
帐号映射的整体介绍
在现实生活中,用户通常会同时使用多个社交网络,例如国外的 Twitter,Instagram,Facebook,也可能使用微信,QQ,微博等国内的产品。基于这些产品的不同定位,用户自身的社交网络会有很大的差异,那么如何通过机器学习算法找到一个人的社交网络帐号就成为了一个有趣的问题。在学术界,有学者对开源的 Facebook,Twitter 等社交网络数据进行了研究,设计了一套帐号映射的技术方案。
帐号映射这个课题有很多的别名,例如:
- Social identity linkage;
- User identity linkage;
- User identity resolution;
- Social network reconciliation;
- User account linkage inference;
- Profile linkage;
- Anchor link prediction;
- Detecting me edges;
帐号映射的目的就是将社交网络上这些看似不同的帐号映射到自然人:帐号(user accounts)-> 真实的自然人(real natural person)。令社交网络 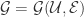
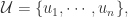
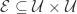
帐号映射(User Identity Linkage)的定义是:给定两个社交网络 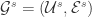
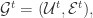
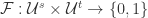
其中
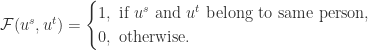
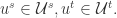
上述函数 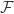
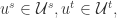
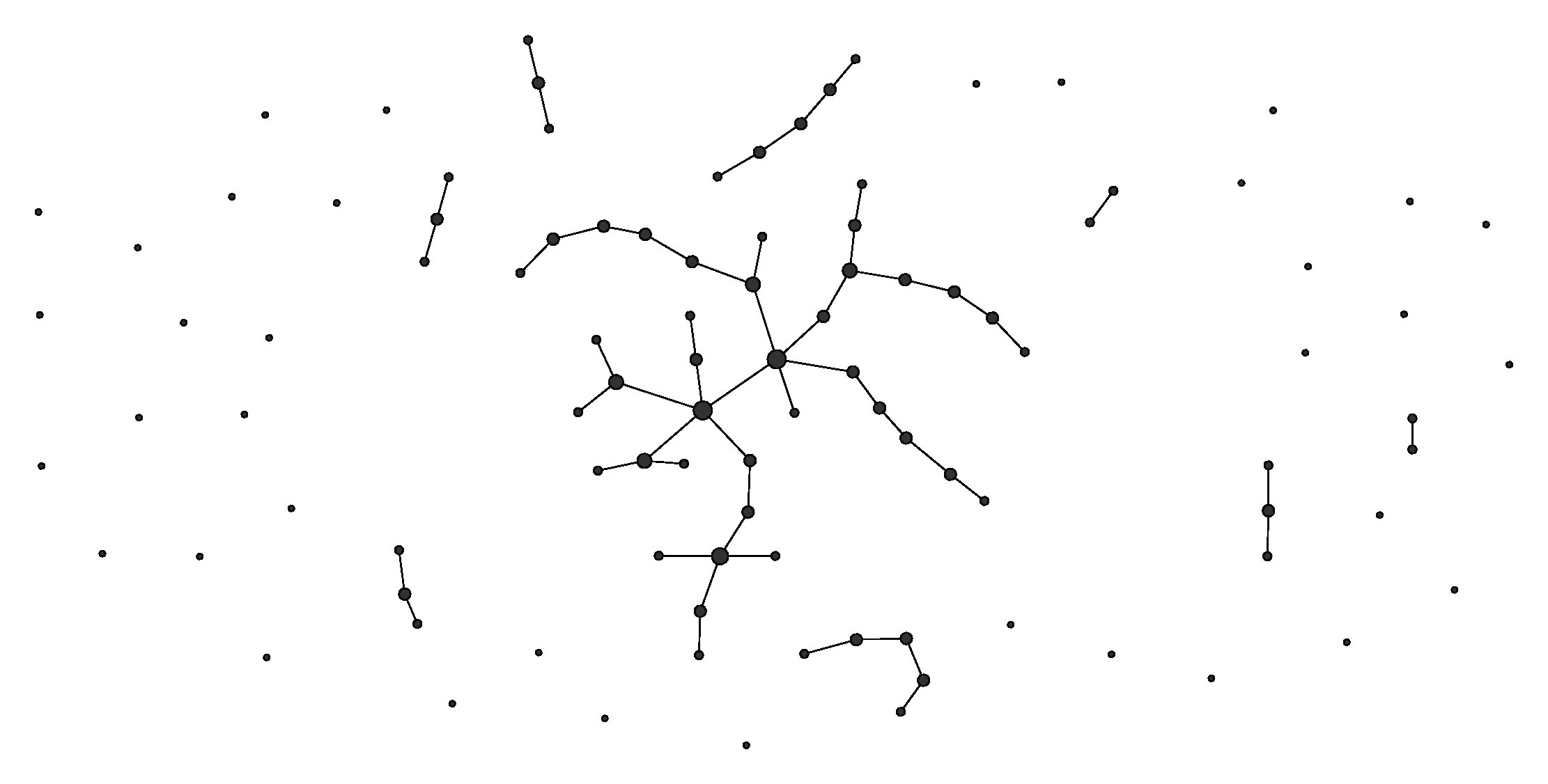
![\mathcal{\hat{F}}(u^{s},u^{t})=p\in [0,1]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7B%5Chat%7BF%7D%7D%28u%5E%7Bs%7D%2Cu%5E%7Bt%7D%29%3Dp%5Cin+%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
一个帐号在社交网络的属性包括很多方面,例如:
| 画像属性(Profile Features) | 内容属性(Content Features) | 社交网络属性(Network Features) |
| ID(社交网络的唯一标识) | 时间戳(timestamp) | 关注,被关注,好友关系(Friendship) |
| 身份证 ID(identity card) | 语音(speech) | 点赞(like) |
| 手机号(phone) | 视频(video) | 评论(comment) |
| 昵称(username) | 图片(image) | @(at) |
| 头像(head image) | 文本(text) | 收藏(collect) |
| 性别(gender) | 设备信息(device) | 消息(message) |
| 年龄(age) | wifi 信息(wifi) | 回复(reply) |
| 邮箱(email) | 地理位置(gps) | |
| 个人网页(url) | ||
| 职业(occupation) |
一般情况下,
- 画像属性:绝大多数帐号都会有基础的画像信息;
- 内容属性:不活跃的帐号较难获取;
- 社交网络属性:线上的社交网络关系并不代表线下的社交网络关系,存在一定的噪声数据。
帐号映射的技术框架可以基于特征工程来做,然后使用有监督算法,无监督算法,或者半监督算法来进行帐号对之间的训练和预测。
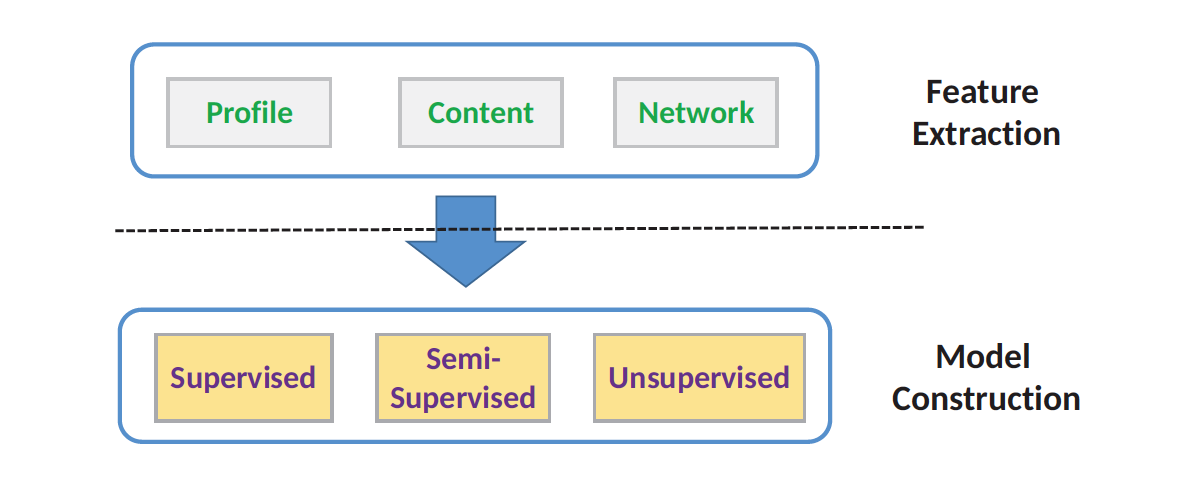
帐号映射的特征工程
帐号的画像特征
对于社交网络 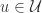
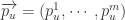

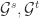
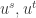
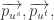
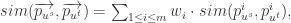

其中 sim 表示相似度,dis 表示距离。
基于距离的方法(distance-based)的方法很多,例如:
- 文本(text field)之间的距离可以考虑用 Jaro-Winkler distance,Jaccard similarity,Levenshtein distance 等方法;
- 图像(visual field)之间的距离可以考虑用 mean square error,dot product,angular distance,peak signal-to-noise ratio,Levenshtein distance 等方法;
基于频率的方法(frequence-based)可以考虑 bag-of-word model,TF-IDF model,Markov-chain model 等方法;
帐号的内容特征
帐号所产生的内容数据包括三个部分:
- 时间上的数据(temporal):时间戳的数据;
- 空间上的数据(spatial):帐号的设备数据,IP 数据,WIFI 数据,地理位置数据等等;
- 内容上的数据(post):帐号所产生的内容数据,包括但不限于视频,文本,语音,图片等。
用数学公式来描述就是 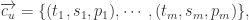
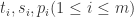
在某个时间段内,帐号所产生的内容特征可以提炼出用户在社交网络上的行为数据和内容数据,形成一个行为序列。通过这个行为序列,可以得到用户的内容特征。
- 基于兴趣的特征(Interest-based):可以基于内容数据判断帐号对哪些内容更感兴趣;
- 基于风格的特征(Style-based):基于内容数据得到帐号的写作风格,例如常用词语等;
- 基于轨迹的特征(Trajectory-based):基于帐号的行为轨迹数据,包括设备,IP,WIFI,地理位置以及相应的时间戳,得到帐号的足迹(footprint)。
帐号的社交网络特征
社交网络包括两种:
- 局部社交网络(local network):查看帐号的邻居(关注,被关注,好友关系)等诸多数据;
- 全局社交网络(global network):查看帐号在全局数据中的位置情况;
对于帐号的社交网络特征,包括以下两种常见形式:
- 基于邻居的特征(Neighborhood-based):共同好友数,共同邻居个数,Jaccard Coefficient,Overlap Coefficient,Dice Coefficient,Adamic/Adar score;
- 基于嵌入的特征(Embedding-based):通过计算帐号在相应的社交网络的嵌入特征,然后计算特征之间的距离或者相似性。
帐号映射的建模思路
机器学习的常见算法包括有监督算法(supervised model),无监督算法(unsupervised model)和半监督算法(semi-supervised model)。
基于上面的特征工程,加上合适的权重之和可以得到一个分数(score),也就是:
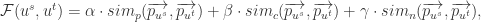
其中 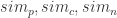
如果有样本的话,全体样本是 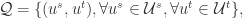

帐号映射的评价指标
对于 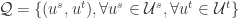
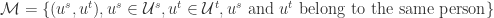
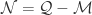
令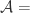
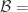
- True Positive(TP):
- True Negative(TN):
- False Negative(FN):
- False Positive(FP):
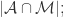
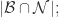
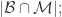
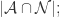
那么,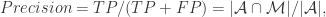
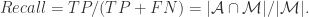
另外,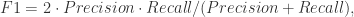
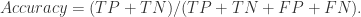
部分论文细节
- Liu, Jing, et al. “What’s in a name? An unsupervised approach to link users across communities.” Proceedings of the sixth ACM international conference on Web search and data mining. 2013. 本篇文章主要是基于用户的名字来识别跨网络的用户的,提取用户的特征之后,使用 SVM 分类器来进行识别;
- Riederer, Christopher, et al. “Linking users across domains with location data: Theory and validation.” Proceedings of the 25th International Conference on World Wide Web. 2016. 本篇文章主要是基于用户的内容特征来进行建模;
- Labitzke, Sebastian, Irina Taranu, and Hannes Hartenstein. “What your friends tell others about you: Low cost linkability of social network profiles.” Proc. 5th International ACM Workshop on Social Network Mining and Analysis, San Diego, CA, USA. 2011. 本篇论文是根据社交网络中的用户邻居数据,来判断用户之间相似性的。
参考文献
- Shu, Kai, et al. “User identity linkage across online social networks: A review.” Acm Sigkdd Explorations Newsletter 18.2 (2017): 5-17.
- Liu, Jing, et al. “What’s in a name? An unsupervised approach to link users across communities.” Proceedings of the sixth ACM international conference on Web search and data mining.
- Riederer, Christopher, et al. “Linking users across domains with location data: Theory and validation.” Proceedings of the 25th International Conference on World Wide Web. 2016.
- Labitzke, Sebastian, Irina Taranu, and Hannes Hartenstein. “What your friends tell others about you: Low cost linkability of social network profiles.” Proc. 5th International ACM Workshop on Social Network Mining and Analysis, San Diego, CA, USA. 2011.
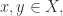 相似性函数
相似性函数  是将
是将  映射到实数域
映射到实数域 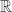 的有界函数,i.e. 存在上下界使得
的有界函数,i.e. 存在上下界使得  它具有以下两个性质:
它具有以下两个性质: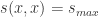 对于所有的
对于所有的  都成立;
都成立; 对于所有的
对于所有的  都成立;
都成立;
 距离函数
距离函数 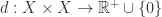 是将
是将  并不存在上界,它具有以下三个性质:
并不存在上界,它具有以下三个性质: 对于所有的
对于所有的  对于所有的
对于所有的 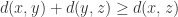 对于所有的
对于所有的  都成立。
都成立。
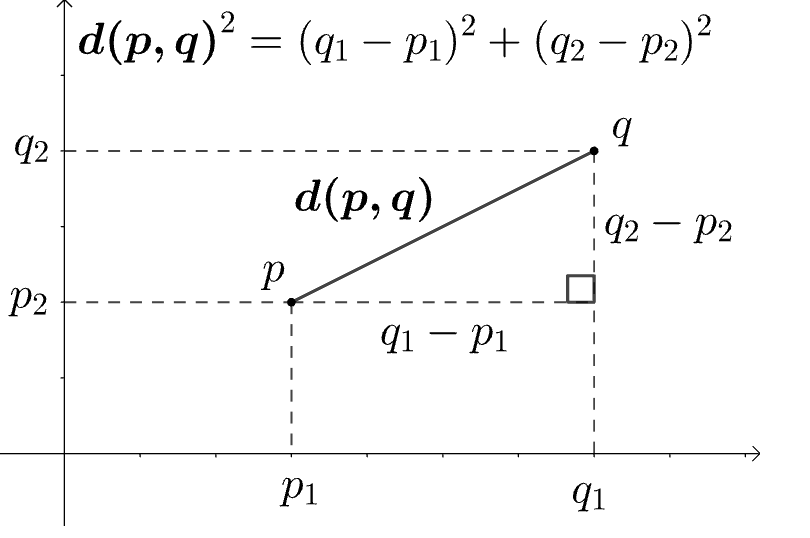
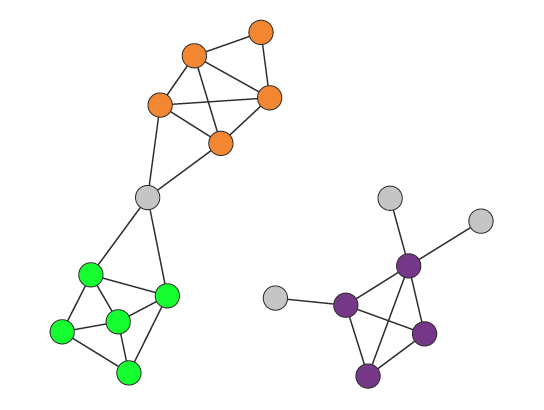
 中的两个点
中的两个点  和
和  而言,可以多种方法来描述它们之间的相似性。
而言,可以多种方法来描述它们之间的相似性。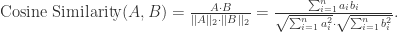
![[-1,1].](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002)


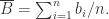 同样根据 Cauchy 不等式可以得到 Pearson Similarity 的取值范围是
同样根据 Cauchy 不等式可以得到 Pearson Similarity 的取值范围是 
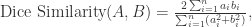
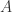 和
和 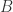 不能同时是零点,并且由均值不等式可以得到 Dice Similarity 的范围也是
不能同时是零点,并且由均值不等式可以得到 Dice Similarity 的范围也是  个点所组成的集合。因此,下面的集合相似度判断方法同样适用于欧式空间的两个点。
个点所组成的集合。因此,下面的集合相似度判断方法同样适用于欧式空间的两个点。
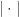 表示集合的势,并且 Jaccard 相似度的取值范围是
表示集合的势,并且 Jaccard 相似度的取值范围是 ![[0,1].](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D.&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 越靠近
越靠近  表示两个集合越相似,越靠近
表示两个集合越相似,越靠近  表示两个集合越不相似。
表示两个集合越不相似。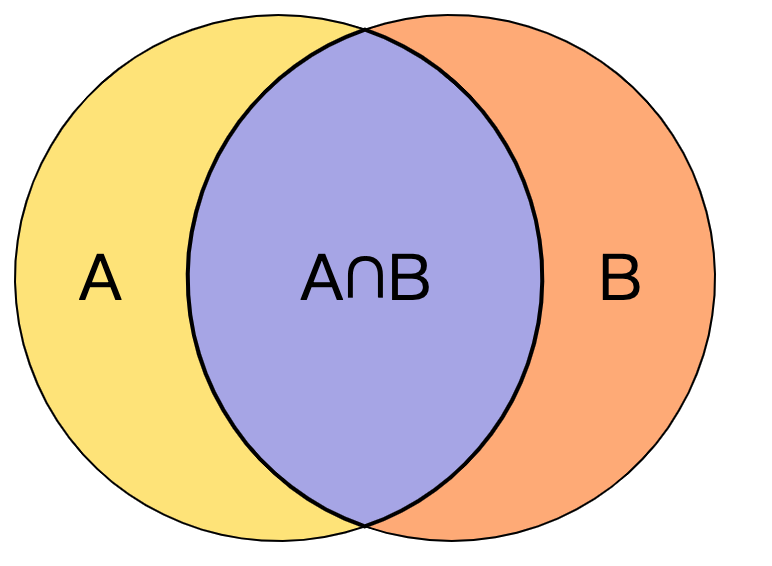



 指的是条件概率,意思分别是
指的是条件概率,意思分别是 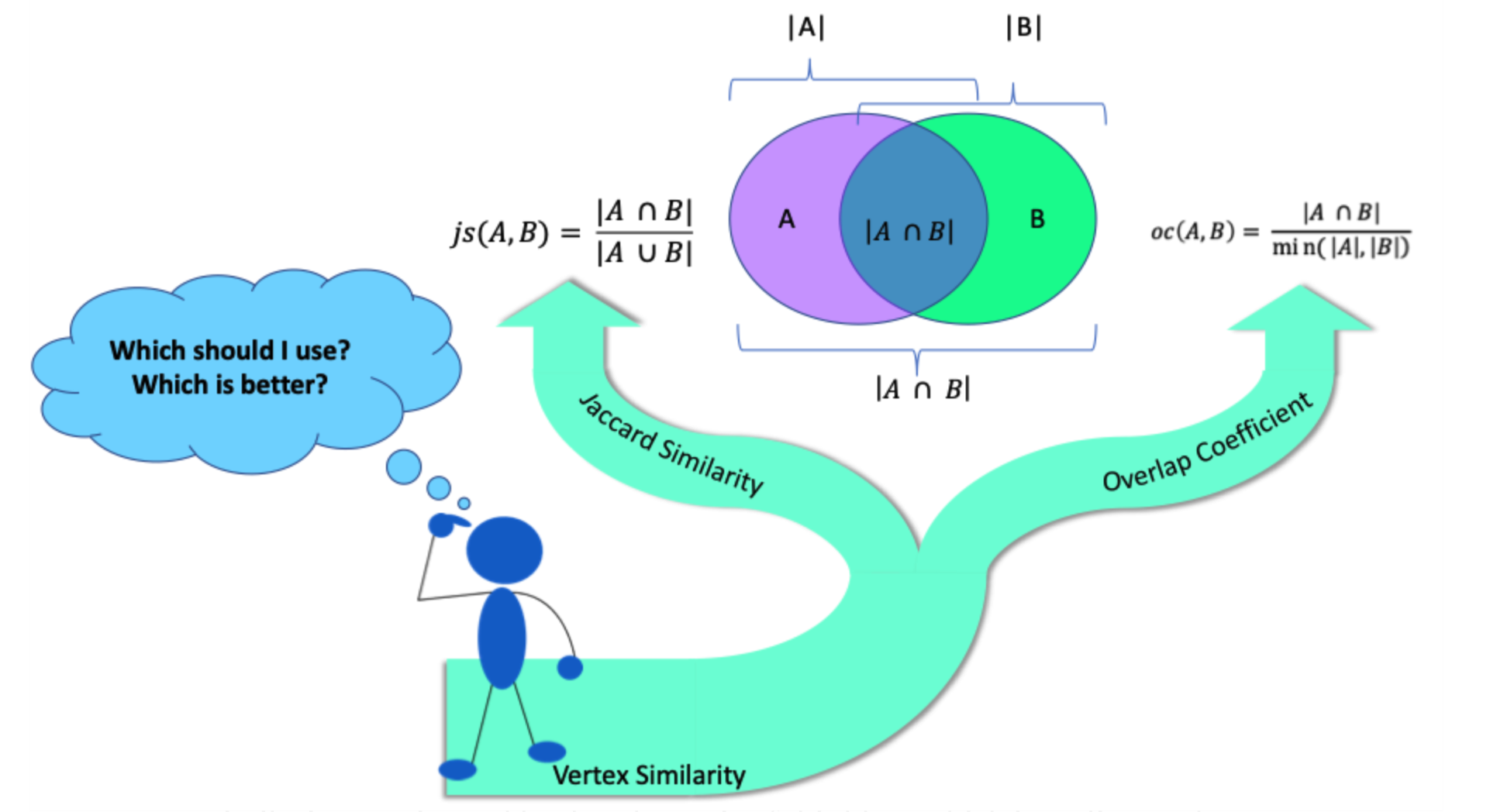

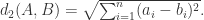
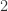 进行推广,则可以引导出
进行推广,则可以引导出 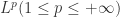 距离如下:
距离如下: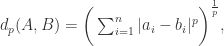 其中
其中 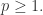

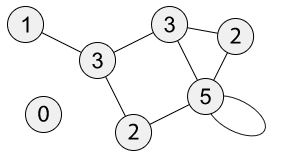
 中,
中, 表示顶点集合,
表示顶点集合,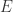 表示边的集合。为了简单起见,这里暂时是考虑无向图的场景。对于顶点
表示边的集合。为了简单起见,这里暂时是考虑无向图的场景。对于顶点  而言,
而言, 表示其邻居的集合。在复杂网络中,同样需要描述两个顶点
表示其邻居的集合。在复杂网络中,同样需要描述两个顶点 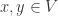 的相似性,于是可以考虑以下指标。
的相似性,于是可以考虑以下指标。

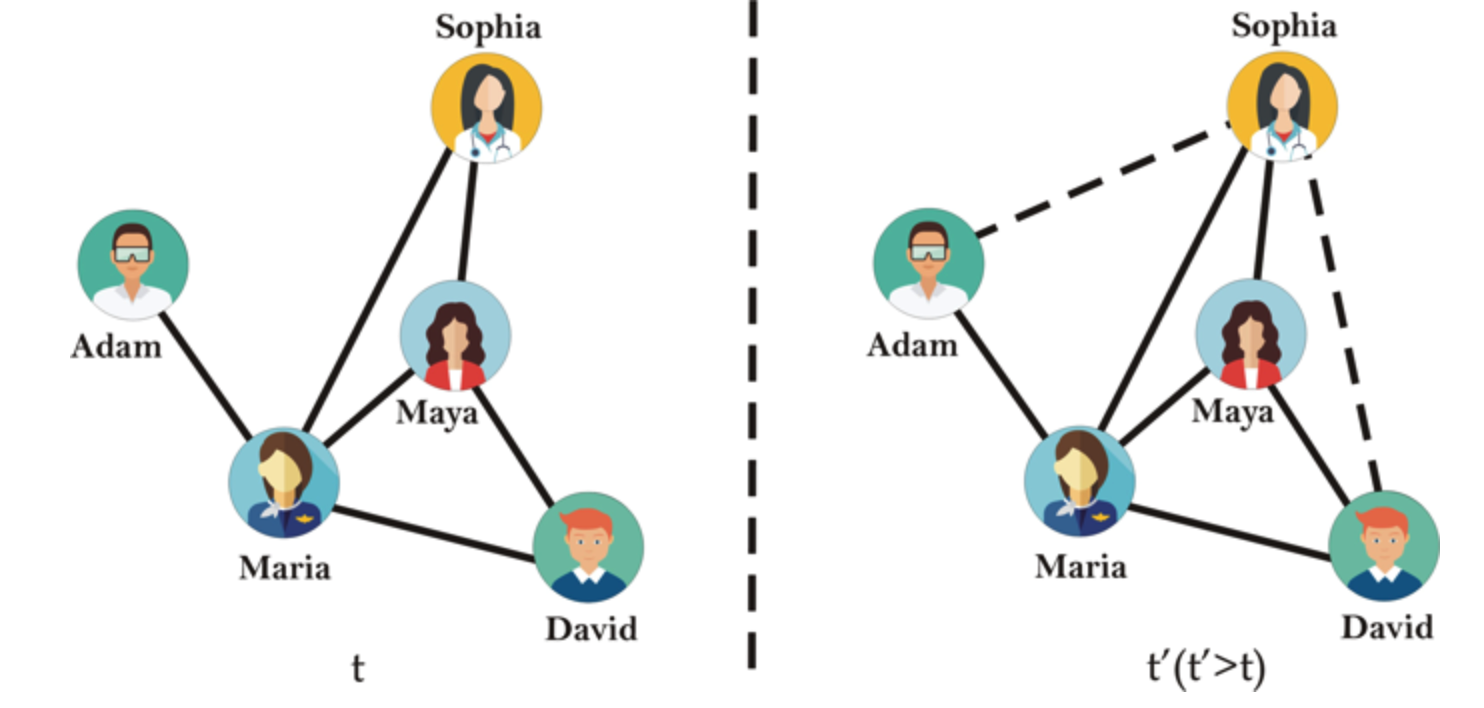
 和
和 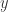 的邻居求并集,也可以得到一个指标,
的邻居求并集,也可以得到一个指标,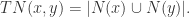
 它将
它将 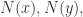
 就可以作为顶点
就可以作为顶点 
 和
和 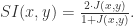
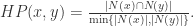


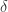 用于判断
用于判断  之间是否有边相连接。如果相连接,则取值为
之间是否有边相连接。如果相连接,则取值为  否则取值为
否则取值为 

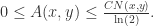 事实上,当
事实上,当  时,
时,
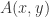 越大,表示顶点
越大,表示顶点  的共同邻居
的共同邻居  拥有较多的邻居,则降低权重,否则增加权重。
拥有较多的邻居,则降低权重,否则增加权重。
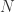 和
和 
 的定义是随机从
的定义是随机从  条边所生成的所有图集合中选择一个。其中,这样的图集合的势是
条边所生成的所有图集合中选择一个。其中,这样的图集合的势是  因此获得其中某一个图的概率是
因此获得其中某一个图的概率是 
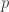 ,
, 的定义是有
的定义是有 ![p\in[0,1]](https://s0.wp.com/latex.php?latex=p%5Cin%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 来决定是否连边。
来决定是否连边。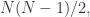 而
而  这里的
这里的  指的是组合数。i.e.
指的是组合数。i.e. 
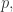 而
而  条边,于是边数为
条边,于是边数为  i.e.
i.e. 
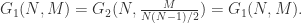
 但如果要计算图的其余指标,用第二种定义
但如果要计算图的其余指标,用第二种定义 
 而言,它的边数大约是
而言,它的边数大约是  最多与该节点相连接的顶点数为
最多与该节点相连接的顶点数为  整个图的顶点平均度是(边数 * 2) / 顶点数,用记号
整个图的顶点平均度是(边数 * 2) / 顶点数,用记号 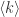 来表示,意味着顶点平均度是
来表示,意味着顶点平均度是  当
当 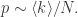
 而言,我们想计算它恰好有
而言,我们想计算它恰好有  条边的概率值。事实上,对于除了
条边的概率值。事实上,对于除了  个点而言,有
个点而言,有  个顶点与
个顶点与  同时需要从这
同时需要从这 
 时,上述概率近似于泊松分布(Possion Distribution)。事实上,
时,上述概率近似于泊松分布(Possion Distribution)。事实上, 并且
并且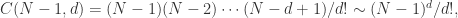

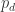 近似于泊松分布,
近似于泊松分布,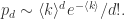
 而言,它的连通分支个数是与顶点的平均度
而言,它的连通分支个数是与顶点的平均度  时,每个顶点都是孤立的,连通分支个数为
时,每个顶点都是孤立的,连通分支个数为  当
当  时,任意两个顶点都有边相连接,整个图是完全图,连通分支的个数是
时,任意两个顶点都有边相连接,整个图是完全图,连通分支的个数是  顶点的平均度从
顶点的平均度从 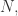 那么在这个变化的过程中,最大连通分支的顶点数究竟是怎样变化的呢?是否存在一些临界点呢?数学家 Erdos 和 Renyi 在 1959 年的论文中给出了答案:
那么在这个变化的过程中,最大连通分支的顶点数究竟是怎样变化的呢?是否存在一些临界点呢?数学家 Erdos 和 Renyi 在 1959 年的论文中给出了答案: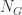 表示最大连通分支的顶点个数,那么对于图的平均度
表示最大连通分支的顶点个数,那么对于图的平均度  那么
那么 
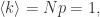 那么
那么 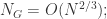
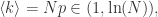 那么巨连通分支(Giant Component)存在,同时存在很多小的连通分支,在临界点
那么巨连通分支(Giant Component)存在,同时存在很多小的连通分支,在临界点  这里
这里 
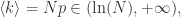 那么图
那么图 
 当
当  时,巨连通分支不存在,所有连通分支的量级都在
时,巨连通分支不存在,所有连通分支的量级都在 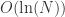 以下;当
以下;当  时,巨连通分支开始出现,量级大约是
时,巨连通分支开始出现,量级大约是  当
当  时,随机图存在一个巨连通分支和很多小的连通分支;当
时,随机图存在一个巨连通分支和很多小的连通分支;当  时,图是连通图。
时,图是连通图。
 图的顶点不在最大连通分支的概率。
图的顶点不在最大连通分支的概率。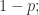 Case(2):要么
Case(2):要么  个顶点中,其概率是
个顶点中,其概率是 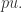 于是,对于所有顶点而言,它不在最大连通分支的概率是
于是,对于所有顶点而言,它不在最大连通分支的概率是  于是,
于是,
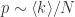 和
和  可以得到当
可以得到当 
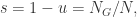 它表示最大连通分支的顶点个数在所有顶点个数的占比,从而可以得到近似方程:
它表示最大连通分支的顶点个数在所有顶点个数的占比,从而可以得到近似方程:
 则
则 
 它的导数是
它的导数是  通过计算可以得到:
通过计算可以得到: 时,
时, 在
在 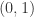 上成立,i.e.
上成立,i.e.  在
在 ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 上的唯一解是
上的唯一解是  换言之,
换言之,
 时,
时,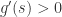 在
在  成立,
成立, 成立。换言之,
成立。换言之, 在
在 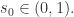 此时会存在巨连通分支,
此时会存在巨连通分支, 是解。
是解。 的情况。对于极限状况而言,假设仅有一个顶点不在最大连通分支中,那么
的情况。对于极限状况而言,假设仅有一个顶点不在最大连通分支中,那么  此刻,
此刻,
 因此,
因此,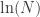 也是一个临界点,并且是出现全连通图的临界点。
也是一个临界点,并且是出现全连通图的临界点。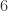 个相识关系。换言之,来自世界上任何地方的两个人都可以通过不超过
个相识关系。换言之,来自世界上任何地方的两个人都可以通过不超过 
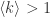 的情况,甚至只考虑
的情况,甚至只考虑  的全连通图。任取一个顶点
的全连通图。任取一个顶点  个距离为
个距离为 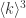 个距离为
个距离为 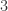 的顶点;
的顶点; 个距离为
个距离为  的顶点;
的顶点;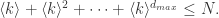 通过等比级数的公式可以得到
通过等比级数的公式可以得到  因此,
因此,
 如果
如果  并且每个人认识
并且每个人认识  个人,于是随机图的直径量级是
个人,于是随机图的直径量级是 
