
Regularized Dual Averaging Algorithm 算法介绍
(一)RDA(Regularized Dual Averaging Algorithm)算法原理
RDA(Regularized Dual Averaging Algorithm)叫做正则对偶平均算法,特征权重的更新策略是:

其中 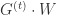
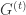




从公式中可以看出:
包括了之前所有梯度的平均值。
- 具有正则项
- 额外项
。
(二)RDA 的 L1 正则化
假设 



此时可以采取同样的策略,把各个维度拆分成 N 个独立的问题来处理。也就是:
其中,

通过数学推导可以证明:


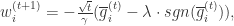
意思就是:当某个维度的累加平均值 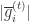
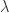
RDA 的算法
(1)输入,初始化
(2)for
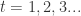
更新
end return W
(三)L1-RDA 与 L1-FOBOS 的对比
从截断方式来看,在 RDA 的算法中,只要梯度的累加平均值小于参数
(四)L1-RDA 与 L1-FOBOS 形式上的统一
在 L1-FOBOS 中,假设 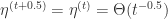
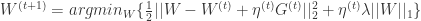
通过计算可以把 L1-FOBOS 写成:

同时 L1-RDA 可以写成:
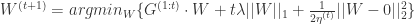
其中 



L1-FOBOS:

L1-RDA :

可以看出:
- L1-FOBOS 考虑了梯度和当前模的 L1 正则项,L1-RDA 考虑的是累积梯度。
- L1-FOBOS 的第三项限制 W 不能够距离已经迭代过的
值太远,L1-RDA 的第三项限制的是 W 不能够距离 0 太远。
