
在时间序列异常检测中,通常有一个较为常见的场景就是“节假日效应”。所谓节假日效应,指的就是在节假日的时候,其时间序列的走势跟日常有着明显的差异性,但是又属于正常的情况。从国内 2020 年的节假日安排可以看出,一年中有好几个关键的假日:
- 元旦:1 天;
- 春节:7 天;
- 清明节:3 天;
- 五一劳动节:5 天;
- 端午节:3 天;
- 国庆节:8 天。
在这些节假日的时候,为了调休,自然也会带来工作日上的调整。例如:在 2020 年 1 月 19 日,2020 年 2 月 1 日是需要上班的(虽然今年受疫情影响最终也没上班)。因此,在这些节假日进行调整和变化的时候,各种各样的业务指标(时间序列)通常也会发生变化,变得跟以往的走势不太一致。因此,如何解决节假日效应的时间序列异常检测就是业务上所面临的问题之一。
![£¨Í¼±í£©[Éç»á]2020Äê½Ú¼ÙÈշżٰ²ÅŹ«²¼](https://zr9558.com/wp-content/uploads/2020/05/2020e5b9b4e4b8ade59bbde88a82e58187e697a5e5ae89e68e92.jpg?w=474)
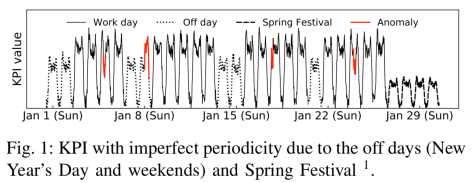
在实际的案例中,我们可以看到,同一条时间序列的走势在工作日(work day),休息日(off day),春节(Spring Festival)明显是不一样的。因此,根据工作日的时间序列走势来预测春节的走势明显是不太合理的;同理,根据春节的走势来预测休息日的走势也会带来一定的偏差的。那么如何解决节假日效应的问题就成为了本篇论文的关键之一。
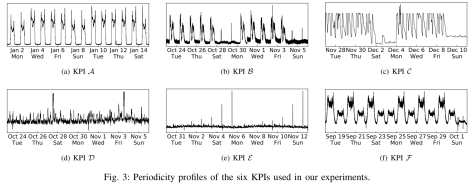
在上图中,我们可以看到论文中使用的数据都具有某种周期性(Periodicity)。KPI A,B,C 都是具有明显具有工作日和周末特点的,在工作日和周末分别有着不同的形状;KPI D 则是关于网上应用商店周五促销的,因此在周五周六的时候,其实时间序列会出现一个尖峰(peak);KPI E 的话则是每隔 7 天,会有两个尖刺,然后并且迅速恢复;KPI F 的话则是可以看出时间序列在十一的走势跟其余的时间点明显有区别。除此之外,对于一些做旅游,电商等行业的公司,其节假日效应会更加突出一点,而且不同的业务在节假日的表现其实也是不一样的。有的时间序列在节假日当天可能会上涨(电商销售额),有的时间序列在节假日当天反而会下降(订车票,飞机票的订单量)。因此,在对这些时间序列做异常检测的同时,如何避免其节假日效应就是一个关键的问题了。
而在实际处理的时候,通常也会遇到几个常见的问题;
- 周期性的多样性:通过实际案例可以看出,对于不同的时间序列,其周期是完全不一样的,而且在不同的周期上也有着完全不同的表现;
- KPI 数量巨大:这个通常来说都是智能运维领域中的常见问题;
- 周期的漂移:一般来说,通过时间序列的走势我们只能够看出一个大致的变化,但是具体到细节的话,周期是存在一定的波动的。例如不一定恰好是 7 天,有可能是 7 天加减 5 分钟之类的周期。这个跟业务的具体场景有关系,也跟当时的实际情况有关。
于是,基于这些挑战,作者们希望提出一个健壮的机器学习算法来解决这个问题,本文的系统被作者们称之为 Period,正好也象征着解决节假日效应这个寓意。
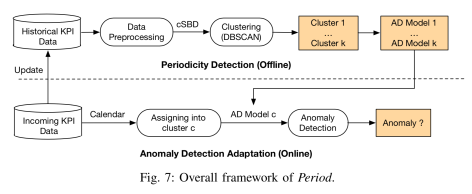
从论文中可以看出 Period 的整体架构如上图所示,包括两个部分:
- 离线周期性检测(offline periodicity detection);
- 在线适应性异常检测(online anomaly detection adaptation)。
在第一部分,每一条时间序列都会被按天切分成很多子序列(subsequence),然后将其聚集起来,把相似的时间序列放在一类,不相似的放在另外一类;在第二部分,新来的时间序列会根据其具体的日期,分入相应的聚类,然后用该类的时间序列异常检测方法来进行异常检测。
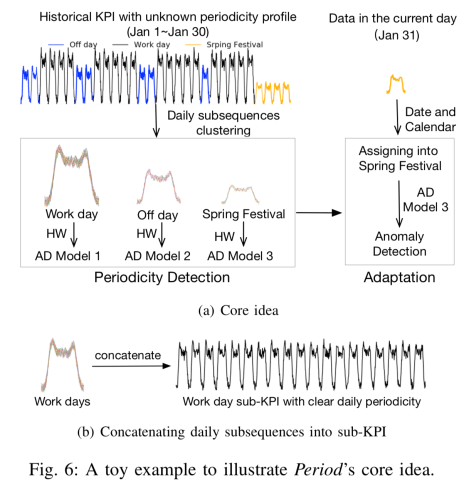
从上图可以看到 Period 的核心思路(core idea)。在本文使用的数据中,时间序列的长度较长,一般来说都是好几个月到半年不等,甚至更长的时间。对于一条时间序列(a given KPI),可以将它的历史数据(historical data)进行按天切分,获得多个子序列(sub KPIs)。对于这多个子序列,需要进行聚类以得到不同类别。或者按照日历直接把时间序列的工作日(work day),休息日(off day),春节(spring festival)序列进行切分,将工作日放在一起,休息日放在一起,春节放在一起。把这些子序列进行拼接就可以得到三条时间序列数据,分别是原时间序列的工作日序列(work day subsequence),休息日序列(off day subsequence),春节序列(spring festival subsequence)。然后分别对着三条时间序列训练一个异常检测的模型(例如 Holt-Winters 算法,简写为 HW)。对于新来的时间序列,可以根据当日具体的日期(工作日,休息日或者春节)放入相应的模型进行异常检测,从而进一步地得到最终的结果。
在离线周期性检测的技术方案里面,是需要对时间序列进行周期性检测(Periodicity Detection)。而周期性检测有多个方案可以选择。第一种就是周期图方法(Periodogram),另外一种就是自相关函数(Auto-correlation function)。但是在这个场景下,用这些方法就不太合适了。作者们提出了别的解决方案。
在本文中,作者们提出了一种 Shape-based distance(SBD)的方法,针对两条时间序列 

令
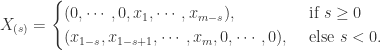
其中 
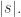
![s\in[-w,w]\cap\mathbb{Z}](https://s0.wp.com/latex.php?latex=s%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

于是,选择令 
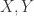
![NCC(X,Y)=\max_{s\in[-w,w]\cap\mathbb{Z}}\frac{CC_{s}(X,Y)}{\|x\|_{2}\cdot\|y\|}.](https://s0.wp.com/latex.php?latex=NCC%28X%2CY%29%3D%5Cmax_%7Bs%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D%7D%5Cfrac%7BCC_%7Bs%7D%28X%2CY%29%7D%7B%5C%7Cx%5C%7C_%7B2%7D%5Ccdot%5C%7Cy%5C%7C%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
而基于 SBD 的距离公式则可以定义为:

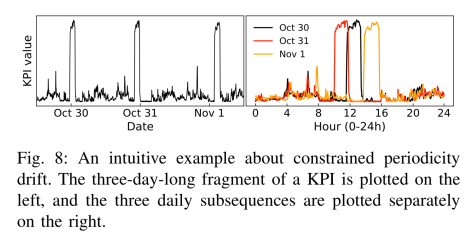
那么为什么需要考虑一个漂移量 

通过相似性和距离的衡量工具,我们可以将时间序列进行聚类,然后通过上述算法也可以对每一个聚类的结果进行命名。
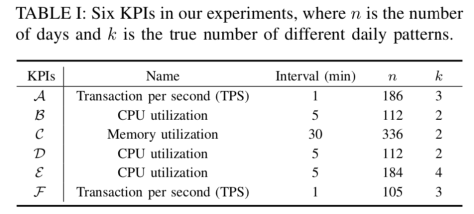
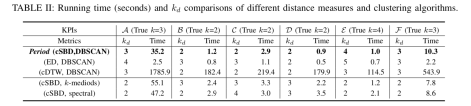
在本文中,针对以上六条时间序列,作者们做了详细的分析,也对其余的 50 条时间序列进行了实验。其使用的方法包括 HW,TSD,Diff,MA,EWMA,Donut。在 HW 中,针对不同的日期使用了不同的方法,例如 HW-day,HW-week,HW-period;其余的方法也是针对不同的日期来做的。
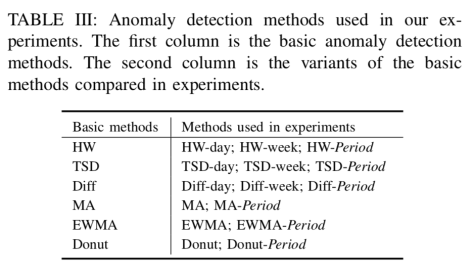
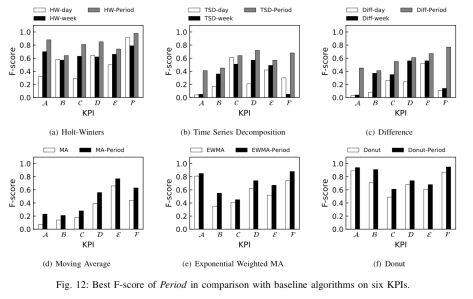
从实验效果来看,Period 方法的话相对于其他方法有一定的优势。
结论:Period 方法包括两个部分,第一部分是离线周期性检测,第二部分是在线适应性异常检测。通过这样的方法,可以有效地减缓时间序列异常检测受节假日效应的影响。除此之外,想必未来也会有其余学者提出相应的问题和解决方案,敬请期待。

2 thoughts on “时间序列异常检测—节假日效应的应对之道”