
随着 DeepMind 成功地使用卷积神经网络(CNN)和强化学习来玩 Atari 游戏,AlphaGo 击败围棋职业选手李世石,强化学习已经成为了机器学习的一个重要研究方向。除此之外,随着人工智能的兴起,自然语言处理在聊天机器人和智能问答客服上也有着广泛的应用。之前在一篇博客里面曾经介绍了强化学习的基本概念,今天要介绍的是强化学习在文本领域的应用,也就是如何使用强化学习来玩文本游戏。要分享的 Paper 是 Deep Reinforcement Learning with a Natural Language Action Space,作者是 Microsoft 的 Ji He 与他的合作者们。
对于强化学习而言,那就不得不提到 Markov 决策过程(Markov Decision Process)。它是由状态(State),动作(Action),状态转移概率(State Transition Probability),折扣因子(Discount Factor),奖励函数(Reward Function)五个部分构成。强化学习做的事情就是该 agent 在某一个时刻处于某个状态 s,然后执行了某个动作 a,从整个环境中获得了奖励 r,根据状态 s 和奖励 r 来继续选择下一个动作 a,目标是让获得的奖励值最大。整个过程其实是一个不断地从环境中执行动作和获得奖励的过程,通过引入动作值函数 Q(s,a) 的概念,介绍了 Q-learning 这个基本算法。通过 Q-learning 来让 agent 获得最大的奖励。
在实际的生产环境中,状态空间 S 很可能是十分巨大的,如果对于 Atari 游戏的话,动作空间 A 是有限的(例如上下左右移动,攻击,躲避等)。因此 DeepMind 在处理这个问题的时候,创新性地使用了卷积神经网络(CNN)和强化学习(RL)两者结合的解决方案。通过 CNN 来读取游戏图像,然后神经网络输出的是动作值函数 Q(s,a),其中 a 就是游戏手柄上的几个动作按钮。然后使用周围环境的反馈和强化学习方法来获得相应的样本,从而训练整个 CNN 神经网络。
下面来介绍本文的正式内容。首先文本游戏和视觉游戏有一定的差别,视觉游戏的状态就是当前的屏幕图像,文本游戏的状态是一段文本描述,然后玩家来给出一个合适的动作进入下一个状态。例如:白色的文字描述就是当前的状态,蓝色的文字就是玩家要选择的动作。

当玩家选择了其中一个状态(例如选择了第一个 A Lister sandwich)之后,就会进入下一个状态,如图所示。

注:关于文本游戏 Machine of Death 的代码和基本信息,可以参见 https://github.com/jvking/text-games.
为了做一个 agent 使其能够自主地玩文本游戏,基于当前的文本游戏背景,就要考虑到两种文本情况,分别是状态文本(state-text)和动作文本(action-text)。agent 需要同时理解这两部分的文本,然后争取在玩游戏的过程中获得最大的收益,最终才能够学会玩游戏。对于每一个时刻 t,状态是 

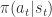

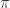
![Q^{\pi}(s,a)=E[\sum_{i=0}^{\infty}\gamma^{i}r_{t+i}|s_{t}=s, a_{t}=a]](https://s0.wp.com/latex.php?latex=Q%5E%7B%5Cpi%7D%28s%2Ca%29%3DE%5B%5Csum_%7Bi%3D0%7D%5E%7B%5Cinfty%7D%5Cgamma%5E%7Bi%7Dr_%7Bt%2Bi%7D%7Cs_%7Bt%7D%3Ds%2C+a_%7Bt%7D%3Da%5D&bg=ffffff&fg=2b2b2b&s=1&c=20201002)
在该paper中,作者使用 softmax 策略来进行必要的探索活动,也就是说在状态

在这里 

因为状态文本(state-text)通常来说是长文本,动作文本(action-text)是短文本,两者有着本质的区别,因此作者在构建神经网络的时候分别对状态文本和动作文本搭建了相应的神经网络。在本文中,作者对比了三种神经网络结构,分别是 Max-action DQN,Pre-action DQN 和 DRRN。如下图所示:

对于 Max-action DQN,该模型适用于对每一个状态
对于 Pre-action DQN,该模型把每一对状态文本和动作文本当作输入,也就是(状态文本,动作文本)这种形式,通过神经网络计算出这一对状态文本和动作文本的 Q 值。
对于 DRRN,该模型把每一对状态文本和动作文本当作输入,依旧是(状态文本,动作文本)这种形式。然后对状态文本和动作文本分别构建一个神经网络,然后对输出的两个向量进行内积的操作,从而获得 Q 值。用数学语言来描述就是,给定一个状态文本和动作文本的对,也就是 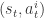

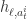

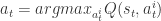







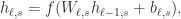

其中 f 是激活函数,

综上所述,DRRN 的伪代码如下:

DRRN 相比另外两个模型其创新点在于分别使用了两个网络来映射状态文本和动作文本,因为如果将长文本和短文本直接拼接输入单个神经网络结构的时候,可能会降低 Q 值的质量,所以把 state-text 和 action-text 分别放入不同的网络结构进行学习,最后使用内积合并的方式获得 Q 值的方法会更加优秀。
参考文献:
- Deep Reinforcement Learning with a Natural Language Action Space
