
机器学习的各种算法在于如何使用特定函数与已知的数据集相匹配,从而达到训练和测试的目的。本篇文章对一些近似的模型做一些相应的介绍。
线性模型
一维输入变量
假设学习对象

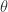
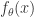
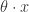
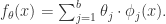
在这个式子中,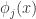

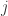

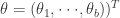
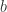

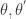
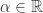
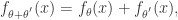

那么这个时候如何选择基函数
数学分析里面有一个经典定理叫做Weierstrass定理,陈述如下:
Weierstrass第一逼近定理:假设 是闭区间
是闭区间![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上的连续函数,对于任意的
上的连续函数,对于任意的 ,则存在多项式
,则存在多项式 使得对于所有的
使得对于所有的![x\in [a,b]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,有
,有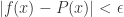 。
。
根据Weierstrass第一逼近定理,对于任何一个闭区间上面的连续函数,都可以用多项式去逼近。所以联系到机器学习,就可以把基函数
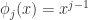
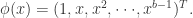
那么上述的

与Weierstrass逼近定理类似,用Fourier级数也可以逼近Lipchitz连续函数。所以也可以选择基函数
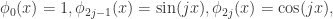
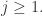
简单来说就是令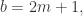
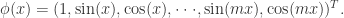
高维输入变量
对于高维的变量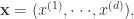
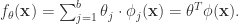
对于多维的输入向量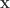
乘法模型指的是把一维的基函数作为因子,通过使其相乘而获得多维基函数的方法。表达式如下:
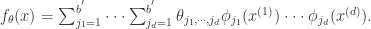
在上面的式子中,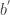

加法模型指的是把一维的基函数作为因子,通过相加而活得高维基函数的方法。表达式如下:

加法模型中所有参数的个数是

核模型
在线性模型中,多项式或三角函数等基函数的选择都是与训练样本无关的,核模型则与之相反,会在进行基函数构造的时候使用输入样本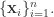
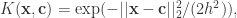
其中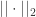
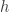


在这个模型中,关于
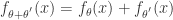

层级模型
对参数来说是非线性的模型,都称为非线性模型。下面要介绍的就是非线性模型中的层级模型,它在很多领域都有应用。假设模型是

上式中,

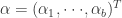
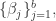
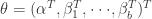

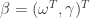
或者高斯函数
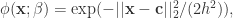

其中S函数模仿的是人类脑细胞的输入输出函数,因此使用S函数的层级模型也被称为人工神经网络模型。
针对像人工神经网络这样的层级模型,采用贝叶斯学习的方法是不错的选择。人工神经网络也以学习过程艰难异常而著称。

写得很好,感觉楼主对机器学习理解得很深了。
LikeLike