
数学在生活中是无处不在的。
每个人从出生开始,都会跟数学打交道。从最开始的认数字,到加减乘除,方程,几何,再到微积分和线性代数,数学几乎贯穿了教育的所有阶段。但是,数学真的在生活中是无处不在的么?对于这个问题,不同的人肯定有着自己完全不同的见解,本文就从近些年最常见的疫情开始谈起吧。

从 2019 年末开始,新冠病毒就开始在社会上悄悄传播,医疗系统开始逐渐被占满。2020 年初,武汉的疫情已经处于比较严重的状态,不少人都去医院治疗疾病,但同时检测系统和治疗系统还没有完全跟上。当时并没有办法在短时间内对几百万甚至上千万人口进行快速的疫情检测,只能够采取封城的策略来应对当时的疫情。
到了 2022 年,很多城市都有了丰富的应对疫情的策略,可以在很短的时间内对几百万甚至上千万人口同时进行核酸检测。根据检测结果,防疫部门就可以进行精准防控,以避免疫情的进一步扩散。能够进行大规模的核酸检测,除了检测能力本身的提升,检测时间的缩短之外,有没有数学办法将其进行优化就是一个关键问题。
核酸检测,其目的就是从大量的人中找到有问题的那一批人,然后进行必要的医疗救治,防止病毒的进一步扩散。近期如果做过大规模核酸的朋友仔细观察的话,其实在检测的时候会将十个人或者多个人的样本进行混合,放入同一个试管中,最终一起对这十个人或者多个人进行检测。如果有问题的话,再去对这十个人进行单独检测。从直觉上讲,多个人混合检测的效率肯定是优于一个人单独检测的,那么其背后的数学依据究竟是什么呢?为什么不进行二十个人,三十个人,一百个人的混合检测呢?
在回答这个问题之前,我们可以看一个更加简单一点的案例。相比大家都知道高校的图书馆,在图书馆的门口都会放有闸机,其目的是防止图书馆的书籍被大家不小心带出去。如果有人不小心把图书馆的书籍放入闸机,那么闸机就会报警。通常情况下,大家去借书的时候都会同时借阅好几本甚至十几本书籍,如果此时有一本书没有借阅成功,而出现了闸机报警的情况,那么如何快速的找到没有借阅成功的那本书呢?

最直接的方式是一本一本将这些书籍进行扫描,然后如果出现了报警,那就找到了这本没有借阅成功的书籍。但这种扫描的方式无疑是效率最低的,如果每次都要扫描所有的书籍,那么图书馆的管理员都会觉得效率低下。
假设某个同学一次借阅了十六本书,但是有一本书没有借阅成功,其实完全可以使用“二分法”来解决问题。将这十六本书分成两份,每一份有八本书,第一次先测试其中的八本,第二次再测试剩下的八本,于是得到了有报警的那八本书;于是再将这八本书分成两份,每份四本,重新在闸机上进行测试,得到有报警的那四本书;再将这四本书分成两份,每份二本,同样的操作之后得到有问题的两本书。最后,将这两本书在闸机上测试,就得到了那本没有扫码成功的书籍。通过这样的方法,可以将检测次数变成 2 + 2 + 2 + 2 = 8 次,测试的次数变成了原来的一半。扩展到一般的形式,如果书籍有 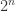
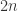

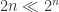
不巧的是,这个方案并不能够完全照搬在传染病的检测中。因为在图书馆这个场景中,我们已经假设只有一本书是没有扫码成功的;但是在现实生活的传染病检测中,患病者的数量肯定不止一个,同时有多少个患病者其实也是未知的,我们只是知道患病者的人数肯定远远小于城市的总人口数。而在图书馆检测中,可以通过一次扫描就得到多本书的结果,在核酸检测的时候其实是做不到这一点的。不过图书馆这个场景倒是给提供了一个有效地思路,那就是将所有的书籍进行分桶。所谓的分桶就是将一个全体分成多份,且每一份的样本数是一致的,每次检测的时候只需要同时检测每一份样本就可以知道一个整体的情况了。
不过,核酸检测可以转换成一个抽象的数学问题。假设城市 A 的人口数是 n,当前感染传染病的人数是 m,并且 m 是远小于 n 的(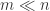
k = 1 的时候就相当于对每个人都进行检测,k = n 的时候就相当于对城市 A 中所有的人都进行检测,这两种极端情况的效率都很低。那么 k 值究竟如何选择,才能够让每个人的平均检测次数最少呢?

在数学上,这种混合检测的方法叫做 Group Testing,最早是美国的统计学家 Robert Dorfman 在 1943 年提出的。这种方法可以非常有效地提升大规模检测的效率和能力。在成本有限的前提下,达到最优的效果。其中心思想就跟核酸检测的方法是一样的,将全体人群按照一定的数量分成多个组,然后对每一个分组进行检测,如果该分组的检测结果没有问题,则这个分组里面的人就没有问题;如果该分组的检测结果有问题,则将这个分组里面的所有人重新进行单独测试。
根据以上方法,每个人的检测次数有可能是 1 次,也有可能是 2 次。只要这个人所在的混合样本没有问题,那么这个人就是 1 次;如果这个人所在的混合样本有问题,那么这个人就需要检测 2 次,那么这 k 个人都需要重新检测 1 次,这 k 个人的总检测次数就是 k + 1。这 k 个人的混合样本没有问题的概率是 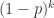
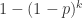
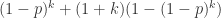
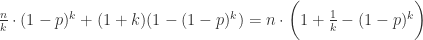
为了解决这个函数的极值问题,最常见的就是使用微积分的方法。当 p < 0.01 时,通过 Taylor 公式可以得到 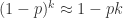
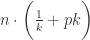
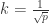
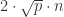
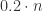
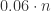
那么,在什么条件下,混合采样的方法会优于逐一检测呢?
此时,总检测次数的期望就要小于逐一检测,用数学公式来描述就是: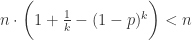
![p<1-\frac{1}{\sqrt[k]{k}}](https://s0.wp.com/latex.php?latex=p%3C1-%5Cfrac%7B1%7D%7B%5Csqrt%5Bk%5D%7Bk%7D%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
如果进行十混一的混合检测方法,也就是当 k = 10 时,需要保证 p < 0.2;如果要进行二十混一的混合检测方法,也就是当 k = 20 时,需要保证 p < 0.14;如果要进行五十混一的混合检测方法,也就是当 k = 50 时,需要保证 p < 0.08。在绝大多数情况下,感染率 p 还是会小于 0.2 的,因此采用十混一或者二十混一的方法在现实生活中是可靠的。
在疫情防控的过程中,核酸检测是可以做到降本增效的,而降本增效的背后并不是拍脑袋的决定,其背后有着数学的理论支持。
参考资料
1. 参考知乎文章:https://zhuanlan.zhihu.com/p/103974270
2. 参考知乎提问:https://www.zhihu.com/question/524417189,https://www.zhihu.com/question/523901192/answer/2442100447
3. 核酸检测数学模型:https://www.zhihu.com/zvideo/1495452303112572928
4. 核酸检测的真假性:https://zhuanlan.zhihu.com/p/452598672,Bayes 公式。
