
交叉验证的定义
交叉验证(Cross Validation),有的时候也称作循环估计(Rotation Estimation),是一种统计学上将数据样本切割成较小子集的实用方法,该理论是由Seymour Geisser提出的。
在模式识别(Pattern Recognition)和机器学习(Machine Learning)的相关研究中,经常会将整个数据集合分成两个部分,分别是训练集合和测试集合。假设


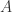
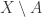
HoldOut检验(Hold-Out Method)
这个方法是将原始的数据集合
交叉检验的常见形式
假设有一个未知模型有一个或者多个未知的参数,并且有一个训练集。操作的过程就是对该模型的参数进行调整,使得该模型能够最大的反映训练集的特征。如果模型因为训练集过小或者参数不合适而产生过度拟合的情况,测试集的测试效果就可以得到验证。交叉验证是一种能够预测模型拟合性能的有效方法。
彻底的交叉验证(Exhaustive Cross Validation)
彻底的交叉验证方法指的是遍历全集

留P验证(Leave-p-out Cross Validation)
留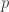

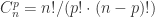
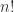
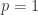

不彻底的交叉验证(Non-exhaustive Cross Validation)
不彻底的交叉验证不需要考虑全集
k-fold交叉验证(K-fold Cross Validation)
在k-fold交叉验证中,全集




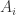

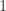
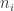

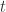
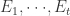




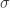
注释:
1. 一般来说,10-fold交叉验证的情况使用得最多。
2. 当



3. 当
一般模型的选择过程
在了解了交叉验证的方法之后,可以来介绍一般模型的选择过程。通过采用不同的输入训练样本,来决定机器学习算法中包含的各个参数值,称作模型选择。下面伪代码表示了模型选择的一般流程。在这个算法中,最重要的就是第三个步骤中的误差评价。
(1)准备候选的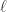
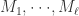
(2)对每个模型
(3)对每个学习结果的误差
(4)选择误差
