
Unsupervised Analytics: Moving Beyond Rules Engines and Learning Models
无监督机器学习:超越规则引擎和有监督机器学习的新一代反欺诈分析方法
Rules engines, machine learning models, ID verification, or reputation lookups (e.g. email, IP blacklists and whitelists) and unsupervised analytics? I’ve often been asked which one to use and should you only go with one over the others. There is a place for each to provide value and you should anticipate incorporating some combination of these fraud solutions along with solid domain expertise to build a fraud management system that best accounts for your business, products and users. With that said, rules engines and learning models are two of the major foundational components of a company’s fraud detection architecture. I’ll explain how they work, discuss the benefits and limitations of each and highlight the demand for unsupervised analytics that can go beyond rules engines and machine learning in order to catch new fraud that has yet to be seen.
Rules Engines
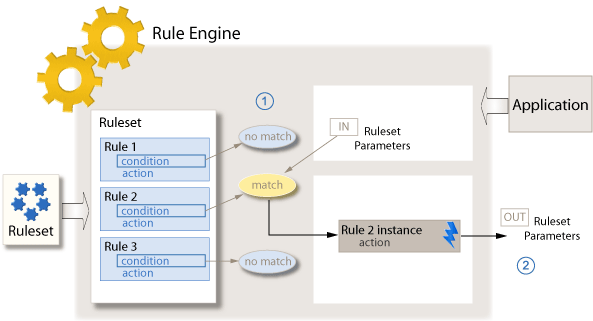
How they work
Rules engines partition the operational business logic from the application code, enabling non-engineering fraud domain experts (e.g. Trust & Safety or Risk Analysts) with SQL/database knowledge to manage the rules themselves. So what types of rules are effective? Rules can be as straightforward as a few lines of logic: If A and B, then do C. For example,
IF (user_email = type_free_email_service) AND (comment_character_count ≥ 150 per sec) {
flag user_account as spammer
mute comment
}
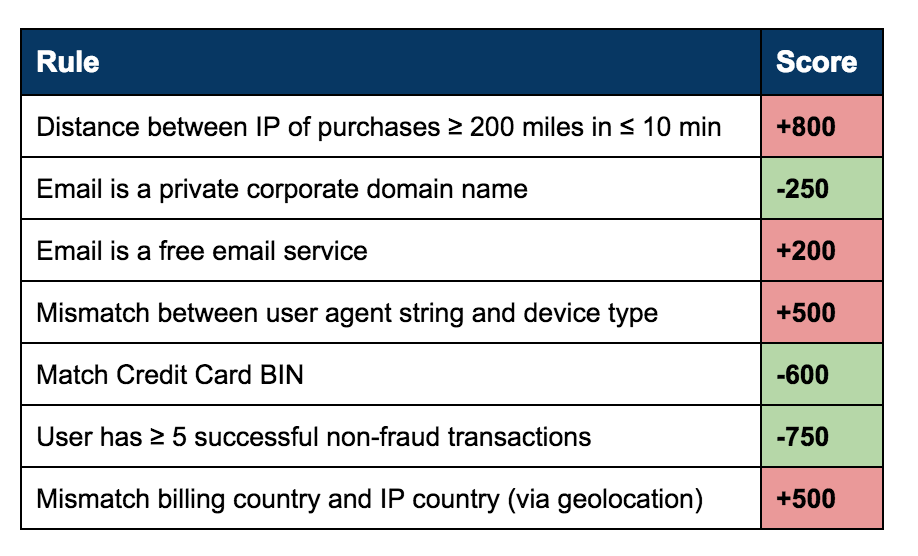
Rules engines can also employ weighted scoring mechanisms. For example, in the table below each rule has a score value, positive or negative, which can be assigned by an analyst. The points for all of the rules triggered will be added together to compute an aggregate score. Subsequently, rules engines aid in establishing business operation workflows based on the score thresholds. In a typical workflow, there could be three types of actions to take based on the score range:
- Above 1000 – Deny (e.g. reject a transaction, suspend the account)
- Below 300 – Accept (e.g. order is ok, approve the content post)
- Between 300 and 1000 – Flag for additional review and place into a manual review bin
Advantages
Rules engines can take black lists (e.g. IP addresses) and other negative lists derived from consortium databases as input data. An analyst can add a new rule as soon as he or she encounters a new fraud/risk scenario, helping the company benefit from the real-world insights of the analyst on the ground seeing the fraud every day. As a result, rules engines give businesses the control and capability to handle one-off brute force attacks, seasonality and short-term emerging trends.
Limitations
Rules engines have limitations when it comes to scale. Fraudsters don’t sit idle after you catch them. They will change what they do after learning how you caught them to prevent being caught again. Thus, the shelf life of rules can be a couple of weeks or even as short as a few days before their effectiveness begins to diminish. Imagine having to add, remove, and update rules and weights every few days when you’re in a situation with hundreds or thousands of rules to run and test. This could require huge operational resources and costs to maintain.
If a fraud analyst wants to calculate the accept, reject, and review rates for 3 rules and get the changes in those rates for adjusting each rule down or up by 100 points, that would require 8 changes: 23^ = 8 (values^rules). Testing 10 rules with 3 different values would be over 59K changes! As the number of rules increases, the time to make adjustments increases quickly.
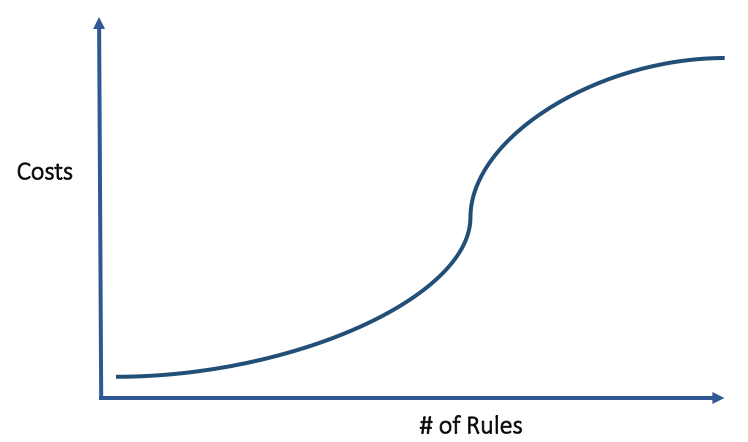
Rules engines don’t automatically learn from analyst observations or feedback. As fraudsters adapt their tactics, businesses can be temporarily exposed to new types of fraud attacks. And since rules engines treat information in a binary fashion and may not detect subtle nuances, this can lead to higher instances of false positives and negative customer experiences.
Learning Models
How they work
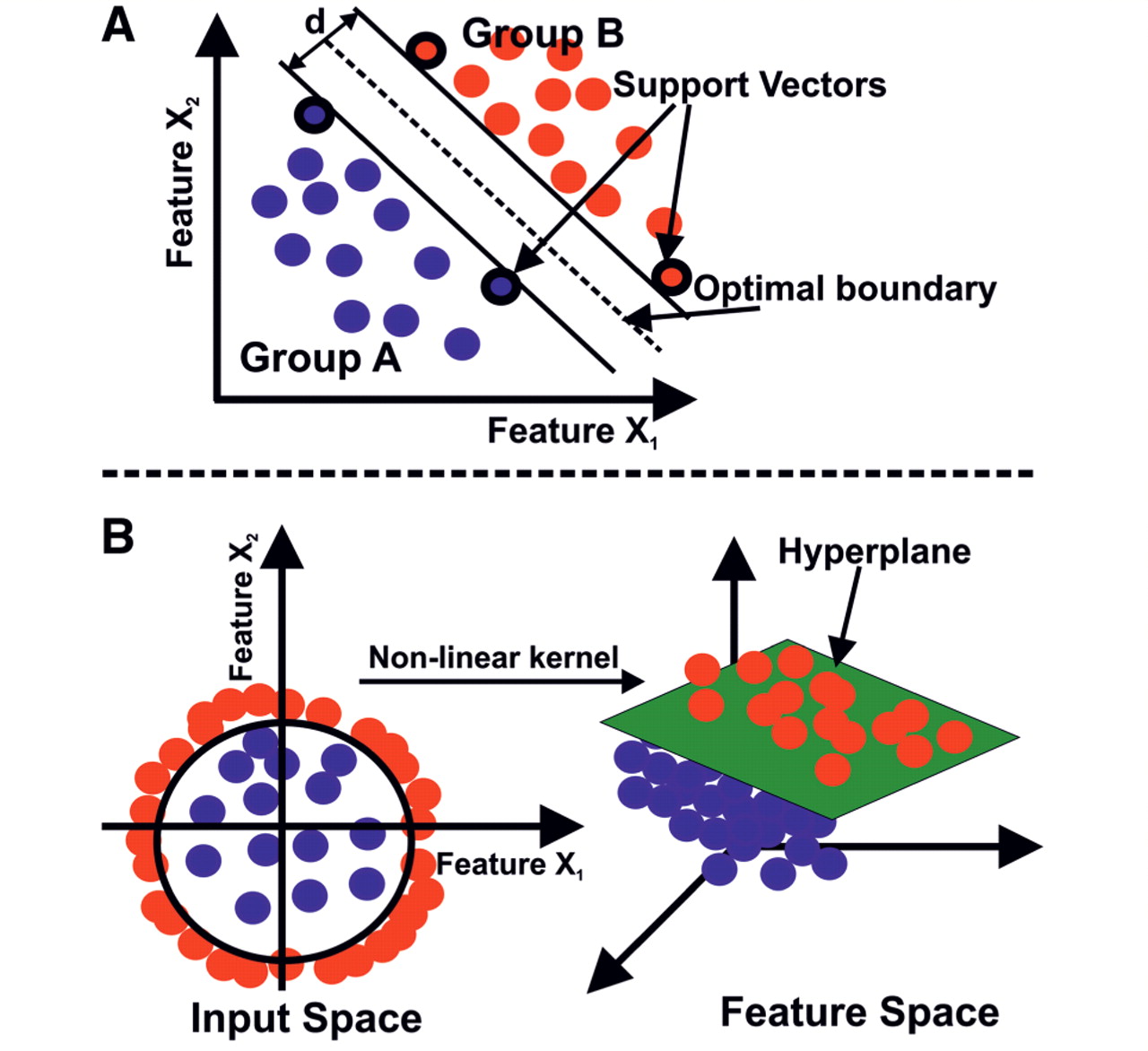
Supervised machine learning is the most widely used learning approach when it comes to fraud detection. A few of the learning techniques include decision trees, random forests, nearest neighbors, Support Vector Machines (SVM) and Naive Bayes. Machine learning models often solve complex computations with hundreds of variables (high-dimensional space) in order to accurately determine cases of fraud.
Having a good understanding of both what is and what is not fraud plays a central role in the process of creating models. The input data to the models influences their effectiveness. The models are trained on known cases of fraud and non-fraud (e.g. labeled training data), which then facilitate its ability to classify new data and cases as either fraudulent or not. Because of their ability to predict the label for a new unlabeled data set, trained learning models fill in the gap and bolster the areas where rules engines may not provide great coverage.
Below is a simplified example of how a supervised machine learning program would classify new data into the categories of non-fraud or fraud. Training data informs the model of the characteristics of two types of fraudsters: 1) credit card fraudsters and 2) spammers. Three features: 1) the email address structure, 2) the IP address type, and 3) the density of linked accounts are indicative of the type of fraud attack (e.g. response variable). Note in reality, there could be hundreds of features for a model.
The trained model recognizes that a user with:
- an email address that has 5 letters followed by 3 numbers
- using an anonymous proxy
- with a medium density (e.g. 10) of connected accounts
is a credit card fraudster.
It also knows recognizes that a user with:
- an email address structure with a “dot” pattern
- using an IP address from a datacenter
- with a high density (e.g. 30+) of linked accounts
is a spammer.
Now suppose your model is evaluating new users from the batch of users below. It computes the email address structure, IP address type, and density of linked accounts for each user. If working properly, it will classify the users in Cases 2 and 3 as spammers and the users in Cases 1, 4 and 5 as credit card fraudsters.

Advantages
Because of their ability to predict the label for a new unlabeled data set, trained learning models fill in the gap and bolster the areas where rules engines may not provide great coverage. Learning models have the ability to digest millions of row of data scalably, pick up from past behaviors and continually improve their predictions based on new and different data. They can handle unstructured data (e.g. images, email text) and recognize sophisticated fraud patterns automatically even if there are thousands of features/variables in the input data set. With learning models, you can also measure effectiveness and improve it by only changing algorithms or algorithm parameters.
Limitations
Trained learning models, while powerful, have their limitations. What happens if there are no labeled examples for a given type of fraud? Given how quickly fraud is evolving, this is not that uncommon of an occurrence. After all, fraudsters change schemes and conduct new types of attacks around the clock. If we have not encountered the fraud attack pattern, and therefore do not have sufficient training data, the trained learning models may not have the appropriate support to return good and reliable results.
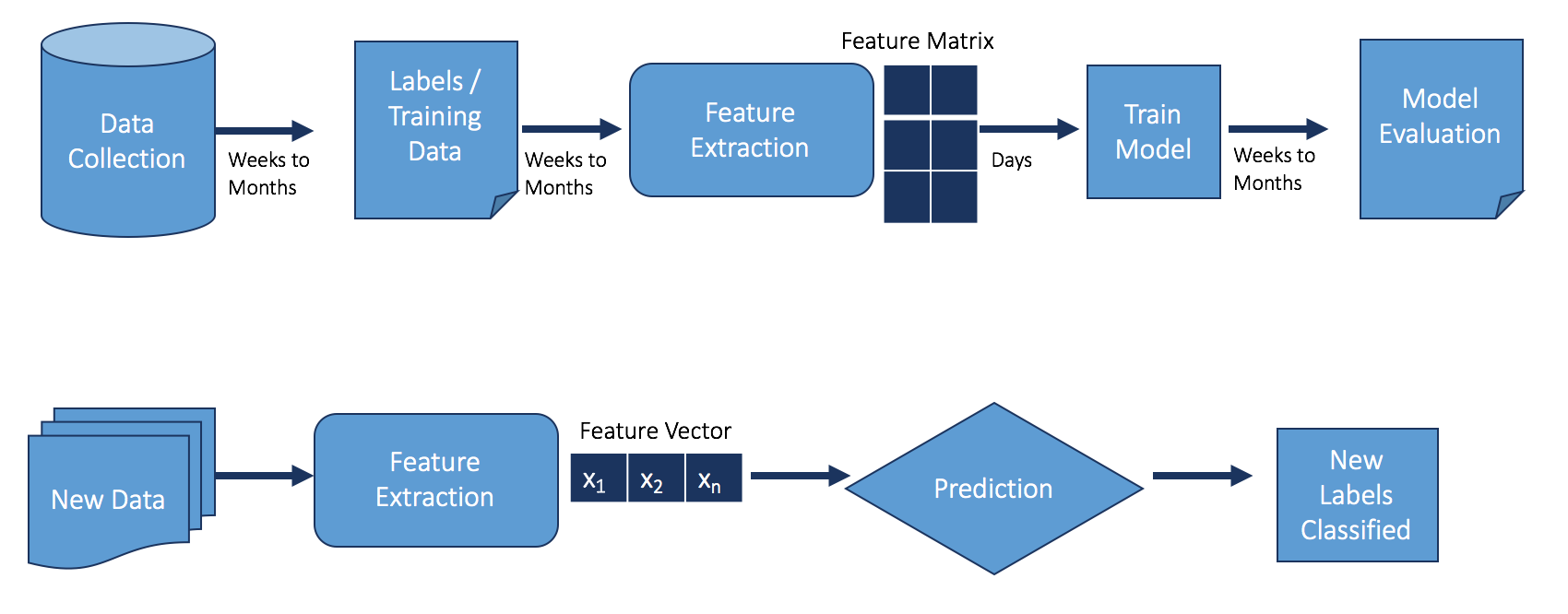
As seen in the diagram below, collecting and labeling data is a crucial part of building a learning model and the time required to generate accurate training labels can be weeks to months. Labeling can involve teams of fraud analysts reviewing cases thoroughly, categorizing it with the right fraud tags, and undergoing a verification process before being used as training data. In the event a new type of fraud emerges, a learning model may not be able to detect it until weeks later after sufficient data has been acquired to properly train it.
Unsupervised Analytics – Going Beyond Rules Engines and Learning Models
While both of these approaches are critical pieces of a fraud detection architecture, here at DataVisor we take it one step further. DataVisor employs unsupervised analytics, which do not rely on having prior knowledge of the fraud patterns. In other words no training data is needed. The core component of the algorithm is theunsupervised attack campaign detection which leverages correlation analysis and graph processing to discover the linkages between fraudulent user behaviors, create clusters and assign new examples into one or the other of the clusters.
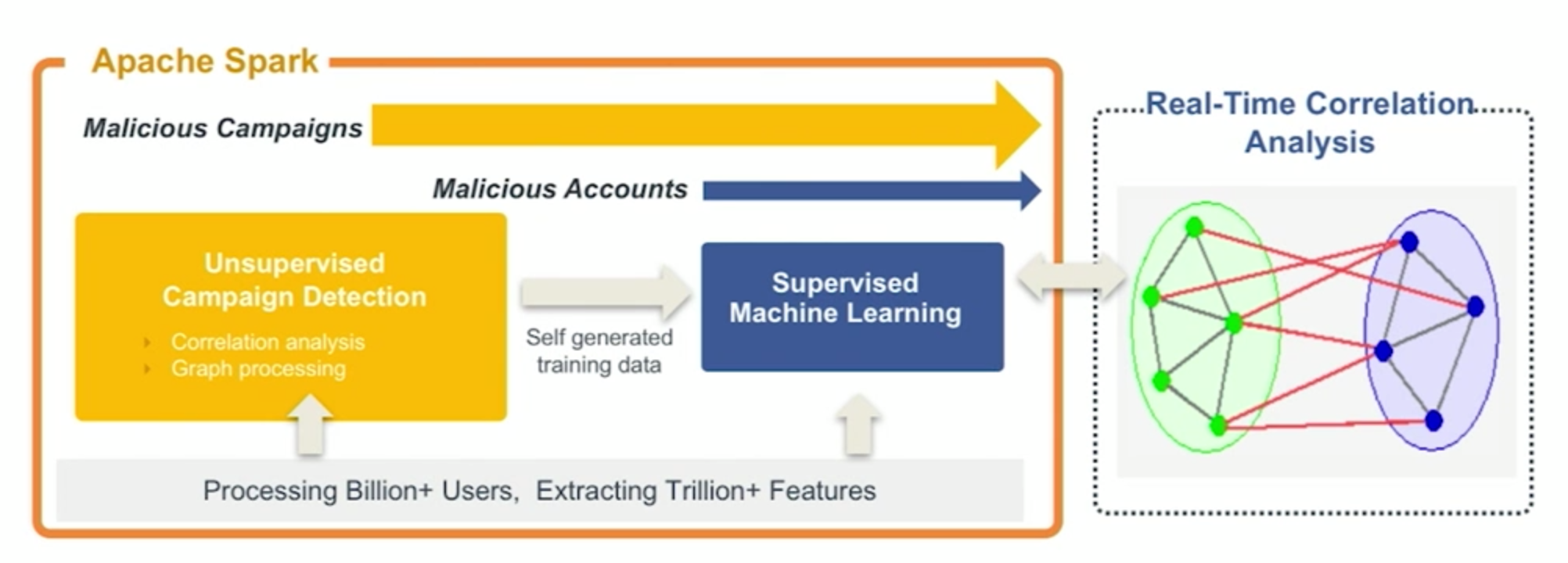
The unsupervised campaign detection provides the attack campaign group info and also the self-generated training data, both of which can be fed into our machine learning models to bootstrap them. With this data, the supervised machine learning will pick up patterns and find the fraudulent users that don’t fit into these large attack campaign groups. This framework enables DataVisor to uncover fraud attacks perpetrated by individual accounts, as well as organized mass scale attacks coordinated among many users such as fraud and crime rings – adding a valuable piece to your fraud detection architecture with a “full-stack.”
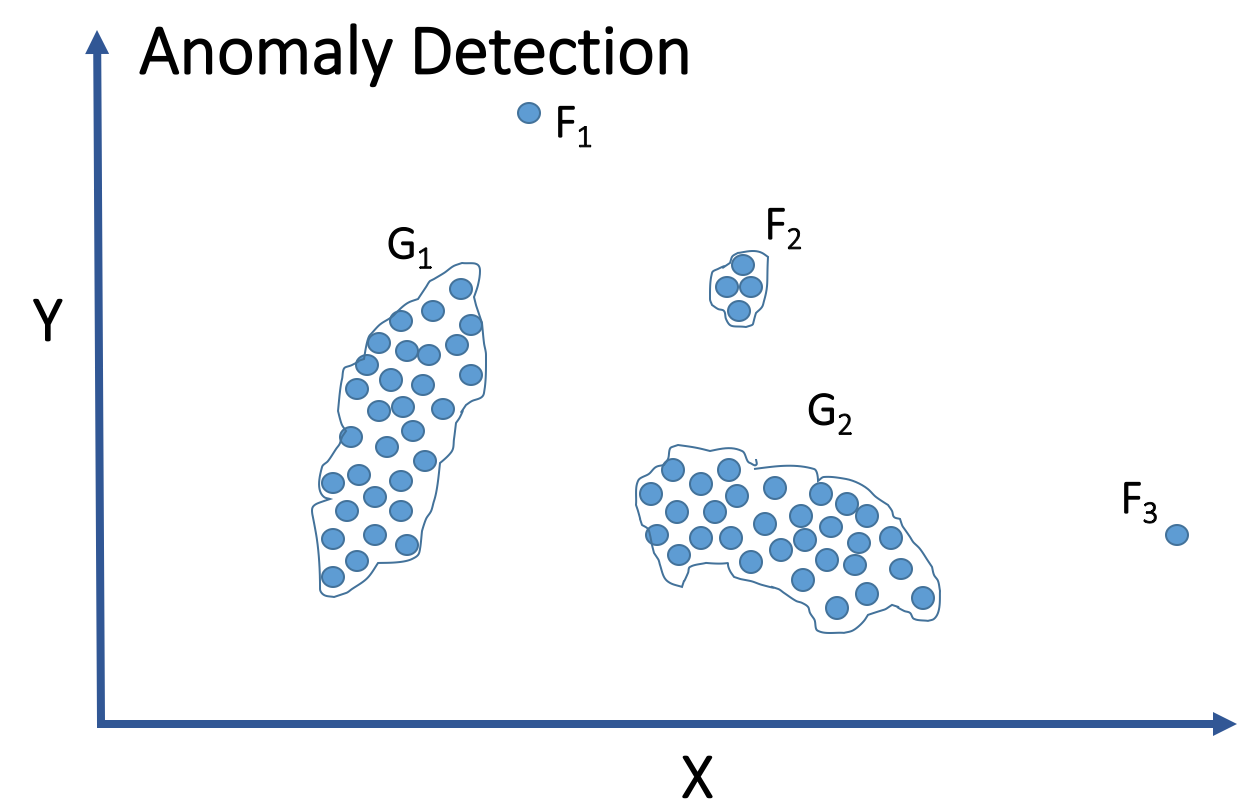
Our correlation analysis groups fraudsters “acting” similarly into the same cluster. In contrast, anomaly detection, another useful technique, finds the set of fraud objects that are considerably dissimilar from the remainder of the good users. It does this is by assuming anomalies do not belong to any group or they belong to small/sparse clusters. See graph below for anomaly detection illustrating fraudsters F1, F3, and group F2and good users G1 and G2. The benefits of unsupervised analytics is on display when comparing it to anomaly detection. While anomaly detection can find outlying fraudsters from a given data set, it would encounter a challenge identifying large fraud groups.
With unsupervised analytics, DataVisor collaborates with rules engines and machine learning models. For customers, the analytics provides them a list of the fraudsters and also gives their fraud analysts insights to create new rules. When DataVisor finds fraud that has not been encountered by a customer previously, the data from the unsupervised campaign detection can serve as early warning signals and/or training data to their learning models, creating new and valuable dimensions to their model’s accuracy.
By focusing on early detection and discovering unknown fraud, DataVisor has helped customers to become better and more efficient in solving fraud in diverse range of areas such as:
- Identifying fake user registration and account takeovers (ATO)
- Detecting fraudulent financial transactions and activity
- Discovering user acquisition and promotion abuse
- Preventing social spam, fake posts, reviews and likes
Stay tuned for future blog posts where I will address topics such as new online fraud attacks, case review management tools, and a closer look into DataVisor’s fraud detection technology stack. If you want to learn more about how DataVisor can help you fight online fraud, please visit https://datavisor.com/ or schedule atrial.
