
灰度预测法是一种对含有不确定因素的系统的预测方法,灰色系统是位于白色系统和黑色系统之间的一种系统。
白色系统指的是一个系统内部的特征是完全已知的,使用者不仅知道系统的输入-输出关系,还知道实现输入-输出的具体方式,譬如函数表达式,微分方程的变化公式,或者物理学的基本定律。比方说牛顿第二定律F=ma, 使用者只需要知道物体的质量和加速度,就可以通过牛顿第二定律求出所使用的力F的具体值。或者说当物体的质量固定之后,已知不同的加速度,就可以求出不同的力的值,力和加速度之间有明确的关系表达式。这种系统就称为白色系统。
黑色系统和白色系统就有鲜明的对比,使用者完全不清楚黑色系统的内部特征,只是知道一些输入和相应的输出。使用者需要通过这一系列的输入和输出的对应关系来判断这个黑色系统的内部特征,对于没有办法打开的黑箱,使用者需要通过输入和输出来建立模型来了解这个黑箱。比方说:高校在进行招生的时候,其实对考生是几乎不了解的,这个时候就需要通过高考或者自主招生考试来判断学生的知识掌握程度和运用知识解决问题的能力。通过测试的结果来判断学生的综合能力的大小,进而判断是不是符合高校的专业需求。
而灰度系统恰好位于白色系统和黑色系统之间,灰度系统内部一部分是已知的,但是另一部分却是未知的。比方说:经济学中的模型,通过数学或者统计学的方法,可以判断某些因素之间确实有关系,但是却不能够完全的判断整个系统的情况,对于很多未知的情况,这些模型就有一定的局限性。于是,灰度系统就需要通过判断系统各个因素之间的发展规律,进行相应的关联分析。通过原始的数列来生成规律性更强的数列,通过生成的数列来建立相应的微分方程模型,从而预测数列的未来发展趋势。灰度模型使用等时间距观测到的数据值来构造灰色预测模型,从而达到能够预测未来某一时刻的数值的目的。
尽管灰度系统的现象不够清楚,内部的结构并不为人所知,数据是杂乱的,但是却是互相关联的,有整体功效的,因而可以对它的变化过程进行预测。其中灰度模型是灰度系统理论的重要组成部分,将杂乱的原始数据整理成规律性较强的数据,然后再利用离散的灰度方程建立连续的微分模型,从而对系统的发展做出全面的观察分析,并做出长期预测。
下面来介绍下灰度模型的几种分类:
已知序列 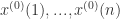

(1) 灰度模型GM(1,1)
第一步需要通过累加形成新序列 

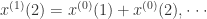

对上面的累加序列取均值,就可以得到序列

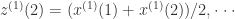
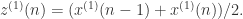
那么GM(1,1)灰度模型相应的微分方程就是

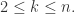
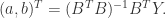

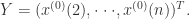
通过常微分方程的求解,可以得到预测模型的解析表达式。这里分两种情况:
第一种情况:




第二种情况:
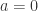
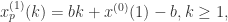

(2) 灰度Verhulst模型
灰度Verhulst模型和前面的灰度模型GM(1,1)相似,也是计算累加生成数列,然后计算中值数列。不过Verhulst模型是建立非线性的常微分方程,所以相应的矩阵B和Y就需要做更改。微分方程是


通过微分方程的求解,可以得到



注:如果

(3) 灰度模型DGM(2,1)
这个DGM(2,1)灰度模型并不需要累加生成序列,直接使用原序列就可以进行操作。微分方程是


通过微分方程的求解,可以得到:
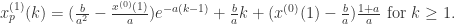
求解原序列的预测值就是:
案例1:灰度模型在电力行业的应用。
某市1984~1990年用电量数据如下:
年份 1984 1985 1986 1987 1988 1989 1990
用电量/GWh 2783.20 3028.26 3290.55 3477.77 3685.02 3935.09 4210.29
这里用n=4,也就是前四个点建立模型,然后后面三个点用来测试模型的正确性。注:这里使用了一些根据上面模型进行改进的灰度模型,进行了模型的融合。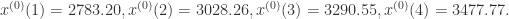



通过平均绝对百分比误差(Mean Absolute Percentage Error)的定义得到:前四项的MAPE<0.005, 所有七项的MAPE<0.01. 通过标准均方根误差(Normalized root mean square error)的定义可以求出前四项的NRMSE<0.027, 所有七项的NRMSE<0.031.
作图如下:
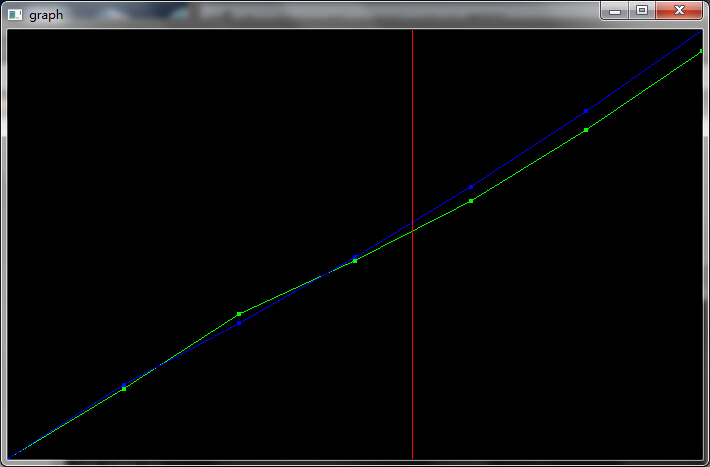
其中绿色线条表示实际的用电量数据,蓝色线条表示用灰度模型模拟的用电量数据。红线左侧表示用来测试的前四项,红线右侧表示预测的未来三年的走势。
案例2:某油藏原始数据
年份 1972 1973 1974 1975 1976 1977 1978 1979
综合含水 31.8 39.1 43.2 48.6 49.8 53.3 58.6 61.7
这里用n=5,也就是前五个点建立模型,然后后面三个点用来测试模型的正确性。

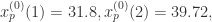
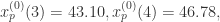

通过平均绝对百分比误差(Mean Absolute Percentage Error)的定义得到:前五项的MAPE<0.015, 所有八项的MAPE<0.023. 通过标准均方根误差(Normalized root mean square error)的定义可以求出前五项的NRMSE<0.054, 所有八项的NRMSE<0.052.
作图如下:
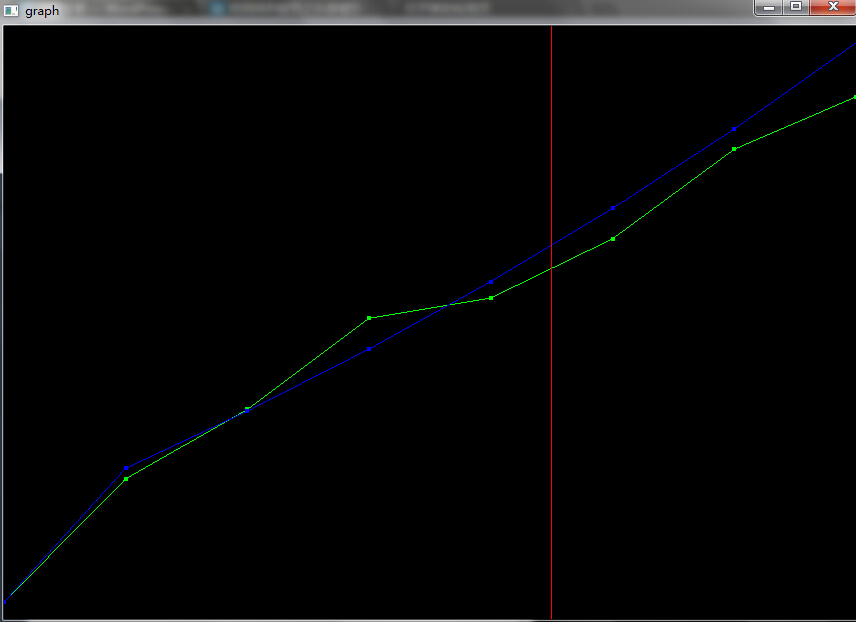
其中绿色线条表示实际的综合含水数据,蓝色线条表示用灰度模型模拟的综合含水数据。红线左侧表示用来测试的前五项,红线右侧表示预测的未来三年的走势。
参考文献:
