
在机器学习领域,很多时候需要衡量两个对象的相似性,特别是在信息检索,模式匹配等方向上。一般情况下,相似性与距离是都是为了描述两个对象之间的某种性质。但在实际使用的时候,需要根据具体的情况来选择合适的相似度或者距离函数。
相似性与距离
首先,我们来看一下相似性函数的含义。对于两个对象 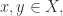


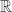

- 自反性:
对于所有的
都成立;
- 对称性:
对于所有的
都成立;
一般情况下,不要求相似度函数具有三角不等式的性质。相似度越大,表示两个元素越相似;相似度越小,表示两个元素越不相似。

其次,我们来看一下距离函数的含义。对于两个对象 
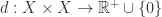

- 自反性:
对于所有的
- 对称性:
对于所有的
- 三角不等式:
对于所有的
都成立。
距离越小,表示两个元素越近;距离越大,表示两个元素越远。
相似度(Similarity)
对于欧式空间 


余弦相似度(Cosine Similarity)
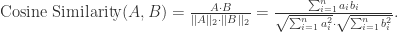
根据 Cauchy 不等式可以得到 Cosine Similarity 的取值范围是
![[-1,1].](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
Pearson 相似度(Pearson Similarity)

其中 
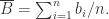

Dice 相似度(Dice Similarity)
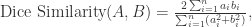
其中 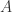
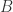
除了欧式空间的点之外,在有的情况下需要对两个集合 
Jaccard 相似度(Jaccard Similarity)
对于集合

其中,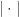
![[0,1].](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
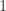

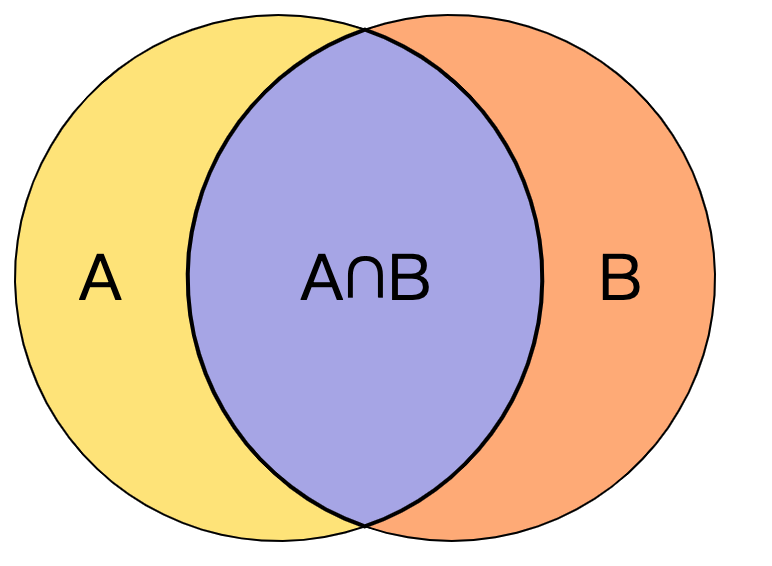
重叠相似度(Overlap Similarity)
对于集合



其中 
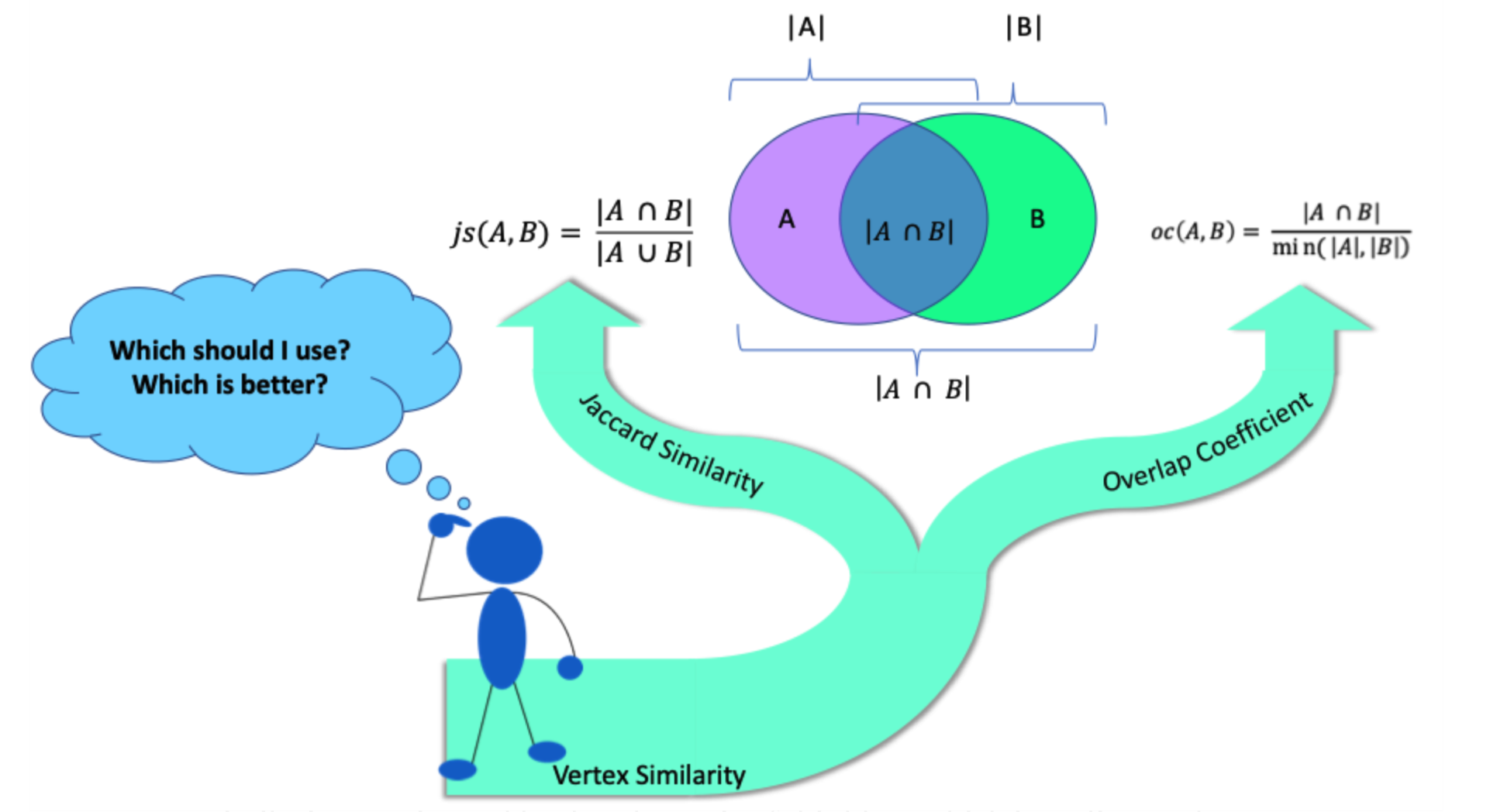
类似的,可以将重叠相似度中的 min 函数换成 max 函数,那就是所谓的 Hub Degressed(HD),用公式来描述就是

它可以用于描述两个集合不重叠的程度。
距离(Distance)
欧氏距离(Euclidean Distance)
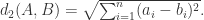
另外,如果将 
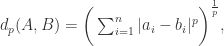
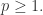

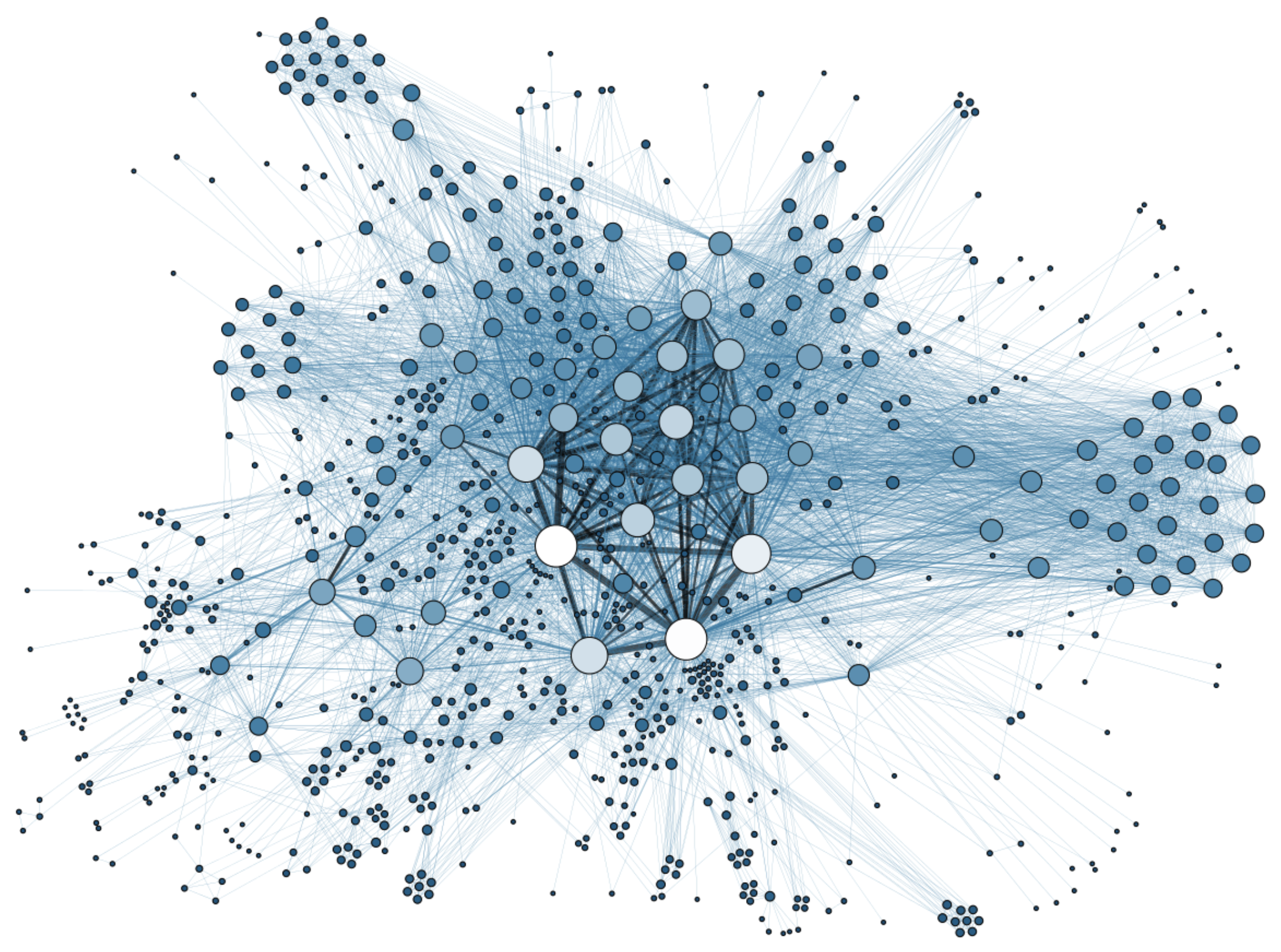
复杂网络中的节点相似性
在复杂网络 



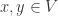
共同邻居相似度(Common Neighbours Similarity)
对于两个顶点

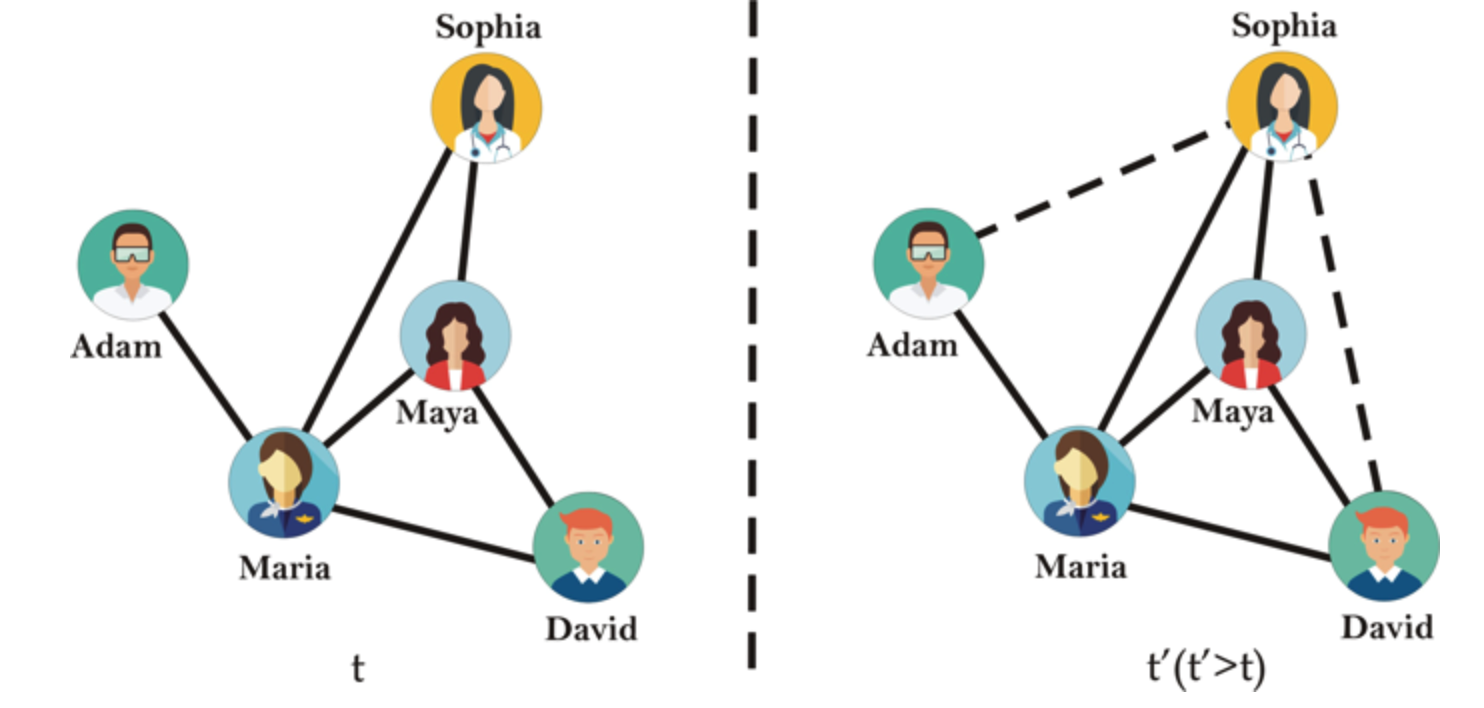
所有邻居相似度(Total Neighbours Similarity)
类似地,将顶点 
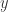
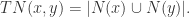
Preferential Attachment

Jaccard 相似度(Jaccard Similarity)
如果将两个节点 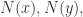

Sorensen-Dice 相似度(Sorensen-Dice Similarity)

该相似度与 Jaccard 相似度有恒等变换,
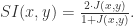
Hub Promoted 相似度
该相似度描述了顶点
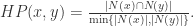
Hub Depressed 相似度

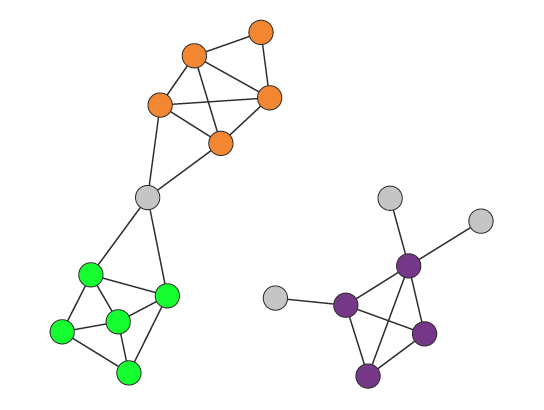
好友度量(Friend Measure)

其中 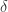



Adamic Adar 相似度(Adamic Adar Similarity)

因此,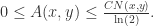


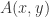


Resource Allocation 相似度(Resource Allocation Similarity)

该相似度函数与 Adamic Adar 相似度类似,只是分母上没有增加对数函数而已。
参考文献:
- Silva, Thiago Christiano, and Liang Zhao. Machine learning in complex networks. Vol. 2016. Switzerland: Springer, 2016.
- Barabási, Albert-László. Network science. Cambridge university press, 2016.
- Wang, Peng, et al. “Link prediction in social networks: the state-of-the-art.” Science China Information Sciences 58.1 (2015): 1-38.
