
回归方法是为了对连续型的数据做出预测,其中最简单的回归方法当然就是线性回归。顾名思义,线性回归就是使用线性方程来对已知的数据集合进行拟合,达到预测未来的目的。线性回归的优点就是结果十分容易理解,计算公式简单;缺点则是对非线性的数据拟合程度不够好。例如,用一个线性函数 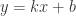

(一)线性回归(Linear Regression)
假设矩阵 X 的每一行表示一个样本,每一列表示相应的特征,列向量 Y 表示矩阵 X 所对应的取值,那么我们需要找到一个列向量 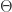
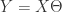
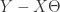

的取值足够小,其中 m 是矩阵 X 的行数,

对 


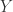

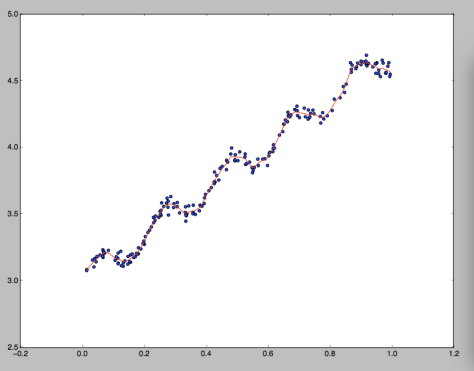
举例说明:蓝色的是数据集,使用线性回归计算的话会得到一条直线。
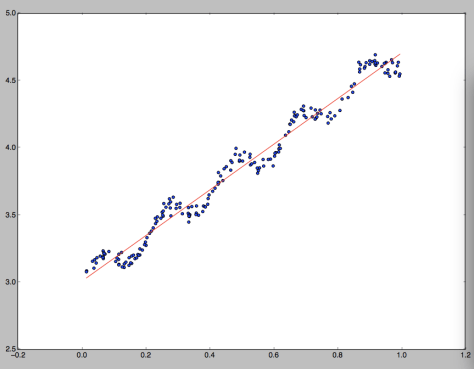
(二)局部加权线性回归(Locally Weighted Linear Regression)
线性回归的一个问题就是会出现欠拟合的情况,因为线性方程确实很难精确地描述现实生活的大量数据集。因此有人提出了局部加权线性回归(Locally Weighted Linear Regression),在该算法中,给每一个点都赋予一定的权重,也就是

其中 


对

令导数等于零之后得到:

局部加权线性回归需要确定权重矩阵 W 的值,那么就需要定义对角线的取值,通常情况下我们会使用高斯核。
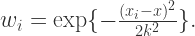
其中 k 是参数。从高斯核的定义可以看出,如果 
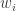

如果选择了合适的

(三)岭回归(Ridge Regression)和 LASSO
如果在某种特殊的情况下,特征的个数 n 大于样本的个数 m,i.e. 矩阵 X 的列数多于行数,那么 X 不是一个满秩矩阵,因此在计算 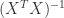




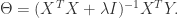
岭回归最初只是为了解决特征数目大于样本数目的情况,现在也可以用于在估计中加入偏差,从而得到更好的估计。
从另一个角度来讲,当样本的特征很多,而样本的数量相对少的时候,
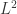
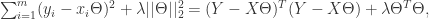
其中 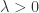
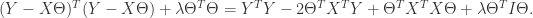
对

令导数等于零可以得到: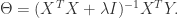
需要注意的是:在进行岭回归的时候,需要在一开始就对特征进行标准化处理,使得每一维度的特征具有相同的重要性。具体来说就是 (特征-特征的均值)/特征的方差,让每一维度的特征都满足零均值和单位方差。
另外,如果把岭回归中的 

其中的参数
(四)前向逐步线性回归(Forward Stagewise Linear Regression)
前向逐步线性回归算法是一种贪心算法,目的是在每一步都尽可能的减少误差。初始化的时候,所有的权重都设置为1,然后每一步所做的据测就是对某个权重增加或者减少一个很小的值 
该算法的伪代码如下所示:
数据标准化,使其分布满足零均值和单位方差
在每一轮的迭代中:
设置当前最小误差为正无穷
对每个特征:
增大或者缩小:
改变一个系数得到一个新的权重W
计算新W下的误差
如果误差Error小于当前误差:设置Wbest等于当前的W
将W设置为新的Wbest
(五)总结
与分类一样,回归也是预测目标值的过程。但是分类预测的是离散型变量,回归预测的是连续型变量。但是在大多数情况下,数据之间会很复杂,这种情况下使用线性模型确实不是特别合适,需要采用其余的方法,例如非线性模型等。
