提到 阶导数,就必须要提一下 Taylor Series 了。对于常见函数的 Taylor Series,SymPy 也是有非常简便的方法,那就是 series 函数。其参数包括 expr, x, x0, n, dir,分别对应着表达式,函数的自变量,Taylor Series 的中心点,n 表示阶数,dir 表示方向,包括”+-“,”-“,”+”,分别表示 , , 。
A, B, C = sympy.symbols("A B C")
>>> sympy.simplify_logic(A | (A & B))
A
>>> sympy.simplify_logic((A>>B) & (B>>A))
(A & B) | (~A & ~B)
>>> A>>B
Implies(A, B)
如果只想获得第 n 个素数,则使用函数 sympy.ntheory.generate.prime(n) 即可。如果是希望计算 x 后面的下一个素数,使用 sympy.ntheory.generate.nextprime(x) 即可。判断 x 是否是素数,可以使用 sympy.ntheory.generate.isprime(x)。
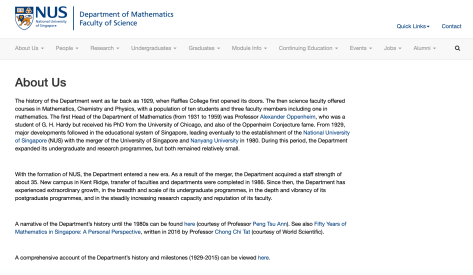
随着 NUS 的建立,数学系就进入了一个新的时代。新的校区在 Kent Ridge,1986 年理学院和数学系就在这里成立。这个时候,数学系就有了巨大的发展,不仅在本科生的招生规模方面有了巨大提高,在研究生项目规模上也有了一定的深度的提升。
新加坡国立大学的数学系与国内的数学系有所不同。一般情况下,国内的数学系能够提供的专业包括数学与应用数学(Mathematics and Applied Mathematics),信息与计算科学(Information and Computing Science)与统计学(Statistics),有的时候会加上金融数学(Financial Mathematics)这一方向。而新加坡国立大学的数学系(Department of Mathematics)与统计系(Statistics)是分开的两个院系,虽然学生可以互相之间选择对方的课程,但是两者却是分属不同的院系。
当年笔者在博士期间的研究方向是“复平面上多项式的 Julia 集合正测度”(PS:估计不是相关方向的人都不太读得懂这个题目的意思)。首先要知道复平面,其次要知道 Julia 集合,再次要知道正测度是什么意思。即使这些名词和概念都知道了,也不足以撬动这个题目。要想解决这个题目,除了导师的必要指导之外,还要自行去查阅各种论文资料来详细阅读。记得当年读过好几篇三五十页的 Annals of Mathematics(数学年刊)的论文,还读过一篇上百页的预印稿(关键是这篇论文有一个核心步骤还是错误的)。在此情况下,导师也只能够给博士生圈定一个论文的范围,告诉学生可以去参考其中的思路和方法,至于学生能不能够读懂这些文献,是导师无法保证的。而纯数学论文与其他专业最明显的不同就是满篇都是数学公式的推导,有很多地方充斥着“显然”,“易得”,“显而易见”诸多词汇。有一种情况是写论文的作者没有想明白,然后糊弄了一把;另外一种情况是这个地方真的是显而易见的,只是读者没有明白。纯数学论文的其中一页读上一两天并不是一件罕见的事情,一篇论文读一个学期能读明白也算完成了一件还不错的任务。PS:数学系有的教材就可以让学生一页读上好几天,例如 GTM 52。某些专业做不出来实验还可以把原因归结为材料不足,经费不足,设备不够,但是纯数学专业看不懂论文只能够把绝大部分原因归结为自己,因为草稿纸,笔,打印机,网络都是买得起的,客观上并不存在任何阻碍。
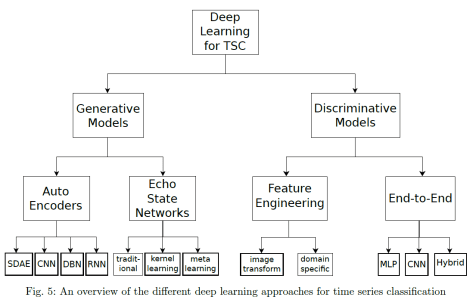
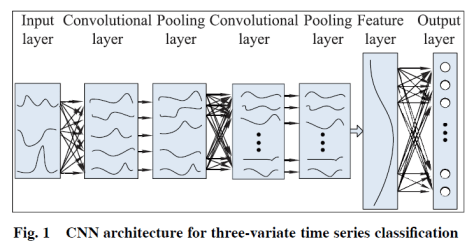
而做时间序列分类的深度学习算法分成生成式(Generative)和判别式(Discriminative)两种方法。在生成式里面包括 Auto Encoder 和 Echo State Networks 等算法,在判别式里面,包括时间序列的特征工程和各种有监督算法,还有端到端的深度学习方法。在端到端的深度学习方法里面,包括前馈神经网络,卷积神经网络,或者其余混合模型等常见算法。
深度学习算法在时间序列分类中的应用:Baseline
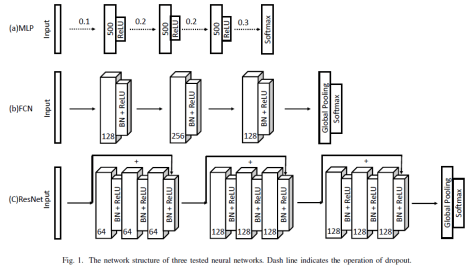
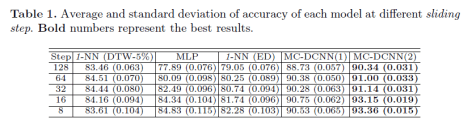
这一部分将会介绍用神经网络算法来做时间序列分类的 Baseline,其中包括三种算法,分别是多层感知机(MLP),FCN(Fully Convolutional Network)和 ResNet。其论文的全名是《Time Series Classification from Scratch with Deep Neural Networks: A Strong Baseline》。这篇论文中使用的神经网络框架如下图所示:
Mean Per Class Error (in Multi-class Classification only) is the average of the errors of each class in your multi-class data set. This metric speaks toward misclassification of the data across the classes. The lower this metric, the better.
模型的评价指标使用的是 Mean Per-Class Error,指的是在多分类场景下,每一类(Class)错误率的平均值。换句话说,一个数据集 是由 个类的元素构成的,每个类的标签是 ,通过模型其实可以计算出模型对每一个类的错误率 ,那么模型的 MPCE 就是:.
其实验结论是:
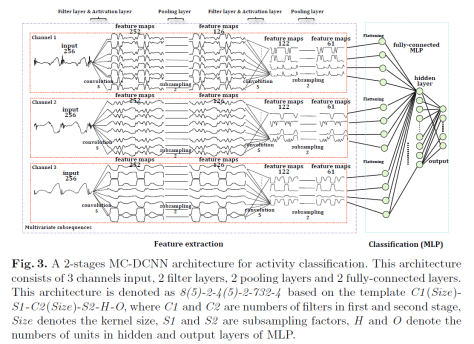
MSCNN
MSCNN 的全称是 Multi-Scale Convolutional Neural Networks,相应的论文是《Multi-Scale Convolutional Neural Networks for Time Series Classification》。
除了 GSAF 和 GSDF 之外,《Imaging Time Series to Improve Classification and Imputation》,《Encoding Time Series as Images for Visual Inspection and Classification Using Tiled Convolutional Neural Networks》,《Encoding Temporal Markov Dynamics in Graph for Time Series Visualization》也提到了把时间序列转换成矩阵 Image 的算法 MTF。在 pyts 开源工具库里面,也提到了 MTF 算法的源码。
Wang Z, Yan W, Oates T. Time series classification from scratch with deep neural networks: A strong baseline[C]//2017 international joint conference on neural networks (IJCNN). IEEE, 2017: 1578-1585.
Cui Z, Chen W, Chen Y. Multi-scale convolutional neural networks for time series classification[J]. arXiv preprint arXiv:1603.06995, 2016.
Wang Z, Oates T. Imaging time-series to improve classification and imputation[C]//Twenty-Fourth International Joint Conference on Artificial Intelligence. 2015.
Wang Z, Oates T. Encoding time series as images for visual inspection and classification using tiled convolutional neural networks[C]//Workshops at the Twenty-Ninth AAAI Conference on Artificial Intelligence. 2015.
Liu L. Encoding Temporal Markov Dynamics in Graph for Time Series Visualization, Arxiv, 2016.
Fawaz H I, Forestier G, Weber J, et al. Deep learning for time series classification: a review[J]. Data Mining and Knowledge Discovery, 2019, 33(4): 917-963.
Zhao B, Lu H, Chen S, et al. Convolutional neural networks for time series classification[J]. Journal of Systems Engineering and Electronics, 2017, 28(1): 162-169.
Le Guennec A, Malinowski S, Tavenard R. Data augmentation for time series classification using convolutional neural networks[C]. 2016.
对于在校学生而言,通常来说都是 Python 跑完模型,然后得到一个模型文件,用它继续离线预测就可以得到最终的结果。但是在工业界,很多机器学习项目都需要进行上线的工作。这种时候只靠一个机器学习人员的战斗力是无法解决问题的,不可避免地需要有开发人力的介入。此时 Jett 发挥了作为一位开发人员的强大战斗力,一个人就能把线上的代码全部完成,没有让我撰写任何一行 C++ 的代码。在码农界有一种“结伴编程”的说法,也就是两个人共同搞一份代码,共同搞一个项目。我是负责数据处理和离线模块,Jett 是负责平台开发。有一次在核对数据的时候,把 Python 的预测结果和 C++ 的预测结果进行核对。也就是为了交流方便,那次我把 Mac Air 搬到了 Jett 的桌子上,两个人并排坐在一起,一起核对数据的准确性和可靠性。
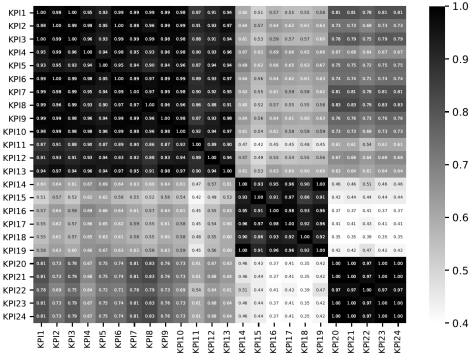
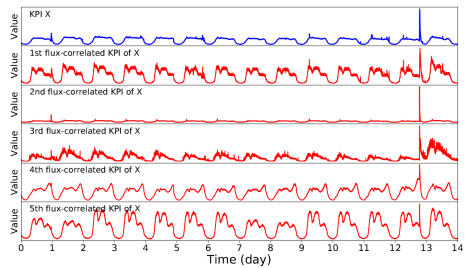
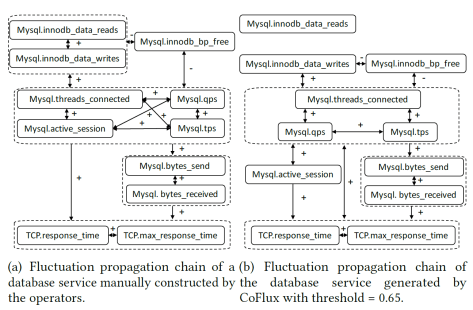
在互联网公司里面,通常都会监控成千上万的时间序列,用于保障整个系统或者平台的稳定性。在这种情况下,如果能够对多条时间序列之间判断其是否相关,则对于监控而言是非常有效的。基于以上的实际情况,清华大学与 Alibaba 集团在2019年一起合作了论文《CoFlux: Robustly Correlating KPIs by Fluctuations for Service Troubleshooting》,并且发表在 IWQos 2019 上。CoFlux 这个方法可以对多条时间序列来做分析,并且主要用途包括以下几点:
从课表上面来看,基本上可以确定几个结论。首先,数学专业作为基础学科,其特点就是理论知识偏多,而学习到的技能偏少,毕竟所学的内容都是理论型,培养的学生都是理论型选手。因此直接导致的结果就是数学系的学生掌握了一堆理论,但是却没有办法把它们直接转化成生产力。在实战中,总不能就靠一门 C++ 来谋求工作吧。其次,既然数学系传授给学生的实用的技能偏少,那么数学系的学生在需要转行的话,就肯定要补充新的技能。在从理论派走向实战派的过程中,不仅要找好自己的前进方向,还需要花费一定的时间和精力去转行。在这里需要澄清一点,转行并不是轻轻松松,而是需要花费时间,勇气和精力的。
当年笔者还在南京大学本科读数学专业的时候,就见到大神 Terence Tao 建立了个人的网站:What’s new(terrytao.wordpress.com),并且后续数十年如一日的更新个人 Blog。在他的 Blog 上面,除了常见的数学基础知识和课程安排之外,更多的是当前数学界的一些新发展和新方向。由于数学系的博文或者论文除了文字之外,更多的是各种各样的数学公式,而这些数学公式使用公式编辑器一类的东西来处理是极其繁琐的,只能够使用 LaTex 等工具来写。恰好的是,WordPress 除了能够支持日常的文本编辑之外,还能够使用 LaTex 来对数学公式进行撰写,也就是说用户只需要在编辑框内写 LaTex,就能够编译成数学公式。因此,WordPress 对数学公式的支持是相对友好的,这对数学系爱好写数学博客的学生,工作人士提供了非常便利的条件。
除了整理数学公式比较容易之外,WordPress 上面还可以相对方便的选择各种各样的主题,这样的话刚注册的新用户也可以较为容易的上路,不用一开始就陷入编辑网站等一些繁琐的事情上面。同时,WordPress 上也有各种各样的小工具,包括日历(可以查看发表 Blog 的时间),文章的目录,比较受欢迎的文章或页面,文章的类别等内容。用户可以根据自己的爱好自行选择栏目,从而可以轻易地搭建出一个个人网站。另外,WordPress 可以统计出 Blog 的点击数量,包括每天,每周,每月,每年的具体点击数量。
第一次使用 WordPress(zr9558.com)正好是攻读博士学位一年,除了日常的科研工作之外,也打算写点东西来记录一下自己的成长。后续读博士期间也逐渐的写了一些数学方面的文章,不过后续回想起来其实应该在读本科的时候就开始写 Blog。如果这样的话,当年所学过的各种数学知识,整理过的各种资料都会更加清晰一些,也更加容易保存一些。毕竟写 Blog 的一个重要目的是给自己回顾用的,看看这段时间自己的积累是什么,自己学到了什么知识,相比去年成长了多少。其实,有的时候偶尔去浏览一下 Terence Tao 的博客,虽然也看不懂,但是可以明显地感受到“大神”的努力程度。牛人尚且如此努力,我等凡人有什么理由不努力呢。
后面进入公司之后,有的时候工作繁忙,整理 Blog 的时间就会减少许多。但是一份工作除了能够给人带来必要的薪资之外,更重要的是给自己不停地积攒经验。无论是现在还是将来都可以让自己在职场中更加值钱。因此,除了日常的搬砖工作之外,也要时刻注意自己的成长和经验的积累。而搬砖的经验会随着项目的结束和时间的迁移在记忆中逐渐淡忘而去,于是,适当的记录就成为了必要的工作。俗话说得好,“好记性不如烂笔头”。因此,隔一段时间(通常来说可以设定为一到两个月的时长)就整理一下经验就显得尤为重要,也是提升个人技术和经验的方法之一。但是在整理 Blog 的时候,一定要注意 Blog 的质量,只有不断地提炼自己 Blog 里面的内容才能够保证文章的质量。
不过现在的 Blog 远没有当年受欢迎,在各种各样 APP 横行的时代,已经比较少有人主动去看别人的 Blog 了。不过在使用搜索引擎来搜索某些关键字的时候,有的时候还是能够看到一些高质量的 Blog。在学习这些 Blog 的同时,其实也可以互相比较一下,取长补短才能够使自己的博客越做越好。其实,无论有没有人读自己所写的内容,都要坚持写下去,因为:
除此之外,我们也可以用 Auto Encoder 等自编码器技术对时间序列进行特征的编码,也就是说该自编码器的输入层和输出层是恒等的,中间层的神经元个数少于输入层和输出层。在这种情况下,是可以做到对时间序列进行特征的压缩和构造的。除了 Auto Encoder 等无监督方法之外,如果使用其他有监督的神经网络结构的话,例如前馈神经网络,循环神经网络,卷积神经网络等网络结构,可以把归一化之后的时间序列当做输入层,输出层就是时间序列的各种标签,无论是该时间序列的形状种类还是时间序列的异常/正常标签。当该神经网络训练好了之后,中间层的输出都可以作为 Time Series To Vector 的一种模式。i.e. 也就是把时间序列压缩成一个更短一点的向量,然后基于 COSINE 相似度等方法来计算原始时间序列的相似度。参考文章:基于自编码器的时间序列异常检测算法,基于前馈神经网络的时间序列异常检测算法。
从深度学习的基础知识可以得到,CNN 的中间层可以用来提取图片的特征,因此,这里的前馈神经网络的隐藏层的输出同样可以作为时间序列的特征层。于是,我们通过实验,基于隐藏层的输出可以作为时间序列的隐藏特征,也就是所谓的 Time Series To Vector。通过 Time Series To Vector,我们可以既可以对时间序列进行聚类(KMeans),也可以对时间序列进行 Cosine 相似度的计算,进而得到同一类时间序列和相似的时间序列。
论文的主要结论
从本文的主要定理和实验效果来看,前馈神经网络是一个非常有效地可以用作时间序列异常检测的工具。本篇论文不仅提供了一个端到端的训练方法,并且不需要对时间序列进行特征工程的操作。从实验数据来看,使用前馈神经网络(feedforward neural network)可以得到与 XGBoost 差不多的效果。并且,前馈神经网络隐藏层的输出可以作为时间序列的隐藏特征(Time Series To Vector),使用 Cosine 相似度或者 KMeans 算法就可以对时间序列进行相似度的计算和聚类操作。在时间序列异常检测领域,使用特征工程 + 有监督算法的方法论比较多,而使用端到端的训练方法,也就是前馈神经网络的方法应该还是相对较少的。因此,端到端的前馈神经网络算法应该是本文的方法与其他方法论的最大不同点。
如果针对机器学习领域的话,就公司或者学术界的一些情况来看,其实机器学习领域的应用范围十分广泛。最经典的当然属于广告推荐和个性化推荐这一块,无论是今日头条,抖音,还是各个 APP,其实都包含了推荐系统,无论这个推荐系统是通过规则的形式做出来的,通过逻辑回归的方法做出来的,还是通过深度学习做出来的,都是可以在点击率和利润等方向上获得收益的。除了推荐系统之外,游戏 AI 也是一个不错的研究方向,几年前强化学习这个方向也是不温不火,但是在 AlphaGo 崛起之后,深度学习和强化学习就已经开始进入了大多数人的视野。随着围棋被攻克之后,德州扑克AI,或者其他的游戏 AI 也被很多学者和大型游戏公司所关注。DeepMind 也在 2017 年开放了星际争霸的研究平台,今年无论是在 Dota2 还是星际争霸上,游戏 AI 相比之前都有了巨大的突破。因此,如何在诸多业务线中,选择一个适合自己的研究方向,才是比较关键的问题。是选择一个成熟的领域努力奋斗,还是选择一个新兴领域开疆拓土,都是需要自己去考虑的。
与之截然不同的是 AI 领域(Machine Learning, CV, NLP, 语音等),一般来说只需要学习微积分/线性代数/概率论就可以基本上看懂机器学习的相关课程,当然要想深入学习 AI 的话还是需要很多数学基础的。随着科技的发展,各种开源工具的层出不穷,很多学校的学生甚至工业界的人士都已经不需要从底层从头开始,一步一步地建立自己的工具库。根据各种丰富的文档和 Blog,不少人都可以快速上手各种 AI 的工作内容,无论是使用 Tensorflow 建立图像分类器,还是使用 XGBoost 刷竞赛的成绩。这种时候,从事 AI 相关工作的门槛将会比之前变得越来越低,毕竟从头开始手动写一个 BP 算法或者说 GBDT 算法还是有一定门槛的。
如果现在有十个岗位,但是只有五个 AI 专业的人来应聘,当然这些人都能够找到工作;但是随着人工智能专业的开设,相关的本科生和研究生开始培养,AI 从业者将会变得越来越多,但是岗位是否能够得到相应的增加就不是特别清楚了。就之前的经验而言,数学系的学生之间在毕业的时候差距还是挺大的,有的很强,有的很差。相信在人工智能专业也会有类似的情况,优秀的学生总是占少数。
就笔者的经验实在是无法确定这一波 AI 浪潮能够持续多久,如果五六年之后这波浪潮还在,蛋糕越来越大,那么现在选择攻读 AI 相关专业的人将会是受益者。但是如果这波浪潮不在了,蛋糕保持稳定甚至缩小的时候,AI 相关专业的人的竞争将会变得更加激烈。无论是工业界还是学术界的竞争,将会比现在的情况变大很多倍。而这波浪潮退去之后,能够留在沙滩上继续前进的永远都是少数人。

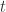
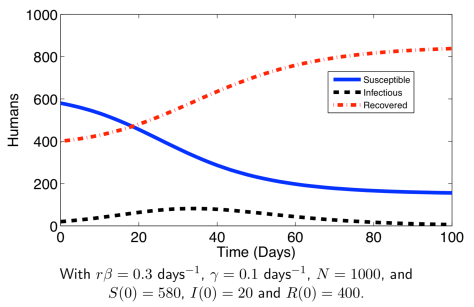
来表示;
来表示;
来表示;

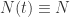
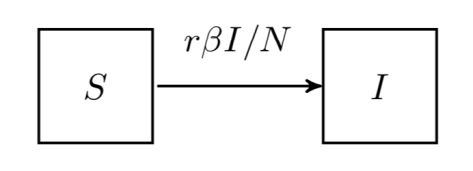
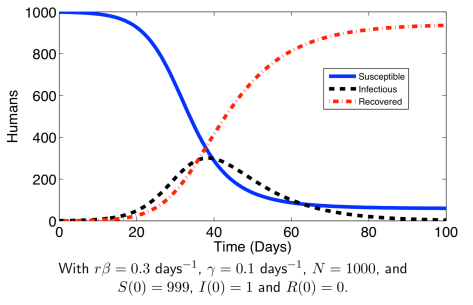
表示在单位时间内感染者接触到的易感者人数;
表示感染者接触到易感者之后,易感者得病的概率;
表示感染者康复的概率,有可能变成易感者(可再感染),也有可能变成康复者(不再感染)。
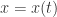


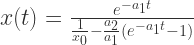

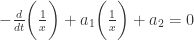


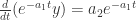

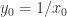




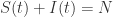


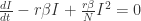





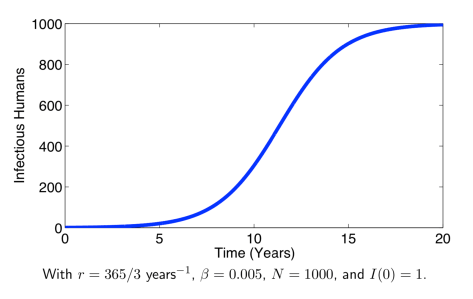
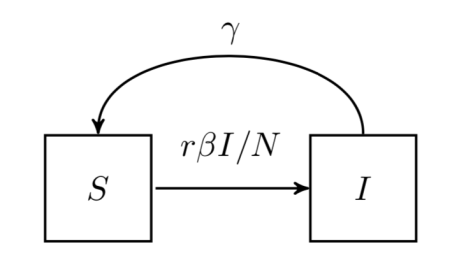
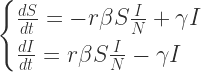



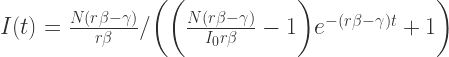
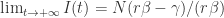

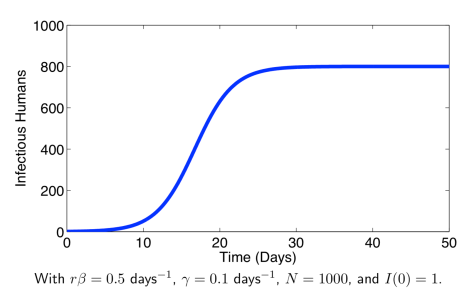
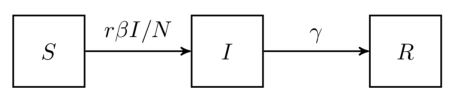



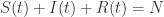
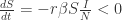
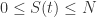
![S_{\infty}\in[0,\infty]](https://s0.wp.com/latex.php?latex=S_%7B%5Cinfty%7D%5Cin%5B0%2C%5Cinfty%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)

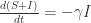

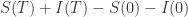
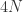






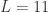 表示叶子节点的值只有 11 个,分别是变量
表示叶子节点的值只有 11 个,分别是变量  和
和  ;
; 表示一元计算只有 15 个,分别是
表示一元计算只有 15 个,分别是  ,
, 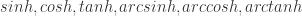 。
。 表示二元计算只有四个,分别是 +, -, *, /;
表示二元计算只有四个,分别是 +, -, *, /; 的表达式就可以作为深度学习的积分训练数据。生成积分的话其实有多种方法:
的表达式就可以作为深度学习的积分训练数据。生成积分的话其实有多种方法: ,然后使用 SymPy 或者 Mathematica 等工具来计算函数
,然后使用 SymPy 或者 Mathematica 等工具来计算函数 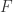 ,那么
,那么  就可以作为一个训练集。当然,有的时候函数
就可以作为一个训练集。当然,有的时候函数  ,于是
,于是  ,那么
,那么 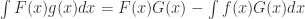 。对于两个随机生成的函数
。对于两个随机生成的函数 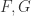 ,可以计算出它们的导数
,可以计算出它们的导数 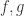 。如果
。如果 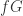 在训练集合里面,那么就把
在训练集合里面,那么就把  的积分计算出来放入训练集合;反之,如果
的积分计算出来放入训练集合;反之,如果 
 选择一个,于是随机把其中的一个整数换成变量
选择一个,于是随机把其中的一个整数换成变量  。例如:在
。例如:在  中就把 2 换成 c,于是得到了一个二元函数
中就把 2 换成 c,于是得到了一个二元函数  。那么就执行以下步骤:
。那么就执行以下步骤: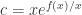 ;
;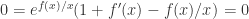 ;
;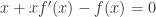 ,也就是
,也就是 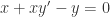 。
。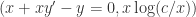 。
。 ;
; 得到
得到  ;
; ;
; 得到
得到  ;
; ;
; ,也就是
,也就是 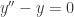 。
。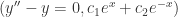 。
。 的表达式,该数据就需要放弃,重新生成新的数据。
的表达式,该数据就需要放弃,重新生成新的数据。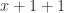 可以简化成
可以简化成 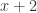 ,
, 可以简化成 1。
可以简化成 1。 可以简化成
可以简化成 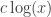 。
。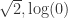 等。
等。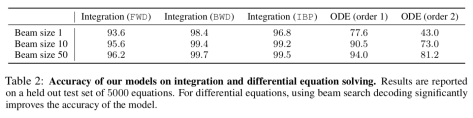




 。
。 是用以下符号来表示的:其中 sympy.exp() 表示以
是用以下符号来表示的:其中 sympy.exp() 表示以  为底的函数。
为底的函数。 的小数值,可以使用 evalf() 函数,其中 evalf() 函数里面的值表示有效数字的位数。例如下面就是精确到 10 位有效数字。当然,也可以不输入。
的小数值,可以使用 evalf() 函数,其中 evalf() 函数里面的值表示有效数字的位数。例如下面就是精确到 10 位有效数字。当然,也可以不输入。 和
和  。
。 ,其中
,其中 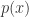 和
和  都是多项式。一般情况下,我们希望对有理函数进行简化,合并或者分解的数学计算。
都是多项式。一般情况下,我们希望对有理函数进行简化,合并或者分解的数学计算。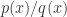 并且去除公因子,那么可以使用 cancel 函数。另一个类似的就是 together 函数,但是不同之处在于 cancel 会消除公因子,together 不会消除公因子。例如:
并且去除公因子,那么可以使用 cancel 函数。另一个类似的就是 together 函数,但是不同之处在于 cancel 会消除公因子,together 不会消除公因子。例如: ,
,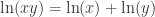 ,
,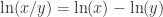 。
。 出发,来介绍 SymPy 的各种函数使用方法。如果想进行变量替换,例如把
出发,来介绍 SymPy 的各种函数使用方法。如果想进行变量替换,例如把 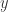 ,那么可以使用 substitution 方法。除此之外,有的时候也希望能够得到函数
,那么可以使用 substitution 方法。除此之外,有的时候也希望能够得到函数  ,那么可以把参数换成 1 即可得到函数的取值。例如,
,那么可以把参数换成 1 即可得到函数的取值。例如, 阶导数也可以用这个函数算。
阶导数也可以用这个函数算。 ,
, 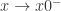 ,
,  。
。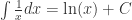 ,
, 。
。 这个概念了,但是在 SymPy 里面的写法还是一样的。
这个概念了,但是在 SymPy 里面的写法还是一样的。 ,
,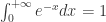 ,
,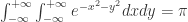 。
。 ,
,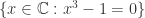 ,
, ,
,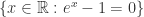 ,
, 。
。
 ,
, ,
, ,
, ,第二个矩阵表示
,第二个矩阵表示 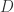 ,
, 。
。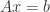 的解,可以有以下方案:
的解,可以有以下方案:![I=[0,1]](https://s0.wp.com/latex.php?latex=I%3D%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和开区间
和开区间  而言,在 SymPy 中使用以下方法来表示:
而言,在 SymPy 中使用以下方法来表示: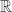 在 SymPy 中用 sympy.S.Reals 来表示,自然数使用 sympy.S.Naturals,非负整数用 sympy.S.Naturals0,整数用 sympy.S.Integers 来表示。补集的计算可以用减号,也可以使用 complement 函数。
在 SymPy 中用 sympy.S.Reals 来表示,自然数使用 sympy.S.Naturals,非负整数用 sympy.S.Naturals0,整数用 sympy.S.Integers 来表示。补集的计算可以用减号,也可以使用 complement 函数。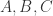 来代表元素。&, |, ~, >> 分别表示 AND,OR,NOT,imply。而逻辑运算同样可以使用 sympy.simplify_logic 简化。
来代表元素。&, |, ~, >> 分别表示 AND,OR,NOT,imply。而逻辑运算同样可以使用 sympy.simplify_logic 简化。 ,
, 。
。 ,
, 。
。 ,
, ,
, ,
, 是一个二元函数,分别满足以下偏微分方程:
是一个二元函数,分别满足以下偏微分方程: ,
, ,
, 。
。














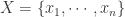

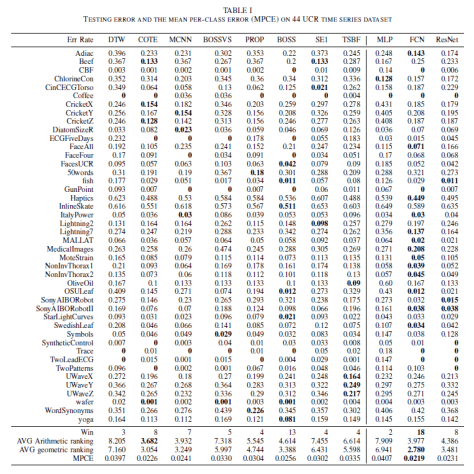
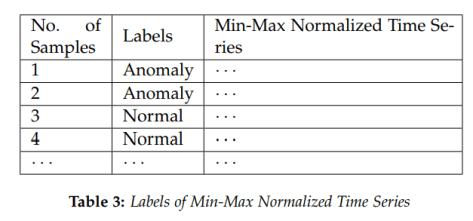
 个不同的单维时间序列而组成的,对于每一个
个不同的单维时间序列而组成的,对于每一个  而言,时间序列
而言,时间序列  的长度都是
的长度都是 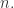 而时间序列的分类数据通常来说都是这种格式:数据集
而时间序列的分类数据通常来说都是这种格式:数据集
 是 one hot 编码,长度为
是 one hot 编码,长度为 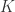 (表示有
(表示有 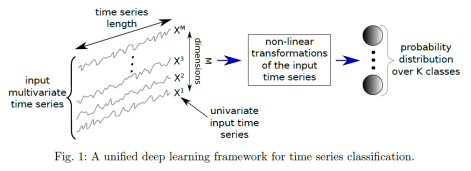
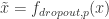 ,
, ,
, .
. ,
, ,
, ,
, 指的是卷积算子,BN 指的是 Batch Normalization,ReLU 则是激活函数。
指的是卷积算子,BN 指的是 Batch Normalization,ReLU 则是激活函数。 来表示第
来表示第  个卷积块,而 Residual 块就定义为:
个卷积块,而 Residual 块就定义为: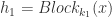 ,
,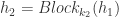 ,
, ,
,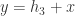 ,
, .
.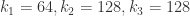 。
。
 是由
是由  ,通过模型其实可以计算出模型对每一个类的错误率
,通过模型其实可以计算出模型对每一个类的错误率 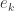 ,那么模型的 MPCE 就是:
,那么模型的 MPCE 就是: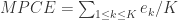 .
.
 ,其中
,其中  表示在时间戳
表示在时间戳  下的取值,并且时间序列
下的取值,并且时间序列  的长度是
的长度是  。其中
。其中 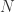 条时间序列,每条时间序列
条时间序列,每条时间序列 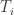 对应着一个标签
对应着一个标签 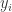 。
。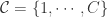 中的元素,
中的元素, 。
。
 ,
, 表示窗口长度。对于不同的窗口长度
表示窗口长度。对于不同的窗口长度 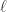 ,我们可以的到不同的时间序列平滑序列,但是它们的长度都是一样的,都是原始的时间序列长度
,我们可以的到不同的时间序列平滑序列,但是它们的长度都是一样的,都是原始的时间序列长度 ![T^{k} = \{t_{1+k\cdot i}\}, 0\leq i \leq [(n-1)/k]](https://s0.wp.com/latex.php?latex=T%5E%7Bk%7D+%3D+%5C%7Bt_%7B1%2Bk%5Ccdot+i%7D%5C%7D%2C+0%5Cleq+i+%5Cleq+%5B%28n-1%29%2Fk%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) .
. 来进行下采样的时间序列提取。在进行了恒等变换,平滑变换,下采样之后,时间序列就可以变成多种形式,作为神经网络的输入。
来进行下采样的时间序列提取。在进行了恒等变换,平滑变换,下采样之后,时间序列就可以变成多种形式,作为神经网络的输入。 ,
, ,可以生成
,可以生成  个子序列如下所示:
个子序列如下所示: ,
,
 ,长度是
,长度是 ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 或者
或者 ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) :
: ,
, ,
,![\tilde{x}_{0}^{i}\in[0,1], \forall 1\leq i\leq n](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7B0%7D%5E%7Bi%7D%5Cin%5B0%2C1%5D%2C+%5Cforall+1%5Cleq+i%5Cleq+n&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,![\tilde{x}_{-1}^{i} \in [-1,1],\forall 1\leq i\leq n](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7B-1%7D%5E%7Bi%7D+%5Cin+%5B-1%2C1%5D%2C%5Cforall+1%5Cleq+i%5Cleq+n&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。于是可以使用三角函数来代替归一化之后的值。下面通用
。于是可以使用三角函数来代替归一化之后的值。下面通用  来表示归一化之后的时间序列,令
来表示归一化之后的时间序列,令 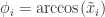 ,
,![\tilde{x}_{i} \in [-1,1]](https://s0.wp.com/latex.php?latex=%5Ctilde%7Bx%7D_%7Bi%7D+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,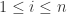 。因此,
。因此,![\phi_{i}\in[0,\pi]](https://s0.wp.com/latex.php?latex=%5Cphi_%7Bi%7D%5Cin%5B0%2C%5Cpi%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,于是,
,于是,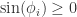 。
。![GASF = [\cos(\phi_{i}+\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=GASF+%3D+%5B%5Ccos%28%5Cphi_%7Bi%7D%2B%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![GASF = [\cos(\phi_{i})\cdot \cos(\phi_{j}) - \sin(\phi_{i})\cdot \sin(\phi_{j})]_{n\times n}](https://s0.wp.com/latex.php?latex=GASF+%3D+%5B%5Ccos%28%5Cphi_%7Bi%7D%29%5Ccdot+%5Ccos%28%5Cphi_%7Bj%7D%29+-+%5Csin%28%5Cphi_%7Bi%7D%29%5Ccdot+%5Csin%28%5Cphi_%7Bj%7D%29%5D_%7Bn%5Ctimes+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 ,可以得到
,可以得到
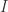 表示单位矩阵。它的对角矩阵是
表示单位矩阵。它的对角矩阵是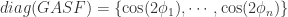

 ,可以得到
,可以得到  。
。![GADF = [\sin(\phi_{i}-\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=GADF+%3D+%5B%5Csin%28%5Cphi_%7Bi%7D-%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![= [\sin(\phi_{i})\cdot cos(\phi_{j}) - \cos(\phi_{i})\cdot\sin(\phi_{j})]_{1\leq i,j\leq n}](https://s0.wp.com/latex.php?latex=%3D+%5B%5Csin%28%5Cphi_%7Bi%7D%29%5Ccdot+cos%28%5Cphi_%7Bj%7D%29+-+%5Ccos%28%5Cphi_%7Bi%7D%29%5Ccdot%5Csin%28%5Cphi_%7Bj%7D%29%5D_%7B1%5Cleq+i%2Cj%5Cleq+n%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
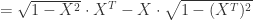 .
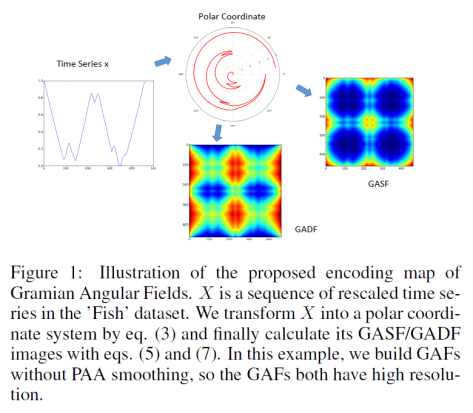
.
 ,我们把它们的值域分成
,我们把它们的值域分成  个桶,那么每一个
个桶,那么每一个  都可以被映射到一个相应的
都可以被映射到一个相应的  上。于是我们可以建立一个
上。于是我们可以建立一个  的矩阵
的矩阵  ,
, 表示在桶
表示在桶  中的元素被在桶
中的元素被在桶  ,同时,它也满足
,同时,它也满足  。于是,得到矩阵
。于是,得到矩阵  。
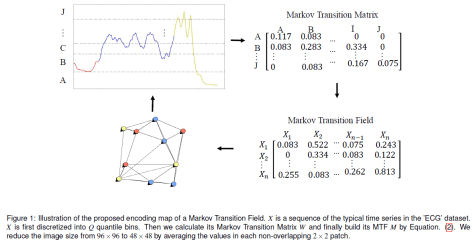
。
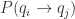 ,同样有
,同样有  。因此,我们同样可以构造出一个
。因此,我们同样可以构造出一个 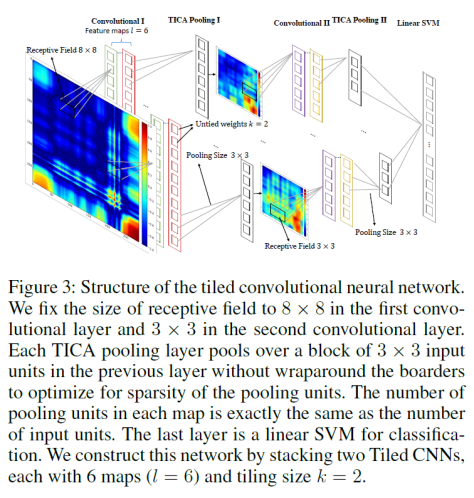
 就作为数据点
就作为数据点 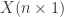 就可以变成特征矩阵
就可以变成特征矩阵  。对于特征矩阵
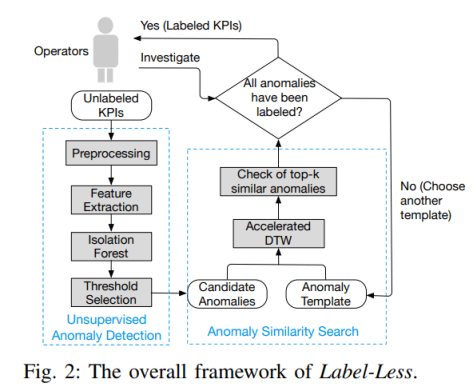
。对于特征矩阵 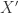 可以使用 isolation forest 来做无监督的异常检测并且做阈值的设定;如下图所示:
可以使用 isolation forest 来做无监督的异常检测并且做阈值的设定;如下图所示: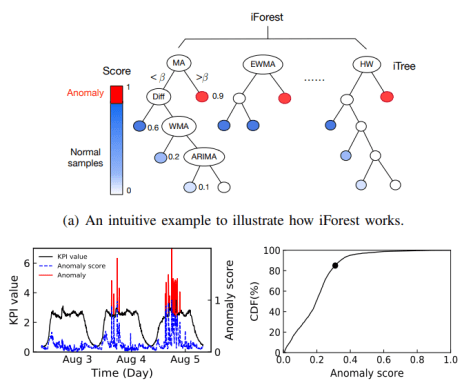
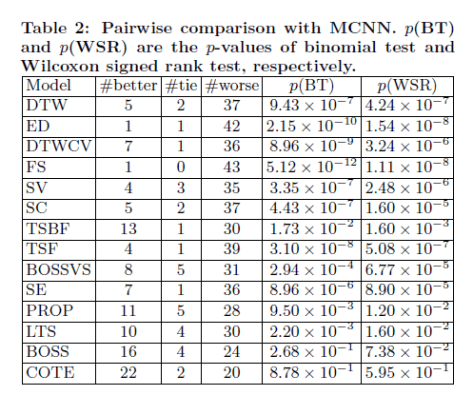
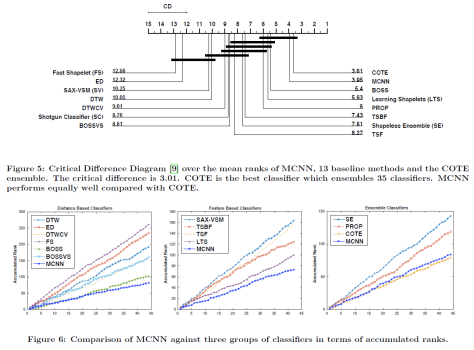
 和
和  ,因此在搜索的时候需要必要的加速工作。在这种地方,作者们使用了 LB-Kim,LB-Keogh,LB-Keogh-Reverse 算法来做搜索的加速工作。而这些的时间复杂度是
,因此在搜索的时候需要必要的加速工作。在这种地方,作者们使用了 LB-Kim,LB-Keogh,LB-Keogh-Reverse 算法来做搜索的加速工作。而这些的时间复杂度是  。整体的思路是,如果两条时间序列
。整体的思路是,如果两条时间序列 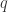 和
和 

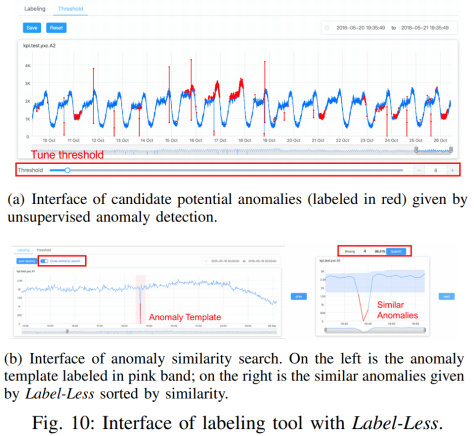
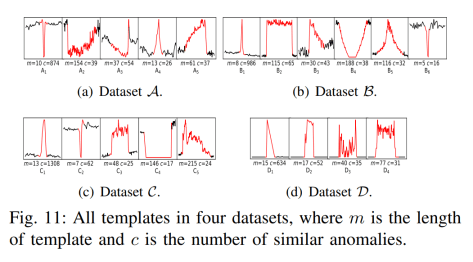













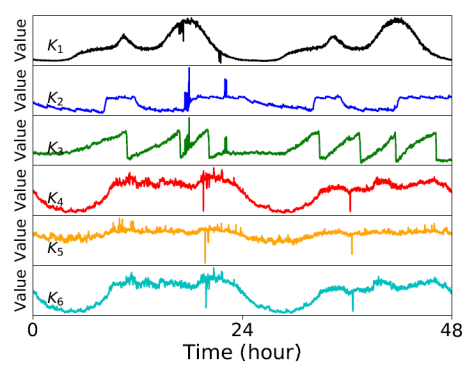
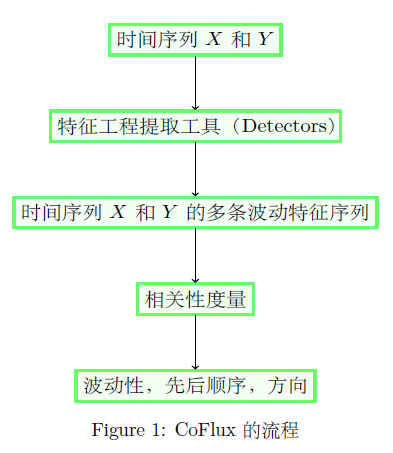
 和
和 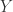 存在波动相关性,则需要输出这两条时间序列的波动先后顺序和是否同向波动。如果两条时间序列
存在波动相关性,则需要输出这两条时间序列的波动先后顺序和是否同向波动。如果两条时间序列 
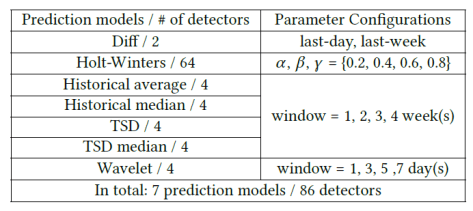
 ,对于任意一个 detector,可以得到一条关于
,对于任意一个 detector,可以得到一条关于 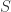 的预测值曲线
的预测值曲线  。于是针对某个 detector 可以得到一个波动特征序列
。于是针对某个 detector 可以得到一个波动特征序列 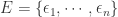 ,其中
,其中  ,
, ;
;
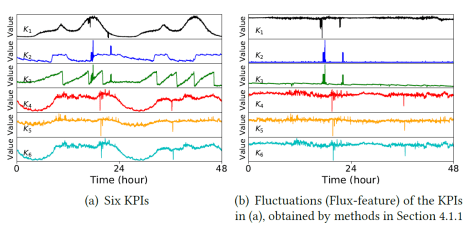


 如下:
如下: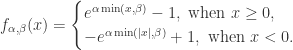

 和
和  ,可以计算它们之间的相关性,先后顺序,是否同向。
,可以计算它们之间的相关性,先后顺序,是否同向。
 个。其中,
个。其中, 。特别地,当
。特别地,当 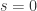 时,
时, ,那么我们可以定义
,那么我们可以定义  与
与 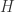 的内积是:
的内积是: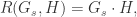
 指的是向量之间的内积(inner product)。同时可以定义相关性(Cross Correlation)为:
指的是向量之间的内积(inner product)。同时可以定义相关性(Cross Correlation)为: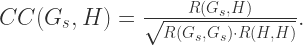



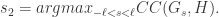

 是一个元组,里面蕴含着三个信息,分别是相关性,波动方向,前后顺序。
是一个元组,里面蕴含着三个信息,分别是相关性,波动方向,前后顺序。![FCC(G,H) \in [-1,1]](https://s0.wp.com/latex.php?latex=FCC%28G%2CH%29+%5Cin+%5B-1%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,越接近 1 或者 -1 就表示放大之后的波动特征曲线
,越接近 1 或者 -1 就表示放大之后的波动特征曲线  和
和 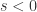 或者
或者 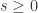 的分析就可以判断先后顺序。因此,CoFlux 方法的是通过对
的分析就可以判断先后顺序。因此,CoFlux 方法的是通过对 
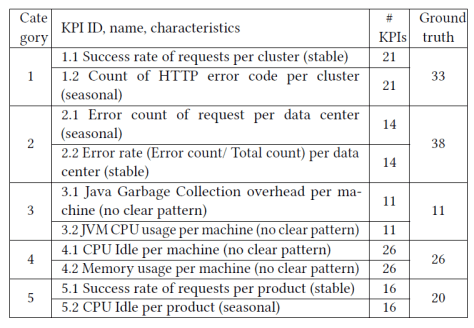
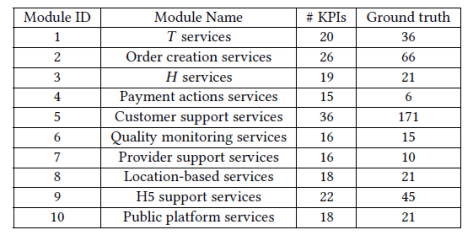
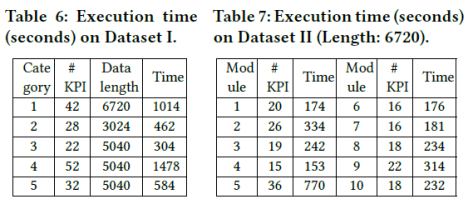
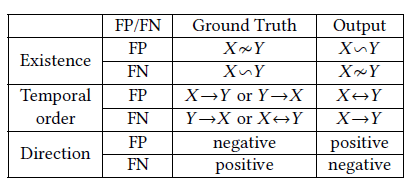
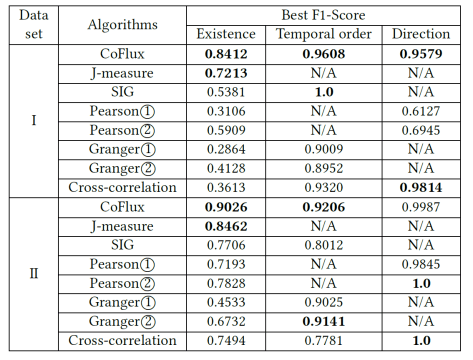






























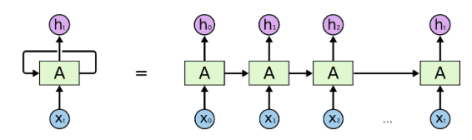
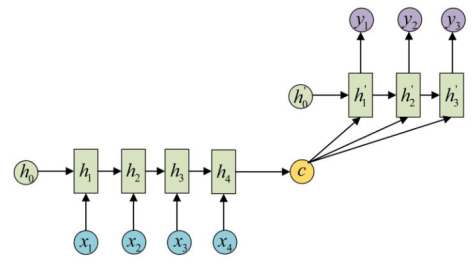
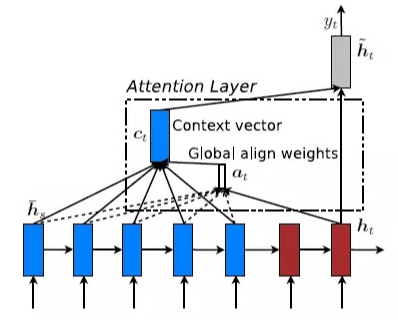
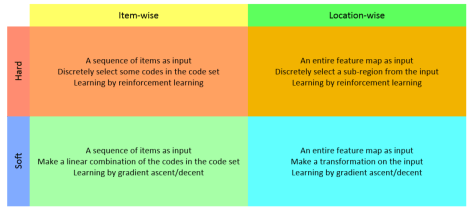
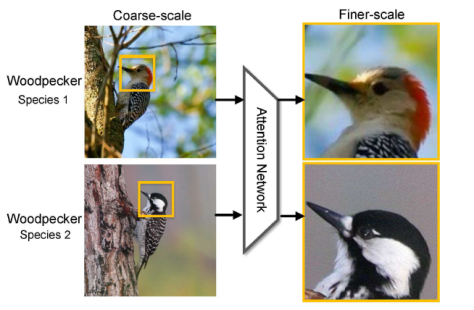
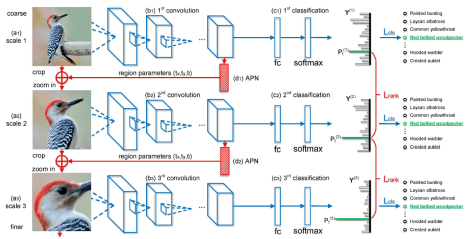

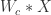 ,这里的
,这里的  指的是卷积等各种各样的操作。所以得到的概率分布情况其实就是
指的是卷积等各种各样的操作。所以得到的概率分布情况其实就是  ,
, 和尺寸大小
和尺寸大小  ,其中
,其中 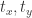 分别指的是横纵坐标,正方形的边长其实是
分别指的是横纵坐标,正方形的边长其实是  。用数学公式来记录这个流程就是
。用数学公式来记录这个流程就是 ![[t_{x}, t_{y}, t_{\ell}] = g(W_{c}*X)](https://s0.wp.com/latex.php?latex=%5Bt_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%5D+%3D+g%28W_%7Bc%7D%2AX%29&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。在坐标值的基础上,我们可以得到以下四个值,分别表示
。在坐标值的基础上,我们可以得到以下四个值,分别表示 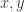 两个坐标轴的上下界:
两个坐标轴的上下界:

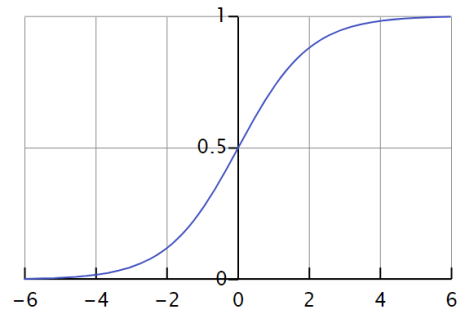
 而言,当
而言,当 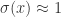 当
当 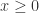 ;
; 当
当 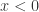 。此时的逻辑回归函数近似于一个阶梯函数。如果假设
。此时的逻辑回归函数近似于一个阶梯函数。如果假设  ,那么
,那么 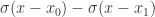 就是光滑一点的阶梯函数,
就是光滑一点的阶梯函数, 当
当  ;
; 当
当  。
。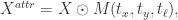 其中,
其中, 表示图片需要关注的区域,
表示图片需要关注的区域, 函数就是
函数就是 ![M(t_{x}, t_{y}, t_{\ell}) = [\sigma(x-t_{x(t\ell)}) - \sigma(x-t_{x(br)})]\cdot[\sigma(y-t_{y(t\ell)}) - \sigma(y-t_{y(br)})],](https://s0.wp.com/latex.php?latex=M%28t_%7Bx%7D%2C+t_%7By%7D%2C+t_%7B%5Cell%7D%29+%3D+%5B%5Csigma%28x-t_%7Bx%28t%5Cell%29%7D%29+-+%5Csigma%28x-t_%7Bx%28br%29%7D%29%5D%5Ccdot%5B%5Csigma%28y-t_%7By%28t%5Cell%29%7D%29+-+%5Csigma%28y-t_%7By%28br%29%7D%29%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这里的
这里的 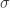 函数对应了一个足够大的
函数对应了一个足够大的 
![m = [i/\lambda] + \alpha, n = [j/\lambda] + \beta](https://s0.wp.com/latex.php?latex=m+%3D+%5Bi%2F%5Clambda%5D+%2B+%5Calpha%2C+n+%3D+%5Bj%2F%5Clambda%5D+%2B+%5Cbeta&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,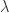 表示上采样因子,
表示上采样因子,![[\cdot], \{\cdot\}](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D%2C+%5C%7B%5Ccdot%5C%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 分别表示一个实数的正数部分和小数部分。
分别表示一个实数的正数部分和小数部分。 表示预测类别的概率,
表示预测类别的概率, 其中
其中  表示在第
表示在第  个尺寸下所得到的类别
个尺寸下所得到的类别  ,也就是说,局部预测的概率值应该高于整体的概率值。
,也就是说,局部预测的概率值应该高于整体的概率值。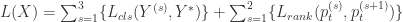 .
.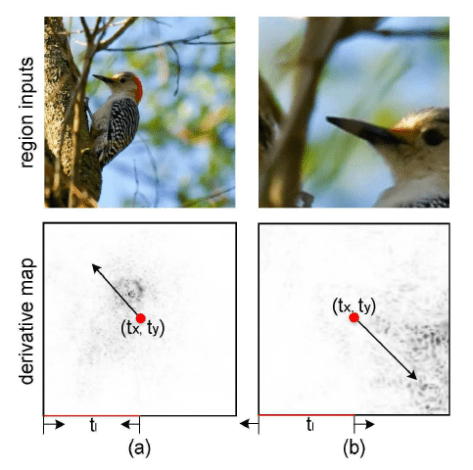
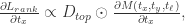
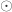 表示元素的点乘,
表示元素的点乘,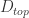 表示之前的网络所得到的导数。
表示之前的网络所得到的导数。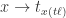 ,
,
 ,
,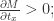

 ,
,
 ,
,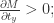
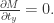


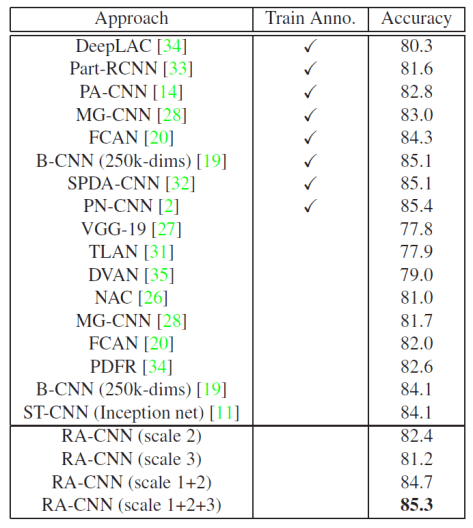
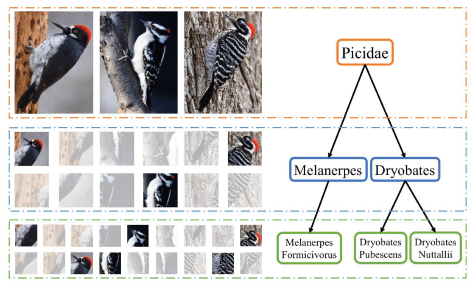
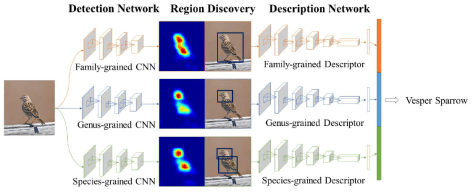

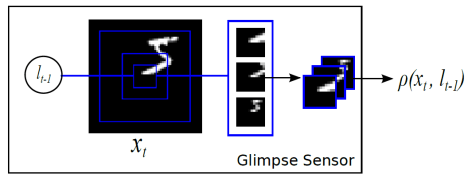
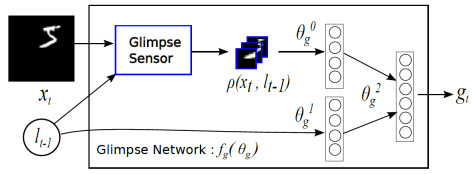
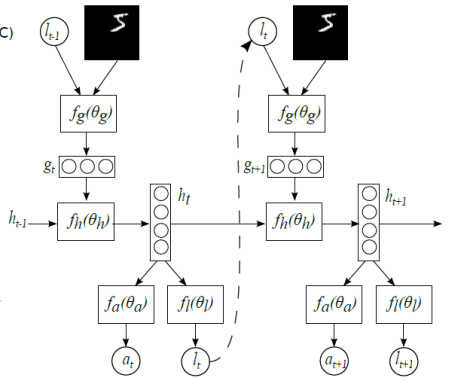
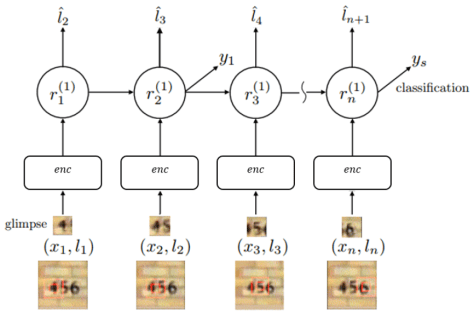
 表示解码的过程,
表示解码的过程, 表示对图片的预测概率或者预测标签。
表示对图片的预测概率或者预测标签。 是解码网络,
是解码网络, 是注意力网络,输出概率在解码网络的最后一个单元输出。
是注意力网络,输出概率在解码网络的最后一个单元输出。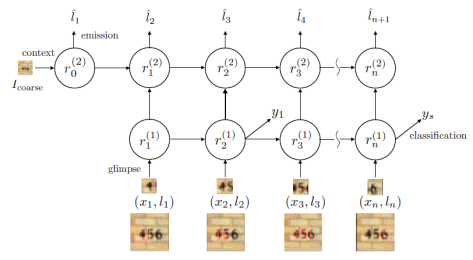
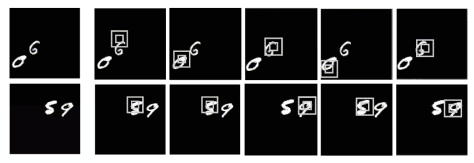

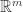 中的
中的 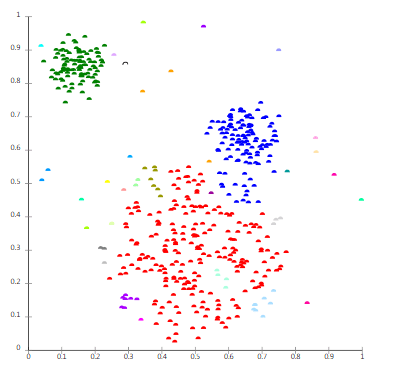
 ,事先设定的类别个数是
,事先设定的类别个数是  是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合
是必须要满足的,因为类别的数目不能够多于点集的元素个数。算法的目标是寻找到合适的集合 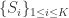 使得
使得  达到最小,其中
达到最小,其中  表示集合
表示集合  中的所有点的均值。
中的所有点的均值。 表示欧式空间的欧几里得距离,在这种情况下,除了使用
表示欧式空间的欧几里得距离,在这种情况下,除了使用 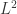 范数之外,还可以使用
范数之外,还可以使用  范数和其余的
范数和其余的 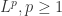 范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。
范数。只要该范数满足距离的三个性质即可,也就是非负数,对称,三角不等式。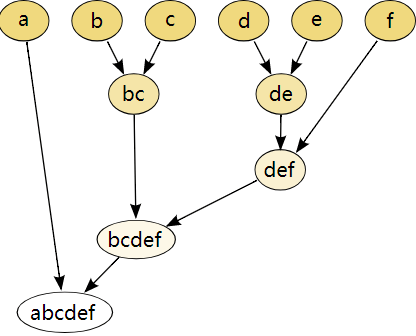
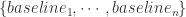 和
和  。i.e.
。i.e.  。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章:
。有的时候,提取完时间序列的基线之后,其实对时间序列的基线做特征,有的时候分类效果会优于对原始的时间序列做特征。参考文章: 距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把
距离之外,还可以使用 DTW 等方法。在这种情况下,DTW 是基于动态规划算法来做的,基本想法是根据动态规划原理,来进行时间序列的“扭曲”,从而把时间序列进行必要的错位,计算出最合适的距离。一个简单的例子就是把  和
和  进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是
进行必要的横坐标平移,计算出两条时间序列的最合适距离。但是,从 DTW 的算法描述来看,它的算法复杂度是相对高的,是  量级的,其中
量级的,其中 
 还是
还是 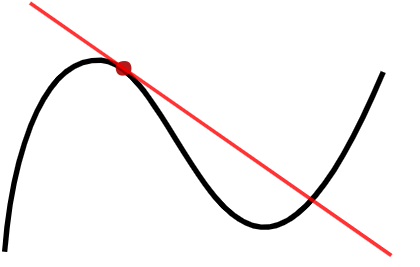
 是定义域
是定义域  上的可导函数,那么某个点
上的可导函数,那么某个点  的导数则定义为:
的导数则定义为:
 。如果
。如果  ,那么在
,那么在  的附近,
的附近, ,那么在
,那么在  ,则基于这个事实无法轻易的判断
,则基于这个事实无法轻易的判断  ,
,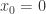 ;(2)
;(2) ,
,
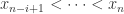 时,表示时间序列在
时,表示时间序列在 ![[n-i+1,n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2Cn%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调递增的;当
这个区间内是严格单调递增的;当  时,表示时间序列在
时,表示时间序列在 ![[n-i+1, n]](https://s0.wp.com/latex.php?latex=%5Bn-i%2B1%2C+n%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。
这个区间内是严格单调下跌的。但是,在现实环境中,较难找到这种严格递增或者严格递减的情况。在大部分情况下,只存在一个上涨或者下跌的趋势,一旦聚焦到某个时间戳附近时间序列是有可能存在抖动性的。所以我们需要给出一个定义,用来描述时间序列在一个区间内的趋势是上升还是下跌。![X_{N} = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的一个子序列
的一个子序列 ![[x_{i},x_{i+1},\cdots,x_{j}]](https://s0.wp.com/latex.php?latex=%5Bx_%7Bi%7D%2Cx_%7Bi%2B1%7D%2C%5Ccdots%2Cx_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,其中
,其中  。如果存在某个
。如果存在某个 ![k\in (i,j]](https://s0.wp.com/latex.php?latex=k%5Cin+%28i%2Cj%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 和一组非负实数
和一组非负实数 ![[w_{i}, w_{i+1},\cdots,w_{j}]](https://s0.wp.com/latex.php?latex=%5Bw_%7Bi%7D%2C+w_%7Bi%2B1%7D%2C%5Ccdots%2Cw_%7Bj%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 使得
使得 其中
其中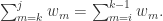
 其中
其中 ![X = [x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,可以考虑第
,可以考虑第  时,
时,

 ,当第一个公式大于零时,表示
,当第一个公式大于零时,表示 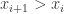 ,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示
,i.e. 处于单调上升的趋势中。当第一个公式小于零时,表示 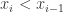 ,i.e. 处于单调下降的趋势中。
,i.e. 处于单调下降的趋势中。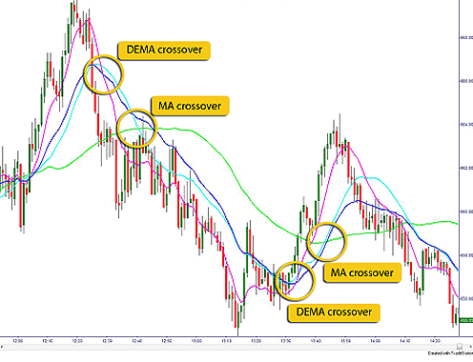
![X=[x_{1},\cdots,x_{N}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,如果考虑时间戳
,如果考虑时间戳 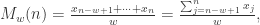
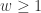 指的就是窗口的大小。
指的就是窗口的大小。 ,
,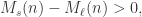 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。 。假设
。假设  ,那么通过数学推导可以得到:
,那么通过数学推导可以得到:

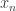 历史上的
历史上的 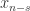 历史上的
历史上的  个点的平均值,该序列有上涨的趋势。反之,如果
个点的平均值,该序列有上涨的趋势。反之,如果  ,那么该序列有下跌的趋势。
,那么该序列有下跌的趋势。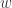 ,对于简单移动平均算法,那么
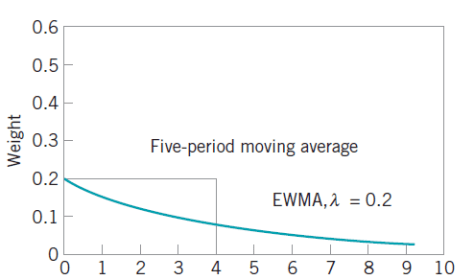
,对于简单移动平均算法,那么  每个元素的权重都是
每个元素的权重都是  ,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
,它们都是一样的权重。有的时候我们不希望权重都是恒等的,因为近期的点照理来说是比历史悠久的点更加重要,于是有人提出带权重的移动平均算法 (Weighted Moving Average)。从数学上来看,带权重的移动平均算法指的是
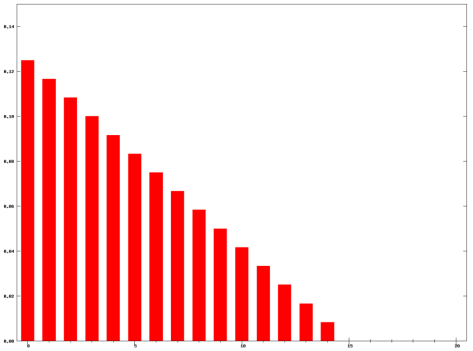
 ,那么
,那么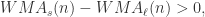 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。
表示短线下穿长线,曲线有下跌的趋势。 。假设
。假设  ,那么
,那么




![j_{0}=[s\cdot(s+1)/(\ell + s-1)]](https://s0.wp.com/latex.php?latex=j_%7B0%7D%3D%5Bs%5Ccdot%28s%2B1%29%2F%28%5Cell+%2B+s-1%29%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,这里的
,这里的 ![[\cdot]](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 表示 Gauss 取整函数。因为
表示 Gauss 取整函数。因为
 ,于是距离当前点
,于是距离当前点 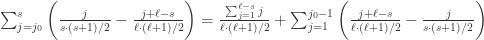

 时,表示时间序列有上涨的趋势;当
时,表示时间序列有上涨的趋势;当  时,表示时间序列有下跌的趋势。
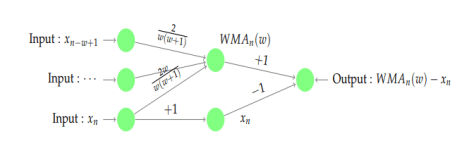
时,表示时间序列有下跌的趋势。 ,那么它的指数移动平均算法就是:
,那么它的指数移动平均算法就是: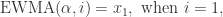

 。
。

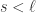 ,那么短线和长线则分别是:
,那么短线和长线则分别是:
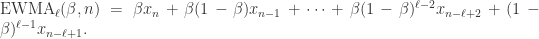
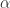 是与
是与  时,
时,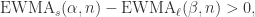 表示短线上穿长线,曲线有上涨的趋势;
表示短线上穿长线,曲线有上涨的趋势; 表示短线下穿长线,曲线有下跌的趋势。注:当
表示短线下穿长线,曲线有下跌的趋势。注:当  时,
时,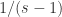 可以看做
可以看做  .
. 。那么
。那么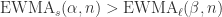


 时,表示时间序列有下跌的趋势。
时,表示时间序列有下跌的趋势。 时,根据假设有
时,根据假设有  ,并且
,并且


 ,通过计算可以得到
,通过计算可以得到  ,也就是说
,也就是说  在
在 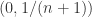 上是递增函数,在
上是递增函数,在  是递减函数。于是当
是递减函数。于是当 


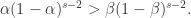
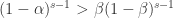 ,那么
,那么  可以写成
可以写成

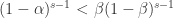 ,那么
,那么 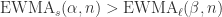 可以写成
可以写成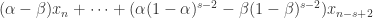

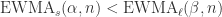 时,也可以使用同样的方法证明时间序列有下跌的趋势。
时,也可以使用同样的方法证明时间序列有下跌的趋势。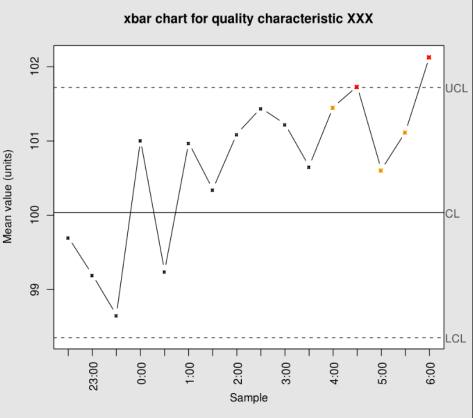
 控制图
控制图![X_{N} = [x_{1},\cdots, x_{N}]](https://s0.wp.com/latex.php?latex=X_%7BN%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7BN%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,为了计算某个时间戳
,为了计算某个时间戳 ![[x_{1},x_{2},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 中的所有点,可以计算出均值和方差如下:
中的所有点,可以计算出均值和方差如下:

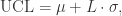


 表示系数,通常选择
表示系数,通常选择  。
。 ,那么说明
,那么说明 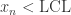 时,那么说明
时,那么说明 
 的方差是
的方差是
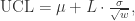

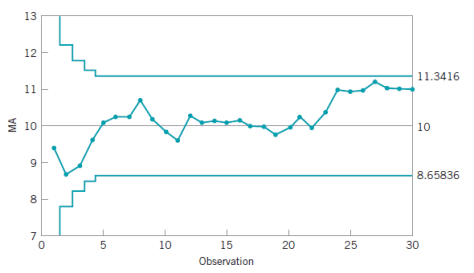
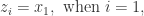

 的方差是:
的方差是:

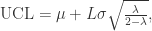

 。
。
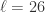 ,
, 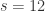 ,
,  ,基于时间序列
,基于时间序列  ,有
,有


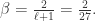

 ,计算 DEA 如下:
,计算 DEA 如下:
 ,
,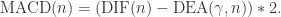




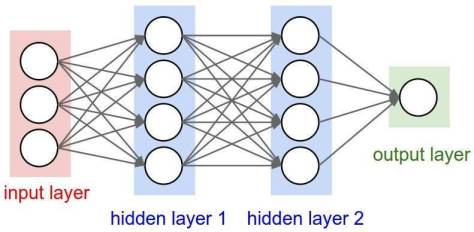
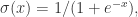
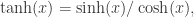
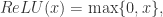




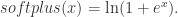
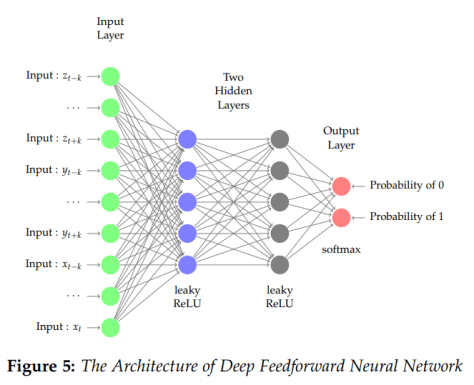
 ,存在一个前馈神经网络
,存在一个前馈神经网络 ![\boldsymbol{X}_{n}=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=%5Cboldsymbol%7BX%7D_%7Bn%7D%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,该神经网络的输入和输出分别是
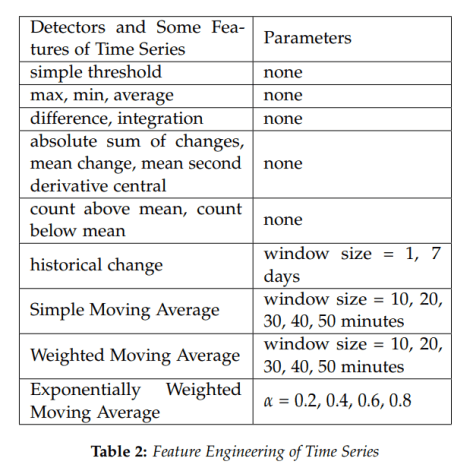
,该神经网络的输入和输出分别是  和表格 2 中
和表格 2 中 ![X_{n} = [x_{1},\cdots, x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2C+x_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的以上统计特征之前,我们可以先使用神经网络构造出这几种运算方法。
的以上统计特征之前,我们可以先使用神经网络构造出这几种运算方法。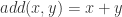 与减法
与减法 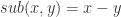 的构造十分简单,如下图构造即可:
的构造十分简单,如下图构造即可:

 通过计算可以得到
通过计算可以得到  所以,可以构造如下的神经网络来表示绝对值函数:
所以,可以构造如下的神经网络来表示绝对值函数: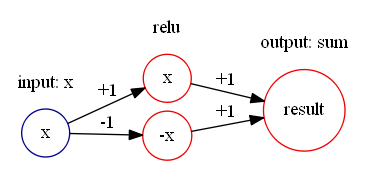
 通过计算可以得到
通过计算可以得到
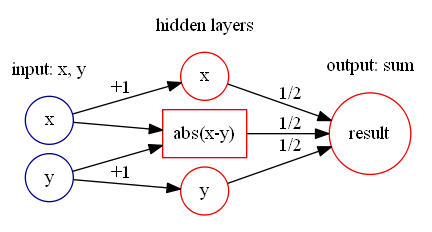
 通过计算可以得到
通过计算可以得到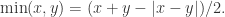
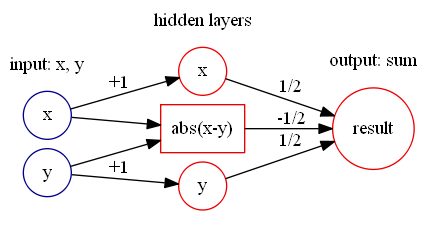


 指的是
指的是 
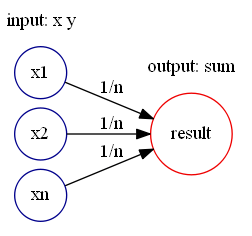
 这个函数可以使用 Softplus 激活函数来表达。令 Softplus 为
这个函数可以使用 Softplus 激活函数来表达。令 Softplus 为



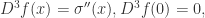



 就可以用神经网络来近似表示:
就可以用神经网络来近似表示: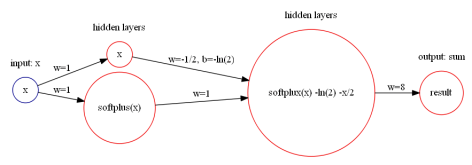
 这个函数可以使用 Sigmoid 激活函数来表达。因为 Sigmoid 函数的 Taylor Series 是
这个函数可以使用 Sigmoid 激活函数来表达。因为 Sigmoid 函数的 Taylor Series 是

 就可以用神经网络来近似表示:
就可以用神经网络来近似表示: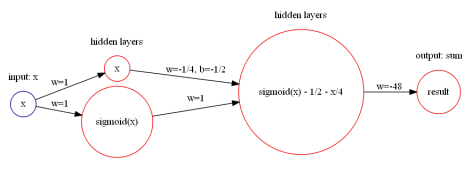
![X_{n} =[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的最大值,最小值等各种各样的统计指标。如果按照上文所描述的,以下特征都可以用神经网络轻松构造出来:
的最大值,最小值等各种各样的统计指标。如果按照上文所描述的,以下特征都可以用神经网络轻松构造出来:



![\sum_{i=1}^{n}[(x_{i}-\mu)/\sigma]^{3},](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%28x_%7Bi%7D-%5Cmu%29%2F%5Csigma%5D%5E%7B3%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![\sum_{i=1}^{n}[(x_{i}-\mu)/\sigma]^{4},](https://s0.wp.com/latex.php?latex=%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5B%28x_%7Bi%7D-%5Cmu%29%2F%5Csigma%5D%5E%7B4%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


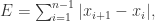


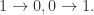
 的时候,
的时候,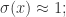 当
当  的时候,
的时候, 因此,可以使用函数
因此,可以使用函数  来估计 NOT 逻辑门。
来估计 NOT 逻辑门。 时,
时,
 时,
时,

 可以得到
可以得到 时,
时,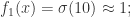
 时,
时,
 近似于判断待测试值
近似于判断待测试值 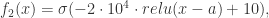 可以得到
可以得到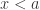 时,
时,
 时,
时,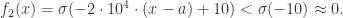
 近似于判断待测试值
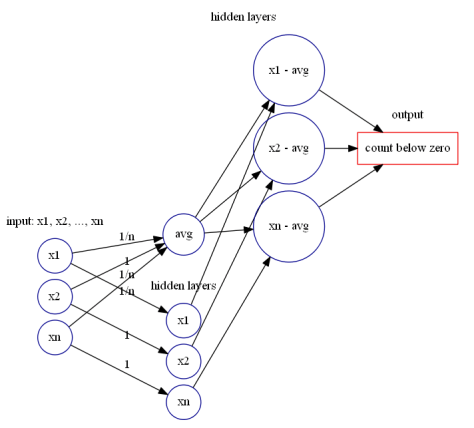
近似于判断待测试值 ![X_{n}=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 每个点与均值的差值,然后使用前面的神经网络模块计算出大于零的差值个数与小于零的差值个数即可。
每个点与均值的差值,然后使用前面的神经网络模块计算出大于零的差值个数与小于零的差值个数即可。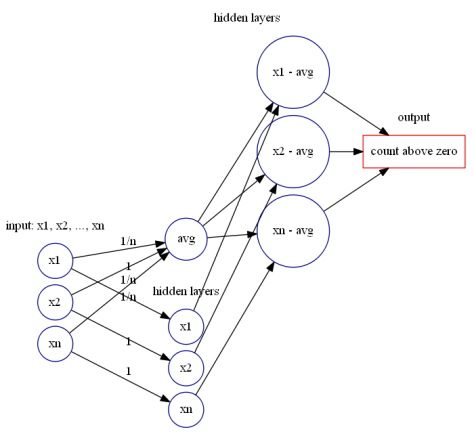
![X_{n} = [x_{1},\cdots,x_{n}],](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 我们可以使用一个窗口值
我们可以使用一个窗口值 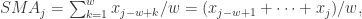
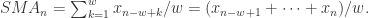
 就可以作为一个特征。然后根据不同的窗口长度
就可以作为一个特征。然后根据不同的窗口长度 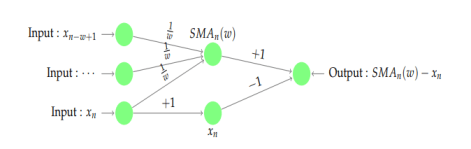
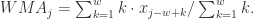




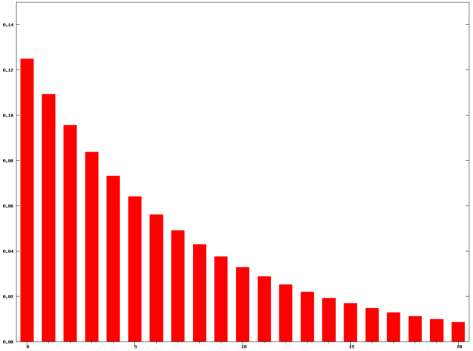
![= \alpha[x_{n-1}+(1-\alpha)x_{n-2}+\cdots+(1-\alpha)^{k}x_{n-(k+1)}] + (1-\alpha)^{k+1}EWMA_{n-(k+1)}](https://s0.wp.com/latex.php?latex=%3D+%5Calpha%5Bx_%7Bn-1%7D%2B%281-%5Calpha%29x_%7Bn-2%7D%2B%5Ccdots%2B%281-%5Calpha%29%5E%7Bk%7Dx_%7Bn-%28k%2B1%29%7D%5D+%2B+%281-%5Calpha%29%5E%7Bk%2B1%7DEWMA_%7Bn-%28k%2B1%29%7D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![\approx \alpha[x_{n-1}+(1-\alpha)x_{n-2}+\cdots+(1-\alpha)^{k}x_{n-(k+1)}]](https://s0.wp.com/latex.php?latex=%5Capprox%C2%A0%5Calpha%5Bx_%7Bn-1%7D%2B%281-%5Calpha%29x_%7Bn-2%7D%2B%5Ccdots%2B%281-%5Calpha%29%5E%7Bk%7Dx_%7Bn-%28k%2B1%29%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 的取值就可以得到特征。所以,神经网络可以构建为如下形式:
的取值就可以得到特征。所以,神经网络可以构建为如下形式:
![X_{n} = [x_{week}, x_{yesterday}, x_{today}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7Bweek%7D%2C+x_%7Byesterday%7D%2C+x_%7Btoday%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 可以拆分成三个部分
可以拆分成三个部分 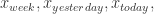 分别是一周前的数据,昨天的数据,今天的数据,假设它们的长度都是 [n/3],最后一点都表示不同天但是同一个时刻的取值。所以,同环比特征
分别是一周前的数据,昨天的数据,今天的数据,假设它们的长度都是 [n/3],最后一点都表示不同天但是同一个时刻的取值。所以,同环比特征![x_{today}[-1] - x_{yesterday}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D+-+x_%7Byesterday%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 与
与 ![x_{today}[-1] - x_{week}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D+-+x_%7Bweek%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 都是可以通过神经网络构造出来。
都是可以通过神经网络构造出来。 与
与 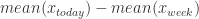 这一类特征也可以构造出来。
这一类特征也可以构造出来。 等函数,再计算两者的差值即可。例如,我们可以构造一个特征用于计算当前值是否高过昨天的峰值,以及超出的幅度是多少。用公式来表示那就是:
等函数,再计算两者的差值即可。例如,我们可以构造一个特征用于计算当前值是否高过昨天的峰值,以及超出的幅度是多少。用公式来表示那就是:![\max\{x_{today}[-1]-\max\{x_{yesterday}\}, 0\},](https://s0.wp.com/latex.php?latex=%5Cmax%5C%7Bx_%7Btoday%7D%5B-1%5D-%5Cmax%5C%7Bx_%7Byesterday%7D%5C%7D%2C+0%5C%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![x_{today}[-1]](https://s0.wp.com/latex.php?latex=x_%7Btoday%7D%5B-1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 大于昨天的最大值,就返回它高出的幅度;否则就返回0。
大于昨天的最大值,就返回它高出的幅度;否则就返回0。![\min\{x_{today}[-1]-\min\{x_{week}\},0\},](https://s0.wp.com/latex.php?latex=%5Cmin%5C%7Bx_%7Btoday%7D%5B-1%5D-%5Cmin%5C%7Bx_%7Bweek%7D%5C%7D%2C0%5C%7D%2C&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 激活函数使用
激活函数使用  即可。
即可。![X_{n} = [x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X_%7Bn%7D+%3D+%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 的取值在
的取值在 ![[0,0.1), [0.1,0.2),\cdots,[0.9,1]](https://s0.wp.com/latex.php?latex=%5B0%2C0.1%29%2C+%5B0.1%2C0.2%29%2C%5Ccdots%2C%5B0.9%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 这十个桶的个数,进一步得到它们落入这十个桶的概率是多少。这一类特征可以通过之前所构造的 count 函数来生成。因此,分类特征也是可以通过构造神经网络来形成的。
这十个桶的个数,进一步得到它们落入这十个桶的概率是多少。这一类特征可以通过之前所构造的 count 函数来生成。因此,分类特征也是可以通过构造神经网络来形成的。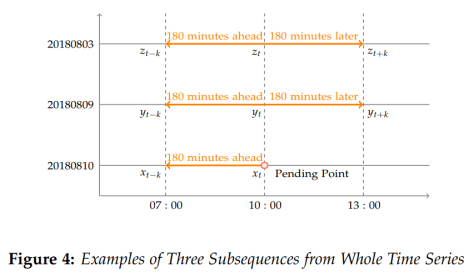


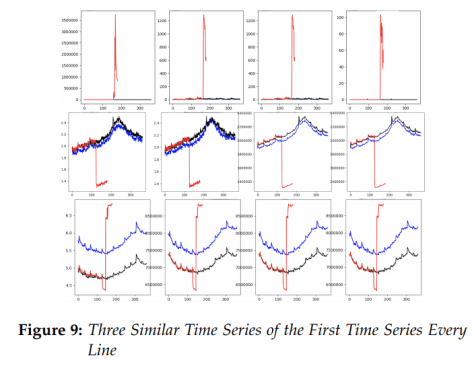





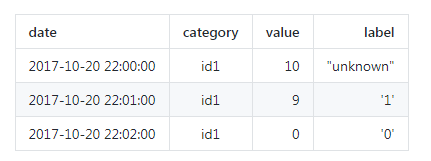

 分成几个部分,分别是季节项
分成几个部分,分别是季节项 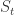 ,趋势项
,趋势项  ,剩余项
,剩余项  。也就是说对所有的
。也就是说对所有的 

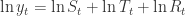 。所以,有的时候在预测模型的时候,会先取对数,然后再进行时间序列的分解,就能得到乘法的形式。在 fbprophet 算法中,作者们基于这种方法进行了必要的改进和优化。
。所以,有的时候在预测模型的时候,会先取对数,然后再进行时间序列的分解,就能得到乘法的形式。在 fbprophet 算法中,作者们基于这种方法进行了必要的改进和优化。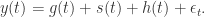
 表示趋势项,它表示时间序列在非周期上面的变化趋势;
表示趋势项,它表示时间序列在非周期上面的变化趋势;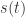 表示周期项,或者称为季节项,一般来说是以周或者年为单位;
表示周期项,或者称为季节项,一般来说是以周或者年为单位; 表示节假日项,表示在当天是否存在节假日;
表示节假日项,表示在当天是否存在节假日; 表示误差项或者称为剩余项。Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。
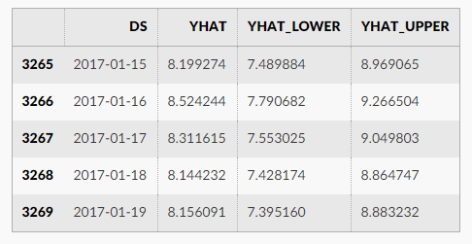
表示误差项或者称为剩余项。Prophet 算法就是通过拟合这几项,然后最后把它们累加起来就得到了时间序列的预测值。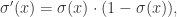 并且
并且 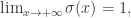
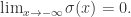 如果增加一些参数的话,那么逻辑回归就可以改写成:
如果增加一些参数的话,那么逻辑回归就可以改写成:
 称为曲线的最大渐近值,
称为曲线的最大渐近值, 时,恰好就是大家常见的 sigmoid 函数的形式。从 sigmoid 的函数表达式来看,它满足以下的微分方程:
时,恰好就是大家常见的 sigmoid 函数的形式。从 sigmoid 的函数表达式来看,它满足以下的微分方程: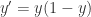 。
。 .
. 的三个参数
的三个参数 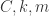 不可能都是常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,作者考虑把这三个参数全部换成了随着时间而变化的函数,也就是
不可能都是常数,而很有可能是随着时间的迁移而变化的,因此,在 Prophet 里面,作者考虑把这三个参数全部换成了随着时间而变化的函数,也就是  。
。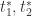 就是时间序列的两个变点。
就是时间序列的两个变点。
 上,那么在这些时间戳上,我们就需要给出增长率的变化,也就是在时间戳
上,那么在这些时间戳上,我们就需要给出增长率的变化,也就是在时间戳  上发生的 change in rate。可以假设有这样一个向量:
上发生的 change in rate。可以假设有这样一个向量: 其中
其中  表示在时间戳
表示在时间戳 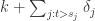 ,通过一个指示函数
,通过一个指示函数  就是
就是
 一旦变化量
一旦变化量 
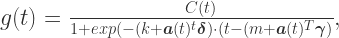
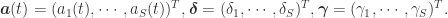
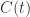 ,在使用 Prophet 的 growth = ‘logistic’ 的时候,需要提前设置好
,在使用 Prophet 的 growth = ‘logistic’ 的时候,需要提前设置好  而分段线性函数指的是在每一个子区间上,函数都是线性函数,但是在整段区间上,函数并不完全是线性的。正如下图所示,分段线性函数就是一个折线的形状。
而分段线性函数指的是在每一个子区间上,函数都是线性函数,但是在整段区间上,函数并不完全是线性的。正如下图所示,分段线性函数就是一个折线的形状。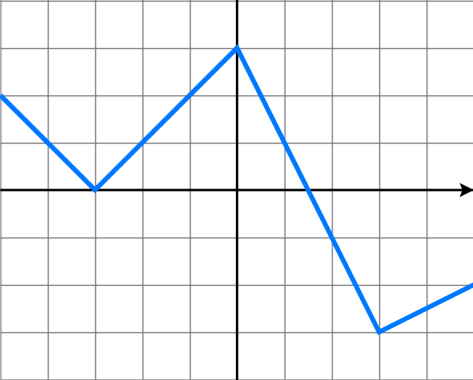

 表示增长率的变化量,
表示增长率的变化量, 的设置不一样,在分段线性函数中,
的设置不一样,在分段线性函数中,
 注意:这与之前逻辑回归函数中的设置是不一样的。
注意:这与之前逻辑回归函数中的设置是不一样的。
 表示位置参数,
表示位置参数, 表示尺度参数。Laplace 分布与正态分布有一定的差异。
表示尺度参数。Laplace 分布与正态分布有一定的差异。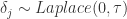 ,这里的
,这里的  就是 change_point_scale。
就是 change_point_scale。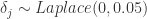 的。因此,当
的。因此,当  的数据中,我们可以选择出
的数据中,我们可以选择出 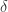 的情况。这里令
的情况。这里令  ,于是新的增长率的变化量就是按照下面的规则来选择的:当
,于是新的增长率的变化量就是按照下面的规则来选择的:当  时,
时,
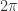 为周期的函数,那么它的傅立叶级数就是
为周期的函数,那么它的傅立叶级数就是 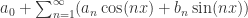 。
。 表示以年为周期,
表示以年为周期, 表示以周为周期。它的傅立叶级数的形式都是:
表示以周为周期。它的傅立叶级数的形式都是: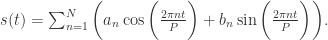
 ;对于以周为周期的序列(
;对于以周为周期的序列( 。这里的参数可以形成列向量:
。这里的参数可以形成列向量: 。
。![X(t) = \bigg[\cos(\frac{2\pi(1)t}{365.25}),\cdots,\sin(\frac{2\pi(10)t}{365.25})\bigg]](https://s0.wp.com/latex.php?latex=X%28t%29+%3D+%5Cbigg%5B%5Ccos%28%5Cfrac%7B2%5Cpi%281%29t%7D%7B365.25%7D%29%2C%5Ccdots%2C%5Csin%28%5Cfrac%7B2%5Cpi%2810%29t%7D%7B365.25%7D%29%5Cbigg%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
![X(t) = \bigg[\cos(\frac{2\pi(1)t}{7}),\cdots,\sin(\frac{2\pi(3)t}{7})\bigg]](https://s0.wp.com/latex.php?latex=X%28t%29+%3D+%5Cbigg%5B%5Ccos%28%5Cfrac%7B2%5Cpi%281%29t%7D%7B7%7D%29%2C%5Ccdots%2C%5Csin%28%5Cfrac%7B2%5Cpi%283%29t%7D%7B7%7D%29%5Cbigg%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 而
而  的初始化是
的初始化是  。这里的
。这里的 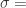 seasonality_prior_scale。这个值越大,表示季节的效应越明显;这个值越小,表示季节的效应越不明显。同时,在代码里面,seasonality_mode 也对应着两种模式,分别是加法和乘法,默认是加法的形式。在开源代码中,
seasonality_prior_scale。这个值越大,表示季节的效应越明显;这个值越小,表示季节的效应越不明显。同时,在代码里面,seasonality_mode 也对应着两种模式,分别是加法和乘法,默认是加法的形式。在开源代码中, 函数是通过 fourier_series 来构建的。
函数是通过 fourier_series 来构建的。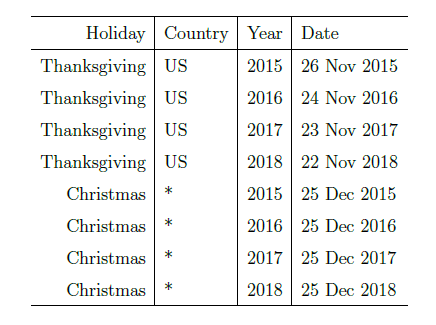
 表示该节假日的前后一段时间。为了表示节假日效应,我们需要一个相应的指示函数(indicator function),同时需要一个参数
表示该节假日的前后一段时间。为了表示节假日效应,我们需要一个相应的指示函数(indicator function),同时需要一个参数  来表示节假日的影响范围。假设我们有
来表示节假日的影响范围。假设我们有 
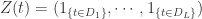 和
和 
 并且该正态分布是受到
并且该正态分布是受到  holidays_prior_scale 这个指标影响的。默认值是 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。用户可以根据自己的情况自行调整。
holidays_prior_scale 这个指标影响的。默认值是 10,当值越大时,表示节假日对模型的影响越大;当值越小时,表示节假日对模型的效果越小。用户可以根据自己的情况自行调整。
 changepoint_prior_scale 可以用来控制趋势的灵活度,
changepoint_prior_scale 可以用来控制趋势的灵活度,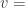 holidays prior scale 用来控制节假日的灵活度。
holidays prior scale 用来控制节假日的灵活度。