
现在做在线学习和 CTR 常常会用到逻辑回归( Logistic Regression),而传统的批量(batch)算法无法有效地处理超大规模的数据集和在线数据流,美国的 Google 公司先后三年时间(2010年-2013年)从理论研究到实际工程化实现的 FTRL(Follow-the-regularized-Leader)算法,在处理诸如逻辑回归之类的带非光滑正则化项(例如 L1 范数,做模型复杂度控制和稀疏化)的凸优化问题上性能非常出色。
通常,优化算法中的 gradient descent 等解法,是对一批样本进行一次求解,得到一个全局最优解。但是,实际的互联网广告应用需要的是快速地进行模型的更新。为了保证快速的更新,训练样本是一条一条地过来的,每来一个样本,模型的参数对这个样本进行一次迭代,从而保证了模型的及时更新,这种方法叫做在线梯度下降法(Online gradient descent)。
在应用的时候,线上来的每一个广告请求,都提取出相应的特征,再根据模型的参数,计算一个点击某广告的概率。在线学习的任务就是学习模型的参数。所谓的模型的参数,其实可以认为是一个目标函数的解。跟之前说的根据批量的样本计算一个全局最优解的方法的不同是,解这个问题只能扫描一次样本,而且样本是一条一条地过来的。
当然这会有误差,所以为了避免这种误差,又为了增加稀疏性,有人又想到了多个版本的算法,Google 公司有人总结了其中几种比较优秀的,例如 FOBOS,AOGD 和微软的 RDA,同时提出了Google自己的算法 FTRL-Proximal。其中,FTRL-Proximal 在稀疏性和精确度等方面表现都比较好。
问题描述(最小化目标函数)
等价条件:
(1)约束优化(convex constraint formulation):


(2)无约束优化描述(soft regularization formulation):

注:当选择合适的常数 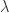
损失函数:
Linear Regression:

Logistic Regression:

传统算法(Gradient Descent)
Batch Gradient Descent: Repeat Until Convergence
{ 
这里的 Gradient Descent 是一种批量处理的方式(Batch),每次更新 W 的时候都需要扫描所有样本来计算一个全局梯度
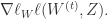
传统算法(Stochastic Gradient Descent)
Stochastic Gradient Descent 是另外一种权重更新方法:
Loop{
for j=1 to M { 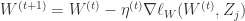
}
这里每次迭代仅仅根据单个样本更新权重 W,这种算法称为随机梯度下降法(Stochastic Gradient Descent)。
Truncated Gradient 算法简介
为了得到稀疏的特征权重 W,最简单粗暴的方式就是设定一个阈值,当 W 的某维度上系数小于这个阈值时将其设置为 0(称作简单截断)。这种方法实现起来很简单,也容易理解。但实际中(尤其在OGD里面)W 的某个系数比较小可能是因为该维度训练不足引起的,简单进行截断会造成这部分特征的丢失。
截断梯度法(TG, Truncated Gradient)是由John Langford,Lihong Li 和 Tong Zhang 在2009年提出,实际上是对简单截断的一种改进。下面首先描述一下 L1 正则化和简单截断的方法,然后我们再来看TG对简单截断的改进以及这三种方法在特定条件下的转化。
(1)L1 正则化法
由于 L1 正则项在 0 处不可导,往往会造成平滑的凸优化问题变成非平滑凸优化问题,因此在每次迭代中采用次梯度计算 L1 正则项的梯度。权重更新方式为:

注意,这里 

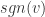





(2)简单截断法
以 k 为窗口,当 t/k 不为整数时采用标准的SGD进行迭代,当 t/k 为整数时,采用如下权重更新方式:这里的 



这里 


(3)截断梯度法(Truncated Gradient)
上面的简单截断法看上去十分 aggressive,因此截断梯度法在此基础上进行了改进工作。

这里的方程 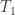
![T_{1}(v_{i},\alpha,\theta)=\max(0,v_{i}-\alpha) \text{ if } v_{i}\in [0,\theta]](https://s0.wp.com/latex.php?latex=T_%7B1%7D%28v_%7Bi%7D%2C%5Calpha%2C%5Ctheta%29%3D%5Cmax%280%2Cv_%7Bi%7D-%5Calpha%29+%5Ctext%7B+if+%7D+v_%7Bi%7D%5Cin+%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


其中 
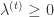


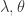
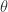

Truncated Gradient 的算法:
输入for t = 1,2,3,... 计算
按照下面规则更新 W, (i)当 t/k 不是整数时,采用标准的 SGD (Stochastic Gradient Descent) 进行迭代。
for all
. (ii)当 t/k 是整数时,采取截断技术。
, if
![(w_{i}-\eta^{(t)}g_{i})\in[0,\theta]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
, else if
![(w_{i}-\eta^{(t)}g_{i})\in[-\theta,0]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B-%5Ctheta%2C0%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
, otherwise return W.
(4)Truncated Gradient,简单截断法,L1 正则化之间的关系。
简单截断法和截断梯度法的区别在于选择了不同的截断公式 
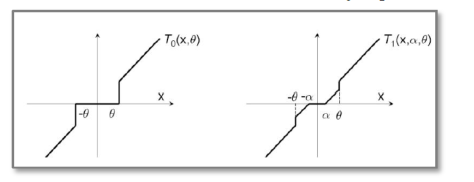
Truncated Gradient -> 简单截断法
从上图可以直接看出:选择 
Truncated Gradient -> L1 正则化
貌似有一点问题,需要重新推导。

您好,请问该怎么计算截断梯度中的G呢
LikeLike
Truncated Gradient 的算法中错了吧,i\in\mathbb{R}^N,应该是i\in\mathbb{R}
LikeLike