
在搜索的业务场景下,基于一个现有的数据候选集(dataset),需要对新来的一个或者多个数据进行查询(query),返回在数据候选集中与该查询最相似的 Top K 数据。

最朴素的想法就是,每次来了一个新的查询数据(query),都遍历一遍数据候选集(dataset)里面的所有数据,计算出 query 与 dataset 中所有元素的相似度或者距离,然后精准地返回 Top K 相似的数据即可。
但是当数据候选集特别大的时候,遍历一遍数据候选集里面的所有元素就会耗费过多的时间,其时间复杂度是 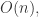
在这个场景下,通常都是欧式空间里面的数据,形如 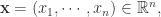

- Manhattan 距离:L1 范数;
- Euclidean 距离:L2 范数;
- Cosine 距离:1 – Cosine 相似度;
- 角距离:用两个向量之间的夹角来衡量两者之间的距离;
- Hamming 距离:一种针对 64 维的二进制数的 Manhattan 距离,相当于
中的 L1 范数;
- Dot Product 距离:
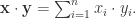

在近似最近邻搜索(ANN)领域,有很多开源的算法可以使用,包括但不限于:
- Annoy(Approximate Nearest Neighbors Oh Yeah);
- ScaNN(Scalable Nearest Neighbors);
- Faiss(Billion-scale similarity search with GPUs);
- Hnswlib(fast approximate nearest neighbor search);
本文将会重点介绍 Annoy 算法及其使用案例;
Annoy 的算法思想
本文以 
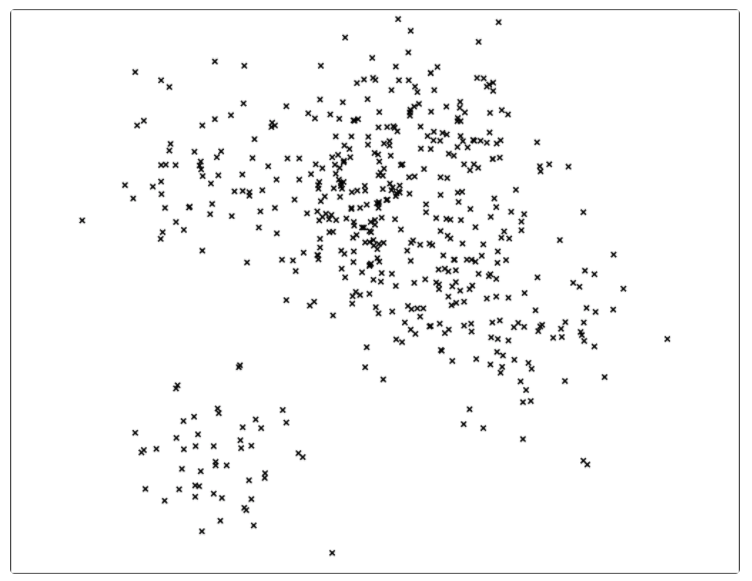
用 n 表示现有的文档个数,如果采用暴力搜索的方式,那么每次查询的耗时是

刚开始的时候,在数据集中随机选择两个点,然后用它们的中垂线来切分整个数据集,于是数据集就被分成了蓝绿两个部分。然后再随机两个平面中各选出一个顶点,再用中垂线进行切分,于是,整个平面就被切成了四份。
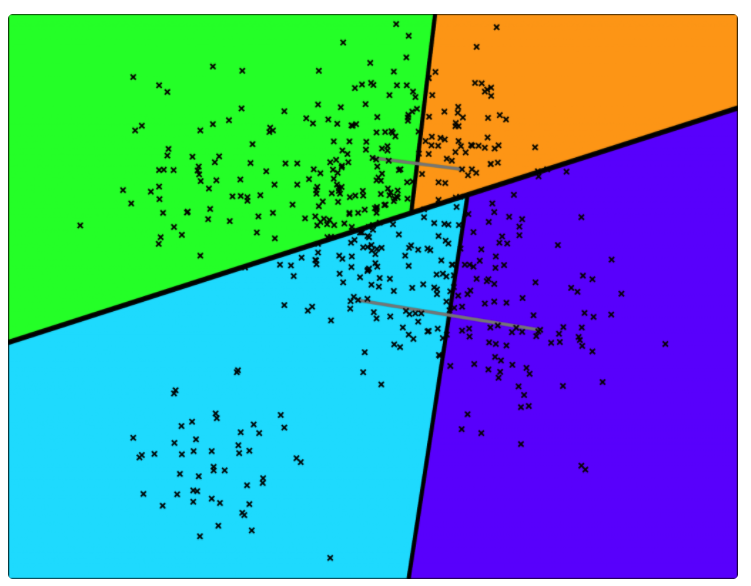
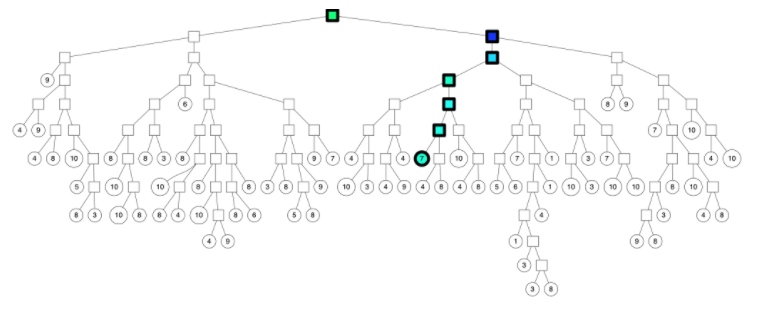
用一颗二叉树来表示这个被切分的平面就是:
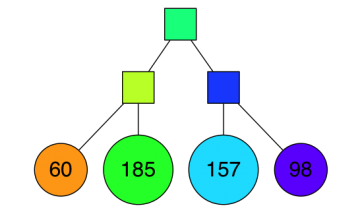
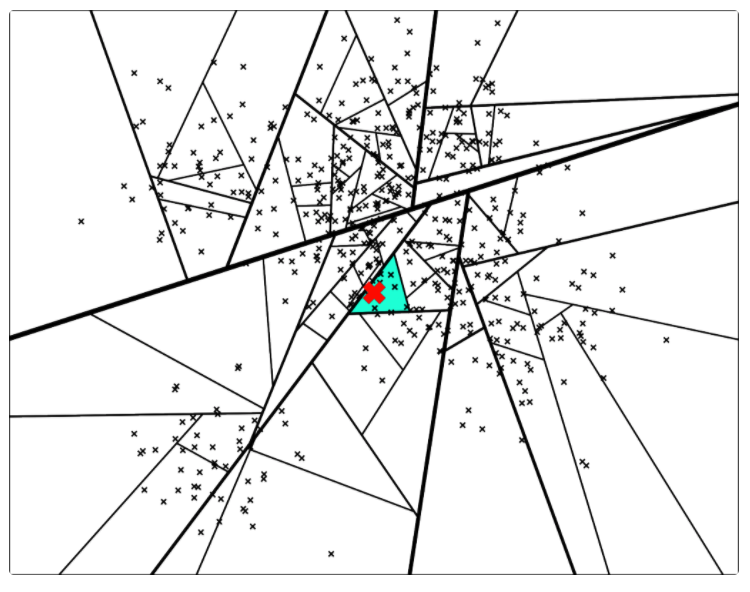
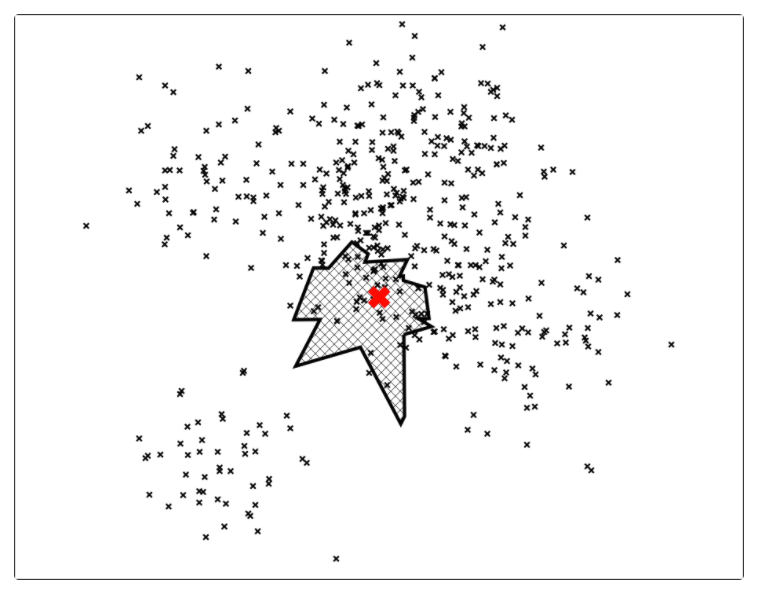
后续继续采用同样的方式进行切分,直到每一个平面区域最多拥有 K 个点为止。当 K = 10 时,其相应的切分平面和二叉树如下图所示。
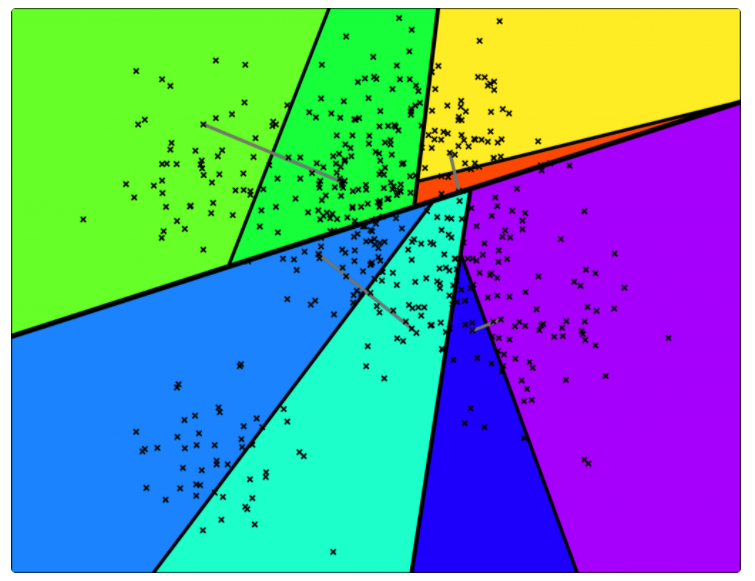
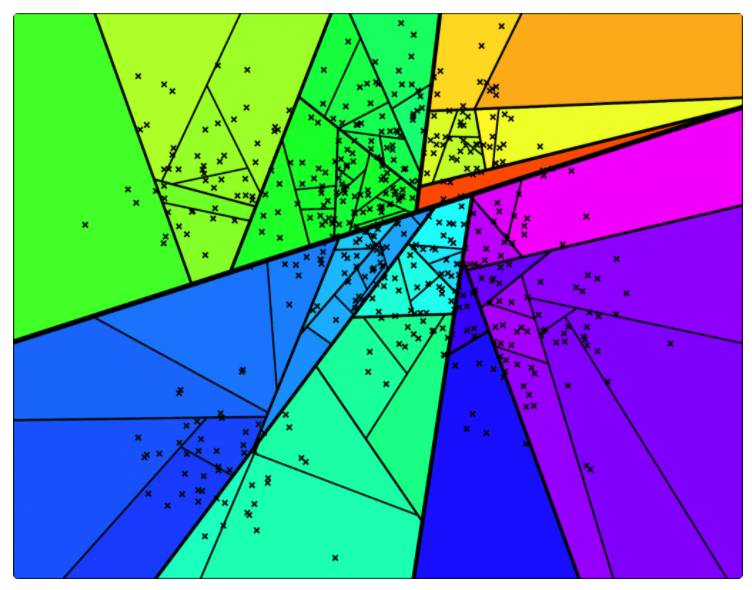
下面,新来的一个点(用红色的叉表示),通过对二叉树的查找,我们可以找到所在的子平面,然后里面最多有 K = 10 个点。从二叉树的叶子节点来看,该区域只有 7 个点。
在 ANN 领域,最常见的两个问题是:
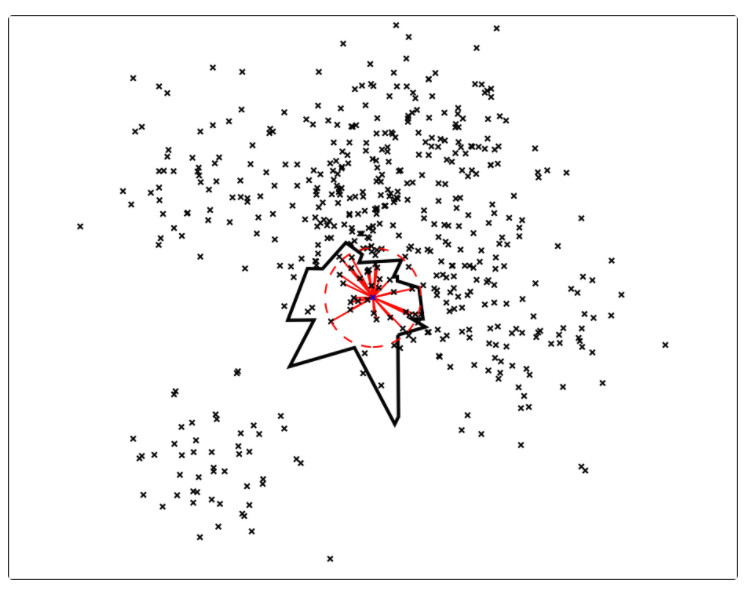
- 如果我们想要 Top K 的点,但是该区域的点集数量不足 K,该怎么办?
- 如果真实的 Top K 中部分点不在这个区域,该怎么办?
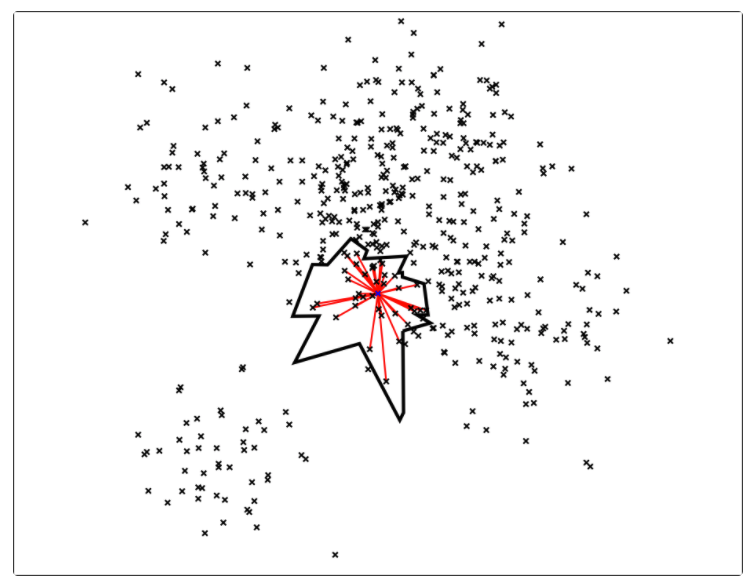
作者用了两个技巧来解决这个问题:
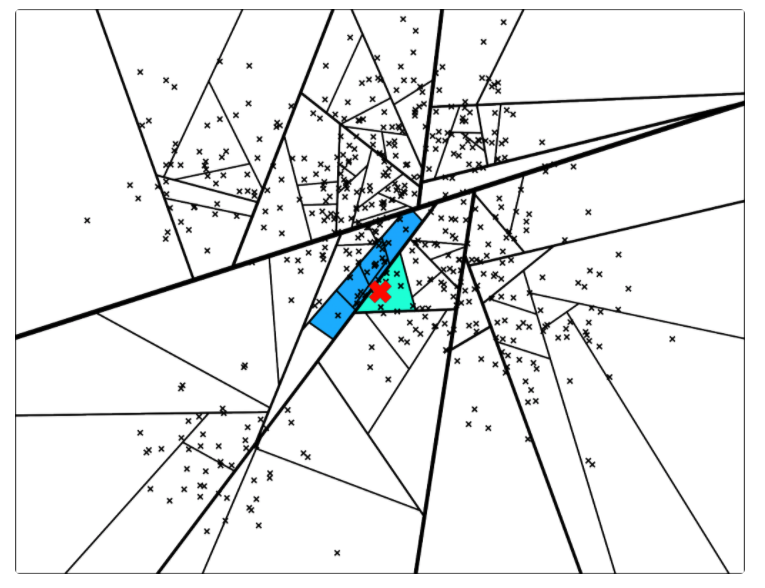
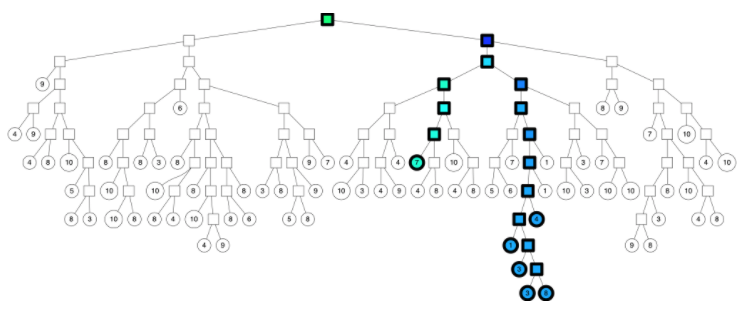
- 使用优先队列(priority queue):将多棵树放入优先队列,逐一处理;并且通过阈值设定的方式,如果查询的点与二叉树中某个节点比较相似,那么就同时走两个分支,而不是只走一个分支;
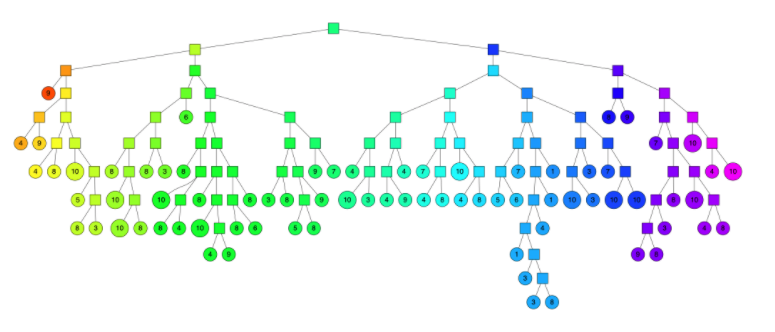
- 使用森林(forest of trees):构建多棵树,采用多个树同时搜索的方式,得到候选集 Top M(M > K),然后对这 M 个候选集计算其相似度或者距离,最终进行排序就可以得到近似 Top K 的结果。
同时走两个分支的的示意图:
随机生成多棵树,构建森林的示意图:

Top K 的查询方法:
Annoy 算法原理:
构建索引:建立多颗二叉树,每颗二叉树都是随机切分的;
查询方法:
1. 将每一颗树的根节点插入优先队列;
2. 搜索优先队列中的每一颗二叉树,每一颗二叉树都可以得到最多 Top K 的候选集;
3. 删除重复的候选集;
4. 计算候选集与查询点的相似度或者距离;
5. 返回 Top K 的集合。
Annoy 的编程实践
Annoy 的安装:
pip install annoy
Annoy 的 Python 接口函数
常用的 Annoy Python 接口函数包括以下内容:
- a = AnnoyIndex(f, metric):f 指的是向量的维度,metric 表示度量公式。在这里,Annoy 支持的度量公式包括:”angular”, “euclidean”, “manhattan”, “hamming”, “dot”;
- a.add_item(i, v):i 是一个非负数,表示 v 是第 i 个向量;
- a.build(n_trees, n_jobs=-1):n_trees 表示树的棵数,n_jobs 表示线程个数,n_jobs=-1 表示使用所有的 CPU 核;
- a.save(fn, prefault=False):表示将索引存储成文件,文件名是 fn;
- a.load(fn, prefault=False):表示将索引从文件 fn 中读取出来;
- a.unload():表示不再加载索引;
- a.get_nns_by_item(i, n, search_k=-1, include_distances=False):返回在索引中的第 i 个向量 Top n 最相似的向量;如果不提供 search_k 值的话,search_k 默认为 n_tree * n,该指标用来平衡精确度和速度;includ_distances=True 表示返回的时候是一个包含两个元素的 tuple,第一个是索引向量的 index,第二个就是相应的距离;
- a.get_nns_by_vector(v, n, search_k=-1, include_distances=False):返回与向量 v Top n 最相似的向量;如果不提供 search_k 值的话,search_k 默认为 n_tree * n,该指标用来平衡精确度和速度;includ_distances=True 表示返回的时候是一个包含两个元素的 tuple,第一个是索引向量的 index,第二个就是相应的距离;
- a.get_item_vector(i):返回添加索引的时候的第 i 个向量;
- a.get_distance(i, j):返回第 i 个向量与第 j 个向量的距离;
- a.get_n_items():返回索引中的向量个数;
- a.get_n_trees():返回索引中的树的棵数;
- a.on_disk_build(fn):在一个文件 fn 中构建索引,并不在内存中构建索引;
- a.set_seed(seed):用给定的种子初始化随机数生成器,需要在建树,添加向量构建索引之前使用该函数;
影响 annoy 算法效率和精度的重要参数:
- n_trees:表示树的棵数,会影响构建索引的时间。值越大表示最终的精度越高,但是会有更多的索引;
- search_k:值越大表示搜索耗时越长,搜索的精度越高;如果需要返回 Top n 最相似的向量,则 search_k 的默认值是 n_trees * n;
Annoy 的使用案例
from annoy import AnnoyIndex
import random
# f 表示向量的维度
f = 40
# 'angular' 是 annoy 支持的一种度量;
t = AnnoyIndex(f, 'angular') # Length of item vector that will be indexed
# 插入数据
for i in range(1000):
v = [random.gauss(0, 1) for z in range(f)]
# i 是一个非负数,v 表示向量
t.add_item(i, v)
# 树的数量
t.build(10) # 10 trees
# 存储索引成为文件
t.save('test.ann')
# 读取存储好的索引文件
u = AnnoyIndex(f, 'angular')
u.load('test.ann') # super fast, will just mmap the file
# 返回与第 0 个向量最相似的 Top 100 向量;
print(u.get_nns_by_item(0, 1000)) # will find the 1000 nearest neighbors
# 返回与该向量最相似的 Top 100 向量;
print(u.get_nns_by_vector([random.gauss(0, 1) for z in range(f)], 1000))
# 返回第 i 个向量与第 j 个向量的距离;
# 第 0 个向量与第 0 个向量的距离
print(u.get_distance(0, 0))
# 第 0 个向量与第 1 个向量的距离
print(u.get_distance(0, 1))
# 返回索引中的向量个数;
print(u.get_n_items())
# 返回索引中的树的棵数;
print(u.get_n_trees())
# 不再加载索引
print(u.unload())
基于 hamming 距离的 annoy 使用案例:
from annoy import AnnoyIndex
# Mentioned on the annoy-user list
bitstrings = [
'0000000000011000001110000011111000101110111110000100000100000000',
'0000000000011000001110000011111000101110111110000100000100000001',
'0000000000011000001110000011111000101110111110000100000100000010',
'0010010100011001001000010001100101011110000000110000011110001100',
'1001011010000110100101101001111010001110100001101000111000001110',
'0111100101111001011110010010001100010111000111100001101100011111',
'0011000010011101000011010010111000101110100101111000011101001011',
'0011000010011100000011010010111000101110100101111000011101001011',
'1001100000111010001010000010110000111100100101001001010000000111',
'0000000000111101010100010001000101101001000000011000001101000000',
'1000101001010001011100010111001100110011001100110011001111001100',
'1110011001001111100110010001100100001011000011010010111100100111',
]
# 将其转换成二维数组
vectors = [[int(bit) for bit in bitstring] for bitstring in bitstrings]
# 64 维度
f = 64
idx = AnnoyIndex(f, 'hamming')
for i, v in enumerate(vectors):
idx.add_item(i, v)
# 构建索引
idx.build(10)
idx.save('idx.ann')
idx = AnnoyIndex(f, 'hamming')
idx.load('idx.ann')
js, ds = idx.get_nns_by_item(0, 5, include_distances=True)
# 输出索引和 hamming 距离
print(js, ds)
基于欧几里得距离的 annoy 使用案例:
from annoy import AnnoyIndex
import random
# f 表示向量的维度
f = 2
# 'euclidean' 是 annoy 支持的一种度量;
t = AnnoyIndex(f, 'euclidean') # Length of item vector that will be indexed
# 插入数据
t.add_item(0, [0, 0])
t.add_item(1, [1, 0])
t.add_item(2, [1, 1])
t.add_item(3, [0, 1])
# 树的数量
t.build(n_trees=10) # 10 trees
t.save('test2.ann')
u = AnnoyIndex(f, 'euclidean')
u.load('test2.ann') # super fast, will just mmap the file
print(u.get_nns_by_item(1, 3)) # will find the 1000 nearest neighbors
print(u.get_nns_by_vector([0.1, 0], 3))
参考资料
- GitHub 的 Annoy 开源代码:https://github.com/spotify/annoy
- Nearest neighbors and vector models – part 2 – algorithms and data structures:https://erikbern.com/2015/10/01/nearest-neighbors-and-vector-models-part-2-how-to-search-in-high-dimensional-spaces.html
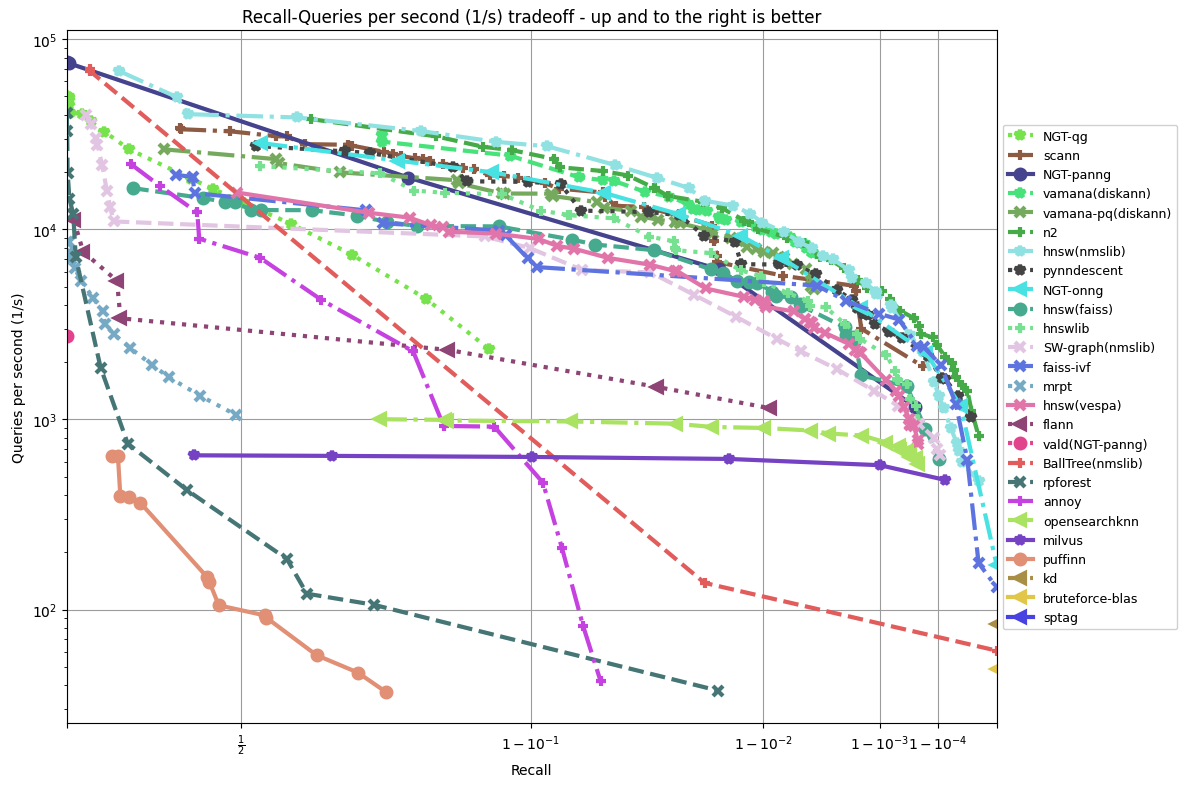
- ann-benchmark 的效果测试:https://github.com/erikbern/ann-benchmarks
