
符号计算
符号计算一直是计算数学的重要领域之一。在开源领域,Python 的 SymPy 就可以支持符号计算。在商业化领域,Maple,Matlab,Mathematica 都能够进行符号计算。它们不仅能够做简单的实数和复数加减乘除,还能够支持数学分析,线性代数,甚至各种各样的大学数学课程。
随着人工智能的进一步发展,深度学习不仅在图像识别,自然语言处理方向上发挥着自身的价值,还在各种各样的领域展示着自己的实用性。在 2019 年底,facebook 两位研究员在 arxiv 上挂出了一篇文章《Deep Learning for Symbolic Mathematics》,在符号计算方向上引入了深度学习的工具。
要想了解符号运算,就要先知道在计算机中,是怎么对数学公式进行表示的。较为常见的表达式形如:


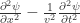
在这里,数学表达式通常都会被表示成树的结构,其中树的内部节点是由算子(operator),函数(function)组成的,叶子节点由数字,变量,函数等组成。例如:
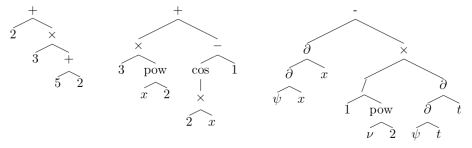
图 1 的三幅图分别对应着上面的三个数学表达式。
在 Python 的 SymPy 工具中,同样可以对数学公式进行展示。其表示方法就是用 sympy.srepr
>>> import sympy >>> x, y = sympy.symbols("x y") >>> expr = sympy.sin(x+y) + x**2 + 1/y - 10 >>> sympy.srepr(expr) "Add(Pow(Symbol('x'), Integer(2)), sin(Add(Symbol('x'), Symbol('y'))), Integer(-10), Pow(Symbol('y'), Integer(-1)))" >>> expr = sympy.sin(x*y)/2 - x**2 + 1/y >>> sympy.srepr(expr) "Add(Mul(Integer(-1), Pow(Symbol('x'), Integer(2))), Mul(Rational(1, 2), sin(Mul(Symbol('x'), Symbol('y')))), Pow(Symbol('y'), Integer(-1)))"
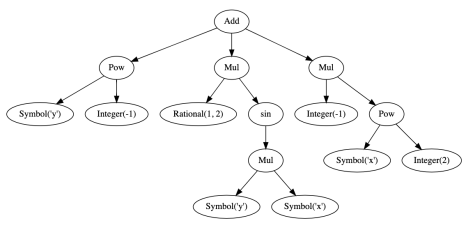
SymPy 的 srepr 函数的输出用树状结构来表示就是形如图 2 这种格式。叶子节点要么是 x,y 这种变量,要么是 -1 和 2 这种整数。对于一元函数而言,例如 sin 函数,就是对应唯一的一个叶子。对于二元函数而言,例如 pow,mul,add,则是对应两个叶子节点。
论文方案
在 Deep Learning for Symbolic Mathematics 这篇论文中,作者们的大致思路是分成以下几步的:
- 生成数据;
- 训练模型;
- 预测结果;
第一步生成数据是为了让深度学习模型是大量的已知样本来做训练;第二步训练模型是用第一步的数据把端到端的深度学习模型进行训练;第三步预测结果是给一个函数或者一个微分方程,使用已经训练好的模型来预测结果,对预测出来的多个结果进行排序,选择最有可能的那个结果作为符号计算的值。
众所周知,深度学习的训练是依赖大量的样本数据的,那么要想用深度学习来解决符号计算的问题,就要解决样本少的问题。在这篇论文中,作者们把精力投入了三个领域,分别是:
- 函数的积分;
- 一阶常微分方程;
- 二阶常微分方程。
在生成数据之前,作者们对数据的范围进行了必要的限制:
- 数学表达式最多拥有 15 个内部节点;
表示叶子节点的值只有 11 个,分别是变量
和
;
表示一元计算只有 15 个,分别是
,
。
表示二元计算只有四个,分别是 +, -, *, /;
意思就是在这个有限的范围内去生成深度学习所需要的数据集。
积分数据的生成
在微积分里面,积分指的是求导的逆运算,那么形如 
第一种方法:前向生成(Forward Generation,简写为 FWD)。主要思路就是在以上的数据范围内随机生成各种各样的方程 

第二种方法:反向生成(Backward Generation,简写为 BWD)。由于积分是求导的逆运算,可以在以上的数据范围内随机生成各种各样的方程 
第三种方法:分部积分(Backward generation with integration by parts,简写为 IBP)。根据分部积分的公式,如果 
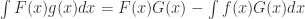
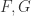
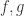
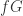

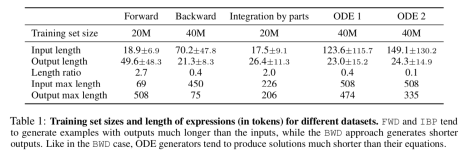
三种方法的比较可以参见表 1,从表 1 可以看出通过分部积分(Integration by parts)所获得的样本表达式相对于前向生成和反向生成都比较长。
一阶常微分方程的生成
一阶常微分方程只有该函数的一阶导数,因此在构造函数的时候,作者们用了一个技巧。在随机生成表达式的时候,叶子节点的元素只从 



- 生成二元函数
- 求解
;
- 对
;
- 简化后得到
,也就是
。
此时,一阶常微分方程的训练数据就是 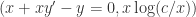
二阶常微分方程不仅可能由该函数的一阶导数,还必须有二阶导数,那么此时就要求导两次:
- 生成三元函数
;
- 求解
得到
;
- 对
;
- 求解
得到
;
- 对
;
- 简化后得到
,也就是
。
那么此时的二阶微分方程的训练数据就是 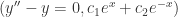
需要注意的事情就是,在生成数据的时候,一旦无法求出 
数据处理
- 数学表达式的简化(expression simplification):例如
可以简化成
,
可以简化成 1。
- 参数的简化(coefficient simplification):例如
可以简化成
。
- 无效表达式的过滤(invalid expression filter):例如
等。
树状结构的表达式,是使用前缀表达式来写成一个句子的。例如 2+3 就写成 + 2 3,2 + x 就写成 + 2 x。
模型训练
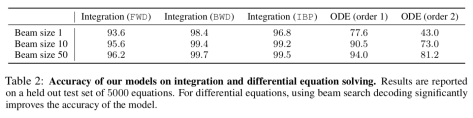
在这里,作者们用了 Transformer 模型,8 attention heads,6 layers,512 个维度,并且发现用更复杂的模型并没有提升其效果。在预测的时候,使用不同的 Beam Size,其准确率是不一样的,在 Beam Size = 50 的时候,效果比较好。参见表 2。
在与其他数学软件的比较中, 作者限制了 Mathematica 的运行时间为 30s。
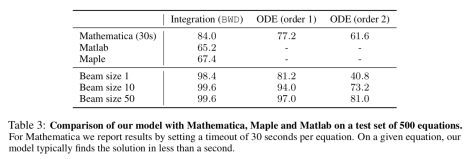
并且举出了几个现有模型能够计算出来,Mathematica 无法计算的例子。

在求解的等价性方面,可以根据 Score 逆序排列,然后这个例子的 Top10 都是等价的。

在使用 SymPy 的过程中,可以获得各种各样的积分表达式如下:

结论
符号计算在 1960 年代末就已经在研究了,有诸多的符号计算软件,例如 Matlab,Mathematica,Maple,PARI,SAGE 等。在这篇论文中,作者们使用标准的 seq2seq 模型来对生成的数据进行训练,然后获得积分,一阶常微分方程,二阶常微分方程的解。在传统符号计算的基础上,开拓了一种新的思路。
