
启发式优化算法的一些调研
启发式优化算法的背景
1. 首先,我们需要有一个目标函数 


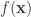
2. 其次,需要计算目标函数 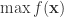
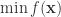
3. 再次,如果存在多个函数 

![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

希望求该目标函数的最小值,那么意思就是使得每一个 


4. 拥有目标函数的目的是寻找最优的 
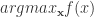
5. 在这里的 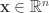
启发式优化算法的实验方法
1. 论文中的方法:找到一些形状怪异的函数作为目标函数,需要寻找这些函数的全局最大值或者全局最小值。除了全局的最大最小值点之外,这些函数也有很多局部极值点。例如 Rastrigin 函数(Chapter 6,Example 6.1,Search and Optimization by Metaheuristics)

其中,![\bold{x}\in[-5.12,5.12]^{n}.](https://s0.wp.com/latex.php?latex=%5Cbold%7Bx%7D%5Cin%5B-5.12%2C5.12%5D%5E%7Bn%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

其中,
![\bold{x} \in [-100,100]^{2}.](https://s0.wp.com/latex.php?latex=%5Cbold%7Bx%7D+%5Cin+%5B-100%2C100%5D%5E%7B2%7D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
2. 最朴素的算法:随机搜索法(Random Search)。也就是把 


3. 启发式优化算法:针对某一个目标函数,使用某种启发式优化算法,然后与随机搜索法做对比,或者与其余的启发式优化算法做对比。
4. 在线调优:启发式优化算法大部分都可以做成实时调优的算法,调优的速度除了算法本身的收敛速度之外,还有给定一个 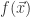
注:可以尝试使用启发式优化算法在线调优推荐系统中的 AUC 或者 CTR。不过 CTR 一般具有波动性,需要几个小时甚至一天的数据才能够统计出一个相对靠谱的取值。同时,如果用户量不够多的话,如果切流量的话,可能会造成一些流量的 CTR 偏高,另外一些流量的 CTR 偏低。并且流量的条数会有上限,一般来说不会超过 100 左右,甚至只有 10 个不同的流量。因此,在其余场景下使用这类方法的时候,一定要注意获取目标函数 value 的时间长度。时间长度越短,能够进行的尝试(探索次数)就会越多,收敛的希望就会越大;反之,时间长度越长,能够进行的尝试(探索次数)就会受到限制,收敛的时间长度就会变长。
启发式优化算法的一些常见算法
以下的内容暂时只涉及最基本的算法,有很多算法的变种暂时不做过多的描述。
粒子群算法(Particle Swarm Optimization)
PSO 算法是有一个粒子群,根据群体粒子和单个粒子的最优效果,来调整每一个粒子的下一步行动方向。假设粒子的个数是 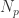

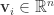

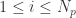
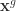
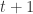
![\bold{v}_{i}(t+1) = \bold{v}_{i}(t) + c r_{1}[\bold{x}_{i}^{*}(t) - \bold{x}_{i}(t)] + c r_{2}[\bold{x}^{g}(t) - \bold{x}_{i}(t)],](https://s0.wp.com/latex.php?latex=%5Cbold%7Bv%7D_%7Bi%7D%28t%2B1%29+%3D+%5Cbold%7Bv%7D_%7Bi%7D%28t%29+%2B+c+r_%7B1%7D%5B%5Cbold%7Bx%7D_%7Bi%7D%5E%7B%2A%7D%28t%29+-+%5Cbold%7Bx%7D_%7Bi%7D%28t%29%5D+%2B+c+r_%7B2%7D%5B%5Cbold%7Bx%7D%5E%7Bg%7D%28t%29+-+%5Cbold%7Bx%7D_%7Bi%7D%28t%29%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
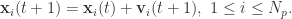
在这里,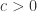

注:需要解决的问题是如何设置这
模拟退火(Simulated Annealing)
其核心思想是构造了温度 
模拟退火的大体思路是这样的:先设置一个较大的温度值 


Repeat:
a. Repeat:
i. 进行一个随机扰动 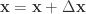
ii. 计算 
如果 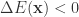


否则,按照 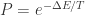

b. 令 
直到
遗传算法的个人理解:
- 如何选择合适的
,可以选择 Gaussian 正态分布,并且可以同时修改
- 一开始在温度
的时候,都会以极大概率接受
,因为此时
。然后一开始都在四处游荡;
- 当温度
- 从遗传算法和 PSO 的对比效果来看,因为 PSO 算法会随时记录当前粒子和所有粒子的最优状态,然后在整个种群中,总会有少数粒子处于当前的最优状态,所以 PSO 的效果从实验效果上来看貌似比不记录状态的遗传算法会好一些。
进化策略(Evolutionary Strategies)
ES 和 GA 有一些方法论上面的不同,这个在书上有论述,等撰写了 GA 在一起看这一块的内容。
进化策略(Evolutionary Strategies)的大体流程与遗传算法(Genetic Algorithm) 相似,不同的是 ES 的步骤是交叉/变异(Crossover/Mutation)在前,选择(Selection)在后。
对于经典的进化策略而言,交叉算子(Crossover Operator)可以按照如下定义:两个父代(parents)


这里的相加就是向量之间的相加。
对于经典的进化策略而言,变异算子(Mutation Operator)可以按照如下定义:对于一个向量 

这里的 
就经验而谈,ES 算法一般来说比 GA 更加 Robust。在交叉(Crossover)或者变异(Mutation)之后,ES 算法就需要进行选择,通常来说,ES 算法有两种方式,分别是 

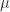
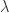
(1)在
(2)在 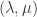

传统的梯度搜索法,例如 Newton-Raphson 方法,需要能够计算目标函数 
如果是 

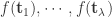
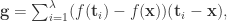
归一化之后得到

Evolutionary gradient search 生成了两个点,分别是:

这里的 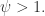


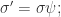

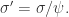
进化策略(ES)包括 gradient search 和 gradient evolution,并且 covariance matrix adaptation(CMA)ES 在一定的限制条件下加速了搜索的效率。
参考资料:
- Search and Optimization by Metaheuristics,Kelin DU, M.N.S. SWAMY,2016年
