Introduction
If things don’t go your way in predictive modeling, use XGboost. XGBoost algorithm has become the ultimate weapon of many data scientist. It’s a highly sophisticated algorithm, powerful enough to deal with all sorts of irregularities of data.
Building a model using XGBoost is easy. But, improving the model using XGBoost is difficult (at least I struggled a lot). This algorithm uses multiple parameters. To improve the model, parameter tuning is must. It is very difficult to get answers to practical questions like – Which set of parameters you should tune ? What is the ideal value of these parameters to obtain optimal output ?
This article is best suited to people who are new to XGBoost. In this article, we’ll learn the art of parameter tuning along with some useful information about XGBoost. Also, we’ll practice this algorithm using a data set in Python.

What should you know ?
XGBoost (eXtreme Gradient Boosting) is an advanced implementation of gradient boosting algorithm. Since I covered Gradient Boosting Machine in detail in my previous article – Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python, I highly recommend going through that before reading further. It will help you bolster your understanding of boosting in general and parameter tuning for GBM.
Special Thanks: Personally, I would like to acknowledge the timeless support provided by Mr. Sudalai Rajkumar (aka SRK), currently AV Rank 2. This article wouldn’t be possible without his help. He is helping us guide thousands of data scientists. A big thanks to SRK!
Table of Contents
- The XGBoost Advantage
- Understanding XGBoost Parameters
- Tuning Parameters (with Example)
1. The XGBoost Advantage
I’ve always admired the boosting capabilities that this algorithm infuses in a predictive model. When I explored more about its performance and science behind its high accuracy, I discovered many advantages:
- Regularization:
- Standard GBM implementation has no regularization like XGBoost, therefore it also helps to reduce overfitting.
- In fact, XGBoost is also known as ‘regularized boosting‘ technique.
- Parallel Processing:
- XGBoost implements parallel processing and is blazingly faster as compared to GBM.
- But hang on, we know that boosting is sequential process so how can it be parallelized? We know that each tree can be built only after the previous one, so what stops us from making a tree using all cores? I hope you get where I’m coming from. Check this link out to explore further.
- XGBoost also supports implementation on Hadoop.
- High Flexibility
- XGBoost allow users to define custom optimization objectives and evaluation criteria.
- This adds a whole new dimension to the model and there is no limit to what we can do.
- Handling Missing Values
- XGBoost has an in-built routine to handle missing values.
- User is required to supply a different value than other observations and pass that as a parameter. XGBoost tries different things as it encounters a missing value on each node and learns which path to take for missing values in future.
- Tree Pruning:
- A GBM would stop splitting a node when it encounters a negative loss in the split. Thus it is more of a greedy algorithm.
- XGBoost on the other hand make splits upto the max_depth specified and then start pruningthe tree backwards and remove splits beyond which there is no positive gain.
- Another advantage is that sometimes a split of negative loss say -2 may be followed by a split of positive loss +10. GBM would stop as it encounters -2. But XGBoost will go deeper and it will see a combined effect of +8 of the split and keep both.
- Built-in Cross-Validation
- XGBoost allows user to run a cross-validation at each iteration of the boosting process and thus it is easy to get the exact optimum number of boosting iterations in a single run.
- This is unlike GBM where we have to run a grid-search and only a limited values can be tested.
- Continue on Existing Model
- User can start training an XGBoost model from its last iteration of previous run. This can be of significant advantage in certain specific applications.
- GBM implementation of sklearn also has this feature so they are even on this point.
I hope now you understand the sheer power XGBoost algorithm. Note that these are the points which I could muster. You know a few more? Feel free to drop a comment below and I will update the list.
Did I whet your appetite ? Good. You can refer to following web-pages for a deeper understanding:
2. XGBoost Parameters
The overall parameters have been divided into 3 categories by XGBoost authors:
- General Parameters: Guide the overall functioning
- Booster Parameters: Guide the individual booster (tree/regression) at each step
- Learning Task Parameters: Guide the optimization performed
I will give analogies to GBM here and highly recommend to read this article to learn from the very basics.
General Parameters
These define the overall functionality of XGBoost.
- booster [default=gbtree]
- Select the type of model to run at each iteration. It has 2 options:
- gbtree: tree-based models
- gblinear: linear models
- silent [default=0]:
- Silent mode is activated is set to 1, i.e. no running messages will be printed.
- It’s generally good to keep it 0 as the messages might help in understanding the model.
- nthread [default to maximum number of threads available if not set]
- This is used for parallel processing and number of cores in the system should be entered
- If you wish to run on all cores, value should not be entered and algorithm will detect automatically
There are 2 more parameters which are set automatically by XGBoost and you need not worry about them. Lets move on to Booster parameters.
Booster Parameters
Though there are 2 types of boosters, I’ll consider only tree booster here because it always outperforms the linear booster and thus the later is rarely used.
- eta [default=0.3]
- Analogous to learning rate in GBM
- Makes the model more robust by shrinking the weights on each step
- Typical final values to be used: 0.01-0.2
- min_child_weight [default=1]
- Defines the minimum sum of weights of all observations required in a child.
- This is similar to min_child_leaf in GBM but not exactly. This refers to min “sum of weights” of observations while GBM has min “number of observations”.
- Used to control over-fitting. Higher values prevent a model from learning relations which might be highly specific to the particular sample selected for a tree.
- Too high values can lead to under-fitting hence, it should be tuned using CV.
- max_depth [default=6]
- The maximum depth of a tree, same as GBM.
- Used to control over-fitting as higher depth will allow model to learn relations very specific to a particular sample.
- Should be tuned using CV.
- Typical values: 3-10
- max_leaf_nodes
- The maximum number of terminal nodes or leaves in a tree.
- Can be defined in place of max_depth. Since binary trees are created, a depth of ‘n’ would produce a maximum of 2^n leaves.
- If this is defined, GBM will ignore max_depth.
- gamma [default=0]
- A node is split only when the resulting split gives a positive reduction in the loss function. Gamma specifies the minimum loss reduction required to make a split.
- Makes the algorithm conservative. The values can vary depending on the loss function and should be tuned.
- max_delta_step [default=0]
- In maximum delta step we allow each tree’s weight estimation to be. If the value is set to 0, it means there is no constraint. If it is set to a positive value, it can help making the update step more conservative.
- Usually this parameter is not needed, but it might help in logistic regression when class is extremely imbalanced.
- This is generally not used but you can explore further if you wish.
- subsample [default=1]
- Same as the subsample of GBM. Denotes the fraction of observations to be randomly samples for each tree.
- Lower values make the algorithm more conservative and prevents overfitting but too small values might lead to under-fitting.
- Typical values: 0.5-1
- colsample_bytree [default=1]
- Similar to max_features in GBM. Denotes the fraction of columns to be randomly samples for each tree.
- Typical values: 0.5-1
- colsample_bylevel [default=1]
- Denotes the subsample ratio of columns for each split, in each level.
- I don’t use this often because subsample and colsample_bytree will do the job for you. but you can explore further if you feel so.
- lambda [default=1]
- L2 regularization term on weights (analogous to Ridge regression)
- This used to handle the regularization part of XGBoost. Though many data scientists don’t use it often, it should be explored to reduce overfitting.
- alpha [default=0]
- L1 regularization term on weight (analogous to Lasso regression)
- Can be used in case of very high dimensionality so that the algorithm runs faster when implemented
- scale_pos_weight [default=1]
- A value greater than 0 should be used in case of high class imbalance as it helps in faster convergence.
Learning Task Parameters
These parameters are used to define the optimization objective the metric to be calculated at each step.
- objective [default=reg:linear]
- This defines the loss function to be minimized. Mostly used values are:
- binary:logistic –logistic regression for binary classification, returns predicted probability (not class)
- multi:softmax –multiclass classification using the softmax objective, returns predicted class (not probabilities)
- you also need to set an additional num_class (number of classes) parameter defining the number of unique classes
- multi:softprob –same as softmax, but returns predicted probability of each data point belonging to each class.
- eval_metric [ default according to objective ]
- The metric to be used for validation data.
- The default values are rmse for regression and error for classification.
- Typical values are:
- rmse – root mean square error
- mae – mean absolute error
- logloss – negative log-likelihood
- error – Binary classification error rate (0.5 threshold)
- merror – Multiclass classification error rate
- mlogloss – Multiclass logloss
- auc: Area under the curve
- seed [default=0]
- The random number seed.
- Can be used for generating reproducible results and also for parameter tuning.
If you’ve been using Scikit-Learn till now, these parameter names might not look familiar. A good news is that xgboost module in python has an sklearn wrapper called XGBClassifier. It uses sklearn style naming convention. The parameters names which will change are:
- eta –> learning_rate
- lambda –> reg_lambda
- alpha –> reg_alpha
You must be wondering that we have defined everything except something similar to the “n_estimators” parameter in GBM. Well this exists as a parameter in XGBClassifier. However, it has to be passed as “num_boosting_rounds” while calling the fit function in the standard xgboost implementation.
I recommend you to go through the following parts of xgboost guide to better understand the parameters and codes:
- XGBoost Parameters (official guide)
- XGBoost Demo Codes (xgboost GitHub repository)
- Python API Reference (official guide)
3. Parameter Tuning with Example
We will take the data set from Data Hackathon 3.x AV hackathon, same as that taken in the GBM article. The details of the problem can be found on the competition page. You can download the data set from here. I have performed the following steps:
- City variable dropped because of too many categories
- DOB converted to Age | DOB dropped
- EMI_Loan_Submitted_Missing created which is 1 if EMI_Loan_Submitted was missing else 0 | Original variable EMI_Loan_Submitted dropped
- EmployerName dropped because of too many categories
- Existing_EMI imputed with 0 (median) since only 111 values were missing
- Interest_Rate_Missing created which is 1 if Interest_Rate was missing else 0 | Original variable Interest_Rate dropped
- Lead_Creation_Date dropped because made little intuitive impact on outcome
- Loan_Amount_Applied, Loan_Tenure_Applied imputed with median values
- Loan_Amount_Submitted_Missing created which is 1 if Loan_Amount_Submitted was missing else 0 | Original variable Loan_Amount_Submitted dropped
- Loan_Tenure_Submitted_Missing created which is 1 if Loan_Tenure_Submitted was missing else 0 | Original variable Loan_Tenure_Submitted dropped
- LoggedIn, Salary_Account dropped
- Processing_Fee_Missing created which is 1 if Processing_Fee was missing else 0 | Original variable Processing_Fee dropped
- Source – top 2 kept as is and all others combined into different category
- Numerical and One-Hot-Coding performed
For those who have the original data from competition, you can check out these steps from the data_preparation iPython notebook in the repository.
Lets start by importing the required libraries and loading the data:
#Import libraries:
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from sklearn import cross_validation, metrics #Additional scklearn functions
from sklearn.grid_search import GridSearchCV #Perforing grid search
import matplotlib.pylab as plt
%matplotlib inline
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4
train = pd.read_csv('train_modified.csv')
target = 'Disbursed'
IDcol = 'ID'
Note that I have imported 2 forms of XGBoost:
- xgb – this is the direct xgboost library. I will use a specific function “cv” from this library
- XGBClassifier – this is an sklearn wrapper for XGBoost. This allows us to use sklearn’s Grid Search with parallel processing in the same way we did for GBM
Before proceeding further, lets define a function which will help us create XGBoost models and perform cross-validation. The best part is that you can take this function as it is and use it later for your own models.
def modelfit(alg, dtrain, predictors,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
if useTrainCV:
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,
metrics='auc', early_stopping_rounds=early_stopping_rounds, show_progress=False)
alg.set_params(n_estimators=cvresult.shape[0])
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain['Disbursed'],eval_metric='auc')
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
#Print model report:
print "\nModel Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['Disbursed'].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['Disbursed'], dtrain_predprob)
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
This code is slightly different from what I used for GBM. The focus of this article is to cover the concepts and not coding. Please feel free to drop a note in the comments if you find any challenges in understanding any part of it. Note that xgboost’s sklearn wrapper doesn’t have a “feature_importances” metric but a get_fscore() function which does the same job.
General Approach for Parameter Tuning
We will use an approach similar to that of GBM here. The various steps to be performed are:
- Choose a relatively high learning rate. Generally a learning rate of 0.1 works but somewhere between 0.05 to 0.3 should work for different problems. Determine the optimum number of trees for this learning rate. XGBoost has a very useful function called as “cv” which performs cross-validation at each boosting iteration and thus returns the optimum number of trees required.
- Tune tree-specific parameters ( max_depth, min_child_weight, gamma, subsample, colsample_bytree) for decided learning rate and number of trees. Note that we can choose different parameters to define a tree and I’ll take up an example here.
- Tune regularization parameters (lambda, alpha) for xgboost which can help reduce model complexity and enhance performance.
- Lower the learning rate and decide the optimal parameters .
Let us look at a more detailed step by step approach.
Step 1: Fix learning rate and number of estimators for tuning tree-based parameters
In order to decide on boosting parameters, we need to set some initial values of other parameters. Lets take the following values:
- max_depth = 5 : This should be between 3-10. I’ve started with 5 but you can choose a different number as well. 4-6 can be good starting points.
- min_child_weight = 1 : A smaller value is chosen because it is a highly imbalanced class problem and leaf nodes can have smaller size groups.
- gamma = 0 : A smaller value like 0.1-0.2 can also be chosen for starting. This will anyways be tuned later.
- subsample, colsample_bytree = 0.8 : This is a commonly used used start value. Typical values range between 0.5-0.9.
- scale_pos_weight = 1: Because of high class imbalance.
Please note that all the above are just initial estimates and will be tuned later. Lets take the default learning rate of 0.1 here and check the optimum number of trees using cv function of xgboost. The function defined above will do it for us.
#Choose all predictors except target & IDcols
predictors = [x for x in train.columns if x not in [target, IDcol]]
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb1, train, predictors)
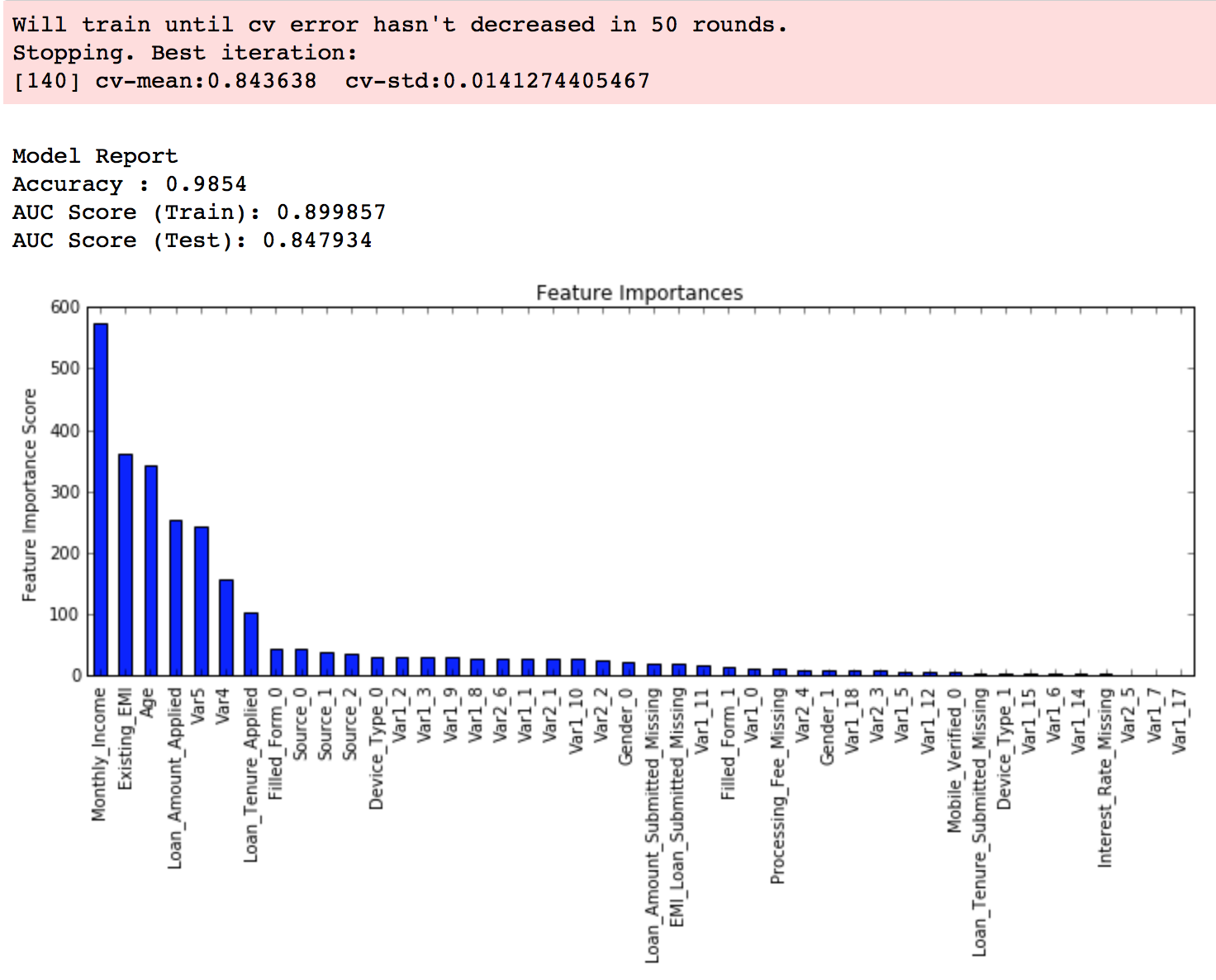
As you can see that here we got 140 as the optimal estimators for 0.1 learning rate. Note that this value might be too high for you depending on the power of your system. In that case you can increase the learning rate and re-run the command to get the reduced number of estimators.
Note: You will see the test AUC as “AUC Score (Test)” in the outputs here. But this would not appear if you try to run the command on your system as the data is not made public. It’s provided here just for reference. The part of the code which generates this output has been removed here.
Step 2: Tune max_depth and min_child_weight
We tune these first as they will have the highest impact on model outcome. To start with, let’s set wider ranges and then we will perform another iteration for smaller ranges.
Important Note: I’ll be doing some heavy-duty grid searched in this section which can take 15-30 mins or even more time to run depending on your system. You can vary the number of values you are testing based on what your system can handle.
param_test1 = {
'max_depth':range(3,10,2),
'min_child_weight':range(1,6,2)
}
gsearch1 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=140, max_depth=5,
min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1, seed=27),
param_grid = param_test1, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch1.fit(train[predictors],train[target])
gsearch1.grid_scores_, gsearch1.best_params_, gsearch1.best_score_

Here, we have run 12 combinations with wider intervals between values. The ideal values are 5 for max_depth and 5 for min_child_weight. Lets go one step deeper and look for optimum values. We’ll search for values 1 above and below the optimum values because we took an interval of two.
param_test2 = {
'max_depth':[4,5,6],
'min_child_weight':[4,5,6]
}
gsearch2 = GridSearchCV(estimator = XGBClassifier( learning_rate=0.1, n_estimators=140, max_depth=5,
min_child_weight=2, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test2, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch2.fit(train[predictors],train[target])
gsearch2.grid_scores_, gsearch2.best_params_, gsearch2.best_score_

Here, we get the optimum values as 4 for max_depth and 6 for min_child_weight. Also, we can see the CV score increasing slightly. Note that as the model performance increases, it becomes exponentially difficult to achieve even marginal gains in performance. You would have noticed that here we got 6 as optimum value for min_child_weight but we haven’t tried values more than 6. We can do that as follow:.
param_test2b = {
'min_child_weight':[6,8,10,12]
}
gsearch2b = GridSearchCV(estimator = XGBClassifier( learning_rate=0.1, n_estimators=140, max_depth=4,
min_child_weight=2, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test2b, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch2b.fit(train[predictors],train[target])
modelfit(gsearch3.best_estimator_, train, predictors)
gsearch2b.grid_scores_, gsearch2b.best_params_, gsearch2b.best_score_

We see 6 as the optimal value.
Step 3: Tune gamma
Now lets tune gamma value using the parameters already tuned above. Gamma can take various values but I’ll check for 5 values here. You can go into more precise values as.
param_test3 = {
'gamma':[i/10.0 for i in range(0,5)]
}
gsearch3 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=140, max_depth=4,
min_child_weight=6, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test3, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch3.fit(train[predictors],train[target])
gsearch3.grid_scores_, gsearch3.best_params_, gsearch3.best_score_

This shows that our original value of gamma, i.e. 0 is the optimum one. Before proceeding, a good idea would be to re-calibrate the number of boosting rounds for the updated parameters.
xgb2 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=4,
min_child_weight=6,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb2, train, predictors)
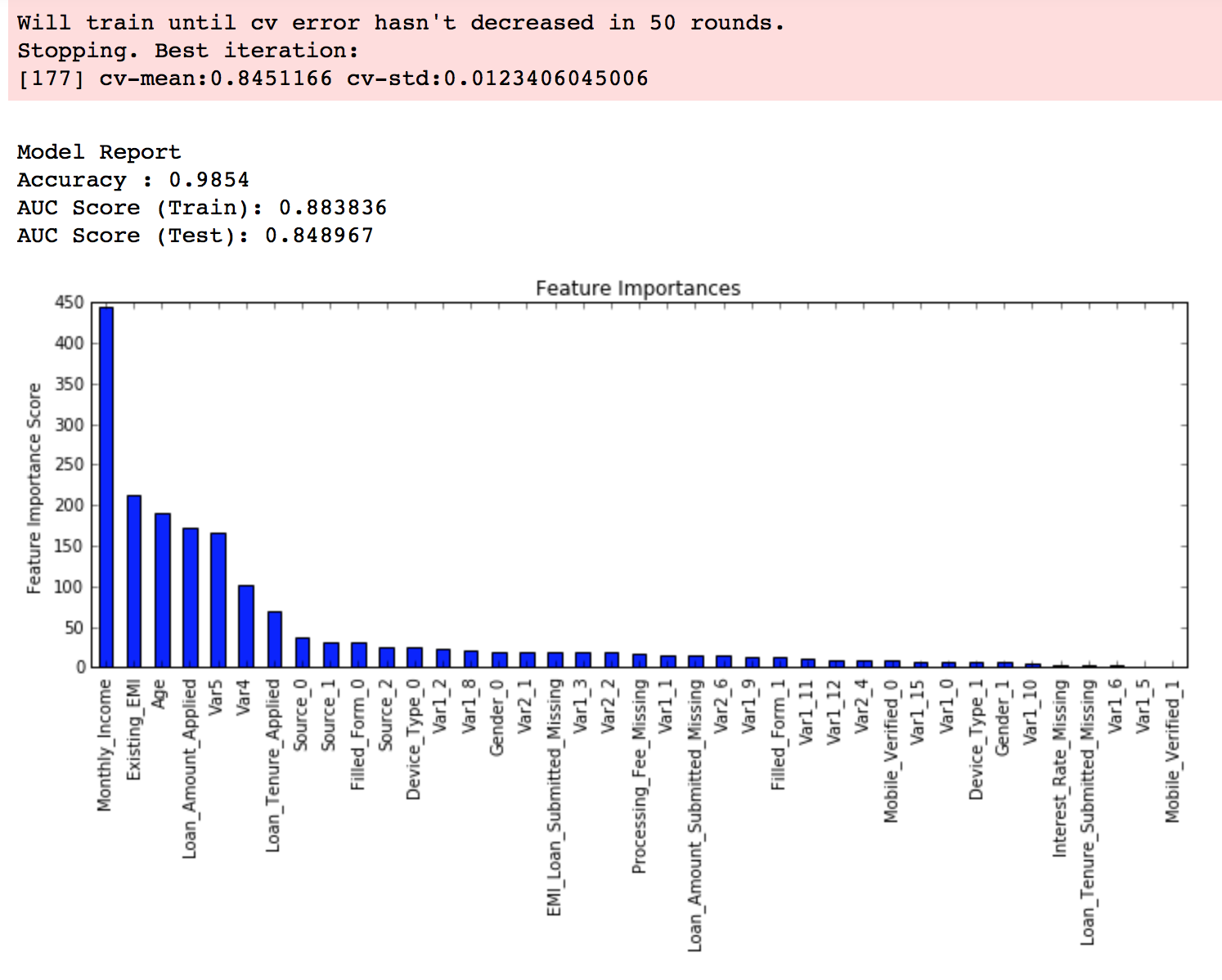 Here, we can see the improvement in score. So the final parameters are:
Here, we can see the improvement in score. So the final parameters are:
- max_depth: 4
- min_child_weight: 6
- gamma: 0
Step 4: Tune subsample and colsample_bytree
The next step would be try different subsample and colsample_bytree values. Lets do this in 2 stages as well and take values 0.6,0.7,0.8,0.9 for both to start with.
param_test4 = {
'subsample':[i/10.0 for i in range(6,10)],
'colsample_bytree':[i/10.0 for i in range(6,10)]
}
gsearch4 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=4,
min_child_weight=6, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test4, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch4.fit(train[predictors],train[target])
gsearch4.grid_scores_, gsearch4.best_params_, gsearch4.best_score_
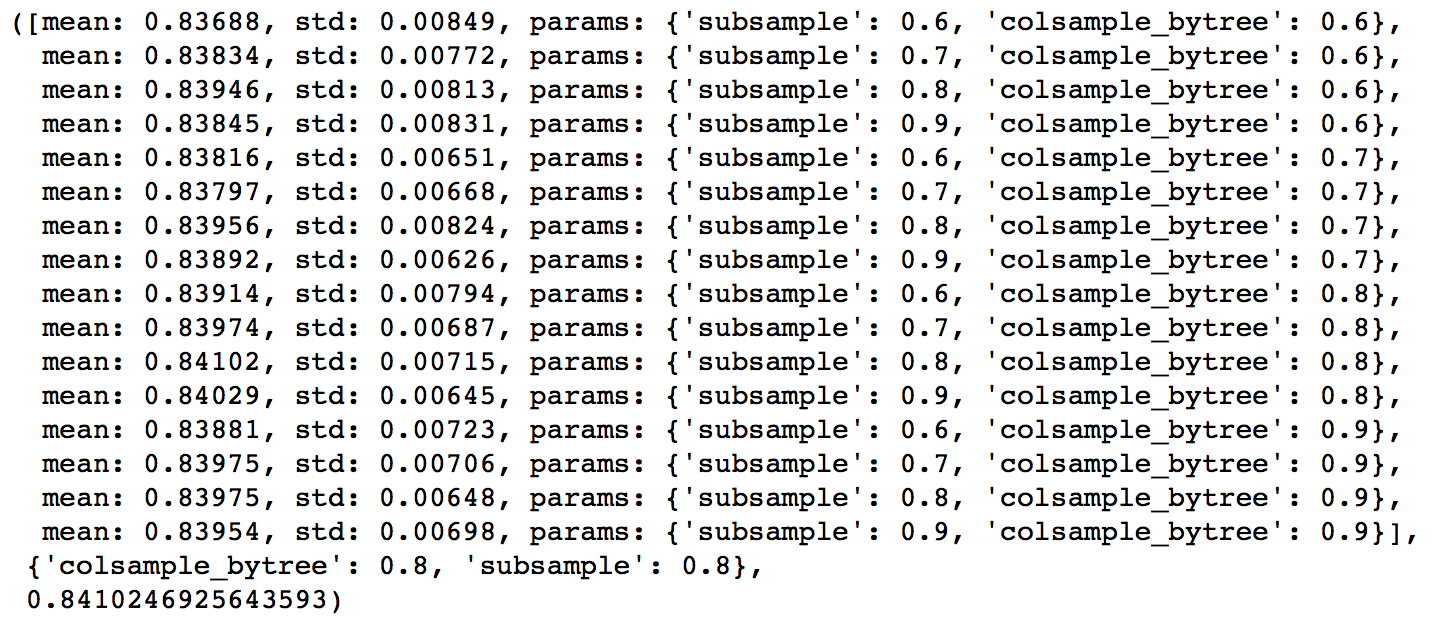
Here, we found 0.8 as the optimum value for both subsample and colsample_bytree. Now we should try values in 0.05 interval around these.
param_test5 = {
'subsample':[i/100.0 for i in range(75,90,5)],
'colsample_bytree':[i/100.0 for i in range(75,90,5)]
}
gsearch5 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=4,
min_child_weight=6, gamma=0, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test5, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch5.fit(train[predictors],train[target])

Again we got the same values as before. Thus the optimum values are:
- subsample: 0.8
- colsample_bytree: 0.8
Step 5: Tuning Regularization Parameters
Next step is to apply regularization to reduce overfitting. Though many people don’t use this parameters much as gamma provides a substantial way of controlling complexity. But we should always try it. I’ll tune ‘reg_alpha’ value here and leave it upto you to try different values of ‘reg_lambda’.
param_test6 = {
'reg_alpha':[1e-5, 1e-2, 0.1, 1, 100]
}
gsearch6 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=4,
min_child_weight=6, gamma=0.1, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test6, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch6.fit(train[predictors],train[target])
gsearch6.grid_scores_, gsearch6.best_params_, gsearch6.best_score_

We can see that the CV score is less than the previous case. But the values tried are very widespread, we should try values closer to the optimum here (0.01) to see if we get something better.
param_test7 = {
'reg_alpha':[0, 0.001, 0.005, 0.01, 0.05]
}
gsearch7 = GridSearchCV(estimator = XGBClassifier( learning_rate =0.1, n_estimators=177, max_depth=4,
min_child_weight=6, gamma=0.1, subsample=0.8, colsample_bytree=0.8,
objective= 'binary:logistic', nthread=4, scale_pos_weight=1,seed=27),
param_grid = param_test7, scoring='roc_auc',n_jobs=4,iid=False, cv=5)
gsearch7.fit(train[predictors],train[target])
gsearch7.grid_scores_, gsearch7.best_params_, gsearch7.best_score_

You can see that we got a better CV. Now we can apply this regularization in the model and look at the impact:
xgb3 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=4,
min_child_weight=6,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.005,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb3, train, predictors)
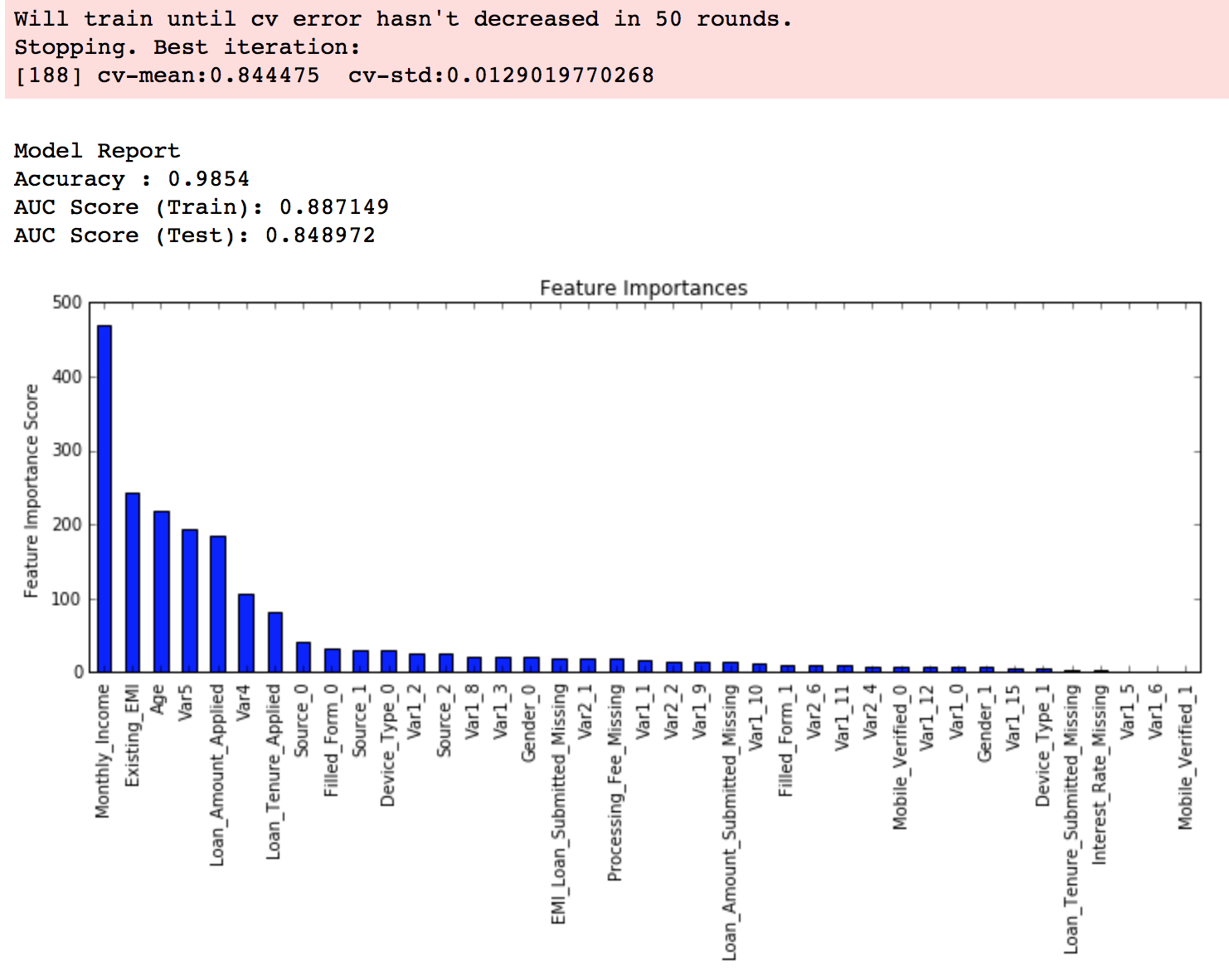
Again we can see slight improvement in the score.
Step 6: Reducing Learning Rate
Lastly, we should lower the learning rate and add more trees. Lets use the cv function of XGBoost to do the job again.
xgb4 = XGBClassifier(
learning_rate =0.01,
n_estimators=5000,
max_depth=4,
min_child_weight=6,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.005,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
modelfit(xgb4, train, predictors)
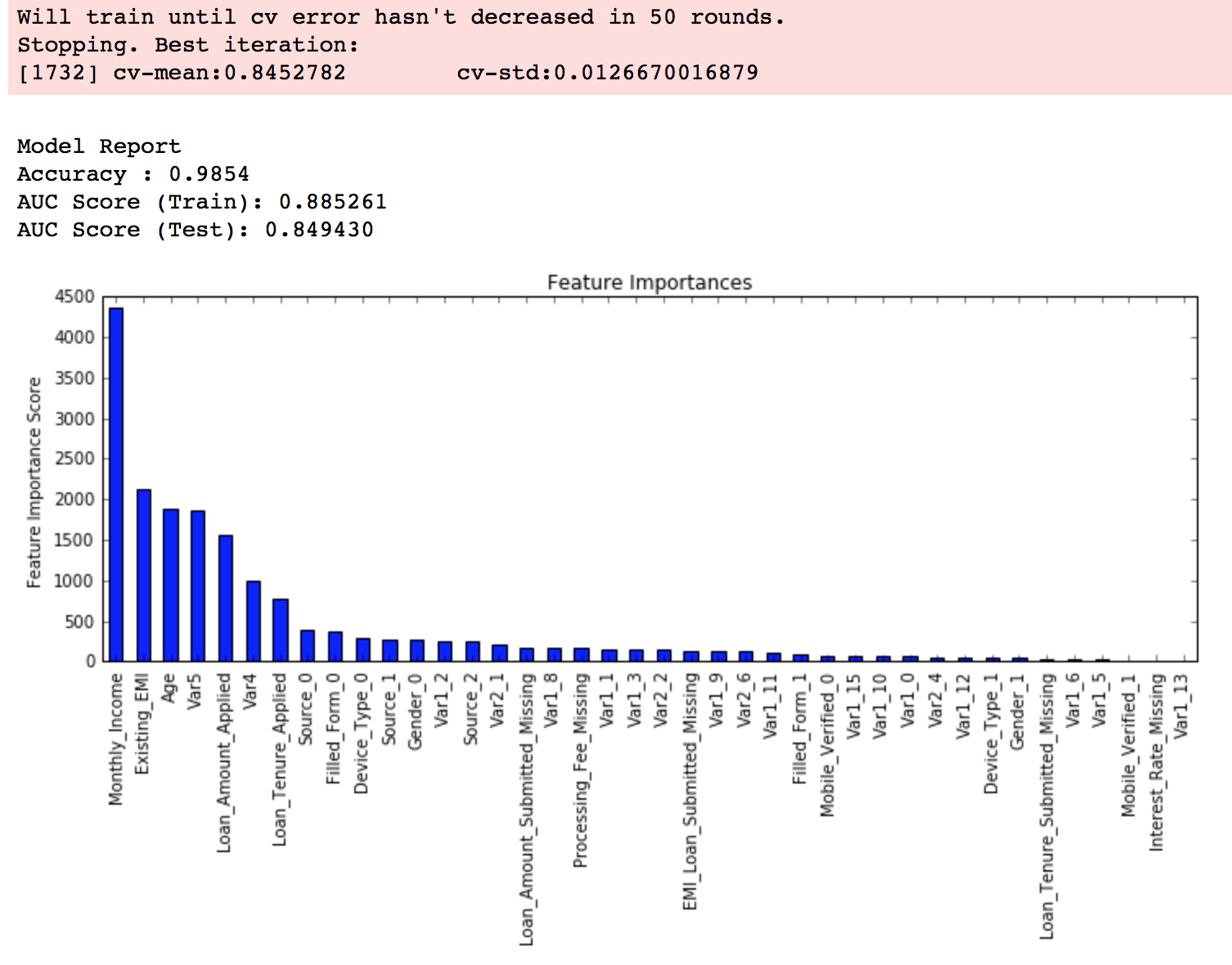
Now we can see a significant boost in performance and the effect of parameter tuning is clearer.
As we come to the end, I would like to share 2 key thoughts:
- It is difficult to get a very big leap in performance by just using parameter tuning or slightly better models. The max score for GBM was 0.8487 while XGBoost gave 0.8494. This is a decent improvement but not something very substantial.
- A significant jump can be obtained by other methods like feature engineering, creating ensemble of models, stacking, etc
You can also download the iPython notebook with all these model codes from my GitHub account. For codes in R, you can refer to this article.
End Notes
This article was based on developing a XGBoost model end-to-end. We started with discussing why XGBoost has superior performance over GBM which was followed by detailed discussion on thevarious parameters involved. We also defined a generic function which you can re-use for making models.
Finally, we discussed the general approach towards tackling a problem with XGBoost and also worked out the AV Data Hackathon 3.x problem through that approach.
I hope you found this useful and now you feel more confident to apply XGBoost in solving a data science problem. You can try this out in out upcoming hackathons.
Did you like this article? Would you like to share some other hacks which you implement while making XGBoost models? Please feel free to drop a note in the comments below and I’ll be glad to discuss.
You want to apply your analytical skills and test your potential? Then participate in our Hackathons and compete with Top Data Scientists from all over the world.


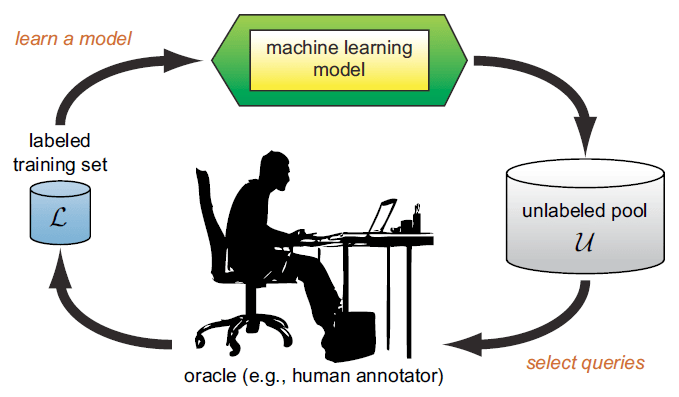
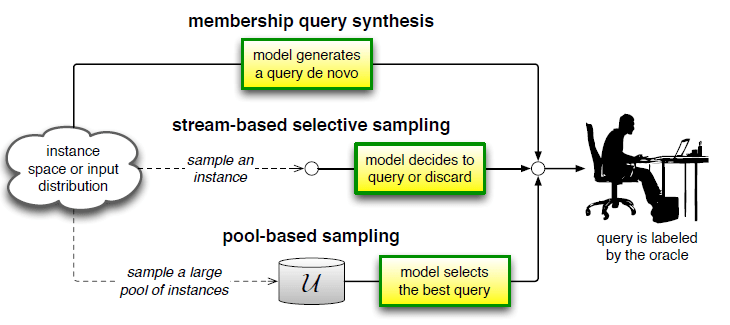
 ,
, ,这里的
,这里的 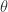 表示一个已经训练好的机器学习模型参数集合。
表示一个已经训练好的机器学习模型参数集合。 对于
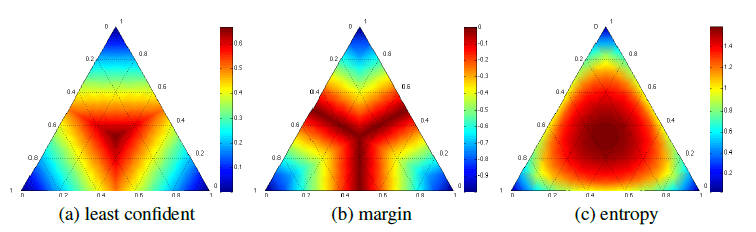
对于  而言是模型预测概率最大的类别。Least Confident 方法考虑那些模型预测概率最大但是可信度较低的样本数据。
而言是模型预测概率最大的类别。Least Confident 方法考虑那些模型预测概率最大但是可信度较低的样本数据。 ,
,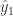 和
和 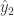 分别表示对于
分别表示对于 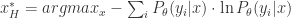 ,
,
 个模型,其参数分别是
个模型,其参数分别是  ,并且这些模型都是通过数据集
,并且这些模型都是通过数据集  的训练得到的。
的训练得到的。 ,
,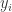 表示第
表示第  类,求和符号表示将所有的类别
类,求和符号表示将所有的类别 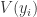 表示投票给
表示投票给 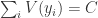 。
。
 也是概率分布,
也是概率分布, 表示两个概率的 KL 散度。
表示两个概率的 KL 散度。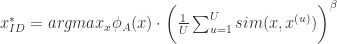 ,
, 表示某个不确定性采样方法或者 QBC 方法,
表示某个不确定性采样方法或者 QBC 方法,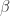 表示指数参数,
表示指数参数, 表示第
表示第  类的代表元,
类的代表元,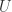 表示类别的个数。加上权重表示会选择那些与代表元相似度较高的元素作为标注候选集。
表示类别的个数。加上权重表示会选择那些与代表元相似度较高的元素作为标注候选集。


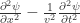
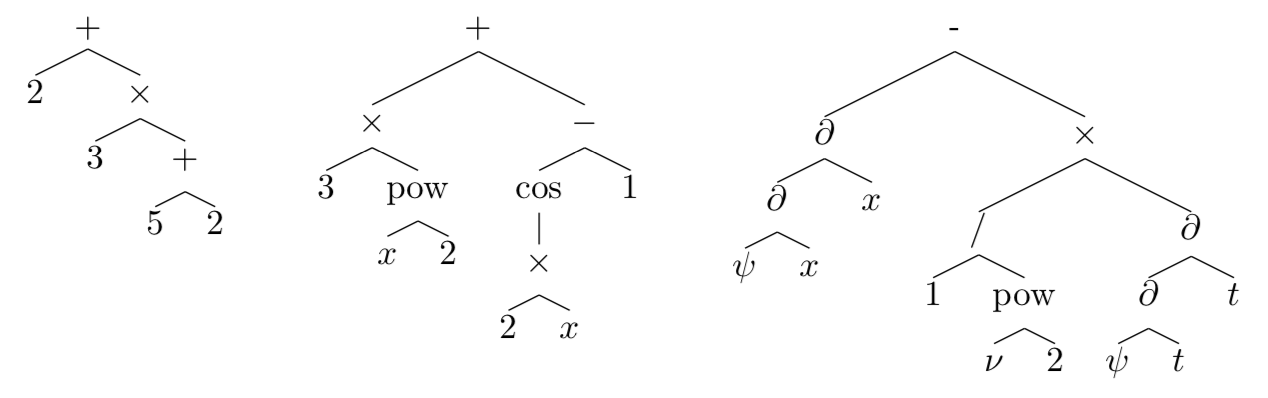
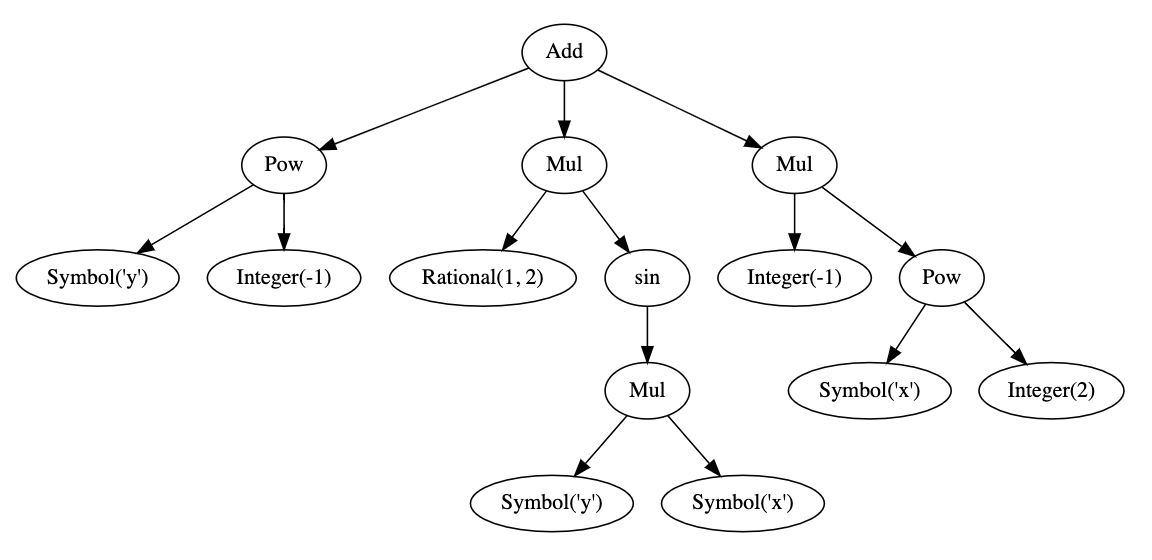
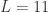 表示叶子节点的值只有 11 个,分别是变量
表示叶子节点的值只有 11 个,分别是变量  ;
; 表示一元计算只有 15 个,分别是
表示一元计算只有 15 个,分别是  ,
, 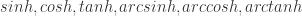 。
。 表示二元计算只有四个,分别是 +, -, *, /;
表示二元计算只有四个,分别是 +, -, *, /; 的表达式就可以作为深度学习的积分训练数据。生成积分的话其实有多种方法:
的表达式就可以作为深度学习的积分训练数据。生成积分的话其实有多种方法: ,然后使用 SymPy 或者 Mathematica 等工具来计算函数
,然后使用 SymPy 或者 Mathematica 等工具来计算函数  ,那么
,那么  就可以作为一个训练集。当然,有的时候函数
就可以作为一个训练集。当然,有的时候函数  ,于是
,于是  ,那么
,那么 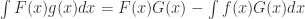 。对于两个随机生成的函数
。对于两个随机生成的函数 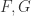 ,可以计算出它们的导数
,可以计算出它们的导数 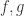 。如果
。如果 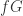 在训练集合里面,那么就把
在训练集合里面,那么就把  的积分计算出来放入训练集合;反之,如果
的积分计算出来放入训练集合;反之,如果 
 选择一个,于是随机把其中的一个整数换成变量
选择一个,于是随机把其中的一个整数换成变量  。例如:在
。例如:在  中就把 2 换成 c,于是得到了一个二元函数
中就把 2 换成 c,于是得到了一个二元函数  。那么就执行以下步骤:
。那么就执行以下步骤: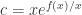 ;
;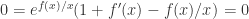 ;
;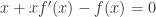 ,也就是
,也就是 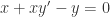 。
。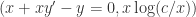 。
。 ;
; 得到
得到  ;
; ;
; 得到
得到  ;
; ;
; ,也就是
,也就是 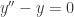 。
。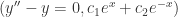 。
。 的表达式,该数据就需要放弃,重新生成新的数据。
的表达式,该数据就需要放弃,重新生成新的数据。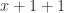 可以简化成
可以简化成 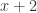 ,
, 可以简化成 1。
可以简化成 1。 可以简化成
可以简化成 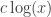 。
。 等。
等。




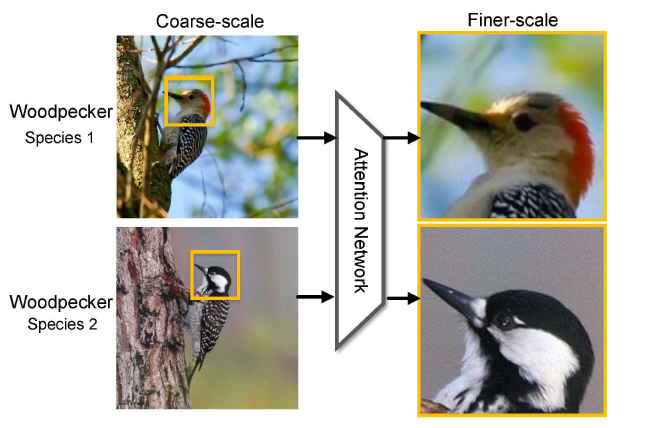


 , 需要提取它的特征,可以记录为
, 需要提取它的特征,可以记录为 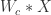 ,这里的
,这里的  指的是卷积等各种各样的操作。所以得到的概率分布情况其实就是
指的是卷积等各种各样的操作。所以得到的概率分布情况其实就是  ,
, 和尺寸大小
和尺寸大小  ,其中
,其中 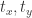 分别指的是横纵坐标,正方形的边长其实是
分别指的是横纵坐标,正方形的边长其实是  。用数学公式来记录这个流程就是
。用数学公式来记录这个流程就是 ![[t_{x}, t_{y}, t_{\ell}] = g(W_{c}*X)](https://s0.wp.com/latex.php?latex=%5Bt_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%5D+%3D+g%28W_%7Bc%7D%2AX%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。在坐标值的基础上,我们可以得到以下四个值,分别表示
。在坐标值的基础上,我们可以得到以下四个值,分别表示 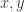 两个坐标轴的上下界:
两个坐标轴的上下界:

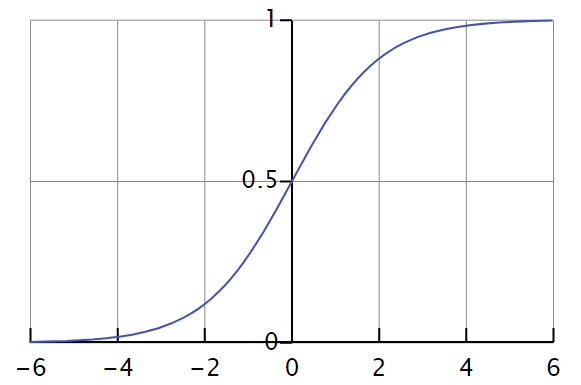
 而言,当
而言,当  足够大的时候,
足够大的时候,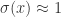 当
当 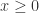 ;
; 当
当 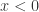 。此时的逻辑回归函数近似于一个阶梯函数。如果假设
。此时的逻辑回归函数近似于一个阶梯函数。如果假设  ,那么
,那么 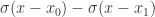 就是光滑一点的阶梯函数,
就是光滑一点的阶梯函数, 当
当  ;
; 当
当  。
。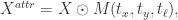 其中,
其中, 表示图片需要关注的区域,
表示图片需要关注的区域, 函数就是
函数就是 ![M(t_{x}, t_{y}, t_{\ell}) = [\sigma(x-t_{x(t\ell)}) - \sigma(x-t_{x(br)})]\cdot[\sigma(y-t_{y(t\ell)}) - \sigma(y-t_{y(br)})],](https://s0.wp.com/latex.php?latex=M%28t_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%29+%3D+%5B%5Csigma%28x-t_%7Bx%28t%5Cell%29%7D%29+-+%5Csigma%28x-t_%7Bx%28br%29%7D%29%5D%5Ccdot%5B%5Csigma%28y-t_%7By%28t%5Cell%29%7D%29+-+%5Csigma%28y-t_%7By%28br%29%7D%29%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这里的
这里的 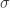 函数对应了一个足够大的
函数对应了一个足够大的 
![m = [i/\lambda] + \alpha, n = [j/\lambda] + \beta](https://s0.wp.com/latex.php?latex=m+%3D+%5Bi%2F%5Clambda%5D+%2B+%5Calpha%2C+n+%3D+%5Bj%2F%5Clambda%5D+%2B+%5Cbeta&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,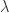 表示上采样因子,
表示上采样因子,![[\cdot], \{\cdot\}](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D%2C+%5C%7B%5Ccdot%5C%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 分别表示一个实数的正数部分和小数部分。
分别表示一个实数的正数部分和小数部分。 表示预测类别的概率,
表示预测类别的概率,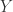 表示真实的类别。除此之外,另外一个部分就是排序的部分,
表示真实的类别。除此之外,另外一个部分就是排序的部分, 其中
其中  表示在第
表示在第  个尺寸下所得到的类别
个尺寸下所得到的类别 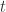 的预测概率,并且最大值函数强制了该深度学习模型在训练中可以保证
的预测概率,并且最大值函数强制了该深度学习模型在训练中可以保证  ,也就是说,局部预测的概率值应该高于整体的概率值。
,也就是说,局部预测的概率值应该高于整体的概率值。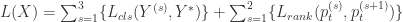 .
.
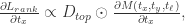
 表示元素的点乘,
表示元素的点乘,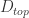 表示之前的网络所得到的导数。
表示之前的网络所得到的导数。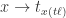 ,
,
 ,
,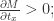

 ,
,
 ,
,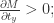
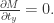

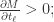

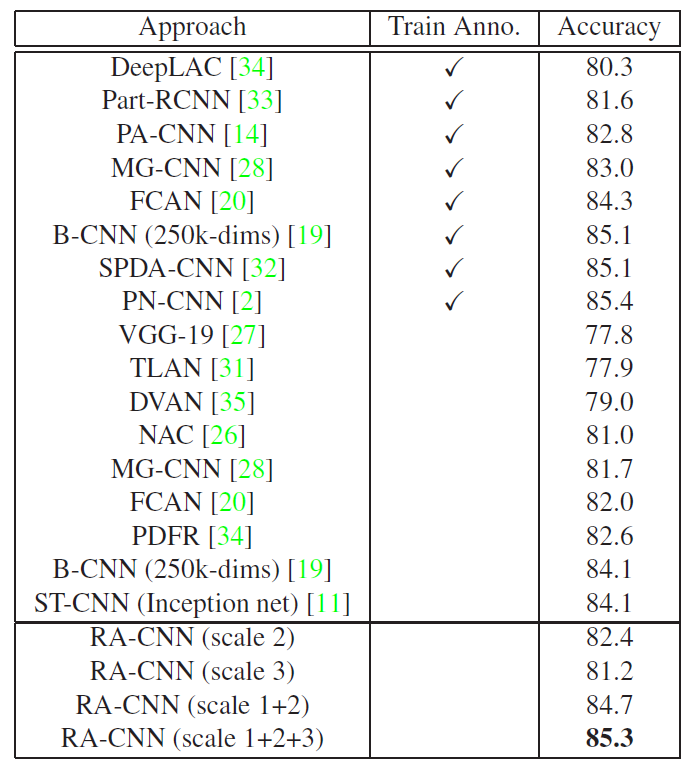

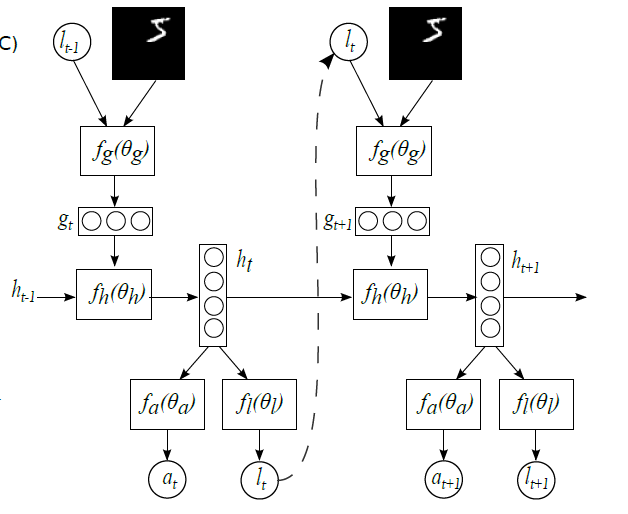
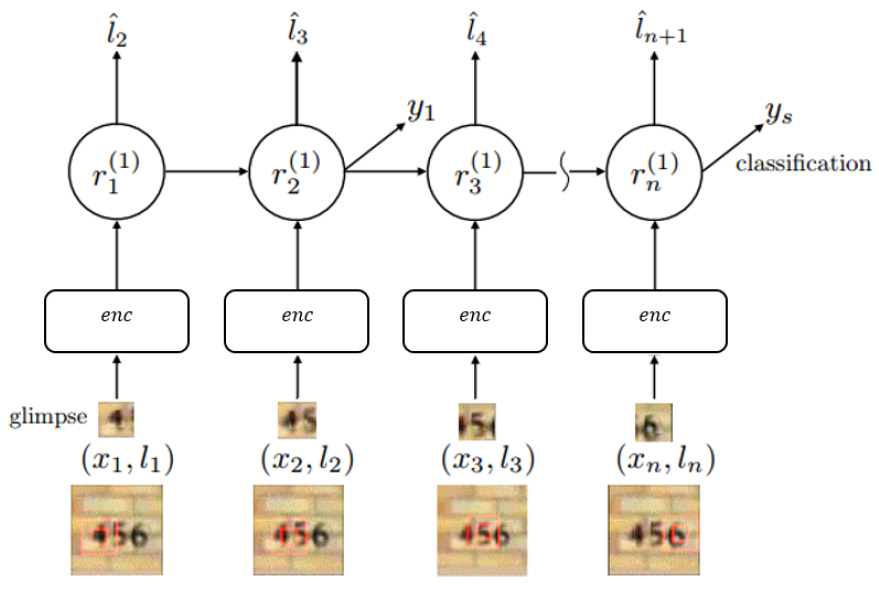
 表示解码的过程,
表示解码的过程, 表示图片的一个子区域。而
表示图片的一个子区域。而  表示对图片的预测概率或者预测标签。
表示对图片的预测概率或者预测标签。 是解码网络,
是解码网络, 是注意力网络,输出概率在解码网络的最后一个单元输出。
是注意力网络,输出概率在解码网络的最后一个单元输出。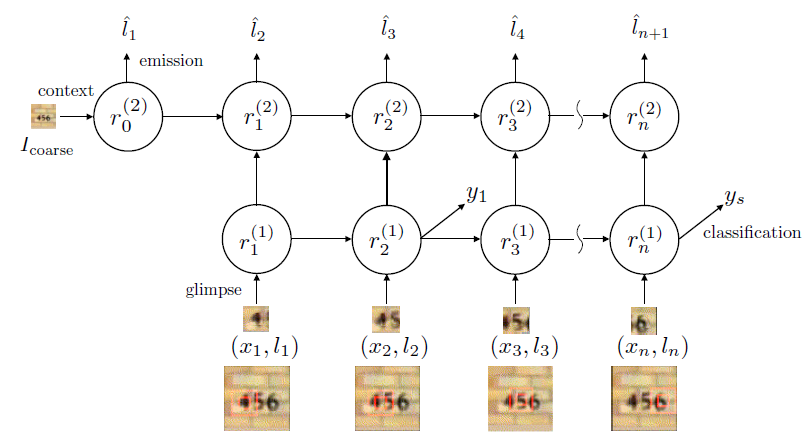
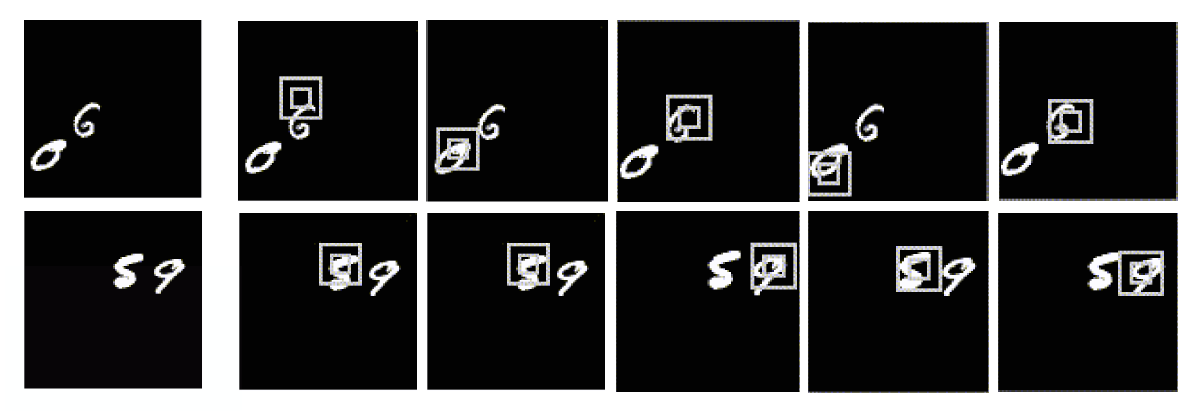

 其中的
其中的  ,
, 是一个正整数。然后,目标函数
是一个正整数。然后,目标函数 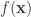 不一定需要是显式的(所谓显式指的是能够精确写出
不一定需要是显式的(所谓显式指的是能够精确写出 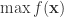 或者最小值
或者最小值 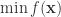 。
。 并且每一个
并且每一个  的值域都在
的值域都在 ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 内。如果目标函数是
内。如果目标函数是

 的定义域内都相差得不多,也就是这
的定义域内都相差得不多,也就是这  条曲线几乎重合。
条曲线几乎重合。 或者
或者 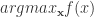 。
。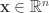 一般都是连续的特征,而不是那种类别特征。如果是类别的特征,并不是所有的启发式优化算法都适用,但是遗传算法之类的算法在这种情况下有着一定的用武之地。
一般都是连续的特征,而不是那种类别特征。如果是类别的特征,并不是所有的启发式优化算法都适用,但是遗传算法之类的算法在这种情况下有着一定的用武之地。
![\bold{x}\in[-5.12,5.12]^{n}.](https://s0.wp.com/latex.php?latex=%5Cbold%7Bx%7D%5Cin%5B-5.12%2C5.12%5D%5E%7Bn%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 或者 Easom 函数(Chapter 2,Example 2.1,Search and Optimization by Metaheuristics)
或者 Easom 函数(Chapter 2,Example 2.1,Search and Optimization by Metaheuristics)
![\bold{x} \in [-100,100]^{2}.](https://s0.wp.com/latex.php?latex=%5Cbold%7Bx%7D+%5Cin+%5B-100%2C100%5D%5E%7B2%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 份,其中
份,其中  计算每一个交点的函数取值,然后统计出其最大值或者最小值就可以了。实际中不适用,因为当
计算每一个交点的函数取值,然后统计出其最大值或者最小值就可以了。实际中不适用,因为当  的时候,这个是指数级别的计算复杂度。
的时候,这个是指数级别的计算复杂度。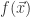 的时间。
的时间。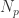 ,每一个粒子
,每一个粒子  都是
都是 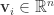 。在每一轮迭代中,需要更新两个最值,分别是每一个粒子在历史上的最优值和所有粒子在历史上的最优值,分别记为
。在每一轮迭代中,需要更新两个最值,分别是每一个粒子在历史上的最优值和所有粒子在历史上的最优值,分别记为  (
(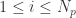 )和
)和 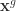 。在第
。在第 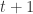 次迭代的时候,
次迭代的时候,![\bold{v}_{i}(t+1) = \bold{v}_{i}(t) + c r_{1}[\bold{x}_{i}^{*}(t) - \bold{x}_{i}(t)] + c r_{2}[\bold{x}^{g}(t) - \bold{x}_{i}(t)],](https://s0.wp.com/latex.php?latex=%5Cbold%7Bv%7D_%7Bi%7D%28t%2B1%29+%3D+%5Cbold%7Bv%7D_%7Bi%7D%28t%29+%2B+c+r_%7B1%7D%5B%5Cbold%7Bx%7D_%7Bi%7D%5E%7B%2A%7D%28t%29+-+%5Cbold%7Bx%7D_%7Bi%7D%28t%29%5D+%2B+c+r_%7B2%7D%5B%5Cbold%7Bx%7D%5E%7Bg%7D%28t%29+-+%5Cbold%7Bx%7D_%7Bi%7D%28t%29%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
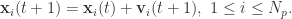
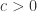 ,并且
,并且  是
是  这个维度,当温度
这个维度,当温度  。假设目标函数是
。假设目标函数是  ,需要寻找
,需要寻找  ,然后执行以下的程序:
,然后执行以下的程序: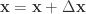 ;
; ,
,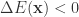 ,也就是
,也就是  ,选择
,选择  ;
;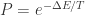 的概率来接受
的概率来接受  。
。 。
。 ,可以选择 Gaussian 正态分布,并且可以同时修改
,可以选择 Gaussian 正态分布,并且可以同时修改 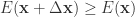 的时候,都会以极大概率接受
的时候,都会以极大概率接受  ,因为此时
,因为此时 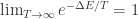 。然后一开始都在四处游荡;
。然后一开始都在四处游荡; 和
和  ,那么子代(children)的交叉可以定义为:
,那么子代(children)的交叉可以定义为:
 ,使用 Gaussian 正态分布可以构造出一个后代如下:
,使用 Gaussian 正态分布可以构造出一个后代如下:
 是基于具体问题的,很难给出一个通用的值。
是基于具体问题的,很难给出一个通用的值。 和
和  两种策略。这里的
两种策略。这里的 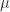 表示人口数量(population size),
表示人口数量(population size),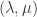 策略中,
策略中, 中选择出来的。
中选择出来的。 的导数,也就是说目标函数必须可导。但是在 Evolutionary Gradient Search 中,不需要
的导数,也就是说目标函数必须可导。但是在 Evolutionary Gradient Search 中,不需要  的方案,它整体来说其实只有一个人口。从当前的点
的方案,它整体来说其实只有一个人口。从当前的点  。计算它们的函数取值
。计算它们的函数取值 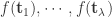 。那么估算的梯度就可以计算出来:
。那么估算的梯度就可以计算出来: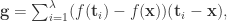


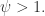 新的个体定义为:
新的个体定义为:  如果
如果  那么
那么 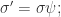 如果
如果  那么
那么 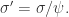
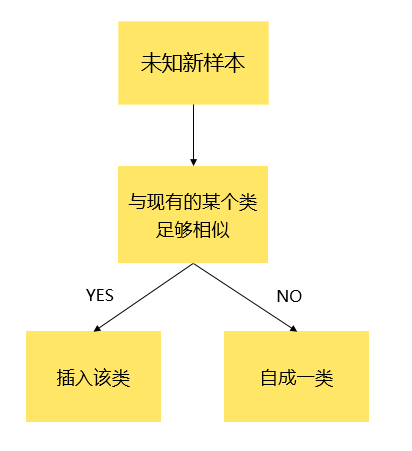
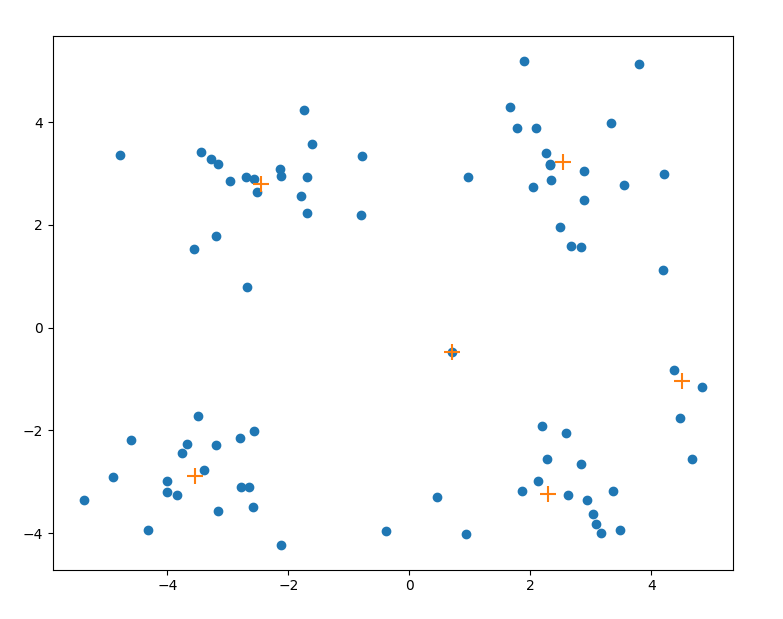
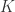 表示在聚类的过程中允许形成的簇的最大个数;
表示在聚类的过程中允许形成的簇的最大个数;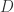 表示距离的阀值,在这里两个点之间的距离可以使用
表示距离的阀值,在这里两个点之间的距离可以使用  范数;
范数;![A[0],A[1],\cdot\cdot\cdot,A[n-1]](https://s0.wp.com/latex.php?latex=A%5B0%5D%2CA%5B1%5D%2C%5Ccdot%5Ccdot%5Ccdot%2CA%5Bn-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,那么质心就是
,那么质心就是 ![\sum_{i=0}^{n-1}A[i]/n](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D0%7D%5E%7Bn-1%7DA%5Bi%5D%2Fn&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ;
;![num[j]](https://s0.wp.com/latex.php?latex=num%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示。
表示。![dataMat[0]](https://s0.wp.com/latex.php?latex=dataMat%5B0%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 而言,自成一类。i.e. 质心就是它本身
而言,自成一类。i.e. 质心就是它本身 ![C[0]=dataMat[0]](https://s0.wp.com/latex.php?latex=C%5B0%5D%3DdataMat%5B0%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,该聚簇的元素个数就是
,该聚簇的元素个数就是 ![num[0]=1](https://s0.wp.com/latex.php?latex=num%5B0%5D%3D1&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,当前所有簇的个数是
,当前所有簇的个数是 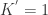 。
。 ,进行如下的循环操作:
,进行如下的循环操作: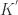 个簇,第 j 个簇的质心是
个簇,第 j 个簇的质心是 ![C[j]](https://s0.wp.com/latex.php?latex=C%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,第 j 个簇的元素个数是
,第 j 个簇的元素个数是 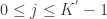 。
。![d= \min_{0\leq j\leq K^{'}-1}Distance(dataMat[i],C[j])](https://s0.wp.com/latex.php?latex=d%3D+%5Cmin_%7B0%5Cleq+j%5Cleq+K%5E%7B%27%7D-1%7DDistance%28dataMat%5Bi%5D%2CC%5Bj%5D%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,其中的 Distance 可以是欧几里德空间的
,其中的 Distance 可以是欧几里德空间的  范数,对应的下标是
范数,对应的下标是  。i.e.
。i.e. ![j'=argmin_{0\leq j\leq K'-1}Distance(dataMat[i],C[j])](https://s0.wp.com/latex.php?latex=j%27%3Dargmin_%7B0%5Cleq+j%5Cleq+K%27-1%7DDistance%28dataMat%5Bi%5D%2CC%5Bj%5D%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。
。 或者
或者  ,则把
,则把 ![dataMat[i]](https://s0.wp.com/latex.php?latex=dataMat%5Bi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 加入到第
加入到第 ![C[j'] \leftarrow (C[j']*num[j]](https://s0.wp.com/latex.php?latex=C%5Bj%27%5D+%5Cleftarrow+%28C%5Bj%27%5D%2Anum%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) +
+ ![dataMat[i])/(num[j]](https://s0.wp.com/latex.php?latex=dataMat%5Bi%5D%29%2F%28num%5Bj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) +
+  ,
,![num[j'] \leftarrow num[j']](https://s0.wp.com/latex.php?latex=num%5Bj%27%5D+%5Cleftarrow+num%5Bj%27%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) +
+ 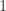 。
。 +
+ ![num[K'-1]=1](https://s0.wp.com/latex.php?latex=num%5BK%27-1%5D%3D1&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,![C[K'-1]=dataMat[i]](https://s0.wp.com/latex.php?latex=C%5BK%27-1%5D%3DdataMat%5Bi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。
。






















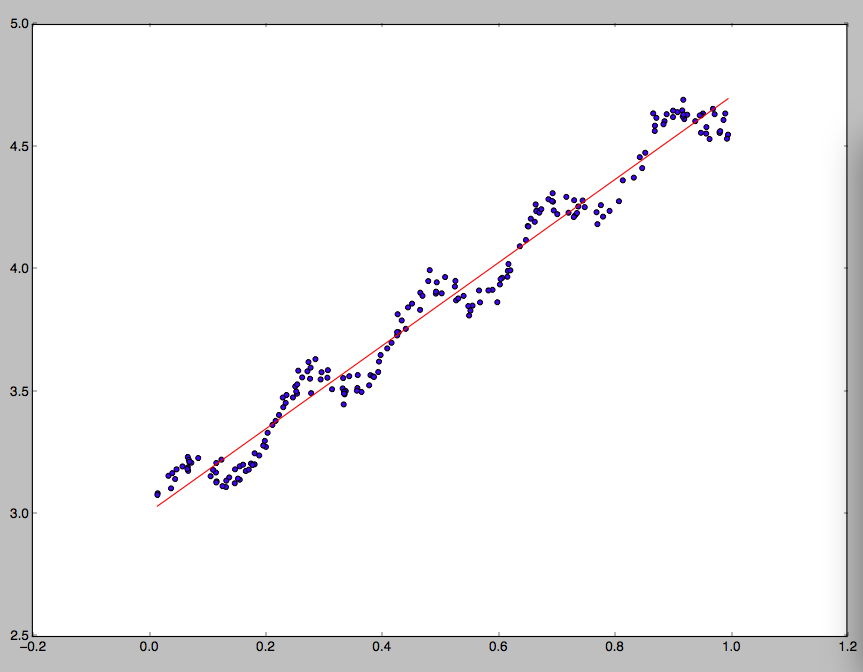
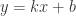 去拟合二次函数
去拟合二次函数  ,结果总是不尽人意。为了解决这类问题,有人提出了局部加权线性回归(locally weighted linear regression),岭回归(ridge regression),LASSO 和 前向逐步线性回归(forward stagewise linear regression)。本文中将会一一介绍这些回归算法。
,结果总是不尽人意。为了解决这类问题,有人提出了局部加权线性回归(locally weighted linear regression),岭回归(ridge regression),LASSO 和 前向逐步线性回归(forward stagewise linear regression)。本文中将会一一介绍这些回归算法。 使得
使得 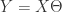 。当然,这样的
。当然,这样的 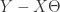 的 Eulidean 范数足够小。换言之,我们需要找到一个向量
的 Eulidean 范数足够小。换言之,我们需要找到一个向量 

 ,求解
,求解  。因此,对于矩阵
。因此,对于矩阵 

 表示以
表示以  为对角线的对角矩阵,其中 m 是矩阵 X 的行数,
为对角线的对角矩阵,其中 m 是矩阵 X 的行数,

 。因此,如果使用局部加权线性回归的话,最佳的系数就是
。因此,如果使用局部加权线性回归的话,最佳的系数就是
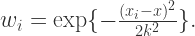
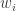 就会较大;如果隔得较远,那么
就会较大;如果隔得较远,那么 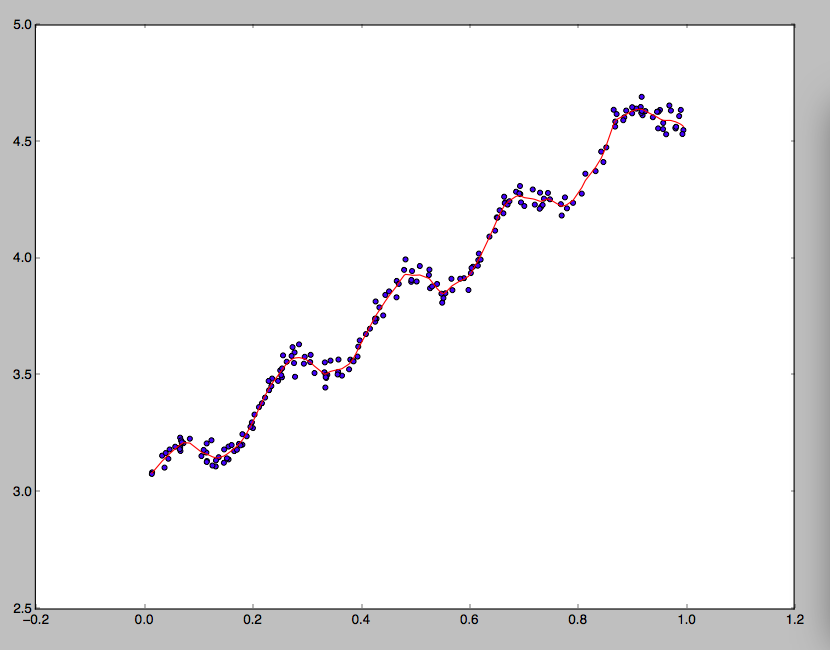
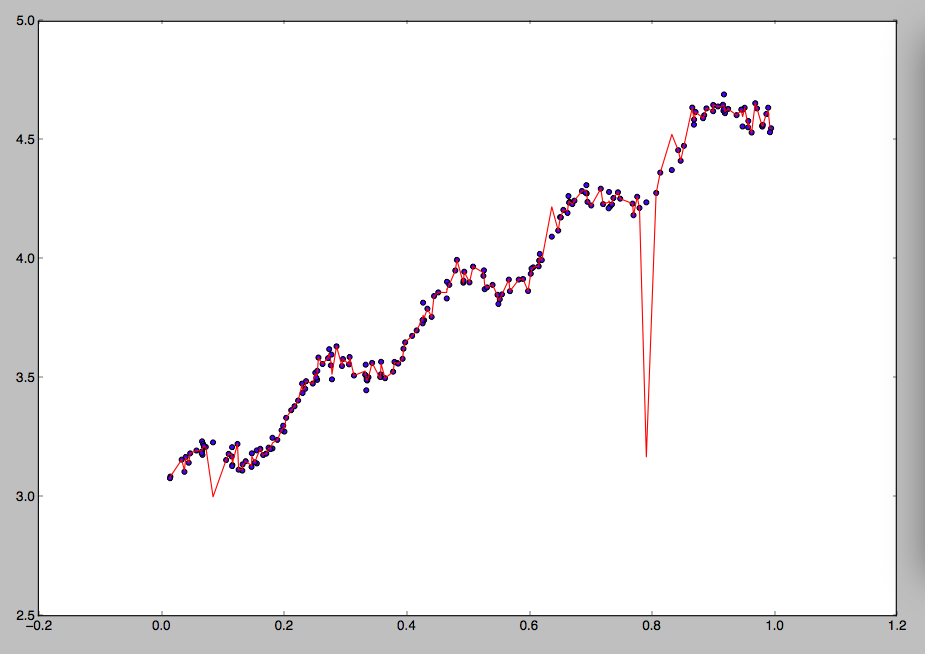
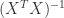 的时候会出现问题。为了解决这个问题,有人引入了岭回归(ridge regression)的概念。也就是说在计算矩阵的逆的时候,增加了一个对角矩阵,目的是使得可以对矩阵进行求逆。用数学语言来描述就是矩阵
的时候会出现问题。为了解决这个问题,有人引入了岭回归(ridge regression)的概念。也就是说在计算矩阵的逆的时候,增加了一个对角矩阵,目的是使得可以对矩阵进行求逆。用数学语言来描述就是矩阵  加上
加上  ,这里的 I 是一个
,这里的 I 是一个  的对角矩阵,使得矩阵
的对角矩阵,使得矩阵  是一个可逆矩阵。在这种情况下,回归系数的计算公式变成了
是一个可逆矩阵。在这种情况下,回归系数的计算公式变成了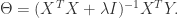
 很容易过拟合。为了缓解过拟合的问题,可以引入正则化项。如果使用
很容易过拟合。为了缓解过拟合的问题,可以引入正则化项。如果使用 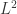 正则化,那么目标函数则是
正则化,那么目标函数则是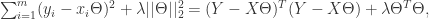
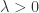 。通过数学推导可以得到:
。通过数学推导可以得到: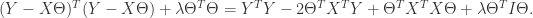

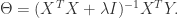 因此,从另一个角度来说,岭回归(Ridge Regression)是在线性规划的基础上添加了一个
因此,从另一个角度来说,岭回归(Ridge Regression)是在线性规划的基础上添加了一个  范数,那么目标函数就变成了
范数,那么目标函数就变成了
 。
。




 ,它与一个未知参数
,它与一个未知参数  ,我们就可以得到这个概率是
,我们就可以得到这个概率是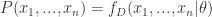 .
. ,然后利用这些数据来估算
,然后利用这些数据来估算 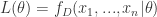 ,
, 的一阶导数等于零。这个使得
的一阶导数等于零。这个使得  称为
称为 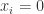 ; 否则
; 否则  . 并且假设
. 并且假设 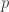 的 Bernoulli 分布的。我们此时的目标是计算最大似然估计
的 Bernoulli 分布的。我们此时的目标是计算最大似然估计  是相互独立的 Bernoulli 随机变量,那么对每一个
是相互独立的 Bernoulli 随机变量,那么对每一个 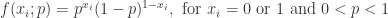 .
.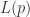 可以定义为:
可以定义为: .
. 求导:
求导:

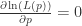 ,可以得到
,可以得到 .
.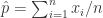 .
. 都是未知的。目标是寻找均值
都是未知的。目标是寻找均值  是满足正态分布的,那么对于每一个变量
是满足正态分布的,那么对于每一个变量 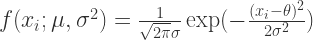 .
.
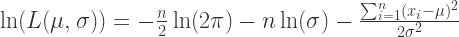


 和
和 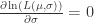 ,可以求解方程组得到:
,可以求解方程组得到: ,
, .
.
 是 shape parameter。特别地,当
是 shape parameter。特别地,当  时,Weibull 分布就是指数分布;当
时,Weibull 分布就是指数分布;当  时,Weibull 分布就是 Rayleigh 分布。
时,Weibull 分布就是 Rayleigh 分布。 ,
,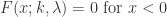 .
. .
. 那么对于每一个
那么对于每一个 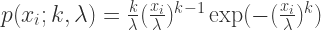 .
.


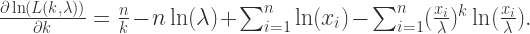
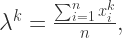
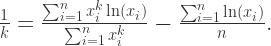

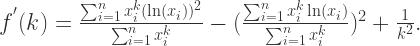

 ,换言之,
,换言之,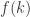 是关于
是关于 

 。如果从一个比较大的数开始的时候,可能使用 Newton 法的时候,会与负轴相交。但是如果从一个较小的数开始,就必定只与正数轴相交。其中 Newton 法的公式是:
。如果从一个比较大的数开始的时候,可能使用 Newton 法的时候,会与负轴相交。但是如果从一个较小的数开始,就必定只与正数轴相交。其中 Newton 法的公式是:

 就可以被当作最大似然估计。
就可以被当作最大似然估计。 ) yields much better results than a system that uses only unsupervised learning. The context is information security, scanning millions of log entries per day to detect suspicious activity and prevent attacks. Examples of attacks include account takeovers, new account fraud (opening a new account using stolen credit card information), and terms of service abuse (e.g. abusing promotional codes, or manipulating cookies for advantage).
) yields much better results than a system that uses only unsupervised learning. The context is information security, scanning millions of log entries per day to detect suspicious activity and prevent attacks. Examples of attacks include account takeovers, new account fraud (opening a new account using stolen credit card information), and terms of service abuse (e.g. abusing promotional codes, or manipulating cookies for advantage).




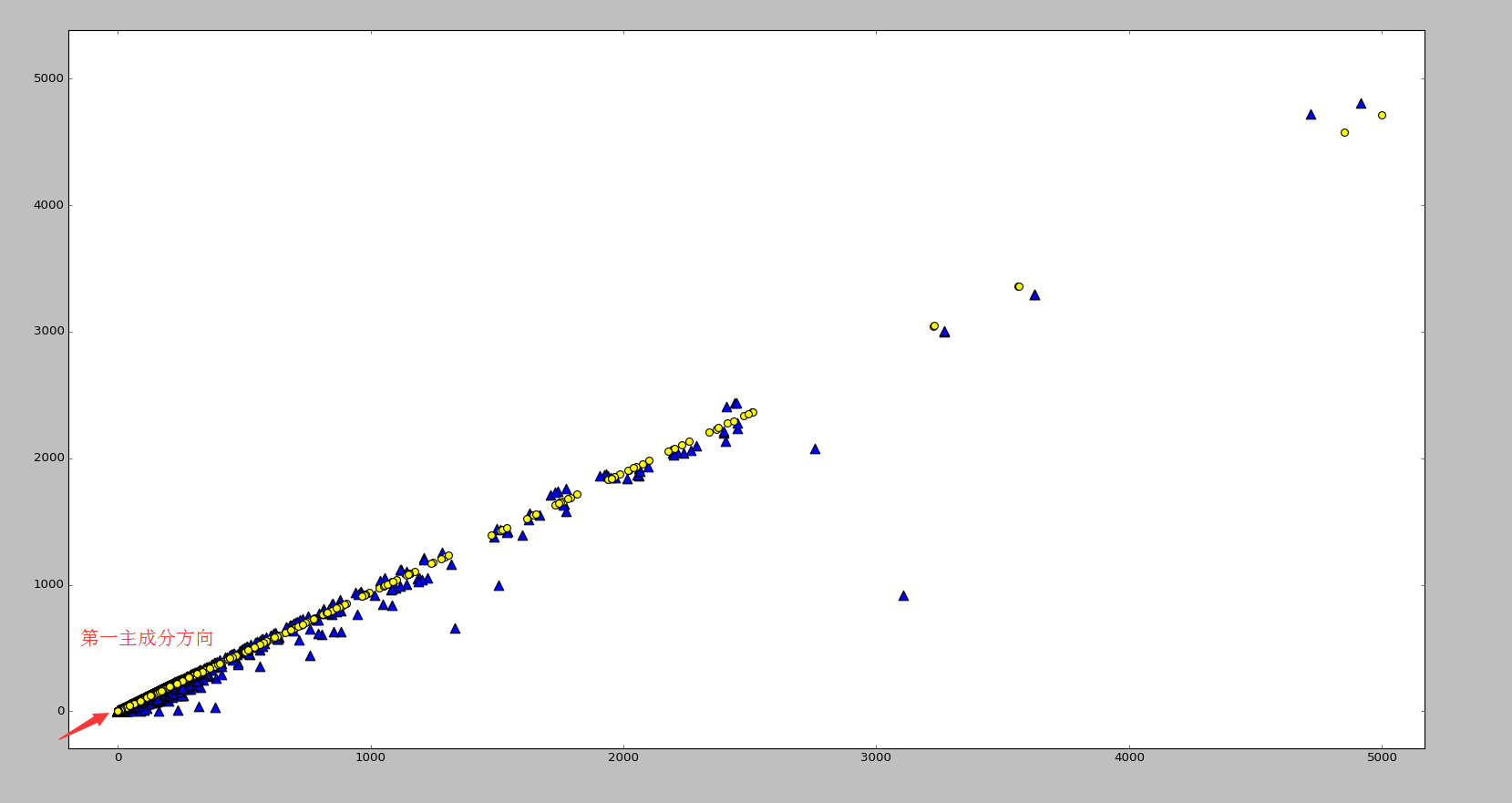
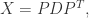
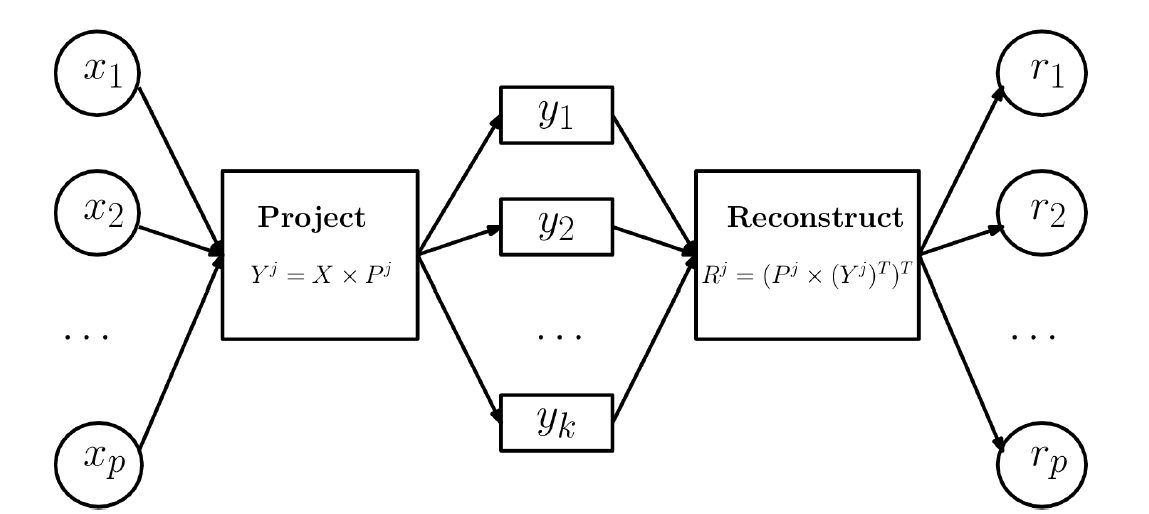
 。从图像上看,一个特征向量可以看成 2 维平面上面的一条线,或者高维空间里面的一个超平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,可以把对角矩阵 D 中的特征值进行从大到小的排序,矩阵 P 的每一列也进行相应的调整,保证 P 的第 i 列对应的是 D 的第 i 个对角值。
。从图像上看,一个特征向量可以看成 2 维平面上面的一条线,或者高维空间里面的一个超平面。特征向量所对应的特征值反映了这批数据在这个方向上的拉伸程度。通常情况下,可以把对角矩阵 D 中的特征值进行从大到小的排序,矩阵 P 的每一列也进行相应的调整,保证 P 的第 i 列对应的是 D 的第 i 个对角值。

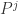 是矩阵 P 的前 j 列,也就是说
是矩阵 P 的前 j 列,也就是说 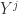 是一个 (N,j) 维的矩阵。如果考虑拉回映射的话(也就是从主成分空间映射到原始空间),重构之后的数据集合是
是一个 (N,j) 维的矩阵。如果考虑拉回映射的话(也就是从主成分空间映射到原始空间),重构之后的数据集合是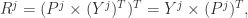
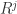 是使用 top-j 的主成分进行重构之后形成的数据集,是一个 (N,p) 维的矩阵。
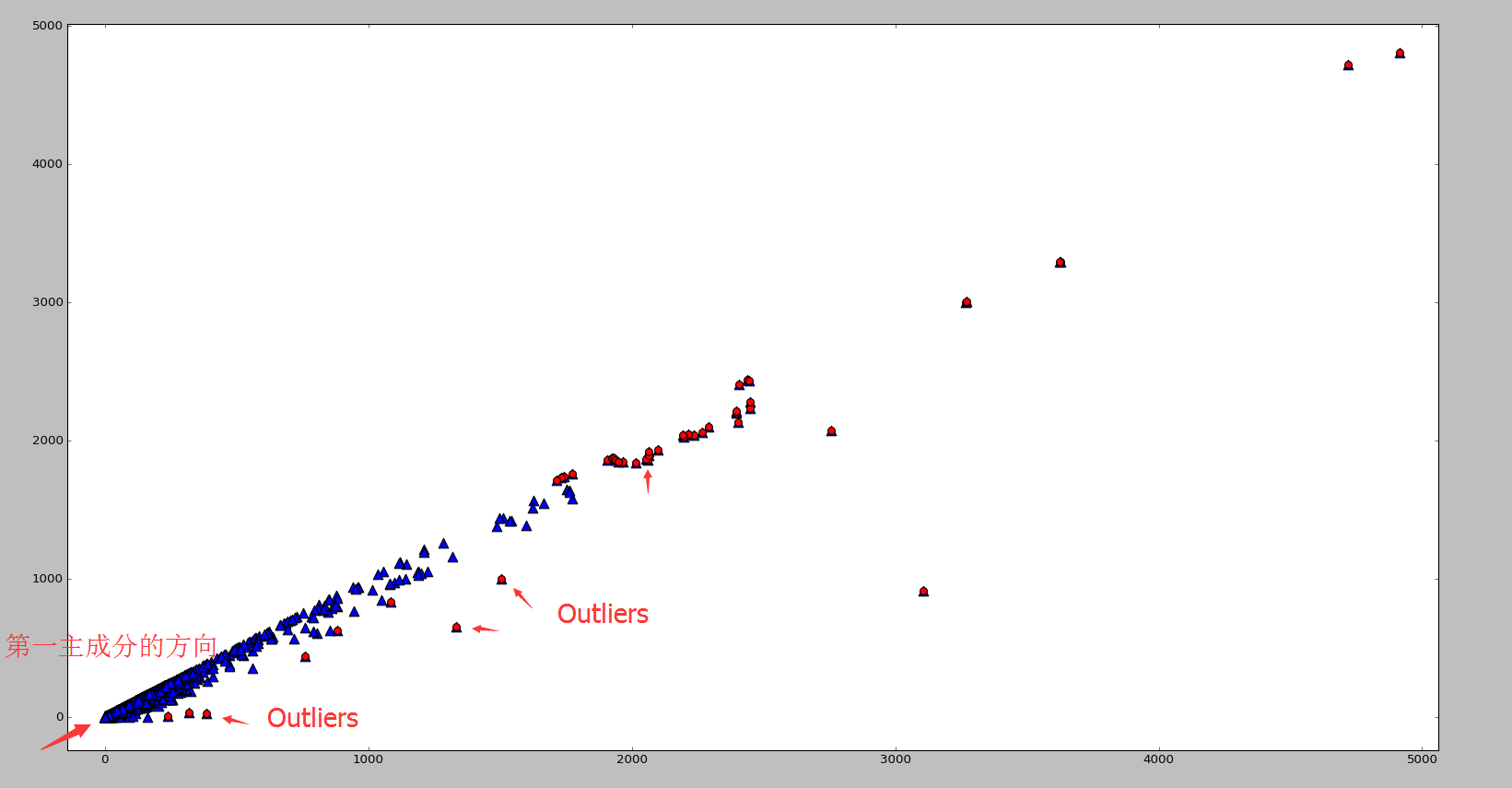
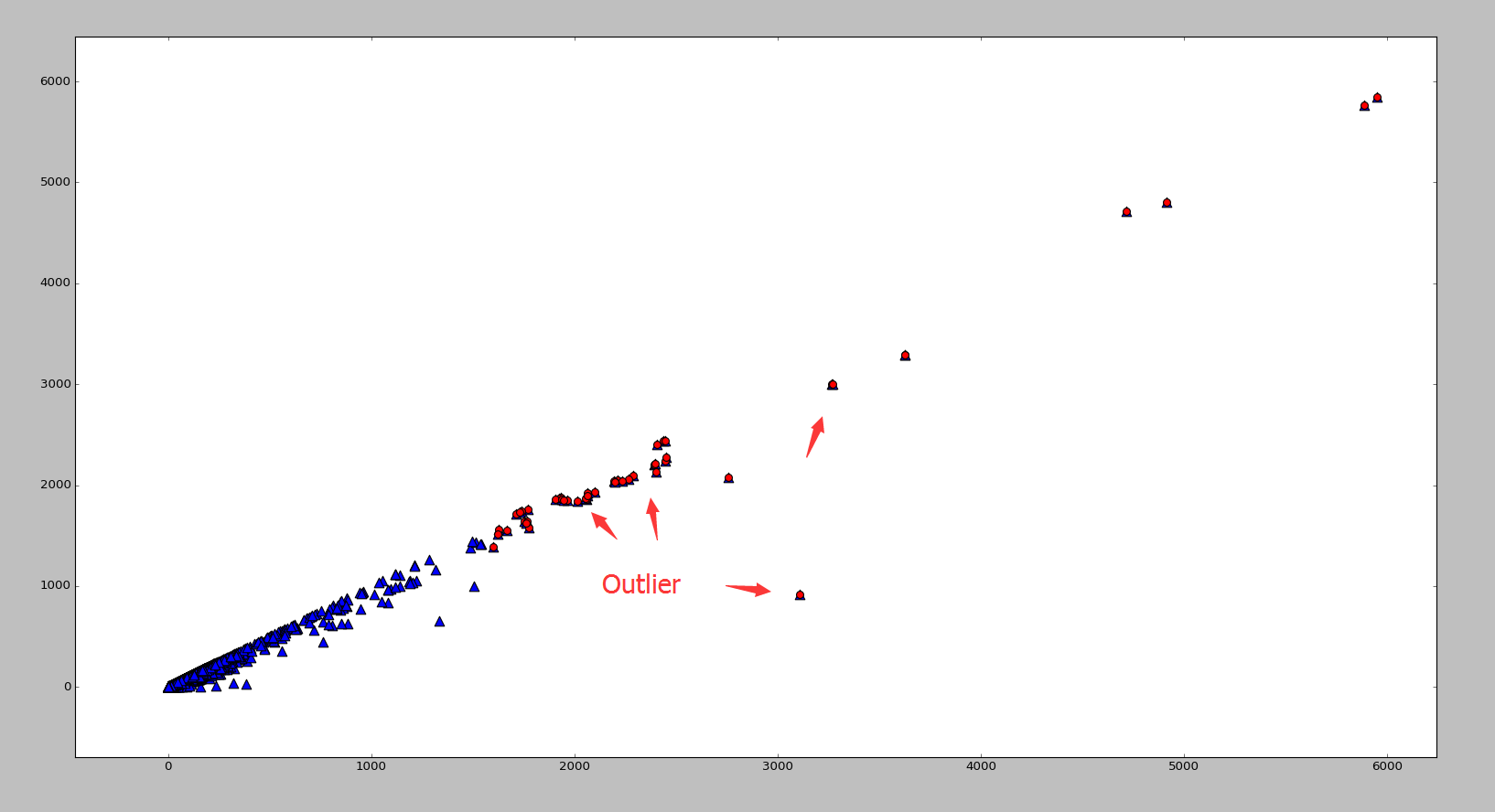
是使用 top-j 的主成分进行重构之后形成的数据集,是一个 (N,p) 维的矩阵。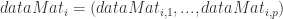 的异常值分数(outlier score)如下:
的异常值分数(outlier score)如下: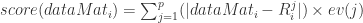
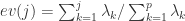
 指的是 Euclidean 范数, ev(j) 表示的是 top-j 的主成分在所有主成分中所占的比例,并且特征值是按照从大到小的顺序排列的。因此,ev(j) 是递增的序列,这就表示 j 越高,越多的方差就会被考虑在 ev(j) 中,因为是从 1 到 j 的求和。在这个定义下,偏差最大的第一个主成分获得最小的权重,偏差最小的最后一个主成分获得了最大的权重 1。根据 PCA 的性质,异常点在最后一个主成分上有着较大的偏差,因此可以获得更高的分数。
指的是 Euclidean 范数, ev(j) 表示的是 top-j 的主成分在所有主成分中所占的比例,并且特征值是按照从大到小的顺序排列的。因此,ev(j) 是递增的序列,这就表示 j 越高,越多的方差就会被考虑在 ev(j) 中,因为是从 1 到 j 的求和。在这个定义下,偏差最大的第一个主成分获得最小的权重,偏差最小的最后一个主成分获得了最大的权重 1。根据 PCA 的性质,异常点在最后一个主成分上有着较大的偏差,因此可以获得更高的分数。