
Riemann 积分和 Lebesgue 积分是数学中两个非常重要的概念。本文将会从 Riemann 积分和 Lebesgue 积分的定义出发,介绍它们各自的性质和联系。
积分
Riemann 积分
Riemann 积分虽然被称为 Riemann 积分,但是在 Riemann 之前就有学者对这类积分进行了详细的研究。早在阿基米德时代,阿基米德为了计算曲线 
下面来看一下 Riemann 积分的详细定义。
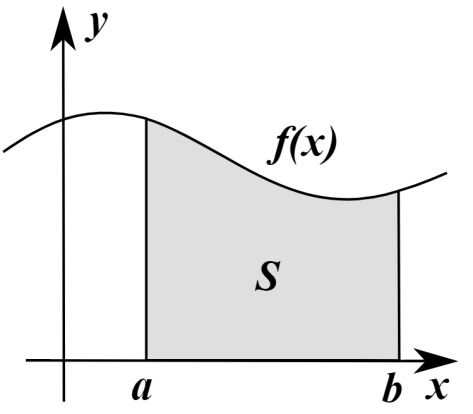
考虑定义在闭区间 [a,b] 上的函数 
取一个有限的点列 
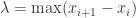

![[x_{i},x_{i+1}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![t_{i}\in[x_{i},x_{i+1}]](https://s0.wp.com/latex.php?latex=t_%7Bi%7D%5Cin%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

当我们说该函数 ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

对于任意 

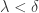
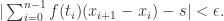
通常来说,用符号来表示就是: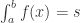
用几幅图来描述 Riemann 积分的思想就是:



Lebesgue 积分
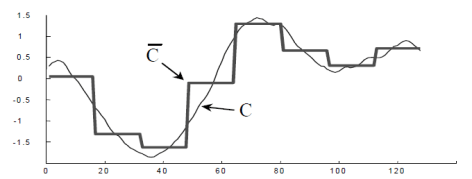
Riemann 积分是为了计算曲线与 X 轴所围成的面积,而 Lebesgue 积分也是做同样的事情,但是计算面积的方法略有不同。要想直观的解释两种积分的原理,可以参见下图:
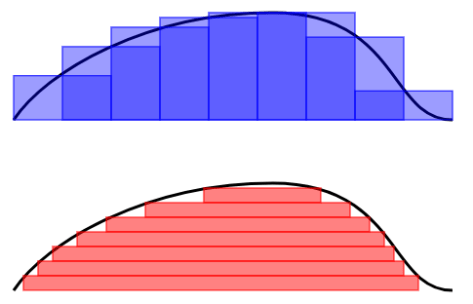
Riemann 积分是把一条曲线的底部分成等长的区间,测量每一个区间上的曲线高度,所以总面积就是这些区间与高度所围成的面积和。
Lebesgue 积分是把曲线化成等高线图,每两根相邻等高线的差值是一样的。每根等高线之内含有它所圈着的长度,因此总面积就是这些等高线内的面积之和。
用再形象一点的语言来描述就是:吃一块汉堡有多种方式
- Riemann 积分:从一个角落开始一口一口吃,每口都包含所有的配料;
- Lebesgue 积分:从最上层开始吃,按照“面包-配菜-肉-蛋-面包”的节奏,一层一层来吃。
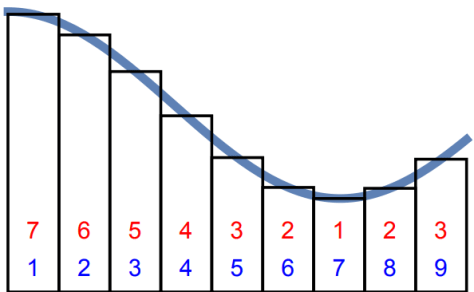
再看一幅图的表示就是:Riemann 积分是按照蓝色的数字顺序相加的,Lebesgue 积分是按照红色的数字来顺序相加的。
基于这些基本的思想,就可以给出 Lebesgue 积分的定义:
简单函数指的是对指示函数的有限线性组合,i.e. 


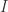

如果 
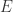

这里的 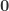
而对于可测函数时,可以把可测函数 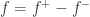

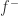
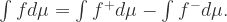
Riemann 积分与Lebesgue 积分的关系
定义了两种积分之后,也许有人会问它们之间是否存在矛盾?其实,它们之间是不矛盾的,因为有学者证明了这样的定理:
如果有界函数
![(R)\int_{a}^{b}f(x)dx = (L)\int_{[a,b]}f(x)dx](https://s0.wp.com/latex.php?latex=%28R%29%5Cint_%7Ba%7D%5E%7Bb%7Df%28x%29dx+%3D+%28L%29%5Cint_%7B%5Ba%2Cb%5D%7Df%28x%29dx&bg=ffffff&fg=2b2b2b&s=1&c=20201002)
左侧是表示 Riemann 积分,右侧表示 Lebesgue 积分。
用形象化一点的语言描述就是:无论从角落一口一口地吃汉堡,还是从顶至下一层一层吃,所吃的汉堡都是同一个。
但是 Lebesgue 积分比 Riemann 积分有着更大的优势,例如 Dirichlet 函数,
- 当
是有理数时,
;
- 当
.
Dirichlet 函数是定义在实数轴的函数,并且值域是 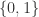
时间序列
提到时间序列,也就是把以上所讨论的连续函数换成离散函数而已,把定义域从一个闭区间 
时间序列的表示 — 基于 Riemann 积分
现在我们可以按照 Riemann 积分的计算方法来表示一个时间序列的特征,于是就有学者把时间序列按照横轴切分成很多段,每一段使用某个简单函数(线性函数等)来表示,于是就有了以下的方法:
- 分段线性逼近(Piecewise Linear Approximation)
- 分段聚合逼近(Piecewise Aggregate Approximation)
- 分段常数逼近(Piecewise Constant Approximation)
说到这几种算法,其实最本质的思想就是进行数据降维的工作,用少数的数据来进行原始时间序列的表示(Representation)。用数学化的语言来描述时间序列的数据降维(Data Reduction)就是:把原始的时间序列 
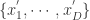
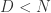
分段聚合逼近(Piecewise Aggregate Approximation)— 类似 Riemann 积分
在这种算法中,分段聚合逼近(Piecewise Aggregate Approximation)是一种非常经典的算法。假设原始的时间序列是 
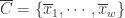
其中

在这里 
至于分段线性逼近(Piecewise Linear Approximation)和分段常数逼近(Piecewise Constant Approximation),只需要在 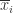
符号特征(Symbolic Approximation)— 类似用简单函数来计算 Lebesgue 积分
在推荐系统的特征工程里面,特征通常来说可以做归一化,二值化,离散化等操作。例如,用户的年龄特征,一般不会直接使用具体的年月日,而是划分为某个区间段,例如 0~6(婴幼儿时期),7~12(小学),13~17(中学),18~22(大学)等阶段。
其实在得到分段特征之后,分段特征在某种程度上来说依旧是某些连续值,能否把连续值划分为一些离散的值呢?于是就有学者使用一些符号来表示时间序列的关键特征,也就是所谓的符号表示法(Symbolic Representation)。下面来介绍经典的 SAX Representation。
如果我们希望使用 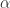



SAX 方法的流程如下:
- 正规化(normalization):把原始的时间序列映射到一个新的时间序列,新的时间序列满足均值为零,方差为一的条件。
- 分段表示(PAA):
。
- 符号表示(SAX):如果
,那么
;如果
,那么
,在这里
;如果
,那么
。
于是,我们就可以用
时间序列的表示 — 基于 Lebesgue 积分
要想考虑一个时间序列的值分布情况,其实就类似于 Lebesgue 积分的计算方法,考虑它们的分布情况,然后使用某些函数去逼近时间序列。要考虑时间序列的值分布情况,可以考虑熵的概念。
熵(Entropy)
通常来说,要想描述一种确定性与不确定性,熵(entropy)是一种不错的指标。对于离散空间而言,一个系统的熵(entropy)可以这样来表示:

如果一个系统的熵(entropy)越大,说明这个系统就越混乱;如果一个系统的熵越小,那么说明这个系统就更加确定。
提到时间序列的熵特征,一般来说有几个经典的熵指标,其中有一个就是 binned entropy。
分桶熵(Binned Entropy)
从熵的定义出发,可以考虑把时间序列的值进行分桶的操作,例如,可以把 [min, max] 这个区间等分为十个小区间,那么时间序列的取值就会分散在这十个桶中。根据这个等距分桶的情况,就可以计算出这个概率分布的熵(entropy)。i.e. Binned Entropy 就可以定义为:

其中 
如果一个时间序列的 Binned Entropy 较大,说明这一段时间序列的取值是较为均匀的分布在 [min, max] 之间的;如果一个时间序列的 Binned Entropy 较小,说明这一段时间序列的取值是集中在某一段上的。
总结
在本篇文章中,笔者从 Riemann 积分和 Lebesgue 积分出发,介绍了它们的基本概念,性质和联系。然后从两种积分出发,探讨了时间序列的分段特征,时间序列的熵特征。在未来的 Blog 中,笔者将会介绍时间序列的更多相关内容。
