
描述统计学(descriptive statistics)又称为叙述统计,是统计学中用于描述和总结所观察到对象的基本统计信息的一门学科。描述统计的结果是对当前已知的数据进行更精确的描述和刻画,分析已知数据的集中性和离散型。描述统计学通过一些数理统计方法来反映数据的特点,并通过图表形式对所收集的数据进行必要的可视化,进一步综合概括和分析得出数据的客观规律。
与之相对应的是推断统计学(statistical inference),又称为推断统计,是统计学中研究如何用样本数据来推断总体特征的一门学科。推断统计学是在对样本数据描述的基础上,对总体的未知数据做出以概率形式来描述的推断。推断统计的结果通常是为了得到下一步的行动策略。
本篇文章将会集中讲解描述统计学中的一些常见变量及其含义。
数据类型:
总体(population),又称为全体或者整体,是指由多个具有某种共同性质的事物的集合。
样本(sample),是指全体中随机抽取的个体。通过对样本的调查,可以大概的了解总体的情况。从总体抽样的时候,需要抽取一定数量的样本,如果样本太少,则不足以反映总体的情况。
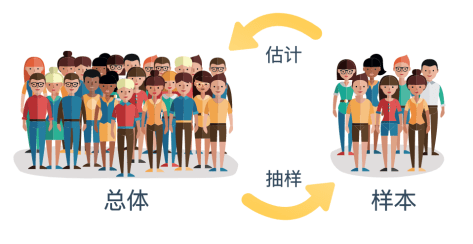
案例 1:一亿张图片所组成的图片集可以称之为一个总体,我们希望分析在这个图片集中包含汽车的图片有多少张。一种方法是一亿张图片每一张都看一遍,从而可以获得包含汽车的图片数量,这样就可以得到一个精确的数字。但是这样的工作量可能相对较大。另外一种方法是从一亿张图片中随机选择十万张或者一百万张,也就是获得了一个样本集。在这个样本集中,把每一张都看一遍,获得这个样本集中包含汽车的图片数量,进一步估算出总体中包含汽车的图片数量。这样的话,工作量相对较少,但是得到的则是一个估算数字。

案例 2:我们想知道某个国家居民的平均身高和体重,一种方法是将所有的居民都测量一遍,但是这样做的效果就是耗费的人力成本巨大。而另外一种办法就是随机抽样,抽取一定数量的居民进行身高和体重的测量。即可估算出这个国家居民的平均身高和体重。
特征类型
在机器学习领域,特征是被观测对象的某种特性和度量。一般情况下,事物的特征很多,但是提取的特征应该尽量要服从于我们的目的,如果提取了很多无效的特征,那么在机器学习实战中的价值也不会很大。通常来说,特征包括两类,第一种是离散型特征,第二种是连续型特征。
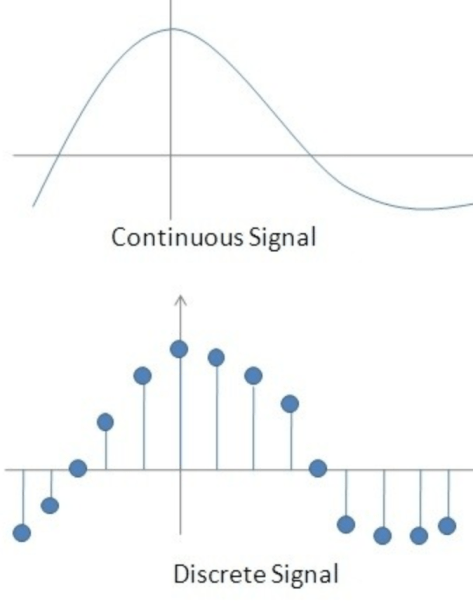
离散型特征指的是该特征的数据类型是离散的(discrete)。例如人的性别,有男女两个选择,可以用 0 或者 1,或者其他记号来表示。例如某个城市是否属于某个省份,如果是的话该特征就是 1,如果否的话该特征就是 0。例如某只股票近期属于上涨还是下跌,上涨用 1 表示,下降用 0 表示。某个人当前处于婴儿,少年,青年,成年,老年的哪个阶段,分别用记号 0,1,2,3,4,5 表示,这种也是离散型特征。离散型特征的数值之间的大小关系(实数域比较)有的时候是没有意义的。例如人的性别,男(0)女(1)两个值,在实数域中 0 < 1,但是却没有意义。
连续性特征指的是该特征的数据类型是连续的(continuous)。例如某个国家一年的天气温度,温度是可以连续变化的,可以从 30 摄氏度连续地下降到 20 摄氏度,也可以连续地上升到 35 摄氏度。某个人的身高,可以从 170 cm 逐渐长高到 175 cm,这也属于连续的特征。连续特征的数值之间有大小关系(实数域比较),比如通过气温特征的值,是可以反映这个地区的温度情况。通过某个人的身高则可以反映出这个人距离上一次测量有没有变化。
特征统计量
集中趋势的度量(measure of central tendency)
集中趋势(central tendency)指的是某种平均的指标,通过这种指标可以反映一组数据的整体分布情况。在这里,这组数据并不需要有先后关系,只要是一个集合即可。对于 

算术平均数(Arithmetic Mean)
数据的总和除以数据的个数,也就是

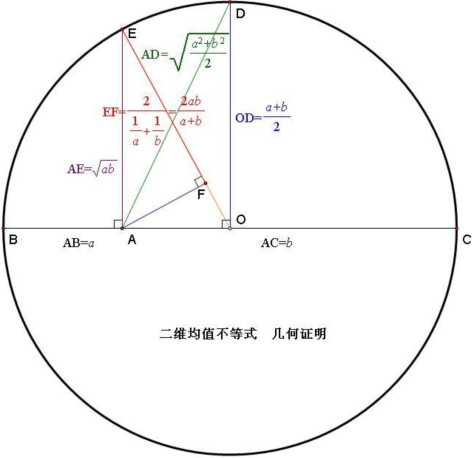
几何平均数(Geometric Mean)
如果该集合里面的数字都是非负数,那么可以定义其几何平均数为
![G_{n}=\sqrt[n]{x_{1}\cdots x_{n}}.](https://s0.wp.com/latex.php?latex=G_%7Bn%7D%3D%5Csqrt%5Bn%5D%7Bx_%7B1%7D%5Ccdots+x_%7Bn%7D%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
从高中的数学知识可以得到几何平均数不大于算术平均数。
调和平均数(Harmonic Mean)
如果该集合里面的数字都是正数,那么可以定义其调和平均数为

平方平均数(Quadratic Mean)
平方平均数指的是

Theorem. 如果 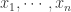

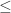
proof. 
方差(Variance),标准差(Standard Deviation)
方差和标准差反映了数据的波动情况,方差指的是 

其中

第二种是样本的标准差(sample standard deviation),此时集合 
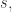

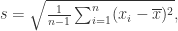
其中
众数(Mode)
众数指的是这个集合
k 阶矩(k Moment),k 阶中心矩(k Central Moment)


它称为样本的 

它称为样本的 
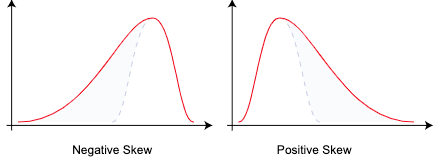
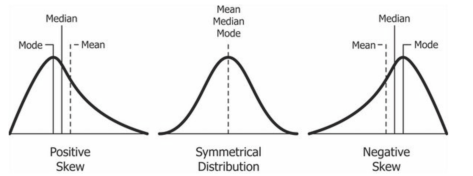
偏度(Skewness)
偏度定义为

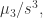

而另外常见的一种样本偏度定义为 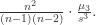
峰度(Kurtosis)

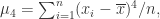

Theorem. 正态分布 4 阶距的值是 3。
Proof. 需要计算 

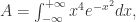



进一步得到 
中位数(Median)
中位数指的是将集合中的数字从小到大排序之后得到的有序数列,中间的那个数字。如果的数列的长度是偶数,则取中间两个数的平均值。

带权重的算术平均数(Weighted Arithmetic Mean)
对于一组数据 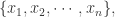
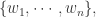
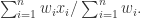
截断平均数(Truncated Mean)
截断平均数是舍弃掉样本中最高和最低的一些样本之后再计算得到的平均值,并且最高和最低两端舍弃的样本数量一致。舍弃的样本数量可以是整体资料数量的占比,也可以是一个固定的数量。
发散度量(measure of dispersion)
四分位距(interquartile range,IQR)
四分位距(IQR),也被称为 midspread,middle 50%,H-spread,它等于 75th 百分位数与 25th 百分位数的差值,也就是
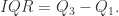
其中,对于长度为 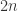

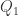

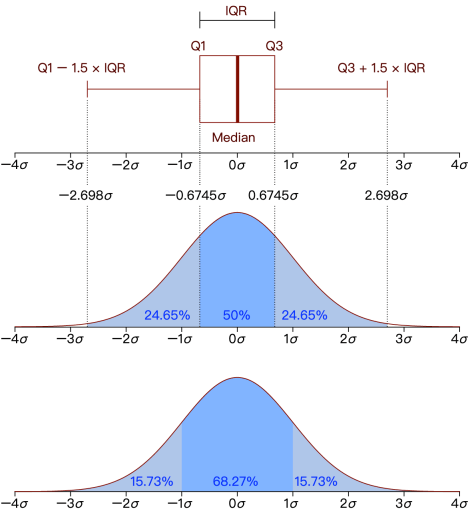
用箱形图(boxplot)作异常检测的时候,上下界分别定义为 

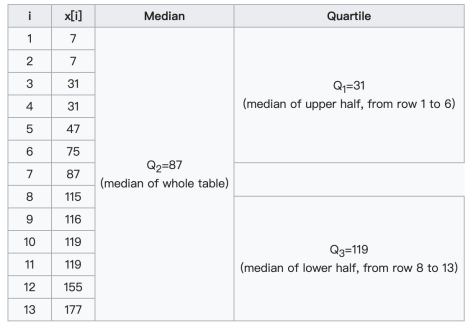
在上述案例中,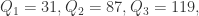



四分位发散系数(quartile coefficient of dispersion)
四分位发散系数也是用于衡量数据集中程度的,对于不同的序列而言,IQR 并没有在一个尺度下进行衡量,无法通过直接对比两个序列的 IQR 来判断它们之间的发散程度(需要先对两个序列进行归一化才行)。于是,有学者提出了另外一种衡量方法,就是四分位发散系数,它的定义就是
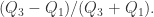
例如: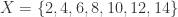



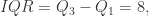

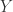

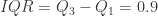

范围(range)
在统计学中,对于集合

该值越大,表示集合的最大值与最小值的差异越大,数据更加发散;该值越小,表示集合的最大值与最小值的差异越小,数据就更加集中。
平均绝对偏差(Mean Absolute Difference)
对于集合 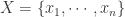

相对平均绝对偏差(Relative Mean Absolute Difference)则定义为:

通过相对平均绝对偏差可以对比两个集合之间的偏差程度。
中位数绝对偏差(median absolute deviation)
中位数绝对偏差定义为 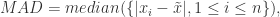

变异系数(coefficient of variation)
变异系数指的是标准差除以均值,i.e.
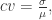
它表示了集合数据相对于均值的波动程度。
例如:

参考资料
- 集中趋势:https://en.wikipedia.org/wiki/Central_tendency
- 离散程度:https://en.wikipedia.org/wiki/Statistical_dispersion
- 描述统计学:https://zh.wikipedia.org/wiki/%E6%8F%8F%E8%BF%B0%E7%BB%9F%E8%AE%A1%E5%AD%A6
- 数据分析的基础—统计学之描述性统计(一):https://zhuanlan.zhihu.com/p/33544707
- 数据分析的基础—统计学之描述性统计(二):https://zhuanlan.zhihu.com/p/34073898
