
引言
在推荐系统中,常常用二部图来表示用户和物品的关系:把用户(Users)看成一类点,把物品(Objects)看成另一类点。如果用户购买了某种物品,那么用户和物品之间就存在一条连线,也就是一条边。如果用户没有购买某种物品,那么用户和物品之间就没有连线。但是用户和用户之间,物品和物品之间是不存在连线的。换句话说就是同一类点之间是不存在连线的。这样的图结构就叫做二部图。电子商务中间的物品推荐,可以看成是二部图的边的挖掘问题。扩散过程可以用来寻找二部图中两个节点的关联强度。经典的扩散过程分成两类:一种叫做物质扩散(Probabilistic Spreading),它满足能量守恒定律;另一种叫做热传导(Heat Spreading),一般由一个或多个热源(物品)驱动,不一定满足能量守恒定律。
物质扩散(Probabilistic Spreading)算法流程
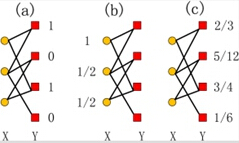
如图所示,用黄色的点来表示用户,用红色的点表示物品。用户有三位,物品有四个。第一个用户和第一个物品有连线表示第一个用户购买了第一个物品,而与第二个物品没有连线表示第一个用户没有购买第二个物品。根据图像(a)所示,第一个物品和第三个物品有能量1,第二个物品和第四个物品有能量0.对于物质扩散过程,第一个物品需要把自己的能量1平均分配给购买过它的用户一和用户二。第三个物品也需要把自己的能量1平均分配给购买过它的用户一和用户三。用户的能量就是所有用物品得到的能量的总和。正如图像(b)所示,第一个用户此时具有能量1,第二个和第三个用户都具有能量1/2.接下来,每个用户再把自身的能量平均分配给所有购买过的物品,物品的能量则是从所有用户得到的能量的总和。所以第一个物品的能量就是第一个用户的能量乘以0.5加上第二个用户的能量乘以1/3,所得的能量则是2/3.其他物品的能量用类似的方法计算。
物质扩散(Probabilistic Spreading)数学模型
假设有m个用户(Users)和n个物品(Objects),可以构造矩阵




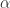



后面需要通过用户的能量来更新物品的能量,假设物品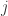


把

在这里对于
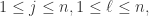

假设




性质1. 矩阵每列的和都是1,i.e.
对于所有的
都成立。
证明.
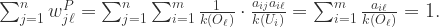
性质2.对于所有的
都成立。换言之,矩阵
证明. 根据
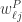
性质3. 矩阵对于所有的
证明. 根据矩阵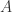
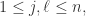

性质4. 能量守恒定律:

证明. 根据前面的性质,已经知道
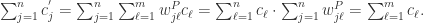
性质5. 如果物品的用户都是物品
的用户,换句话说,如果
则有
那么
对于所有的
那么物品
证明. 根据


根据条件,如果
根据上面性质,可以定义变量

其中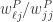



性质6.对于所有的
都是成立的。
证明. 根据以上性质可以得到
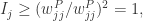
基于物质扩散算法的用户相似度
回顾一下基于用户的协同过滤算法:用户
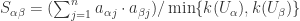
或者使用余弦表达式
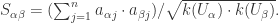
如果用户
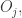

这里的求和指的把除了用户
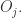


下面来介绍基于物质扩散方法的算法。与上面的方法类似,第一步就是定义用户相似度

上面定义表示物品



对于物质扩散的算法,可以用以下简单方法进行推广。增加参数



当


