
(I)特征工程可以解决什么样的问题?
Actually the sucess of all Machine Learning algorithms depends on how you present the data.
—— Mohammad Pezeshki
Better feature means flexibility. Better feature means simpler models. Better feature means better results.
有的时候,可以使用一些不是最优的模型来训练数据,如果特征选择得好的话,依然可以得到一个不错的结果。很多机器学习的模型都能够从数据中选择出不错的结构,从而进行良好的预测。一个优秀的特征具有极强的灵活性,可以使用不那么复杂的,运算速度快,容易理解和维护的模型来得到不错的结果。
(II)什么才是特征工程?
Feature Engineering is the process of transforming raw data into features that better represent the underlying problem to the predictive models, resulting in improved model accuracy on unseen data.
—— Jason Brownlee
Feature Engineering is manually designing what the input x’s should be.
—— Tomasz Malisiewicz
从这个概念可以看出,特征工程其实是一个如何展示和表现数据的问题,在实际工作中需要把数据以一种“良好”的方式展示出来,使得能够使用各种各样的机器学习模型来得到更好的效果。如何从原始数据中去除不佳的数据,展示合适的数据就成为了特征工程的关键问题。
(III)特征有用性的预估
每次构造了一个特征,都需要从各个方面去证明该特征的有效性。一个特征是否重要主要在于该特征与要预测的东西是否是高度相关的,如果是高度相关,那么该特征就是十分重要的。比如常用的工具就是统计学里面的相关系数。
(IV)特征的构造过程
在实际工作中首先肯定要确定具体的问题,然后就是数据的选择和准备过程,再就是模型的准备和计算工作,最后才是展示数据的预测结果。构造特征的一般步骤:
[1]任务的确定:
根据具体的业务确定需要解决的问题。
[2]数据的选择:
整合数据,收集数据。这个时候需要对这些数据的可用性进行评估,可以分成几个方面来考虑。获取这批数据的难易程度,比方说有的数据非常隐私,这批数据获得的难度就很大。其次就是这批数据的覆盖率。比方说要构造某个年龄的特征,那么这些用户中具有年龄特征的比例是多少就是一个关键的指标。如果覆盖率低,那么最后做出的特征可以影响的用户数量就会有限制。如果覆盖率高,那么年龄特征做得好,对最后的模型训练结果都会有一个明显的提升。再就是这批数据的准确率,因为从网上或者其他地方获取的数据,会由于各种各样的因素(用户的因素,数据上报的因素)导致数据不能够完整的反映真实的情况。这个时候就需要事先对这批数据的准确性作出评估。
[3]预处理数据:
[4]特征的构造:
 ,这里
,这里 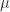 是这个特征的均值,
是这个特征的均值,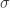 是这个特征的方差。这里的归一化的关键之处在于数据的变化(Data Transforming)。对于处理一些大尺度数据(比方说某个视频被所有用户观看的次数之类的),一般会使用对数来处理数据,或者双曲线函数。例如:
是这个特征的方差。这里的归一化的关键之处在于数据的变化(Data Transforming)。对于处理一些大尺度数据(比方说某个视频被所有用户观看的次数之类的),一般会使用对数来处理数据,或者双曲线函数。例如:

[5] 选择特征的常用方法:
(5.1)过滤(Filter):
过滤这种方法是选定一个指标来评估这个特征的可行性,根据指标值来对已经构造的特征进行排序工作,去掉无法达到要求的特征。这个时候,选择一个合适的指标来判断特征是否有效就是关键所在。从统计学的角度来看,相关系数(Correlation Coefficient)是一个评价两个随机变量 X 和 Y 是否线性相关的一个重要指标。
![\rho_{XY}=cov(X,Y)/(\sigma_{X}\sigma_{Y})\in [-1,1]](https://s0.wp.com/latex.php?latex=%5Crho_%7BXY%7D%3Dcov%28X%2CY%29%2F%28%5Csigma_%7BX%7D%5Csigma_%7BY%7D%29%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
就是相关系数的计算方法。如果 


(5.2)包装(Wrapper):
包装这种方法和前面的过滤方法不一样。包装方法需要首先选定一种评估模型效果的方法,比方说 AUC(Area Under the Curve),MAE(Mean Absolute Error),Mean Squared Error(MSE)等。此时有两个不同的方案,分别是前向特征选择(Forward Feature Selection)和后向特征选择(Backward Feature Selection)。前向特征选择是从空集(Empty Set)开始,使用一种贪心算法,每次在现有特征的基础上逐渐添加一个使得模型效果更好的特征。反之,后向特征选择是从(Full Set)开始,每次去掉一个让模型效果提升最多的特征。或者可以使用增 L 去 R 算法(Plus-L Minus-R Selection),也就是说从空集开始,每次增加 L 个,同时减去 R 个,选择最优的特征,其中 L>R。或者从全集开始,每次减去 R 个,同时增加 L 个,选择最优的特征,其中 L<R。
(5.3)嵌入(Embedding):
嵌入特征选择方法和算法本身紧密结合,在模型训练的过程中完成特征的选择。例如:决策树(Decision Tree)算法每次都是优先选择分类能力最强的特征;逻辑回归(Logistic Regression)算法加上 L1 和 L2 等惩罚项之后,也会使得某些信号比较弱的特征权重很小甚至为 0。至于 Logistic Regression 的一些算法,可以参考 TG(Truncated Gradient Algorithm),FOBOS(Forward and Backward Splitting),RDA(Regularized Dual Averaging Algorithm), FTRL(Follow-the-Regularized-Leader Algorithm) 算法,参考文献:Ad Click Prediction: a View from the Trenches。
[6]模型的使用:
[7]上线的效果:
通过在线测试来看效果。数据的转换(Transforming Data)就是把数据从原始的数据状态转换成适合模型计算的状态,从某些层面上来说,“数据转换“和”特征构造“的过程几乎是一致的。
(V)特征工程的迭代过程
特征工程的迭代步骤:
[1]选择特征:
需要进行头脑风暴(brainstorm)。通过分析具体的问题,查看大量的数据,从数据中观察出数据的关键之处;
[2]设计特征:
这个需要具体问题具体分析,可以自动进行特征提取工作,也可以进行手工进行特征的构造工作,甚至混合两种方法;
[3]判断特征:
使用不同的特征构造方法,来从多个层面来判断这个特征的选择是否合适;
[4]计算模型:
通过模型计算得到模型在该特征上所提升的准确率。
[5]上线测试:
通过在线测试的效果来判断特征是否有效。监控重要特征,防止特征的质量下滑,影响模型的效果。
 subject to
subject to 

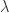 时,这两种描述是等价的。
时,这两种描述是等价的。

 }
}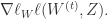
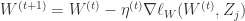 }
}
 是一个标量,且
是一个标量,且  ,为 L1 正则化参数。
,为 L1 正则化参数。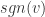 是符号函数,如果
是符号函数,如果  是一个向量,那么
是一个向量,那么  。
。 是学习率,通常假设为
是学习率,通常假设为  的函数。
的函数。 代表了第 t 次迭代中损失函数的梯度,由于 OGD 每次仅根据观测到的一个样本进行权重更新,因此也不再使用区分样本的下标 j。
代表了第 t 次迭代中损失函数的梯度,由于 OGD 每次仅根据观测到的一个样本进行权重更新,因此也不再使用区分样本的下标 j。 是分段函数,
是分段函数,


 并且
并且  。如果
。如果  。
。
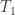 定义为:
定义为:![T_{1}(v_{i},\alpha,\theta)=\max(0,v_{i}-\alpha) \text{ if } v_{i}\in [0,\theta]](https://s0.wp.com/latex.php?latex=T_%7B1%7D%28v_%7Bi%7D%2C%5Calpha%2C%5Ctheta%29%3D%5Cmax%280%2Cv_%7Bi%7D-%5Calpha%29+%5Ctext%7B+if+%7D+v_%7Bi%7D%5Cin+%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


 ,并且
,并且 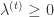 。Truncated Gradient 方法同样是以 k 作为窗口,每进行 k 步就进行一次截断操作。当 t/k 不是整数时,
。Truncated Gradient 方法同样是以 k 作为窗口,每进行 k 步就进行一次截断操作。当 t/k 不是整数时, ,当 t/k 是整数时,
,当 t/k 是整数时, 。从上面的公式可以看出,
。从上面的公式可以看出,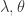 决定了 W 的稀疏程度,如果
决定了 W 的稀疏程度,如果 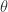 都很大,那么稀疏性就会越强。特别的,当
都很大,那么稀疏性就会越强。特别的,当  时,此时只需要控制一个参数就可以控制稀疏性。
时,此时只需要控制一个参数就可以控制稀疏性。 for t = 1,2,3,... 计算
for t = 1,2,3,... 计算  按照下面规则更新 W,
(i)当 t/k 不是整数时,采用标准的 SGD (Stochastic Gradient Descent) 进行迭代。
按照下面规则更新 W,
(i)当 t/k 不是整数时,采用标准的 SGD (Stochastic Gradient Descent) 进行迭代。 for all
for all 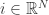 .
(ii)当 t/k 是整数时,采取截断技术。
.
(ii)当 t/k 是整数时,采取截断技术。
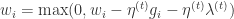 , if
, if ![(w_{i}-\eta^{(t)}g_{i})\in[0,\theta]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B0%2C%5Ctheta%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
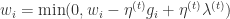 , else if
, else if ![(w_{i}-\eta^{(t)}g_{i})\in[-\theta,0]](https://s0.wp.com/latex.php?latex=%28w_%7Bi%7D-%5Ceta%5E%7B%28t%29%7Dg_%7Bi%7D%29%5Cin%5B-%5Ctheta%2C0%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 , otherwise
return W.
, otherwise
return W. 和
和 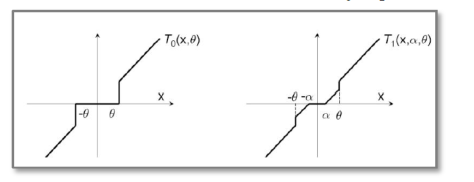
 ,截断梯度法就可以变成简单截断法。从公式上也可以通过计算直接得出。
,截断梯度法就可以变成简单截断法。从公式上也可以通过计算直接得出。
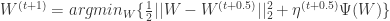

 ,如果
,如果  存在一个最优解,那么可以推断 0 向量一定属于
存在一个最优解,那么可以推断 0 向量一定属于  的次梯度集合:
的次梯度集合: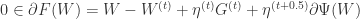 .
.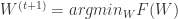 , 那么可以得到权重更新的另外一种形式:
, 那么可以得到权重更新的另外一种形式: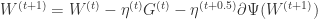
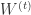 有关,还和自己
有关,还和自己 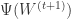 有关。这也许就是”前向后向切分”这个名称的由来。
有关。这也许就是”前向后向切分”这个名称的由来。 是 L1 范数,中间向量是
是 L1 范数,中间向量是  , 并且参数
, 并且参数 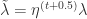 ,那么公式就可以展开得到
,那么公式就可以展开得到
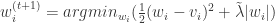 for all $latex 1\leq i \leq N$.
for all $latex 1\leq i \leq N$. 是
是  的最优解,那么
的最优解,那么  .
. ,那么
,那么  , 这与条件矛盾。
, 这与条件矛盾。
 for all
for all 
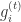 是梯度
是梯度 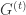 在第 i 个维度的分量。
在第 i 个维度的分量。 , 则有
, 则有  意思就是如果这次训练产生梯度的变化不足以令权重值发生足够大的变化时,就认为在这次训练中该维度不够重要,应该强制其权重是0.
意思就是如果这次训练产生梯度的变化不足以令权重值发生足够大的变化时,就认为在这次训练中该维度不够重要,应该强制其权重是0. ,那么则有
,那么则有
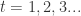 , 计算
, 计算  ,
, for all
for all  (3)Return W
(3)Return W ,可以得到 L1-FOBOS 与 Truncated Gradient 完全一致,换句话说 L1-FOBOS 是 Truncated Gradient 在一些特定条件下的形式。
,可以得到 L1-FOBOS 与 Truncated Gradient 完全一致,换句话说 L1-FOBOS 是 Truncated Gradient 在一些特定条件下的形式。
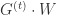 指的是向量
指的是向量  是一个严格凸函数,
是一个严格凸函数, 是一个非负递增序列。
是一个非负递增序列。 包括了之前所有梯度的平均值。
包括了之前所有梯度的平均值。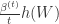 。
。 ;
; ,i.e.
,i.e.  是一个非负递增序列。那么 RDA 算法就可以写成:
是一个非负递增序列。那么 RDA 算法就可以写成:



 if
if 
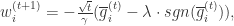 otherwise
otherwise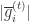 小于
小于  ,初始化
,初始化  (2)for
(2)for  更新
更新 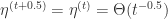 ,可以得到:
,可以得到: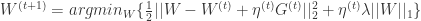

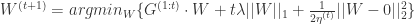
 。如果令
。如果令 

 上面的公式可以写成:
上面的公式可以写成:

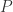 和
和 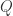 的一个非对称的度量公式。这个概念是由 Solomon Kullback 和 Richard Leibler 在 1951 年引入的。从概率分布
的一个非对称的度量公式。这个概念是由 Solomon Kullback 和 Richard Leibler 在 1951 年引入的。从概率分布  来表示。尽管从直觉上看 KL 散度是一个度量或者是一个距离,但是它却不满足度量或者距离的定义。例如,从
来表示。尽管从直觉上看 KL 散度是一个度量或者是一个距离,但是它却不满足度量或者距离的定义。例如,从 
 对于所有的
对于所有的  都成立。如果
都成立。如果 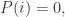 那么可以假设KL散度的第
那么可以假设KL散度的第 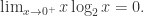
 的两个概率分布
的两个概率分布 
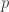 和
和 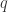 是概率分布
是概率分布  几乎处处成立的时候,才会有
几乎处处成立的时候,才会有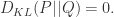
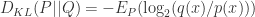
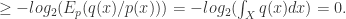
 是独立分布,并且联合分布是
是独立分布,并且联合分布是 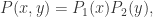
 是独立分布并且联合分布是
是独立分布并且联合分布是  那么
那么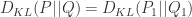 +
+ 
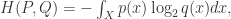

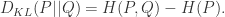

 +
+ 
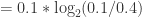 +
+  +
+ 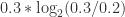 +
+ 
 函数的输入是一组实数,那么对该函数进行近似的时候,最简单的方案就是
函数的输入是一组实数,那么对该函数进行近似的时候,最简单的方案就是 。在这里,
。在这里,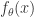 的参数。机器学习就是通过对这个参数的学习,完成函数的近似计算。这个模型对于
的参数。机器学习就是通过对这个参数的学习,完成函数的近似计算。这个模型对于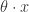 扩展成如下形式:
扩展成如下形式: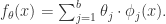
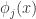 是基函数向量
是基函数向量 的第
的第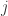 个分量,
个分量, 是
是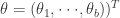 的第
的第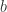

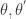 和
和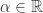 ,满足
,满足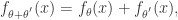


![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上的连续函数,对于任意的
上的连续函数,对于任意的 ,则存在多项式
,则存在多项式 使得对于所有的
使得对于所有的![x\in [a,b]](https://s0.wp.com/latex.php?latex=x%5Cin+%5Ba%2Cb%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,有
,有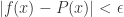
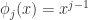
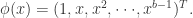
 的非线性函数,而且
的非线性函数,而且 可以逼近关于
可以逼近关于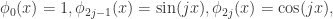 其中
其中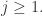
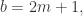
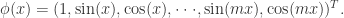
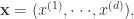 函数依旧可以扩展成如下模式:
函数依旧可以扩展成如下模式: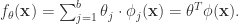
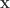
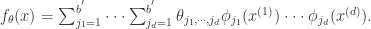
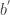 是各个维数的参数个数。对于这个模型而言,它的表现力十分丰富,但是不足之处在于所有的参数个数是
是各个维数的参数个数。对于这个模型而言,它的表现力十分丰富,但是不足之处在于所有的参数个数是 是一个非常巨大的数字,导致的维数灾难,所以在实际运用中,不主张用这个模型。
是一个非常巨大的数字,导致的维数灾难,所以在实际运用中,不主张用这个模型。
 它是一个关于维数
它是一个关于维数
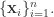
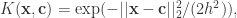
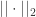
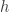


 有
有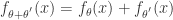 和
和  对于核函数来说,无论输入的是一维变量还是高维变量,核函数都可以容易的进行扩展。
对于核函数来说,无论输入的是一维变量还是高维变量,核函数都可以容易的进行扩展。
 是关于参数向量
是关于参数向量 的基函数,层级模型是基于参数向量
的基函数,层级模型是基于参数向量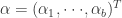 的线性形式。同时也包含参数向量
的线性形式。同时也包含参数向量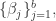 所以层级模型是基于参数向量
所以层级模型是基于参数向量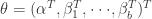 的非线性形式。
的非线性形式。 其中
其中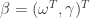
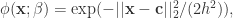 其中
其中
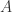 与其余三个物品1,2,3的相似度分别是
与其余三个物品1,2,3的相似度分别是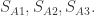 物品1,2,3的点击率(click through rate)分别是
物品1,2,3的点击率(click through rate)分别是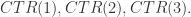 此刻如果物品3的点击率过低,那么需要把第3个物品与物品
此刻如果物品3的点击率过低,那么需要把第3个物品与物品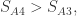 从而使得第4个物品能够取代第3个物品。
从而使得第4个物品能够取代第3个物品。
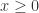 是待定的系数。下面就来研究新的相似度满足的性质。
是待定的系数。下面就来研究新的相似度满足的性质。 对任何的实数
对任何的实数 i.e. 第1个物品的点击率最高,那么
i.e. 第1个物品的点击率最高,那么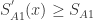 对于任何
对于任何 对于
对于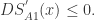
 换句话说,随着
换句话说,随着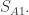
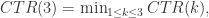 那么
那么 对于任何
对于任何 对于
对于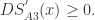
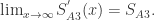 换句话说,随着
换句话说,随着
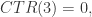 那么
那么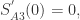 通过选择合适的
通过选择合适的 可以使得
可以使得 在这里的
在这里的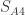 指的是物品
指的是物品
 如果
如果 ,那么表示用户i购买了物品j;如果
,那么表示用户i购买了物品j;如果 , 那么表示用户i没有购买物品j。用
, 那么表示用户i没有购买物品j。用 来表示物品1到物品n的能量。用
来表示物品1到物品n的能量。用 表示用户
表示用户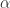 的度,也就是该用户购买的物品数量。用
的度,也就是该用户购买的物品数量。用 表示物品j的度,也就是该物品被多少个用户购买过。根据物质扩散的算法描述,第一步需要计算出用户从物品那里得到的能量,此时用户
表示物品j的度,也就是该物品被多少个用户购买过。根据物质扩散的算法描述,第一步需要计算出用户从物品那里得到的能量,此时用户 表示,那么
表示,那么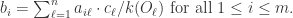
 表示,那么
表示,那么
 我们有
我们有
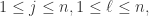

 矩阵
矩阵 列向量
列向量 和
和 ,那么
,那么
 每列的和都是1,i.e.
每列的和都是1,i.e.  对于所有的
对于所有的 都成立。
都成立。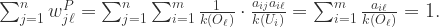
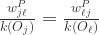 对于所有的
对于所有的 都成立。换言之,矩阵
都成立。换言之,矩阵 和
和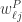 的定义可以得到结论。
的定义可以得到结论。 对于所有的
对于所有的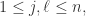 可以得到
可以得到

 可以直接计算得到:
可以直接计算得到: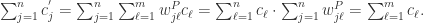
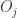 的用户都是物品
的用户都是物品 的用户,换句话说,如果
的用户,换句话说,如果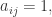 则有
则有 那么
那么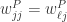 对于所有的
对于所有的 那么物品
那么物品

 那么上面两个式子相等。i.e.
那么上面两个式子相等。i.e. 
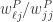 可以看成物品
可以看成物品 那么说明物品
那么说明物品 那么说明物品
那么说明物品 越小,那么物品
越小,那么物品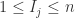 对于所有的
对于所有的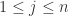 都是成立的。
都是成立的。 对于
对于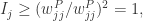 所以上面性质成立。
所以上面性质成立。 的相似度是
的相似度是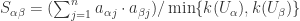
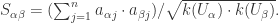
 并没有选择物品
并没有选择物品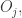 那么预测分数则是
那么预测分数则是
 是否购买了物品
是否购买了物品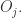 然后对于任意的用户和物品组成的对
然后对于任意的用户和物品组成的对 只要
只要 从大到小对
从大到小对 如下:
如下:
 对计算用户相似度的时候有抑制作用。此时的评分系统则是:如果用户
对计算用户相似度的时候有抑制作用。此时的评分系统则是:如果用户 之前没有购买物品
之前没有购买物品 那么其预测分数则是
那么其预测分数则是
 定义用户
定义用户 的相似度
的相似度 如下:
如下:
 时,减弱了热门物品对用户相似度的影响;当
时,减弱了热门物品对用户相似度的影响;当 时,增加了热门物品对用户相似度的影响。某篇论文显示基于某些数据,
时,增加了热门物品对用户相似度的影响。某篇论文显示基于某些数据, 是最佳的参数。
是最佳的参数。