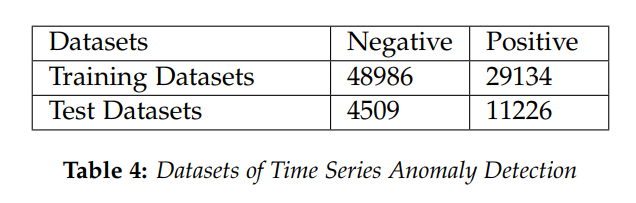Prophet 简介
Facebook 去年开源了一个时间序列预测的算法,叫做 fbprophet,它的官方网址与基本介绍来自于以下几个网站:
- Github:https://github.com/facebook/prophet
- 官方网址:https://facebook.github.io/prophet/
- 论文名字与网址:Forecasting at scale,https://peerj.com/preprints/3190/
从官网的介绍来看,Facebook 所提供的 prophet 算法不仅可以处理时间序列存在一些异常值的情况,也可以处理部分缺失值的情形,还能够几乎全自动地预测时间序列未来的走势。从论文上的描述来看,这个 prophet 算法是基于时间序列分解和机器学习的拟合来做的,其中在拟合模型的时候使用了 pyStan 这个开源工具,因此能够在较快的时间内得到需要预测的结果。除此之外,为了方便统计学家,机器学习从业者等人群的使用,prophet 同时提供了 R 语言和 Python 语言的接口。从整体的介绍来看,如果是一般的商业分析或者数据分析的需求,都可以尝试使用这个开源算法来预测未来时间序列的走势。
Prophet 的算法原理
Prophet 数据的输入和输出
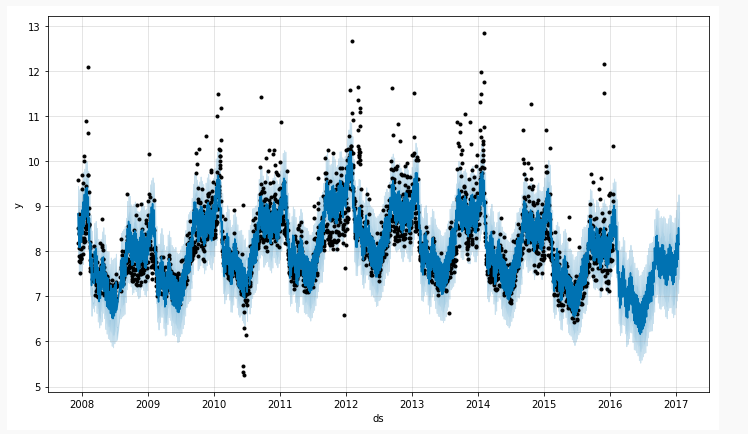
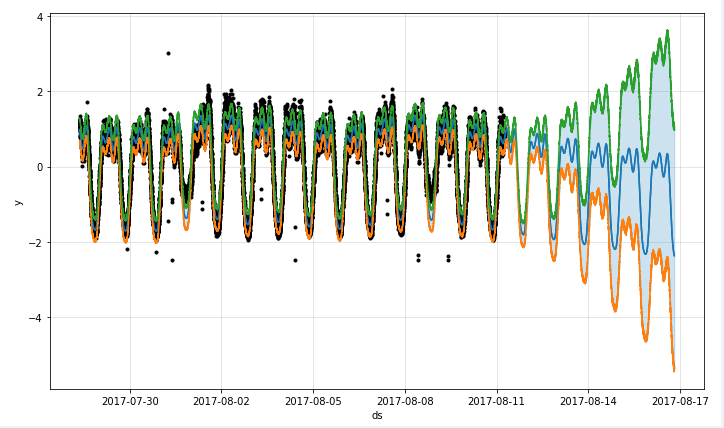
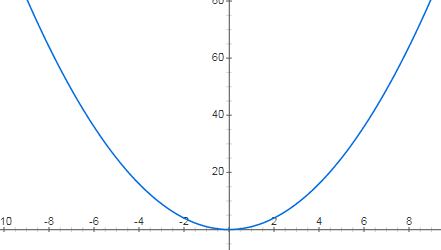
首先让我们来看一个常见的时间序列场景,黑色表示原始的时间序列离散点,深蓝色的线表示使用时间序列来拟合所得到的取值,而浅蓝色的线表示时间序列的一个置信区间,也就是所谓的合理的上界和下界。prophet 所做的事情就是:
- 输入已知的时间序列的时间戳和相应的值;
- 输入需要预测的时间序列的长度;
- 输出未来的时间序列走势。
- 输出结果可以提供必要的统计指标,包括拟合曲线,上界和下界等。
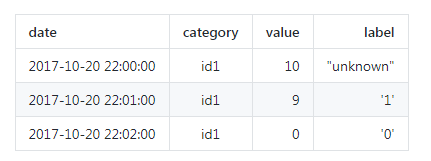
就一般情况而言,时间序列的离线存储格式为时间戳和值这种格式,更多的话可以提供时间序列的 ID,标签等内容。因此,离线存储的时间序列通常都是以下的形式。其中 date 指的是具体的时间戳,category 指的是某条特定的时间序列 id,value 指的是在 date 下这个 category 时间序列的取值,label 指的是人工标记的标签(’0′ 表示异常,’1‘ 表示正常,’unknown’ 表示没有标记或者人工判断不清)。
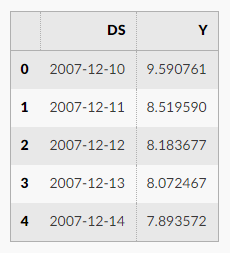
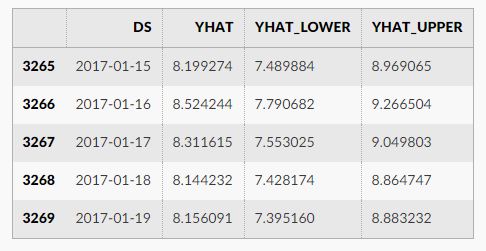
而 fbprophet 所需要的时间序列也是这种格式的,根据官网的描述,只要用 csv 文件存储两列即可,第一列的名字是 ‘ds’, 第二列的名称是 ‘y’。第一列表示时间序列的时间戳,第二列表示时间序列的取值。通过 prophet 的计算,可以计算出 yhat,yhat_lower,yhat_upper,分别表示时间序列的预测值,预测值的下界,预测值的上界。两份表格如下面的两幅图表示。
Prophet 的算法实现
在时间序列分析领域,有一种常见的分析方法叫做时间序列的分解(Decomposition of Time Series),它把时间序列  分成几个部分,分别是季节项
分成几个部分,分别是季节项 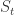 ,趋势项
,趋势项  ,剩余项
,剩余项  。也就是说对所有的
。也就是说对所有的  ,都有
,都有

除了加法的形式,还有乘法的形式,也就是:

以上式子等价于 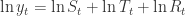 。所以,有的时候在预测模型的时候,会先取对数,然后再进行时间序列的分解,就能得到乘法的形式。在 fbprophet 算法中,作者们基于这种方法进行了必要的改进和优化。
。所以,有的时候在预测模型的时候,会先取对数,然后再进行时间序列的分解,就能得到乘法的形式。在 fbprophet 算法中,作者们基于这种方法进行了必要的改进和优化。
一般来说,在实际生活和生产环节中,除了季节项,趋势项,剩余项之外,通常还有节假日的效应。所以,在 prophet 算法里面,作者同时考虑了以上四项,也就是:
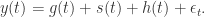
其中  表示趋势项,它表示时间序列在非周期上面的变化趋势;
表示趋势项,它表示时间序列在非周期上面的变化趋势;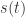 表示周期项,或者称为季节项,一般来说是以周或者年为单位;
表示周期项,或者称为季节项,一般来说是以周或者年为单位; 表示节假日项,表示在当天是否存在节假日;
表示节假日项,表示在当天是否存在节假日; 表示误差项或者称为剩余项。Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
表示误差项或者称为剩余项。Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
趋势项模型
在 Prophet 算法里面,趋势项有两个重要的函数,一个是基于逻辑回归函数(logistic function)的,另一个是基于分段线性函数(piecewise linear function)的。
首先,我们来介绍一下基于逻辑回归的趋势项是怎么做的。
如果回顾逻辑回归函数的话,一般都会想起这样的形式: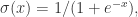 它的导数是
它的导数是 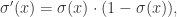 并且
并且 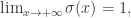
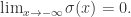 如果增加一些参数的话,那么逻辑回归就可以改写成:
如果增加一些参数的话,那么逻辑回归就可以改写成:

这里的  称为曲线的最大渐近值,
称为曲线的最大渐近值, 表示曲线的增长率,
表示曲线的增长率, 表示曲线的中点。当
表示曲线的中点。当  时,恰好就是大家常见的 sigmoid 函数的形式。从 sigmoid 的函数表达式来看,它满足以下的微分方程:
时,恰好就是大家常见的 sigmoid 函数的形式。从 sigmoid 的函数表达式来看,它满足以下的微分方程: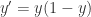 。
。
那么,如果使用分离变量法来求解微分方程 就可以得到:
 .
.
但是在现实环境中,函数  的三个参数
的三个参数 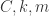 不可能都是常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,作者考虑把这三个参数全部换成了随着时间而变化的函数,也就是
不可能都是常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,作者考虑把这三个参数全部换成了随着时间而变化的函数,也就是  。
。
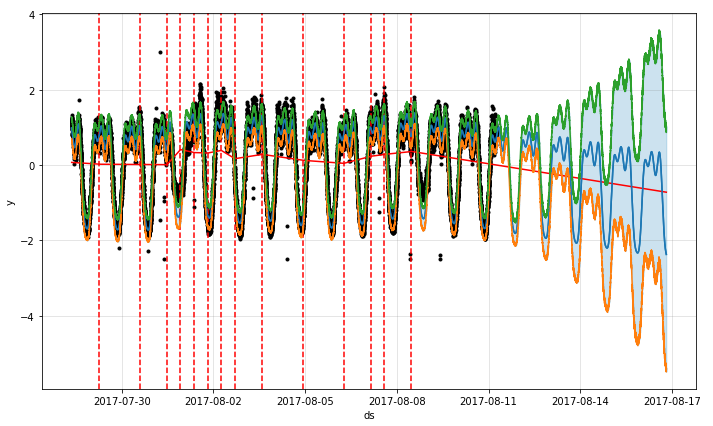
除此之外,在现实的时间序列中,曲线的走势肯定不会一直保持不变,在某些特定的时候或者有着某种潜在的周期曲线会发生变化,这种时候,就有学者会去研究变点检测,也就是所谓 change point detection。例如下面的这幅图的  就是时间序列的两个变点。
就是时间序列的两个变点。
在 Prophet 里面,是需要设置变点的位置的,而每一段的趋势和走势也是会根据变点的情况而改变的。在程序里面有两种方法,一种是通过人工指定的方式指定变点的位置;另外一种是通过算法来自动选择。在默认的函数里面,Prophet 会选择 n_changepoints = 25 个变点,然后设置变点的范围是前 80%(changepoint_range),也就是在时间序列的前 80% 的区间内会设置变点。通过 forecaster.py 里面的 set_changepoints 函数可以知道,首先要看一些边界条件是否合理,例如时间序列的点数是否少于 n_changepoints 等内容;其次如果边界条件符合,那变点的位置就是均匀分布的,这一点可以通过 np.linspace 这个函数看出来。
下面假设已经放置了  个变点了,并且变点的位置是在时间戳
个变点了,并且变点的位置是在时间戳  上,那么在这些时间戳上,我们就需要给出增长率的变化,也就是在时间戳
上,那么在这些时间戳上,我们就需要给出增长率的变化,也就是在时间戳  上发生的 change in rate。可以假设有这样一个向量:
上发生的 change in rate。可以假设有这样一个向量: 其中
其中  表示在时间戳 上的增长率的变化量。如果一开始的增长率我们使用 来代替的话,那么在时间戳
表示在时间戳 上的增长率的变化量。如果一开始的增长率我们使用 来代替的话,那么在时间戳  上的增长率就是
上的增长率就是 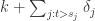 ,通过一个指示函数
,通过一个指示函数  就是
就是

那么在时间戳 上面的增长率就是  一旦变化量 确定了,另外一个参数 也要随之确定。在这里需要把线段的边界处理好,因此通过数学计算可以得到:
一旦变化量 确定了,另外一个参数 也要随之确定。在这里需要把线段的边界处理好,因此通过数学计算可以得到:

所以,分段的逻辑回归增长模型就是:
其中,
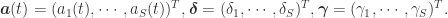
在逻辑回归函数里面,有一个参数是需要提前设置的,那就是 Capacity,也就是所谓的  ,在使用 Prophet 的 growth = ‘logistic’ 的时候,需要提前设置好 的取值才行。
,在使用 Prophet 的 growth = ‘logistic’ 的时候,需要提前设置好 的取值才行。
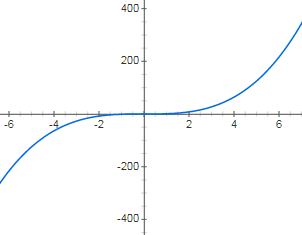
再次,我们来介绍一下基于分段线性函数的趋势项是怎么做的。众所周知,线性函数指的是  而分段线性函数指的是在每一个子区间上,函数都是线性函数,但是在整段区间上,函数并不完全是线性的。正如下图所示,分段线性函数就是一个折线的形状。
而分段线性函数指的是在每一个子区间上,函数都是线性函数,但是在整段区间上,函数并不完全是线性的。正如下图所示,分段线性函数就是一个折线的形状。
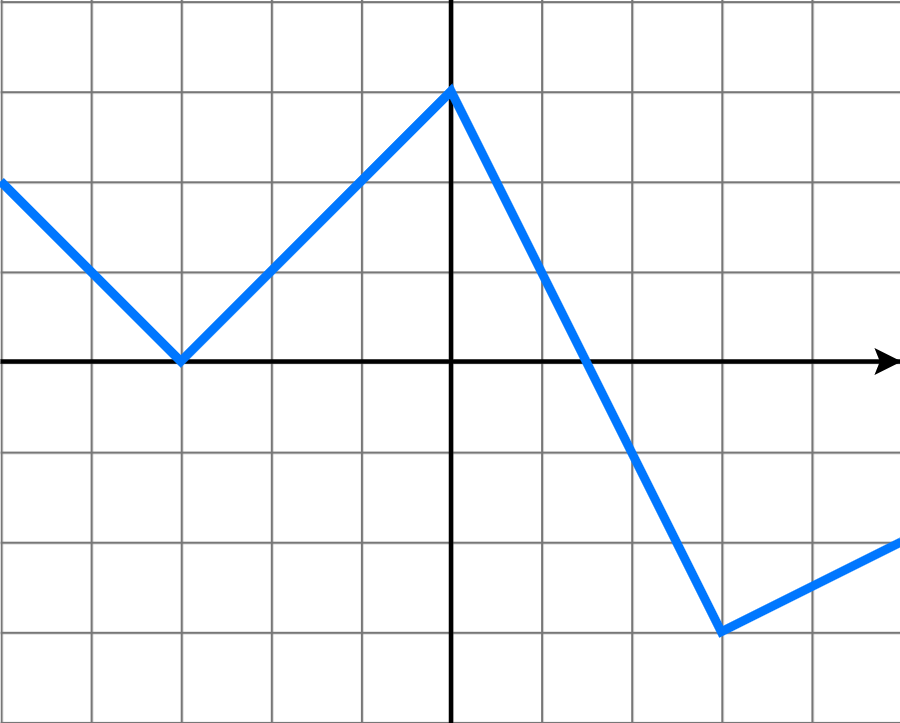
因此,基于分段线性函数的模型形如:

其中 表示增长率(growth rate), 表示增长率的变化量, 表示 offset parameter。而这两种方法(分段线性函数与逻辑回归函数)最大的区别就是
表示增长率的变化量, 表示 offset parameter。而这两种方法(分段线性函数与逻辑回归函数)最大的区别就是  的设置不一样,在分段线性函数中,
的设置不一样,在分段线性函数中,
 注意:这与之前逻辑回归函数中的设置是不一样的。
注意:这与之前逻辑回归函数中的设置是不一样的。
在 prophet 的源代码中,forecast.py 这个函数里面包含了最关键的步骤,其中 piecewise_logistic 函数表示了前面所说的基于逻辑回归的增长函数,它的输入包含了 cap 这个指标,因此需要用户事先指定 capacity。而在 piecewise_linear 这个函数中,是不需要 capacity 这个指标的,因此 m = Prophet() 这个函数默认的使用 growth = ‘linear’ 这个增长函数,也可以写作 m = Prophet(growth = ‘linear’);如果想用 growth = ‘logistic’,就要这样写:
m = Prophet(growth='logistic')
df['cap'] = 6
m.fit(df)
future = m.make_future_dataframe(periods=prediction_length, freq='min')
future['cap'] = 6
变点的选择(Changepoint Selection)
在介绍变点之前,先要介绍一下 Laplace 分布,它的概率密度函数为:
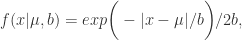
其中 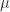 表示位置参数,
表示位置参数, 表示尺度参数。Laplace 分布与正态分布有一定的差异。
表示尺度参数。Laplace 分布与正态分布有一定的差异。
在 Prophet 算法中,是需要给出变点的位置,个数,以及增长的变化率的。因此,有三个比较重要的指标,那就是
- changepoint_range,
- n_changepoint,
- changepoint_prior_scale。
changepoint_range 指的是百分比,需要在前 changepoint_range 那么长的时间序列中设置变点,在默认的函数中是 changepoint_range = 0.8。n_changepoint 表示变点的个数,在默认的函数中是 n_changepoint = 25。changepoint_prior_scale 表示变点增长率的分布情况,在论文中, 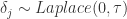 ,这里的
,这里的  就是 change_point_scale。
就是 change_point_scale。
在整个开源框架里面,在默认的场景下,变点的选择是基于时间序列的前 80% 的历史数据,然后通过等分的方法找到 25 个变点(change points),而变点的增长率是满足 Laplace 分布 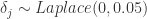 的。因此,当 趋近于零的时候, 也是趋向于零的,此时的增长函数将变成全段的逻辑回归函数或者线性函数。这一点从 的定义可以轻易地看出。
的。因此,当 趋近于零的时候, 也是趋向于零的,此时的增长函数将变成全段的逻辑回归函数或者线性函数。这一点从 的定义可以轻易地看出。
对未来的预估(Trend Forecast Uncertainty)
从历史上长度为  的数据中,我们可以选择出 个变点,它们所对应的增长率的变化量是 。此时我们需要预测未来,因此也需要设置相应的变点的位置,从代码中看,在 forecaster.py 的 sample_predictive_trend 函数中,通过 Poisson 分布等概率分布方法找到新增的 changepoint_ts_new 的位置,然后与 changepoint_t 拼接在一起就得到了整段序列的 changepoint_ts。
的数据中,我们可以选择出 个变点,它们所对应的增长率的变化量是 。此时我们需要预测未来,因此也需要设置相应的变点的位置,从代码中看,在 forecaster.py 的 sample_predictive_trend 函数中,通过 Poisson 分布等概率分布方法找到新增的 changepoint_ts_new 的位置,然后与 changepoint_t 拼接在一起就得到了整段序列的 changepoint_ts。
changepoint_ts_new = 1 + np.random.rand(n_changes) * (T - 1)
changepoint_ts = np.concatenate((self.changepoints_t, changepoint_ts_new))
第一行代码的 1 保证了 changepoint_ts_new 里面的元素都大于 change_ts 里面的元素。除了变点的位置之外,也需要考虑 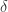 的情况。这里令
的情况。这里令  ,于是新的增长率的变化量就是按照下面的规则来选择的:当
,于是新的增长率的变化量就是按照下面的规则来选择的:当  时,
时,

季节性趋势
几乎所有的时间序列预测模型都会考虑这个因素,因为时间序列通常会随着天,周,月,年等季节性的变化而呈现季节性的变化,也称为周期性的变化。对于周期函数而言,大家能够马上联想到的就是正弦余弦函数。而在数学分析中,区间内的周期性函数是可以通过正弦和余弦的函数来表示的:假设  是以
是以 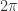 为周期的函数,那么它的傅立叶级数就是
为周期的函数,那么它的傅立叶级数就是 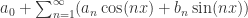 。
。
在论文中,作者使用傅立叶级数来模拟时间序列的周期性。假设 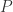 表示时间序列的周期,
表示时间序列的周期, 表示以年为周期,
表示以年为周期, 表示以周为周期。它的傅立叶级数的形式都是:
表示以周为周期。它的傅立叶级数的形式都是:
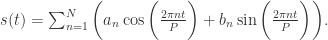
就作者的经验而言,对于以年为周期的序列()而言, ;对于以周为周期的序列( )而言,
;对于以周为周期的序列( )而言, 。这里的参数可以形成列向量:
。这里的参数可以形成列向量:
 。
。
当 时,
![X(t) = \bigg[\cos(\frac{2\pi(1)t}{365.25}),\cdots,\sin(\frac{2\pi(10)t}{365.25})\bigg]](https://s0.wp.com/latex.php?latex=X%28t%29+%3D+%5Cbigg%5B%5Ccos%28%5Cfrac%7B2%5Cpi%281%29t%7D%7B365.25%7D%29%2C%5Ccdots%2C%5Csin%28%5Cfrac%7B2%5Cpi%2810%29t%7D%7B365.25%7D%29%5Cbigg%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
当 时,
![X(t) = \bigg[\cos(\frac{2\pi(1)t}{7}),\cdots,\sin(\frac{2\pi(3)t}{7})\bigg]](https://s0.wp.com/latex.php?latex=X%28t%29+%3D+%5Cbigg%5B%5Ccos%28%5Cfrac%7B2%5Cpi%281%29t%7D%7B7%7D%29%2C%5Ccdots%2C%5Csin%28%5Cfrac%7B2%5Cpi%283%29t%7D%7B7%7D%29%5Cbigg%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
因此,时间序列的季节项就是: 而
而  的初始化是
的初始化是  。这里的
。这里的 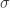 是通过 seasonality_prior_scale 来控制的,也就是说
是通过 seasonality_prior_scale 来控制的,也就是说 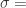 seasonality_prior_scale。这个值越大,表示季节的效应越明显;这个值越小,表示季节的效应越不明显。同时,在代码里面,seasonality_mode 也对应着两种模式,分别是加法和乘法,默认是加法的形式。在开源代码中,
seasonality_prior_scale。这个值越大,表示季节的效应越明显;这个值越小,表示季节的效应越不明显。同时,在代码里面,seasonality_mode 也对应着两种模式,分别是加法和乘法,默认是加法的形式。在开源代码中,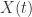 函数是通过 fourier_series 来构建的。
函数是通过 fourier_series 来构建的。
节假日效应(holidays and events)
在现实环境中,除了周末,同样有很多节假日,而且不同的国家有着不同的假期。在 Prophet 里面,通过维基百科里面对各个国家的节假日的描述,hdays.py 收集了各个国家的特殊节假日。除了节假日之外,用户还可以根据自身的情况来设置必要的假期,例如 The Super Bowl,双十一等。
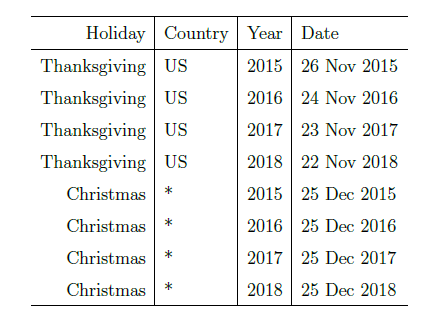
由于每个节假日对时间序列的影响程度不一样,例如春节,国庆节则是七天的假期,对于劳动节等假期来说则假日较短。因此,不同的节假日可以看成相互独立的模型,并且可以为不同的节假日设置不同的前后窗口值,表示该节假日会影响前后一段时间的时间序列。用数学语言来说,对与第  个节假日来说,
个节假日来说,  表示该节假日的前后一段时间。为了表示节假日效应,我们需要一个相应的指示函数(indicator function),同时需要一个参数
表示该节假日的前后一段时间。为了表示节假日效应,我们需要一个相应的指示函数(indicator function),同时需要一个参数  来表示节假日的影响范围。假设我们有
来表示节假日的影响范围。假设我们有  个节假日,那么
个节假日,那么

其中 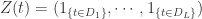 和
和 
其中  并且该正态分布是受到
并且该正态分布是受到  holidays_prior_scale 这个指标影响的。默认值是 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。用户可以根据自己的情况自行调整。
holidays_prior_scale 这个指标影响的。默认值是 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。用户可以根据自己的情况自行调整。
模型拟合(Model Fitting)
按照以上的解释,我们的时间序列已经可以通过增长项,季节项,节假日项来构建了,i.e.

下一步我们只需要拟合函数就可以了,在 Prophet 里面,作者使用了 pyStan 这个开源工具中的 L-BFGS 方法来进行函数的拟合。具体可以参考 forecast.py 里面的 stan_init 函数。
Prophet 中可以设置的参数
在 Prophet 中,用户一般可以设置以下四种参数:
- Capacity:在增量函数是逻辑回归函数的时候,需要设置的容量值。
- Change Points:可以通过 n_changepoints 和 changepoint_range 来进行等距的变点设置,也可以通过人工设置的方式来指定时间序列的变点。
- 季节性和节假日:可以根据实际的业务需求来指定相应的节假日。
- 光滑参数:
 changepoint_prior_scale 可以用来控制趋势的灵活度, seasonality_prior_scale 用来控制季节项的灵活度,
changepoint_prior_scale 可以用来控制趋势的灵活度, seasonality_prior_scale 用来控制季节项的灵活度,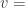 holidays prior scale 用来控制节假日的灵活度。
holidays prior scale 用来控制节假日的灵活度。
如果不想设置的话,使用 Prophet 默认的参数即可。
Prophet 的实际使用
Prophet 的简单使用
因为 Prophet 所需要的两列名称是 ‘ds’ 和 ‘y’,其中,’ds’ 表示时间戳,’y’ 表示时间序列的值,因此通常来说都需要修改 pd.dataframe 的列名字。如果原来的两列名字是 ‘timestamp’ 和 ‘value’ 的话,只需要这样写:
df = df.rename(columns={'timestamp':'ds', 'value':'y'})
如果 ‘timestamp’ 是使用 unixtime 来记录的,需要修改成 YYYY-MM-DD hh:mm:ss 的形式:
df['ds'] = pd.to_datetime(df['ds'],unit='s')
在一般情况下,时间序列需要进行归一化的操作,而 pd.dataframe 的归一化操作也十分简单:
df['y'] = (df['y'] - df['y'].mean()) / (df['y'].std())
然后就可以初始化模型,然后拟合模型,并且进行时间序列的预测了。
初始化模型:m = Prophet()
拟合模型:m.fit(df)
计算预测值:periods 表示需要预测的点数,freq 表示时间序列的频率。
future = m.make_future_dataframe(periods=30, freq='min')
future.tail()
forecast = m.predict(future)
而 freq 指的是 pd.dataframe 里面的一个指标,’min’ 表示按分钟来收集的时间序列。具体参见文档:http://pandas.pydata.org/pandas-docs/stable/timeseries.html#offset-aliases
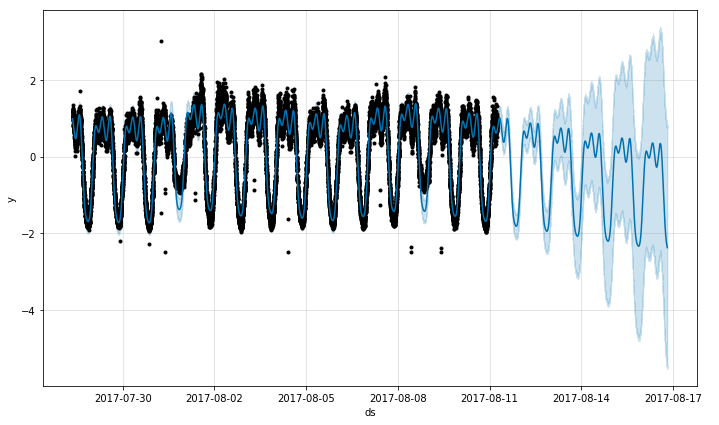
在进行了预测操作之后,通常都希望把时间序列的预测趋势画出来:
画出预测图:
m.plot(forecast)
画出时间序列的分量:
m.plot_components(forecast)

如果要画出更详细的指标,例如中间线,上下界,那么可以这样写:
x1 = forecast['ds']
y1 = forecast['yhat']
y2 = forecast['yhat_lower']
y3 = forecast['yhat_upper']
plt.plot(x1,y1)
plt.plot(x1,y2)
plt.plot(x1,y3)
plt.show()
其实 Prophet 预测的结果都放在了变量 forecast 里面,打印结果的话可以这样写:第一行是打印所有时间戳的预测结果,第二行是打印最后五个时间戳的预测结果。
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']])
print(forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail())
Prophet 的参数设置
Prophet 的默认参数可以在 forecaster.py 中看到:
def __init__(
self,
growth='linear',
changepoints=None,
n_changepoints=25,
changepoint_range=0.8,
yearly_seasonality='auto',
weekly_seasonality='auto',
daily_seasonality='auto',
holidays=None,
seasonality_mode='additive',
seasonality_prior_scale=10.0,
holidays_prior_scale=10.0,
changepoint_prior_scale=0.05,
mcmc_samples=0,
interval_width=0.80,
uncertainty_samples=1000,
):
增长函数的设置
在 Prophet 里面,有两个增长函数,分别是分段线性函数(linear)和逻辑回归函数(logistic)。而 m = Prophet() 默认使用的是分段线性函数(linear),并且如果要是用逻辑回归函数的时候,需要设置 capacity 的值,i.e. df[‘cap’] = 100,否则会出错。
m = Prophet()
m = Prophet(growth='linear')
m = Prophet(growth='logistic')
变点的设置
在 Prophet 里面,变点默认的选择方法是前 80% 的点中等距选择 25 个点作为变点,也可以通过以下方法来自行设置变点,甚至可以人为设置某些点。
m = Prophet(n_changepoints=25)
m = Prophet(changepoint_range=0.8)
m = Prophet(changepoint_prior_scale=0.05)
m = Prophet(changepoints=['2014-01-01'])
而变点的作图可以使用:
from fbprophet.plot import add_changepoints_to_plot
fig = m.plot(forecast)
a = add_changepoints_to_plot(fig.gca(), m, forecast)
周期性的设置
通常来说,可以在 Prophet 里面设置周期性,无论是按月还是周其实都是可以设置的,例如:
m = Prophet(weekly_seasonality=False)
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
m = Prophet(weekly_seasonality=True)
m.add_seasonality(name='weekly', period=7, fourier_order=3, prior_scale=0.1)

节假日的设置
有的时候,由于双十一或者一些特殊节假日,我们可以设置某些天数是节假日,并且设置它的前后影响范围,也就是 lower_window 和 upper_window。
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((playoffs, superbowls))
m = Prophet(holidays=holidays, holidays_prior_scale=10.0)
结束语
对于商业分析等领域的时间序列,Prophet 可以进行很好的拟合和预测,但是对于一些周期性或者趋势性不是很强的时间序列,用 Prophet 可能就不合适了。但是,Prophet 提供了一种时序预测的方法,在用户不是很懂时间序列的前提下都可以使用这个工具得到一个能接受的结果。具体是否用 Prophet 则需要根据具体的时间序列来确定。
参考文献:
- https://otexts.org/fpp2/components.html
- https://en.wikipedia.org/wiki/Decomposition_of_time_series
- A review of change point detection methods, CTruong, L. Oudre, N.Vayatis
- https://github.com/facebook/prophet
- https://facebook.github.io/prophet/


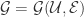 是一个图,顶点是帐号
是一个图,顶点是帐号 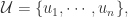 边是由帐号之间的连线
边是由帐号之间的连线 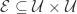 所构成的。
所构成的。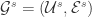 和
和 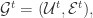 其目标是找到一个函数
其目标是找到一个函数 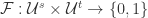 使得,
使得,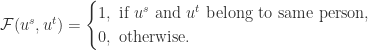
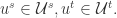
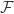 就是模型需要学习的目标函数,进一步地,对于
就是模型需要学习的目标函数,进一步地,对于 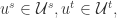 学习得到的预测函数
学习得到的预测函数 ![\mathcal{\hat{F}}(u^{s},u^{t})=p\in [0,1]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7B%5Chat%7BF%7D%7D%28u%5E%7Bs%7D%2Cu%5E%7Bt%7D%29%3Dp%5Cin+%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示两个帐号属于同一个自然人的概率值。
表示两个帐号属于同一个自然人的概率值。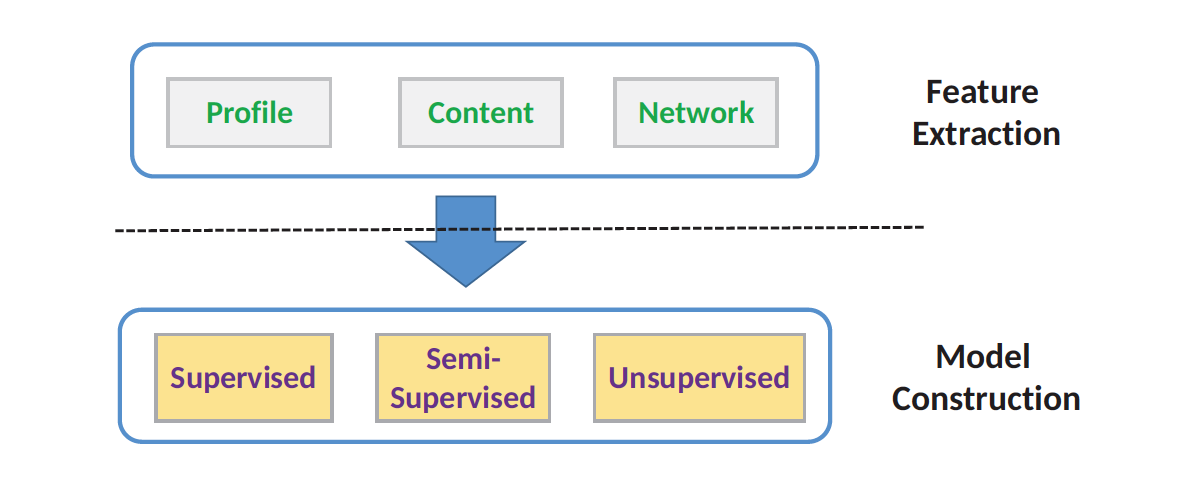
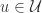 而言,用
而言,用 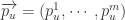 来表示画像特征向量,其中
来表示画像特征向量,其中  表示画像属性特征的个数。对于两个社交网络
表示画像属性特征的个数。对于两个社交网络 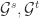 的帐号
的帐号 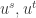 而言,可以得到相应的画像特征向量
而言,可以得到相应的画像特征向量 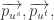 然后可以用基于距离(distance-based)或者基于频率(frequence-based)的方法来获得向量的距离或者相似性。换句话说,就是通过加权平均算法来获得结果:
然后可以用基于距离(distance-based)或者基于频率(frequence-based)的方法来获得向量的距离或者相似性。换句话说,就是通过加权平均算法来获得结果: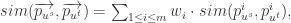 或者
或者
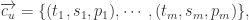 其中
其中 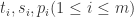 分别表示时间戳,空间数据,内容数据。
分别表示时间戳,空间数据,内容数据。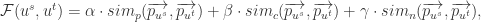
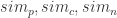 分别表示画像(profile),内容(content),社交网络(network)之间的相似度。
分别表示画像(profile),内容(content),社交网络(network)之间的相似度。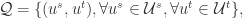 那么正样本是
那么正样本是  负样本
负样本 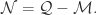 在实际使用的时候,要注意采样的比例和负样本的选择方法。
在实际使用的时候,要注意采样的比例和负样本的选择方法。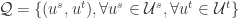 是所有的帐号对,
是所有的帐号对,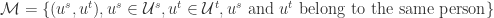 是所有属于相同自然人的帐号对,
是所有属于相同自然人的帐号对, 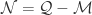 是所有属于不同自然人的帐号对。
是所有属于不同自然人的帐号对。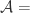 {被算法映射成相同自然人的帐号对},
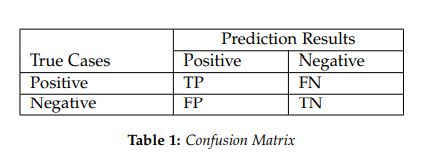
{被算法映射成相同自然人的帐号对},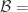 {被算法映射成不同自然人的帐号对};用 TP, TN, FN, FP 来描述就是:
{被算法映射成不同自然人的帐号对};用 TP, TN, FN, FP 来描述就是: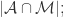
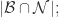
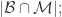
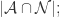
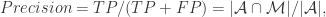
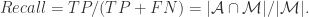
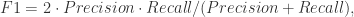
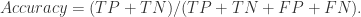

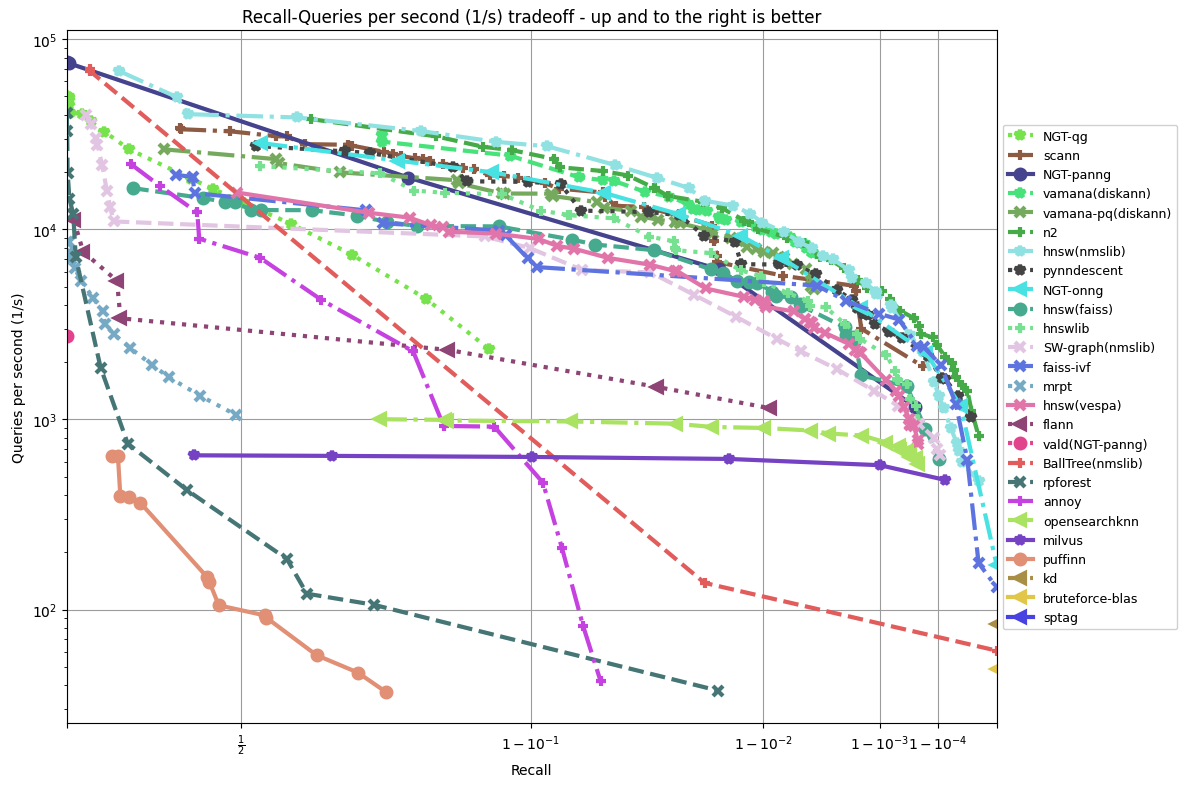
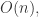 因此,计算机科学家们开发了各种各样的近似最近邻搜索方法(approximate nearest neighbors)来加快其搜索速度,在精确率和召回率上面就会做出一定的牺牲,但是其搜索速度相对暴力搜索有很大地提高。
因此,计算机科学家们开发了各种各样的近似最近邻搜索方法(approximate nearest neighbors)来加快其搜索速度,在精确率和召回率上面就会做出一定的牺牲,但是其搜索速度相对暴力搜索有很大地提高。 其中
其中  是欧氏空间的维度。常用的距离公式包括:
是欧氏空间的维度。常用的距离公式包括: 中的 L1 范数;
中的 L1 范数;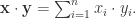

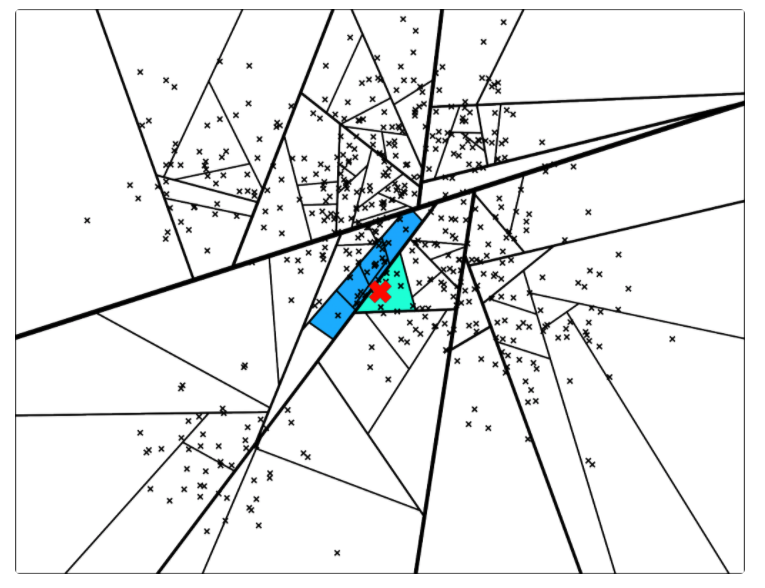
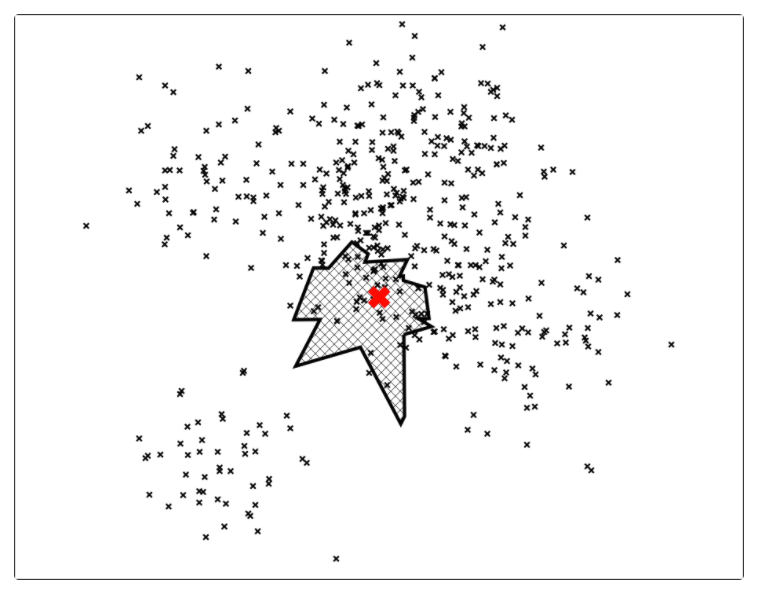
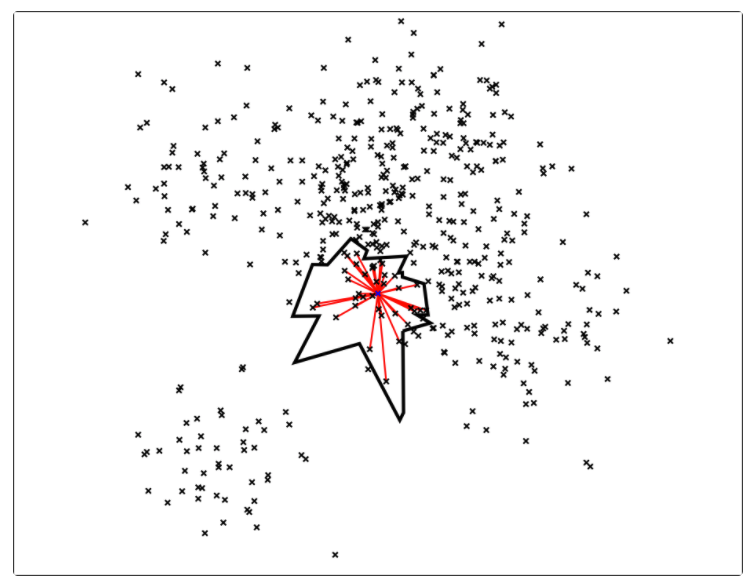
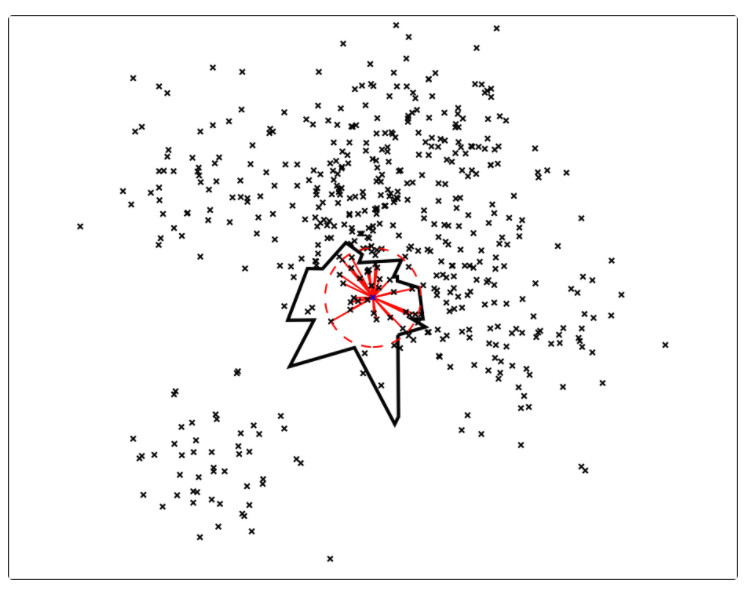
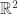 中的点集来作为案例,介绍 annoy 算法的基本思想和算法原理。
中的点集来作为案例,介绍 annoy 算法的基本思想和算法原理。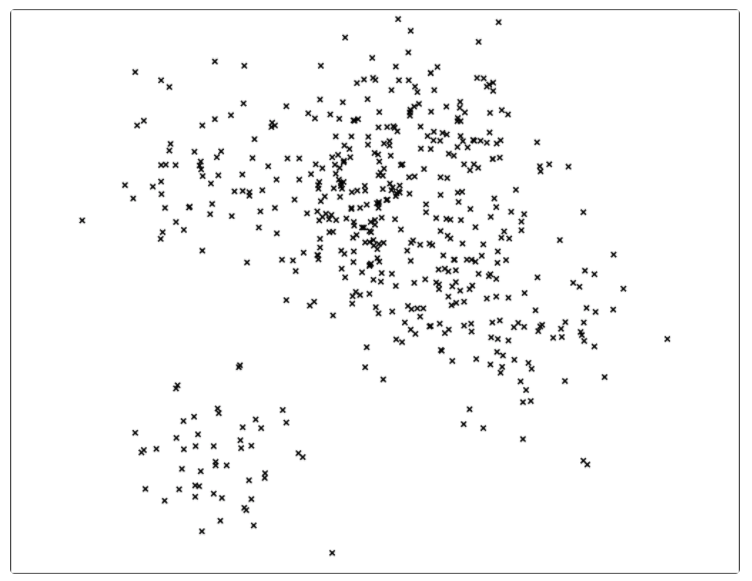
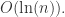


 其 n 元语法分别是:
其 n 元语法分别是:![X=X[0,\cdots,m-1]=[X[0],\cdots,X[m-1]]](https://s0.wp.com/latex.php?latex=X%3DX%5B0%2C%5Ccdots%2Cm-1%5D%3D%5BX%5B0%5D%2C%5Ccdots%2CX%5Bm-1%5D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 而言,其 unigram,bigram,trigram,multiset(多重集合)分别是:
而言,其 unigram,bigram,trigram,multiset(多重集合)分别是:![unigram(X)=\{X[i], 0\leq i\leq m-1\};](https://s0.wp.com/latex.php?latex=unigram%28X%29%3D%5C%7BX%5Bi%5D%2C+0%5Cleq+i%5Cleq+m-1%5C%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![bigram(X)=\{X[i]X[i+1], 0\leq i\leq m-2\};](https://s0.wp.com/latex.php?latex=bigram%28X%29%3D%5C%7BX%5Bi%5DX%5Bi%2B1%5D%2C+0%5Cleq+i%5Cleq+m-2%5C%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![trigram(X)=\{X[i]X[i+1]X[i+2], 0\leq i\leq m-3\};](https://s0.wp.com/latex.php?latex=trigram%28X%29%3D%5C%7BX%5Bi%5DX%5Bi%2B1%5DX%5Bi%2B2%5D%2C+0%5Cleq+i%5Cleq+m-3%5C%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![multiset(X)=\{X[i]:d[i], 0\leq i\leq m-1\},](https://s0.wp.com/latex.php?latex=multiset%28X%29%3D%5C%7BX%5Bi%5D%3Ad%5Bi%5D%2C+0%5Cleq+i%5Cleq+m-1%5C%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![d[i]](https://s0.wp.com/latex.php?latex=d%5Bi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示
表示 ![X[i]](https://s0.wp.com/latex.php?latex=X%5Bi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 出现的次数。通过 n 元语法,我们可以将一个字符串转换成一个集合,然后通过计算集合之间的相似性来评估字符串的相似性。对于字符串
出现的次数。通过 n 元语法,我们可以将一个字符串转换成一个集合,然后通过计算集合之间的相似性来评估字符串的相似性。对于字符串  而言,其相似度可以转换为:
而言,其相似度可以转换为:
 表示集合的相似度计算函数。
表示集合的相似度计算函数。
 表示集合的距离计算函数。
表示集合的距离计算函数。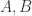 而言,其
而言,其  的选型就包括但不限于以下几种:
的选型就包括但不限于以下几种: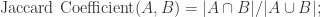




 同时,不仅集合之间可以进行交集,并集的计算,多重集合之间同样可以进行类似的操作,于是上述方法同样可以应用在多重集合上。
同时,不仅集合之间可以进行交集,并集的计算,多重集合之间同样可以进行类似的操作,于是上述方法同样可以应用在多重集合上。 表示字符串
表示字符串  其中
其中 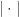 表示多重集合的 SIZE,减法
表示多重集合的 SIZE,减法  表示多重集合的差集。
表示多重集合的差集。![[x_{0},x_{1},x_{2},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B0%7D%2Cx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 而言,其子序列(subsequence)
而言,其子序列(subsequence) ![[x_{n_{1}},\cdots,x_{n_{k}}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bn_%7B1%7D%7D%2C%5Ccdots%2Cx_%7Bn_%7Bk%7D%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 指的是从原始的序列中通过去除某些元素但不破坏余下元素的相对位置(在前或者在后)而形成的新序列。子串(substring)是相对于一个字符串而言,它是其原始字符串中的完整一段。例如:对于“苹果手机”而言,“苹手”是其子序列,但“苹手”并不是子串。
指的是从原始的序列中通过去除某些元素但不破坏余下元素的相对位置(在前或者在后)而形成的新序列。子串(substring)是相对于一个字符串而言,它是其原始字符串中的完整一段。例如:对于“苹果手机”而言,“苹手”是其子序列,但“苹手”并不是子串。 和
和 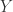 的最长公共子序列的长度和最长公共子串的长度,就需要使用动态规划方面的知识,构建其边界条件和动态转移方程。
的最长公共子序列的长度和最长公共子串的长度,就需要使用动态规划方面的知识,构建其边界条件和动态转移方程。![X=X[0,\cdots,m-1], Y=Y[0,\cdots,n-1].](https://s0.wp.com/latex.php?latex=X%3DX%5B0%2C%5Ccdots%2Cm-1%5D%2C+Y%3DY%5B0%2C%5Ccdots%2Cn-1%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![L(m,n)=L(X[0,\cdots,m-1], Y[0,\cdots,n-1])](https://s0.wp.com/latex.php?latex=L%28m%2Cn%29%3DL%28X%5B0%2C%5Ccdots%2Cm-1%5D%2C+Y%5B0%2C%5Ccdots%2Cn-1%5D%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示字符串
表示字符串 ![X[0,\cdots,m-1]](https://s0.wp.com/latex.php?latex=X%5B0%2C%5Ccdots%2Cm-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和
和 ![Y[0,\cdots,n-1]](https://s0.wp.com/latex.php?latex=Y%5B0%2C%5Ccdots%2Cn-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的最长公共子序列的长度。则可以得到其状态转移方程如下:
的最长公共子序列的长度。则可以得到其状态转移方程如下:![L(m,n)=\begin{cases} L(m-1,n-1)+1, \text{ if } X[m-1] == Y[n-1] \\ \max(L(m-1,n), L(m, n-1)), \text{ else }. \end{cases}](https://s0.wp.com/latex.php?latex=L%28m%2Cn%29%3D%5Cbegin%7Bcases%7D+L%28m-1%2Cn-1%29%2B1%2C+%5Ctext%7B+if+%7D+X%5Bm-1%5D+%3D%3D+Y%5Bn-1%5D+%5C%5C+%5Cmax%28L%28m-1%2Cn%29%2C+L%28m%2C+n-1%29%29%2C+%5Ctext%7B+else+%7D.+%5Cend%7Bcases%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 返回
返回 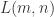 即可表示最长公共子序列的长度。
即可表示最长公共子序列的长度。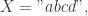
 则有
则有 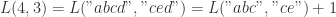

![L(m,n)=\begin{cases} L(m-1,n-1)+1, \text{ if } X[m-1]==Y[n-1] \\ 0, \text{ else }. \end{cases}](https://s0.wp.com/latex.php?latex=L%28m%2Cn%29%3D%5Cbegin%7Bcases%7D+L%28m-1%2Cn-1%29%2B1%2C+%5Ctext%7B+if+%7D+X%5Bm-1%5D%3D%3DY%5Bn-1%5D+%5C%5C+0%2C+%5Ctext%7B+else+%7D.+%5Cend%7Bcases%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 即可表示最长公共子串的长度。
即可表示最长公共子串的长度。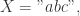
 则有最长公共子串的长度是
则有最长公共子串的长度是 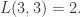
 而言,如果两个字符
而言,如果两个字符 ![X[i], Y[j]](https://s0.wp.com/latex.php?latex=X%5Bi%5D%2C+Y%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 满足以下两个条件:
满足以下两个条件:![X[i]=Y[j];](https://s0.wp.com/latex.php?latex=X%5Bi%5D%3DY%5Bj%5D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![|i-j|\leq [\max(|X|,|Y|)/2]-1;](https://s0.wp.com/latex.php?latex=%7Ci-j%7C%5Cleq+%5B%5Cmax%28%7CX%7C%2C%7CY%7C%29%2F2%5D-1%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![X[i],Y[j]](https://s0.wp.com/latex.php?latex=X%5Bi%5D%2CY%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 被称为匹配(matching),其中
被称为匹配(matching),其中 ![[\cdot]](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示高斯取整函数。在此定义下计算出
表示高斯取整函数。在此定义下计算出  从定义可以得到
从定义可以得到  的长度是一样的,记为
的长度是一样的,记为 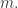 令
令 ![t=[\#\{0\leq i\leq m-1:X'[i]\neq Y'[i]\}/2]](https://s0.wp.com/latex.php?latex=t%3D%5B%5C%23%5C%7B0%5Cleq+i%5Cleq+m-1%3AX%27%5Bi%5D%5Cneq+Y%27%5Bi%5D%5C%7D%2F2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 称为 transposition。于是,Jaro 相似度就可以定义为:
称为 transposition。于是,Jaro 相似度就可以定义为:
 可以得到
可以得到 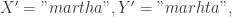 于是
于是  因此,Jaro 相似度是
因此,Jaro 相似度是
 可以得到
可以得到  于是
于是  因此,Jaro 相似度是
因此,Jaro 相似度是
 可以得到
可以得到  于是
于是 
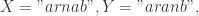 可以得到
可以得到  于是
于是  因此,Jaro 相似度是
因此,Jaro 相似度是


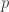 表示系数(默认是 0.1,可以调整),
表示系数(默认是 0.1,可以调整),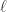 表示
表示  的最长前缀子串的 SIZE,并且不超过 4。
的最长前缀子串的 SIZE,并且不超过 4。 因此,Jaro-Winkler 相似度为
因此,Jaro-Winkler 相似度为 
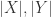 分别表示字符串
分别表示字符串  表示
表示 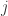 个字符的 Levenshtein 距离,
个字符的 Levenshtein 距离,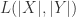 表示两个字符串的 Levenshtein 距离。
表示两个字符串的 Levenshtein 距离。![Lev(i,j)=\begin{cases} j, \text{ if } i=0,\\ i, \text{ else if } j=0,\\ \min\begin{cases}Lev(i-1,j)+1,\\ Lev(i,j-1)+1,\\ Lev(i-1,j-1)+1_{X[i-1]\neq Y[j-1]} \end{cases}\text{ otherwise }.\end{cases}](https://s0.wp.com/latex.php?latex=Lev%28i%2Cj%29%3D%5Cbegin%7Bcases%7D+j%2C+%5Ctext%7B+if+%7D+i%3D0%2C%5C%5C+i%2C+%5Ctext%7B+else+if+%7D+j%3D0%2C%5C%5C+%5Cmin%5Cbegin%7Bcases%7DLev%28i-1%2Cj%29%2B1%2C%5C%5C+Lev%28i%2Cj-1%29%2B1%2C%5C%5C+Lev%28i-1%2Cj-1%29%2B1_%7BX%5Bi-1%5D%5Cneq+Y%5Bj-1%5D%7D+%5Cend%7Bcases%7D%5Ctext%7B+otherwise+%7D.%5Cend%7Bcases%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
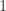 表示指示函数,
表示指示函数,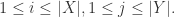
![f:[0,+\infty)\rightarrow [-1,1]](https://s0.wp.com/latex.php?latex=f%3A%5B0%2C%2B%5Cinfty%29%5Crightarrow+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 是将距离转换成相似度的函数,则可以表示为
是将距离转换成相似度的函数,则可以表示为  其中,
其中, 是严格递减函数,值域属于
是严格递减函数,值域属于 ![[-1,1],](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

![g:[-1,1]\rightarrow [0,+\infty)](https://s0.wp.com/latex.php?latex=g%3A%5B-1%2C1%5D%5Crightarrow+%5B0%2C%2B%5Cinfty%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 是将相似度转换为距离的函数,则可以表示为
是将相似度转换为距离的函数,则可以表示为  其中,
其中,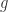 是严格递减函数,值域属于
是严格递减函数,值域属于 

 来转换;
来转换; 也可以使用函数
也可以使用函数  来计算。
来计算。 其中
其中  得到的;
得到的;![[0,100].](https://s0.wp.com/latex.php?latex=%5B0%2C100%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 如果需要计算相似度,直接除以 100 即可。
如果需要计算相似度,直接除以 100 即可。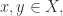 相似性函数
相似性函数  是将
是将  映射到实数域
映射到实数域 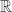 的有界函数,i.e. 存在上下界使得
的有界函数,i.e. 存在上下界使得  它具有以下两个性质:
它具有以下两个性质: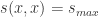 对于所有的
对于所有的  都成立;
都成立; 对于所有的
对于所有的  都成立;
都成立;
 距离函数
距离函数 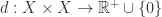 是将
是将  并不存在上界,它具有以下三个性质:
并不存在上界,它具有以下三个性质: 对于所有的
对于所有的  对于所有的
对于所有的 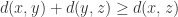 对于所有的
对于所有的  都成立。
都成立。
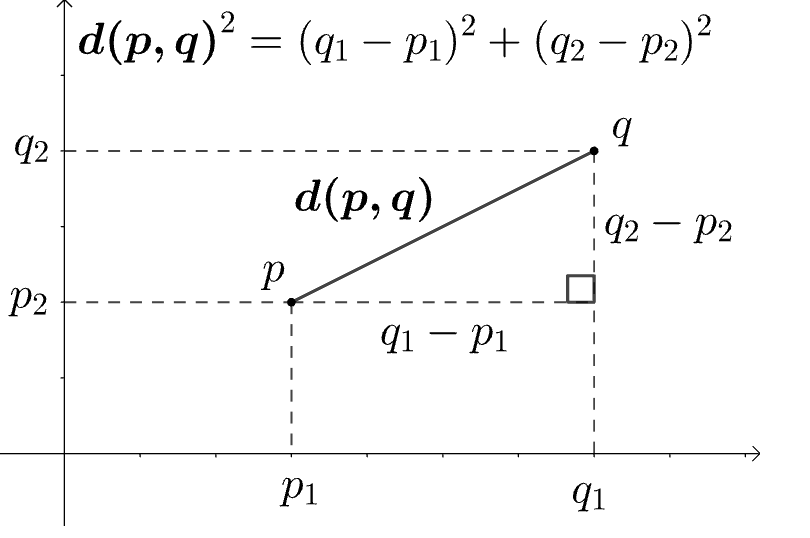
 中的两个点
中的两个点  和
和  而言,可以多种方法来描述它们之间的相似性。
而言,可以多种方法来描述它们之间的相似性。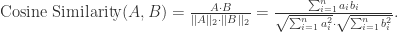
![[-1,1].](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


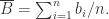 同样根据 Cauchy 不等式可以得到 Pearson Similarity 的取值范围是
同样根据 Cauchy 不等式可以得到 Pearson Similarity 的取值范围是 
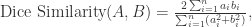
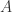 和
和 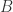 不能同时是零点,并且由均值不等式可以得到 Dice Similarity 的范围也是
不能同时是零点,并且由均值不等式可以得到 Dice Similarity 的范围也是 
![[0,1].](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 越靠近
越靠近  表示两个集合越不相似。
表示两个集合越不相似。



 指的是条件概率,意思分别是
指的是条件概率,意思分别是 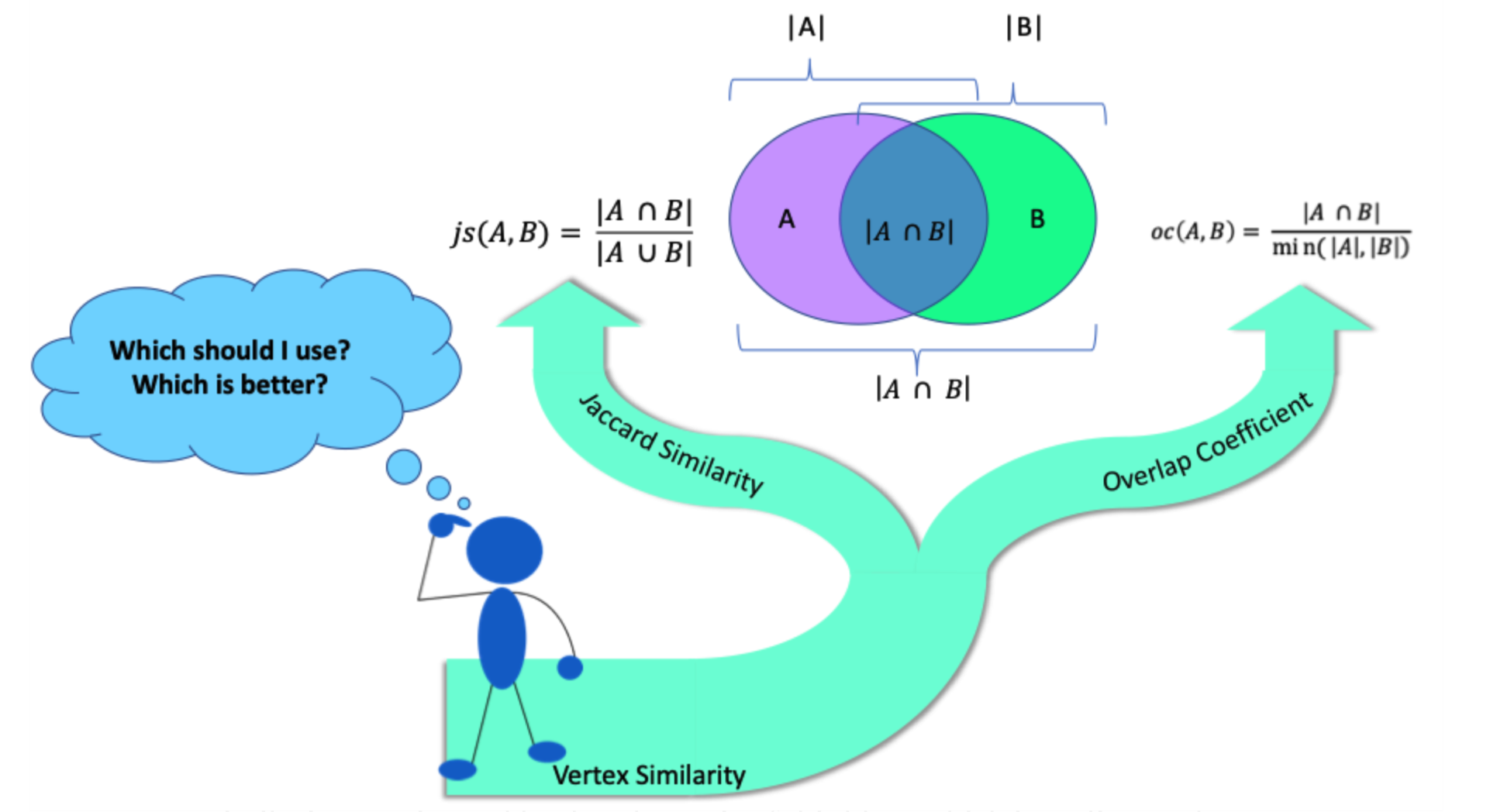

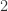 进行推广,则可以引导出
进行推广,则可以引导出 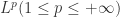 距离如下:
距离如下: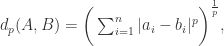 其中
其中 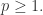

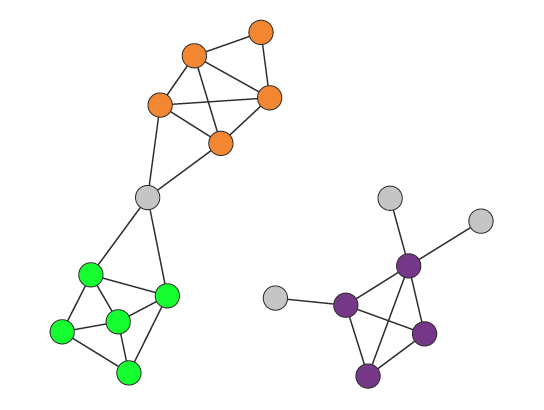
 中,
中, 表示顶点集合,
表示顶点集合,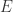 表示边的集合。为了简单起见,这里暂时是考虑无向图的场景。对于顶点
表示边的集合。为了简单起见,这里暂时是考虑无向图的场景。对于顶点  而言,
而言, 表示其邻居的集合。在复杂网络中,同样需要描述两个顶点
表示其邻居的集合。在复杂网络中,同样需要描述两个顶点 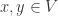 的相似性,于是可以考虑以下指标。
的相似性,于是可以考虑以下指标。

 和
和 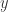 的邻居求并集,也可以得到一个指标,
的邻居求并集,也可以得到一个指标,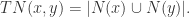
 它将
它将 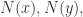
 就可以作为顶点
就可以作为顶点 
 和
和 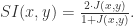


 之间是否有边相连接。如果相连接,则取值为
之间是否有边相连接。如果相连接,则取值为  否则取值为
否则取值为 

 事实上,当
事实上,当  时,
时,
 越大,表示顶点
越大,表示顶点  的共同邻居
的共同邻居  拥有较多的邻居,则降低权重,否则增加权重。
拥有较多的邻居,则降低权重,否则增加权重。
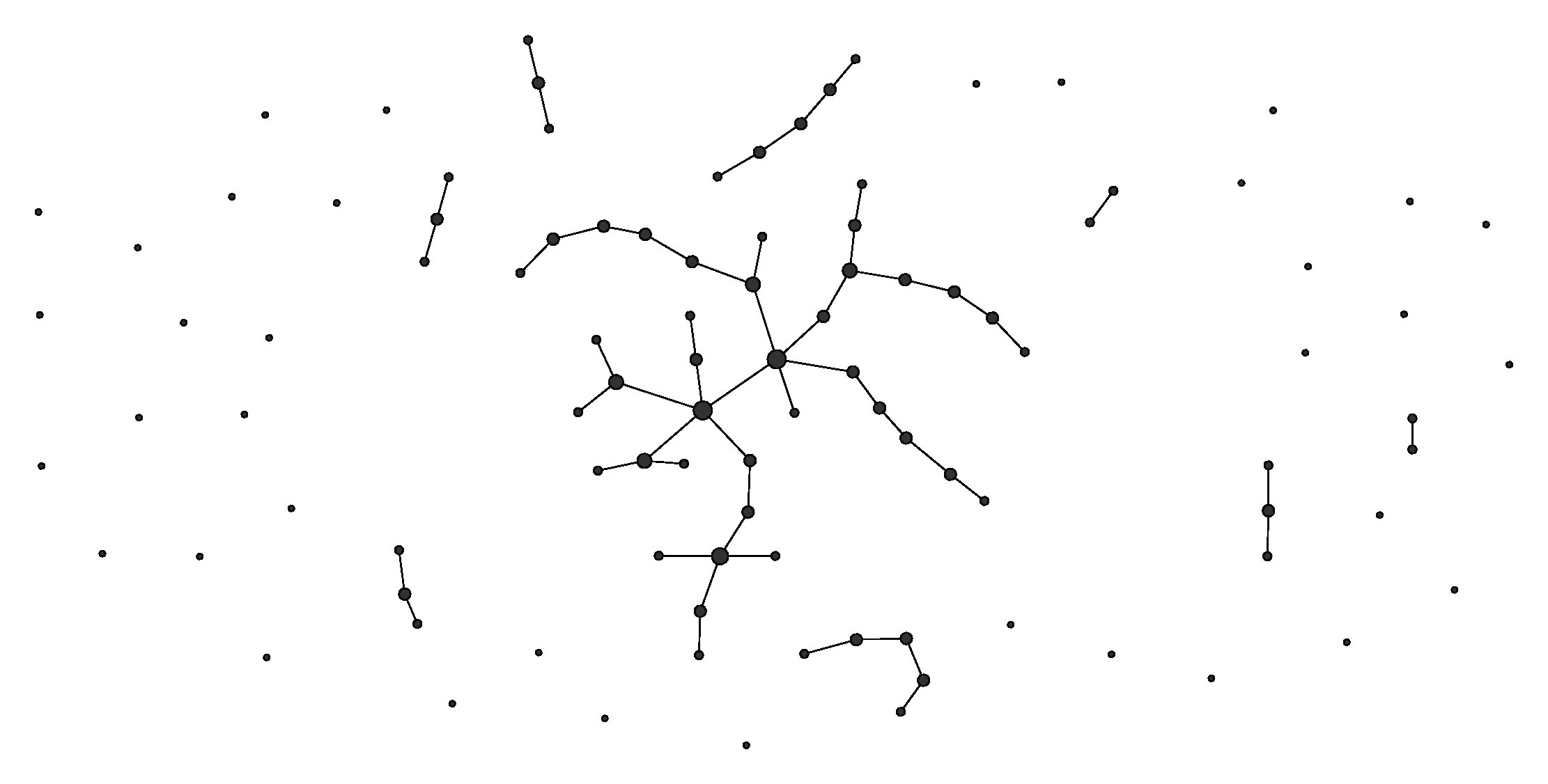
 和
和 
 的定义是随机从
的定义是随机从  条边所生成的所有图集合中选择一个。其中,这样的图集合的势是
条边所生成的所有图集合中选择一个。其中,这样的图集合的势是  因此获得其中某一个图的概率是
因此获得其中某一个图的概率是 
 的定义是有
的定义是有 ![p\in[0,1]](https://s0.wp.com/latex.php?latex=p%5Cin%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 来决定是否连边。
来决定是否连边。 而
而  这里的
这里的 
 而
而  条边,于是边数为
条边,于是边数为  i.e.
i.e. 
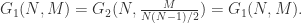
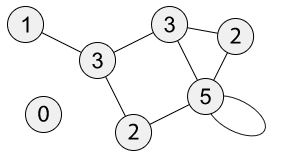
 但如果要计算图的其余指标,用第二种定义
但如果要计算图的其余指标,用第二种定义 
 而言,它的边数大约是
而言,它的边数大约是  最多与该节点相连接的顶点数为
最多与该节点相连接的顶点数为  整个图的顶点平均度是(边数 * 2) / 顶点数,用记号
整个图的顶点平均度是(边数 * 2) / 顶点数,用记号 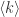 来表示,意味着顶点平均度是
来表示,意味着顶点平均度是  当
当 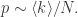
 条边的概率值。事实上,对于除了
条边的概率值。事实上,对于除了  个点而言,有
个点而言,有  个顶点与
个顶点与  同时需要从这
同时需要从这 
 时,上述概率近似于泊松分布(Possion Distribution)。事实上,
时,上述概率近似于泊松分布(Possion Distribution)。事实上, 并且
并且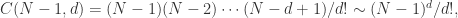

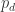 近似于泊松分布,
近似于泊松分布,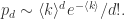
 而言,它的连通分支个数是与顶点的平均度
而言,它的连通分支个数是与顶点的平均度  时,每个顶点都是孤立的,连通分支个数为
时,每个顶点都是孤立的,连通分支个数为  当
当  时,任意两个顶点都有边相连接,整个图是完全图,连通分支的个数是
时,任意两个顶点都有边相连接,整个图是完全图,连通分支的个数是  顶点的平均度从
顶点的平均度从 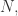 那么在这个变化的过程中,最大连通分支的顶点数究竟是怎样变化的呢?是否存在一些临界点呢?数学家 Erdos 和 Renyi 在 1959 年的论文中给出了答案:
那么在这个变化的过程中,最大连通分支的顶点数究竟是怎样变化的呢?是否存在一些临界点呢?数学家 Erdos 和 Renyi 在 1959 年的论文中给出了答案: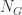 表示最大连通分支的顶点个数,那么对于图的平均度
表示最大连通分支的顶点个数,那么对于图的平均度  那么
那么 
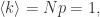 那么
那么 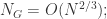
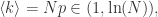 那么巨连通分支(Giant Component)存在,同时存在很多小的连通分支,在临界点
那么巨连通分支(Giant Component)存在,同时存在很多小的连通分支,在临界点  这里
这里 
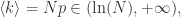 那么图
那么图 
 当
当  时,巨连通分支不存在,所有连通分支的量级都在
时,巨连通分支不存在,所有连通分支的量级都在 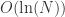 以下;当
以下;当  时,巨连通分支开始出现,量级大约是
时,巨连通分支开始出现,量级大约是  当
当  时,随机图存在一个巨连通分支和很多小的连通分支;当
时,随机图存在一个巨连通分支和很多小的连通分支;当  时,图是连通图。
时,图是连通图。
 图的顶点不在最大连通分支的概率。
图的顶点不在最大连通分支的概率。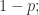 Case(2):要么
Case(2):要么  个顶点中,其概率是
个顶点中,其概率是 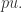 于是,对于所有顶点而言,它不在最大连通分支的概率是
于是,对于所有顶点而言,它不在最大连通分支的概率是  于是,
于是,
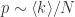 和
和  可以得到当
可以得到当 
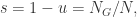 它表示最大连通分支的顶点个数在所有顶点个数的占比,从而可以得到近似方程:
它表示最大连通分支的顶点个数在所有顶点个数的占比,从而可以得到近似方程:
 则
则 
 它的导数是
它的导数是  通过计算可以得到:
通过计算可以得到: 时,
时, 在
在 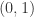 上成立,i.e.
上成立,i.e.  在
在 ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上的唯一解是
上的唯一解是  换言之,
换言之,
 时,
时,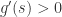 在
在  成立,
成立, 成立。换言之,
成立。换言之, 在
在 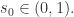 此时会存在巨连通分支,
此时会存在巨连通分支, 是解。
是解。 的情况。对于极限状况而言,假设仅有一个顶点不在最大连通分支中,那么
的情况。对于极限状况而言,假设仅有一个顶点不在最大连通分支中,那么  此刻,
此刻,
 因此,
因此,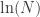 也是一个临界点,并且是出现全连通图的临界点。
也是一个临界点,并且是出现全连通图的临界点。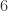 个相识关系。换言之,来自世界上任何地方的两个人都可以通过不超过
个相识关系。换言之,来自世界上任何地方的两个人都可以通过不超过 
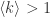 的情况,甚至只考虑
的情况,甚至只考虑  的全连通图。任取一个顶点
的全连通图。任取一个顶点  个距离为
个距离为 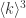 个距离为
个距离为 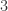 的顶点;
的顶点; 个距离为
个距离为  的顶点;
的顶点;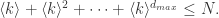 通过等比级数的公式可以得到
通过等比级数的公式可以得到  因此,
因此,
 如果
如果  并且每个人认识
并且每个人认识  个人,于是随机图的直径量级是
个人,于是随机图的直径量级是 
 ,
, ,这里的
,这里的 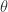 表示一个已经训练好的机器学习模型参数集合。
表示一个已经训练好的机器学习模型参数集合。 对于
对于  ,
,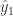 和
和 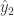 分别表示对于
分别表示对于 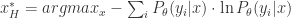 ,
,
 ,并且这些模型都是通过数据集
,并且这些模型都是通过数据集  的训练得到的。
的训练得到的。 ,
,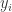 表示第
表示第 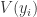 表示投票给
表示投票给 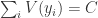 。
。
 也是概率分布,
也是概率分布, 表示两个概率的 KL 散度。
表示两个概率的 KL 散度。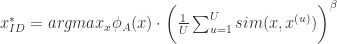 ,
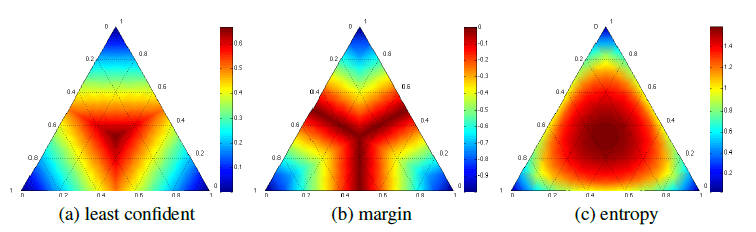
, 表示某个不确定性采样方法或者 QBC 方法,
表示某个不确定性采样方法或者 QBC 方法,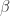 表示指数参数,
表示指数参数, 表示第
表示第 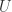 表示类别的个数。加上权重表示会选择那些与代表元相似度较高的元素作为标注候选集。
表示类别的个数。加上权重表示会选择那些与代表元相似度较高的元素作为标注候选集。
 而言,它可能存在重复的元素,用
而言,它可能存在重复的元素,用 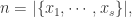 并且这个集合可以表示为
并且这个集合可以表示为  目标是:使用
目标是:使用 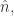 其中
其中  并且估计值
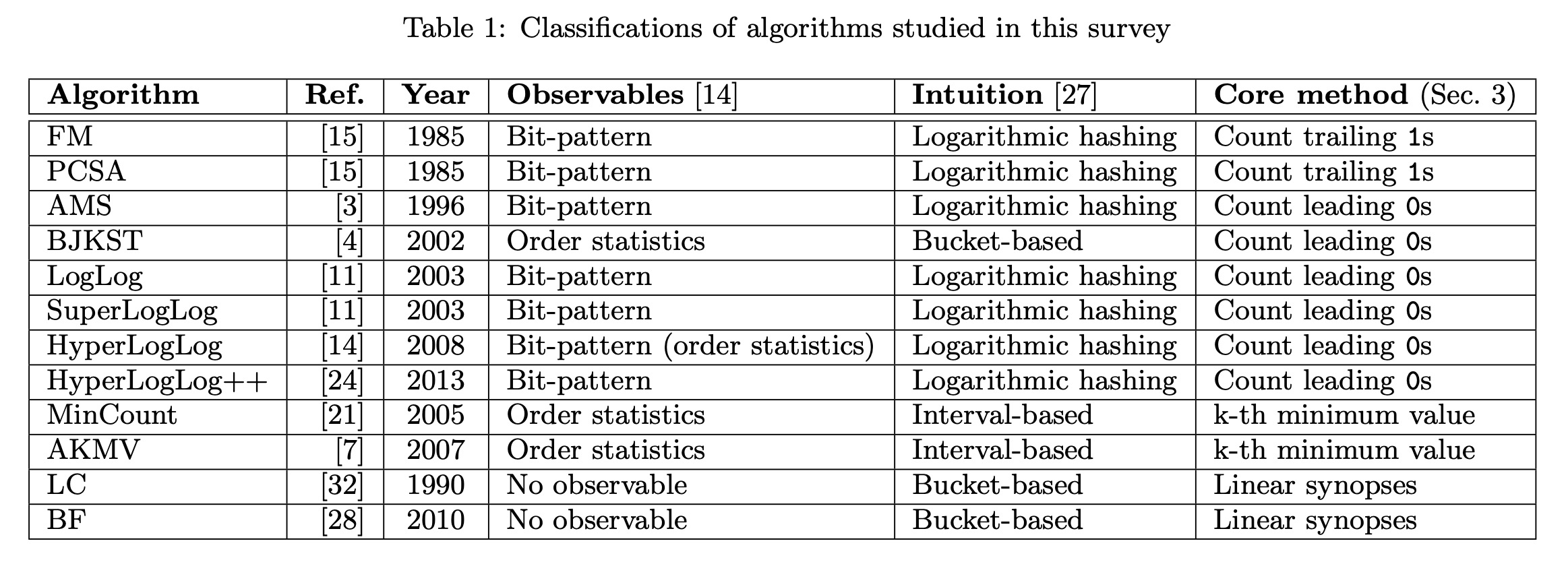
并且估计值 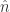 和实际值
和实际值 

 映射到
映射到  也就是说用二进制来表示数据流中的元素。每一个数据流中的元素
也就是说用二进制来表示数据流中的元素。每一个数据流中的元素  序列。
序列。 依次扔出
依次扔出 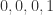 的概率是多少?通过概率计算可以得到是这个概率是
的概率是多少?通过概率计算可以得到是这个概率是  那么相当于平均需要扔
那么相当于平均需要扔 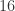 次,才会获得
次,才会获得  这个序列。反之,如果出现了
这个序列。反之,如果出现了 
 令
令  那么在扔硬币的场景下,出现这样的序列平均至少需要扔
那么在扔硬币的场景下,出现这样的序列平均至少需要扔  次。对于一批大量的随机的
次。对于一批大量的随机的  意味着不重复的元素估计有
意味着不重复的元素估计有 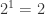 个;
个; 意味着不重复的元素估计有
意味着不重复的元素估计有  个;
个; 意味着不重复的元素估计有
意味着不重复的元素估计有  个;
个;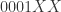 意味着不重复的元素估计有
意味着不重复的元素估计有  个。
个。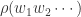 来表示
来表示 

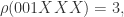

 的最大值,就可以预估出整体的数量。i.e.
的最大值,就可以预估出整体的数量。i.e.  整体的数量预估是
整体的数量预估是 

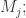 于是就可以对
于是就可以对  进行均值处理,可以使用以下方法:
进行均值处理,可以使用以下方法: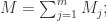
![M=\sqrt[m]{M_{1}\cdots M_{m}};](https://s0.wp.com/latex.php?latex=M%3D%5Csqrt%5Bm%5D%7BM_%7B1%7D%5Ccdots+M_%7Bm%7D%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

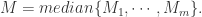
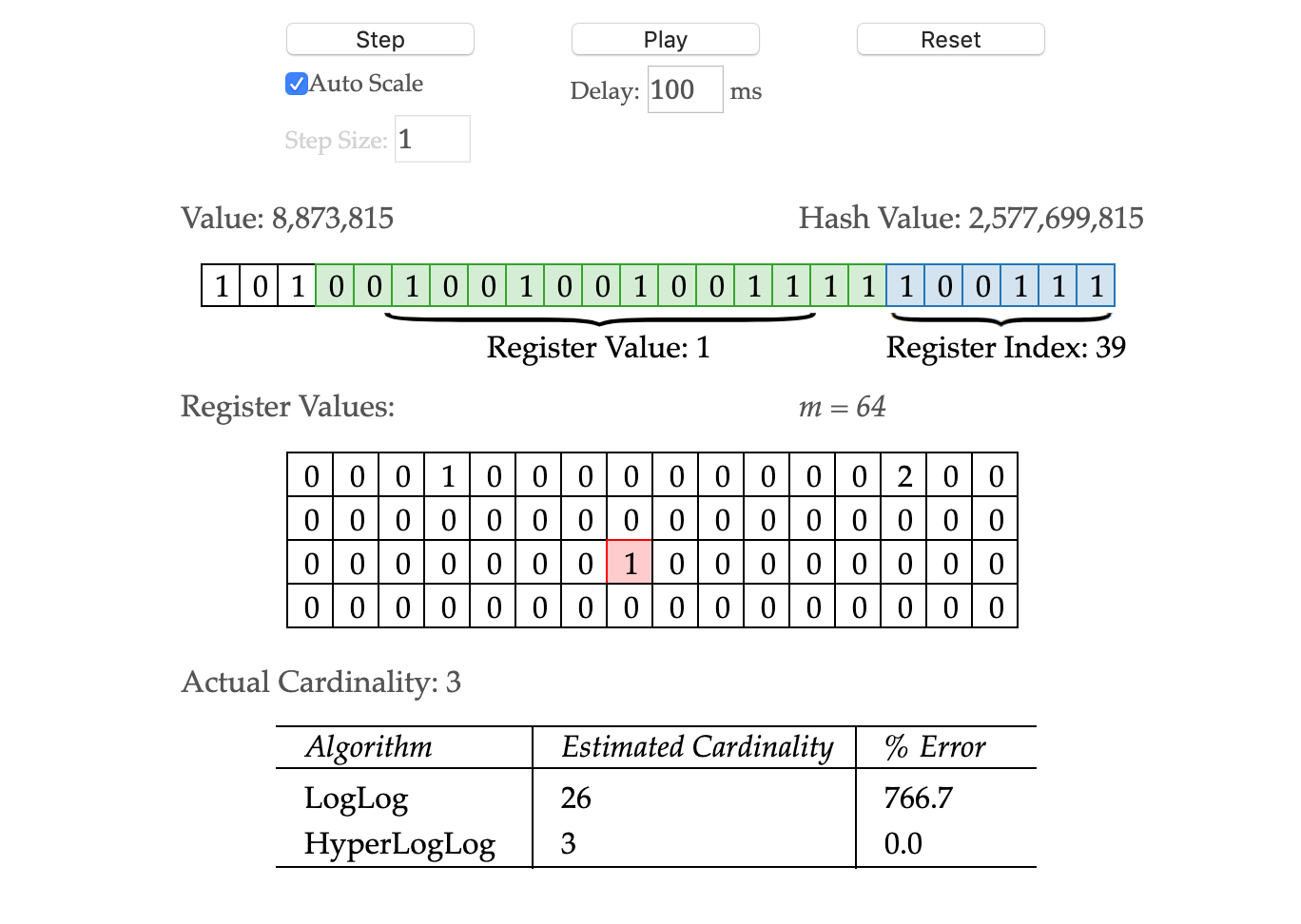
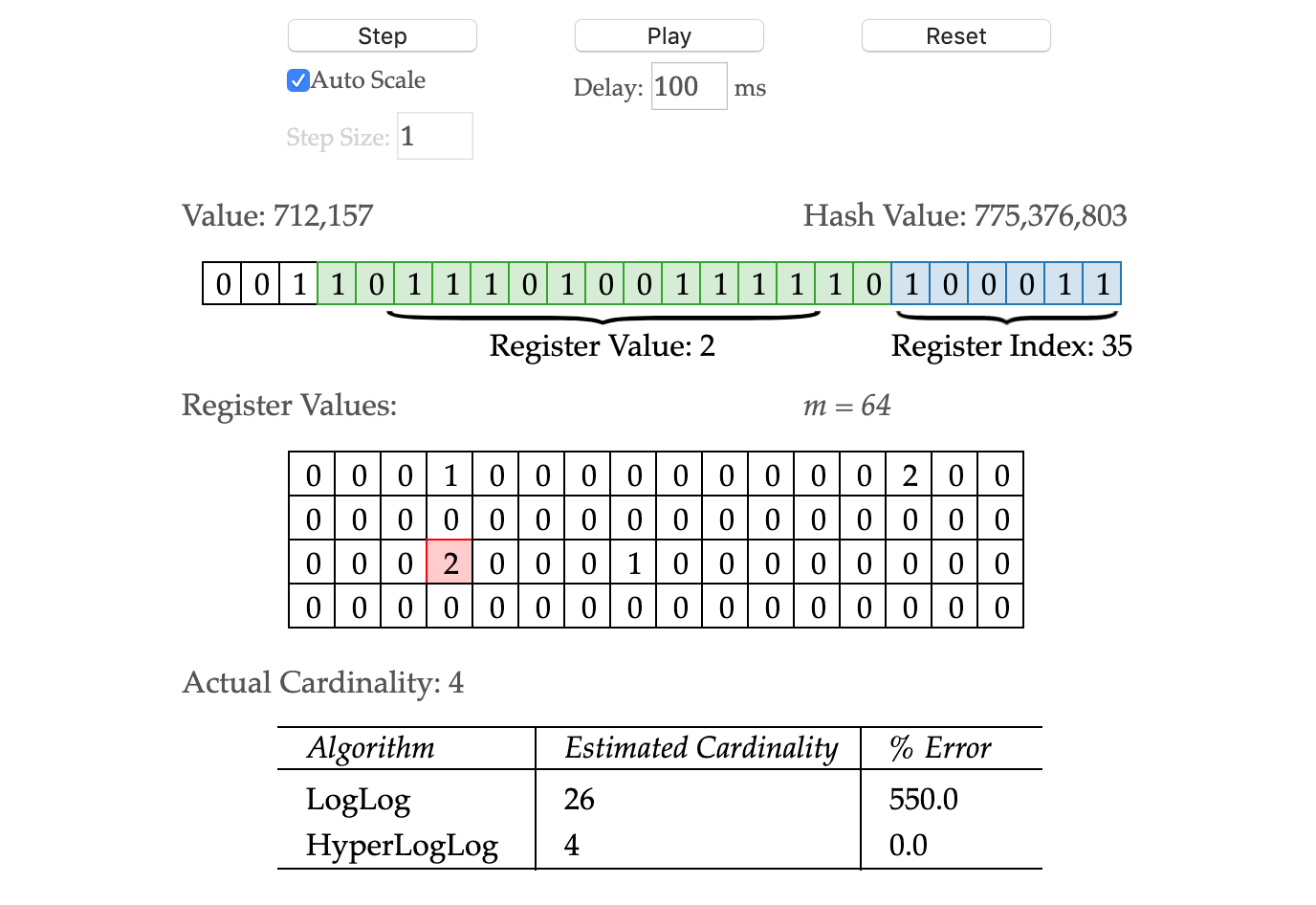
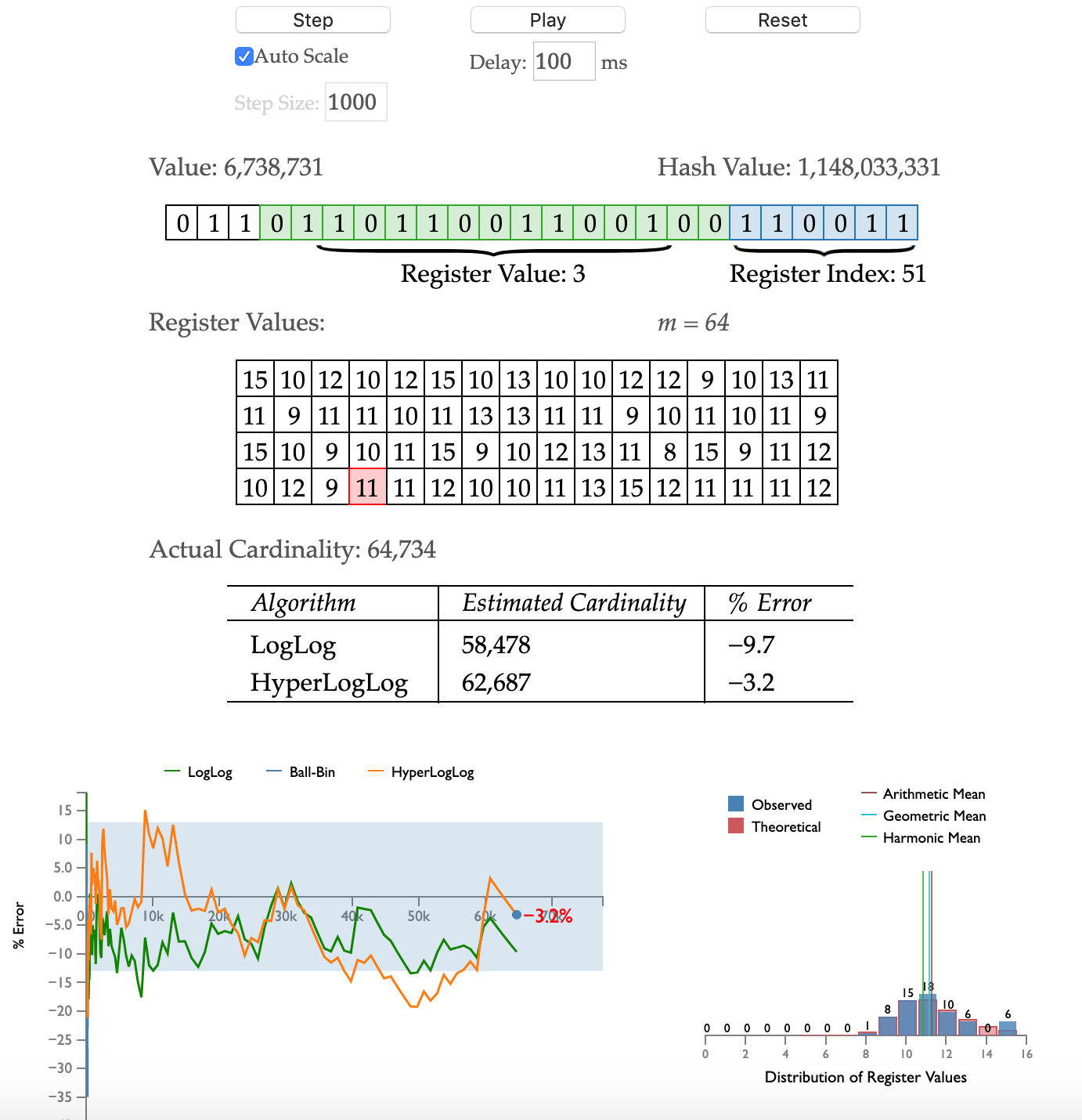
 HyperLogLog 从某个位置
HyperLogLog 从某个位置 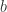 开始,低位
开始,低位  用于决定桶的序号,也就是第几个桶。桶的个数就是
用于决定桶的序号,也就是第几个桶。桶的个数就是  高位
高位  用于估算放在桶里面的元素个数。
用于估算放在桶里面的元素个数。 预估元素个数
预估元素个数 
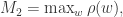 预估元素个数
预估元素个数 
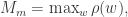 预估元素个数
预估元素个数 
 来估算桶里面的元素个数,那么在有
来估算桶里面的元素个数,那么在有 

 当
当  的时候,
的时候, 是发散的;当
是发散的;当 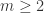 的时候,
的时候, 是收敛的。因此,在使用这个算法的时候最好放入
是收敛的。因此,在使用这个算法的时候最好放入  中的每一个元素
中的每一个元素  可以通过 hash 函数转换成一个
可以通过 hash 函数转换成一个 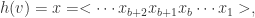 其中
其中  表示二进制中的最低位,
表示二进制中的最低位,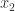 表示次低位。
表示次低位。 来计算放在第
来计算放在第 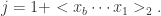 同时将
同时将  计算这批序列的
计算这批序列的  函数的最大值,然后记为
函数的最大值,然后记为 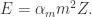
 这个量级的,其中
这个量级的,其中  二进制就是
二进制就是 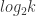 个 bit 就能够存储;
个 bit 就能够存储;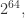 二进制就是
二进制就是  位,
位,


 此时的基数相对于桶的数量而言不算太多,因此可能存在多个空桶,需要进行调整。
此时的基数相对于桶的数量而言不算太多,因此可能存在多个空桶,需要进行调整。 是
是 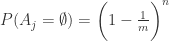 表示桶
表示桶  空的概率;
空的概率; 表示桶
表示桶  同时为空的概率(
同时为空的概率( );
); 当
当  充分大的时候,约为
充分大的时候,约为  个。
个。 那么可以更新为
那么可以更新为  事实上,可以通过
事实上,可以通过  解出
解出 
 那么更新为
那么更新为  其中
其中 
 的误差大约在
的误差大约在 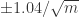 左右。
左右。 其实也可以用近似值来代替,毕竟如下公式的计算是有一定的成本的。
其实也可以用近似值来代替,毕竟如下公式的计算是有一定的成本的。
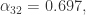
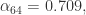
 当
当 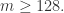

![\alpha_{m}\cdot m^{2}\cdot\bigg(\sum_{j=1}^{m}2^{-M[j]}\bigg)^{-1};](https://s0.wp.com/latex.php?latex=%5Calpha_%7Bm%7D%5Ccdot+m%5E%7B2%7D%5Ccdot%5Cbigg%28%5Csum_%7Bj%3D1%7D%5E%7Bm%7D2%5E%7B-M%5Bj%5D%7D%5Cbigg%29%5E%7B-1%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)



![£¨Í¼±í£©[Éç»á]2020Äê½Ú¼ÙÈշżٰ²ÅŹ«²¼](https://zr9558.com/wp-content/uploads/2020/05/2020e5b9b4e4b8ade59bbde88a82e58187e697a5e5ae89e68e92.jpg)
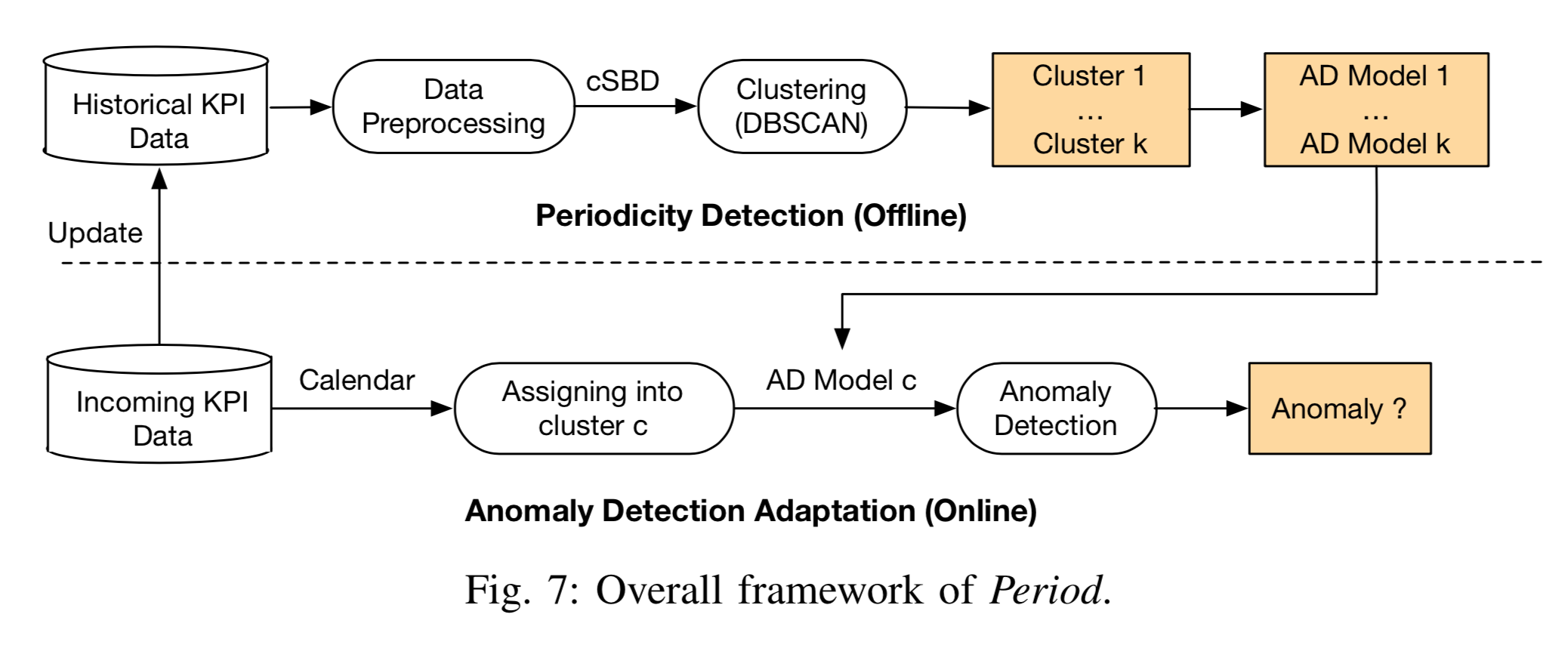
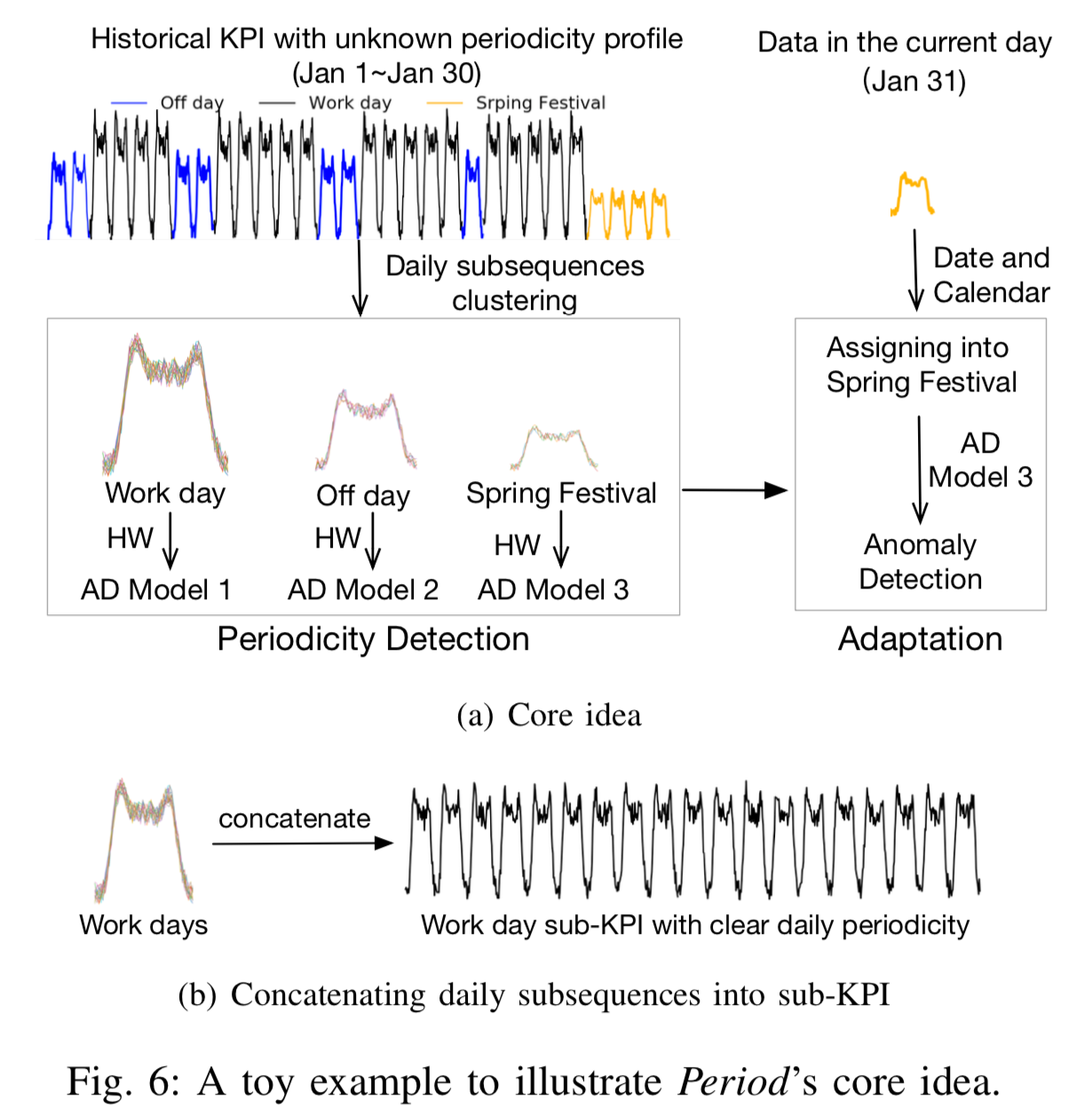
 和
和  ,提出了相似性的计算方法。
,提出了相似性的计算方法。
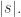 进一步可以定义,当
进一步可以定义,当 ![s\in[-w,w]\cap\mathbb{Z}](https://s0.wp.com/latex.php?latex=s%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 时,
时,
 归一化之后的最大值作为
归一化之后的最大值作为 ![NCC(X,Y)=\max_{s\in[-w,w]\cap\mathbb{Z}}\frac{CC_{s}(X,Y)}{\|x\|_{2}\cdot\|y\|}.](https://s0.wp.com/latex.php?latex=NCC%28X%2CY%29%3D%5Cmax_%7Bs%5Cin%5B-w%2Cw%5D%5Ccap%5Cmathbb%7BZ%7D%7D%5Cfrac%7BCC_%7Bs%7D%28X%2CY%29%7D%7B%5C%7Cx%5C%7C_%7B2%7D%5Ccdot%5C%7Cy%5C%7C%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

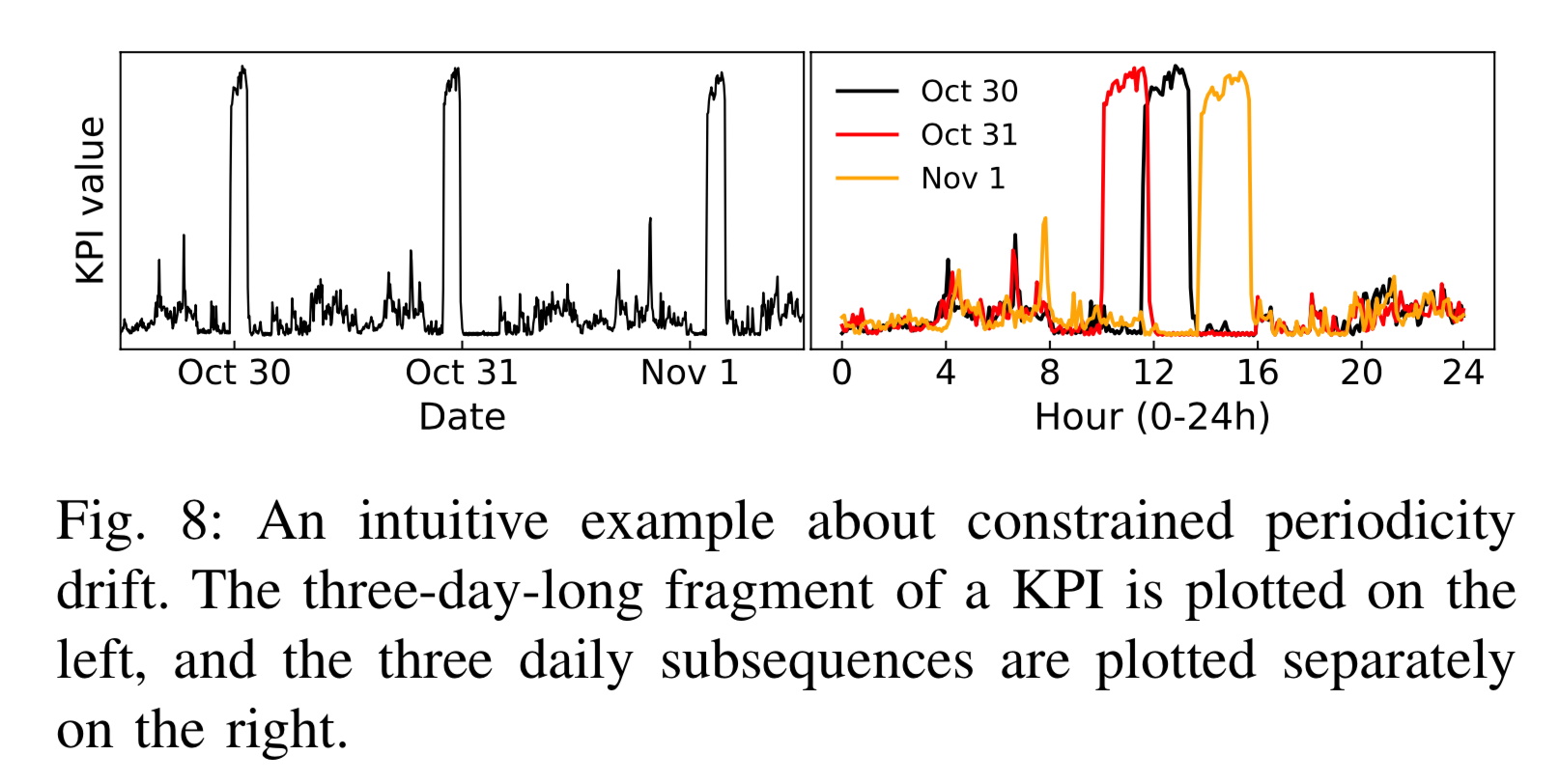
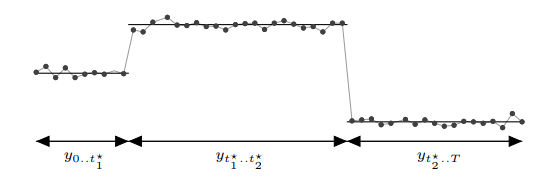
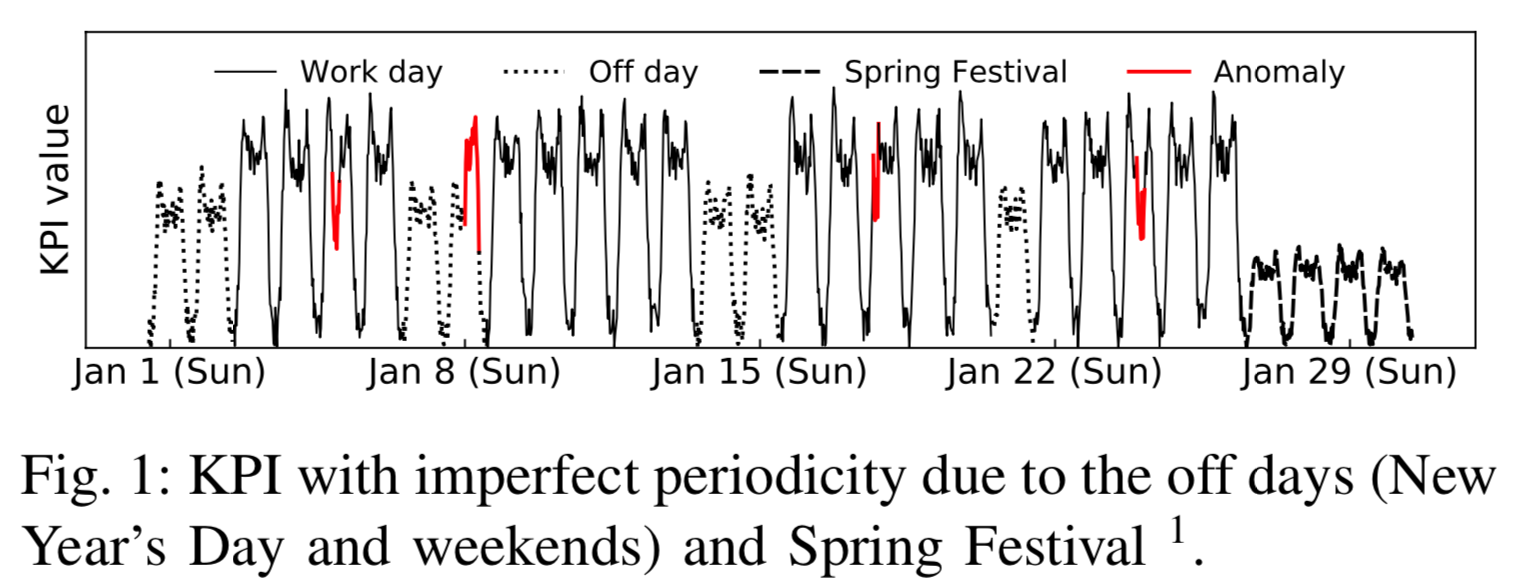
 呢,因为在一些实际的情况下,时间序列是会存在漂移的,例如上图所示。该时间序列在 10 月 30 日,31 日,11 月 1 日 都出现了一个凸起,但是如果考虑它的同比图,其实是可以清楚地看出该时间序列就存在了漂移,也就是说并不是在一个固定的时间戳就会出现同样的凸起,而是间隔了一段时间。这就是为什么需要考虑
呢,因为在一些实际的情况下,时间序列是会存在漂移的,例如上图所示。该时间序列在 10 月 30 日,31 日,11 月 1 日 都出现了一个凸起,但是如果考虑它的同比图,其实是可以清楚地看出该时间序列就存在了漂移,也就是说并不是在一个固定的时间戳就会出现同样的凸起,而是间隔了一段时间。这就是为什么需要考虑 
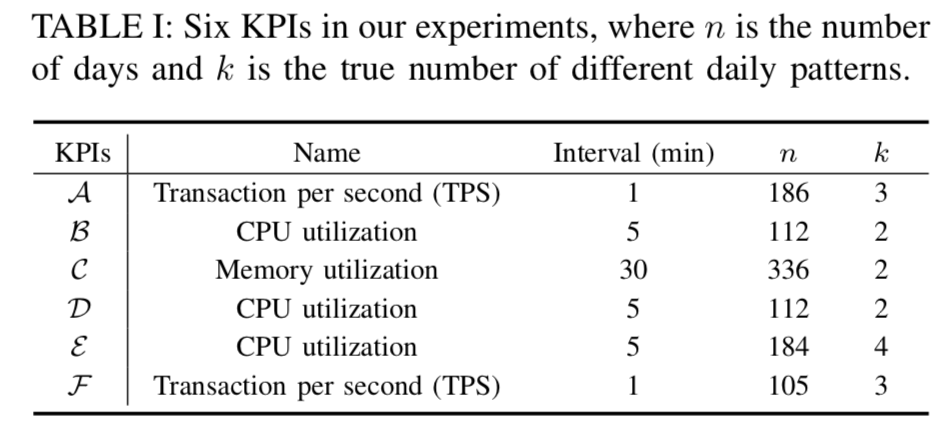
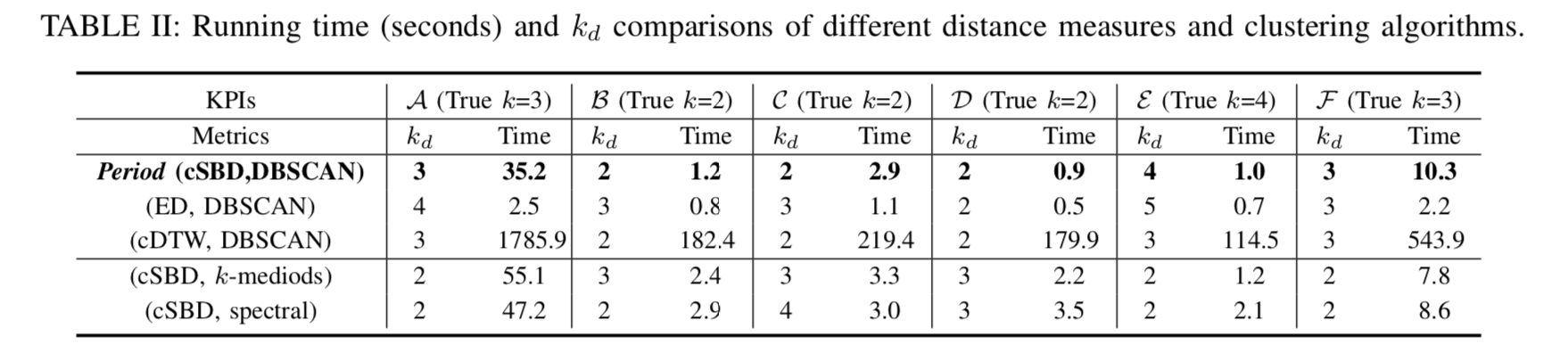
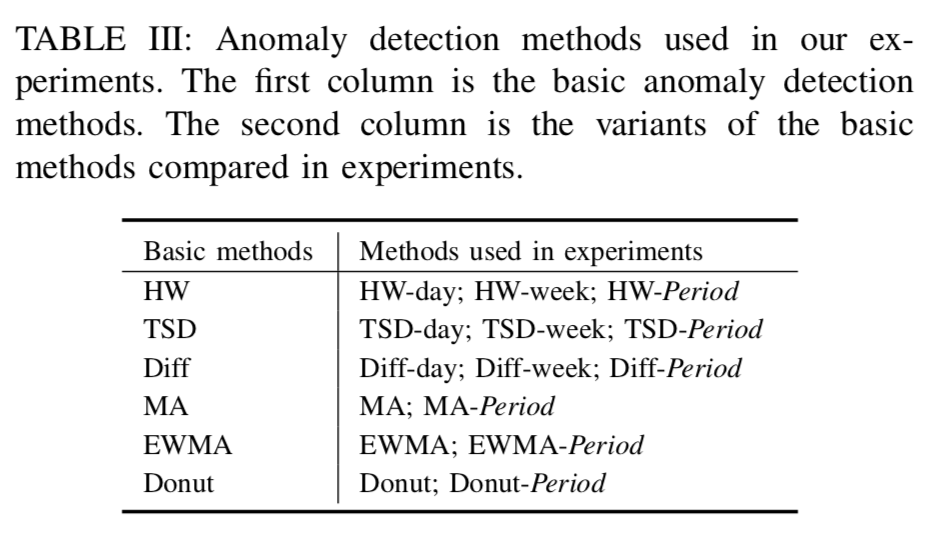
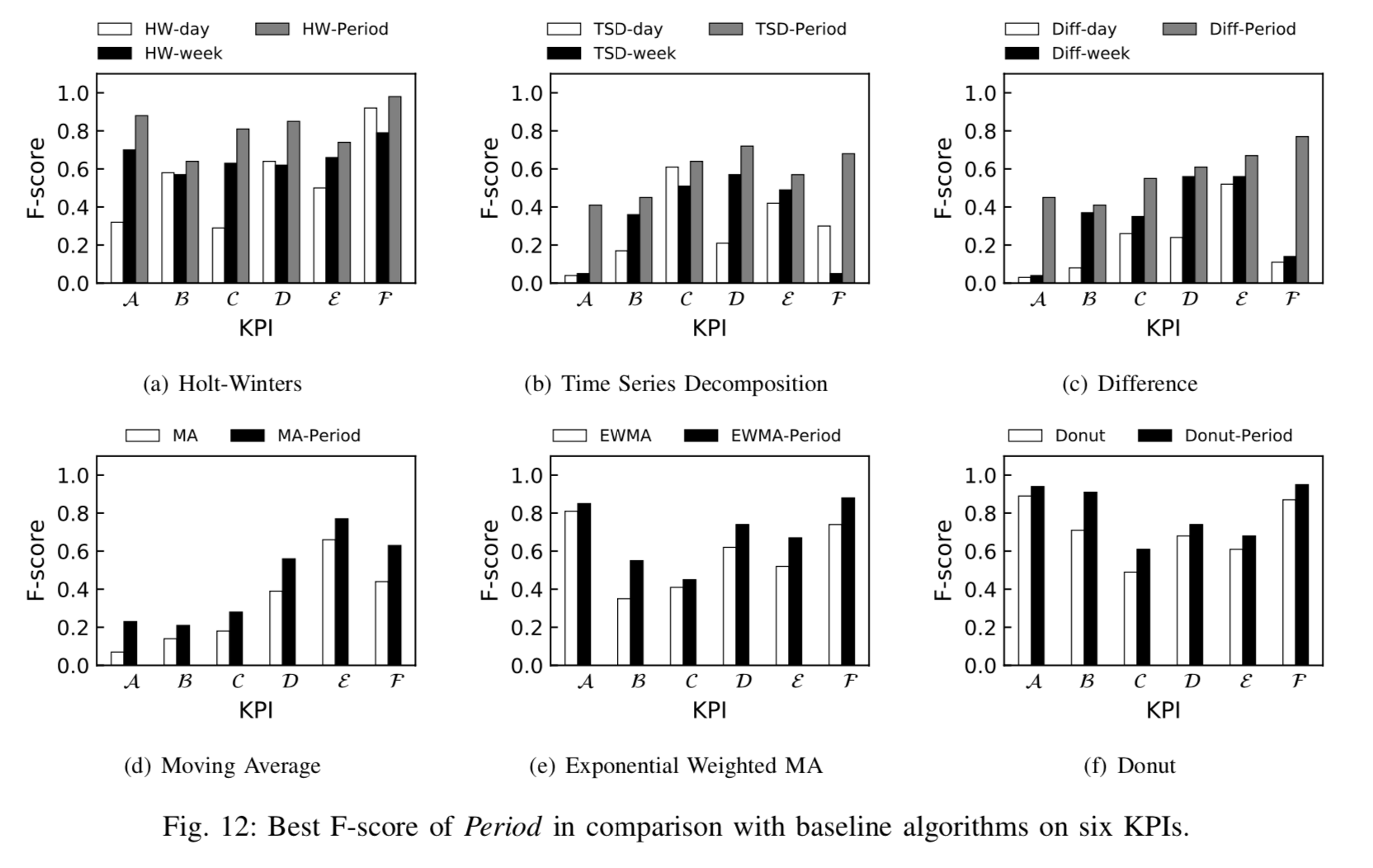
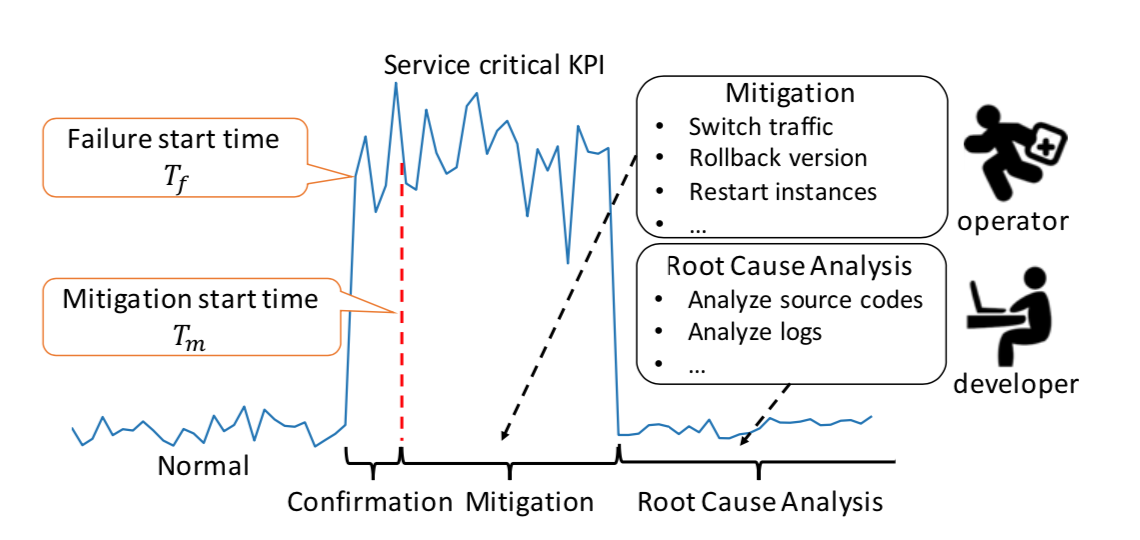
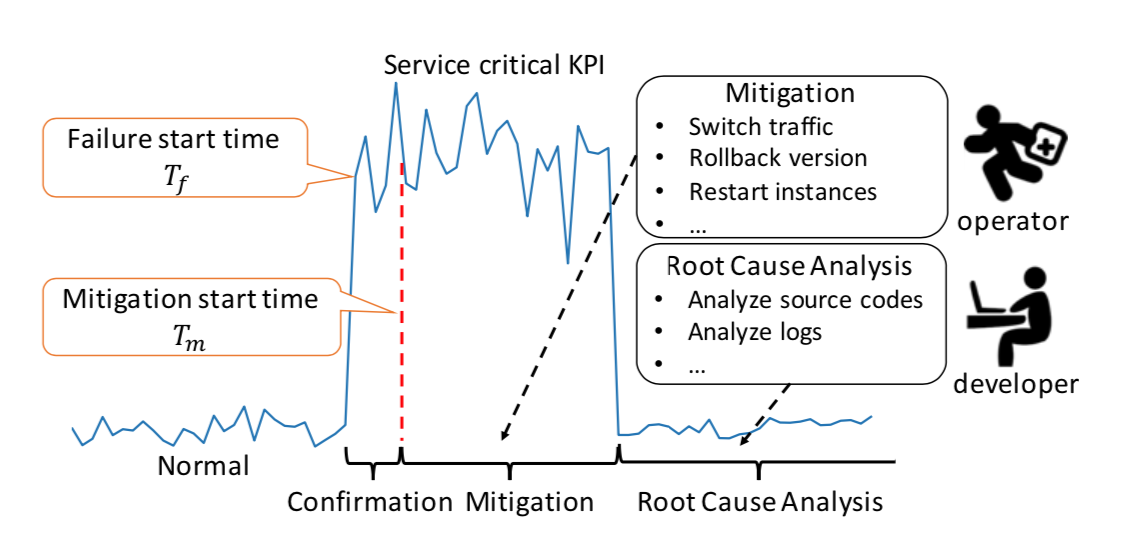
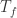 ,这个时间戳是运维领域非常重要的时间戳,它由异常检测(anomaly detection)产生,无论在告警收敛(alarm convergence)还是根因分析(root cause analysis)都非常依赖这个时间戳。而另外一个时间戳虽然没有故障开始时间那么重要,但是也有着其实用价值,那就是缓和开始时间(mitigation start time),它表示故障虽然还没有恢复,但是出于稍微平稳的走势,并没有持续恶化。在出现了故障之后,通常都会发送相应的告警给运维人员,那么在发送告警的时候,如果将异常定位的结果随之带出,则会大大减少运维人员排障的时间。在故障缓和的时间内,运维人员通常需要进行必要的操作来排查故障,例如切换流量(switch Traffic),回滚版本(Rollback Version),重启实例(Restart Instances),下线机器等操作。除此之外,为了定位问题(Root Cause Analysis),运维人员需要分析源码(Code Analysis),查看日志(Log Analysis)等一系列操作。如果能够将这一系列操作融入相应的机器学习模块中,将会节省运维人员大量的排障时间。
,这个时间戳是运维领域非常重要的时间戳,它由异常检测(anomaly detection)产生,无论在告警收敛(alarm convergence)还是根因分析(root cause analysis)都非常依赖这个时间戳。而另外一个时间戳虽然没有故障开始时间那么重要,但是也有着其实用价值,那就是缓和开始时间(mitigation start time),它表示故障虽然还没有恢复,但是出于稍微平稳的走势,并没有持续恶化。在出现了故障之后,通常都会发送相应的告警给运维人员,那么在发送告警的时候,如果将异常定位的结果随之带出,则会大大减少运维人员排障的时间。在故障缓和的时间内,运维人员通常需要进行必要的操作来排查故障,例如切换流量(switch Traffic),回滚版本(Rollback Version),重启实例(Restart Instances),下线机器等操作。除此之外,为了定位问题(Root Cause Analysis),运维人员需要分析源码(Code Analysis),查看日志(Log Analysis)等一系列操作。如果能够将这一系列操作融入相应的机器学习模块中,将会节省运维人员大量的排障时间。
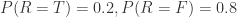 。
。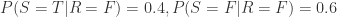 ,
, 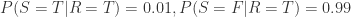 。
。 ,
,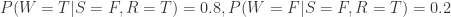 ,
, ,
,
 。从 Bayes 公式可以得到:
。从 Bayes 公式可以得到: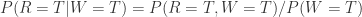 。分别计算分子分母即可:
。分别计算分子分母即可:

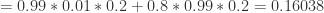 ,
,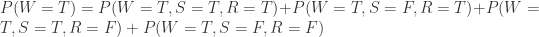
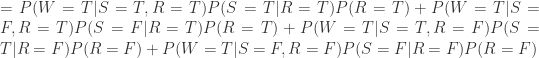

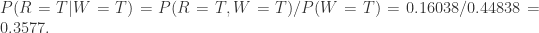
 。在失败开始时间
。在失败开始时间 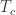 小于或者等于
小于或者等于  即可。关键时间点的排序为
即可。关键时间点的排序为  。
。![X=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 而言,MAD 定义为
而言,MAD 定义为  ,而每个点的异常程度可以定义为:
,而每个点的异常程度可以定义为: 当
当 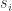 较大或者较小的时候,表示上涨或者下降的异常程度。通过设置相应的阈值,同样可以获得时间序列的异常开始时间。
较大或者较小的时候,表示上涨或者下降的异常程度。通过设置相应的阈值,同样可以获得时间序列的异常开始时间。![X=[x_{1},x_{2},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,可以预估它的目标值(target value)
,可以预估它的目标值(target value)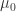 ,通常可以用均值来估计,也需要计算出这条时间序列的标准差
,通常可以用均值来估计,也需要计算出这条时间序列的标准差  ,
, 。而 Tabular CUSUM 指的是迭代公式
。而 Tabular CUSUM 指的是迭代公式 ![C_{i}^{+}=\max[0,x_{i}-(\mu_{0}+K)+C_{i-1}^{+}]](https://s0.wp.com/latex.php?latex=C_%7Bi%7D%5E%7B%2B%7D%3D%5Cmax%5B0%2Cx_%7Bi%7D-%28%5Cmu_%7B0%7D%2BK%29%2BC_%7Bi-1%7D%5E%7B%2B%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,![C_{i}^{-}=\max[0,(\mu_{0}-K)-x_{i}+C_{i-1}^{-}]](https://s0.wp.com/latex.php?latex=C_%7Bi%7D%5E%7B-%7D%3D%5Cmax%5B0%2C%28%5Cmu_%7B0%7D-K%29-x_%7Bi%7D%2BC_%7Bi-1%7D%5E%7B-%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,初始值是
,初始值是  。当累计偏差
。当累计偏差  或者
或者  大于
大于  的时候,表示
的时候,表示  出现了异常,也就是 out of control。通过这个值,可以获得时间序列开始异常的时间。
出现了异常,也就是 out of control。通过这个值,可以获得时间序列开始异常的时间。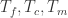 等时间戳。根据变化开始时间(change start time)
等时间戳。根据变化开始时间(change start time) ,例如 60 分钟(1 小时)。可以从两个时间段获取数据,正常时间段
,例如 60 分钟(1 小时)。可以从两个时间段获取数据,正常时间段  ,异常时间段
,异常时间段 ![[T_{c},T_{m}]](https://s0.wp.com/latex.php?latex=%5BT_%7Bc%7D%2CT_%7Bm%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,分别获取到数据
,分别获取到数据  和
和  ,前者是在变化开始时间之前的数据点,后者是在变化开始之后的数据点。于是,作者们通过概率值来计算变化程度
,前者是在变化开始时间之前的数据点,后者是在变化开始之后的数据点。于是,作者们通过概率值来计算变化程度  ,意思就是计算一个条件概率,在观察到
,意思就是计算一个条件概率,在观察到  ,在这里
,在这里 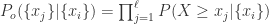 ,
,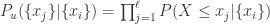 ,
,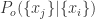 表示上涨的程度,
表示上涨的程度,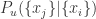 表示下降的程度。如果不想处理连乘的话,则需要处理连加:
表示下降的程度。如果不想处理连乘的话,则需要处理连加: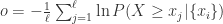 ,
, .
.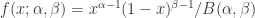 ,其中
,其中  。在机器 KPIs 中,CPU 等指标可以用 Beta 分布;
。在机器 KPIs 中,CPU 等指标可以用 Beta 分布; ,在机器 KPIs 中,SYS_OOM 用于衡量超出内存的频率,可以用泊松分布来做。
,在机器 KPIs 中,SYS_OOM 用于衡量超出内存的频率,可以用泊松分布来做。 。
。
 和
和  。
。![Y=[y_{1},\cdots,y_{n}]](https://s0.wp.com/latex.php?latex=Y%3D%5By_%7B1%7D%2C%5Ccdots%2Cy_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
, 其中
其中 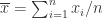 ,
,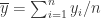 。
。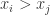 且
且  ) 或者 (
) 或者 ( 且
且  ),那么称之为 concordant;如果 (
),那么称之为 concordant;如果 ( 或者
或者  ,则既不是 concordant,也不是 discordant。那么 Kendall tau 定义为
,则既不是 concordant,也不是 discordant。那么 Kendall tau 定义为 ![[\text{(number of concordant pairs)}-\text{(number of disordant paris)}] / [n(n-1)/2]](https://s0.wp.com/latex.php?latex=%5B%5Ctext%7B%28number+of+concordant+pairs%29%7D-%5Ctext%7B%28number+of+disordant+paris%29%7D%5D+%2F+%5Bn%28n-1%29%2F2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 ,后者表示
,后者表示 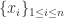 的位置,称之为秩次(rank),得到序列
的位置,称之为秩次(rank),得到序列 ![X'=[x_{1}',\cdots,x_{n}']](https://s0.wp.com/latex.php?latex=X%27%3D%5Bx_%7B1%7D%27%2C%5Ccdots%2Cx_%7Bn%7D%27%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。对原始序列
。对原始序列 ![Y'=[y_{1}',\cdots,y_{n}']](https://s0.wp.com/latex.php?latex=Y%27%3D%5By_%7B1%7D%27%2C%5Ccdots%2Cy_%7Bn%7D%27%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。一个相同的值在一列数据中必须有相同的秩次,那么在计算中采用的秩次就是数值在按从大到小排列时所在位置的平均值。如果没有相同的 rank,那么使用公式
。一个相同的值在一列数据中必须有相同的秩次,那么在计算中采用的秩次就是数值在按从大到小排列时所在位置的平均值。如果没有相同的 rank,那么使用公式 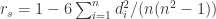 进行计算,其中
进行计算,其中  ;如果存在相同的秩次,则对
;如果存在相同的秩次,则对  。
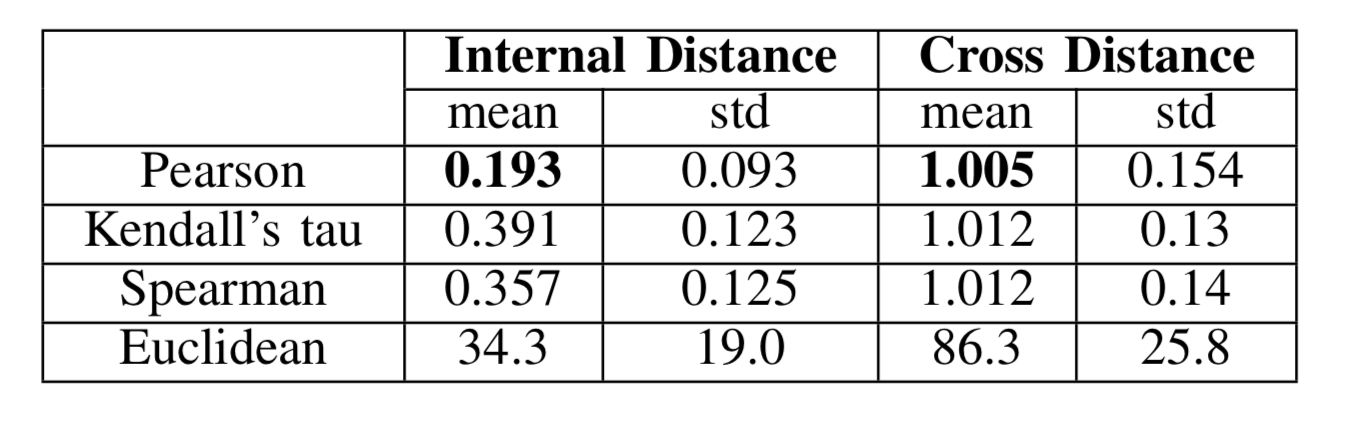
。
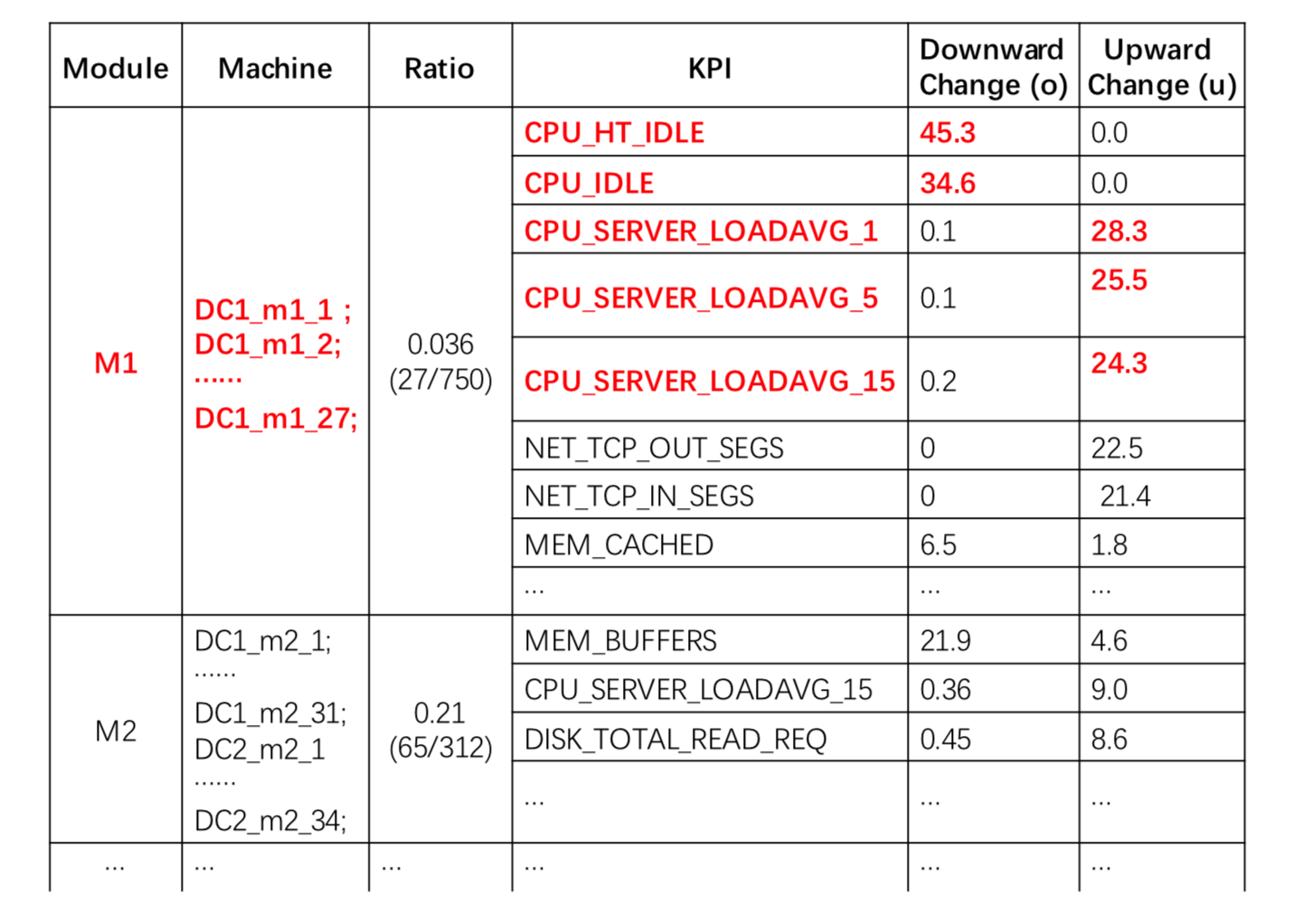

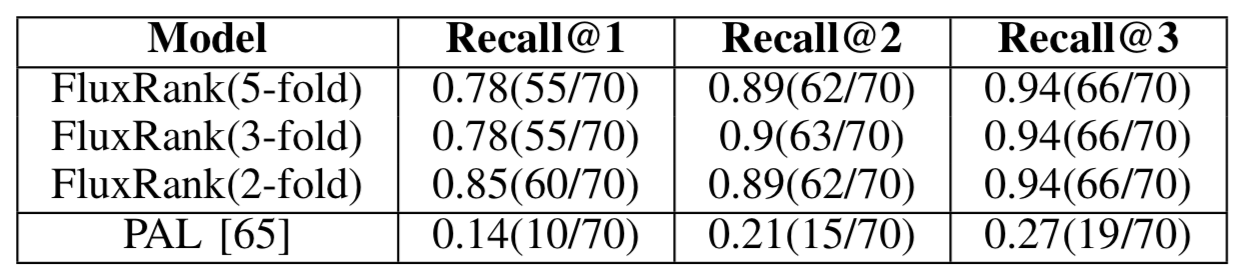
 或者
或者 


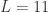 表示叶子节点的值只有 11 个,分别是变量
表示叶子节点的值只有 11 个,分别是变量  ;
; 表示一元计算只有 15 个,分别是
表示一元计算只有 15 个,分别是  ,
, 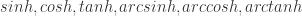 。
。 表示二元计算只有四个,分别是 +, -, *, /;
表示二元计算只有四个,分别是 +, -, *, /; 的表达式就可以作为深度学习的积分训练数据。生成积分的话其实有多种方法:
的表达式就可以作为深度学习的积分训练数据。生成积分的话其实有多种方法: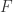 ,那么
,那么  就可以作为一个训练集。当然,有的时候函数
就可以作为一个训练集。当然,有的时候函数  ,于是
,于是  ,那么
,那么 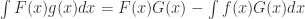 。对于两个随机生成的函数
。对于两个随机生成的函数 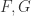 ,可以计算出它们的导数
,可以计算出它们的导数 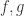 。如果
。如果 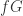 在训练集合里面,那么就把
在训练集合里面,那么就把  的积分计算出来放入训练集合;反之,如果
的积分计算出来放入训练集合;反之,如果 
 选择一个,于是随机把其中的一个整数换成变量
选择一个,于是随机把其中的一个整数换成变量  。例如:在
。例如:在  中就把 2 换成 c,于是得到了一个二元函数
中就把 2 换成 c,于是得到了一个二元函数  。那么就执行以下步骤:
。那么就执行以下步骤: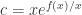 ;
;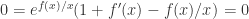 ;
;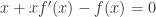 ,也就是
,也就是 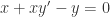 。
。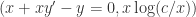 。
。 ;
; 得到
得到  ;
; ;
; 得到
得到  ;
; ;
; ,也就是
,也就是 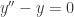 。
。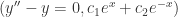 。
。 的表达式,该数据就需要放弃,重新生成新的数据。
的表达式,该数据就需要放弃,重新生成新的数据。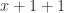 可以简化成
可以简化成 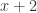 ,
, 可以简化成 1。
可以简化成 1。 可以简化成
可以简化成 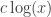 。
。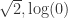 等。
等。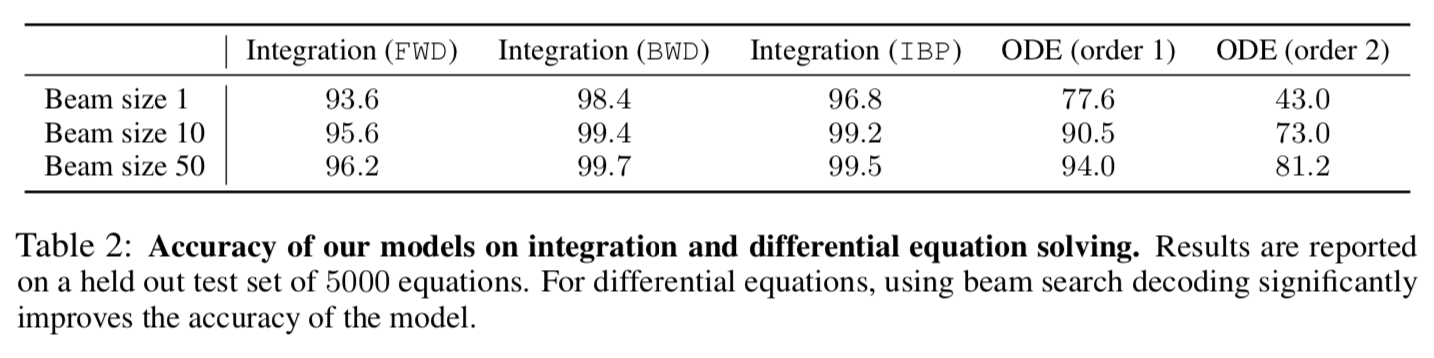




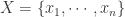

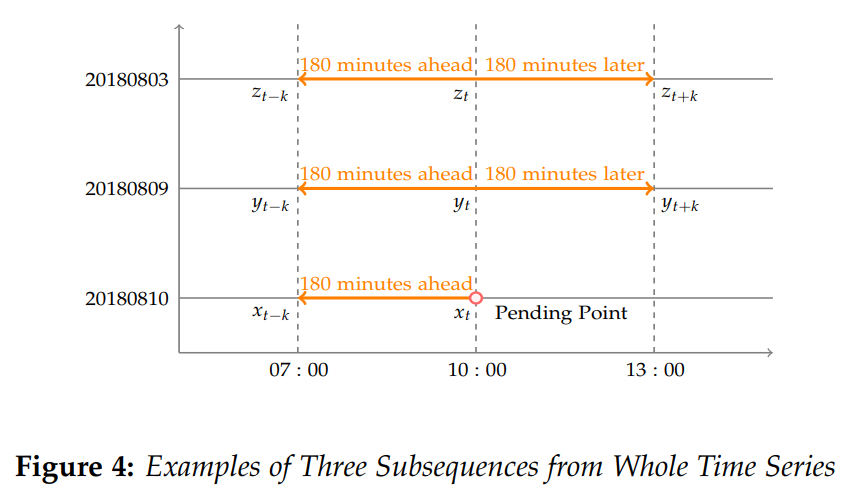
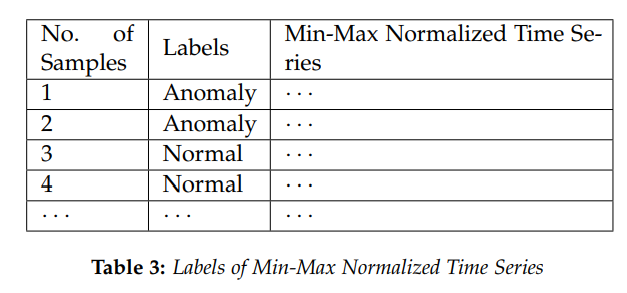
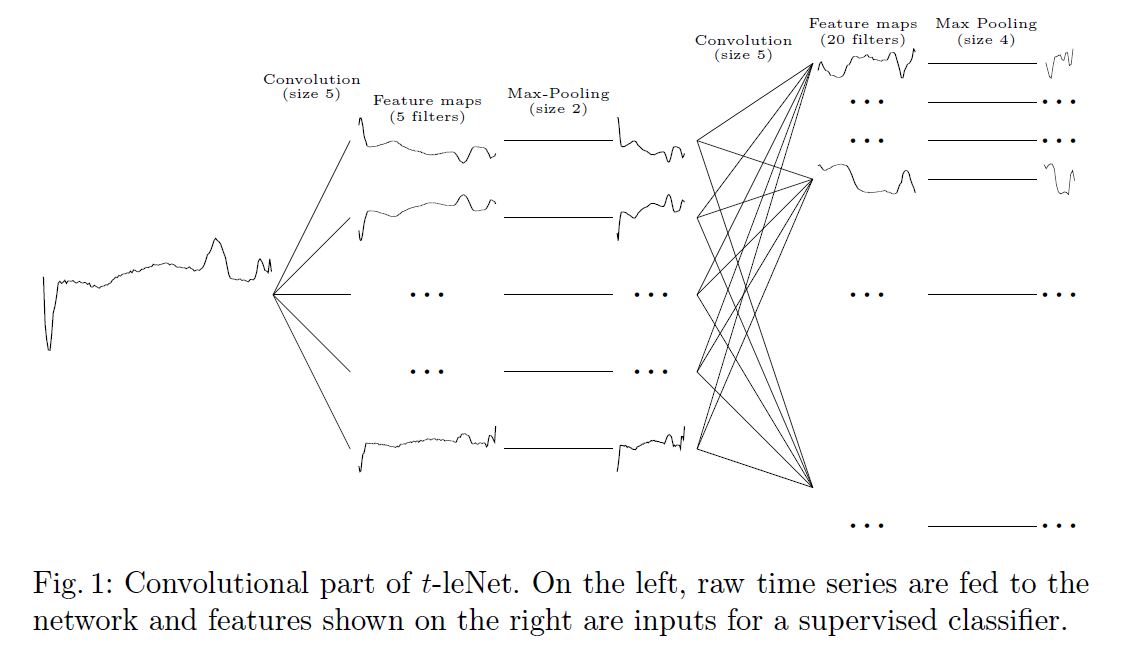
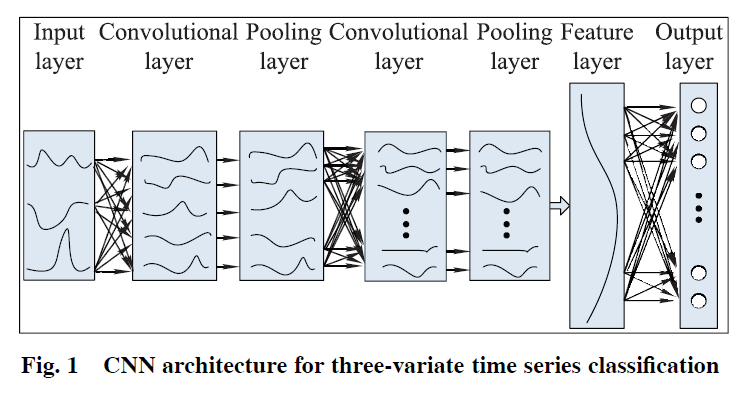
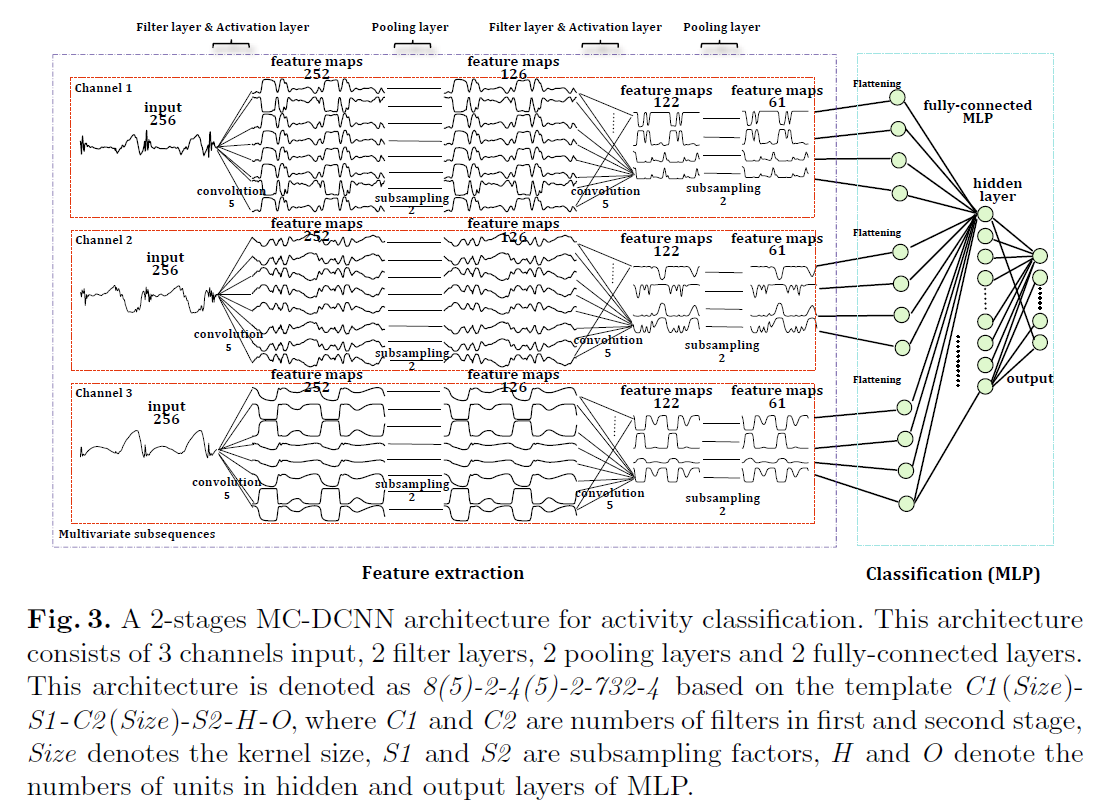
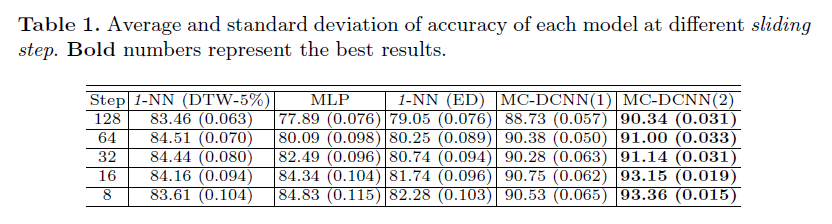
 而言,时间序列
而言,时间序列  的长度都是
的长度都是 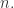 而时间序列的分类数据通常来说都是这种格式:数据集
而时间序列的分类数据通常来说都是这种格式:数据集
 是 one hot 编码,长度为
是 one hot 编码,长度为 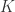 (表示有
(表示有 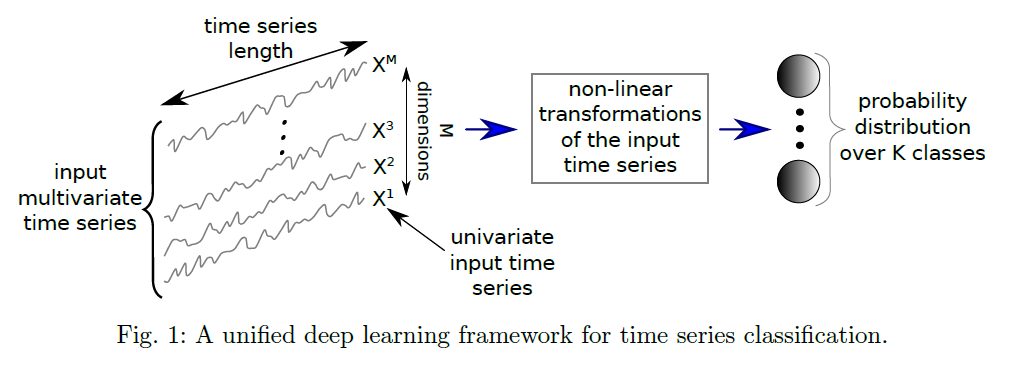
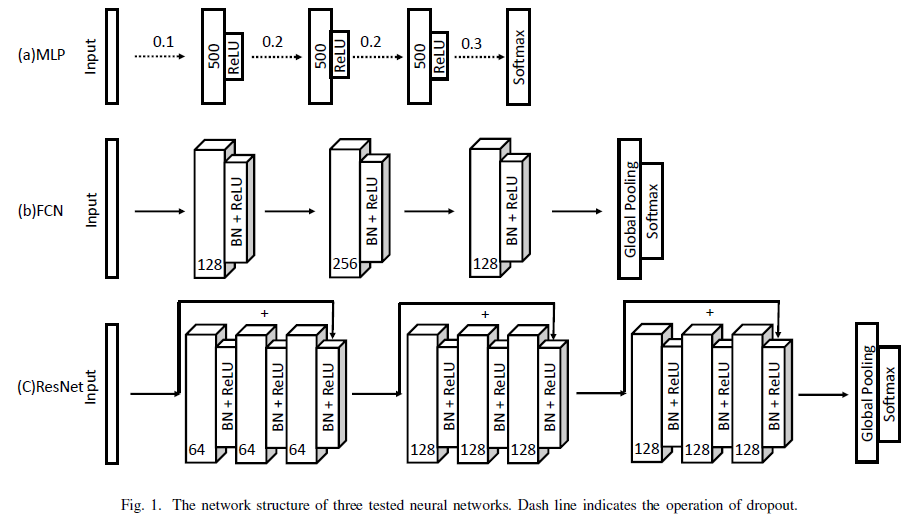
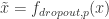 ,
, ,
, .
. ,
, ,
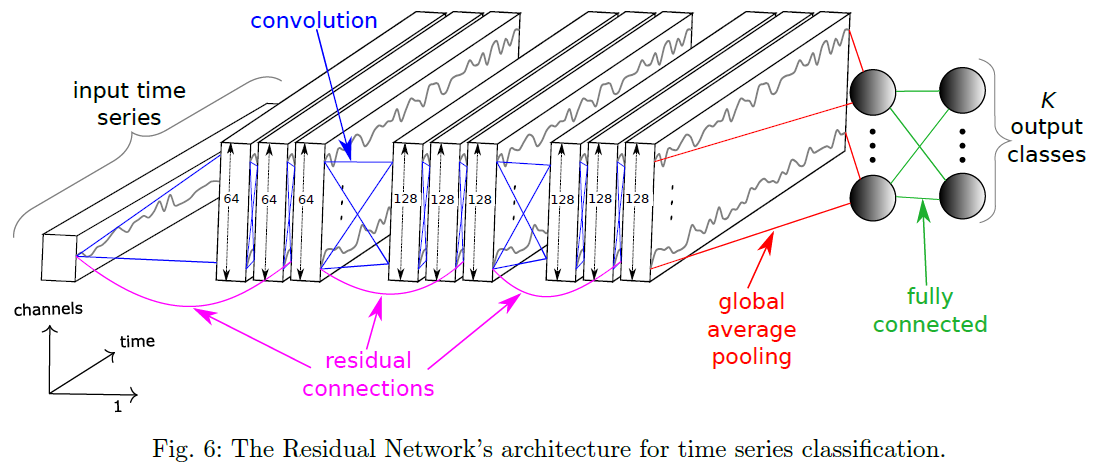
, ,
, 指的是卷积算子,BN 指的是 Batch Normalization,ReLU 则是激活函数。
指的是卷积算子,BN 指的是 Batch Normalization,ReLU 则是激活函数。 来表示第
来表示第 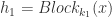 ,
,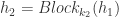 ,
, ,
,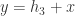 ,
, .
.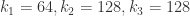 。
。
 是由
是由  ,通过模型其实可以计算出模型对每一个类的错误率
,通过模型其实可以计算出模型对每一个类的错误率 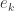 ,那么模型的 MPCE 就是:
,那么模型的 MPCE 就是: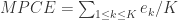 .
.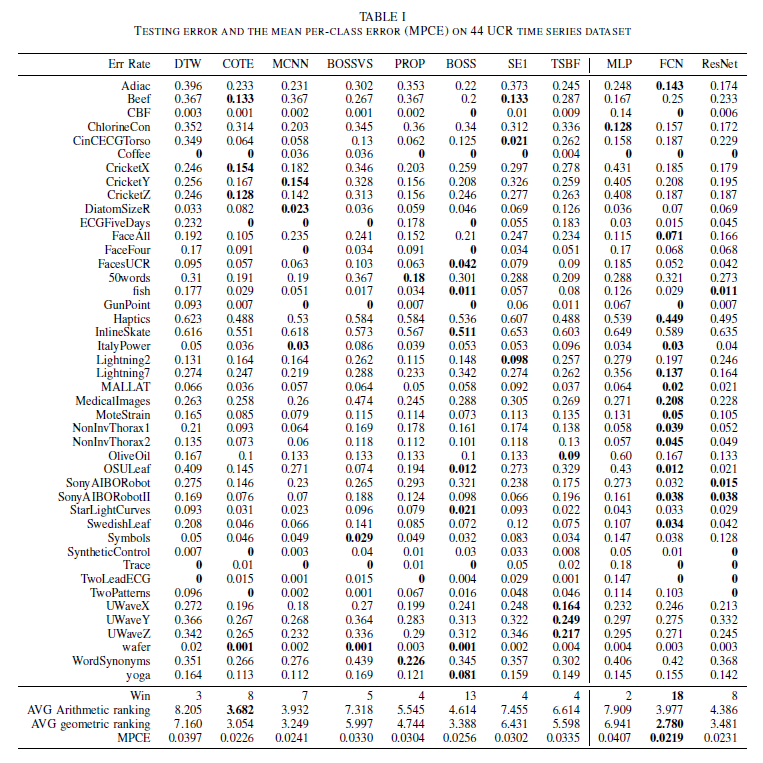
 ,其中
,其中  表示在时间戳
表示在时间戳  的长度是
的长度是  。其中
。其中 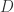 集合里面包含
集合里面包含 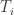 对应着一个标签
对应着一个标签 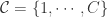 中的元素,
中的元素, 。
。
 ,
, 表示窗口长度。对于不同的窗口长度
表示窗口长度。对于不同的窗口长度 ![T^{k} = \{t_{1+k\cdot i}\}, 0\leq i \leq [(n-1)/k]](https://s0.wp.com/latex.php?latex=T%5E%7Bk%7D+%3D+%5C%7Bt_%7B1%2Bk%5Ccdot+i%7D%5C%7D%2C+0%5Cleq+i+%5Cleq+%5B%28n-1%29%2Fk%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) .
. 来进行下采样的时间序列提取。在进行了恒等变换,平滑变换,下采样之后,时间序列就可以变成多种形式,作为神经网络的输入。
来进行下采样的时间序列提取。在进行了恒等变换,平滑变换,下采样之后,时间序列就可以变成多种形式,作为神经网络的输入。 ,
, ,可以生成
,可以生成  个子序列如下所示:
个子序列如下所示: ,
,
 ,长度是
,长度是 ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) :
: ,
, ,
,![\tilde{x}_{0}^{i}\in[0,1], \forall 1\leq i\leq n](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7B0%7D%5E%7Bi%7D%5Cin%5B0%2C1%5D%2C+%5Cforall+1%5Cleq+i%5Cleq+n&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,![\tilde{x}_{-1}^{i} \in [-1,1],\forall 1\leq i\leq n](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7B-1%7D%5E%7Bi%7D+%5Cin+%5B-1%2C1%5D%2C%5Cforall+1%5Cleq+i%5Cleq+n&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。于是可以使用三角函数来代替归一化之后的值。下面通用
。于是可以使用三角函数来代替归一化之后的值。下面通用  来表示归一化之后的时间序列,令
来表示归一化之后的时间序列,令 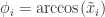 ,
,![\tilde{x}_{i} \in [-1,1]](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7Bi%7D+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,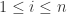 。因此,
。因此,![\phi_{i}\in[0,\pi]](https://s0.wp.com/latex.php?latex=%5Cphi_%7Bi%7D%5Cin%5B0%2C%5Cpi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,于是,
,于是,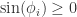 。
。![GASF = [\cos(\phi_{i}+\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=GASF+%3D+%5B%5Ccos%28%5Cphi_%7Bi%7D%2B%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![GASF = [\cos(\phi_{i})\cdot \cos(\phi_{j}) - \sin(\phi_{i})\cdot \sin(\phi_{j})]_{n\times n}](https://s0.wp.com/latex.php?latex=GASF+%3D+%5B%5Ccos%28%5Cphi_%7Bi%7D%29%5Ccdot+%5Ccos%28%5Cphi_%7Bj%7D%29+-+%5Csin%28%5Cphi_%7Bi%7D%29%5Ccdot+%5Csin%28%5Cphi_%7Bj%7D%29%5D_%7Bn%5Ctimes+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 ,可以得到
,可以得到
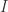 表示单位矩阵。它的对角矩阵是
表示单位矩阵。它的对角矩阵是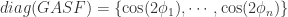

 ,可以得到
,可以得到  。
。![GADF = [\sin(\phi_{i}-\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=GADF+%3D+%5B%5Csin%28%5Cphi_%7Bi%7D-%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![= [\sin(\phi_{i})\cdot cos(\phi_{j}) - \cos(\phi_{i})\cdot\sin(\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=%3D+%5B%5Csin%28%5Cphi_%7Bi%7D%29%5Ccdot+cos%28%5Cphi_%7Bj%7D%29+-+%5Ccos%28%5Cphi_%7Bi%7D%29%5Ccdot%5Csin%28%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
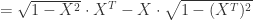 .
.
 ,我们把它们的值域分成
,我们把它们的值域分成 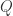 个桶,那么每一个
个桶,那么每一个  上。于是我们可以建立一个
上。于是我们可以建立一个  的矩阵
的矩阵  ,
, 表示在桶
表示在桶  ,同时,它也满足
,同时,它也满足  。于是,得到矩阵
。于是,得到矩阵  。
。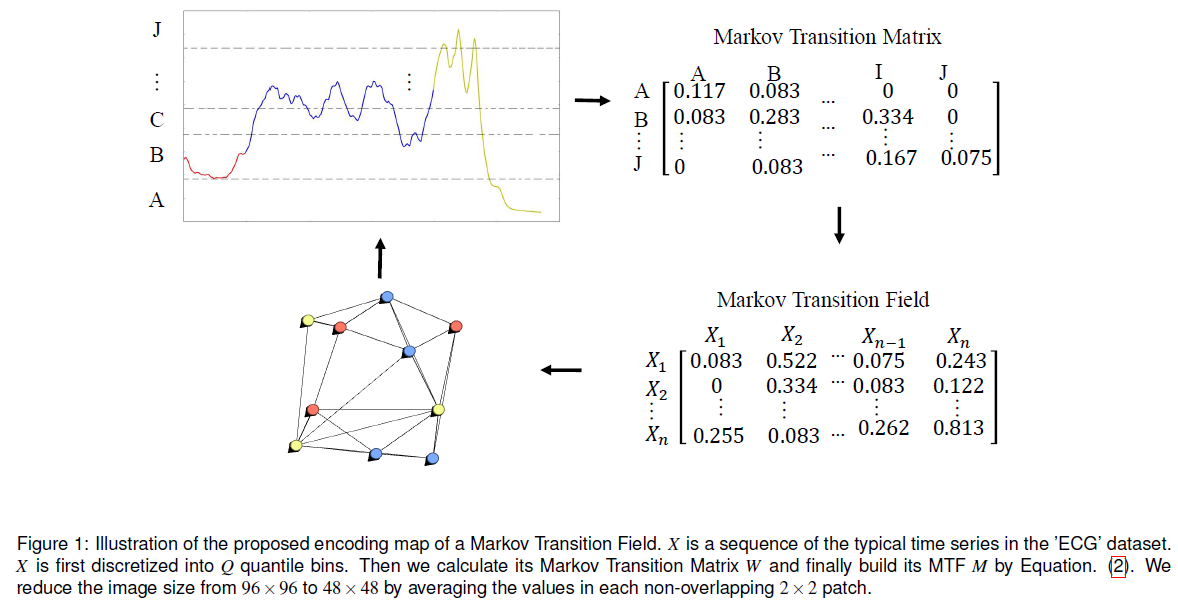
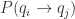 ,同样有
,同样有  。因此,我们同样可以构造出一个
。因此,我们同样可以构造出一个 

 就作为数据点
就作为数据点 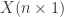 就可以变成特征矩阵
就可以变成特征矩阵  。对于特征矩阵
。对于特征矩阵 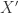 可以使用 isolation forest 来做无监督的异常检测并且做阈值的设定;如下图所示:
可以使用 isolation forest 来做无监督的异常检测并且做阈值的设定;如下图所示: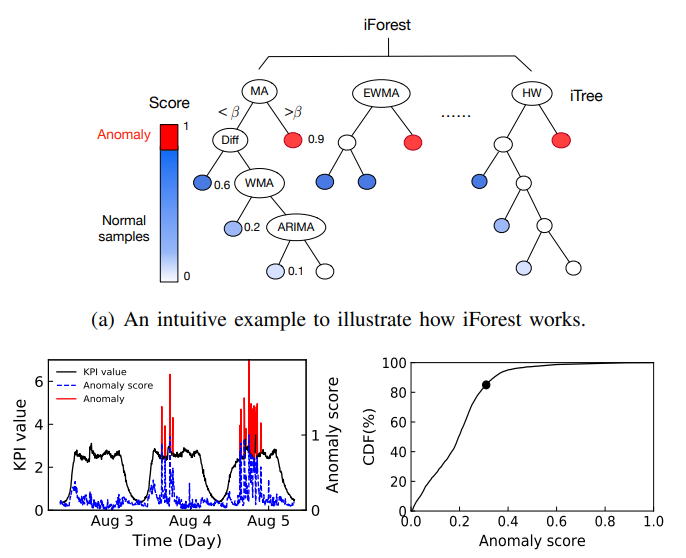
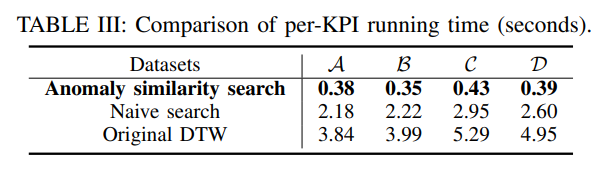
 ,因此在搜索的时候需要必要的加速工作。在这种地方,作者们使用了 LB-Kim,LB-Keogh,LB-Keogh-Reverse 算法来做搜索的加速工作。而这些的时间复杂度是
,因此在搜索的时候需要必要的加速工作。在这种地方,作者们使用了 LB-Kim,LB-Keogh,LB-Keogh-Reverse 算法来做搜索的加速工作。而这些的时间复杂度是  。整体的思路是,如果两条时间序列
。整体的思路是,如果两条时间序列 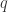 和
和 
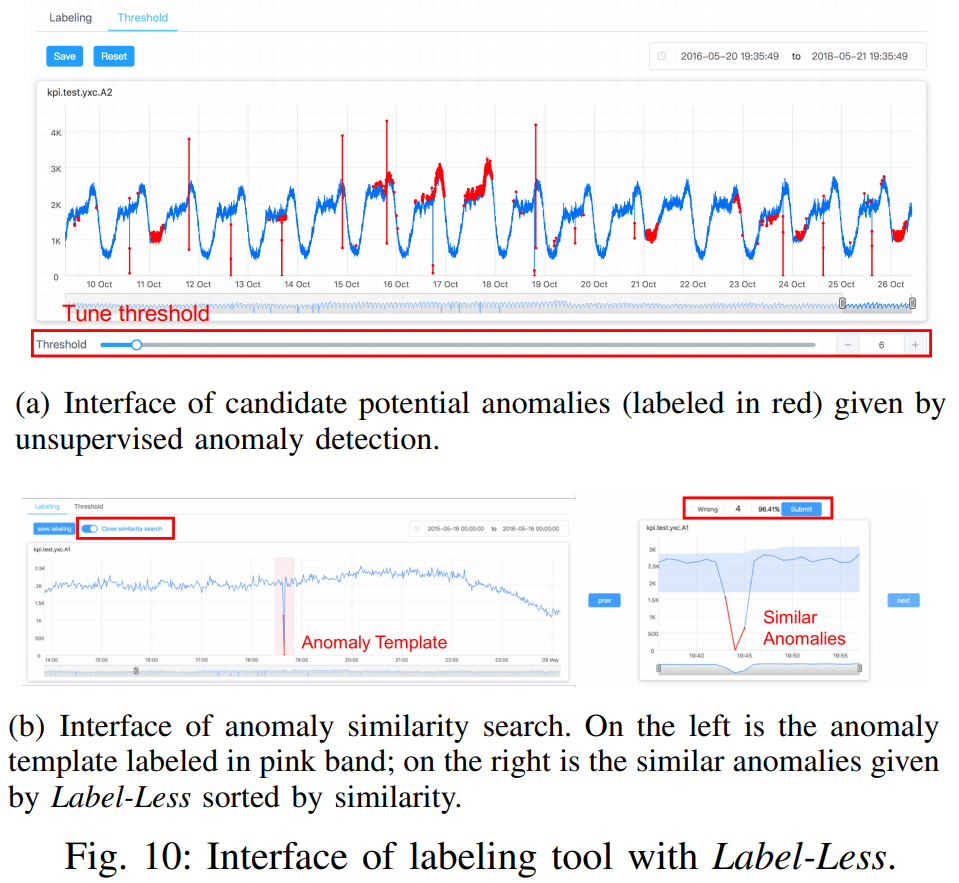
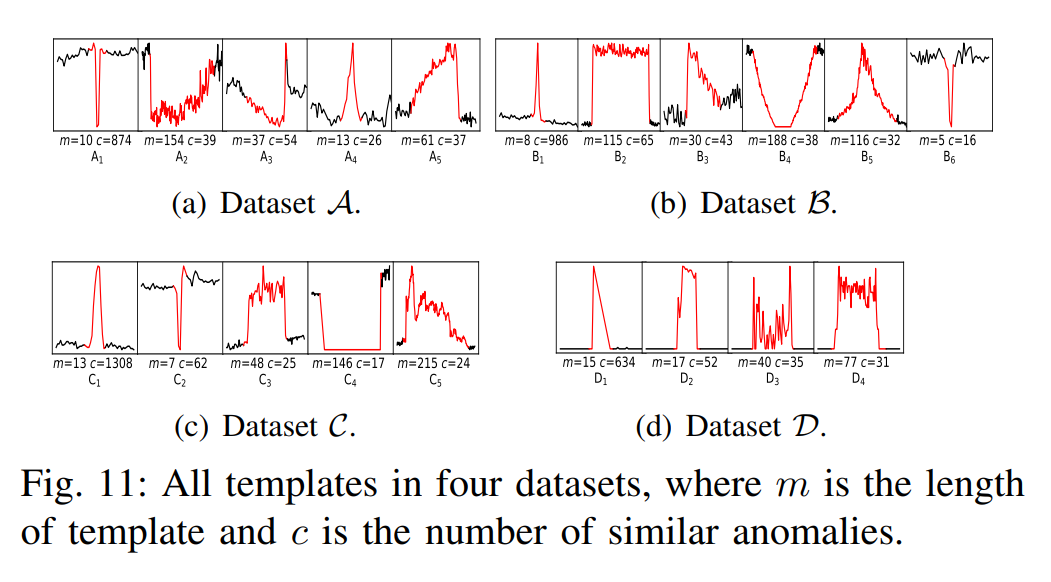
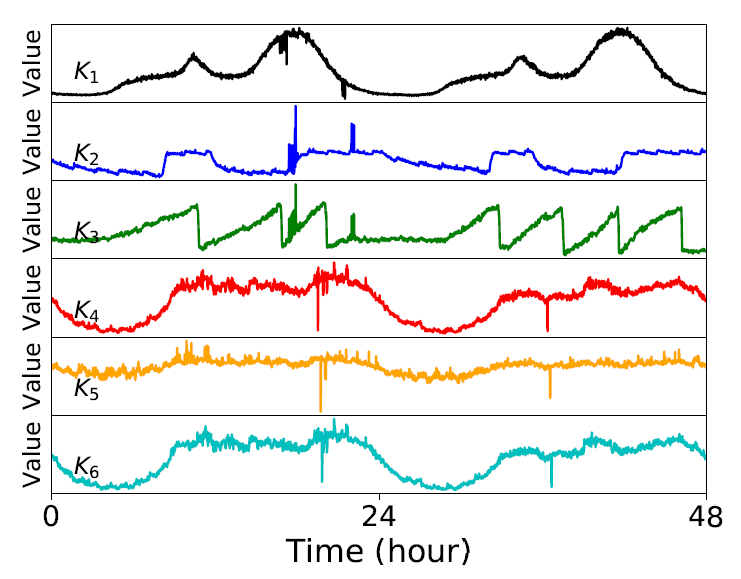
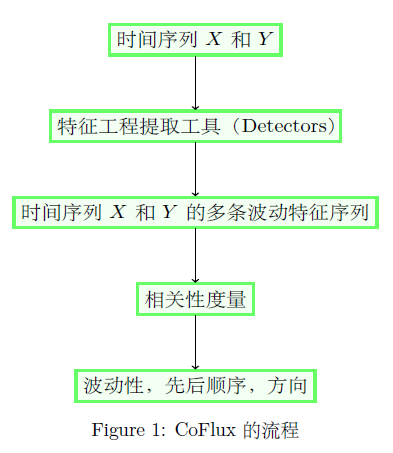

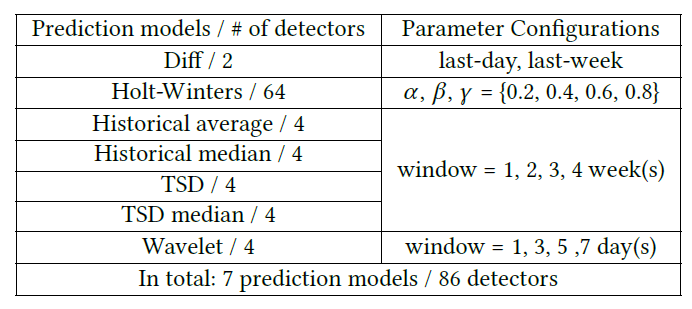
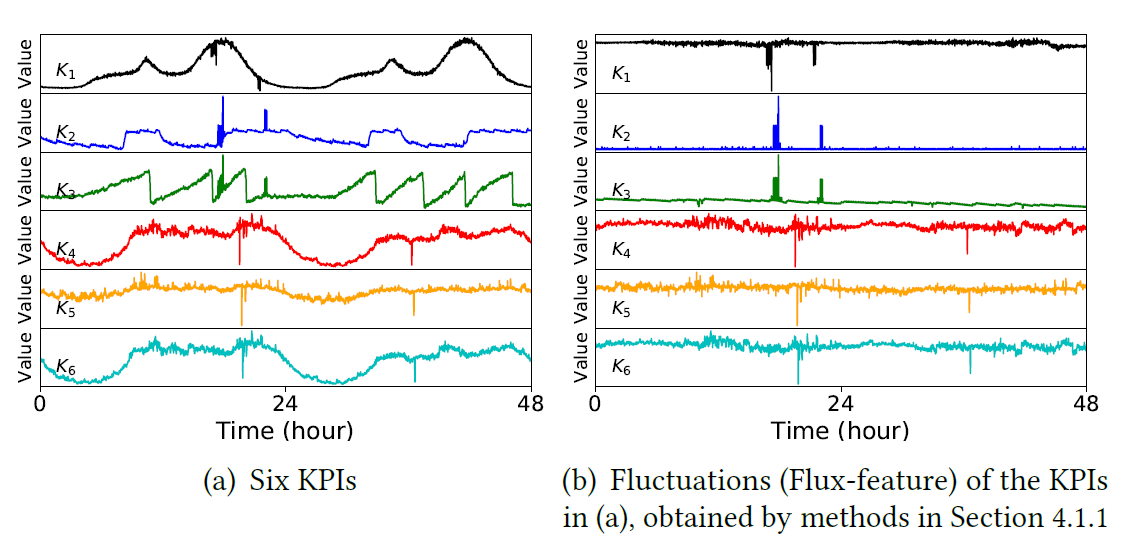
 ,对于任意一个 detector,可以得到一条关于
,对于任意一个 detector,可以得到一条关于  。于是针对某个 detector 可以得到一个波动特征序列
。于是针对某个 detector 可以得到一个波动特征序列 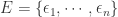 ,其中
,其中  ,
, ;
;


 如下:
如下: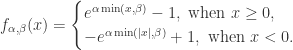

 和
和  ,可以计算它们之间的相关性,先后顺序,是否同向。
,可以计算它们之间的相关性,先后顺序,是否同向。
 个。其中,
个。其中,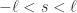 。特别地,当
。特别地,当 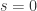 时,
时, ,那么我们可以定义
,那么我们可以定义  与
与 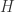 的内积是:
的内积是: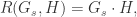
 指的是向量之间的内积(inner product)。同时可以定义相关性(Cross Correlation)为:
指的是向量之间的内积(inner product)。同时可以定义相关性(Cross Correlation)为: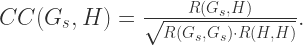



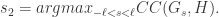

 是一个元组,里面蕴含着三个信息,分别是相关性,波动方向,前后顺序。
是一个元组,里面蕴含着三个信息,分别是相关性,波动方向,前后顺序。![FCC(G,H) \in [-1,1]](https://s0.wp.com/latex.php?latex=FCC%28G%2CH%29+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,越接近 1 或者 -1 就表示放大之后的波动特征曲线
,越接近 1 或者 -1 就表示放大之后的波动特征曲线 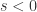 或者
或者  的分析就可以判断先后顺序。因此,CoFlux 方法的是通过对
的分析就可以判断先后顺序。因此,CoFlux 方法的是通过对 
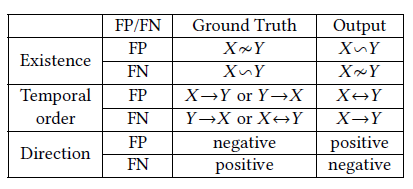
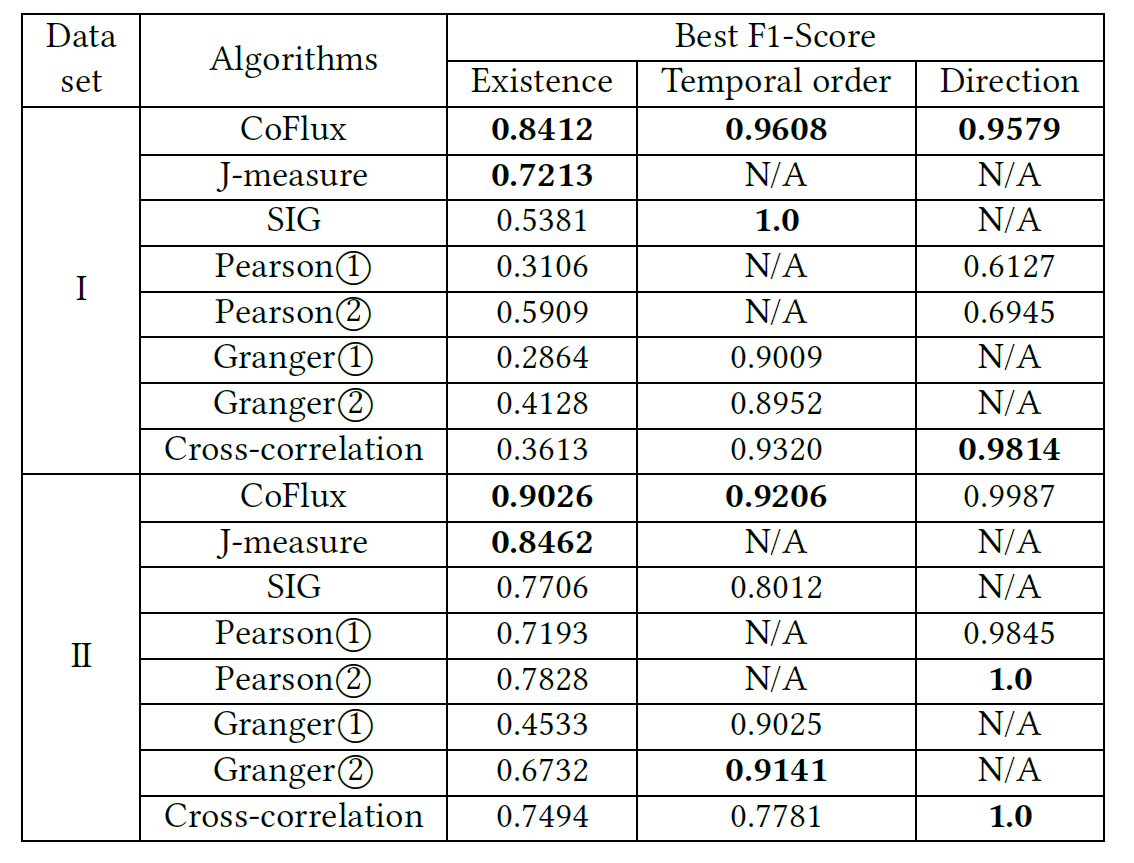
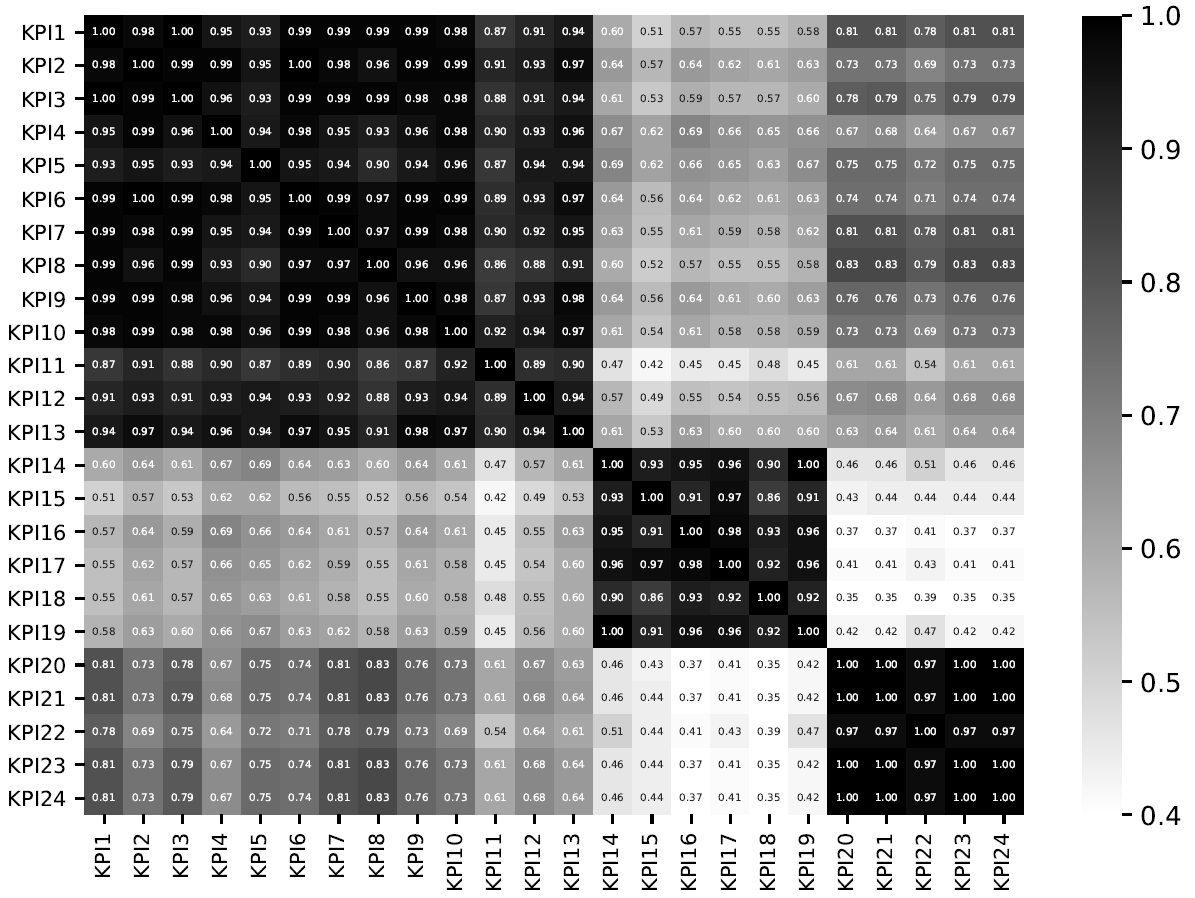
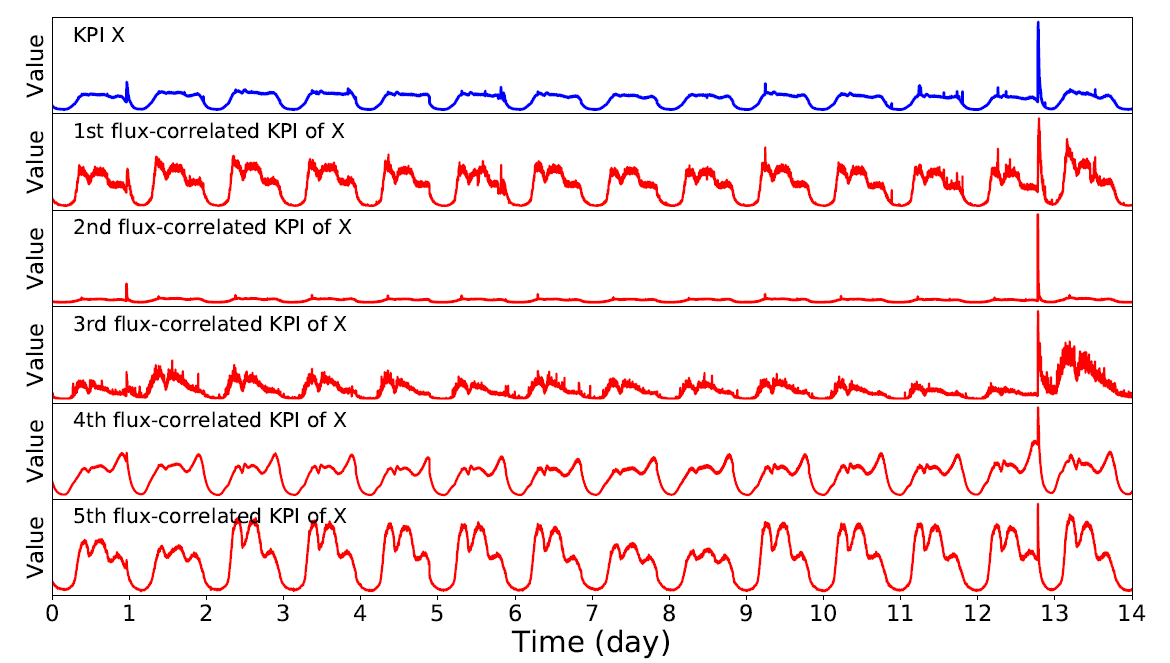
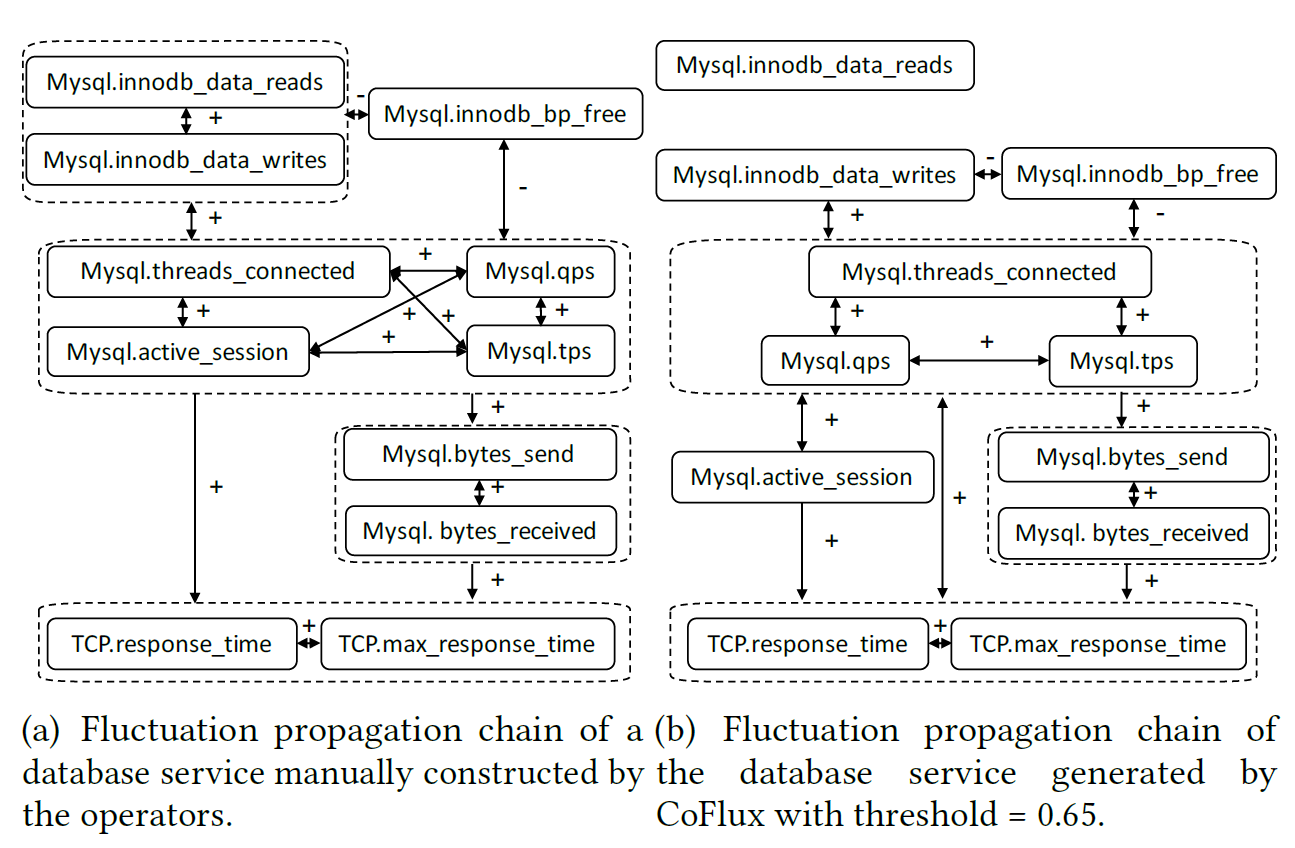
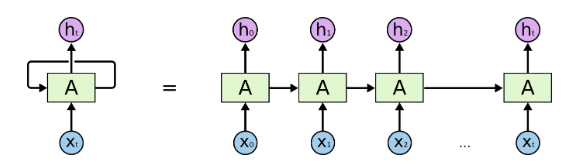
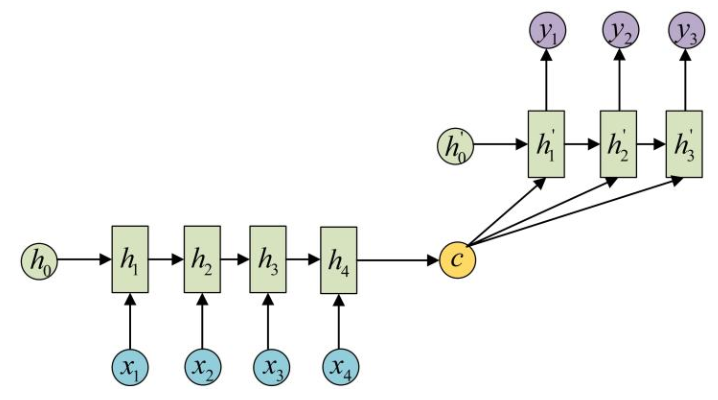
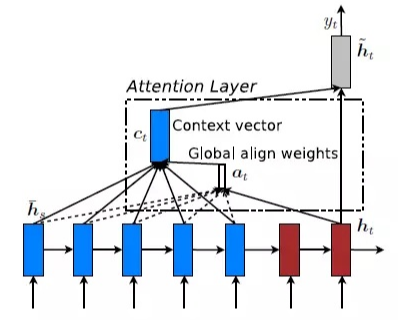
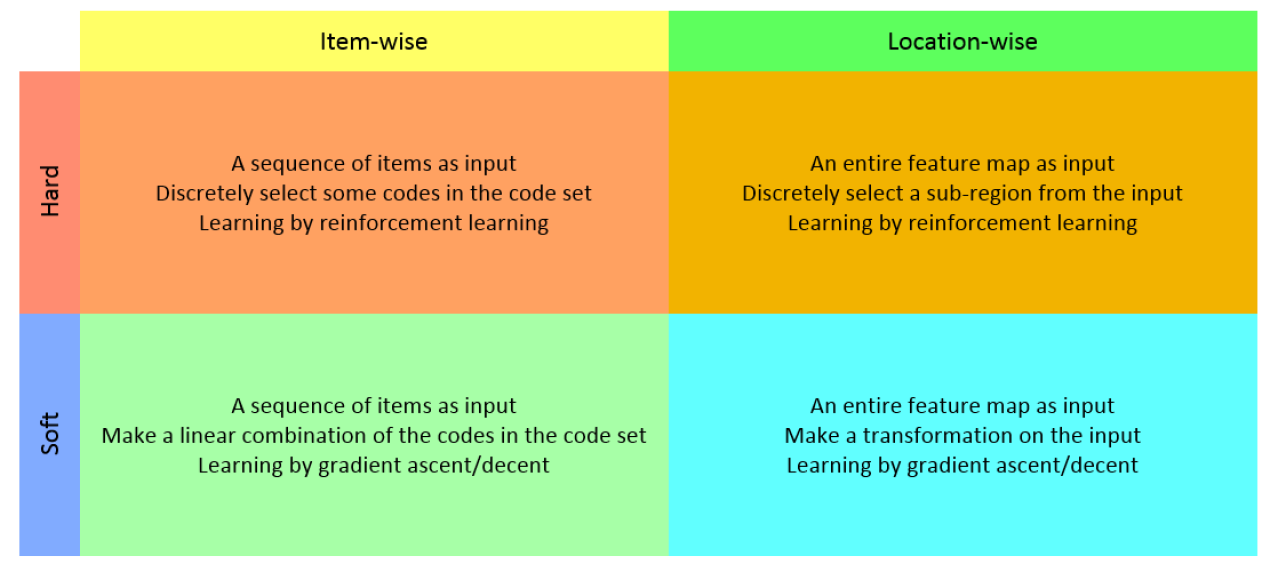
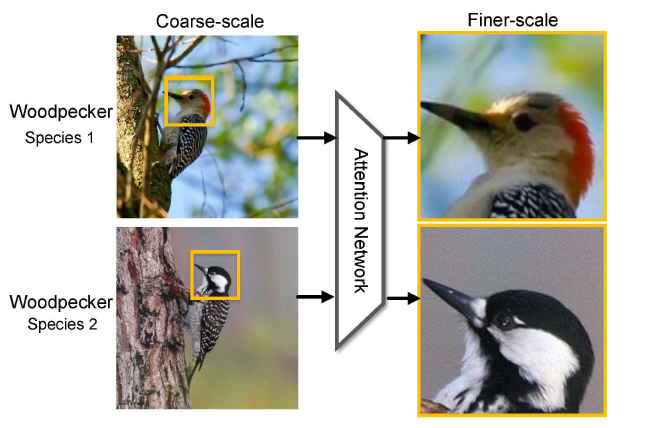


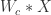 ,这里的
,这里的  指的是卷积等各种各样的操作。所以得到的概率分布情况其实就是
指的是卷积等各种各样的操作。所以得到的概率分布情况其实就是  ,
, 和尺寸大小
和尺寸大小  ,其中
,其中 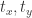 分别指的是横纵坐标,正方形的边长其实是
分别指的是横纵坐标,正方形的边长其实是  。用数学公式来记录这个流程就是
。用数学公式来记录这个流程就是 ![[t_{x}, t_{y}, t_{\ell}] = g(W_{c}*X)](https://s0.wp.com/latex.php?latex=%5Bt_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%5D+%3D+g%28W_%7Bc%7D%2AX%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。在坐标值的基础上,我们可以得到以下四个值,分别表示
。在坐标值的基础上,我们可以得到以下四个值,分别表示 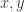 两个坐标轴的上下界:
两个坐标轴的上下界:

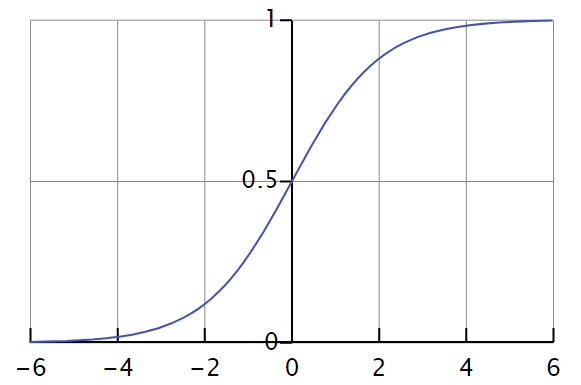
 而言,当
而言,当 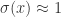 当
当 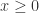 ;
; 当
当 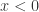 。此时的逻辑回归函数近似于一个阶梯函数。如果假设
。此时的逻辑回归函数近似于一个阶梯函数。如果假设  ,那么
,那么 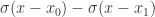 就是光滑一点的阶梯函数,
就是光滑一点的阶梯函数, 当
当  ;
; 当
当  。
。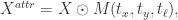 其中,
其中, 表示图片需要关注的区域,
表示图片需要关注的区域, 函数就是
函数就是 ![M(t_{x}, t_{y}, t_{\ell}) = [\sigma(x-t_{x(t\ell)}) - \sigma(x-t_{x(br)})]\cdot[\sigma(y-t_{y(t\ell)}) - \sigma(y-t_{y(br)})],](https://s0.wp.com/latex.php?latex=M%28t_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%29+%3D+%5B%5Csigma%28x-t_%7Bx%28t%5Cell%29%7D%29+-+%5Csigma%28x-t_%7Bx%28br%29%7D%29%5D%5Ccdot%5B%5Csigma%28y-t_%7By%28t%5Cell%29%7D%29+-+%5Csigma%28y-t_%7By%28br%29%7D%29%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这里的
这里的 
![m = [i/\lambda] + \alpha, n = [j/\lambda] + \beta](https://s0.wp.com/latex.php?latex=m+%3D+%5Bi%2F%5Clambda%5D+%2B+%5Calpha%2C+n+%3D+%5Bj%2F%5Clambda%5D+%2B+%5Cbeta&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,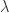 表示上采样因子,
表示上采样因子,![[\cdot], \{\cdot\}](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D%2C+%5C%7B%5Ccdot%5C%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 分别表示一个实数的正数部分和小数部分。
分别表示一个实数的正数部分和小数部分。 表示预测类别的概率,
表示预测类别的概率, 其中
其中  表示在第
表示在第  ,也就是说,局部预测的概率值应该高于整体的概率值。
,也就是说,局部预测的概率值应该高于整体的概率值。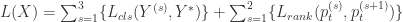 .
.
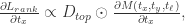
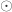 表示元素的点乘,
表示元素的点乘,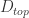 表示之前的网络所得到的导数。
表示之前的网络所得到的导数。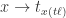 ,
,
 ,
,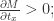

 ,
,
 ,
,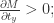
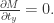


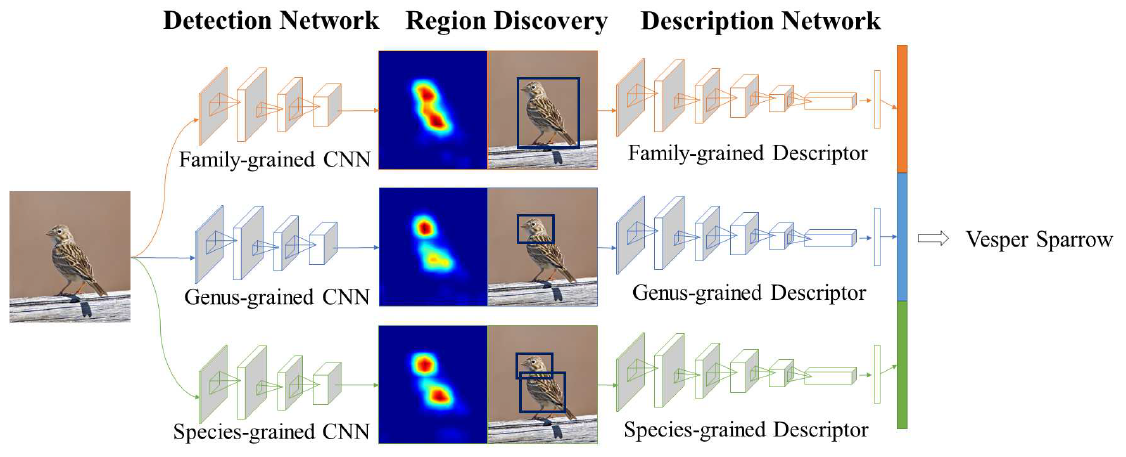

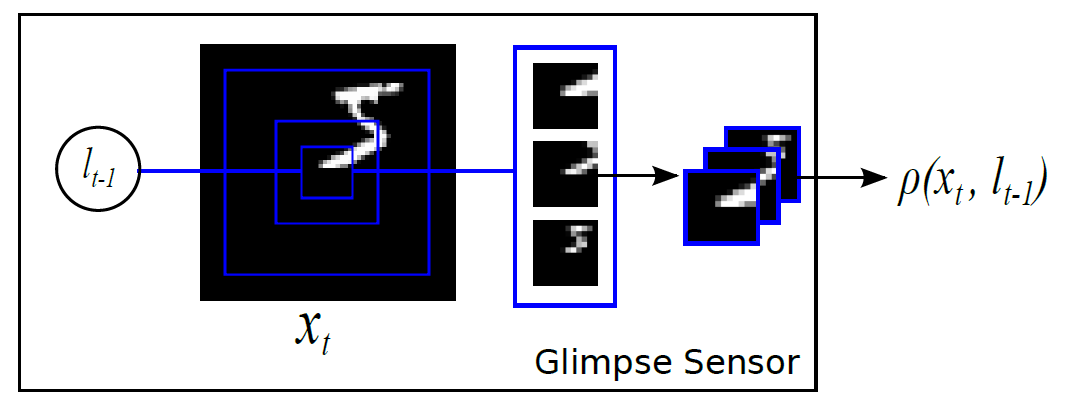
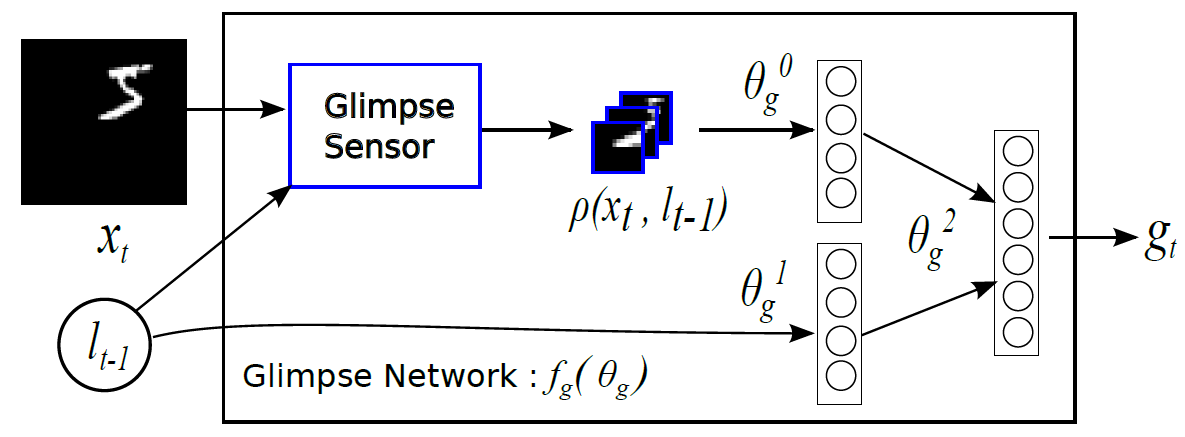
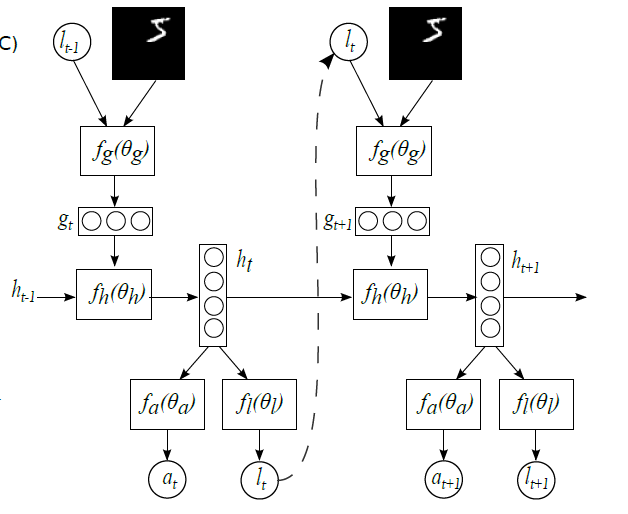
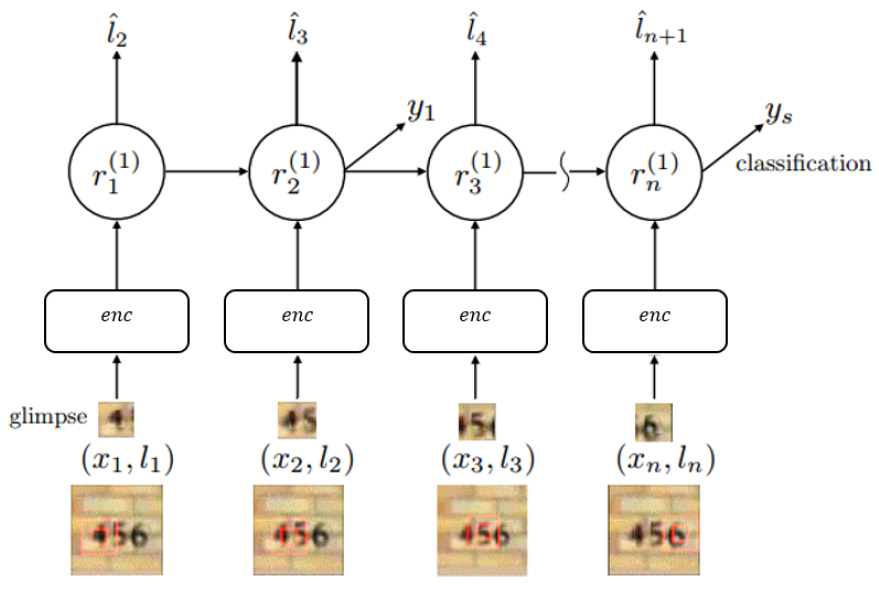
 表示解码的过程,
表示解码的过程, 表示对图片的预测概率或者预测标签。
表示对图片的预测概率或者预测标签。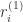 是解码网络,
是解码网络,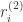 是注意力网络,输出概率在解码网络的最后一个单元输出。
是注意力网络,输出概率在解码网络的最后一个单元输出。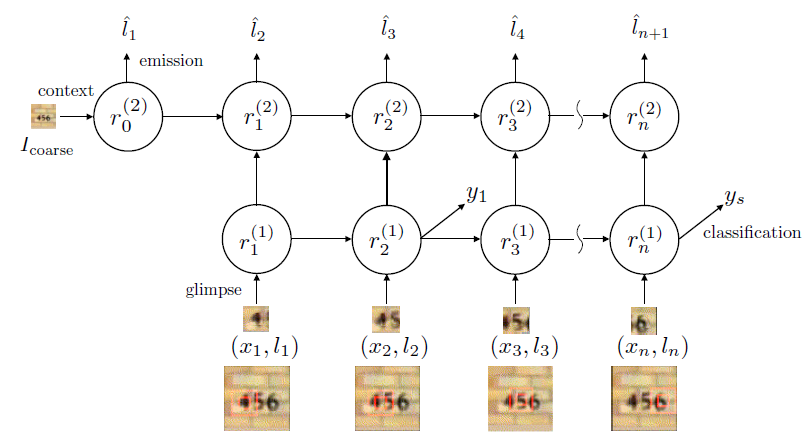
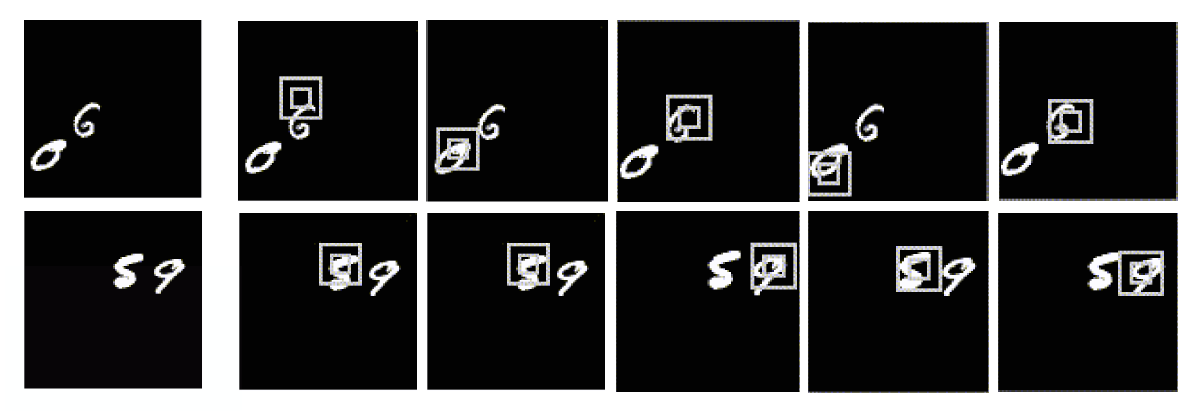

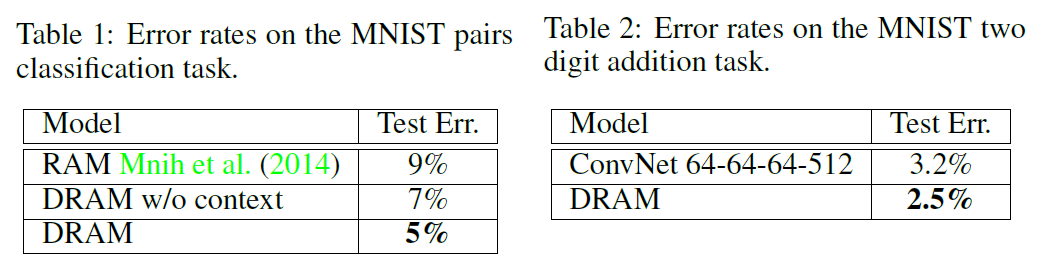
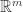 中的
中的 
 ,事先设定的类别个数是
,事先设定的类别个数是  是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合
是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合 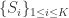 使得
使得  达到最小,其中
达到最小,其中  表示集合
表示集合  中的所有点的均值。
中的所有点的均值。 表示欧式空间的欧几里得距离,在这种情况下,除了使用
表示欧式空间的欧几里得距离,在这种情况下,除了使用 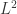 范数之外,还可以使用
范数之外,还可以使用  范数和其余的
范数和其余的 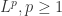 范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。
范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。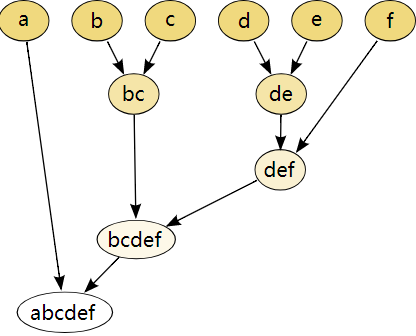
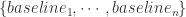 和
和  。i.e.
。i.e.  。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章:
。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章: 距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把
距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把  和
和  进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是
进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是  量级的,其中
量级的,其中 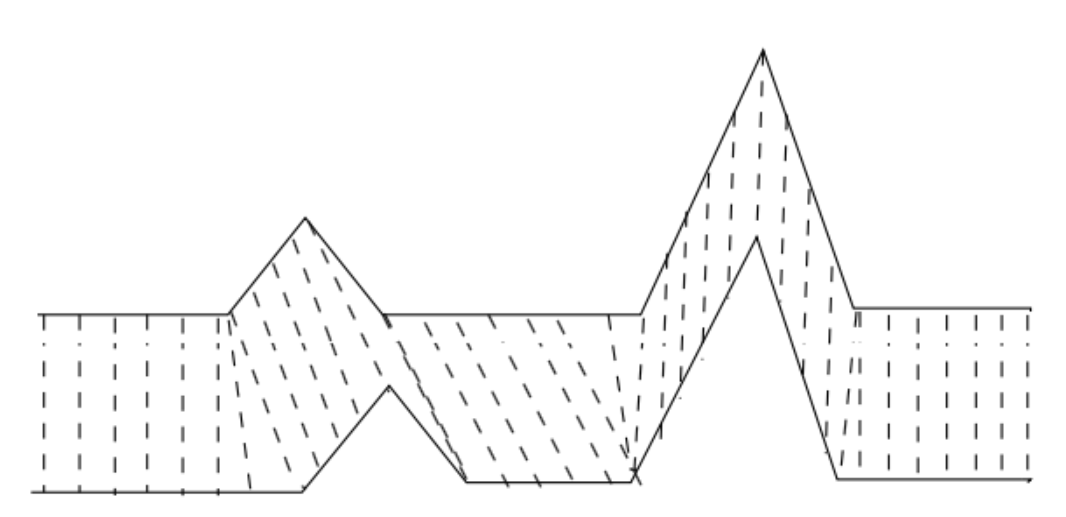
 还是
还是 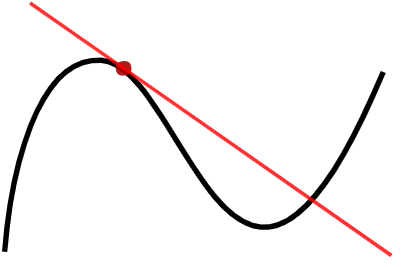
 上的可导函数,那么某个点
上的可导函数,那么某个点  的导数则定义为:
的导数则定义为:
 。如果
。如果  ,那么在
,那么在  的附近,
的附近, ,那么在
,那么在  ,则基于这个事实无法轻易的判断
,则基于这个事实无法轻易的判断  ,
,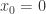 ;(2)
;(2)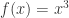 ,
,
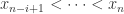 时,表示时间序列在
时,表示时间序列在 ![[n-i+1,n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2Cn%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调递增的;当
这个区间内是严格单调递增的;当  时,表示时间序列在
时,表示时间序列在 ![[n-i+1, n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2C+n%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。
这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。![X_{N} = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的一个子序列
的一个子序列 ![[x_{i},x_{i+1},\cdots,x_{j}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%2C%5Ccdots%2Cx_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,其中
,其中  。如果存在某个
。如果存在某个 ![k\in (i,j]](https://s0.wp.com/latex.php?latex=k%5Cin+%28i%2Cj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和一组非负实数
和一组非负实数 ![[w_{i}, w_{i+1},\cdots,w_{j}]](https://s0.wp.com/latex.php?latex=%5Bw_%7Bi%7D%2C+w_%7Bi%2B1%7D%2C%5Ccdots%2Cw_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 使得
使得 其中
其中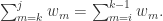
 其中
其中 ![X = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,可以考虑第
,可以考虑第  时,
时,

 ,当第一个公式大于零时,表示
,当第一个公式大于零时,表示 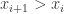 ,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示
,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示 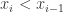 ,i.e. 处于单调下降的趋势中。
,i.e. 处于单调下降的趋势中。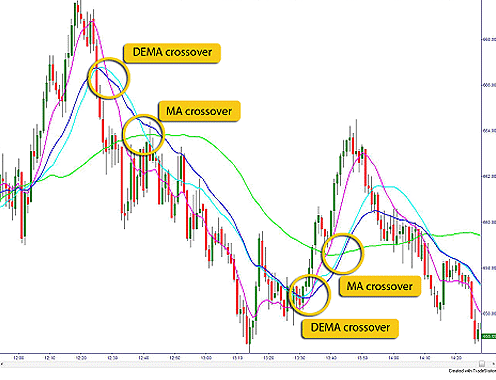
![X=[x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,如果考虑时间戳
,如果考虑时间戳 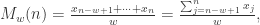
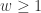 指的就是窗口的大小。
指的就是窗口的大小。 ,
,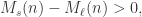 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。 。假设
。假设  ,那么通过数学推导可以得到:
,那么通过数学推导可以得到:

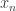 历史上的
历史上的 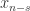 历史上的
历史上的  个点的平均值,该序列有上涨的趋势。反之,如果
个点的平均值,该序列有上涨的趋势。反之,如果  ,那么该序列有下跌的趋势。
,那么该序列有下跌的趋势。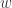 ,对于简单移动平均算法,那么
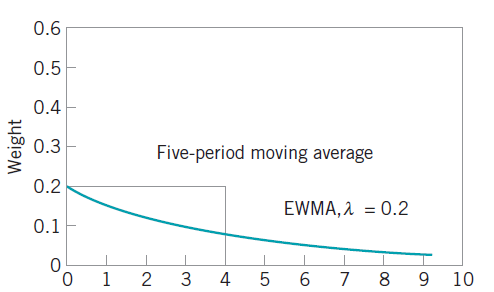
,对于简单移动平均算法,那么  每个元素的权重都是
每个元素的权重都是  ,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
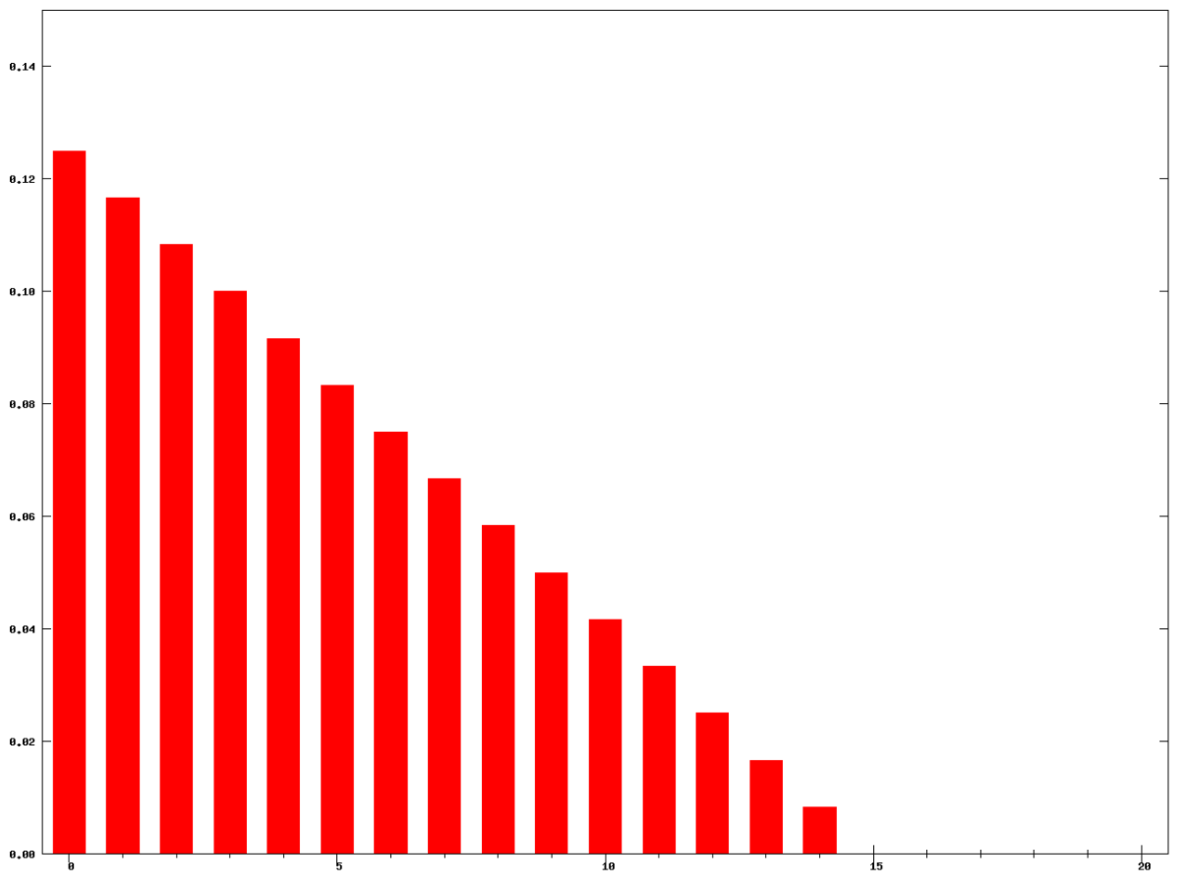
 ,那么
,那么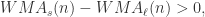 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。 。假设
。假设  ,那么
,那么




![j_{0}=[s\cdot(s+1)/(\ell + s-1)]](https://s0.wp.com/latex.php?latex=j_%7B0%7D%3D%5Bs%5Ccdot%28s%2B1%29%2F%28%5Cell+%2B+s-1%29%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,这里的
,这里的 
 ,于是距离当前点
,于是距离当前点 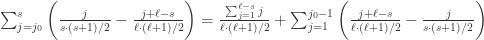

 时,表示时间序列有上涨的趋势;当
时,表示时间序列有上涨的趋势;当  时,表示时间序列有下跌的趋势。
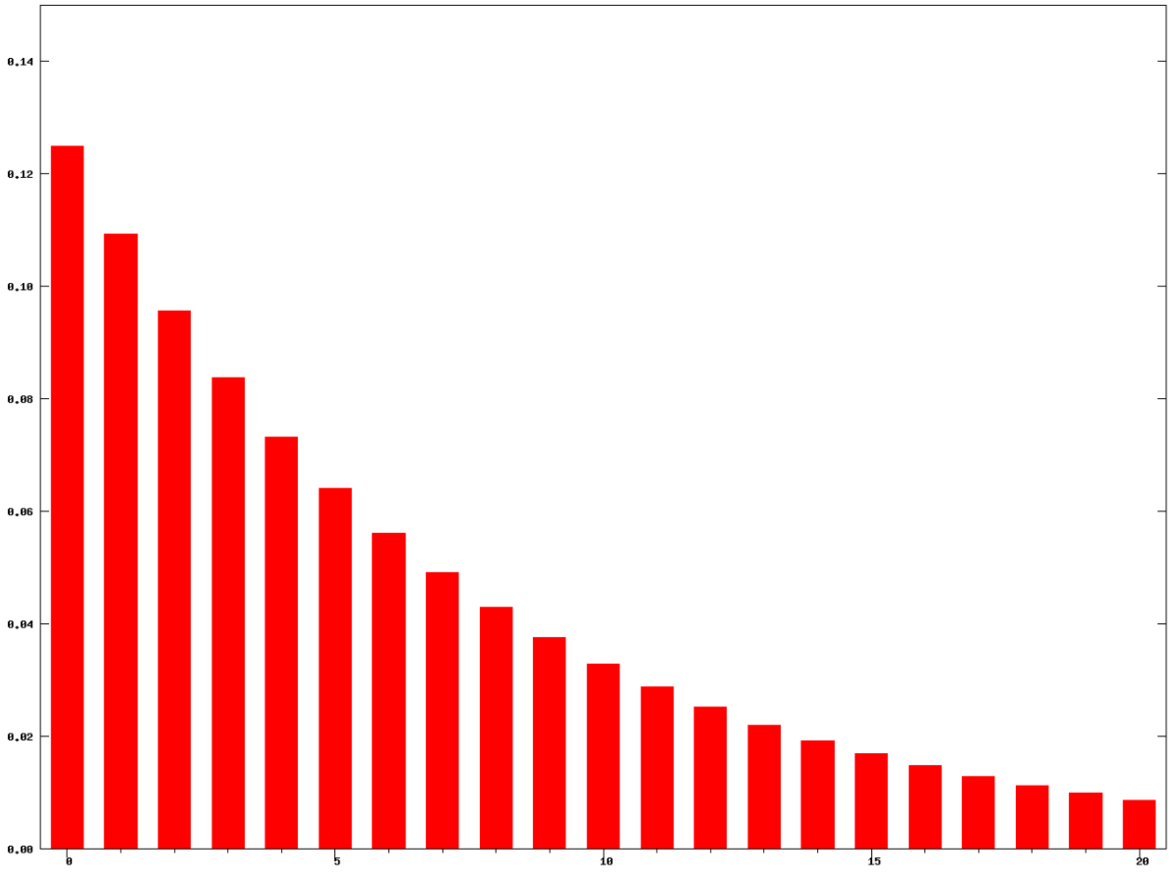
时,表示时间序列有下跌的趋势。 ,那么它的指数移动平均算法就是:
,那么它的指数移动平均算法就是: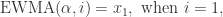

 。
。

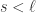 ,那么短线和长线则分别是:
,那么短线和长线则分别是:
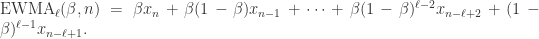
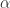 是与
是与  时,
时,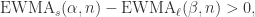 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。注:当
表示短线下穿长线,曲线有下跌的趋势。注:当  时,
时,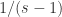 可以看做
可以看做  .
. 。那么
。那么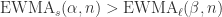


 时,表示时间序列有下跌的趋势。
时,表示时间序列有下跌的趋势。 时,根据假设有
时,根据假设有  ,并且
,并且


 ,通过计算可以得到
,通过计算可以得到  ,也就是说
,也就是说  在
在 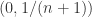 上是递增函数,在
上是递增函数,在  是递减函数。于是当
是递减函数。于是当 


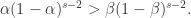
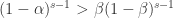 ,那么
,那么  可以写成
可以写成

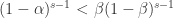 ,那么
,那么 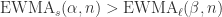 可以写成
可以写成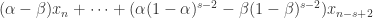

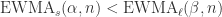 时,也可以使用同样的方法证明时间序列有下跌的趋势。
时,也可以使用同样的方法证明时间序列有下跌的趋势。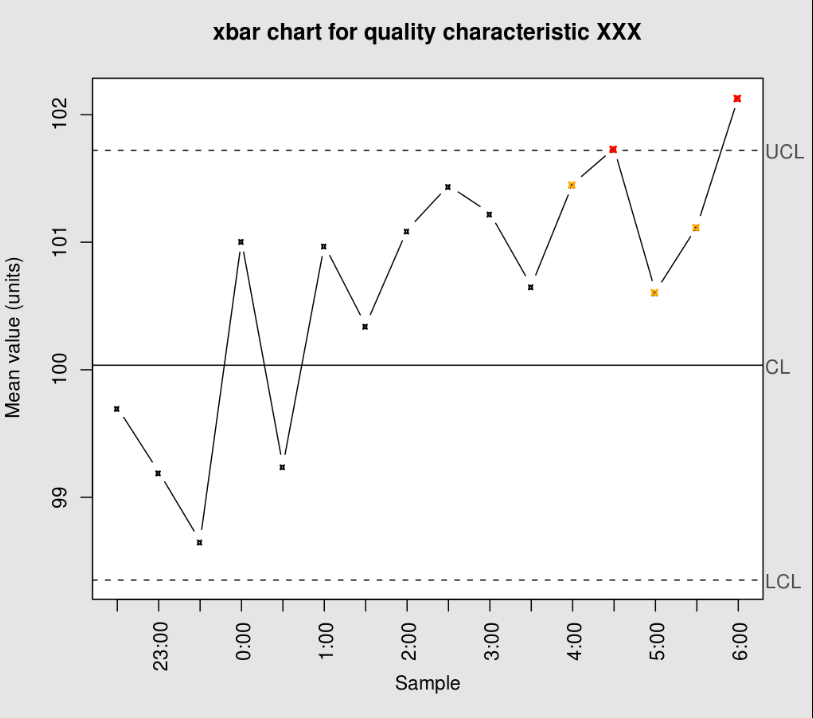
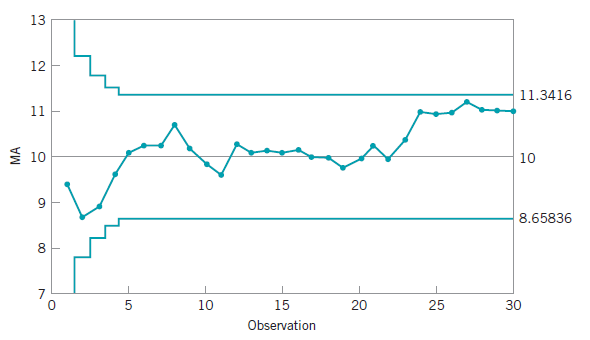
 控制图
控制图![X_{N} = [x_{1},\cdots, x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,为了计算某个时间戳
,为了计算某个时间戳 ![[x_{1},x_{2},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 中的所有点,可以计算出均值和方差如下:
中的所有点,可以计算出均值和方差如下:

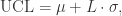


 。
。 ,那么说明
,那么说明 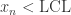 时,那么说明
时,那么说明 
 的方差是
的方差是
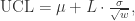

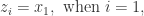

 的方差是:
的方差是:

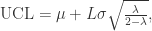

 。
。
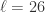 ,
, 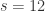 ,
,  ,基于时间序列
,基于时间序列  ,有
,有


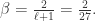

 ,计算 DEA 如下:
,计算 DEA 如下:
 ,
,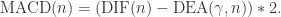
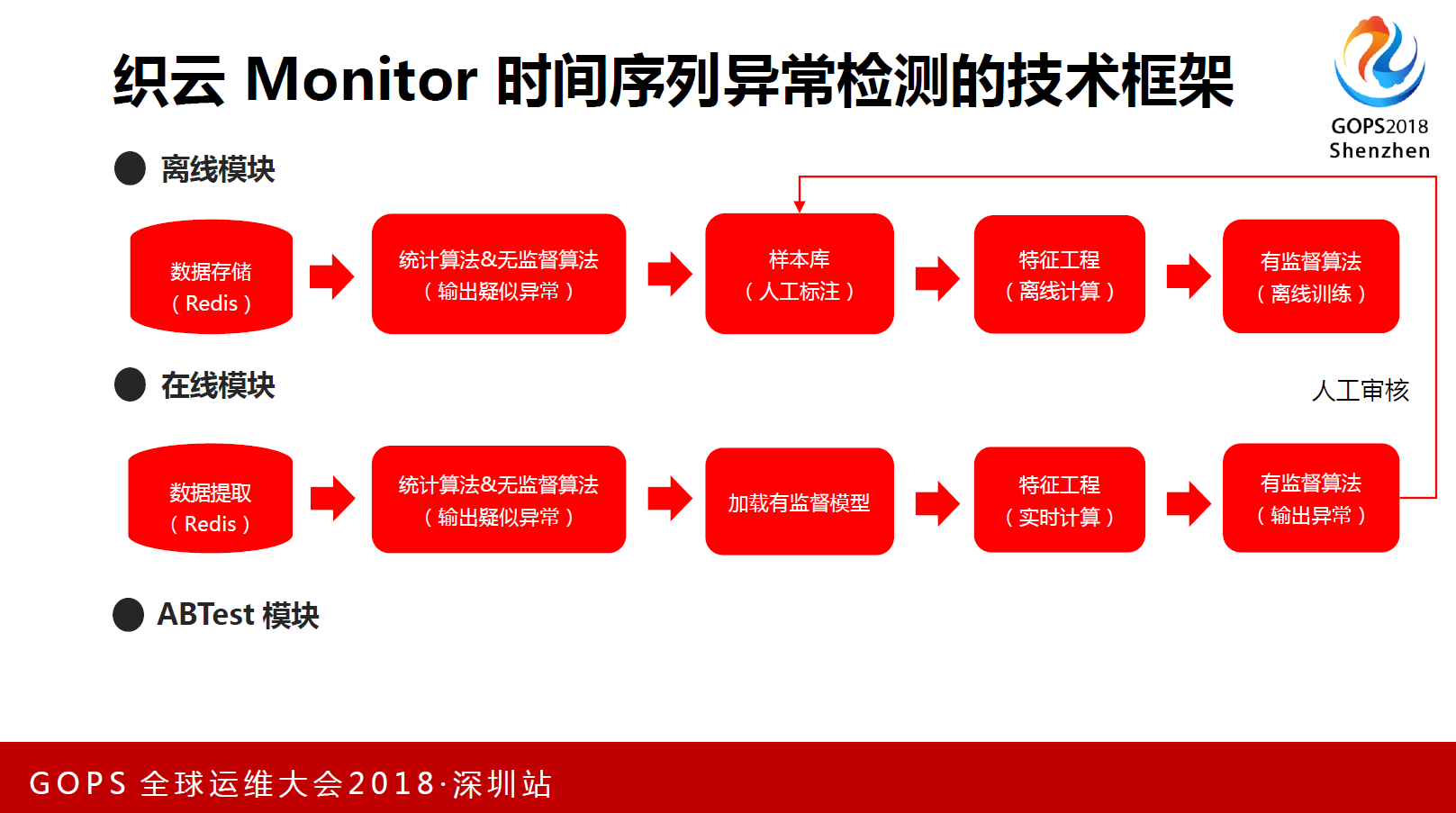




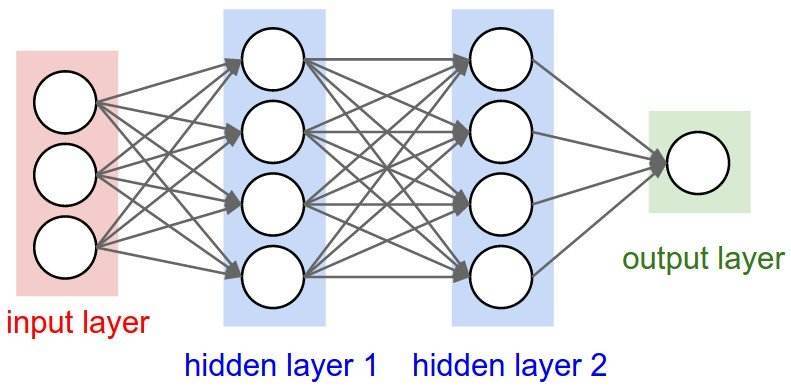
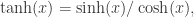
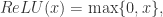




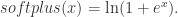
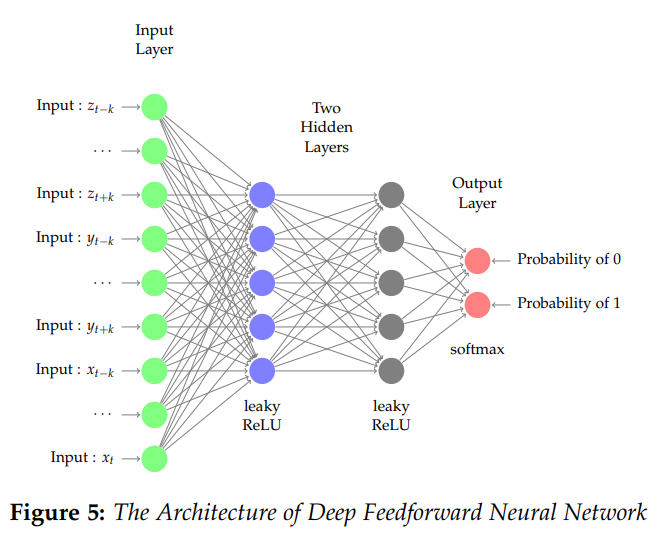
 ,存在一个前馈神经网络
,存在一个前馈神经网络 ![\boldsymbol{X}_{n}=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7BX%7D_%7Bn%7D%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,该神经网络的输入和输出分别是
,该神经网络的输入和输出分别是  和表格 2 中
和表格 2 中 ![X_{n} = [x_{1},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的以上统计特征之前,我们可以先使用神经网络构造出这几种运算方法。
的以上统计特征之前,我们可以先使用神经网络构造出这几种运算方法。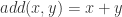 与减法
与减法 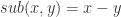 的构造十分简单,如下图构造即可:
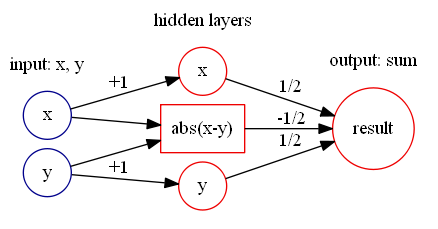
的构造十分简单,如下图构造即可:

 通过计算可以得到
通过计算可以得到  所以,可以构造如下的神经网络来表示绝对值函数:
所以,可以构造如下的神经网络来表示绝对值函数: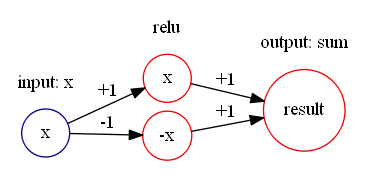
 通过计算可以得到
通过计算可以得到
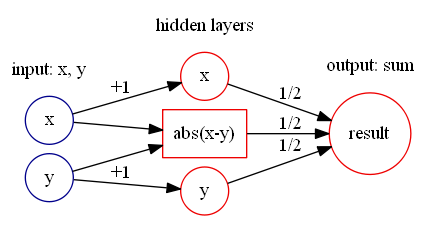
 通过计算可以得到
通过计算可以得到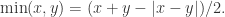


 指的是
指的是 
 这个函数可以使用 Softplus 激活函数来表达。令 Softplus 为
这个函数可以使用 Softplus 激活函数来表达。令 Softplus 为



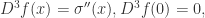



 就可以用神经网络来近似表示:
就可以用神经网络来近似表示: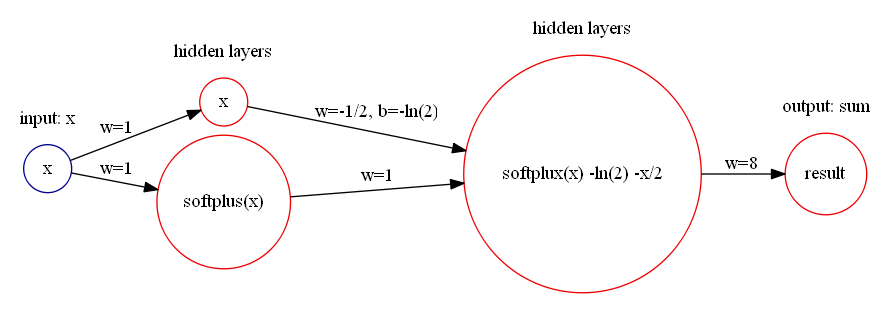
 这个函数可以使用 Sigmoid 激活函数来表达。因为 Sigmoid 函数的 Taylor Series 是
这个函数可以使用 Sigmoid 激活函数来表达。因为 Sigmoid 函数的 Taylor Series 是

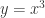 就可以用神经网络来近似表示:
就可以用神经网络来近似表示: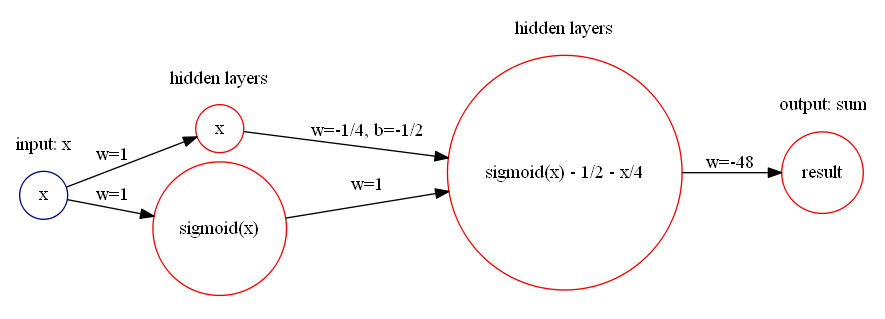
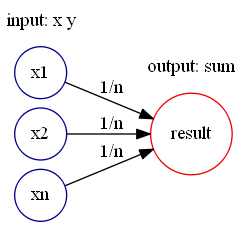
![X_{n} =[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的最大值,最小值等各种各样的统计指标。如果按照上文所描述的,以下特征都可以用神经网络轻松构造出来:
的最大值,最小值等各种各样的统计指标。如果按照上文所描述的,以下特征都可以用神经网络轻松构造出来:



![\sum_{i=1}^{n}[(x_{i}-\mu)/\sigma]^{3},](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%28x_%7Bi%7D-%5Cmu%29%2F%5Csigma%5D%5E%7B3%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![\sum_{i=1}^{n}[(x_{i}-\mu)/\sigma]^{4},](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%28x_%7Bi%7D-%5Cmu%29%2F%5Csigma%5D%5E%7B4%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


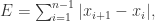


 的时候,
的时候,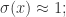 当
当  的时候,
的时候, 因此,可以使用函数
因此,可以使用函数  来估计 NOT 逻辑门。
来估计 NOT 逻辑门。 时,
时,
 时,
时,

 可以得到
可以得到 时,
时,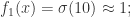
 时,
时,
 近似于判断待测试值
近似于判断待测试值 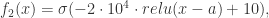 可以得到
可以得到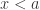 时,
时,
 时,
时,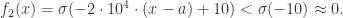
 近似于判断待测试值
近似于判断待测试值 ![X_{n}=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 每个点与均值的差值,然后使用前面的神经网络模块计算出大于零的差值个数与小于零的差值个数即可。
每个点与均值的差值,然后使用前面的神经网络模块计算出大于零的差值个数与小于零的差值个数即可。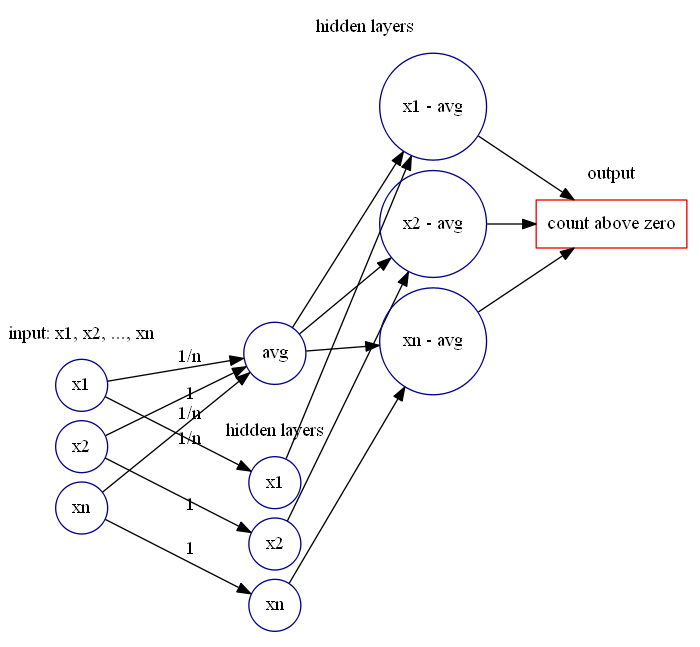
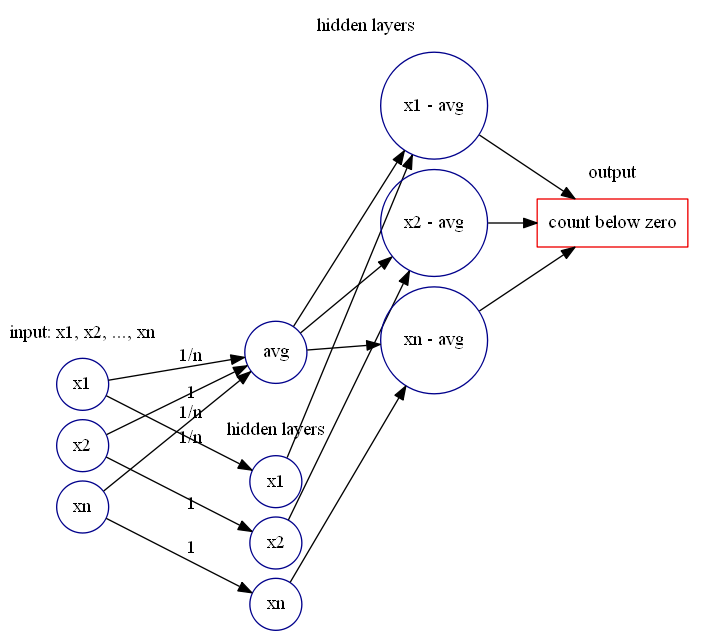
![X_{n} = [x_{1},\cdots,x_{n}],](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 我们可以使用一个窗口值
我们可以使用一个窗口值 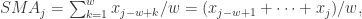
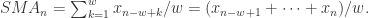
 就可以作为一个特征。然后根据不同的窗口长度
就可以作为一个特征。然后根据不同的窗口长度 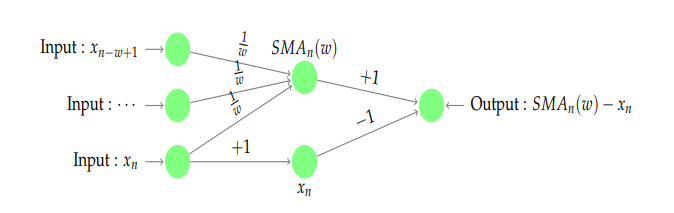
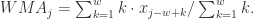

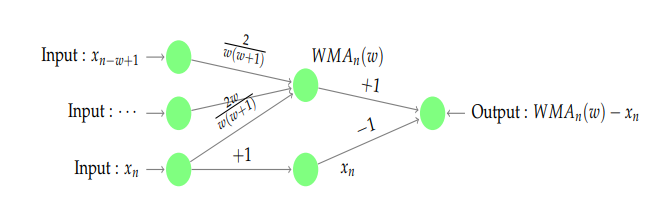



![= \alpha[x_{n-1}+(1-\alpha)x_{n-2}+\cdots+(1-\alpha)^{k}x_{n-(k+1)}] + (1-\alpha)^{k+1}EWMA_{n-(k+1)}](https://s0.wp.com/latex.php?latex=%3D+%5Calpha%5Bx_%7Bn-1%7D%2B%281-%5Calpha%29x_%7Bn-2%7D%2B%5Ccdots%2B%281-%5Calpha%29%5E%7Bk%7Dx_%7Bn-%28k%2B1%29%7D%5D+%2B+%281-%5Calpha%29%5E%7Bk%2B1%7DEWMA_%7Bn-%28k%2B1%29%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![\approx \alpha[x_{n-1}+(1-\alpha)x_{n-2}+\cdots+(1-\alpha)^{k}x_{n-(k+1)}]](https://s0.wp.com/latex.php?latex=%5Capprox%C2%A0%5Calpha%5Bx_%7Bn-1%7D%2B%281-%5Calpha%29x_%7Bn-2%7D%2B%5Ccdots%2B%281-%5Calpha%29%5E%7Bk%7Dx_%7Bn-%28k%2B1%29%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 的取值就可以得到特征。所以,神经网络可以构建为如下形式:
的取值就可以得到特征。所以,神经网络可以构建为如下形式: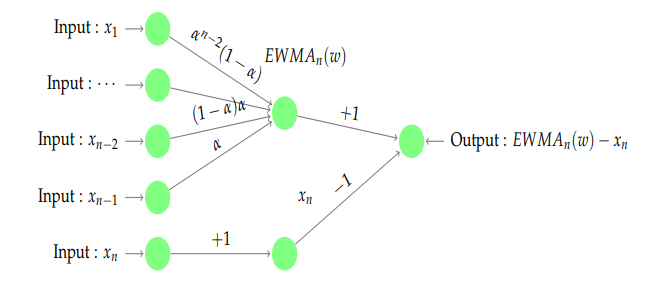
![X_{n} = [x_{week}, x_{yesterday}, x_{today}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7Bweek%7D%2C+x_%7Byesterday%7D%2C+x_%7Btoday%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 可以拆分成三个部分
可以拆分成三个部分 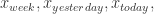 分别是一周前的数据,昨天的数据,今天的数据,假设它们的长度都是 [n/3],最后一点都表示不同天但是同一个时刻的取值。所以,同环比特征
分别是一周前的数据,昨天的数据,今天的数据,假设它们的长度都是 [n/3],最后一点都表示不同天但是同一个时刻的取值。所以,同环比特征![x_{today}[-1] - x_{yesterday}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D+-+x_%7Byesterday%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 与
与 ![x_{today}[-1] - x_{week}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D+-+x_%7Bweek%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 都是可以通过神经网络构造出来。
都是可以通过神经网络构造出来。 与
与  这一类特征也可以构造出来。
这一类特征也可以构造出来。 等函数,再计算两者的差值即可。例如,我们可以构造一个特征用于计算当前值是否高过昨天的峰值,以及超出的幅度是多少。用公式来表示那就是:
等函数,再计算两者的差值即可。例如,我们可以构造一个特征用于计算当前值是否高过昨天的峰值,以及超出的幅度是多少。用公式来表示那就是:![\max\{x_{today}[-1]-\max\{x_{yesterday}\}, 0\},](https://s0.wp.com/latex.php?latex=%5Cmax%5C%7Bx_%7Btoday%7D%5B-1%5D-%5Cmax%5C%7Bx_%7Byesterday%7D%5C%7D%2C+0%5C%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![x_{today}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 大于昨天的最大值,就返回它高出的幅度;否则就返回0。
大于昨天的最大值,就返回它高出的幅度;否则就返回0。![\min\{x_{today}[-1]-\min\{x_{week}\},0\},](https://s0.wp.com/latex.php?latex=%5Cmin%5C%7Bx_%7Btoday%7D%5B-1%5D-%5Cmin%5C%7Bx_%7Bweek%7D%5C%7D%2C0%5C%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 激活函数使用
激活函数使用  即可。
即可。![X_{n} = [x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的取值在
的取值在 ![[0,0.1), [0.1,0.2),\cdots,[0.9,1]](https://s0.wp.com/latex.php?latex=%5B0%2C0.1%29%2C+%5B0.1%2C0.2%29%2C%5Ccdots%2C%5B0.9%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这十个桶的个数,进一步得到它们落入这十个桶的概率是多少。这一类特征可以通过之前所构造的 count 函数来生成。因此,分类特征也是可以通过构造神经网络来形成的。
这十个桶的个数,进一步得到它们落入这十个桶的概率是多少。这一类特征可以通过之前所构造的 count 函数来生成。因此,分类特征也是可以通过构造神经网络来形成的。