
(一)基本思想
给定一个概率分布 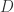

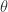


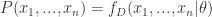
但是,在这里我们并不知道参数 
最大似然估计 (maximal likelihood estimator) 算法会计算参数
用数学的语言来说,首先我们需要定义似然函数:
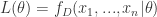
并且在 

Remark. 最大似然函数不一定是唯一的,甚至不一定是存在的。
(二)基本算法
求解最大似然函数估计值的一般步骤:
(1)定义似然函数;
(2)对似然函数求导数,或者说对似然函数的对数求导数,目的都是为了更加方便地计算一阶导数;
(3)令一阶导数等于零,得到关于参数
(4)求解似然方程,得到的参数就是最大似然估计。在求解的过程中,如果不能够直接求解方程的话,可以采取牛顿法来近似求解。
(三)例子
(i)Bernoulli 分布(Bernoulli Distribution)
假设我们有 
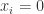


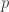
如果 
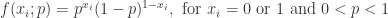
因此,似然函数 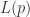

为了计算参数 


令 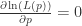

也就是说最大似然估计是
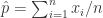
(ii)Gaussian Distribution
假设 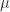

如果 
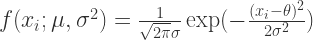
似然函数就是:

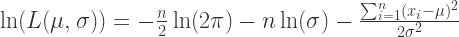


令 
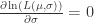


(iii) Weibull 分布(Weibull Distribution)
首先,我们回顾一下 Weibull 分布的定义。Weibull 分布(Weibull Distribution)是连续型的概率分布,其概率密度函数是:

其中,
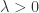



Weibull 分布的累积分布函数是

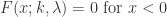
Weibull 分布的分位函数(quantile function, inverse cumulative distribution)是

其次,我们来计算最大似然估计。
假设 
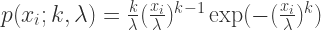
定义似然函数为:

取对数之后得到:

计算一阶偏导数得到:

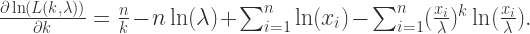
可以计算得出:
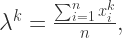
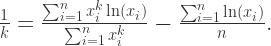
其中第一个式子可以计算出 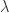

令

求导得到:
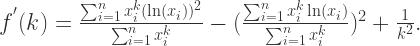
根据 Cauchy’s Inequality, 可以得到:

所以,
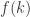


那么对于递增函数 


当 
