本文纯转载,并且是 2012 年的文章,有的观点可能不符合现在的场景,请读者自行甄别。
[回复本文][原帖] 发信人: WAMozart(含泪微笑的天使), 信区: PhD
标 题: 博士这条船
发信站: 饮水思源 (2012年12月17日15:50:49 星期一)
一、前言
原先我是准备等到毕业的那一天,痛痛快快地哭过了之后,一口气写掉这篇文章的。其实一直在零散时间打腹稿,差不多已经煲熟了。刚才有同样读博士读得凄凄惨惨切切的师兄表示期待,于是一横心决定现在就写了。何况,早点让更多还没上博士这条船的弟妹们看到,提醒他们读博要谨慎谨慎再谨慎,能多挽救一个像我们哥俩这样不是读博的料的孩子,也好。
文章原先是分八篇发表的,现整理为一整篇,每一部分加上原先的标题。有几点要说明的:
1.或许有人嫌太长了不想看,或许我的观点片面甚至偏激,或许我的经历太特殊而不具备代表性
但是无论如何,请点进来看的每一位想要读博士的朋友,还包括尚未高考的小朋友和他们的爸妈们,切记,在做出选择之前做一下人格测试/职业倾向测试等等,至少没有坏处。职业倾向测试会给出比较细致的职业类型建议,会大大减少选择专业的盲目性。至少,对于有明显偏科倾向的孩子来说,不要在文理科之间站错队。为什么从读博士扯到高考选专业呢?因为对于有些专业来说,不读到博士几乎就等于没读,比如我们生物专业,如果读到硕士毕业,只能每天背个包挨个实验室敲门推销试剂,或者在流水线上做质检,在可口可乐之类勉强与生物擦个边的公司给博士打下手。要想做研发,土博士都没人理你,海龟博士铺天盖地的。所以选择有些专业就意味着除非转行,否则一定要从一而终,读到博士才能在本专业内做点有意义的事情。要特别强调的一点是“隐性偏科”。像我这种在高中阶段已经表现出偏科倾向的孩子,其实从成绩来看并不算明显偏科。但那是我基本不花时间在语文和英语上,而咬着牙狠命拼数学的结果。另外得益于上海的高考政策,我高二已经放弃物理了,选了半文半理的化学。背点东西什么的,对我来说从来就是轻松愉快的事情,而逻辑推理是要了命的。这种孩子其实内心很明白自己到底是属于文科还是理科世界的,至少能清楚地感受到自己到底是对史地生还是数理化更有兴趣,学起来更轻松。
简单说下我上错理科这条船,继而又上了博士这条小艇,沉浮于学术苦海这一故事的起因:高中的时候,家长和老师都希望我选理科,理由是男生嘛,理科拼一拼还是很不错的(确实高考数学被我拼到了138),不要学文科,以后没饭吃。我高考前还是上个世纪末,网络刚刚进入人们的生活,那时候高中生上哪里去找几个走过大学的人去听听他们的故事呢,又怎么知道还有各种测试性格、思维方式和职业倾向的科学测试呢?现在的孩子们要利用好你们拿起手机就能拥有的这些宝贵资源啊!而我的性格真的决定了我的命运,我不够有魄力,缺乏那种豁出去了一定要执着于自己的梦想的气概。其实如果我从知道音乐学院作曲指挥系需要考钢琴那一刻开始,两年时间内狠命练钢琴,同时凑活着读点书,钢琴肯定可以过关,高考分数绝对也能达到音乐学院那点分数线了。
虽然说在这个现实的社会中,吃饱饭确实是第一要务,吃饱了饭才能做好自己热爱的事情。而搞纯正的文科或艺术类专业,除非成为同行中的佼佼者,确实很难挣大钱。但我就不信一个人如果能够从事自己真正热爱而且擅长的事情,因此不仅仅为了一家人能吃饱饭去工作,而是为了让自己的灵魂不至于枯死、为了让自己和其他人的生命持续发光、为了让周围的人拥有shinning eyes(请搜索Classical Music and Shinning Eyes,美国一位指挥家一段20分钟的讲座视频,其中提到他所认为的成功便是如此),那么,不管他读什么专业,我就不信他会找不到工作,我就不信他会饿死!尽管可能太天真,太理想主义,我还是觉得,比挣大钱更重要的是发挥出一个人天赐的价值,遵从其内心深处的理想,能够从事一份不存在上下班概念,不给加班工资也乐意继续工作而不以之为“加班”的事业。而只有这样的事业,才真正称得上是事业,而不仅仅是职业。他或许会因此而活得不那么光鲜,或许买不起豪宅开不起豪车,但他会是世界上最幸福的那一小群人——人生理想和职业理想能够重合——之一。
而世界上最大的悲剧,除了“你未来的丈母娘站在你面前而你只能喊阿姨”,便是,不得不把上帝赐予自己的天赋打包藏起来,把梦想掩埋起来,用自己的短处去跟一群强者争一口饭吃。然后只能在业余时间偷偷拿出自己的梦想来把玩一下,以免自己的灵魂凋零。楼主便不幸是这么个悲剧人物。并且已经一把年纪了,不再有年轻的资本,能豪迈地呐喊,去你的permanent head damage,老子不干了,老子要实现自己的理想。都而立之年了,棱角磨平了,梦想的光芒也穿不透打包盒了,生存的压力和对安稳的渴求已经压倒了一切。认命了。
2.公认地,化学和生物是所有专业中读博士最苦逼的专业
所以一个生物学博士生的血泪史,尤其还包括一段在大洋彼岸一个指鹿为马偷梁换柱暗度陈仓装腔作势无中生有咆哮如雷喷吐唾沫诸项技能无所不精的极品手下做学术民工的生涯,已经达到苦逼的极致了。我所能有把握说到位的,也仅限于生物专业。何况行文之中无论如何不可能完全排除个人的情感因素,一定会有夸张的成分,只是绝不会无中生有。其他专业的朋友们,不要把本文太当真,参考参考就行,还是多听听自己专业前辈们的说法。但从另一个方面来说,不管什么专业的博士,有一些要求是相通的。下文中会详细展开。
3.对于真正适合读博士做科研并且真心热爱科研的人,什么都拦不住的
本文能够拦住的,一定是相当不适合上这条船的人。其实你们像我一样,会在其他领域发挥自己的才能,没必要硬着头皮上船,走进下船前流着热泪劝弟妹的历史循环。对介于此两极之间的中间派,读博无妨,不过别想着在高校和科研院所做研究了。现实点,去企业做研发吧,或者像我这样,有文字和英语方面特长的,打个擦边球,在本专业范围内从事文字工作。做理论研究是投入产出比最低的工作,在相当一部分专业是如此。因为中间派的人生理想并不是扔下家庭没日没夜地泡实验室,所以,在有年收益率将近5%的债券什么的可供选择的情况下,何必把钱存银行呢?所以,在不误读我的文章的前提下,我不担心乱写一气会给弟妹们带来不利的影响。至少至少,给大家打打预防针,上船前多做点切合实际的准备,总没错呢。
二、读完博士能够干什么
实际上这个问题问出来,有点亵渎“博士”这个词的本真涵义。Philosophy degree的本意应当是授予拥有相当智慧(注意,知识和技能都只是“智慧”的子集)的人的最高学位,因为philo和sophy这两个来源于希腊语的词根本意分别是“爱”和“智慧”。在西方国家,花白头发的博士生并不罕见,而这类无止境地追求自身更高精神境界的勇士才最配被授予荣耀的博士学位。或者说,读博士的目的应当不仅仅局限于为了找份更有技术含量报酬更高的工作。实际上如果我真的如愿去音乐学院读博士,我不会仅仅问“博士毕业之后能做什么”,我更看重的是学习的过程会为我这如同空气和水一样重要的爱好(实在不仅仅是一种爱好)带来什么样的benefit,会让我的一生拥有怎样一个精神境界和视野,会给我的后代,给整个人类社会留下点什么无价的财富。可惜的是,在大学无异于职业技能培训所的中国,绝大部分博士生,包括现在上了生物学博士这条船的我,对于博士学业的意义,只能问出这样一个问题:毕业之后我能干什么?
毕竟我们的国情不同于西方发达国家,生存的压力对于绝大多数中国人来说是压倒一切的。生存问题得不到一个足够强有力的保证,谁都不会去考虑更高层次的需求,包括对什么事物的热爱。我有个在美国读过硕士的朋友告诉我,他的室友有个绝对强大的老爸,财产足够他坐吃一辈子而不空,但是他就是不读大学,而是做了一个快乐的厨师。而我在美国做学术民工时所见到的美国学生,包括来自一些发达国家的学生,基本上家境都比较殷实,另外一方面在美国博士毕业之后的收入通常来说并不比硕士乃至本科毕业的高太多。所以那些欧美国家的学生,基本都是在一种不着急毕业了挣钱的情况下,怀揣着对学术由衷的热爱,把科研当成爱好来做的。既然是爱好,就不大可能以牺牲睡眠,必要的recreation and social time,以及最重要的健康,这样的代价,去谋求更上一层楼。所以通常来说天黑之后老外实验室基本都关灯了,如果没关灯的话在里面埋头苦干的基本上是来自中国、印度等第三世界国家的学生,再就是晚上在黑灯瞎火的地方只要不张嘴绝对隐形的那种老黑——美国本土并不出产黑到这种程度的老黑…… 而也只有把科研当成爱好而不只是任务或者通向未来的一个台阶,才有可能真正做得好科研。做任何一件有挑战性的事情,由衷的热爱都是绝对必须的先决条件。否则,普通人绝无可能面对无穷无尽的困难而依然保持足够强大的动力。
所以我们来回答当前我们国家国情下的这个问题吧:博士毕业之后能干什么?
其实大家都知道,无非以下这么几条路。其中涉及到的详情,我只能说生物医药领域的,其它领域的,请各个领域的朋友们补充。
1.出国做博士后
作为学位,博士到顶了,可是之后还有圣斗士,壮士,烈士。博士毕业之后还有不少人去企业,而做完博士后的人留在基础研究领域的可能性则更高一些。基础研究领域包括高校和科研院所,也不排除一些特别强大的医药和生命科学类企业中的上游研究。但这种研究在西方国家比较常见,在国内还是凤毛麟角——国内能够做点像样研究的企业都不多,从数量上说占多数的都是些倒买倒卖试剂的皮包公司,大家都知道的……所以做完博士后,基本上就要把整个人生献给科学事业了。当然也有少数不得志的,一辈子做博士后,那点工资也够养家糊口……这条路适合真心热爱做科研,生命中没有什么爱好能够压倒科研,为了科研可以牺牲很多东西乃至包括家庭的那些人。正是这些人为全人类的进步提供了最大的动力,他们的自我牺牲值得崇敬。只是,绝大部分人是达不到这一境界的。
2.直接留在高校和科研院所
因为没有博士后经历,即使是国外名校博士毕业回到国内,也得爬几年才有可能爬到副教授职位(二三流大学不用提了,那是养老的所在,读博士就是为了去二三流大学的可以不用看下去了)。国内博士毕业的,即使是名校比如咱交大,要想直接留在一流大学或者去一流科研院所,那对不起,只能从食物链的最底层开始爬。我们实验室几位近几年博士毕业的青椒,包括两位交大毕业的,只能从讲师开始干起。跟我们学生做几乎同样强度的实验,晚上和周末经常加班干活(对学生来说是常态,生物实验不像写电脑程序,有些实验扔下来休息一天可能就报废了得从头开始重新做起),还要负责实验室琐碎的事情,还要给本科生上课。就这样累死累活,每个月到手才4000。当我知道这一事实的时候我简直忍不住要爆粗口了,要知道现在上海的公交司机每个月到手都能有4000!交大本科毕业起薪都能有三四千,工作到正常博士毕业的岁数七八千总有了。吭哧吭哧读到博士毕业,在高校里做了个听起来很不错的老师,收入只能跟开公交的持平?去二三流大学收入会高很多,因为人家求贤若渴,而一流大学根本不怕没人来。即使爬到食物链的上层(需要有国外访学经历、领导过一定级别以上的课题、发表过一定数量和质量的论文,才有资格去竞争晋升的名额),做了教授,据说在咱生物学领域做基础研究的(也就是没有很多来自企业的横向课题,而是主要靠国家的经费生存的),算上正常额度的灰色收入(不能说太细了,但这种“正常额度”内的还算是很厚道的了,而且对低到令人发指的工资来说简直是必须的),每月收入也就刚过万。这就是悲惨的现实。诸君莫怪很多教授搞三产,捞“超过正常额度”的外快,这实在并不是道德败坏到溃烂,而是为生存压力所迫——教授的尊严何在,应有的体面生活何在?
3. 去企业
国内目前一般的生物医药行业企业,刨去那些倒买倒卖试剂的皮包公司,给博士的待遇都要比高校讲师高得多。起薪就翻个倍达到8000左右,很快可以过万。至于皮包公司,小庙也容不下胖和尚,总不能让博士去推销试剂咯。但生物学博士去企业的这个收入,跟其它很多专业的比起来,实在是太寒碜了。做实验最辛苦,毕业难度名列前茅,毕业后收入在博士中几乎垫底(可以跟文科博士抱团痛哭了),这就是生物学博士被称为失足青年的原因。不过好歹月收入万把块,如果配偶收入也还可以,在上海是勉强可以生存下去了。就整个博士群体而言,在国内工作的待遇也还是偏低的。
4. 其它零碎的出路
比如我今后的去向,做本专业英文SCI杂志的编辑,或者去果壳网之类的科普网站/杂志写科普文章。后者倒是我的兴趣和长处之所在,据说待遇也还可以。或者创业。不过本专业创业的难度是极大的。比如做药的话,要知道一个药从实验室开始研究到最后能获准上市至少十年,而且在实验室或临床实验的某个阶段被砍掉的概率至少在七八成。没有哪个创业者能够承担这样的成本和风险。做试剂的话稍微好点,但要搞出自己拥有专利的试剂谈何容易,大部分还是落得个倒买倒卖的下场,走入同质化低价竞争的死胡同。所以除非博士阶段做出过惊天地泣鬼神的原创性成果,而且很快就可以产业化,自己在生物医药领域创业几乎是无法生存下去的。
5. 转行
好吧,可是如果毕业之后转行的话,为啥要读博士?不过到了山穷水尽的地步,走这条路总比饿死好点吧。。。。。。。
三、怎样的人适合读博士?
回答这个非常宽泛的问题前,请允许我讲个我自己的故事。
记得2005年初,我在选择本科毕业论文导师(通常也就是研究生阶段的导师)时,从我大三起带我做PRP的老教授向李老师推荐我,说这孩子对科学有非常纯真的热情和兴趣,思路活跃有灵感,就收了他吧。李老师刚归国,原本不想招太多人,但在德高望重的老教授面前还是答应了。读研前两年,我也确实没辜负老教授的期望,甚至李老师送我出国交流前还表示希望把我培养成他的接班人。后来发生的转折,我的老朋友们都知道,先按下不表。我要说的便是那“热情,兴趣和灵感”。确实,在我刚涉足科研领域时,这三个词放在我身上,我是不用谦虚的。大二暑假里我就从“鸽子每胎生两个一定是一雌一雄”的传言中,结合专业课上学到的皮毛知识,萌生了自己立项做PRP(participate in research program)的想法。于是我扣开老教授的办公室门说明想法,他同意给我指导,但项目由我自己申请。获批三千块经费后,我跑上图去查文献,拉拢了几个同学,靠在我寝室的床上把整个宏伟的蓝图描绘得天花乱坠(就跟现在那些创业公司骗风险基金似的=。=)。然后在老生物楼(现在的本科生物理实验楼)一间实验室堆放废旧仪器的角落里,打扫干净建立了自己的实验室。瓶瓶罐罐和基本的仪器设备是从各个实验室化缘而来的,要用稍微高端点的仪器就要跑上跑下借用。鸽子呢,正好学校里就有,用经费换了超市购物券打点好管鸽子的大爷,就可以去抓几只鸽子,拿几只鸽子蛋。再买了点最便宜的试剂,几个人就开始干活了。2006年交大110周年校庆征文,我以此段经历为材料写的《老生物楼309,我的科研之梦开始的地方》获得一等奖。特等奖获得者全是老者,而我是一等奖中唯一的学生。那篇文章确实是我饱含热泪写出来的,因为写作的时候老生物楼已经在施工改造了,那亲手拼凑起来的小角落,已经与那只从我们手中逃脱而弄得满屋子“鸽”飞蛋打的鸽子一样,成为了永远的回忆。
当时我是学院历史上第一个自己申请PRP课题的,跟绝大部分做PRP的同学不同——他们基本上是去为师兄师姐们刷瓶子装枪头混报告的。后来我自己也带过PRP本科生,试着让他做实验,才知道为什么会这样:教他做比自己做更累,而关键是他做出来的数据不敢用啊,用了能发论文能毕业吗?生物学实验是门手艺活……
PRP那两年中我们自己动手把论文上的文字变成手艺活,艰难也可想而知。不过我们都乐在其中。这其实是最本真的科研——完全由纯真的好奇心驱动,不受任何诸如考核、毕业等要求和标准的污染,没有任何功利性目的。每个周末我们当中的上海人不回家,泡在实验室,是自觉自愿的。当时我跟我妈说,我觉得就算在实验室里扫地的时候也很开心。可惜的是,这种纯真的状态在我去美国做学术民工之后就一去不复返了。然而,当年我的热情,兴趣,灵感,莫非是虚假的?绝不是!现在我恍然大悟,破灭的并不是我的兴趣、灵感和热情,而是科研本应有的纯真的,不带功利性目的的环境。当然,如果没有那段血泪民工史,我的这些财富还不至于这么快这么彻底地化为泡影。
长长的故事讲完了……就是希望那些觉得自己对科研很有兴趣或者被老师这样夸赞的,对科研殿堂充满美好憧憬的弟妹们,要多长一个心眼,要看看自己是不是拥有我接下来要说的这些资质。这些才是科研工作者真正必需的。我把读博士等同于做科研了,因为不管毕业之后怎样,读的过程中每个人必然要自己做科研。当然我只能描述生物医药类(或许可以旁通到化学化工类)研究的情况,其它学科的,作作参考就好。
1.极强的自制力
因为极少有人会从骨子里热爱做科研,胜过喜爱花前月下饕餮大餐环游世界以及一觉睡到中午•﹏• 所以没日没夜没周末缺假期(实验学科的博士生暑假能有一两周假期就不错了,还得看老鼠的脸色),在实验室埋头苦干,必须有极强的自我约束力。靠老板管是没用的,如果处于老板不在就乐翻天的状态,基本上也就只能混毕业了。
2.狭窄的兴趣和有限的社会活动
经常要进城看音乐会?每天晚上要陪女朋友?得了吧。在实验学科读博士,过的绝不可能是正常人过的日子。除非你禀赋惊人又运气好到爆,否则想天一黑就离开实验室该干嘛干嘛,在中国是行不通的。因为这里有博士毕业必在SCI杂志发表一定数量和质量论文的规定。也就是说。虽然科学研究的本质就是探索未知世界,未知世界的面目不可能在几年前就确定,但一个博士生在四到六年的时间内必须把未知世界探索到一定的广度和深度并且取得一定质和量的成果。翻译一下,就是必须做到一定量的实验,以保证去掉必然会存在的“此路不通”之后剩下的都还够。再说得形象点,就好比把一个猎人赶进从没人进去过的原始森林,规定他几天后出来必须带多少大小以上的禽畜,至少总共多少公斤。现在知道为什么中国人论文造假层出不穷了吧?知道为什么纽约大学动物房的耗子们被淹死之后自然科学界的博士们纷纷转帖向这些要延期毕业了的同行们默哀了吧?所以,如果不愿冒造假被抓的风险,又没有惊人的禀赋和好到爆的运气可以用idea击败审稿人(这样也还是必须做实验的),那就用工作量堆呗。
3.说得不好听点,要有点geek
比如什么呢?比如我做学术民工时的那个老板,每天午饭就用微波炉热份冷冻垃圾食品,拿在手里满实验室转悠,逮着谁做实验不够好就骂;每天半夜两三点回家早上八九点来实验室,周末晚一两个小时来同样时间走;一坐在实验台前就快乐得哼小曲儿,回到家除了睡觉吃饭就是偶尔看电视(自己告诉我们的,还很骄傲地说他老婆非常好把所有的事都包了)。这个太极品了?那说说我现在的老板吧,他说他就是觉得坐在办公室里才安心了,幸福了,回到家就无聊得要死,呆不住。他也是两个孩子的父亲。是不是跟大部分人“老婆孩子热炕头,神马来着就老酒”(是这样说的吗,记不起“神马来着”是神马了-_-#)这么点追求不一样?为全人类作出巨大贡献的正是这样一些geek,然而实在是奇怪了点。而但凡科研做得非常出色的博士生,除了刚才提到过两次的特殊情况,多少也有点geek味。或者,至少能在这段时间内看起来像geek。
4.家里有一定的财力
女朋友不很物质(或男朋友是大款),没被催着结婚。第一条是保证博士生熬白了头发终于毕业开始挣钱时,爸妈还不等着他供养,最好还已经准备好了房子,免得博士生还得工作好几年到快要四十岁了才能结婚。后两条是保证博士生能有比较稳定的感情,因为有时候被耗子虐得想跳楼,心爱的人会是最温暖的慰藉(~~o(>_<)o~~)。或者,干脆搞基得了……
5.脸皮要厚,心脏要坚强
被老板骂得狗血喷头实属正常,实验一次成功可以马上去买彩票了。漫漫五年左右的岁月,没这两条属性怎么行?没有也得练出来!
6.不要往上比,要往下比
高中同学聚会,当年考试分数被自己永远秒杀的傻不拉几只会踢球的哥们,带着娇妻抱着宝宝开着宝马,饭桌上充斥着育儿经,股票基金,年终奖,IPO等等话题。此时,兜里只有几百块钱孓然一身来赴宴的博士生,须秉持“不该看的不看,不该听的不听,不该吃的赶紧多捞几口”的原则,在心中默念“我毕竟比华联生活中心卖鸡蛋灌饼的幸福多了”。。。。。。
前几天遇到一个人,是交大一位学霸的亲戚,聊了一会,对这一段又有了新的思路。
先说这个学霸的故事:82还是83年生人,交大航空航天还是机动学院(那个亲戚说不清楚)硕博连读毕业,就在交大留下,拿到副教授待遇,去了美国做博后。父母都只有初中文化水平,但孩子从小读书不用父母管,总是自觉完成所有作业,成绩始终拔尖,初高中经常数学满分(初中在区重点学校一会处于班级中游一会流窜到前几名一会又跌回中游的掩面路过)。从本科到博士年年拿很牛的奖学金,论文发到手软。出国前导师给他二十万让他写本书,在很短的时间内就写完了。到博士毕业也没谈过恋爱,一毕业人家给介绍了个某省高考状元,在海外博士毕业的妹子(一般男人听到这样的妹子都腿软,不敢要啊),很快结婚一起去美国了。
故事讲完了。仰视得脖子已经骨折,惭愧得已经挖地洞挖到地下十八层了。
这样天资聪颖而意志力极强的人,天生就是汉白玉,当然是极其罕见,属于最适合读博士搞科研的极小一部分人。而比较适合读博士搞科研的那一大类人,也在一定程度上具有他身上的可贵品质。除了上篇中写到的,还有以下几点:
7.强大的逻辑思维能力
那位学霸数学经常拿满分,不光是靠拼命用功就能做到的。一些拼命到不要命但逻辑思维能力毕竟没有出类拔萃的女生,数学经常考得到95分但很难拿到满分。物理也一样。学霸的逻辑思维能力是他学到这个境界的必要条件之一。像我这种高等数学课从不拉下一节,作业从来都自己试图完成,但几乎什么都没搞懂过然后毫无悬念地挂在高树上了的人,就是吃了神药每天24小时学习,在他这个专业都未必能博士毕业。换过来,要他像我这样三天打鱼两天晒网地准备了两个礼拜就拿到GRE作文5.5,估计让他去英语系每天24小时学习几年他也做不到。我当时看到题目想了一分钟就开始不停地写,一小时写了几屏幕大约两千多英文词。因为根据我常年观察,除非是极品天才,人的语言文字能力(与形象思维关系不小)和逻辑思维能力极难两全。人的天赋一部分是由大脑结构决定的,这里面又有一部分是由基因决定的,扔不掉,也拿不来。当然也有后天因素,但像我这样一直努力学数学却从来没学好过,从未感受到过数理学科任何一丁点美的,读理工科博士可以,但从入学起就扔掉以后搞科研的念头吧!干脆地、彻底地,啪地一下把那个气球戳破掉。别像我似的,两年前(读博士的第三年)还跟导师说我想毕业后去美国做博后,他莞尔一笑,你生活在火星上吗?
人对自己有个清醒的,准确的,客观的认识,由此规划自己的人生道路,扬长避短,是很关键的。
那么,对所有的专业来说逻辑思维能力都很重要吗?文科我不敢说,但听说也需要相当程度的逻辑思维能力。当然不是狭义地指数理方面那种线性的思维能力,具体也说不太清楚,请文科的朋友来补充。理工科方面,大家知道,生物学是最偏文科的一门。尤其本科时候学的那些东西,生物化学,遗传学,分子生物学,免疫学,发育生物学等等,没有一门需要用到比四则运算更加复杂的数学。对不起,四则运算只是算术,还不是数学。。。。。算术之外说穿了都是文科那种要背的东西,在背的基础上再去融会贯通。即使到了硕博士搞科研阶段,如果不是搞生物信息学、生物工程等少数分支,就算在Nature上发文章,最高级的数学也只是用到方差计算等一些最基础的概率与统计而已。而且我相信至少在近几十年内,生命科学不可能发展成一门以数学为主要工具的,模型化的,线性的自然科学。因为生命现象和活动的随机性、复杂性和动态特性太强,数学工具用来描述这些现象和活动,至少以目前数学的发展水平来看,是达不到足够的准确度的。
就是这样一门不能再“文科”一点的理工科,搞研究缺乏逻辑思维能力还是不行。比如,我每次组会上拿出来的ppt,老板的评语总是“像散文”,在美国时的导师的评语是“像小说”,那已经是我尽量简洁表达的产物了。我绞尽脑汁学人家的样弄出来的图表,总是连我自己都看不下去。但对于逻辑思维能力强的人来说,表达实验结果天然地就是用图表比较爽,要他们用文字描述清楚反而得费不少功夫。所以大家都觉得写论文比做实验痛苦,写完中文还得翻译成英文更痛苦。唯有我觉得直接用英文写论文好轻松,不开夜车两天足够搞定一篇SC。只是我写出来的论文还是像文学作品,现场感描述得很生动而缺少逻辑性。我更主要的问题是得费好大的功夫折腾出一些勉强算是实验结果的东西,才够我写一次文章。可是对于理工科研究生来说,没有做出质和量都在一定档次以上的实验结果,你写个啥?写文章再轻松有个啥用?再比如,设计实验思路,我觉得自己一步步走得已经很逻辑了,老板的评语是“顺序都不对,你不知道做这个实验之前必须先做哪几个实验,出现了问题应该按照什么样的顺序去找问题”,而这种正确的顺序我怎么都学不到位,因为我根本就不擅长那种一步步推导的线性思维。
设计实验不行,trouble shooting不行,表述结果也不行,光会写文学作品那还读个啥理工科博士?即使动手能力强做得好实验有什么用?生物学实验本身都是民工也能做得好的,只要培训足够长的时间。而博士的价值在于把握研究方向,设计实验思路,trouble shooting,以及销售自己的成果。除非导师每一个实验步骤都给你设计好,每一个结果会给你检查,你只需要像机器人一样干活,否则逻辑思维能力差的人即使再努力也绝对不可能成为一个优秀的理工科博士生,继而在科研领域做出大的成就。逻辑思维能力特别差的,像我这种,甚至可能遭遇生存危机,绝非危言耸听。好在我毕业后还有本专业文字工作的饭碗可以端端,可以让我扬眉吐气地实现自己的价值,否则简直是绝望了。我都不知道我高考的时候“理智地”报了理工科中最偏文科的生物学,到底是幸运还是不幸。或许如果我报了数学、计算机、机械动力这一类我小宇宙爆发也还是理解不能的天书学科,大二的时候就会因为挂科太多而被劝退,或许我就横下一条心去学音乐了,整个人生道路就完全不同了。祸兮,福兮?现在想这些也没用了,到了一定的岁数渐渐就信命了,就淡定地接受上帝的安排了。
就是希望让尽可能多的人知道,只要你学理科,逻辑思维能力一定要好,否则就现实一点早点工作算了。已经读博士了的能下船就下船,下不了的就早作毕业后尽快逃离学术圈的准备,别弄到太被动了。
8.有极清晰并且得到严格执行的(阶段性)人生目标
上文提到的学霸,快30岁了博士毕业才初恋然后很快结婚,是不是跟“正常人”不大一样?如果不是取向异常,那就是阶段性人生目标非常清晰而且得到严格执行。我妈有个同事的儿子也是这样,读博士阶段坚决不谈恋爱。追求他的姑娘其实不少,据说不乏非常优秀的。但他就是铁了心这几年要过苦行僧一样的生活。学业当然是完成得非常漂亮。等到毕业,就娶了一位苦苦等了他很多年的姑娘,几乎都没经过恋爱阶段。在他读博士期间这位姑娘多次表白,他很简单地回答,你愿意等就等,不愿意拉倒……我估计啊,有一些姑娘就此不再相信爱情了,或者就变成啦啦了……
这样执行人生目标,或许有点残忍。然而不得不承认,最能做得成大事情的恰恰有不少是这种理性得可怕的人。
读博士最理想的状态,确实是不要有爱好,不要有很多朋友,不要谈恋爱,成天像个机器人泡在实验室或者图书馆。某位教授的原话如此,而且我觉得他说得很到位。这可不是为了考研几个月不打DOTA那么简单,这可是在昔日同窗纷纷踏入婚姻殿堂的几年中,一直要忍受孤苦伶仃的滋味啊。如果一位男博士的女朋友,能够在这样一种情况下:大部分的晚上要等到男朋友干完了活十点十一点甚至更晚才能见个面抱一抱,大部分周末都没法拉他出去逛一逛吃个饭买点衣服,最需要他的时候他正戴着手套在虐待耗子(或者被耗子虐待)连电话都没法听短信都没法及时回,又穷得连送她一根最便宜的施华洛世奇项链都要咬咬牙,就这样陪他一起走过了这么多年的话……那么恭喜这位博士生,他要么是找到了一位也是没日没夜泡实验室的同行,一生中每天都可以回到家继续讨论学术问题;要么是找到了一位打着灯笼也找不着的好姑娘,恋爱的时候在这种情况下都不离不弃,结了婚还有什么能拆散这一对!
暂时写到这里,留待日后补充。
四、怎样读博士?
老规矩,我在这里所能谈论的只能是生物医药领域的科研情况(还不包括生物信息学这种dry work,双手不沾鲜血的孩纸们),顶多能够延伸到化学化工这一类同为劳动密集型学科的失足青年专业。但是这些劳动密集型专业博士的读法,稀释一下之后多少也能用于其它专业吧。不管做什么事情,如果你决心把它做好,做到自己的极致,把自己的价值发挥到极致,而不只是走个过场踏个台阶拿块敲门砖,那你就必须从一百分的天赋、精力、热情和毅力中拿出一百二十分来,不是么?
1.从入学那一刻起就牢记,你是SB,你是渣渣,你什么都不是
在短短几个月内出色地完成了本科毕业论文,得到了“优”的评价,甚至发表在了SCI杂志上,所以你很牛?是的,在本科生当中你很牛。可是当太阳又一次升起之后,现在你是博士(硕士)生了。你的参照系底部从你家那幢楼的底层上升到了金茂54层的凯悦大酒店大堂,并且住在87层行政层的那些顶级大牛也在同一个参照系里面。并不因为你年轻,你缺乏经验,你偶尔疏忽会犯错,你就可以花光了口袋里的资本而继续赖在酒店里,你会被直接从窗口扔出去。学术研究的现状,尤其在中国,就是这样残酷:做不好实验,发不了论文,你就滚蛋,没人会救你。你不再可以只把自己跟你家隔壁的小明乃至楼下那双颊还泛着红晕的阿芳去美滋滋地比。不管你是谁,你有什么历史,你在有影响力的杂志上发了论文,名字在第一位,才有人鸟你。否则你房间里的被子还得自己叠,给钱都没服务生睬你。当然这是指学术圈至少中上游流域的情况。如果你希望毕业之后做一条下游的鱼,戴一顶教授的高帽子,成天拉一帮人吃吃喝喝搞一些名字很漂亮其实就是一包草的“课题”,养两三个学生成天在实验室打DOTA发中文核心期刊综述(不用做实验,零打碎敲摘抄别人的论文就可以凑出一篇。据说有些二三流大学博士毕业就真是不需要英文SCI,搞个中文核心就可以,或者只要求发英文SCI而不限影响因子,那印出来只能当草纸用的英文SCI杂志也确实是有的),或者你就是这样一位教授的DOTA学生,那你就不必那么谦虚了。可是,有点志向的人们,你们愿意做这样一种腐烂得恶臭的鱼?
你以为你在本科阶段就已经有了满脑袋的灵感,好像比老板的还多,所以你很了不起?等你读到了博士,发现自己本科阶段苦读文献坚持操练实验技术终于掌握了的“复杂技能”不过是博士们每天干一直干到要吐的routine job,发现自己引以为傲地写成了一本书那么厚的毕业论文里面没有一个字可以发表到影响因子10分以上的SCI杂志上,你就知道,原来本科时候的自己就是SB,就是渣渣。站在一个小圆圈的边界上,你不知道大圆圈可以有多大,所以现在我告诉你,你的小圆圈什么都不是。这要比你自己过几年才终于发现这一事实,要好得多。
我本科做毕业论文之前带一帮人做PRP的时候,自我感觉是最好的。我简直就是一个导师。我在动手做第一个实验之前就靠在寝室床上把宏伟蓝图描绘得让在下面听的几个同班同学一愣一愣的。那时候上个厕所都会产生新的灵感。我觉得自己牛逼到了迪拜塔顶了。结果玩了一年多的鸽子和鸽子蛋,练就了以后当家下厨杀鸡的本事,却没能把文章发到哪怕是中文核心期刊上。连个确定的结果都没拿到,因为有个跑PCR的技术“难关”,尝试了各种方法,包括偷用我本科毕业论文导师买的顶级的罗氏Taq酶,跑一次PCR,8个样品就花掉1000多块,还是攻克不了。几年后我知道PCR只是比装枪头略微高级一点点的基础技能,要用到的时候五十个样品一字排开呼啦啦地跑,而且在生物公司里为客户做检测的大专文化程度技术员,做PCR比我们这些博士生牛多了。本科的时候这样自认为牛X不要紧,成了博士生之后,尤其是头一两年中,还这样那就惨了。以为老板的想法也没什么牛的,好像还是自己上厕所的时候迸发出来的灵感更有可能做出大文章?你还不知道没有足够的文献积累,没有在这潭泥浆中摸爬滚打好几年,你迸发出来的灵感确实有可能做成了大文章而你导师的想法做到一半就死了,但这种概率,我觉得不比我们全都要在几天之后分解成游离原子和分子状态的概率来得大。你吃个饭迸发出十个灵感,激动得要死,被老板嘲笑得无地自容,你很愤怒。但老板只提出了一个想法,两年后师兄把它发到了Nature上,而你的十个想法没有一个能够做下去的。你傻眼了?
所以,切记,当你开始学术生涯的时候,扔掉你本科时候热得烫手的GPA和牛X闪闪的论文,从零开始,跟着你的导师慢慢学。前提是你的导师确实是有学术水平的。如果不幸撞上了一个不学无术只会喝酒骗钱的,又没法转导师了,怎么办?我的导师说得好,教科书和论文(当然不包括中文论文和印出来只能当草纸用的英文SCI)是最好的老师,在他们面前人人平等。如果有一篇论文一本教科书写的东西我自己也不懂,那我也是它的学生。所以只有一类人可以不鸟我这一段长篇大论,那就是禀赋异于常人,并且敢于跟老板拍桌子说,我不鸟你的idea,但你还是要给我经费做实验的牛人。
2.你是木头人,你是机器人
读了博士,夸张点讲,你就不是人。人都有七情六欲,人都喜欢睡懒觉,人都喜欢吃好吃的,人都喜欢扔下工作去做自己喜欢的事情。如果你工作了,你抑制自己这些本能的动力或许来自于绩效考评,来自于下个月的零花钱额度,来自于老板那双贼溜溜的眼睛。可是大部分博导并不会像企业老板那样对你严加看管,或者即使管你,毕竟跟劳务聘用关系基础上的约束力不是同一个等级的。那读博士的时候你要强制自己尽量远离这些本能,就只能靠前面两篇文章所说的极强的自制力等品质。
不要抱着侥幸心理,觉得我就玩这几天,耽误几天的实验,没事。读博士最理想的状态是你的脑袋里始终充满了学术那些事,从睁开眼睛到睡着都这样,那你才能保持对学术最高程度的敏感性。先不说有些实验在有些步骤上一旦停下来就算彻底报废了所以你必须每天守在实验室。就是有些可以在某个步骤停下来然后过几天重新启动的实验,你的敏感性降低了,你做实验的手感减弱了,你的脑袋里还残留着度假期间的欢愉,心时常从实验室飘到那美丽的沙滩,那你不把实验搞砸了就算撞大运了。所以读博士期间,能不回家就不回家,能不旅游就不旅游,能不腐败就不腐败,能不逛街就不逛街。君不见我们实验室漂亮的师妹们,几年来买衣服都是利用实验间隙上淘宝,进城逛个商场早已成了奢望。上海同学最好周末就别回去孝敬父母了,前几年我经常就是这样的,三个礼拜一个月回一次家。不要觉得博士学制有四年,然后还可以延期两年,好像时间非常宽裕。我很快就要进入第六个年头了(扣除在美国交换的一年),博士资格面试的情境还恍如昨日呢。
博士毕业了做科研,如果能混到个PI的位置,不要以为自己爬到食物链顶端了就可以休闲养生了。高处不胜寒啊。你在跟全世界的同行竞争杂志上那两三页纸的位置,那个位置就是你和你学生们的命根子。在美国,系里公用的共聚焦激光显微镜只要10美元一小时,一个楼层就有两台所以几乎任何时间都可以去用,你在国内是400人民币一小时加200开机费;人家只要在晚上八点前把DNA样品放到楼下一个窗口,贴上自己实验室的条形码,第二天一早就有测序结果发到你的邮箱,你在国内要打电话联系皮包公司来取样然后过几天才拿到结果;人家一幢楼里从早到晚不间断地有学术报告,诺贝尔奖获得者来做个讲座根本就是家常便饭,去听报告经常还有免费的食物供应,你在国内来一个老外教授就像过节了似的;人家凭一个学生ID可以想下什么文献就下什么文献,你在国内要下一些文献只能找在海外的师兄帮忙,隔了时差给你发过来;人家跑完胶在凝胶成像仪上按个按钮,直接在旁边的打印机上把图打印出来,看到好的文献在电脑上按个按钮,直接在大堂里的打印机上免费彩色打印,人家的实验记录本是活页的装订得像时尚杂志一样漂亮,而你在国内实验室那台像蜗牛一样慢的打印机没墨了还得打电话让外地口音的大妈来换墨盒;人家一个系十个实验室就有四位秘书和一位主管秘书全职服务,大到申报和报销经费小到个人要订个机票都帮你办了,实验室订工作午餐自己垫付了把收据交给秘书一小时之后就能拿回现金,你在国内一个课题结题要由一位青椒带动几乎全体博士生像四大里面突击搞审计那样折腾,然后一天跑个四五趟财务处去欣赏窗口里面那张长满麻子像铁板一样硬的脸,有时候还要长途跋涉到市区里面去欣赏另外一些面孔。以上这些“人家”都是我亲眼所见,亲手所做。可正如上文所说,你在金茂凯悦酒店里,不因为任何理由而会有人对你施恩。所以你要在中国读博士,要在中国做PI,很多方面要比在国外辛苦得多。但你是木头人,是机器人,你不知道辛苦,不懂得艰难,不理解辛酸,不需要休息,你唯一的任务就是埋头苦干。
如果你的人生哲学并不是事业至上,并不是不计一切地投身于工作甚至连付出健康的代价都在所不惜,那就至少不要做科研梦了吧。博士还是可以读,但委屈一下自己,在这几年中不要做自己了。或者,如果你觉得自己真正的事业并不在你的专业你的工作上,那也一样。实际上每个人人都会为了自己所认定的事业而付出他所能付出的全部心血、精力,时间和代价。比如我有时候会因为躺下去之后突然闪现写作灵感而半夜里起来,查找多资料来写一篇关于音乐或者别的什么的长文(虽然通常是又臭又长,事后自己也不要看)。但我现在不会为了做科研而这样了。如果你的情况跟我相似,那就不要硬逼着自己走学术道路了,你真心不适合。事业并不仅仅包括那份供你养家糊口的工作,事实上仅仅以养家糊口,名利双收,拓展人脉以及晋升职位为目的的工作根本谈不上是事业(career),那只是职业(job)。事业必须是没有上下班的界限,没有退休的概念,少了它你的灵魂就会枯竭的那块玉石。你的事业在别处,那就现实一点,尽量混个毕业找份工作,去支持自己一辈子的事业吧!
要想读好博士,光把自己当成渣渣,并且成功变身木头人机器人,还不够。那两条我个人觉得最基础,但还有一些Tips也很重要。
3.做实验要高度专心
我导师规定手机不得带入实验室,一开始我觉得过分,后来自己吃了苦头,已经自觉养成习惯了。生物学实验是细致到家的手艺活,一个半秒钟的疏忽就可能让几十甚至上百小时的劳动成果完全报废。不像编程,打错了字改正一下就行,哪怕全部写完了再debug也能挽救。而有些生物学实验会仅仅因为一次走神就做砸了,必须重新来过,如果浪费了实验动物可能还要等很久才能订得到下一批,代价会非常惨重。比如给一排ep管加试剂,标准做法是加完一管就把管子往上移一格以防一走神忘记自己加到哪一管了。尤其往大体积比如一两百微升的溶液里加一微升的酶,全都是无色透明溶液,根本无从确认有没有加过酶。加两倍的酶可能就会影响实验结果了,漏加当然不用说了。(忍不住吐槽劳动密集型实验,这种机械的事情,不识字的农妇都做得来。完全可以实现自动化,可是博士生比机器便宜得多啊)如果一边做实验一边听音乐,像我这种只要喜欢的音乐一响起来,可能连别人跟我说话都直接从同一个耳朵出去的人,那完了。心里发一声感叹“真好听啊”,加完一排样品才意识到忘记把加完了的管子往上移一格,根本不知道自己有没有漏加或重复加。继续做下去吧,要冒几天之后结果出来才知道加错了的风险。从这个步骤开始推倒重来吧,不甘心。最后基本上还是乖乖取出冻存的备份样品(什么东西都要留备份,留后路,非常重要!),把耳机放回办公桌,重新加样。所以从几年前开始,我就习惯了进实验室不带任何会导致自己分心的东西。可是脑袋里储存的音乐删不掉,有时候几个小时坐下来受不了了,脑袋里突然蹦出一句什么旋律,完了……
文科做研究当然也需要专注,但假如必需临时放下手头的事离开,只要把当前的想法简单记下来回头继续,已经写下来的东西总不会丢掉。总不至于像实验那样,一旦回不到原来的点就要把几天几周甚至几个月的努力全部推倒重来吧。
4.底子不够厚就老老实实照规矩来,别乱创新
Protocol上的繁琐步骤,老板的奇异规定,师兄师姐的古怪经验,可能照着做很麻烦,但别轻易地扔了它们。手艺活靠的就是经验,很多经验可能看起来没道理甚至违反常理,但在你成熟到可以向别人系统地传授经验之前,别人的经验就是王道,至少在你尝试过,并与自己的想法系统地比较过之前。科学研究需要质疑精神,需要创新,但是盲目质疑,就跟反右时我外公仅仅因为给员工分发福利就被打成右派一样是犯罪,而缺乏根基只靠拍脑袋的创新就跟钢产量两年赶英三年超美一样是胡闹。尤其在刚开始读博士时,你是渣渣,渣渣还质疑啥,创新啥?
5.读文献,读文献,读更多的文献
二战美国海军名将“公牛”哈尔西被问到准备如何对日作战时回答,杀日本鬼子,杀日本鬼子,杀更多的日本鬼子!读文献也一样。夸张点说,读多少好文献决定了毕业时能发多少好文章。没有通读几百篇英文文献,不要跟别人说你博士毕业了。文献当然没文学作品美丽,实际上简直是丑陋,八股文字读得让人很反感。但这些“日本鬼子”必须杀掉。惭愧,虽然我读英文文献比大部分理工科学生轻松得多,地铁上半小时足够我把一篇四五页的英文文章从头看到尾还不用字典。但我没读过多少文献,反正肯定没有我博士期间读过的五线谱的页数多。所以我做实验有如盲人摸象。设计实验不知道一条好的实验思路是怎样的,需要哪些理论和实验基础,到了每一个阶段通常应当怎样走。具体的实验方案方面,也没有足够的文献积累可供参考。慢慢地我才懂得,因为偷懒而省下一个小时的文献阅读时间去玩,几乎一定会付出几十倍的时间去做徒劳无功的实验。另外补充一下,把文献从头读到尾是很愚蠢的做法。除了必需精读的几篇顶级综述,以及为了学习论文写作而解剖的几篇研究论文,大部分论文只要读通abstract,扫一眼图和表格,把自己用得到的实验方法摘录下来,再看看人家引用的参考文献有哪几篇可以为我所用,就够了。能用一句话概括论文的核心idea和结论就记在本子上,否则就划出来留待日后翻阅。
6.重视实验记录
做实验的时候用到的试剂仪器和方法,当时可能早已司空见惯,懒得重复写在记录本上。但做完实验写论文时,要写实验材料和方法,就想不起一年前做实验时候的一些细节,当时所用的试剂早已用完了包装扔掉了,当年的测序报告可能已经找不到了,这下傻眼了。我就吃够了自己散文式实验记录的苦头,有时候偷懒没把具体信息写全,甚至先做了实验回头再写,记忆已经有误。实验结果也要妥当有序地存放好,电子数据一定要备份,免得电脑失窃或坏了之后欲哭无泪。
7.重视presentation skill的锻炼
我在美国时第二个导师传授了我很多经验,包括:做presentation一定要是audience oriented,文字要少图表要多,严格控制在每张slide一分钟然后按总时间决定slides数量,slides之间要有承上启下的衔接,演讲前最好背出讲稿尽量多看观众(我那次把整个半小时的讲稿,以PPT里的一点图表和文字为依托,硬是全部背出来的,所以跟听众交流比较多,系里的师生反响特别好)。她说,一个好的科研工作者除了做得一手好实验,还要是一个优秀的salesman。能不能拿到足够的经费,很大程度上看你能不能成功地把自己的成果卖出去,尤其在美国(在中国可能主要得靠酒量)。但不管怎么说,即使博士毕业之后不搞科研,在博士毕业答辩的现场作一次精彩的展示,毕竟是给自己好几年的苦读划上一个圆满的句号。而且工作中也难免作报告之类的吧,利用博士期间每一次组会作报告的机会,锻炼自己的presentation skill吧。最最起码,把妹也用得着。。。。。。。。
8.尽量多帮助实验室里的每一位成员
生物医药行业不仅是一个劳动密集型行业,而且非常接近流水线生产的形式。不是说日本那种每个研究生负责一项技术然后真的以流水线形式生产论文,而是说这个领域内的技能种类实在是太多了,一个人不可能精通所有的技能,大家互帮互助是团队存在之最重要的意义。光说实验领域,怎么着也能数出至少一百种,比如分子克隆(这其中的倒平板、转化、涂板、挑克隆、抽质粒、酶切、连接等步骤已经打包了,否则能数出上千种吧),PCR,Western,Southern,CoIP, 流式细胞,共聚焦显微镜,显微注射,动物解剖,血涂片制作和血象观察统计,实验动物的各种注射(尾静脉,腹腔,皮下等等),各种生理指标的观测,实在是太繁杂了。像琼脂糖凝胶电泳,SDS-PAGE这种天天做的事情已经都不能列为技能了,这都成本能了。每个实验室可能用得到的就得有几十种,而每个人在博士阶段可能用得到十几种。如果想要在每一种技能上都成为专家,估计可以读一辈子的博士了。所以大家互帮互助,各自多做自己擅长的事情,大家都做不了就求助于楼上楼下其他实验室的兄弟姐妹们。大家都是失足青年,抱起团来特别有爱。在实验技能之外还有文字技能呢,比如我就经常帮人家修改论文,换取别人帮助我一起做实验。一定要记住,试图靠一己之力完成劳动密集型专业的博士学业,除非你禀赋异于常人,否则几乎是不可能的。
五、在美国读博士
在这个系列的最后,我想就我在美国做学术民工的所见所闻,谈谈在国外生物医药领域读博士的情况。我在那边时间不长,也不是拿学位的性质,所以描述未必准确, 还请在美国读博士的朋友们补充指正。另外,欧洲和澳洲的情况我不了解,请相应的朋友们帮忙补充,谢谢。
首先要岔开了说下目前在中国读博士的现状。在中国读博士,实在是不得已的下下策,除非能进中科院上海生科院神经所这类体制接近国外研究机构的异类,那还稍好一些。如果我本科时的数学物理等公共课能不挂掉那么多,凭专业课成绩和GT分数早就出国读博士了,也就不会有那么多曲曲折折。中国很多高校和科研院所,对博士毕业条件的规定实在是荒唐。虽然在前文中我说过,因为国情不同,如果在我国也像美国那样对博士毕业条件不作硬性规定,而由答辩委员会对博士学习期间实际所受学术训练的质和量以及学生实际学术水平进行考察来决定(我在美国就见过没有第一作者SCI论文而毕业的哈佛生物学博士来应聘博士后)。那样的话,先不说国内大部分导师有没有这种考察能力,此制度本身必然导致更大范围内更严重的学术腐败。但并不是说除了这种当前情况下最合理的方式,就不可以有其它辅助方式。以其为单一标准,比如交大规定理工科博士必须发表影响因子总和大于三分的至少两篇文章,这种强奸学术的规定逼迫学生要么抓住狗熊将其痛打一顿让它承认自己是兔子,要么就尽量规避风险,尽量在别人走过的老路上试图挖点残羹剩饭吃。因为创新程度越大必然意味着风险越大,意味着出成果所需时间越长。没有人会愿意拿无法顺利毕业为赌注,去赌自己可能在创新的领域中作出大成就。只有我在前文中反复提到的“少数秉赋异于常人而且运气特别好”的人可以例外。这种规定,与其贼兄盗弟——高校教师和院所研究员晋升的规定中关于发表论文质和量的部分一样,是我所知道的学术规定中最荒谬,危害最大的。它们不仅给博士生和青年教师施加了无谓的压力,催生了一大堆在世界范围内臭名昭著的,印出来只能当草纸用的中国式SCI/EI论文(包括我自己的在内),而且使我们这个民族的创新能力受到极大的损害。
昨天排四重奏时我跟Patrick聊天,他是赛诺菲中国(制药)的部门总监。他说据他在曾经工作和生活的几个地方——美国,法国,日本和中国——的观察,中国科研人员所做的具有真正原创性意义的研究,是最少的。这种原创性意义不仅不可能用SCI论文数量来衡量,而且SCI论文影响因子和被引用次数也不是准确的标准,因为写论文的时候尽量引用自己人的论文,不管实际上是不是真的在文中具有参考意义,这是很自然的。中国人多嘛,所以中国人的论文被引用次数上升很快有此一个原因。相对地,做出一个成果所需的时间倒是一个更有规律性的标准。CNS(Cell, Nature, Science)上的文章,鲜有在一两年之内就做出来的,而那种印出来只能当草纸用的杂志,里面的文章多是同一个课题组一年能灌好几篇的水文。一项真正有意义的原创性工作,除非得到上帝赐予的灵感从而一次尝试就成功,必然要经历艰苦的摸索,反复的尝试,再加上经验,灵感,日复一日枯燥难耐的工作,才能诞生。中国的博士培养制度为啥不允许培植这类珍贵果实的土壤存在?我们的博士学制一般是三到四年,交大去年才延长到四年,又规定延期不得超过两年,像我这样出国交流休过学的还不能对休学的时间相应给予补偿。去掉疲于对付各种课程(只有赵立平教授的课是真正有意义的,其它都是枉然浪费时间)而无法投身实验室的第一年,论文投稿准备答辩的最后一年,只剩最多四年。等到导师摸清了学生的特点而给了他合适的课题,学生也锻炼出了堪用的能力,课题做到能判断可否继续下去的程度,又是一到两年过去了。最后只剩一两年时间,想做原创性研究?连失败一次的机会都没有。
美国的情况如何呢?我有两个表姐都在美国拿了生物学博士,其中一个还在哈佛做过博后,加上我自己做交换生期间的耳闻目见,算是有所了解。博士读个七八年,在美国太正常了。在这期间没有发表第一作者SCI论文的硬性要求,那干什么呢?在学术的海洋中畅游,这才能叫畅游!一开始就是在多个实验室轮转,寻找到你情我愿的最佳组合。然后,甩开胳膊游泳。这个领域不喜欢,这个课题似乎做不下去,没关系,只要老板不太harsh的话,就换一个。发表文章不是唯一目标,接受从思维方法到具体技术的严格训练才是要务,也正是论文答辩时所要考核的。
美国博士淘汰率不低,所以含金量在全世界最高。美国学生不怕白读了几年博士然后还是个学士?这当然有点悲惨,不过美国人读博士失败的代价要比中国人小得多了。在美国,即使开公交车,也可以活得快乐,体面,有尊严。我的一位朋友在美国读书期间有个美国室友,家里坐拥金山银山,但他偏要学厨师,背井离乡租房做厨师。因为他的人生理想就是做个优秀的厨师。在这样一个社会,博士毕不了业并不意味着世界末日。可是在中国就不一样了。所以我们这里博士毕业要求很硬,而达到要求之后,审通过,答辩不过是走个过场,顺带教授们聚个会吃个饭。我从来没听说过发表论文达到要求,大论文通过盲审而在答辩现场被枪毙的事情。从而这个仪式也就失去了其作为人类社会中,就学历而言最高层次的智慧展示和交锋,这样的光辉和神圣色彩。
对于有足够才干和机遇的人来说,出国读博士是不二选择。之前的文章只是写给那些已经在国内上船或者因为各种原因以后还是要在国内上船的人看的。那么,在美国读博士要注意什么呢?
1.千万避开三种导师
中国人,女人,AP(Assistant Professor,刚取得教职的人,最低的职称)。中国老板往往擅长欺负自己的同胞,而且自己也是干活不要命,所以学生也不得不卖命干活,这是出名的。我们读书是为了锻炼和完善自己,不是去卖命的。女人呢,做到教授,尤其学术光环闪亮的,跟普通的贤妻良母几乎必有本质区别,这是不言而喻的。科研能力强的女导师,有好多都不婚,结了婚而家庭幸福的也很少。自己的家庭都不幸福,做她的学生能幸福?至于AP呢,刚拿到教职建立实验室,急于出成果,各方面条件又有限,一个学生干两三个人的事情。实验室规模又小,成天盯在学生屁股后面。我在美国短期呆过的两个实验室,第一位老板是已经拿到终身教职的中国人,但也是在学术圈里已经是一流大牛而自觉自愿每天朝八晚二到晚三(就是第二天。。。)在实验室,年中无休的特殊人才;第二位则集中国人,女人,AP三项于一身。于是,我那暗无天日的生活也就在情理之中了。无数前辈们用血泪买来的教训,可不止我这孤立的两个例子,绝对是有统计学意义的。弟妹们切记,切记!不是说这三类人当中没有正常一点的,只是要冒太大风险才可能找到,何必呢?斯斯文文,闪耀着人性光芒的欧美学术大牛,一抓一大把。他们实验室里面贴的不是Rules&Regulations and Protocols,而是lab party and tour的欢乐照,晚上和周末不会像中国老板的实验室那样总是晃动着人影,门口却挂着比中国实验室更多的CNS文章。不像我这样被直送地狱而有选择之自由的朋友们,你们选哪种?顺便说句,碰到印度老板也要绕道走,原因和中国老板差不多。
2.Hard Working
这还是必须的。虽然我们去国外留学,不是用严重损害健康的代价去换取什么,不是为了在一堆中国人之间没日没夜没假期做几年实验,就和在国内没什么本质区别。但毕竟也不是出去度假的。在美国做科研,软硬件条件确实好,但这不意味着你可以有丝毫的松懈。除了像爱因斯坦那种天才,拍拍脑袋演算几张草稿纸就可以创造一个新理论,大部分人做科研即使运气再好,也离不开非常勤奋的工作。基本上,在劳动密集型领域读博士,想每天晚上都窝在家里,周末总能正常享受,属于痴心妄想。用功当然也得讲究方法和策略,不过楼主作为一个在错的船上无甚成就的家伙,在这些方面提不出什么建议。只是告诉大家,在国外一样要过不是正常人的日子。
3.多交外国朋友
这里面有两层含义:一是生活上的朋友。在美国这样一个大部分人口都是信徒的基督教国家,我所遇到过的大部分老美确实比较善良,易于交往。初来乍到,当地的朋友所能给你的帮助和安慰非常重要。我在那里认识了学校乐团一对老夫妇,在那里他们就是我的美国父母,很多难关是他们提供帮助才度过的。五年来我们一直还保持通信。同龄人中也有很多非常nice的。回忆起来,当时认识的中国人中甚至没一个记得起名字的,而外国朋友依然可以随口叫出一打名字。并不是我崇洋媚外,中国人之间,尤其不知道为什么在国外的中国人之间,缺少美国人那种单纯,直率和真诚。我所在的小城市位于中部地区,民风淳朴,东西海岸大城市不太一样。但不管怎么说,即使只是出于在这几年中多些玩伴,困难时多得到些帮助和安慰的功利性目的,多结交一些来自不同文化的朋友没有坏处。第二层含义,多到其它实验室串门,多搭讪欧美学生。他们在科研方面的思维方式,看问题的方法等等,很有益处。具体的知识和技能都是浮云,而自主学习的能力,科学的质疑精神和创新精神等等,才是博士学业真正带给人的学术方面的财富。从小在应试教育的泥坑里摸爬滚打长大的中国人,不利用出国学习的机会补补自己的短板,岂不可惜?不用说了解异国文化,拓宽自己视野等这些非学术范畴的好处了。
4.多参加学术活动
欧美国家的学术活动通常免费提供不少好吃的,上面的人讲PPT下面的人咔咔开易拉罐嚼bengal并不奇怪。不过这当然不是重点。我觉得美国学术界相对中国来说,最大的优点不在硬件设备,而在于参加不完的高质量学术活动。不像国内一些什么博士生论坛之类搞得形式大于实际意义,美国学术机构中的seminar,以我所参加过的而言,那种大家勤于思考踊跃讨论的氛围,在国内几乎找不到。更不要说从早开到晚的讲座,大师云集。就我所在那个小城市的研究所,短短几个月内,生物医药领域的诺贝尔奖得主就来过好几个了,我在交大十几年都没见过那么多生物医药领域诺贝尔奖得主 。
关于在国外读博士的Tips,就先说到这里了。
六、结语——关于事业
很多人说,科学和艺术在较高层次上是相通的。在下不才,在科学领域只能仰望那“较高层次”,无法与自己在艺术领域的感悟“相通”。但是,在一部奥斯卡最佳纪录片From Mao to Mozart中,在犹太裔美国小提琴大师斯特恩访华时所说的几段话中,我找到了这种沟通艺术和科学的桥梁。
Being a musician is not a profession. It’s not just a job, and it’s not something occasional. It is the totality of your life , and your DEVOTION to something in which you BELIEVE PROFOUNDLY. And you have to BELIEVE in order to make other people BELIEVE.
Unless you feel that you will live with music, that music can say more than words, that music can mean more, that without music we are NOT ALIVE. You don’t feel all that, don’t be a musician.
Every time you take up the instrument, you are making a statement, YOUR statement. And it must be the statement of FAITH, that you believe this is the way you WANT to speak, not the way you are REQUIRED.
在前两条中,只要简单地把music换成science,把musician换成scientist,然后去掉关于音乐与语言之间的比较,那直接就是对希望从事科研事业的人所说的金玉良言。第三条,大师说的是中国音乐教育体系的弊端:不重视学生内心的WANT而REQUIRE他们去make a statement。这原话移到中国的学术圈,又有什么问题!
仔细看看第一条吧。若要从事科研事业,除非你觉得科研对你来说并不仅仅是一份混饭吃的职业,不仅仅是偶尔为之的工作,是你生命中的全部,你离开了科研就没法活下去。如果不满足这些条件,那还是算了,去企业做研发吧,那里有上下班的概念,下了班有自己的生活。而大学和科研院所里是没有上下班概念的——not occasional。我遇到过的两位导师就是这种“离开了科研就没法活下去”的人,科学界最杰出的基本上就是这一类人。
然后,科研要是你的信仰。人可以是有神论者也可以是无神论者,但最好是有信仰者。若要从事科研事业而不是科研工作,最好信仰科学本身。信仰它能够带给人类的一切力量。如果像我这样渐渐地怀疑科学的力量之界限究竟有多大,开始相信有些东西是以人类的识、工具、智慧和力量所永远无法企及的,是神秘和不应当为人类所触动的,那还是不要搞自然科学了。你都不相信自己搞的东西会具有overwhelming power,那你搞个毛线?就像你作为领导说I have an idea,但你又说but I am not sure how many people would say yes to it.
最后一条,如果你在读本科和硕士的时候,觉得自己写到论文里的东西是一些自己都不相信的bullshit,是你被毕业发表论文的要求REQUIRE要写的而不是你发自内心WANT写的,那还是趁早下船吧。如果此时你的博士学业也就刚刚开始,那下船还来得及,或者赶紧把毕业后的目标从科研机构转向企业,那也好多做准备。
其实,真要做一份事业,不管是哪个领域的,不管形式上是不是一份工作(经营一个家庭,教育一个孩子,完善自己的心智,何尝不是一份需要投入无限精力,没有上下班概念,持续终生,并可能带来巨大回报的事业!),怎能少得了devotion,怎能不是your DEVOTION to something in which you BELIEVE PROFOUNDLY? 要做一份事业,你怎能像只做一份工作的凡人一样,计较加班工资,盘算如何最大程度地用好年假,每天只想着快点完成任务回家哄老婆抱孩子?
有时候我们这些科研领域的门外汉看那些全身心扑在实验室的大牛,觉得敬佩而又困惑,为啥这些人好像对基本的精神和物质生活无欲无求,为啥这些人会自觉自愿加班加点又多拿不到一分钱。实际上,对于离开了科研就无法活下去的人来说,实验室这一方天地就是他整个的精神和物质生活之界限,而家只是个回去睡觉的地方(我的一位导师亲口这样说的)。在实验室里,他感到无比的满足,安宁和幸福,他在此实现他的价值。我们无法理解,但实际上,我们当中很多人会在另外一方天地中找到全部这些财富。比如对我来说,任何我能听到音乐,能拉琴,能码字的地方,就能够给我满足,安宁和幸福,能够实现我的价值。只不过我没有偏执到觉得这些就是我整个的精神和物质生活之界限,我觉得家绝不仅仅是个回去睡觉的地方。
所以,其实还是不要把这些人称为geek了。为全人类文明的进步作出最大贡献的人群当中,就有这些牺牲了正常人很多难以割舍的东西而DEVOTE到科学中的伟人。
但并不是每个人都可以成为这样的伟人。当我们面临升学的选择,不妨扪心自问,我能达到前两句话中所提的要求吗?或者说,我心中有没有另外两个词可以取代science和scientist?如果science和scientist被取代得毫无疑义,那如果你还年轻,还有机会,那就勇敢地遵从自己内心的渴求吧!
有一句话永远是对的:只要你在做的是一份事业而不只是工作,不管它本身给你带来的收入可能多微博,不管在世俗的眼光中这如何算不上一份体面的工作,从你开始从事这份事业的那一天起,你已经成功了!








































 是将整数k表示为两个平方和的方法数,
是将整数k表示为两个平方和的方法数, 是Ramanujan和。
是Ramanujan和。















































 空间(
空间( )中的三角多项式
)中的三角多项式  ,有
,有  ,这一结果在逼近论中广泛应用。共轭函数的可积性:若
,这一结果在逼近论中广泛应用。共轭函数的可积性:若  ,则其共轭函数
,则其共轭函数  ,且满足
,且满足  。Zygmund 类(Lip
。Zygmund 类(Lip  ):修正了经典 Lipschitz 空间的定义,解决了整数阶光滑函数的逼近问题。
):修正了经典 Lipschitz 空间的定义,解决了整数阶光滑函数的逼近问题。 空间:用于刻画共轭函数的可积性,成为调和分析中权重理论的基础。
空间:用于刻画共轭函数的可积性,成为调和分析中权重理论的基础。 空间(有界变差且满足 Lip
空间(有界变差且满足 Lip  的函数):证明其傅里叶级数绝对收敛,在有理逼近中优于多项式逼近(如 Petrushev 和 Pekarskii 的工作)。
的函数):证明其傅里叶级数绝对收敛,在有理逼近中优于多项式逼近(如 Petrushev 和 Pekarskii 的工作)。
 空间的有界性(
空间的有界性( )。建立了核的尺寸条件、光滑性条件和消失矩条件(如
)。建立了核的尺寸条件、光滑性条件和消失矩条件(如  )。该理论推广了 Hilbert 变换和 Riesz 变换,并为偏微分方程的正则性分析提供了工具。
)。该理论推广了 Hilbert 变换和 Riesz 变换,并为偏微分方程的正则性分析提供了工具。

 在弱
在弱  型下有界,则对中间空间
型下有界,则对中间空间  也是强有界的。这一成果成为 20 世纪 60–70 年代算子插值理论的核心,影响了 Peetre 的 K-泛函和 J-泛函方法。
也是强有界的。这一成果成为 20 世纪 60–70 年代算子插值理论的核心,影响了 Peetre 的 K-泛函和 J-泛函方法。
 和 Lusin 函数
和 Lusin 函数  刻画傅里叶级数的收敛性。该理论后被 Stein 推广至高维,成为研究多变量调和分析的重要工具。
刻画傅里叶级数的收敛性。该理论后被 Stein 推广至高维,成为研究多变量调和分析的重要工具。







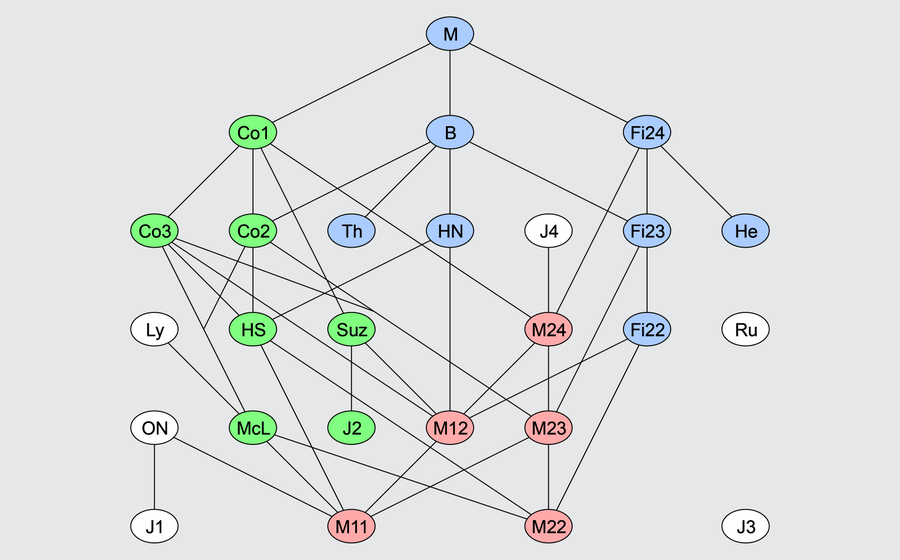
 ,它没有非平凡的正规子群(即除了
,它没有非平凡的正规子群(即除了  和
和 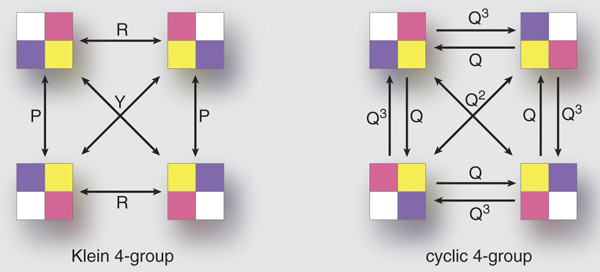
 (
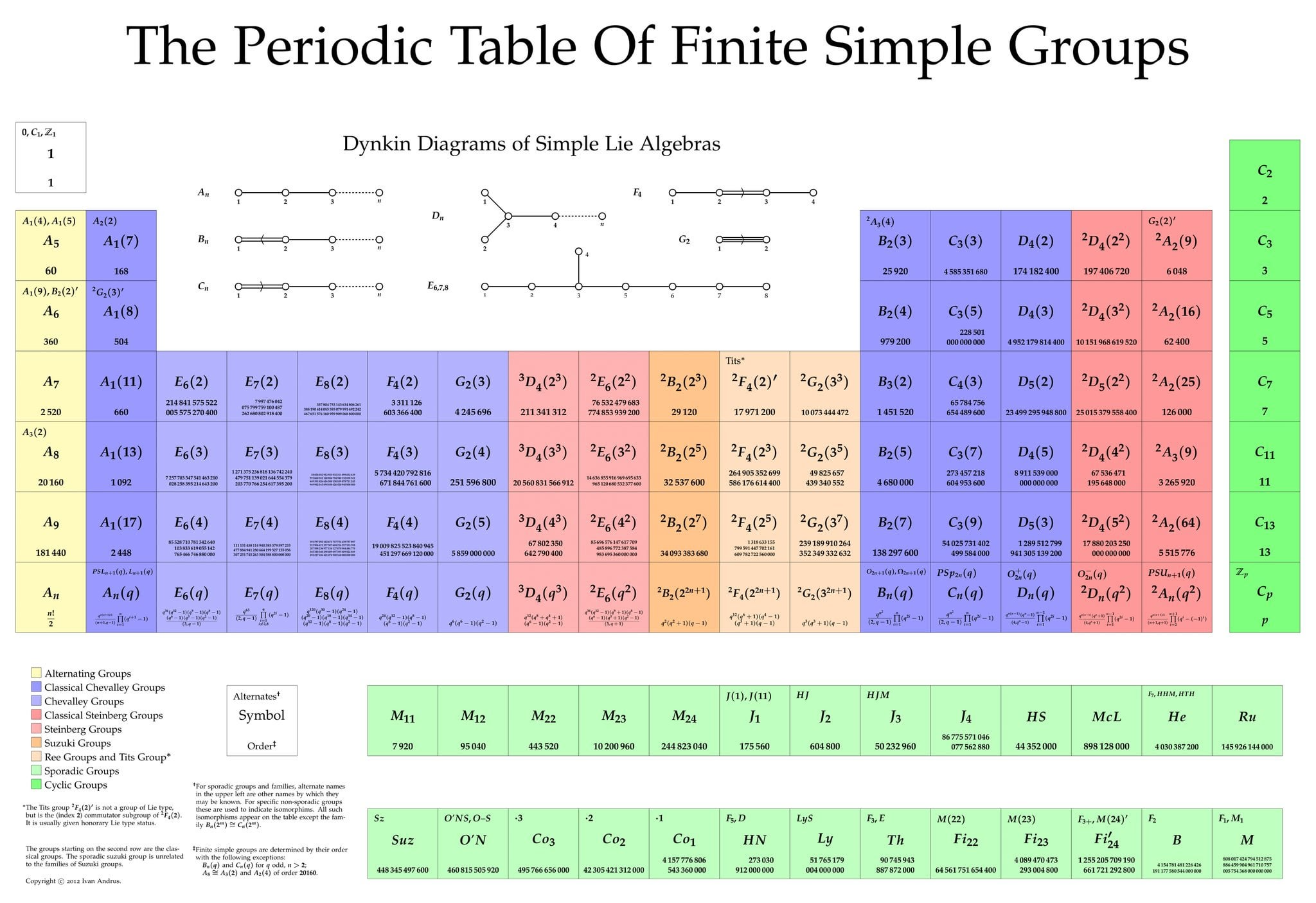
( )和某些线性群是单群。1892年,德国数学家奥托·赫尔德(Otto Hölder)首次明确提出“分类所有有限单群”的构想。单群是数学中的“原子”——它们无法分解为更小的群结构,就像质数是数的基本构建块一样。赫尔德的开创性工作激发了早期研究者如伯恩赛德(Burnside)和科尔(Cole)的兴趣。伯恩赛德在1899年证明了第一个分类定理:若一个非阿贝尔单群的所有非单位元均为对合(阶为2的元素)或奇阶元素,则它必同构于
)和某些线性群是单群。1892年,德国数学家奥托·赫尔德(Otto Hölder)首次明确提出“分类所有有限单群”的构想。单群是数学中的“原子”——它们无法分解为更小的群结构,就像质数是数的基本构建块一样。赫尔德的开创性工作激发了早期研究者如伯恩赛德(Burnside)和科尔(Cole)的兴趣。伯恩赛德在1899年证明了第一个分类定理:若一个非阿贝尔单群的所有非单位元均为对合(阶为2的元素)或奇阶元素,则它必同构于  。这一阶段工具有限,主要依赖西罗定理和计数技巧。
。这一阶段工具有限,主要依赖西罗定理和计数技巧。
 定理:阶为两素数幂的群必可解。弗罗贝尼乌斯则研究了弗罗贝尼乌斯群的结构。与此同时,美国数学家迪克森(Dickson)系统构造了有限域上的线性群,为后来的李型群分类奠定基础。这一时期的成果虽零散,但逐步建立了单群研究的框架。
定理:阶为两素数幂的群必可解。弗罗贝尼乌斯则研究了弗罗贝尼乌斯群的结构。与此同时,美国数学家迪克森(Dickson)系统构造了有限域上的线性群,为后来的李型群分类奠定基础。这一时期的成果虽零散,但逐步建立了单群研究的框架。


 ,随后费舍尔(Fischer)、格里斯(Griess)等人陆续构造出“魔群”(Monster,阶约
,随后费舍尔(Fischer)、格里斯(Griess)等人陆续构造出“魔群”(Monster,阶约  )等怪物级结构。这一时期共发现26个散在群,其神秘性质(如“月光猜想”)至今仍是数学物理的研究热点。
)等怪物级结构。这一时期共发现26个散在群,其神秘性质(如“月光猜想”)至今仍是数学物理的研究热点。



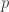 是素数。例如:
是素数。例如: (模5加法群)。
(模5加法群)。
 个元素的偶置换构成。例如
个元素的偶置换构成。例如  (正二十面体的对称群),其阶数为
(正二十面体的对称群),其阶数为  。
。
 密切相关。包括: 线性群如
密切相关。包括: 线性群如  (特殊射影线性群)。辛群如
(特殊射影线性群)。辛群如 (保持辛形式的群)。例外李群如
(保持辛形式的群)。例外李群如  ,其中
,其中 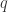 是某个素数的幂。
是某个素数的幂。

 ),其阶数约为
),其阶数约为