
Excellent
Value Iteration Networks Tamar et al., NIPS 2016
‘Value Iteration Networks’ won a best paper award at NIPS 2016. It tackles two of the hot issues in reinforcement learning at the moment: incorporating longer range planning into the learned strategies, and improving transfer learning from one problem to another. It’s two for the price of one, as both of these challenges are addressed by an architecture that learns to plan.
In the grid-world domain shown below, a standard reinforcement learning network, trained on several instances of the world, may still have trouble generalizing to a new unseen domain (right-hand image).
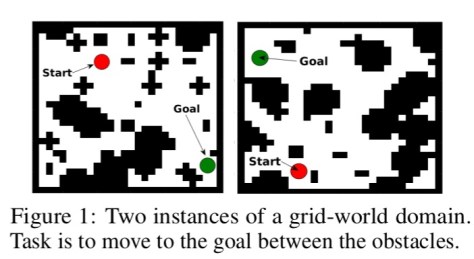
(This setup is very similar to the maze replanning challenge in ‘Strategic attentive writer for learning macro actions‘ from the Google DeepMind team that we looked at earlier this year. Both papers were published at the same time).
… as we show in our experiments, while standard…
View original post 1,025 more words
