
统计距离(Statistical Distance)
统计距离的定义
在欧式空间,如果要衡量两个 




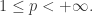


在统计学中,如果需要衡量两个统计对象之间的“距离”,在离散的场景下除了可以使用欧式距离之外,还可以使用其他的统计距离来描述这两个统计对象之间的距离。与之对应的,在连续的场景下,同样可以定义出两个统计对象之间的距离。
首先,我们来回顾一下距离的定义;
距离是定义在集合 

对于所有的
都成立;
对于所有的
对于所有的
都成立。

而广义的距离会缺少其中一个或者多个条件,例如时间序列领域中的 DTW 距离就不满足三角不等式。
在微积分中,凸函数(convex 函数)




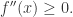
其次,在统计距离中,通常会基于一个函数 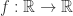


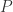
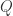
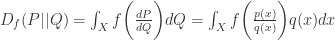
定义了概率分布 
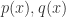

- KL – 散度(KL – Divergence):
- Reverse KL -散度(Reverse KL – Divergence):
- Hellinger 距离(Hellinger Distance):
或者
- 变分距离(Total Variation Distance):
- Pearson
– 散度(Pearson
或者
或者
- Reverse Pearson
或者
- Jensen-Shannon-Divergence:
- L1 – 范数(L1 – Norm):

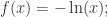


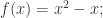



在这样的定义下,
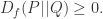

在数学中有如下定理:如果 

根据以上定理,可以得到:对于 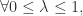
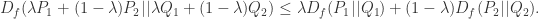
除了 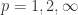



统计距离的函数分析
事实上,对于 KL 散度和 Reverse KL 散度而言,令


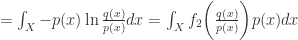
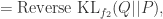
这就是函数 
类似地,对于函数 
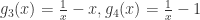


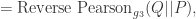
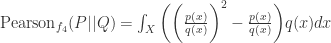


对于 Jensen-Shannon Divergence(简写为 JSD)而言,
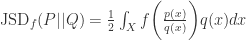


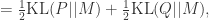
其中 

对于 Hellinger Distance 而言,



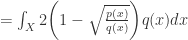
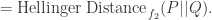
其中 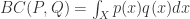
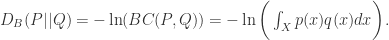
统计距离的上下界分析
对于以上函数而言,由于凸函数 

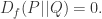
KL 散度是没有上界的,但是 Jensen Shannon Divergence 是具有上界的。事实上,如果

同样地,
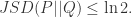
根据 Hellinger 距离的公式,可以得到:


考虑


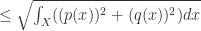


证明以上不等式使用了性质 

多重集合
多重集合的定义与性质
在数学中,集合(set)中不能够包含重复的元素,但一个多重集合(multiset)中则可以包含重复的元素,并且计算了元素的重数。例如,
- 当
时,
可以看成集合,也可以看成重数为 1 的多重集合,可以记为
或者
- 在多重集合
中,
的重数是 2,
的重数是 1,可以记为
或者
- 在多重集合
中,
的重数都是 3。
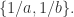
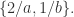
对于一个有限集合 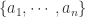




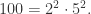
假设多重集合 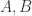

- 子集:如果对于所有的
有
则称多重集合
是多重集合
的子集;
- 交集:如果
则称多重集合
是多重集合
- 并集:如果
则称多重集合
- 求和:如果
则称多重集合
- 求差:如果
则称多重集合


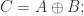

假设 
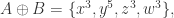



多重集合的相似度和距离
由于已经定义了多重集合的交集和并集,因此集合相似度中的 Jaccard 相似度,Overlap 相似度都可以应用到多重集合中。
对于多重集合 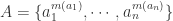


参考资料
- 统计距离:https://en.wikipedia.org/wiki/Statistical_distance
- f – divergence:https://en.wikipedia.org/wiki/F-divergence:包括了 KL 散度的其余变形方式。
- Bregman distance:https://en.wikipedia.org/wiki/Bregman_divergence
- Jensen Shannon Divergence:https://en.wikipedia.org/wiki/Jensen%E2%80%93Shannon_divergence
- KL Divergence:https://en.wikipedia.org/wiki/Kullback%E2%80%93Leibler_divergence
- Bhattacharyya distance:https://en.wikipedia.org/wiki/Bhattacharyya_distance
- Wasserstein metric:https://en.wikipedia.org/wiki/Wasserstein_metric
- 多重集合:multiset:https://en.wikipedia.org/wiki/Multiset

张博士,
您好!
我现在是一个在读的能源专业博士生,我一直在关注你的blog,感叹于自己数学方面的不足,在你的这里学到了非常多的东西。
在看了你这篇统计距离和上一篇相似度的文章后,我把其中的数学模型用在了能源分析上。在翻看了你的reference之后,我还是有一些疑问,希望能烦劳你帮忙解答一下。
我把Jaccard, overlap, dice 和 Pearson都用在了我的风电场发电数据分析上,希望能找到相关发电机组的相似性。但是我发现4个处理出来的结果,有一些结果的差异非常大。我翻看我专业的文章里面,大多数都是pearson,也就是matlab里面常用的corrcoef。
我想咨询一下的就是,这四个不同的处理方式,我如何能从中找到他们之间的相似结论,也即,我希望通过4个不同的处理,找到运行结果类似的风场模型。
非常感谢!
此致
敬礼
杨士辰
LikeLike
风场数据我暂时不太了解。Jaccard / Overlap /Dice 主要是为了处理集合类型的数据,Pearson 可以处理序列型的数据。在不同的场景下,应该是需要使用不同的相似度指标来进行计算。在不同的时候,需要的相似度是不一样的。
可以根据具体的场景来进行选择。
LikeLike
个人感觉四种相似度算法,得到的差异性较大应该是合理的,毕竟四种相似度算法描述的“相似度”是不一样的。选择一个最合适的即可。
LikeLike
了解了。也就是说’similarity’ 和’correlation‘的差别,我理解了。感谢!
LikeLike