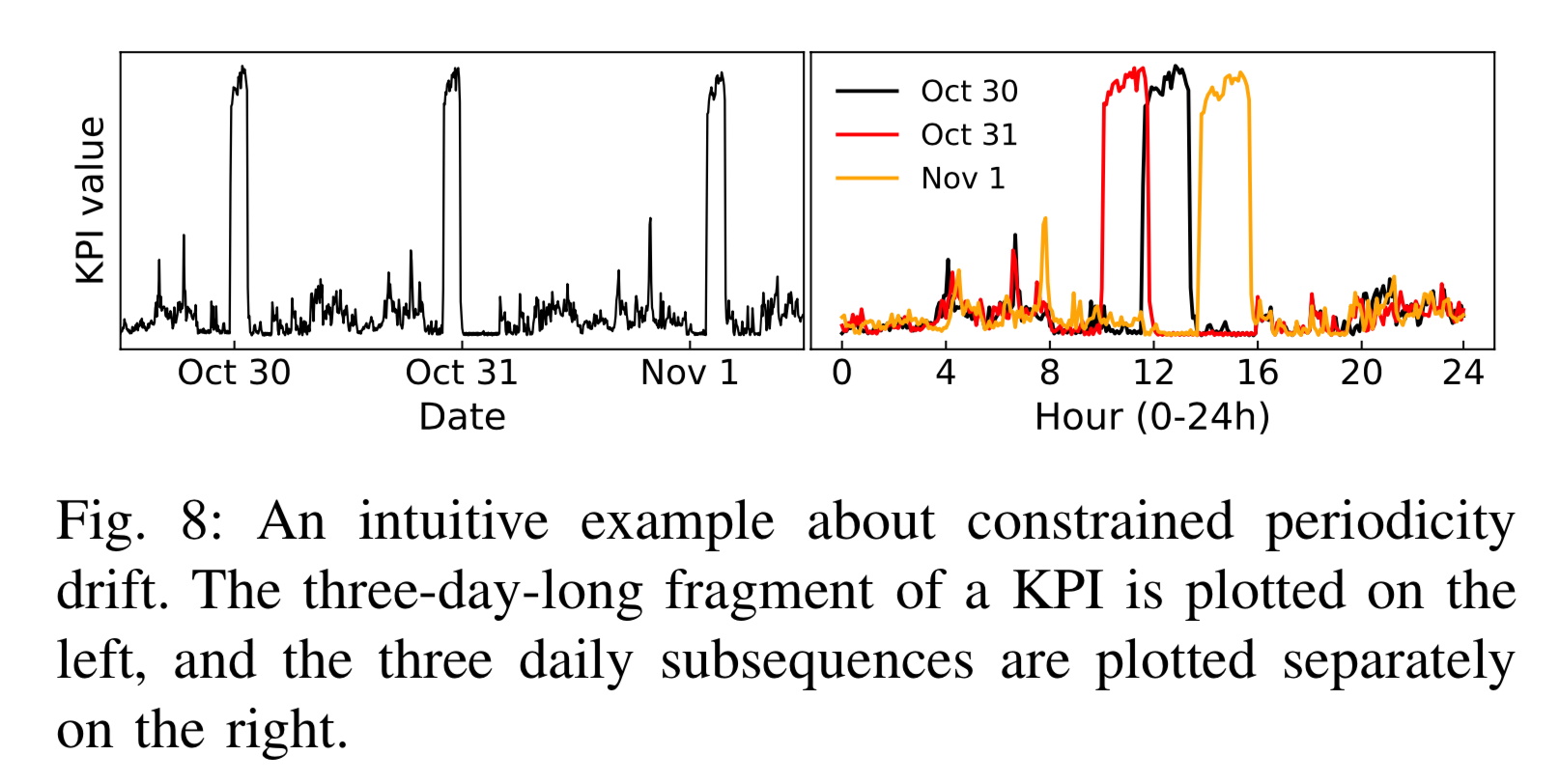
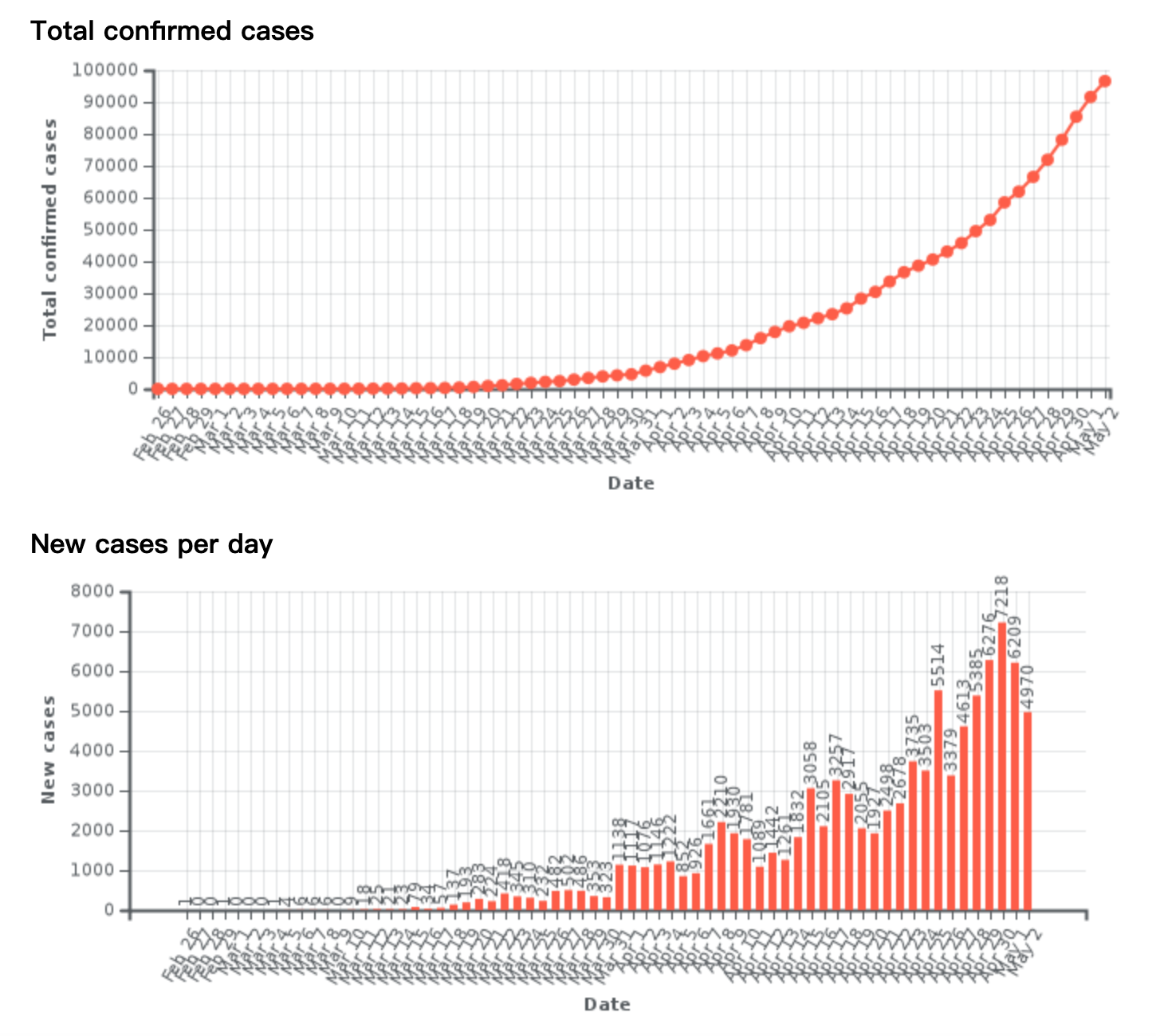
 呢,因为在一些实际的情况下,时间序列是会存在漂移的,例如上图所示。该时间序列在 10 月 30 日,31 日,11 月 1 日 都出现了一个凸起,但是如果考虑它的同比图,其实是可以清楚地看出该时间序列就存在了漂移,也就是说并不是在一个固定的时间戳就会出现同样的凸起,而是间隔了一段时间。这就是为什么需要考虑
呢,因为在一些实际的情况下,时间序列是会存在漂移的,例如上图所示。该时间序列在 10 月 30 日,31 日,11 月 1 日 都出现了一个凸起,但是如果考虑它的同比图,其实是可以清楚地看出该时间序列就存在了漂移,也就是说并不是在一个固定的时间戳就会出现同样的凸起,而是间隔了一段时间。这就是为什么需要考虑 
 并且还有很多其他有意思的性质。
并且还有很多其他有意思的性质。


 有界性的关键定理,是整个调和分析的基础。
有界性的关键定理,是整个调和分析的基础。







![G_{n}=\sqrt[n]{x_{1}\cdots x_{n}}.](https://s0.wp.com/latex.php?latex=G_%7Bn%7D%3D%5Csqrt%5Bn%5D%7Bx_%7B1%7D%5Ccdots+x_%7Bn%7D%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


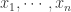 都是正数,那么
都是正数,那么  也就是说,调和平均数
也就是说,调和平均数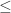 几何平均数
几何平均数 的情形证明如下图。其余可以用数学归纳法等多种方法证明。
的情形证明如下图。其余可以用数学归纳法等多种方法证明。
 而标准差则有两种情况,第一种是总体的样本差(population standard deviation),总体的标准差定义为方差正的平方根,记为 SD,
而标准差则有两种情况,第一种是总体的样本差(population standard deviation),总体的标准差定义为方差正的平方根,记为 SD,

 是从一个更大的总体抽样出来的部分数据。样本的标准差记为
是从一个更大的总体抽样出来的部分数据。样本的标准差记为 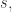
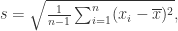

 就是算术平均数。
就是算术平均数。
 就是样本方差。
就是样本方差。
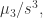 其中
其中 
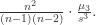 而偏度的结果可以是正数,负数,或者零。分别被称为 Positive Skew(右侧的尾巴更长), Negative Skew(左侧的尾巴更长) 和 Zero Skew。当均值等于中位数等于众数的时候,该概率分布是对称的。Median(中位数)相对于 Mean(均值)是更加接近 Mode(众数)的数字,因此根据 Median 和 Mean 的大小关系也能够大致判断 Skew(偏度)的趋势。
而偏度的结果可以是正数,负数,或者零。分别被称为 Positive Skew(右侧的尾巴更长), Negative Skew(左侧的尾巴更长) 和 Zero Skew。当均值等于中位数等于众数的时候,该概率分布是对称的。Median(中位数)相对于 Mean(均值)是更加接近 Mode(众数)的数字,因此根据 Median 和 Mean 的大小关系也能够大致判断 Skew(偏度)的趋势。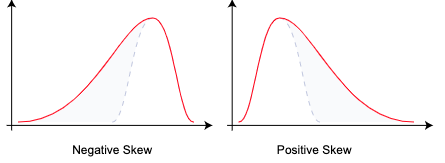
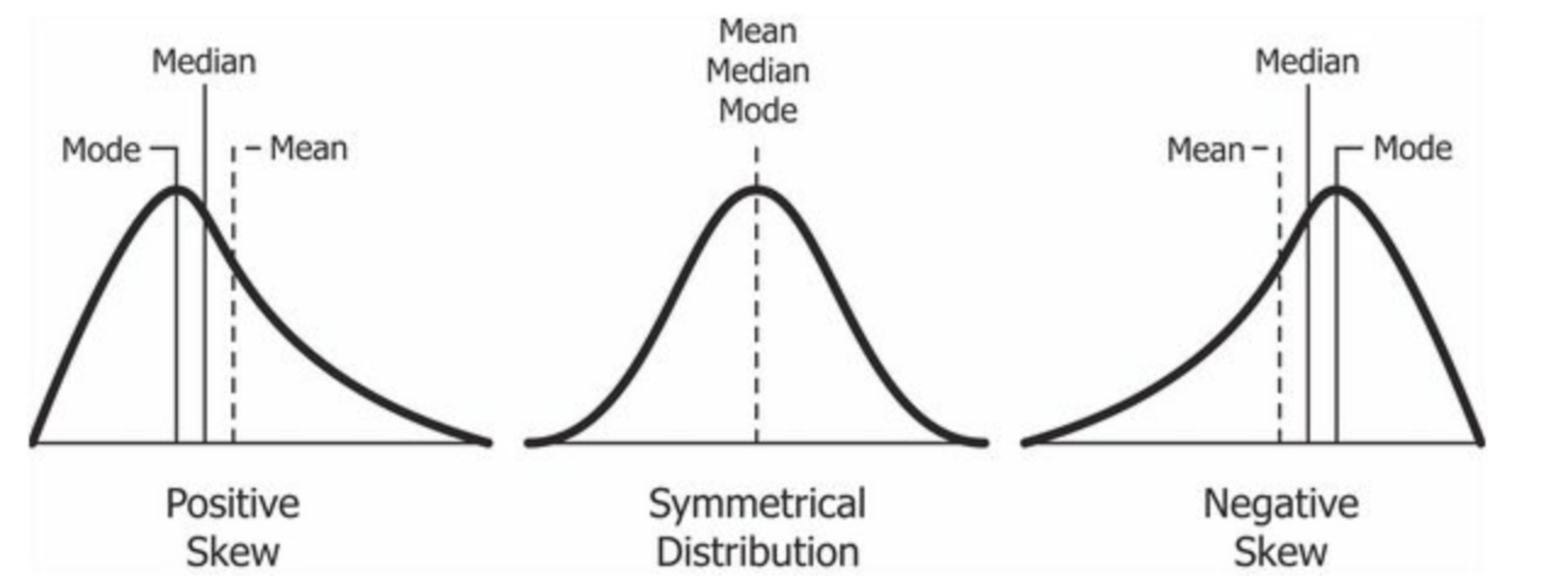
 其中
其中 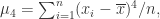
 减去 3 的目的是为了让正态分布的峰度为零。
减去 3 的目的是为了让正态分布的峰度为零。 的值。可以使用极坐标的方法来解决,首先通过坐标变换可以得到原式子等于
的值。可以使用极坐标的方法来解决,首先通过坐标变换可以得到原式子等于  其次,令
其次,令 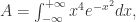 可以得到
可以得到


 从而原式子等于 3。i.e. 正态分布 4 阶距的值是 3。
从而原式子等于 3。i.e. 正态分布 4 阶距的值是 3。
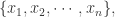 可以设置其一组正数权重
可以设置其一组正数权重  然后得到其带权重的算术平均数为
然后得到其带权重的算术平均数为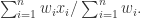
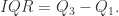
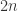 或者
或者  的数列而言,
的数列而言,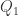 就是
就是  就是
就是 


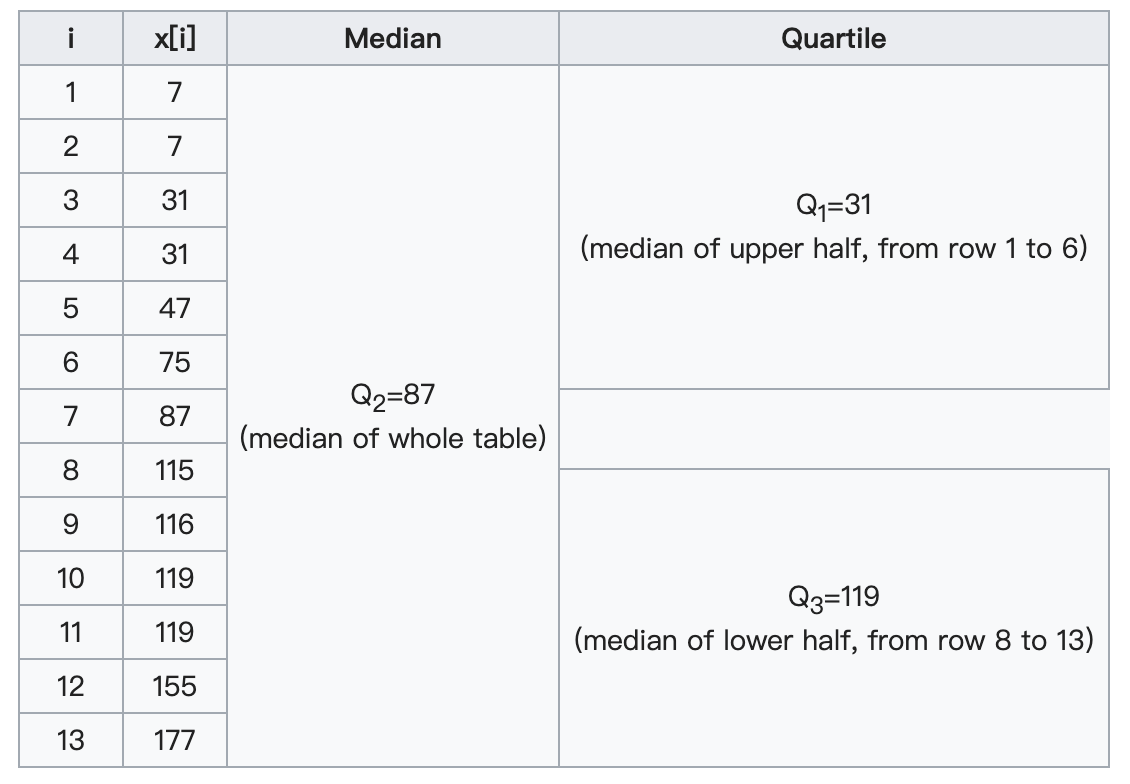
 从而四分位距
从而四分位距  异常检测的上下界分别是
异常检测的上下界分别是 

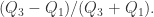
 和
和  两个集合。对于
两个集合。对于  而言,
而言, 它的
它的 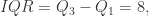 四分位发散系数为
四分位发散系数为  对于
对于 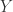 而言,
而言, 它的
它的 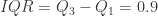 ,四分位发散系数为
,四分位发散系数为  因此集合
因此集合 
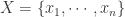 而言,平均绝对偏差(Mean Absolute Difference)定义为:
而言,平均绝对偏差(Mean Absolute Difference)定义为:

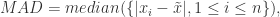 其中
其中  可以看出数据的偏移程度。
可以看出数据的偏移程度。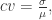
 通过定义可以计算出它们的变异系数
通过定义可以计算出它们的变异系数  变异系数越大,表示集合的数据波动程度越大。变异系数越小,表示集合的数据波动程度越小。
变异系数越大,表示集合的数据波动程度越大。变异系数越小,表示集合的数据波动程度越小。