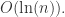2. 个人的实力不太行,听讲座会觉得有较大的压力,然后日常就是记笔记,但是最后回顾起来,这些笔记对我来说并没有什么作用。甚至不如自己学的那些 C++ 代码和算法导论知识。
不管怎么样,第二年的学术生涯也就结束了。
第三年的讨论班
到了第三年,我确实也感受到了毕业带来的压力,总算把自己的科研论文捡了回来,重新翻阅了一下。在日常跟导师的汇报中,我把那篇有 Gap 的论文读完了,也知道是 Part 10 的一个定理证明错误了。但是,我个人并没有什么方法来解决这个问题。第三年的第一个学期的主要精力就放在了这篇论文上,当时我对这几篇论文只能说大致有一个理解,但是并没有太深刻的认识。
2. 张益唐于 2013 年 4 月 17 日在《数学年刊》(Annals of Mathematics)发表《素数间的有界间隔》,首次证明了存在无穷多对素数对(p, q),其中每一对素数之差,即 p 和 q 的距离,不超过 7000 万。 这为世纪难题“孪生素数猜想”的解决做出了突破性工作,他从一位默默无闻的大学讲师跻身世界重量级数学家的行列。这一故事让我知道了“庾信平生最萧瑟,暮年诗赋动江关”这首诗,人只要坚持不懈地做一件事情,是有可能达成最终目标的。
于是,我从 2013 年 4 月份开始奋发图强,在 Prince George Park 的自习室里面学习,平时也不再去办公室,就天天窝在自习室和自己的宿舍。每天就带着一堆草稿纸和论文,围绕着一个方程思考,草稿纸算了一堆有一堆。但是随着我的坚持,没想到两周之后我居然有了一个突破,证明了 Real Bound Theorem。
不过科研这种事情总是充满了不确定性,不逼一下自己永远也不知道自己能够做到什么程度。在第四年的毕业压力之下,通过个人的努力和坚持不懈,总算在 Real Bound Theorem 的基础上跟上一层楼。在 2014 年 4 月底的时候几乎已经认为可以做出论文了。甚至有一天我已经认为自己做出来课题,导师问我多久能够写出论文,我直接开口说三天即可,因为当时总算是看到了毕业的曙光。不过这种感觉转瞬即逝,等我回去仔细思考之后,发现该方案并不能够解决问题,心情直接就像过山车一样的从天空落到了谷底。不过这个只是一个小问题,之前再大的困难都被克服了,怎么能够在最后关头倒下。于是重新审视了问题所在,发现原来的方法处理不了这个问题,但是恰好能解决其他的问题,于是赶紧把该方法运用到类似的问题上,这才算做完了自己的毕业论文,后续的工作只是把论文的步骤整理好即可。
当时,我意识到这个课题已经做完了之后,毕业的压力瞬间就是消失了,无论我做什么都不会再有毕业的压力了。可以尽情的享受生活,enjoy my life。2014 年 6 月份有段时间我还去过 NUS 的 Central Library,在那里回顾了一下自己这四年的科研旅途,毕竟第一年我没有 Office 的时候,可是整天泡在 Science Library 和 Central Library 的。
做完了课题之后,顿时觉得新加坡的天空十分晴朗,正好此时巴西世界杯也在 2014 年的 6 月份开战,于是自己白天在办公室整理自己的论文,或者去 Vivo City 的 Golden Village 去看电影,晚上就回宿舍看世界杯。此刻也感受了球迷 Zhoufeng 的热情,每天都去买零食和可乐,分给大家喝,于是我在不知不觉中又变胖了。此刻在 NUS 的第四年生涯也算是结束了。
当年笔者为了阅读这篇文章,自然也读了周边的一系列文章,下面这篇文章同样是发表在 Annals of Mathematics(数学年刊)上。但是这是一篇关于实动力系统的文章,证明了 wild Cantor attractor 的存在性,其方法有希望应用到复动力系统领域,来最终证明 Fibonacci 多项式的 Julia 集合具有正测度。
[3] Bruin, Henk, et al. “Wild Cantor attractors exist.” Annals of mathematics (1996): 97-130.
可惜,遗憾的是,虽然这个方法在实动力系统上是成立了,论文也发表在 Annals of Mathematics 上,但是上述方法并不能够直接应用到复动力系统上,导致 Julia 集合的正测度一直是 Open Question。
但是,针对 2 次多项式的 Julia 集合的正测度研究,却一直有着不错的进展,而且每一篇文章都发表在数学的四大期刊上。
[4] Lyubich, Mikhail, and John Milnor. “The Fibonacci unimodal map.” Journal of the American Mathematical Society 6.2 (1993): 425-457.
这篇文章证明了 The quadratic unimodal map with Fibonacci combinatorial type has no wild Cantor attractor,发表在 JAMS 上。
[5] Lyubich, Mikhail. “Combinatorics, geometry and attractors of quasi-quadratic maps.” Annals of Mathematics 140.2 (1994): 347-404.
这篇文章证明了 Assume f is unimodal and has a quadratic critical point. If there exists a set X of positive Lebesgue measure so that for all x ∈ X, ω(x) is equal to a Cantor set C, then C is a solenoidal attractor and C = ω(c) for the critical point c. i.e. f has no wild Cantor attractor. 同样发表在 Annals of Mathematics 上。
[6] Buff, Xavier, and Arnaud Chéritat. “Quadratic Julia sets with positive area.” Annals of Mathematics (2012): 673-746.
后来到了 2012 年,有两位数学家证明了存在 2 次多项式使得它的 Julia 集合是正测度。到了 2022 年,数学家 Avila 和 Lyubich 又找到一类 2 次多项式,它们的 Julia 集合同样是正测度。这两篇论文都发表在 Annals of Mathematics 上。
Open Question: Is the measure of Julia set of Fibonacci Polynomial positive or not?
事后回想起来,这个问题可能还是比较难,至少对我本人来说是太难了,可能已经超越了我能够把控的范围。阅读一篇有 Gap 的论文从某种层面打击到了自己的信心,导致后续我对这个问题根本不感兴趣,但是手上又没有其他课题可以做。有一次向导师提出了需要更换课题,但是被导师一口否决了,也只好沿着这个方向一直做下去。在一个没有讨价还价的读博环境下,无论导师提出什么样的学术要求,为了毕业我都会完成,但是坏处就是我对动力系统这个方向就完全失去了兴趣。
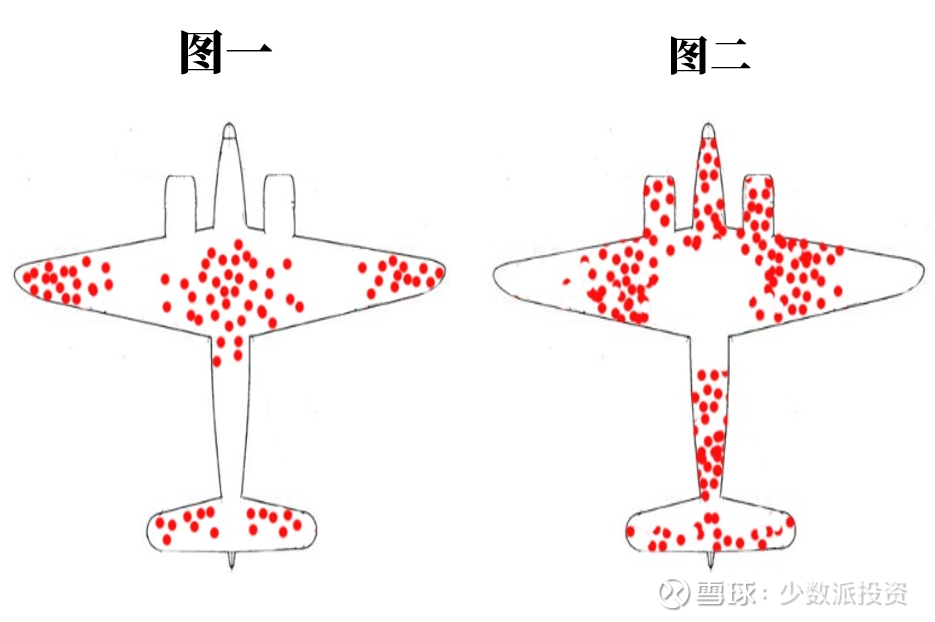
最终,沃尔德的论文题目是:A Method of Estimating Plane Vulnerability Based on Damage of Survivors,翻译出来就是一种根据幸存飞机损伤情况推测飞机要害部位的方法。在论文中,他应用详细的数据来证明他自己的观点。弹孔最稀疏处就是战斗机的要害处,因为没有被击中要害处的飞机才有更多的机会返航,进入军方的统计样本。这就是幸存者偏差。
不过,核酸检测可以转换成一个抽象的数学问题。假设城市 A 的人口数是 n,当前感染传染病的人数是 m,并且 m 是远小于 n 的()。令 p = m / n 表示患病率且 p < 0.01。为了减少检测量,检测人员想对人群进行分桶操作,每 k 个人的样本进行混合,并且对这个混合样本进行检测。如果该混合样本没有问题,则这 k 个人都没有问题;如果该混合样本有问题,则再次对这 k 个人进行逐一检测。通过这样的方法,就可以得到最终的结果。那么,这个 k 该如何选择呢?
k = 1 的时候就相当于对每个人都进行检测,k = n 的时候就相当于对城市 A 中所有的人都进行检测,这两种极端情况的效率都很低。那么 k 值究竟如何选择,才能够让每个人的平均检测次数最少呢?
在数学上,这种混合检测的方法叫做 Group Testing,最早是美国的统计学家 Robert Dorfman 在 1943 年提出的。这种方法可以非常有效地提升大规模检测的效率和能力。在成本有限的前提下,达到最优的效果。其中心思想就跟核酸检测的方法是一样的,将全体人群按照一定的数量分成多个组,然后对每一个分组进行检测,如果该分组的检测结果没有问题,则这个分组里面的人就没有问题;如果该分组的检测结果有问题,则将这个分组里面的所有人重新进行单独测试。
根据以上方法,每个人的检测次数有可能是 1 次,也有可能是 2 次。只要这个人所在的混合样本没有问题,那么这个人就是 1 次;如果这个人所在的混合样本有问题,那么这个人就需要检测 2 次,那么这 k 个人都需要重新检测 1 次,这 k 个人的总检测次数就是 k + 1。这 k 个人的混合样本没有问题的概率是 ,有问题的概率是 。那么,这 k 个人总检测次数的期望值就是 。由于城市 A 总共有 n 个人,那么就需要 n / k 个桶,因此,总检测次数的期望是 。
如果进行十混一的混合检测方法,也就是当 k = 10 时,需要保证 p < 0.2;如果要进行二十混一的混合检测方法,也就是当 k = 20 时,需要保证 p < 0.14;如果要进行五十混一的混合检测方法,也就是当 k = 50 时,需要保证 p < 0.08。在绝大多数情况下,感染率 p 还是会小于 0.2 的,因此采用十混一或者二十混一的方法在现实生活中是可靠的。
在大公司内部每个人都有着自己的工作职责,有程序员,产品经理,运营等诸多岗位。如果能够基于现有的一些工作技能来开展副业,那么对于个人而言就是一个 Plan B。但是副业是需要长期日常积累的,并不是临时一两个月就可以完全搞得起来的。如果在日常工作生活中有条件的话,大家可以想办法搞一个或者多个副业,一开始并不需要盈利,但只要坚持下去和方法得当,就有可能成为一个盈利的工作,甚至未来可以通过它来养家糊口。Plan B 如何选择完全基于自身的具体情况,毕竟每个人所擅长的领域也是完全不同的。
强化学习是人工智能领域一个非常重要的分支,在游戏 AI 领域的应用是无处不在的,包括大家耳熟能详的 AlphaGo 和王者荣耀,其背后都使用了大量的强化学习方法。随着人工智能技术在互联网公司的日渐普及,人们对人工智能的期待也越来越高,也期待着人工智能未来能够做更多的事情。除了各种门禁系统,人脸识别系统在各个公司的应用之外,在游戏领域,强化学习也扮演着举足轻重的作用。
当前的强化学习技术除了使用在游戏 AI 领域之外,也在机器人控制,推荐系统等领域有着很多应用,也取得了不少商业价值。但强化学习的学习还是存在一定的门槛,除了一些在线的 tutorial 和零零散散的资料之外,其实还是需要一本相对完整和优秀的教材来辅助高校的老师和学生,只有这样,强化学习才能够成为一门课进入高校课堂。
从教育经历这一块来看,就开始有区分度了。不同的学历的面试标准和要求是存在一定差异性的,不同的学校也是存在一定的区分度的。当然学校的区分度并不是指 Top 2,C9,985,211 的学生就一定会通过面试,在面试的过程中,任何学校的候选人都存在机会。不同公司的不同部门会根据自身的实际情况招聘最合适的候选人,并且最合适的候选人并不是最强的人。
Liu, Jing, et al. “What’s in a name? An unsupervised approach to link users across communities.” Proceedings of the sixth ACM international conference on Web search and data mining. 2013. 本篇文章主要是基于用户的名字来识别跨网络的用户的,提取用户的特征之后,使用 SVM 分类器来进行识别;
Riederer, Christopher, et al. “Linking users across domains with location data: Theory and validation.” Proceedings of the 25th International Conference on World Wide Web. 2016. 本篇文章主要是基于用户的内容特征来进行建模;
Labitzke, Sebastian, Irina Taranu, and Hannes Hartenstein. “What your friends tell others about you: Low cost linkability of social network profiles.” Proc. 5th International ACM Workshop on Social Network Mining and Analysis, San Diego, CA, USA. 2011. 本篇论文是根据社交网络中的用户邻居数据,来判断用户之间相似性的。
参考文献
Shu, Kai, et al. “User identity linkage across online social networks: A review.” Acm Sigkdd Explorations Newsletter 18.2 (2017): 5-17.
Liu, Jing, et al. “What’s in a name? An unsupervised approach to link users across communities.” Proceedings of the sixth ACM international conference on Web search and data mining.
Riederer, Christopher, et al. “Linking users across domains with location data: Theory and validation.” Proceedings of the 25th International Conference on World Wide Web. 2016.
Labitzke, Sebastian, Irina Taranu, and Hannes Hartenstein. “What your friends tell others about you: Low cost linkability of social network profiles.” Proc. 5th International ACM Workshop on Social Network Mining and Analysis, San Diego, CA, USA. 2011.
a.build(n_trees, n_jobs=-1):n_trees 表示树的棵数,n_jobs 表示线程个数,n_jobs=-1 表示使用所有的 CPU 核;
a.save(fn, prefault=False):表示将索引存储成文件,文件名是 fn;
a.load(fn, prefault=False):表示将索引从文件 fn 中读取出来;
a.unload():表示不再加载索引;
a.get_nns_by_item(i, n, search_k=-1, include_distances=False):返回在索引中的第 i 个向量 Top n 最相似的向量;如果不提供 search_k 值的话,search_k 默认为 n_tree * n,该指标用来平衡精确度和速度;includ_distances=True 表示返回的时候是一个包含两个元素的 tuple,第一个是索引向量的 index,第二个就是相应的距离;
a.get_nns_by_vector(v, n, search_k=-1, include_distances=False):返回与向量 v Top n 最相似的向量;如果不提供 search_k 值的话,search_k 默认为 n_tree * n,该指标用来平衡精确度和速度;includ_distances=True 表示返回的时候是一个包含两个元素的 tuple,第一个是索引向量的 index,第二个就是相应的距离;
search_k:值越大表示搜索耗时越长,搜索的精度越高;如果需要返回 Top n 最相似的向量,则 search_k 的默认值是 n_trees * n;
Annoy 的使用案例
from annoy import AnnoyIndex
import random
# f 表示向量的维度
f = 40
# 'angular' 是 annoy 支持的一种度量;
t = AnnoyIndex(f, 'angular') # Length of item vector that will be indexed
# 插入数据
for i in range(1000):
v = [random.gauss(0, 1) for z in range(f)]
# i 是一个非负数,v 表示向量
t.add_item(i, v)
# 树的数量
t.build(10) # 10 trees
# 存储索引成为文件
t.save('test.ann')
# 读取存储好的索引文件
u = AnnoyIndex(f, 'angular')
u.load('test.ann') # super fast, will just mmap the file
# 返回与第 0 个向量最相似的 Top 100 向量;
print(u.get_nns_by_item(0, 1000)) # will find the 1000 nearest neighbors
# 返回与该向量最相似的 Top 100 向量;
print(u.get_nns_by_vector([random.gauss(0, 1) for z in range(f)], 1000))
# 返回第 i 个向量与第 j 个向量的距离;
# 第 0 个向量与第 0 个向量的距离
print(u.get_distance(0, 0))
# 第 0 个向量与第 1 个向量的距离
print(u.get_distance(0, 1))
# 返回索引中的向量个数;
print(u.get_n_items())
# 返回索引中的树的棵数;
print(u.get_n_trees())
# 不再加载索引
print(u.unload())
基于 hamming 距离的 annoy 使用案例:
from annoy import AnnoyIndex
# Mentioned on the annoy-user list
bitstrings = [
'0000000000011000001110000011111000101110111110000100000100000000',
'0000000000011000001110000011111000101110111110000100000100000001',
'0000000000011000001110000011111000101110111110000100000100000010',
'0010010100011001001000010001100101011110000000110000011110001100',
'1001011010000110100101101001111010001110100001101000111000001110',
'0111100101111001011110010010001100010111000111100001101100011111',
'0011000010011101000011010010111000101110100101111000011101001011',
'0011000010011100000011010010111000101110100101111000011101001011',
'1001100000111010001010000010110000111100100101001001010000000111',
'0000000000111101010100010001000101101001000000011000001101000000',
'1000101001010001011100010111001100110011001100110011001111001100',
'1110011001001111100110010001100100001011000011010010111100100111',
]
# 将其转换成二维数组
vectors = [[int(bit) for bit in bitstring] for bitstring in bitstrings]
# 64 维度
f = 64
idx = AnnoyIndex(f, 'hamming')
for i, v in enumerate(vectors):
idx.add_item(i, v)
# 构建索引
idx.build(10)
idx.save('idx.ann')
idx = AnnoyIndex(f, 'hamming')
idx.load('idx.ann')
js, ds = idx.get_nns_by_item(0, 5, include_distances=True)
# 输出索引和 hamming 距离
print(js, ds)
基于欧几里得距离的 annoy 使用案例:
from annoy import AnnoyIndex
import random
# f 表示向量的维度
f = 2
# 'euclidean' 是 annoy 支持的一种度量;
t = AnnoyIndex(f, 'euclidean') # Length of item vector that will be indexed
# 插入数据
t.add_item(0, [0, 0])
t.add_item(1, [1, 0])
t.add_item(2, [1, 1])
t.add_item(3, [0, 1])
# 树的数量
t.build(n_trees=10) # 10 trees
t.save('test2.ann')
u = AnnoyIndex(f, 'euclidean')
u.load('test2.ann') # super fast, will just mmap the file
print(u.get_nns_by_item(1, 3)) # will find the 1000 nearest neighbors
print(u.get_nns_by_vector([0.1, 0], 3))
Nearest neighbors and vector models – part 2 – algorithms and data structures:https://erikbern.com/2015/10/01/nearest-neighbors-and-vector-models-part-2-how-to-search-in-high-dimensional-spaces.html
利弗莫尔 1900 年第一次结婚,后来炒股破产,妻子 Netit (Nettie) Jordan 不愿变卖首饰支持他炒股,两人感情失和,终于在1917年离婚。他的第二任演员妻子温德特(Dorothy Wendt)嗜酒、花名在外,最后温德特跟他离婚,还把他的财产挥霍一空,又在一次酒醉后,对长子开枪,造成长子残废。家庭生活的失衡,使他因为私人生活问题而致心灰意冷,他多次破产,但也多次从破产中崛起。1934 年 3 月 5 日第四次破产,患有深度抑郁症。他的儿子说服他写书,借此鼓舞情绪,1940 年 3 月,利弗莫尔出版《股票作手杰西·利弗莫尔尔操盘术》(How to Trade in Stocks),但书卖得不好。同年11月他在饭店用晚餐时,留下遗书给第三任妻子Harriett Metz Noble,然后在洗手间举枪自杀。 利弗莫尔的遗书:
“ Cant help it. Things have been bad with me. I am tired of fighting. Cant carry on any longer. This is the only way out. I am unworthy of your love. I am a failure. I am truly sorry, but this is the only way out for me. (忍受不了,所有事情对我来说都很差。我厌倦了抵抗,不能够再坚持下去,这是唯一的出路!我不值得你去爱,我是个失败者,我…真的很对不起,但这个方法是我唯一的出路。) ”
生命中最后一年的长期抑郁症应该是自杀的主要原因。
这位华尔街的传奇大亨的书籍《How to Trade in Stocks》至今被奉为经典之作。下面摘选书籍中部分经典交易法则。



































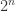 本,那么一本一本检测的话需要
本,那么一本一本检测的话需要 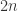 次;当
次;当  很大的时候,可以清楚地知道
很大的时候,可以清楚地知道 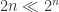 ,其检测的次数会呈现明显的减少。
,其检测的次数会呈现明显的减少。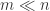 )。令 p = m / n 表示患病率且 p < 0.01。为了减少检测量,检测人员想对人群进行分桶操作,每 k 个人的样本进行混合,并且对这个混合样本进行检测。如果该混合样本没有问题,则这 k 个人都没有问题;如果该混合样本有问题,则再次对这 k 个人进行逐一检测。通过这样的方法,就可以得到最终的结果。那么,这个 k 该如何选择呢?
)。令 p = m / n 表示患病率且 p < 0.01。为了减少检测量,检测人员想对人群进行分桶操作,每 k 个人的样本进行混合,并且对这个混合样本进行检测。如果该混合样本没有问题,则这 k 个人都没有问题;如果该混合样本有问题,则再次对这 k 个人进行逐一检测。通过这样的方法,就可以得到最终的结果。那么,这个 k 该如何选择呢?
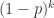 ,有问题的概率是
,有问题的概率是 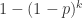 。那么,这 k 个人总检测次数的期望值就是
。那么,这 k 个人总检测次数的期望值就是 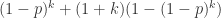 。由于城市 A 总共有 n 个人,那么就需要 n / k 个桶,因此,总检测次数的期望是
。由于城市 A 总共有 n 个人,那么就需要 n / k 个桶,因此,总检测次数的期望是 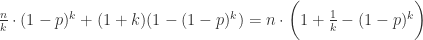 。
。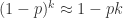 ,因此,总检测次数的期望值约等于
,因此,总检测次数的期望值约等于 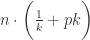 。当
。当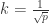 时,上述公式达到最小值
时,上述公式达到最小值 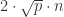 。如果 p=0.01 时,k 取 10 可以达到最小值
。如果 p=0.01 时,k 取 10 可以达到最小值 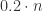 ;当 p=0.001 时,k 取 32 可以达到最小值
;当 p=0.001 时,k 取 32 可以达到最小值 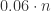 。通过混合采样的方法,可以将总检测次数的期望变成原来的五分之一甚至十分之一以下。
。通过混合采样的方法,可以将总检测次数的期望变成原来的五分之一甚至十分之一以下。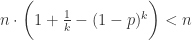 ,化简之后得到
,化简之后得到 ![p<1-\frac{1}{\sqrt[k]{k}}](https://s0.wp.com/latex.php?latex=p%3C1-%5Cfrac%7B1%7D%7B%5Csqrt%5Bk%5D%7Bk%7D%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。
。













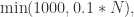 其中
其中 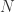 表示总量;例如,当
表示总量;例如,当 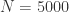 时,最大样本数可以选择 500;而当
时,最大样本数可以选择 500;而当  时,最大样本数只需要选择 1000 即可;
时,最大样本数只需要选择 1000 即可;
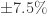
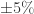
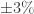



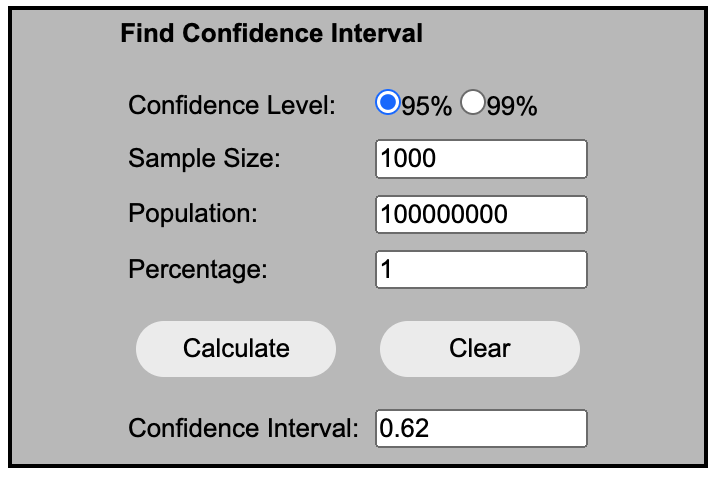
 表示总体中满足某个选项的数量,
表示总体中满足某个选项的数量, 表示样本中满足某个选项的数量。令
表示样本中满足某个选项的数量。令 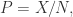
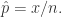
 ,且正态分布的概率用 Prob 表示,那么
,且正态分布的概率用 Prob 表示,那么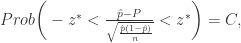
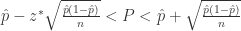 . 其中
. 其中 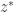 和
和 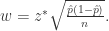

 所以,
所以,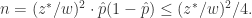 最大样本数可以选择为
最大样本数可以选择为 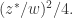

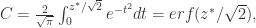
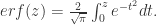
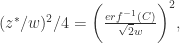
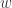 表示置信区间,
表示置信区间,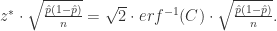
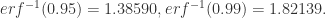
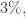 置信度
置信度  的时候,最大样本数是:
的时候,最大样本数是:
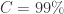 的时候,最大样本数是:
的时候,最大样本数是: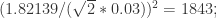
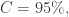
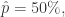
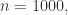 置信区间是
置信区间是 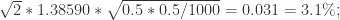

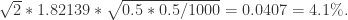
 是一个图,顶点是帐号
是一个图,顶点是帐号 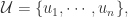 边是由帐号之间的连线
边是由帐号之间的连线 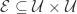 所构成的。
所构成的。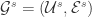 和
和 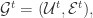 其目标是找到一个函数
其目标是找到一个函数 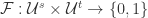 使得,
使得,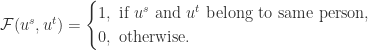
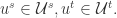
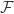 就是模型需要学习的目标函数,进一步地,对于
就是模型需要学习的目标函数,进一步地,对于 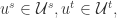 学习得到的预测函数
学习得到的预测函数 ![\mathcal{\hat{F}}(u^{s},u^{t})=p\in [0,1]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7B%5Chat%7BF%7D%7D%28u%5E%7Bs%7D%2Cu%5E%7Bt%7D%29%3Dp%5Cin+%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示两个帐号属于同一个自然人的概率值。
表示两个帐号属于同一个自然人的概率值。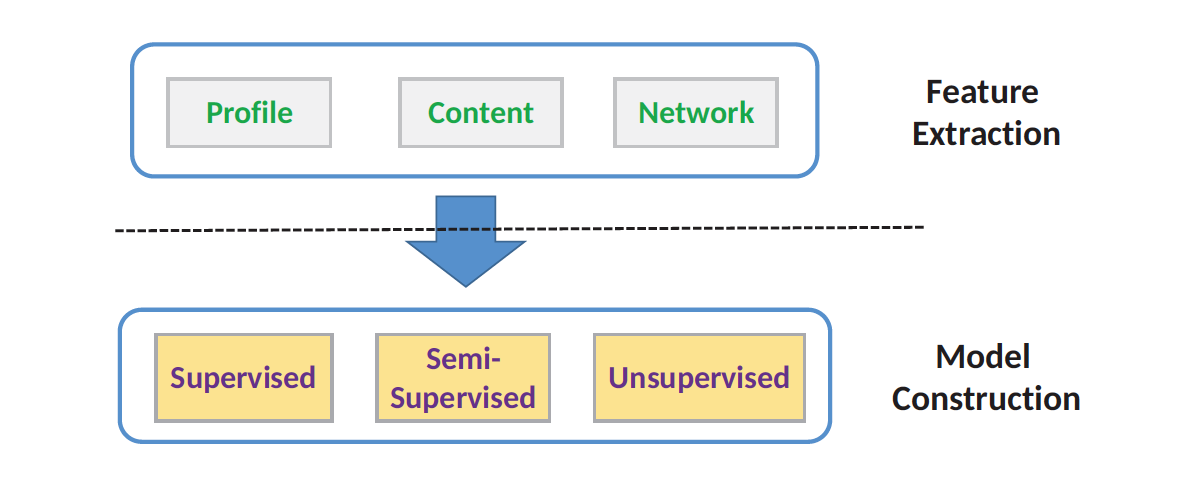
 而言,用
而言,用 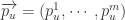 来表示画像特征向量,其中
来表示画像特征向量,其中  表示画像属性特征的个数。对于两个社交网络
表示画像属性特征的个数。对于两个社交网络 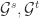 的帐号
的帐号 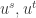 而言,可以得到相应的画像特征向量
而言,可以得到相应的画像特征向量 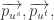 然后可以用基于距离(distance-based)或者基于频率(frequence-based)的方法来获得向量的距离或者相似性。换句话说,就是通过加权平均算法来获得结果:
然后可以用基于距离(distance-based)或者基于频率(frequence-based)的方法来获得向量的距离或者相似性。换句话说,就是通过加权平均算法来获得结果: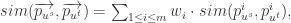 或者
或者
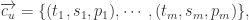 其中
其中 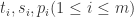 分别表示时间戳,空间数据,内容数据。
分别表示时间戳,空间数据,内容数据。
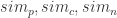 分别表示画像(profile),内容(content),社交网络(network)之间的相似度。
分别表示画像(profile),内容(content),社交网络(network)之间的相似度。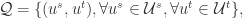 那么正样本是
那么正样本是  负样本
负样本 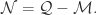 在实际使用的时候,要注意采样的比例和负样本的选择方法。
在实际使用的时候,要注意采样的比例和负样本的选择方法。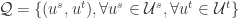 是所有的帐号对,
是所有的帐号对,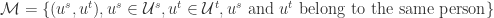 是所有属于相同自然人的帐号对,
是所有属于相同自然人的帐号对, 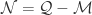 是所有属于不同自然人的帐号对。
是所有属于不同自然人的帐号对。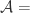 {被算法映射成相同自然人的帐号对},
{被算法映射成相同自然人的帐号对},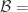 {被算法映射成不同自然人的帐号对};用 TP, TN, FN, FP 来描述就是:
{被算法映射成不同自然人的帐号对};用 TP, TN, FN, FP 来描述就是: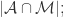
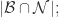
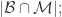
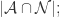
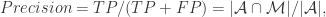
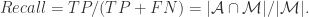
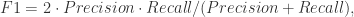
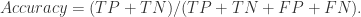

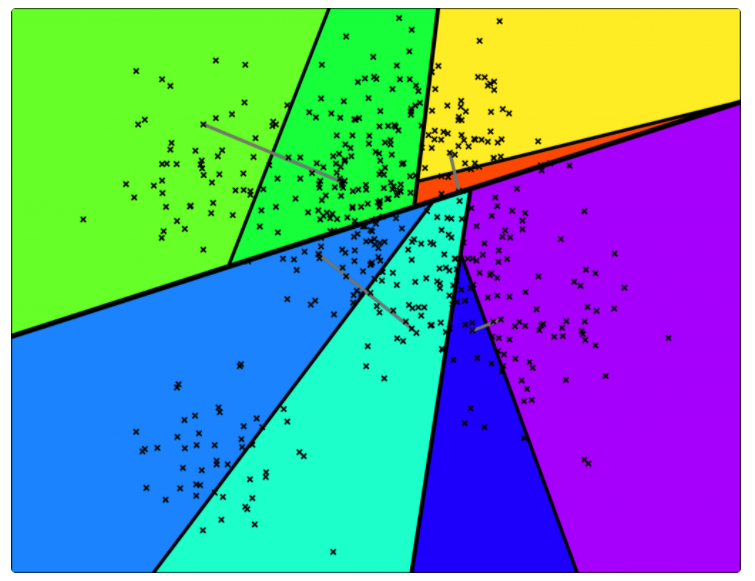
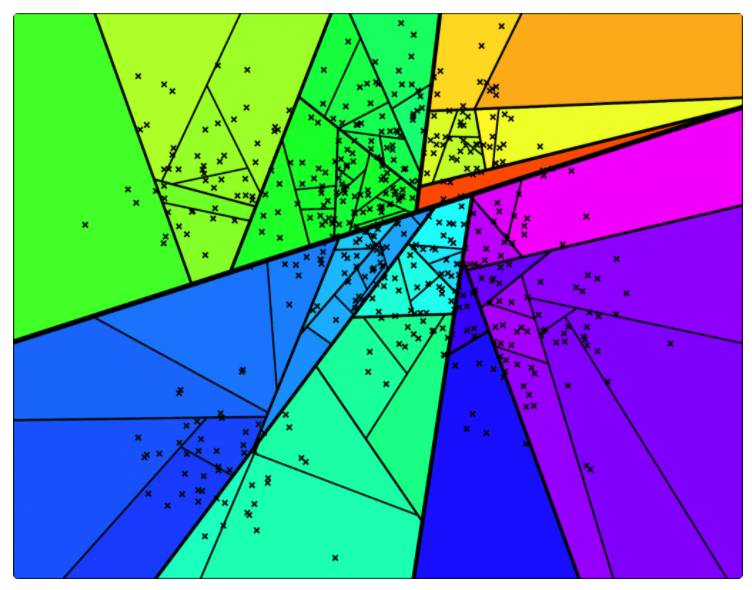
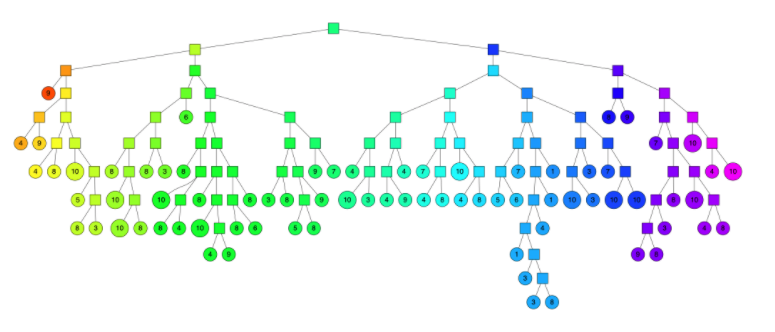
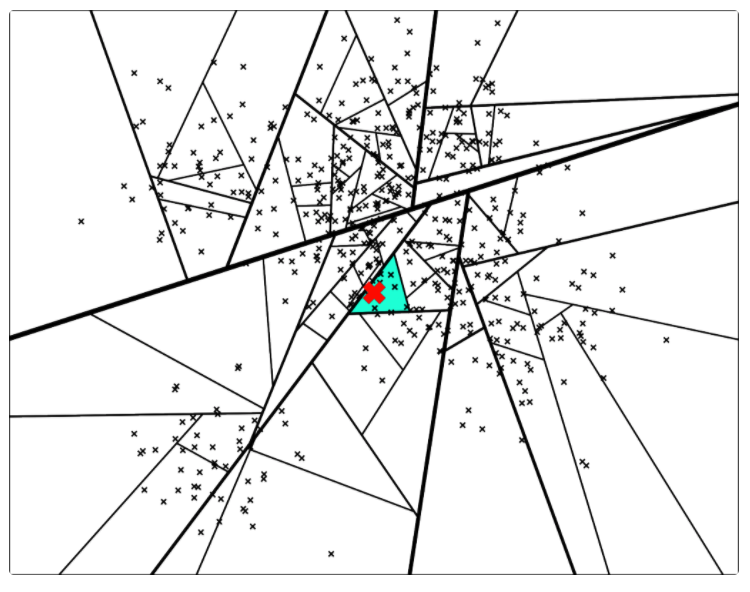
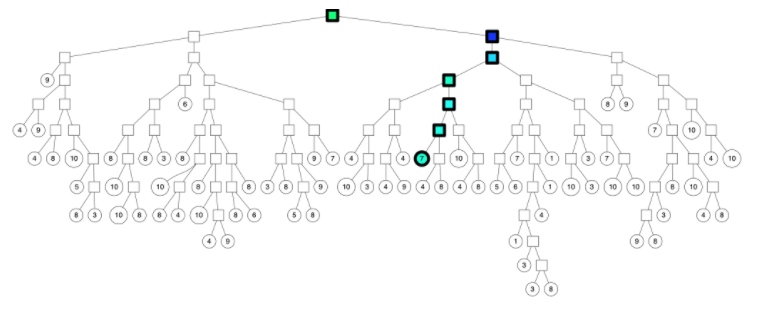
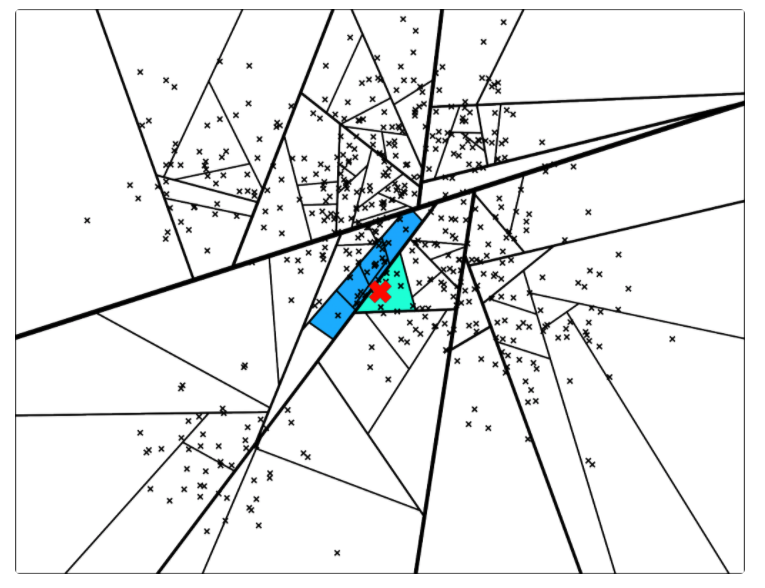
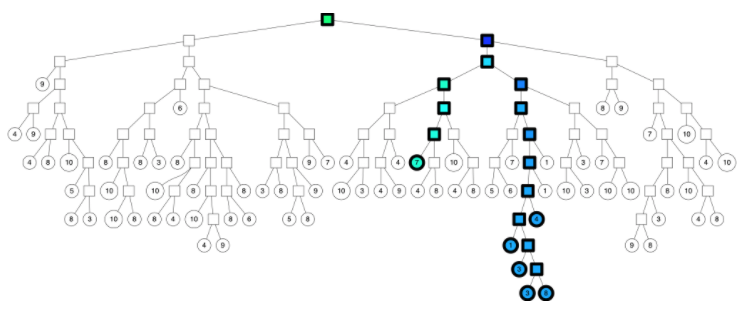
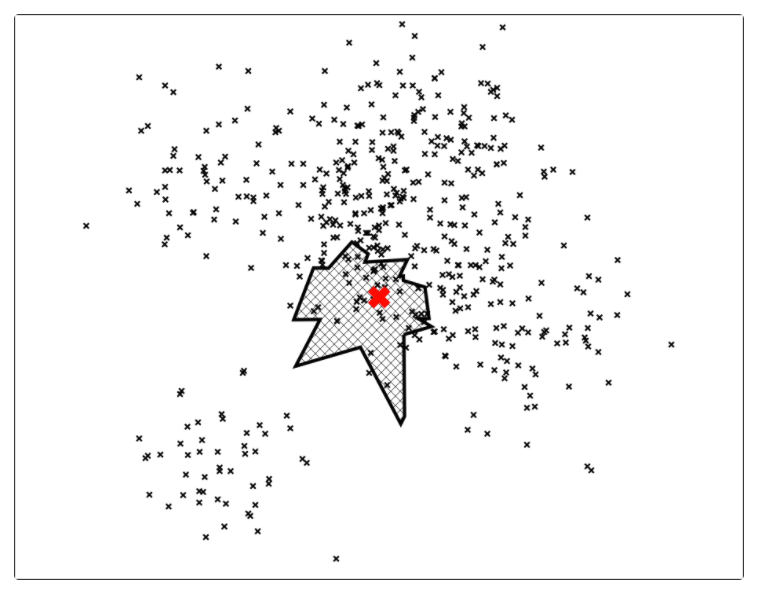
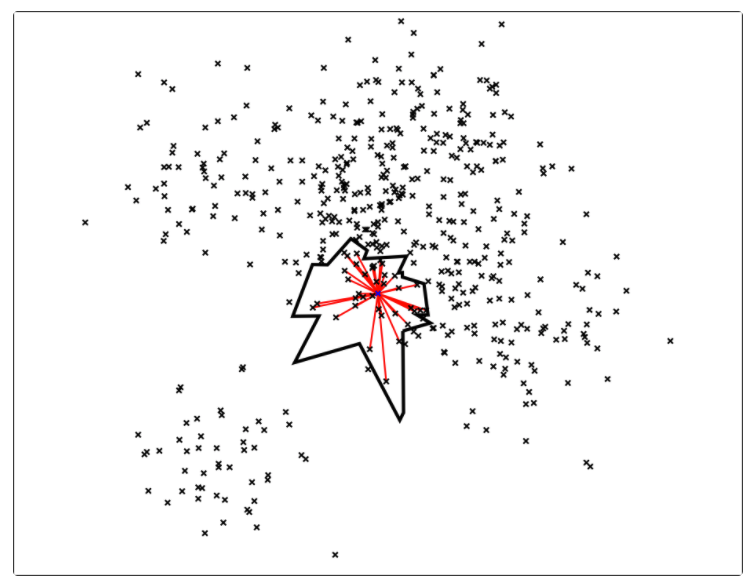
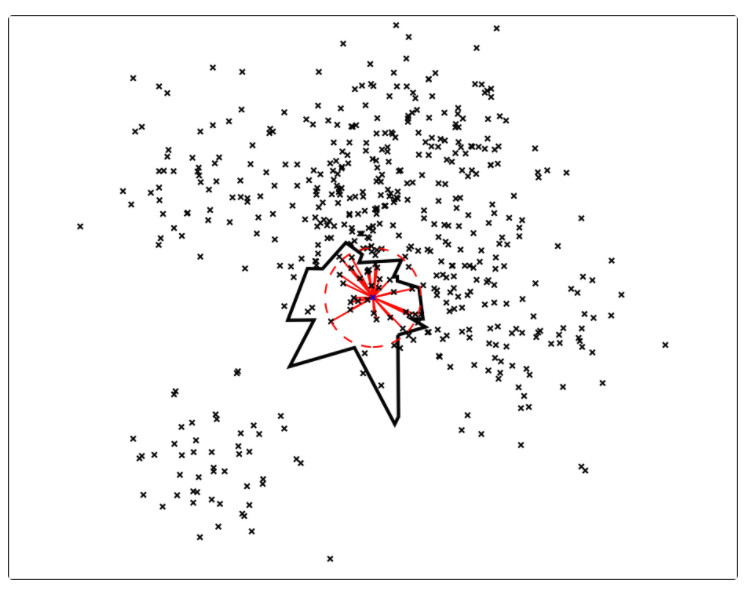
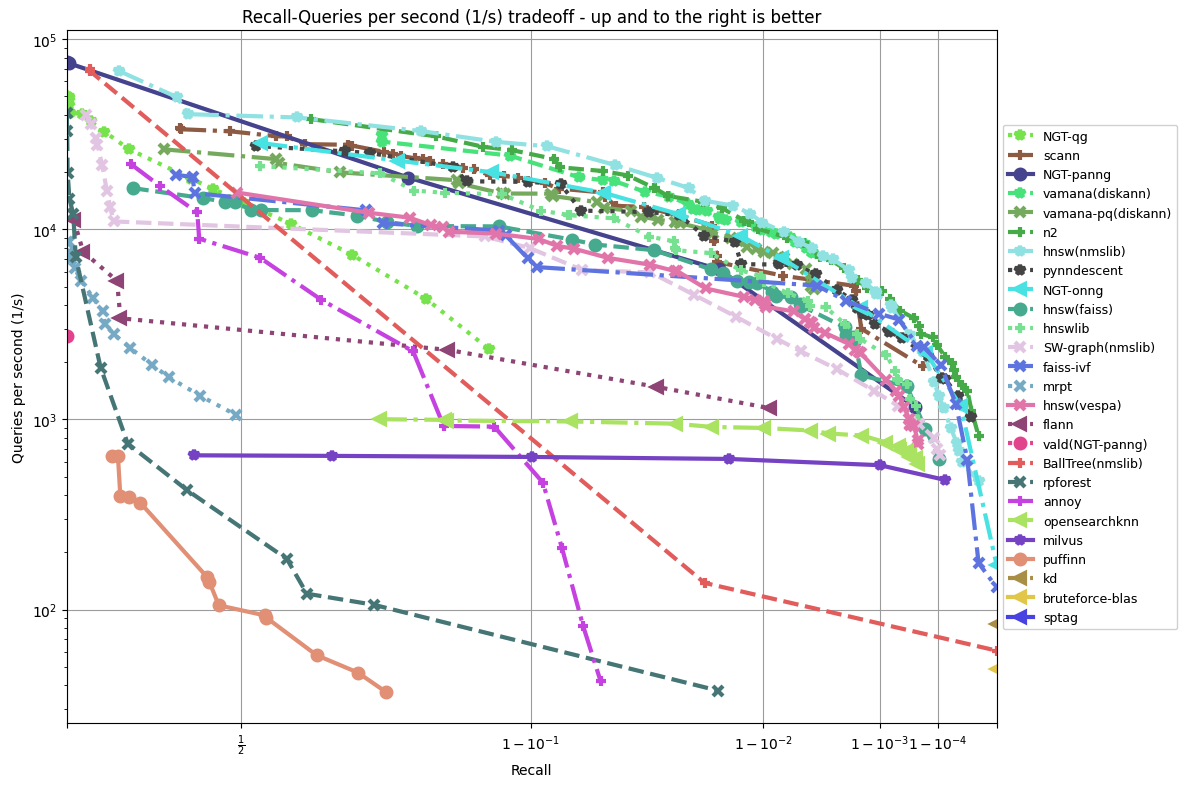
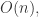 因此,计算机科学家们开发了各种各样的近似最近邻搜索方法(approximate nearest neighbors)来加快其搜索速度,在精确率和召回率上面就会做出一定的牺牲,但是其搜索速度相对暴力搜索有很大地提高。
因此,计算机科学家们开发了各种各样的近似最近邻搜索方法(approximate nearest neighbors)来加快其搜索速度,在精确率和召回率上面就会做出一定的牺牲,但是其搜索速度相对暴力搜索有很大地提高。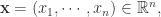 其中
其中  中的 L1 范数;
中的 L1 范数;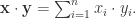

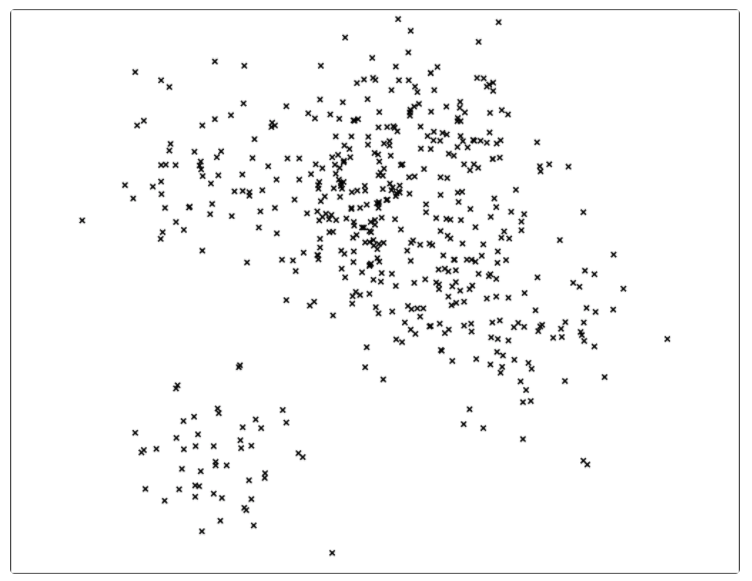
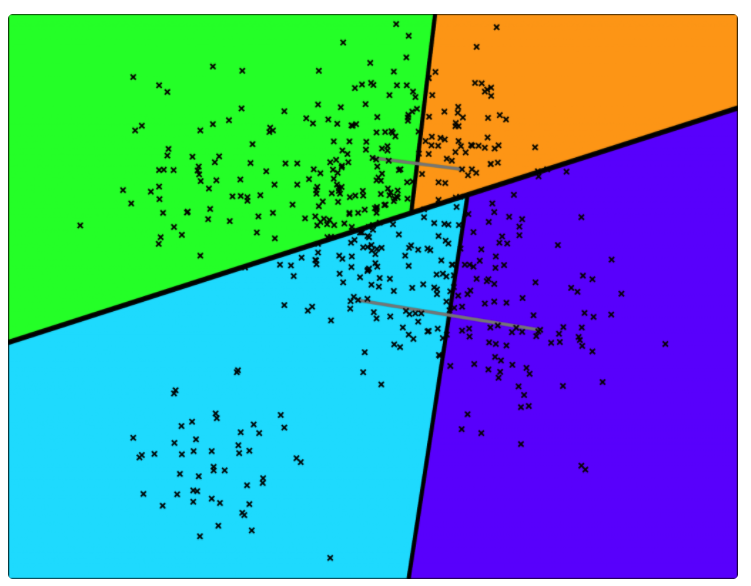
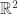 中的点集来作为案例,介绍 annoy 算法的基本思想和算法原理。
中的点集来作为案例,介绍 annoy 算法的基本思想和算法原理。