
就在今天(2020 年 3 月 21 日),新加坡首次出现两起由于新冠病毒(COVID-19)引起的死亡病例。

从 MOH(Ministry of Health)的官网上可以看到,今天已经有两位感染新冠病毒(Coronavirus Disease 2019,简称为 COVID-19)的病人在新加坡离世。
第一名病人是一位 75 岁的女性新加坡公民,于 2020 年 2 月 23 日送入 NCID,并且当天确诊感染了 COVID-19。
第二名病人是一位 64 岁的男性印度尼西亚公民,于 2020 年 3 月 13 日送入 NCID,并且于 2020 年 3 月 14 日确诊感染了 COVID-19。

从新加坡政府的官网上可以看到:截止时间至 2020 年 3 月 21 日 12 点,现存确诊为 252 例(238 例稳定,14 例严重), 死亡 2 例,治愈 131 例。
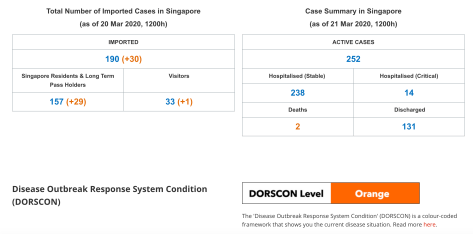
疾病爆发相应等级为橙色(orange)。

而新加坡政府也在其主页上呼吁大家注意卫生:
- 勤洗手,多用肥皂;
- 每天测量两次体温;
- 咳嗽或者打喷嚏的时候用纸巾遮住口鼻;
- 及时处理垃圾和食物,保持桌面整洁;
- 注意室内通风,保持厕所干净。
一旦发现自己生病,请带上口罩去医院,并且保证后续在家隔离。
而近三天,新加坡也有不少新增的病例。2020 年 3 月 20 日有 40 个病例,其中 30 位有欧洲,北美,亚洲的旅游史,7 位联系上了以前的病例,3 位没有找到传染病联系。

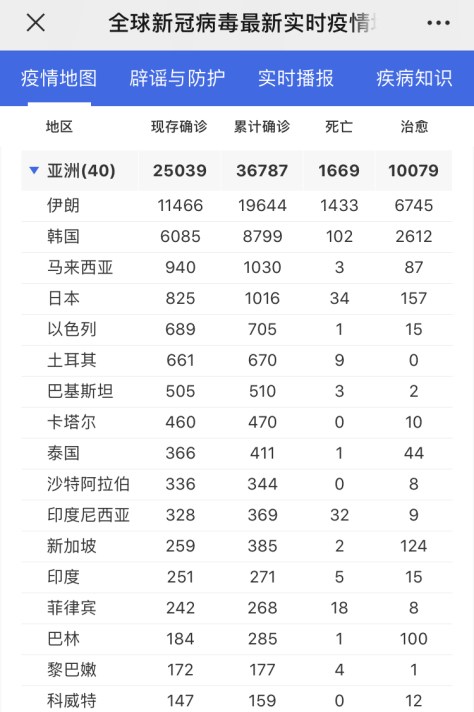
除此之外,从丁香医生的小程序可以看出,亚洲很多国家的疫情其实不容乐观。
最后,无论在国内还是国外,大家都要注意安全。抗击疫情,人人有责。

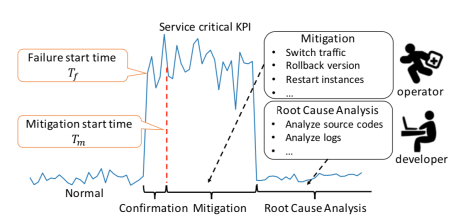
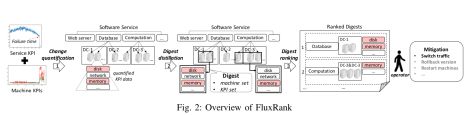
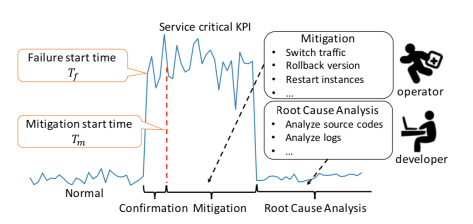
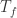 ,这个时间戳是运维领域非常重要的时间戳,它由异常检测(anomaly detection)产生,无论在告警收敛(alarm convergence)还是根因分析(root cause analysis)都非常依赖这个时间戳。而另外一个时间戳虽然没有故障开始时间那么重要,但是也有着其实用价值,那就是缓和开始时间(mitigation start time),它表示故障虽然还没有恢复,但是出于稍微平稳的走势,并没有持续恶化。在出现了故障之后,通常都会发送相应的告警给运维人员,那么在发送告警的时候,如果将异常定位的结果随之带出,则会大大减少运维人员排障的时间。在故障缓和的时间内,运维人员通常需要进行必要的操作来排查故障,例如切换流量(switch Traffic),回滚版本(Rollback Version),重启实例(Restart Instances),下线机器等操作。除此之外,为了定位问题(Root Cause Analysis),运维人员需要分析源码(Code Analysis),查看日志(Log Analysis)等一系列操作。如果能够将这一系列操作融入相应的机器学习模块中,将会节省运维人员大量的排障时间。
,这个时间戳是运维领域非常重要的时间戳,它由异常检测(anomaly detection)产生,无论在告警收敛(alarm convergence)还是根因分析(root cause analysis)都非常依赖这个时间戳。而另外一个时间戳虽然没有故障开始时间那么重要,但是也有着其实用价值,那就是缓和开始时间(mitigation start time),它表示故障虽然还没有恢复,但是出于稍微平稳的走势,并没有持续恶化。在出现了故障之后,通常都会发送相应的告警给运维人员,那么在发送告警的时候,如果将异常定位的结果随之带出,则会大大减少运维人员排障的时间。在故障缓和的时间内,运维人员通常需要进行必要的操作来排查故障,例如切换流量(switch Traffic),回滚版本(Rollback Version),重启实例(Restart Instances),下线机器等操作。除此之外,为了定位问题(Root Cause Analysis),运维人员需要分析源码(Code Analysis),查看日志(Log Analysis)等一系列操作。如果能够将这一系列操作融入相应的机器学习模块中,将会节省运维人员大量的排障时间。
 。
。 ,
, 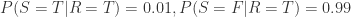 。
。 ,
,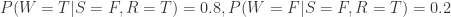 ,
, ,
,
 。从 Bayes 公式可以得到:
。从 Bayes 公式可以得到: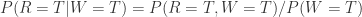 。分别计算分子分母即可:
。分别计算分子分母即可:

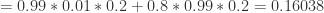 ,
,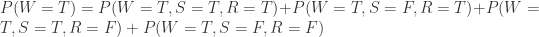
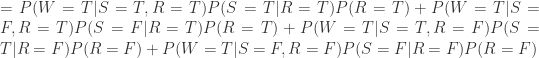

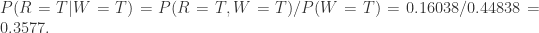
 。在失败开始时间
。在失败开始时间 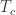 小于或者等于
小于或者等于  即可。关键时间点的排序为
即可。关键时间点的排序为  。
。![X=[x_{1},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 而言,MAD 定义为
而言,MAD 定义为  ,而每个点的异常程度可以定义为:
,而每个点的异常程度可以定义为: 当
当 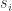 较大或者较小的时候,表示上涨或者下降的异常程度。通过设置相应的阈值,同样可以获得时间序列的异常开始时间。
较大或者较小的时候,表示上涨或者下降的异常程度。通过设置相应的阈值,同样可以获得时间序列的异常开始时间。![X=[x_{1},x_{2},\cdots,x_{n}]](https://s0.wp.com/latex.php?latex=X%3D%5Bx_%7B1%7D%2Cx_%7B2%7D%2C%5Ccdots%2Cx_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,可以预估它的目标值(target value)
,可以预估它的目标值(target value)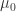 ,通常可以用均值来估计,也需要计算出这条时间序列的标准差
,通常可以用均值来估计,也需要计算出这条时间序列的标准差 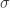 。通常设定
。通常设定  ,
, 。而 Tabular CUSUM 指的是迭代公式
。而 Tabular CUSUM 指的是迭代公式 ![C_{i}^{+}=\max[0,x_{i}-(\mu_{0}+K)+C_{i-1}^{+}]](https://s0.wp.com/latex.php?latex=C_%7Bi%7D%5E%7B%2B%7D%3D%5Cmax%5B0%2Cx_%7Bi%7D-%28%5Cmu_%7B0%7D%2BK%29%2BC_%7Bi-1%7D%5E%7B%2B%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
,![C_{i}^{-}=\max[0,(\mu_{0}-K)-x_{i}+C_{i-1}^{-}]](https://s0.wp.com/latex.php?latex=C_%7Bi%7D%5E%7B-%7D%3D%5Cmax%5B0%2C%28%5Cmu_%7B0%7D-K%29-x_%7Bi%7D%2BC_%7Bi-1%7D%5E%7B-%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,初始值是
,初始值是  。当累计偏差
。当累计偏差  或者
或者  大于
大于  的时候,表示
的时候,表示  出现了异常,也就是 out of control。通过这个值,可以获得时间序列开始异常的时间。
出现了异常,也就是 out of control。通过这个值,可以获得时间序列开始异常的时间。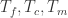 等时间戳。根据变化开始时间(change start time)
等时间戳。根据变化开始时间(change start time) ,例如 60 分钟(1 小时)。可以从两个时间段获取数据,正常时间段
,例如 60 分钟(1 小时)。可以从两个时间段获取数据,正常时间段  ,异常时间段
,异常时间段 ![[T_{c},T_{m}]](https://s0.wp.com/latex.php?latex=%5BT_%7Bc%7D%2CT_%7Bm%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,分别获取到数据
,分别获取到数据  和
和  ,前者是在变化开始时间之前的数据点,后者是在变化开始之后的数据点。于是,作者们通过概率值来计算变化程度
,前者是在变化开始时间之前的数据点,后者是在变化开始之后的数据点。于是,作者们通过概率值来计算变化程度  ,意思就是计算一个条件概率,在观察到
,意思就是计算一个条件概率,在观察到  ,在这里
,在这里 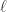 表示集合
表示集合 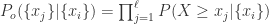 ,
,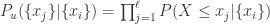 ,
,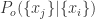 表示上涨的程度,
表示上涨的程度,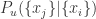 表示下降的程度。如果不想处理连乘的话,则需要处理连加:
表示下降的程度。如果不想处理连乘的话,则需要处理连加: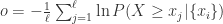 ,
, .
.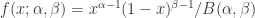 ,其中
,其中  。在机器 KPIs 中,CPU 等指标可以用 Beta 分布;
。在机器 KPIs 中,CPU 等指标可以用 Beta 分布; ,在机器 KPIs 中,SYS_OOM 用于衡量超出内存的频率,可以用泊松分布来做。
,在机器 KPIs 中,SYS_OOM 用于衡量超出内存的频率,可以用泊松分布来做。 。
。
 和
和  两个值。
两个值。 个 KPIs,那么这台机器所对应的向量就是
个 KPIs,那么这台机器所对应的向量就是  。
。![Y=[y_{1},\cdots,y_{n}]](https://s0.wp.com/latex.php?latex=Y%3D%5By_%7B1%7D%2C%5Ccdots%2Cy_%7Bn%7D%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) ,
, 其中
其中 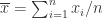 ,
,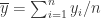 。
。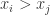 且
且  ) 或者 (
) 或者 ( 且
且  ),那么称之为 concordant;如果 (
),那么称之为 concordant;如果 ( 或者
或者  ,则既不是 concordant,也不是 discordant。那么 Kendall tau 定义为
,则既不是 concordant,也不是 discordant。那么 Kendall tau 定义为 ![[\text{(number of concordant pairs)}-\text{(number of disordant paris)}] / [n(n-1)/2]](https://s0.wp.com/latex.php?latex=%5B%5Ctext%7B%28number+of+concordant+pairs%29%7D-%5Ctext%7B%28number+of+disordant+paris%29%7D%5D+%2F+%5Bn%28n-1%29%2F2%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002)
 ,后者表示
,后者表示 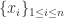 的位置,称之为秩次(rank),得到序列
的位置,称之为秩次(rank),得到序列 ![X'=[x_{1}',\cdots,x_{n}']](https://s0.wp.com/latex.php?latex=X%27%3D%5Bx_%7B1%7D%27%2C%5Ccdots%2Cx_%7Bn%7D%27%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。对原始序列
。对原始序列 ![Y'=[y_{1}',\cdots,y_{n}']](https://s0.wp.com/latex.php?latex=Y%27%3D%5By_%7B1%7D%27%2C%5Ccdots%2Cy_%7Bn%7D%27%5D&bg=ffffff&fg=2b2b2b&s=0&c=20201002) 。一个相同的值在一列数据中必须有相同的秩次,那么在计算中采用的秩次就是数值在按从大到小排列时所在位置的平均值。如果没有相同的 rank,那么使用公式
。一个相同的值在一列数据中必须有相同的秩次,那么在计算中采用的秩次就是数值在按从大到小排列时所在位置的平均值。如果没有相同的 rank,那么使用公式 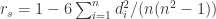 进行计算,其中
进行计算,其中  ;如果存在相同的秩次,则对
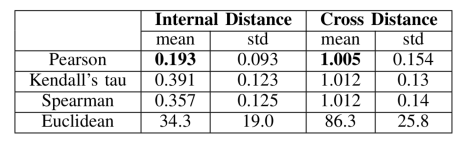
;如果存在相同的秩次,则对  。
。
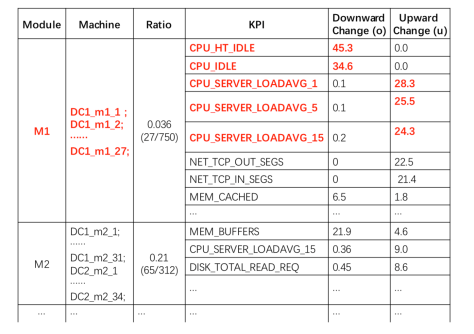

 或者
或者 
