
在运维领域,服务侧的异常会由多方面的原因造成,有的时候是因为网络的抖动,有的时候是因为机器的故障,有的时候甚至是因为人为的变更。本篇博客会介绍一种机器异常定位的方法,论文是来自于清华 Netman 实验室的《FluxRank:A Widely-Deployable Framework to Automatically Localizting Root Cause Machines for Software Service Failure Mitigation》。本篇论文主要介绍了如何从服务的故障定位到局部异常的机器,也就是说在发现服务故障的同时,进一步推断出是由哪些机器出现问题而导致的。
通常来说,在服务异常(例如服务的耗时长,失败数上涨)的时候,需要运维人员通过历史上的经验迅速定位到是哪个业务,哪个模块,甚至哪台服务器出现了故障。而人工定位的速度总是会出现瓶颈的,无论对模块的判断,还是机器的判断,都依赖于人工所积累的经验。而每个人的经验却各不相同,并且经验的传承也需要一定的时间成本。那么如何基于人工运维的经验来构建模型,进一步地提升异常定位的速度就是智能运维的关键之处之一。
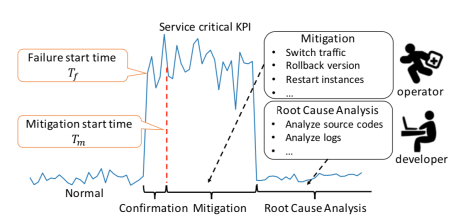
对于一条业务指标(时间序列)而言,大多数情况下是处于正常的状态(normal)。但是如果出现了错误的变更,发布了错误的程序,或者服务器突然出现了故障,都会导致业务指标出现变化,就从正常(normal)变成异常(abnormal)。这个时候就会出现一个故障的开始时间,也就是 failure start time 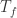
贝叶斯网络
通常来说,故障定位也称为根因分析或者根源分析(Root Cause Analysis),都是为了排查产生这次故障的原因。在机器学习领域,为了进行因果分析(Causal Analysis),则需要使用相应的模型来进行建模。其中较为经典的统计分析方法则是贝叶斯分析法,其中的贝叶斯网络(Bayesian Network)则是经典模型之一。下面来看一个简单的例子。
假设降雨(Rain)的概率是 0.2,不降雨的概率是 0.8;而洒水器(Sprinkler)是否开启会受到降雨的影响,其条件概率与下图所示。而降雨或者洒水器都会导致草湿润(Grass Wet),其概率分布如下图所示。那么可以问如下问题:
- 如果草已经湿润,求降雨的概率是多少?
- 如果草已经湿润,求没有降雨且洒水器开启的概率是多少?
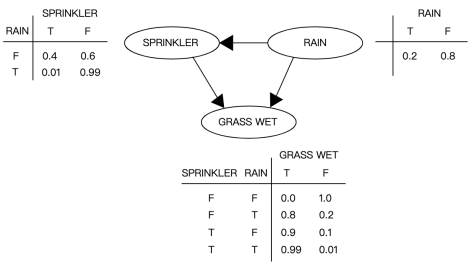
而这一类的问题可以通过贝叶斯公式来进行解答。从表格来看:
从 Rain 的表格可得: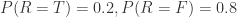
从 Rain 和 Sprinkler 的表格可得: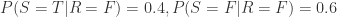
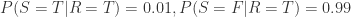
从 Grass Wet 和 Sprinkler,Rain 的表格可得:
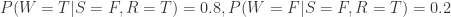


针对问题 1,需要计算条件概率 
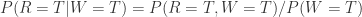


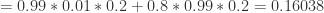
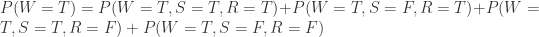
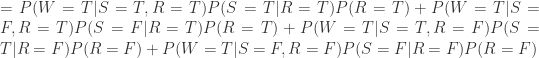

那么如果草已经湿润,求降雨的概率是
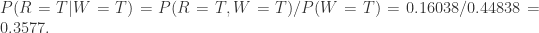
另外一个题目可以用类似的方法进行求解,在此不再赘述。
虽然贝叶斯算法能够计算出条件概率,例如本次故障是由哪些原因导致的,但是这个需要长期收集数据,需要对历史数据进行积累,才能通过人工或者统计的方法得到以上表格的条件概率。但是在实际的环境中是较难获取这些数据的,需要大数据平台的支持,因此需要探索其他的解决方案。
FluxRank
在本论文中,为了克服贝叶斯网络模型中的一些问题,针对子机异常定位的场景,设计了一套技术方案,作者们称之为 FluxRank。
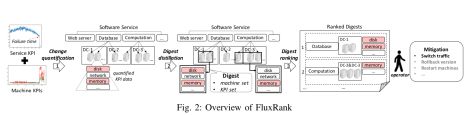
FluxRank 这一模块的触发需要服务指标(Service KPI)的异常,因此需要对服务指标(Service KPI)进行异常检测。这里的服务指标通常指的是业务指标,包括某块 APP 的在线人数,某个接口的成功率,某个视频网站的卡顿数等指标。当服务指标出现了异常的时候,就启动 FluxRank 模块进行异常机器定位。
如果按照人工处理的流程来看,分成几个步骤:
- 异常检测部分:通过设定阈值或者某个简单的规则来进行异常检测,包括服务的 KPI(Service KPI)和机器的 KPI(machine KPIs);
- 手工检查异常的时间段,并且查看在异常的时间段内发生了什么情况;
- 运维人员根据自身的业务经验来对机器的故障程度做人工排序;
- 运维人员根据自身的业务经验来对故障进行处理,并且人工给出处理方案。
那么 FluxRank 所面临的挑战就有以下几点:
- 如何衡量海量 KPIs 的变化程度?在这里不仅有服务的 KPIs,还有机器的 KPIs。而机器的 KPIs 包括内存,硬盘,IO,CPU等诸多固定的指标,那么如何对这些海量的 KPI 曲线进行变化程度的衡量,为后续的指标排序做准备就成为了一个难点;
- 如何对 KPIs 进行异常性或者重要性的聚类,让运维人员能够一眼看出每个聚簇的差异或者异常程度?
- 如何对 KPIs 聚类的结果进行排序?
为了解决以上的问题,FluxRank 的框架有以下几个贡献点:
- 基于 Kenel Density Estimation 用于衡量海量 KPIs 在某一个时间段的变化程度和异常程度;
- 基于上一步生成的异常程度,对诸多机器所形成的特征使用距离公式或者相似度公式,然后使用 DBSCAN 聚类算法来对机器进行聚类;
- 在排序部分,对上一步的机器聚类结果进行排序;
Change Quantification
首先,来看一下 Change Quantification 是怎么样做出来的。这里的 Change Quantification 使用与衡量机器 KPIs 的变化程度,称之为 change degree。Change degree 可以用于 CPU,内存,IO 等诸多机器指标。为了达到衡量变化程度,需要一个非常重要的信息,那就是变化的开始时间,change start time,也就是说在哪个时刻时间序列开始出现了变化。于是在 Change Quantification 部分,就分成两部分:(1)用 absolute derivative 或者 CUSUM 算法获得变化开始时间(change start time);(2)用 Kernel Density Estimation(KDE)来计算变化程度(change degree)。
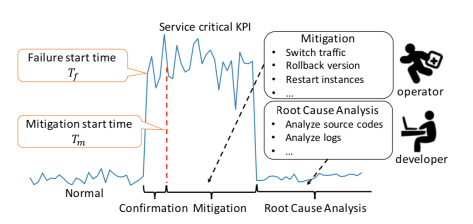
正如上图所示,针对服务 KPIs(ervice KPIs),存在两个关键的时间点,那就是失败开始时间(Failure Start Time)
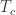


对于服务 KPIs 的异常检测,FluxRank 中提到了两种方法:分别是 absolute derivative 和 CUSUM 方法。
- absolute derivative 方法:个人理解就是对时间序列进行一阶差分操作,然后对一阶差分来做时间序列异常检测,例如 3-sigma 等方法,一旦有明显的变化,就说明当前的时间点出现了突增或者突降;与该方法比较类似的一种方法是:MAD(Median Absolute Deviation)。对于一条时间序列
而言,MAD 定义为
,而每个点的异常程度可以定义为:
当
较大或者较小的时候,表示上涨或者下降的异常程度。通过设置相应的阈值,同样可以获得时间序列的异常开始时间。
- CUSUM 算法也是用于时间序列异常检测的。对于一条时间序列
,可以预估它的目标值(target value)
,通常可以用均值来估计,也需要计算出这条时间序列的标准差
。通常设定
,
。而 Tabular CUSUM 指的是迭代公式
,
,初始值是
。当累计偏差
或者
大于
的时候,表示
出现了异常,也就是 out of control。通过这个值,可以获得时间序列开始异常的时间。
从论文的描述来看,作者是使用 absolute derivative 来做异常检测的,并且定位其异常开始时间的准确率较高。
Change Degree
其次,我们来看一下变化程度(Change Degree)是怎么计算出来的,通过之前的计算,我们已经可以获得一些关键的时间戳,例如 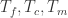


![[T_{c},T_{m}]](https://s0.wp.com/latex.php?latex=%5BT_%7Bc%7D%2CT_%7Bm%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)



为了计算以上概率值,需要简化模型,因此这里需要假设 
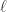
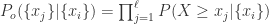
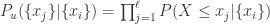
其中 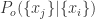
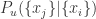
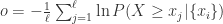

在这里,作者们使用了三种概率分布函数,分别是 Beta 分布(Beta distribution),泊松分布(Poisson distribution),高斯分布(Gaussian distribution)。
Beta 分布的概率密度函数(probabilisty density function)是 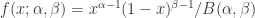

泊松分布的概率密度函数是 
高斯分布的概率密度函数 
根据论文中的陈述,机器 KPIs 分别适用于以下概率分布:

通过以上公式,可以计算出每一个机器的每一个指标的 

Digest Distillation
再来看一下 Digest Distillation 部分,在此部分需要对机器的 KPIs 进行聚类操作;那么就需要构造特征向量和距离函数,再加上聚类算法即可获得结果。
每一个机器的特征向量是由之前计算的 Change Degree 形成的,由于每台机器的 KPIs 都是一样的,因此可以对它们的 KPIs 的 change degree 进行排列。假设每台机器有 

在描述向量的相似性方面,可以使用相关性的系数,包括 Pearson 系数,Kendall tau 系数,Spearman 系数。对于两条时间序列而言,![Y=[y_{1},\cdots,y_{n}]](https://s0.wp.com/latex.php?latex=Y%3D%5By_%7B1%7D%2C%5Ccdots%2Cy_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
Pearson 系数指的是:
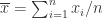
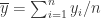
Kendall tau 系数指的是:如果 (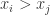





![[\text{(number of concordant pairs)}-\text{(number of disordant paris)}] / [n(n-1)/2]](https://s0.wp.com/latex.php?latex=%5B%5Ctext%7B%28number+of+concordant+pairs%29%7D-%5Ctext%7B%28number+of+disordant+paris%29%7D%5D+%2F+%5Bn%28n-1%29%2F2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
Spearman 系数指的是:通过原始序列变成秩次变量(rank)(从大到小降序排列即可),
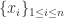
![X'=[x_{1}',\cdots,x_{n}']](https://s0.wp.com/latex.php?latex=X%27%3D%5Bx_%7B1%7D%27%2C%5Ccdots%2Cx_%7Bn%7D%27%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![Y'=[y_{1}',\cdots,y_{n}']](https://s0.wp.com/latex.php?latex=Y%27%3D%5By_%7B1%7D%27%2C%5Ccdots%2Cy_%7Bn%7D%27%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
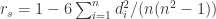


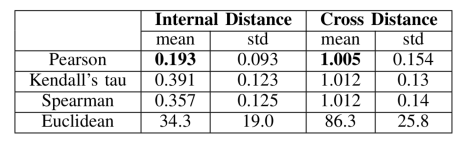
通过作者们的实验,说明 Pearson 系数在这个数据集上效果最佳。在聚类算法的场景下,作者们同样对比了 KMeans,Gaussian Mixture,Hierarchical Clustering,DBSCAN 算法的效果,最后使用了 DBSCAN 的聚类算法。每一个聚类的结果,作者称之为一个 digest,也就是下图的 M1,M2 等聚类结果。
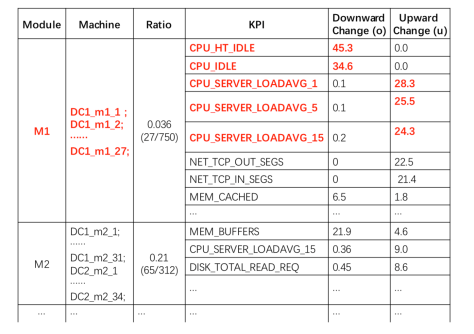
Digest Ranking
最后,就是对聚类结果的排序工作。通过观察会发现:
- 变化开始时间(change start time)
- 不同的故障机器 KPIs 的 change start time 是非常接近的;
- 故障机器的一些 KPIs 的 change degree 是非常大的;
- 故障机器的占比是与故障原因相关的,故障机器越多说明故障越大;
在同一个模块下,如果出现故障机器的占比较大,那么故障将集中于这个模块下,可以通过 ratio 这个指标进行排序工作。
实验数据
在 FluxRank 论文中,作者们收集了 70 个真实的案例,然后根据实验效果获得了结果。

在标记的时候,除了标记异常机器(Root Cause Machines,简称为 RCM)之外,也需要标记相关的指标(Relevant KPI,简称为 RK)。Root Cause Digest(简称为 RCD)把包括两个部分,不仅包括 RCM 的一个聚类结果,还包括聚类结果中的 top-five KPIs。
通过对 FluxRank 进行实验,可以得到如下实验数据:
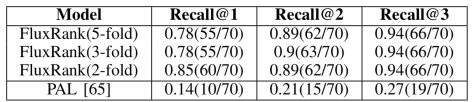
其中 Recall@K 指的是:

参考资料
- FluxRank: A Widely-Deployable Framework to Automatically Localizing Root Cause Machines for Software Service Failure Mitigation,Ping Liu,Yu Chen,Xiaohui Nie,Jing Zhu,Shenglin Zhang,Kaixin Sui,Ming Zhang,Dan Pei,ISSRE 2019, Berlin, Germany, Oct 28-31, 2019。
- Introduction to Statistical Quality Control,6th edition,Douglas C.Montgomery。
- Bayesian Network:https://en.wikipedia.org/wiki/Bayesian_network
