
基数估算问题
基数估算(Cardinality Estimation),也称为 count-distinct problem,一直是大数据领域的重要问题之一。顾名思义,基数估算就是为了估算在一批数据中,它的不重复元素有多少个。
这个问题的应用场景十分广泛。例如:对于 Google 主页面而言,同一个账户可能会访问 Google 主页面多次。于是,在诸多的访问流水中,如何计算出 Google 主页面每天被多少个不同的账户访问过就是一个重要的问题。那么对于 Google 这种访问量巨大的网页而言,其实统计出有十亿 的访问量或者十亿零十万的访问量其实是没有太多的区别的,因此,在这种业务场景下,为了节省成本,其实可以只计算出一个大概的值,而没有必要计算出精准的值。
从数学上来说,基数估计这个问题的详细描述是:对于一个数据流 

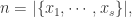


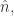

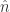
如果是想得到精确的基数,可以使用字典(dictionary)这一个数据结构。对于新来的元素,可以查看它是否属于这个字典;如果属于这个字典,则整体计数保持不变;如果不属于这个字典,则先把这个元素添加进字典,然后把整体计数增加一。当遍历了这个数据流之后,得到的整体计数就是这个数据流的基数了。

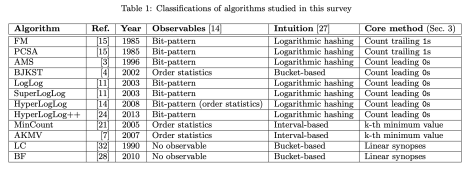
这种算法虽然精准度很高,但是使用的空间复杂度却很高。那么是否存在一些近似的方法,可以估算出数据流的基数呢?其实,在近几十年,不少的学者都提出了很多基数估算的方法,包括 LogLog,HyperLogLog,MinCount 等等。下面将会简要的介绍一下这些方法。
HyperLogLog 的理论介绍
HyperLogLog 是大数据基数统计中的常见方法,无论是 Redis,Spark 还是 Flink 都提供了这个功能,其目的就是在一定的误差范围内,用最小的空间复杂度来估算一个数据流的基数。

HyperLogLog 算法简要思路是通过一个 hash 函数把数据流 



在介绍 HyperLogLog 之前,我们可以考虑这个实际的场景。在一个抛硬币的场景下,假设硬币的正面对应着 

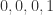

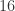

考虑这样一个 


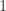


- 出现序列
意味着不重复的元素估计有
个;
- 出现序列
意味着不重复的元素估计有
个;
- 出现序列
意味着不重复的元素估计有
个;
- 出现序列
意味着不重复的元素估计有
个。
于是,对于随机的 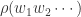


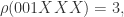

简单来看,其实 HyperLogLog 的基数统计就使用了这样的思想,通过二进制中 



那么如果只有 
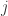
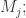

- 算术平均数:
- 几何平均数:
- 调和平均数:
- 中位数:
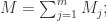
![M=\sqrt[m]{M_{1}\cdots M_{m}};](https://s0.wp.com/latex.php?latex=M%3D%5Csqrt%5Bm%5D%7BM_%7B1%7D%5Ccdots+M_%7Bm%7D%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

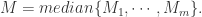
从而可以预估整体的数量为
如果按照以上的步骤进行操作,就是需要重复进行多次操作,在足够多的情况下,其实是没有必要那么操作的。HyperLogLog 也是用了多个桶,但是用了一个截断的技巧。对于一个 
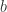



每次都可以获得一个值,也就是桶里面第一次出现
- 第 1 个桶:计算出
预估元素个数
- 第 2 个桶:计算出
预估元素个数
- ….
- 第
预估元素个数



均值的计算,HyperLogLog 使用了调和平均数 


其中的 


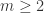

HyperLogLog 分成两块,第一块就是 add 模块,用于分桶和统计;
for v in M:
set x := h(v);
set j = 1 + <x(b),...,x(2),x(1)>;
set w := x(b+1)x(b+2)...;
set M[j] := max(M[j], \rho(w));
在 HyperLogLog 算法中,对于集合 

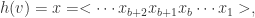

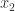
然后可以通过 
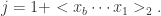


compute Z := (\sum_{j=1}^{m}2^{-M[j]})^{-1};
上一步就是 HyperLogLog 的另外一步,count 模块,于是,进一步估算出
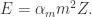
HyperLogLog 的空间复杂度特别低,大约是 
- 假设基数为
二进制就是
个 bit 就能够存储;
- 假设基数为
二进制就是
位,
个 bit 就可以存储。

在论文中,论文 “Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm” 的作者们针对各种算法进行了对比,其实 HyperLogLog 的空间复杂度是非常小的,并且误差也在可控的范围内。

在论文 “Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm” 作者们得到上述定理,精准的给出了 HyperLogLog 算法的误差估计。因此,HyperLogLog 算法其实是有数学定理证明的。
以上只是获得了理论上的 HyperLogLog 算法,但是在实战中,其实是需要进行微调的。主要的微调部分是根据理论中的 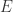
- 小范围;
- 中等范围;
- 大范围;

Case(1):小范围
在小范围的情况下,
可以思考这样一个问题:假设有
Answer:假设 
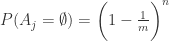


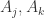

那么空桶个数的期望就是 


因此,在小范围的情况下,如果空桶的个数 



Case(2):中等范围
Case(3):大范围
当 


通过这样的方法,
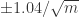
除此之外,
近似的值为 
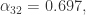
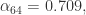

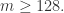
HyperLogLog 的案例分析
有一个关于 HyperLogLog 的 demo 网站可以看到 HyperLogLog 的算法过程,其链接是 http://content.research.neustar.biz/blog/hll.html
在这个 demo 中,作者对比了 LogLog 和 HyperLogLog 的区别和运行过程,有助于大家理解整个过程。其中 LogLog 与 HyperLogLog 的区别就在与它们平均值的处理方式不一样,前者是使用算术平均值,后者是使用调和平均值。
- LogLog:
- HyperLogLog:

![\alpha_{m}\cdot m^{2}\cdot\bigg(\sum_{j=1}^{m}2^{-M[j]}\bigg)^{-1};](https://s0.wp.com/latex.php?latex=%5Calpha_%7Bm%7D%5Ccdot+m%5E%7B2%7D%5Ccdot%5Cbigg%28%5Csum_%7Bj%3D1%7D%5E%7Bm%7D2%5E%7B-M%5Bj%5D%7D%5Cbigg%29%5E%7B-1%7D%3B&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
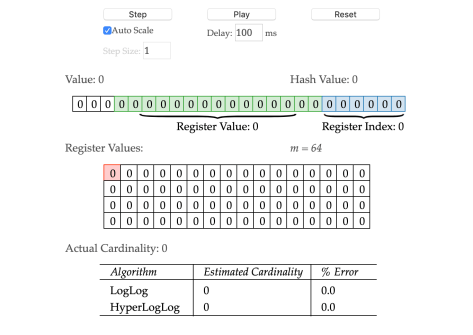

3852172429 的二进制是:11100101100110110111110010001101,可以划分为100 110110111110010 001101。最后的六位是 001101,十进制就是 13,那么这个数字就会被放入第 13 个桶;而 110110111110010(从低位到高位看),
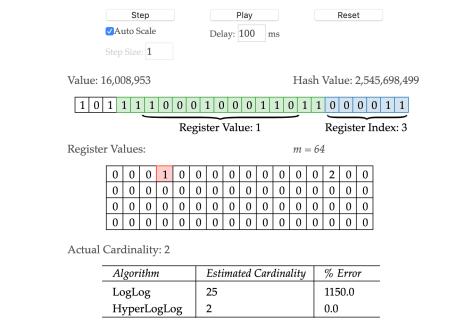
2545698499 的二进制是 10010111101111000100011011000011,用同样的分析可得结论。

2577699815 的二进制是 10011001101001001001001111100111。
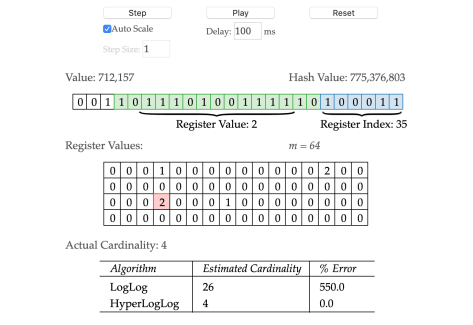
775376803 的二进制是 101110001101110100111110100011。
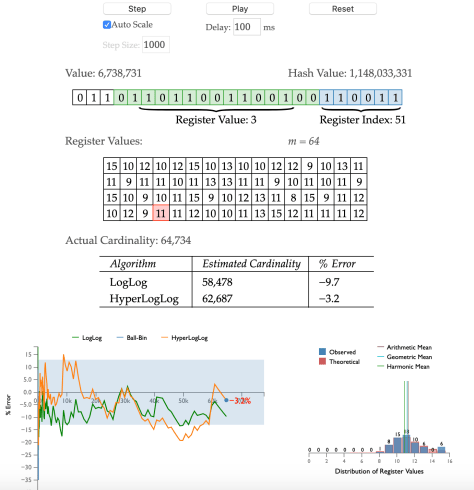
从以上的 Demo 运行过程可以看出,整个 HyperLogLog 的算法逻辑还是相对清晰的,其整个算法的亮点应该在于借助了抛硬币的场景,用抛硬币的结果来估算抛硬币的次数。
参考文献:
- Count-distinct Problem 的维基百科:https://en.wikipedia.org/wiki/Count-distinct_problem
- Heule, Stefan, Marc Nunkesser, and Alexander Hall. “HyperLogLog in practice: algorithmic engineering of a state of the art cardinality estimation algorithm.” Proceedings of the 16th International Conference on Extending Database Technology. 2013.
- Flajolet, Philippe, et al. “Hyperloglog: the analysis of a near-optimal cardinality estimation algorithm.” 2007.
- HyperLogLog 的 demo 网站:http://content.research.neustar.biz/blog/hll.html
