HIVE 介绍
(1)hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
(2)Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
要理解hive,必须先理解hadoop和mapreduce,如果有不熟悉的童鞋,可以百度一下。
使用hive的命令行接口,感觉很像操作关系数据库,但是hive和关系数据库还是有很大的不同,下面我就比较下hive与关系数据库的区别,具体如下:
- hive和关系数据库存储文件的系统不同,hive使用的是hadoop的HDFS(hadoop的分布式文件系统),关系数据库则是服务器本地的文件系统;
- hive使用的计算模型是mapreduce,而关系数据库则是自己设计的计算模型;
- 关系数据库都是为实时查询的业务进行设计的,而hive则是为海量数据做数据挖掘设计的,实时性很差;实时性的区别导致hive的应用场景和关系数据库有很大的不同;
- Hive很容易扩展自己的存储能力和计算能力,这个是继承hadoop的,而关系数据库在这个方面要比数据库差很多。
以上都是从宏观的角度比较hive和关系数据库的区别,下面介绍一下在实际工作中遇到的一些常用语句和方法。
HIVE 基础
hive 常用命令
假设有数据库 fm_data,里面有表格 shield_fm_feature_item_ctr
show databases; //列出数据库
desc database fm_data; // 展示数据库 fm_data 的信息
use fm_data; // 使用某个数据库 fm_data\
set hive.cli.print.current.db=true; 显示列头
set hive.cli.print.current.db=false; 关闭列头
show tables; // 展示这个数据库里面的所有表格
show tables in fm_data; // 展示数据库 fm_data 里面的所有表格
show tables like ‘*ctr*’; // 模糊查找
show create table shield_fm_feature_item_ctr; // 获得表格 shield_fm_feature_item_ctr 的建表语句,其中包括表格的字段,HDFS 的 location 等信息
desc shield_fm_feature_item_ctr; // 展示表格 shield_fm_feature_item_ctr 的字段以及字段类型
desc formatted shield_fm_feature_item_ctr; // 详细描述表格 shield_fm_feature_item_ctr,包括表格的结构,所在的 database,owner,location,表格的类型 (Managed Table or External Table),存储信息等
内部表与外部表
hive 的表格分两种,一种是 managed tables,另一种是 external tables。hive 创建表格时,默认创建的是 managed table,这种表会把数据移动到自己的数据仓库目录下;另外一种是 external tables,它关联的数据不是 hive 维护的,也不在 hive 的数据仓库内。
创建内部表格和外部表格:
create table test(name string);
create external table test(name string); 创建外部表格需要加上external;
修改表属性:
alter table test set tblproperties (‘EXTERNAL’=’TRUE’); 内部表转外部表
alter table test set tblproperties (‘EXTERNAL’=’FALSE’); 外部表转内部表
归纳一下Hive中表与外部表的区别:
1. 在导入数据到外部表,数据并没有移动到自己的数据仓库目录下(如果指定了location的话),也就是说外部表中的数据并不是由它自己来管理的!而内部表则不一样;
2. 在删除内部表的时候,Hive将会把属于表的元数据和数据全部删掉;而删除外部表的时候,Hive仅仅删除外部表的元数据,数据是不会删除的!换言之,内部表DROP时会删除HDFS上的数据;外部表DROP时不会删除HDFS上的数据。
3. 在创建内部表或外部表时加上location 的效果是一样的,只不过表目录的位置不同而已,加上partition用法也一样,只不过表目录下会有分区目录而已,load data local inpath直接把本地文件系统的数据上传到hdfs上,有location上传到location指定的位置上,没有的话上传到hive默认配置的数据仓库中。
4. 使用场景:内部表:HIVE中间表,结果表,一般不需要从外部(如本地文件,HDFS上 load 数据)的情况;外部表:源表,需要定期将外部数据映射到表格中。
创建表格
create table test1 like test; 只是复制了表的结构,并没有复制内容;
create table test2 as select name from test; 从其他表格查询,再创建表格;
CREATE EXTERNAL TABLE t_zr9558 (
id INT,
ip STRING COMMENT ‘访问者IP’,
avg_view_depth DECIMAL(5,1),
bounce_rate DECIMAL(6,5)
) COMMENT ‘test.com’
PARTITIONED BY (day STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘,’
STORED AS textfile
LOCATION ‘hdfs://cdh5/tmp/zr9558/’;
(1)关键字EXTERNAL:表示该表为外部表,如果不指定EXTERNAL关键字,则表示内部表
(2)关键字COMMENT:为表和列添加注释
(3)关键字PARTITIONED BY:表示该表为分区表,分区字段为day,类型为string
(4)关键字ROW FORMAT DELIMITED:指定表的分隔符,通常后面要与以下关键字连用:
FIELDS TERMINATED BY ‘,’ //指定每行中字段分隔符为逗号
LINES TERMINATED BY ‘\n’ //指定行分隔符
COLLECTION ITEMS TERMINATED BY ‘,’ //指定集合中元素之间的分隔符
MAP KEYS TERMINATED BY ‘:’ //指定数据中Map类型的Key与Value之间的分隔符
(5)关键字STORED AS:指定表在HDFS上的文件存储格式,可选的文件存储格式有:
TEXTFILE //文本,默认值
SEQUENCEFILE // 二进制序列文件
RCFILE //列式存储格式文件 Hive0.6以后开始支持
ORC //列式存储格式文件,比RCFILE有更高的压缩比和读写效率,Hive0.11以后开始支持
PARQUET //列出存储格式文件,Hive0.13以后开始支持
(6)关键词LOCATION:指定表在HDFS上的存储位置。
注:hive 建表的时候默认的分隔符是’\001’,如果建表的时候没有指定分隔符,load文件的时候的分隔符是’\001’。如果需要在建表的时候指定分隔符,需要如下操作:
create table pokes(foo int,bar string)
row format delimited fields terminated by ‘\t’ lines terminated by ‘\n’ stored as textfile;
load data local inpath ‘/root/pokes.txt’ into table pokes;
修改表格
alter table shield_fm_feature_item_ctr add columns ( reporttime STRING COMMENT ‘上报日期时间’) //为表格增加列
alter table test rename to test2; //修改表名
alter table test add partition (day=20160301); //增加分区
alter table test drop partition (day=20160301); //删除分区
alter table test partition (day=20160301) rename to partition (day=20160302); //修改分区
load data local inpath ‘/liguodong/hivedata/datatest’ overwrite into table test; // 从文件加载数据:覆盖原来数据
load data local inpath ‘/liguodong/hivedata/datatest’ into table test; // 从文件加载数据:添加数据
insert overwrite directory ‘tmp/csl_rule_cfg’ select a.* from test a; // 导出数据到文件
查询和分析数据
dfs -ls /user/hive/warehouse/fm_data.db/shield_fm_feature_item_ctr // 查看 hdfs 文件信息
set hive.cli.print.header=true; 显示列名称
set hive.cli.print.header=false; 不显示列名称
(i)基础操作
假设表格 shield_fm_feature_item_ctr 的格式是:owner (string), key (string), value (int), day (bigint);
select * from shield_fm_feature_item_ctr; // 查找数据
select * from shield_fm_feature_item_ctr limit 10; // 查找10行数据
select * from shield_fm_feature_item_ctr where day=20160301; //查询 day=20160301 的数据
select * from shield_fm_feature_item_ctr where day >= 20160301 and day<=20160302; //查询 day>=20160301 并且 day<=20160302 的数据
select * from shield_fm_feature_item_ctr where day = 20160301 or day =20160302; //查询 day=20160301 或者 day=20160302 的数据
select * from shield_fm_feature_item_ctr where day=20160301 order by value; // 按照value 的值增序排列
select * from shield_fm_feature_item_ctr where day=20160301 order by value desc; // 按照 value 的值降序排列
insert [overwrite] into table shield_fm_feature_item_ctr partition (day=20160301) values (‘20032′,’key_20032’,1.0) // 不使用overwrite是往表格里追加一条数据,如果使用overwrite就是覆盖整个表格。
(ii)高级操作
select * from shield_fm_feature_item_ctr where day between 20160301 and 20160302; //查询表格中从20160301到20160302的数据
JOIN 操作:
inner join: 在表格中至少存在一个匹配时,inner join 的关键字返回行;注:inner join 和 join 是相同的。
left join: 会从左边的表格返回所有的行,即使在右边的表格中没有匹配的行。
right join:会从右边的表格返回所有的行,即使在左边的表格中没有匹配的行。
full join:只要其中的一张表存在匹配,full join 就会返回行。在某些数据库中,full join 也称作 full outer join。
union:用于合并两个或者多个 select 语句的结果集。
is NULL & is not NULL:来判断某个字段是否是空集。
(iii)聚合函数
group by:通常和聚合函数一起使用,根据一个或者多个列对结果进行分组
常见的聚合函数有:
AVG:返回数列值的平均值
COUNT:返回一列值的数目
MAX/MIN:返回一列值的最大值/最小值
SUM:返回数列值的总和
(iv)数值函数:Scalar Functions
MOD(x,y):取模 x%y
ln(double a):返回给定数值的自然对数
power(double a, double b):返回某数的乘幂
sqrt(double a):开平方
sin/cos/asin/acos:三角函数
(v)字符串函数
字符串函数(替换,拼接,逆序等)
(vi)日期函数
进行unix的时间转换等
hive命令行操作
[avilazhang@hadoop-bigdata-hive ~]$ hive -e ‘select * from fm_data.shield_fm_feature_item_ctr where day=20160508;’
[avilazhang@hadoop-bigdata-hive ~]$ hive -S -e ‘select * from fm_data.shield_fm_feature_item_ctr where day=20160508;’ 终端的输出不会有mapreduce的进度,只会输出结果。
执行sql文件:hive -f hive_sql.sql
杀掉任务
杀掉某个任务:kill hadoop jobs:依赖于版本:
如果 version<2.3.0 : hadoop job -kill $jobId
获取所有运行的 jobId: hadoop job -list
如果 version>=2.3.0 : yarn application -kill $ApplicationId
获取所有运行的 jobId: yarn application -list
FS Shell
调用文件系统 (FS)Shell 命令应使用 bin/hadoop fs <args>的形式。 所有的的 FS shell 命令使用 URI路径作为参数。URI 格式是 scheme://authority/path。对HDFS文件系统,scheme 是 hdfs,对本地文件系统,scheme 是 file。其中 scheme 和 authority 参数都是可选的,如果未加指定,就会使用配置中指定的默认 scheme。一个 HDFS 文件或目录比如 /parent/child 可以表示成 hdfs://namenode:namenodeport/parent/child,或者更简单的 /parent/child(假设你配置文件中的默认值是 namenode:namenodeport)。大多数 FS Shell 命令的行为和对应的 Unix Shell 命令类似,不同之处会在下面介绍各命令使用详情时指出。出错信息会输出到 stderr,其他信息输出到 stdout。
fs 最常用的命令:
hadoop fs -ls hdfs_path //查看HDFS目录下的文件和子目录
hadoop fs -mkdir hdfs_path //在HDFS上创建文件夹
hadoop fs -rm hdfs_path //删除HDFS上的文件
hadoop fs -rmr hdfs_path //删除HDFS上的文件夹
hadoop fs -put local_file hdfs_path //将本地文件copy到HDFS上
hadoop fs -get hdfs_file local_path //复制HDFS文件到本地
hadoop fs -cat hdfs_file //查看HDFS上某文件的内容
fs 查看目录下文件夹或者文件的大小:
//单位Byte:
hadoop fs -du / | sort -n
//单位MB:
hadoop fs -du / | awk -F ‘ ‘ ‘{printf “%.2fMB\t\t%s\n”, $1/1024/1024,$2}’ | sort -n
//单位GB,大于1G:
hadoop fs -du / | awk -F ‘ ‘ ‘{num=$1/1024/1024/1024; if(num>1){printf “%.2fGB\t\t%s\n”, num, $2} }’ | sort -n
sort -n 表示按照文件大小,从小到大排列顺序。
hadoop fs -du -h hdfs_path
使用-h显示hdfs对应路径下每个文件夹和文件的大小,文件的大小用方便阅读的形式表示,例如用64M代替67108864
其余FS Shell命令:
hadoop fs -cat hdfs_path //将路径指定的文件内容输出到 stdout
hadoop fs -tail hdfs_path //将文件尾部1k字节的内容输出到 stdout
hadoop fs -stat hdfs_path //返回指定路径的统计信息
hadoop fs -du hdfs_path //返回目录中所有文件的大小,或者只指定一个文件时,显示该文件的大小
详细可见:https://hadoop.apache.org/docs/r1.0.4/cn/hdfs_shell.html
DistCp 概述
DistCp(分布式拷贝)是用于大规模集群内部和集群之间拷贝的工具。 它使用Map/Reduce实现文件分发,错误处理和恢复,以及报告生成。 它把文件和目录的列表作为map任务的输入,每个任务会完成源列表中部分文件的拷贝。 由于使用了Map/Reduce方法,这个工具在语义和执行上都会有特殊的地方。 这篇文档会为常用DistCp操作提供指南并阐述它的工作模型。
详细可见:https://hadoop.apache.org/docs/r1.0.4/cn/distcp.html

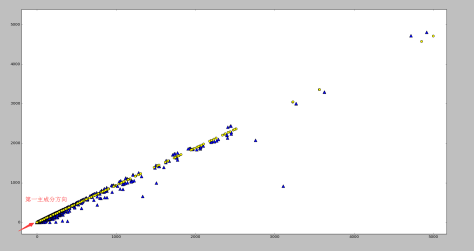
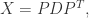
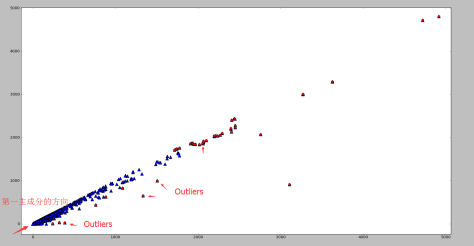
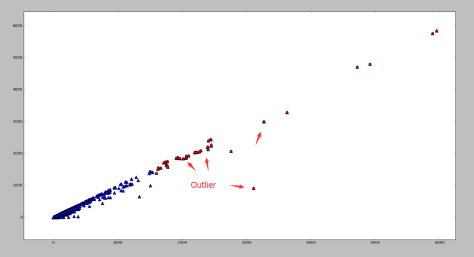
 。从图像上看,一个特征向量可以看成 2 维平面上面的一条线,或者高维空间里面的一个超平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,可以把对角矩阵 D 中的特征值进行从大到小的排序,矩阵 P 的每一列也进行相应的调整,保证 P 的第 i 列对应的是 D 的第 i 个对角值。
。从图像上看,一个特征向量可以看成 2 维平面上面的一条线,或者高维空间里面的一个超平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,可以把对角矩阵 D 中的特征值进行从大到小的排序,矩阵 P 的每一列也进行相应的调整,保证 P 的第 i 列对应的是 D 的第 i 个对角值。

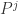 是矩阵 P 的前 j 列,也就是说
是矩阵 P 的前 j 列,也就是说 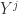 是一个 (N,j) 维的矩阵。如果考虑拉回映射的话(也就是从主成分空间映射到原始空间),重构之后的数据集合是
是一个 (N,j) 维的矩阵。如果考虑拉回映射的话(也就是从主成分空间映射到原始空间),重构之后的数据集合是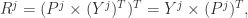
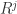 是使用 top-j 的主成分进行重构之后形成的数据集,是一个 (N,p) 维的矩阵。
是使用 top-j 的主成分进行重构之后形成的数据集,是一个 (N,p) 维的矩阵。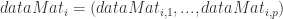 的异常值分数(outlier score)如下:
的异常值分数(outlier score)如下: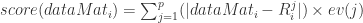
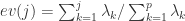
 指的是 Euclidean 范数, ev(j) 表示的是 top-j 的主成分在所有主成分中所占的比例,并且特征值是按照从大到小的顺序排列的。因此,ev(j) 是递增的序列,这就表示 j 越高,越多的方差就会被考虑在 ev(j) 中,因为是从 1 到 j 的求和。在这个定义下,偏差最大的第一个主成分获得最小的权重,偏差最小的最后一个主成分获得了最大的权重 1。根据 PCA 的性质,异常点在最后一个主成分上有着较大的偏差,因此可以获得更高的分数。
指的是 Euclidean 范数, ev(j) 表示的是 top-j 的主成分在所有主成分中所占的比例,并且特征值是按照从大到小的顺序排列的。因此,ev(j) 是递增的序列,这就表示 j 越高,越多的方差就会被考虑在 ev(j) 中,因为是从 1 到 j 的求和。在这个定义下,偏差最大的第一个主成分获得最小的权重,偏差最小的最后一个主成分获得了最大的权重 1。根据 PCA 的性质,异常点在最后一个主成分上有着较大的偏差,因此可以获得更高的分数。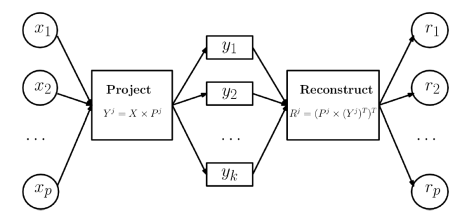
 ,那么可以计算出这 n 个点的均值
,那么可以计算出这 n 个点的均值  和方差
和方差 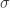 。均值和方差分别被定义为:
。均值和方差分别被定义为: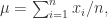

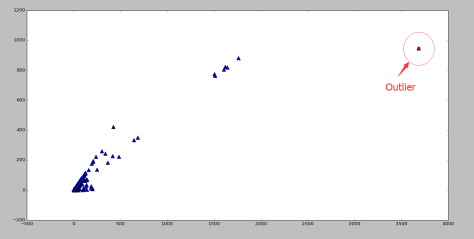
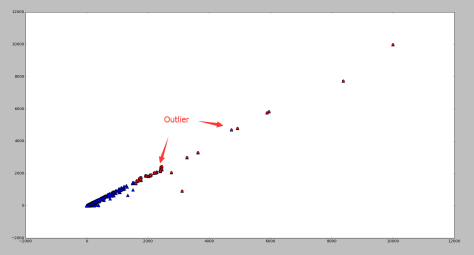
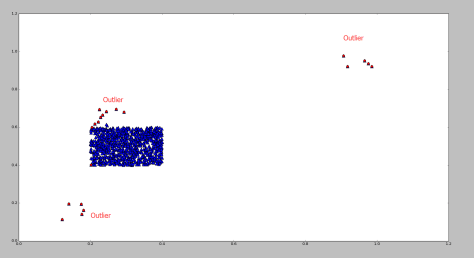
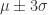 包含了99.7% 的数据,如果某个值距离分布的均值
包含了99.7% 的数据,如果某个值距离分布的均值  ,那么这个值就可以被简单的标记为一个异常点(outlier)。
,那么这个值就可以被简单的标记为一个异常点(outlier)。 ,那么可以计算每个维度的均值和方差
,那么可以计算每个维度的均值和方差  具体来说,对于
具体来说,对于  ,可以计算
,可以计算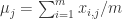
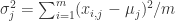
 ,可以计算概率
,可以计算概率 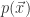 如下:
如下:
 ,可以计算 n 维的均值向量
,可以计算 n 维的均值向量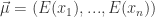
 的协方差矩阵:
的协方差矩阵:![\Sigma=[Cov(x_{i},x_{j})], i,j \in \{1,...,n\}](https://s0.wp.com/latex.php?latex=%5CSigma%3D%5BCov%28x_%7Bi%7D%2Cx_%7Bj%7D%29%5D%2C+i%2Cj+%5Cin+%5C%7B1%2C...%2Cn%5C%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

 是均值向量,那么对于数据集 D 中的其他对象
是均值向量,那么对于数据集 D 中的其他对象  ,从
,从 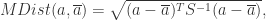
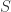 是协方差矩阵。
是协方差矩阵。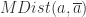 是数值,可以对这个数值进行排序,如果数值过大,那么就可以认为点
是数值,可以对这个数值进行排序,如果数值过大,那么就可以认为点  进行离群点检测,如果
进行离群点检测,如果 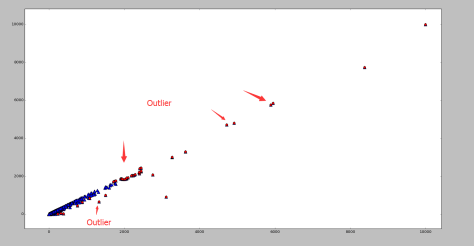
 统计量检测多元离群点
统计量检测多元离群点 ,
,
 是
是  是所有对象在第 i 维的均值,n 是维度。如果对象
是所有对象在第 i 维的均值,n 是维度。如果对象 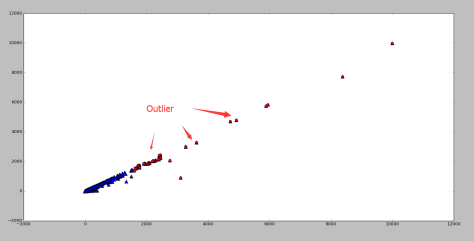
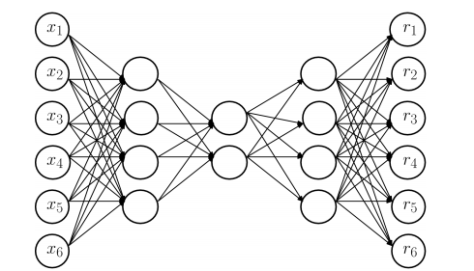

 ,其中
,其中  表示第 k 层中第 i 个神经元的输入,
表示第 k 层中第 i 个神经元的输入, 表示第 k 层使用的激活函数。那么
表示第 k 层使用的激活函数。那么
 是第 k 层中第 j 个神经元的输出,
是第 k 层中第 j 个神经元的输出, 是第 k 层神经元的个数。对于第二层和第四层而言 (k=2,4),激活函数选择为
是第 k 层神经元的个数。对于第二层和第四层而言 (k=2,4),激活函数选择为
 是一个参数,通常假设为1。对于中间层 (k=3) 而言,激活函数是一个类阶梯 (step-like) 函数。有两个参数 N 和
是一个参数,通常假设为1。对于中间层 (k=3) 而言,激活函数是一个类阶梯 (step-like) 函数。有两个参数 N 和  ,N 表示阶梯的个数,
,N 表示阶梯的个数,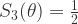 +
+ .
. ,
, . 那么
. 那么  就如下图所示。
就如下图所示。
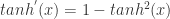 和
和  。因此有学者指出 [1],使用三个隐藏层是没有必要的,使用1个或者2个隐藏层的神经网络也能够得到类似的结果;同样,没有必要使用
。因此有学者指出 [1],使用三个隐藏层是没有必要的,使用1个或者2个隐藏层的神经网络也能够得到类似的结果;同样,没有必要使用 
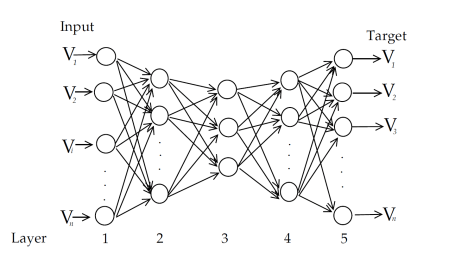
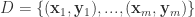 ,其中有 m 个样本,并且输入和输出是一样的值。换句话说,也就是 n 维向量
,其中有 m 个样本,并且输入和输出是一样的值。换句话说,也就是 n 维向量 .
.![q=[(n+1)/2]](https://s0.wp.com/latex.php?latex=q%3D%5B%28n%2B1%29%2F2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,这里的 [] 表示 Gauss 取整函数。输出层第 j 个神经元的阈值使用
,这里的 [] 表示 Gauss 取整函数。输出层第 j 个神经元的阈值使用  表示,隐藏层第 h 个神经元的阈值使用
表示,隐藏层第 h 个神经元的阈值使用 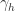 表示。输入层第 i 个神经元与隐藏层第 h 个神经元之间的连接权重是
表示。输入层第 i 个神经元与隐藏层第 h 个神经元之间的连接权重是  , 隐藏层第 h 个神经元与输出层第 j 个神经元之间的连接权重是
, 隐藏层第 h 个神经元与输出层第 j 个神经元之间的连接权重是  其中
其中 



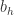 是隐藏层第 h 个神经元的输出,
是隐藏层第 h 个神经元的输出,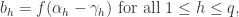
 是激活函数。写成矩阵形式就是:
是激活函数。写成矩阵形式就是: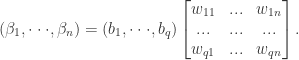
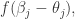 其中
其中 
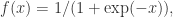 那么直接通过导数计算可以得到
那么直接通过导数计算可以得到 
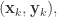 通过神经网络得到的输出是
通过神经网络得到的输出是  并且
并且  对于
对于 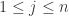 都成立。那么神经网络在训练集
都成立。那么神经网络在训练集  的均方误差是
的均方误差是
 整体的误差是
整体的误差是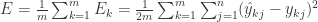
 +
+
 来获得更新规则,下面来推导每一个参数的更新规则。对于
来获得更新规则,下面来推导每一个参数的更新规则。对于  计算梯度
计算梯度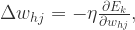
 先影响到第 j 个输出层神经元的输入值
先影响到第 j 个输出层神经元的输入值  再影响到第 j 个输出层神经元的输出值
再影响到第 j 个输出层神经元的输出值  ,最后影响到
,最后影响到 
 可以得到
可以得到  对于
对于  可以得到
可以得到 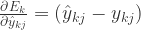 .
. 和
和  可以得到
可以得到 

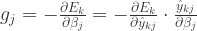

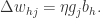
 .
.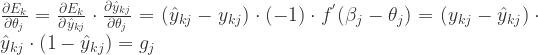




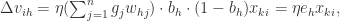 其中
其中 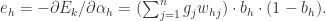

 +
+ 并且更新的规则如下:
并且更新的规则如下:



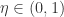 控制着算法每一轮迭代中的更新步长,若步长太大则容易振荡,太小则收敛速度过慢,需要人工调整学习率。 对每个训练样例,BP 算法执行下面的步骤:先把输入样例提供给输入层神经元,然后逐层将信号往前传,直到计算出输出层的结果;然后根据输出层的误差,再将误差逆向传播至隐藏层的神经元,根据隐藏层的神经元误差来对连接权和阈值进行迭代(梯度下降法)。该迭代过程循环进行,直到达到某个停止条件为止。
控制着算法每一轮迭代中的更新步长,若步长太大则容易振荡,太小则收敛速度过慢,需要人工调整学习率。 对每个训练样例,BP 算法执行下面的步骤:先把输入样例提供给输入层神经元,然后逐层将信号往前传,直到计算出输出层的结果;然后根据输出层的误差,再将误差逆向传播至隐藏层的神经元,根据隐藏层的神经元误差来对连接权和阈值进行迭代(梯度下降法)。该迭代过程循环进行,直到达到某个停止条件为止。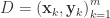 和学习率
和学习率 

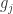
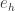
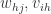 与阈值
与阈值 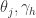
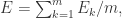 其中 m 是训练集合中样本的个数。不过,标准的 BP 算法每次仅针对一个训练样例更新连接权重和阈值,也就是说,标准 BP 算法的更新规则是基于单个的
其中 m 是训练集合中样本的个数。不过,标准的 BP 算法每次仅针对一个训练样例更新连接权重和阈值,也就是说,标准 BP 算法的更新规则是基于单个的 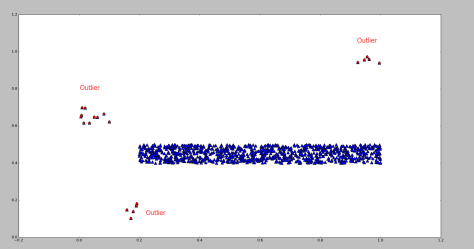
![E=\sum_{i=1}^{K}\sum_{p \in C[i]} dist(p, c[i])^{2}](https://s0.wp.com/latex.php?latex=E%3D%5Csum_%7Bi%3D1%7D%5E%7BK%7D%5Csum_%7Bp+%5Cin+C%5Bi%5D%7D+dist%28p%2C+c%5Bi%5D%29%5E%7B2%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
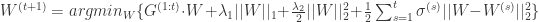

 上式等价于
上式等价于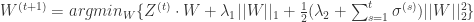
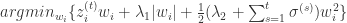

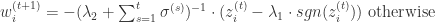
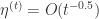 ,意味着学习率是一个正数并且逐渐递减,对每一个维度都是一样的。而在 FTRL 算法里面,每个维度的学习率是不一样的。如果特征 A 比特征 B变化快,那么在维度 A 上面的学习率应该比维度 B 上面的学习率下降得更快。在 FTRL 中,维度 i 的学习率是这样定义的:
,意味着学习率是一个正数并且逐渐递减,对每一个维度都是一样的。而在 FTRL 算法里面,每个维度的学习率是不一样的。如果特征 A 比特征 B变化快,那么在维度 A 上面的学习率应该比维度 B 上面的学习率下降得更快。在 FTRL 中,维度 i 的学习率是这样定义的:
 , 所以
, 所以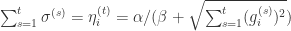
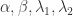 ,初始化
,初始化  (2)for
(2)for 
 for
for 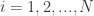
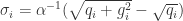
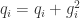 // equals to
// equals to 



 end
end
end
end
 是 sigmoid 函数,
是 sigmoid 函数, ,需要预估
,需要预估 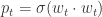 ,那么 LogLoss 函数是
,那么 LogLoss 函数是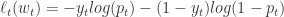 ,
,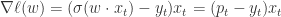 ,所以 Logistic Regression 的 FTRL 算法就是:
,所以 Logistic Regression 的 FTRL 算法就是: // gradient of loss function
// gradient of loss function
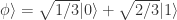 , 那么 p(0)=1/3,p(1)=2/3。如果测量的结果是0,那么这个 qubit 的状态就是0,换言之,
, 那么 p(0)=1/3,p(1)=2/3。如果测量的结果是0,那么这个 qubit 的状态就是0,换言之,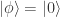 ;如果测量的结果是1,那么这个 qubit 的状态也就变成了1,换言之,
;如果测量的结果是1,那么这个 qubit 的状态也就变成了1,换言之,  。
。 ,如果我们对第一个 qubit 使用 Hadamard Gate,那么状态就会变成
,如果我们对第一个 qubit 使用 Hadamard Gate,那么状态就会变成 ,其中
,其中 ,
,  。也就是说每一对
。也就是说每一对  和
和  都会被映射成
都会被映射成  和
和 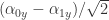 。因此就证明了,仅仅对 n 个量子比特中的第一位进行了 Hadamard gate 运算,所有的 2^n 个系数都会改变。这个就是在 quantum fourier transform 算法中达到指数级别加速的基础。
。因此就证明了,仅仅对 n 个量子比特中的第一位进行了 Hadamard gate 运算,所有的 2^n 个系数都会改变。这个就是在 quantum fourier transform 算法中达到指数级别加速的基础。 ,
, .
.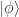 . Then we have
. Then we have 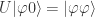 ,
, 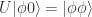 from the assumption of U. Let
from the assumption of U. Let 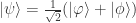 , we get
, we get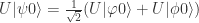 .
.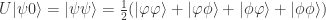
 ,这里
,这里 

![\rho_{XY}=cov(X,Y)/(\sigma_{X}\sigma_{Y})\in [-1,1]](https://s0.wp.com/latex.php?latex=%5Crho_%7BXY%7D%3Dcov%28X%2CY%29%2F%28%5Csigma_%7BX%7D%5Csigma_%7BY%7D%29%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 ,那么说明两个变量是线性反相关的;如果
,那么说明两个变量是线性反相关的;如果  ,那么说明两个变量是线性相关的。不过需要主要的是,即使
,那么说明两个变量是线性相关的。不过需要主要的是,即使  ,也只是说明两个变量是线性无关的,并不能推出它们之间是独立的。此时知道的就是一个线性分类器并不能把这个特征的正负样本分开,需要把该特征和其他特征交叉或者做其余的特征运算,形成一个或者多个新的特征,让这些新的特征发挥新的价值,做好进一步的分类工作。
,也只是说明两个变量是线性无关的,并不能推出它们之间是独立的。此时知道的就是一个线性分类器并不能把这个特征的正负样本分开,需要把该特征和其他特征交叉或者做其余的特征运算,形成一个或者多个新的特征,让这些新的特征发挥新的价值,做好进一步的分类工作。


 subject to
subject to 

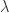 时,这两种描述是等价的。
时,这两种描述是等价的。

 }
}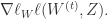
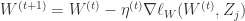 }
}
 是一个标量,且
是一个标量,且  ,为 L1 正则化参数。
,为 L1 正则化参数。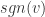 是符号函数,如果
是符号函数,如果  是一个向量,那么
是一个向量,那么  。
。 是学习率,通常假设为
是学习率,通常假设为  的函数。
的函数。 代表了第 t 次迭代中损失函数的梯度,由于 OGD 每次仅根据观测到的一个样本进行权重更新,因此也不再使用区分样本的下标 j。
代表了第 t 次迭代中损失函数的梯度,由于 OGD 每次仅根据观测到的一个样本进行权重更新,因此也不再使用区分样本的下标 j。 是分段函数,
是分段函数,


 并且
并且  。如果
。如果  。
。
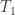 定义为:
定义为:![T_{1}(v_{i},\alpha,\theta)=\max(0,v_{i}-\alpha) \text{ if } v_{i}\in [0,\theta]](https://s0.wp.com/latex.php?latex=T_%7B1%7D%28v_%7Bi%7D%2C%5Calpha%2C%5Ctheta%29%3D%5Cmax%280%2Cv_%7Bi%7D-%5Calpha%29+%5Ctext%7B+if+%7D+v_%7Bi%7D%5Cin+%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


 ,并且
,并且 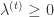 。Truncated Gradient 方法同样是以 k 作为窗口,每进行 k 步就进行一次截断操作。当 t/k 不是整数时,
。Truncated Gradient 方法同样是以 k 作为窗口,每进行 k 步就进行一次截断操作。当 t/k 不是整数时, ,当 t/k 是整数时,
,当 t/k 是整数时, 。从上面的公式可以看出,
。从上面的公式可以看出,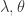 决定了 W 的稀疏程度,如果
决定了 W 的稀疏程度,如果 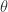 都很大,那么稀疏性就会越强。特别的,当
都很大,那么稀疏性就会越强。特别的,当  时,此时只需要控制一个参数就可以控制稀疏性。
时,此时只需要控制一个参数就可以控制稀疏性。 for t = 1,2,3,... 计算
for t = 1,2,3,... 计算  for all
for all 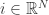 .
(ii)当 t/k 是整数时,采取截断技术。
.
(ii)当 t/k 是整数时,采取截断技术。
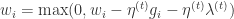 , if
, if ![(w_{i}-\eta^{(t)}g_{i})\in[0,\theta]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
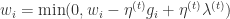 , else if
, else if ![(w_{i}-\eta^{(t)}g_{i})\in[-\theta,0]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B-%5Ctheta%2C0%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 , otherwise
return W.
, otherwise
return W. 和
和 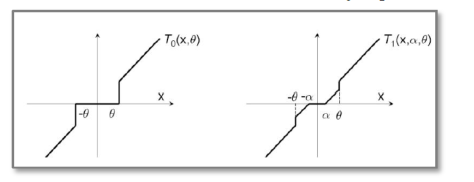
 ,截断梯度法就可以变成简单截断法。从公式上也可以通过计算直接得出。
,截断梯度法就可以变成简单截断法。从公式上也可以通过计算直接得出。
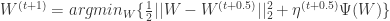

 ,如果
,如果  存在一个最优解,那么可以推断 0 向量一定属于
存在一个最优解,那么可以推断 0 向量一定属于  的次梯度集合:
的次梯度集合: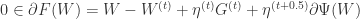 .
.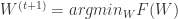 , 那么可以得到权重更新的另外一种形式:
, 那么可以得到权重更新的另外一种形式: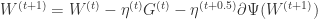
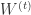 有关,还和自己
有关,还和自己 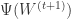 有关。这也许就是”前向后向切分”这个名称的由来。
有关。这也许就是”前向后向切分”这个名称的由来。 是 L1 范数,中间向量是
是 L1 范数,中间向量是  , 并且参数
, 并且参数 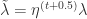 ,那么公式就可以展开得到
,那么公式就可以展开得到
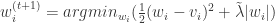 for all $latex 1\leq i \leq N$.
for all $latex 1\leq i \leq N$. 是
是  的最优解,那么
的最优解,那么  .
. ,那么
,那么  , 这与条件矛盾。
, 这与条件矛盾。
 for all
for all 
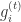 是梯度
是梯度 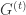 在第 i 个维度的分量。
在第 i 个维度的分量。 , 则有
, 则有  意思就是如果这次训练产生梯度的变化不足以令权重值发生足够大的变化时,就认为在这次训练中该维度不够重要,应该强制其权重是0.
意思就是如果这次训练产生梯度的变化不足以令权重值发生足够大的变化时,就认为在这次训练中该维度不够重要,应该强制其权重是0. ,那么则有
,那么则有
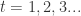 , 计算
, 计算  ,
, for all
for all  (3)Return W
(3)Return W ,可以得到 L1-FOBOS 与 Truncated Gradient 完全一致,换句话说 L1-FOBOS 是 Truncated Gradient 在一些特定条件下的形式。
,可以得到 L1-FOBOS 与 Truncated Gradient 完全一致,换句话说 L1-FOBOS 是 Truncated Gradient 在一些特定条件下的形式。
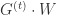 指的是向量
指的是向量  是一个严格凸函数,
是一个严格凸函数, 是一个非负递增序列。
是一个非负递增序列。 包括了之前所有梯度的平均值。
包括了之前所有梯度的平均值。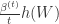 。
。 ;
; ,i.e.
,i.e.  是一个非负递增序列。那么 RDA 算法就可以写成:
是一个非负递增序列。那么 RDA 算法就可以写成:



 if
if 
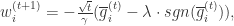 otherwise
otherwise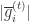 小于
小于  ,初始化
,初始化  (2)for
(2)for  更新
更新 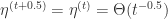 ,可以得到:
,可以得到: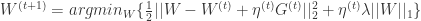

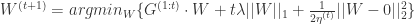
 。如果令
。如果令 

 上面的公式可以写成:
上面的公式可以写成:

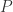 和
和 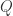 的一个非对称的度量公式。这个概念是由 Solomon Kullback 和 Richard Leibler 在 1951 年引入的。从概率分布
的一个非对称的度量公式。这个概念是由 Solomon Kullback 和 Richard Leibler 在 1951 年引入的。从概率分布  来表示。尽管从直觉上看 KL 散度是一个度量或者是一个距离,但是它却不满足度量或者距离的定义。例如,从
来表示。尽管从直觉上看 KL 散度是一个度量或者是一个距离,但是它却不满足度量或者距离的定义。例如,从 
 对于所有的
对于所有的  都成立。如果
都成立。如果 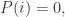 那么可以假设KL散度的第
那么可以假设KL散度的第 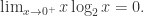
 的两个概率分布
的两个概率分布 
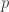 和
和 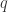 是概率分布
是概率分布  几乎处处成立的时候,才会有
几乎处处成立的时候,才会有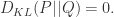
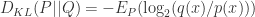
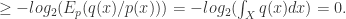
 是独立分布,并且联合分布是
是独立分布,并且联合分布是 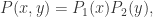
 是独立分布并且联合分布是
是独立分布并且联合分布是  那么
那么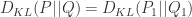 +
+ 
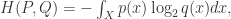

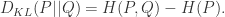

 +
+ 
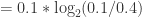 +
+  +
+ 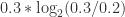 +
+ 
 。在这里,
。在这里,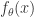 的参数。机器学习就是通过对这个参数的学习,完成函数的近似计算。这个模型对于
的参数。机器学习就是通过对这个参数的学习,完成函数的近似计算。这个模型对于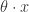 扩展成如下形式:
扩展成如下形式: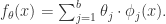
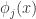 是基函数向量
是基函数向量 的第
的第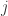 个分量,
个分量,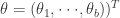 的第
的第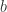

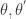 和
和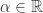 ,满足
,满足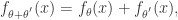


![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上的连续函数,对于任意的
上的连续函数,对于任意的 ,则存在多项式
,则存在多项式 使得对于所有的
使得对于所有的![x\in [a,b]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,有
,有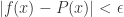
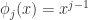
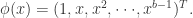
 的非线性函数,而且
的非线性函数,而且 可以逼近关于
可以逼近关于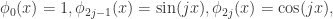 其中
其中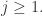
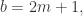
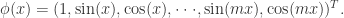
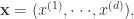 函数依旧可以扩展成如下模式:
函数依旧可以扩展成如下模式: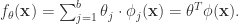
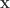
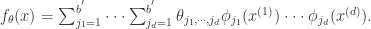
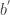 是各个维数的参数个数。对于这个模型而言,它的表现力十分丰富,但是不足之处在于所有的参数个数是
是各个维数的参数个数。对于这个模型而言,它的表现力十分丰富,但是不足之处在于所有的参数个数是 是一个非常巨大的数字,导致的维数灾难,所以在实际运用中,不主张用这个模型。
是一个非常巨大的数字,导致的维数灾难,所以在实际运用中,不主张用这个模型。
 它是一个关于维数
它是一个关于维数
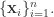
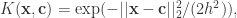
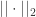
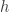


 有
有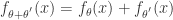 和
和  对于核函数来说,无论输入的是一维变量还是高维变量,核函数都可以容易的进行扩展。
对于核函数来说,无论输入的是一维变量还是高维变量,核函数都可以容易的进行扩展。
 是关于参数向量
是关于参数向量 的基函数,层级模型是基于参数向量
的基函数,层级模型是基于参数向量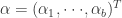 的线性形式。同时也包含参数向量
的线性形式。同时也包含参数向量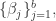 所以层级模型是基于参数向量
所以层级模型是基于参数向量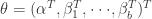 的非线性形式。
的非线性形式。 其中
其中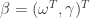
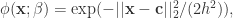 其中
其中
 是全集
是全集 则是集合
则是集合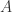
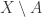

 ,这个方法的时间复杂度是指数级别的。
,这个方法的时间复杂度是指数级别的。
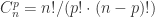
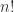
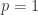






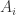
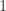 到
到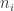

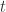
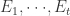
 ,
, 
 。这样该模型的错误率就是
。这样该模型的错误率就是


 当训练集并且
当训练集并且